[230804]Grounding DINO (Marrying DINO with Grounded Pre-Training for Open-Set Object Detection)
Object detection
목록 보기
7/23
왜 해?
- GLIP(https://velog.io/@hsbc/230818-Grounded-language-image-pre-training.-GLIP)과 다르게, transformer SOTA 였던 DINO(https://velog.io/@hsbc/230804-DETR-with-Improved-DeNoising-AnchorBoxes-for-End-to-End-Object-Detection-DINO)를 기반으로 multi-modality정보를 융합하는 구조를 제안하여 오픈셋 객체 탐지 성능을 더 높임.
- 이전에는(GLIP) 주로 새로운 물체에 대한 탐지 능력을 평가했지만, 이 논문에서는 물체의 특징을 설명하는 언어를 이해하는 능력도 함께 평가
- 오픈셋 객체 탐지 평가를
참조 표현 이해(REC) 데이터셋에 확장하는 것을 제안- Reference Expression Comprehension: 객체들이 속성으로 설명되는 것
- 본 연구에서는 오픈셋 객체 탐지를 REC를 지원하도록 확장하고, 또한 REC 데이터셋에서의 성능을 평가합니다.
- 이는 freeform text inputs 에 대한 성능을 높일 수 있습니다.
- 오픈셋 객체 탐지 평가를
Abstract
- 오픈셋 객체 탐지를 더 잘하기 위해, 언어를 사용해서 모델에 새로운 물체의 정보를 주입하는 방법을 사용
- 이렇게 하면 모델이 이전에 학습한 내용을 바탕으로 새로운 물체를 이해할 수 있습니다.
- 이를 위해 모델을 세 단계로 나누어 생각합니다.
- 첫 번째:
물체의 특징을 더 잘 잡아내기 위해 정보를 강화 - 두 번째:
언어를 사용해서 어떤 물체를 찾을지에 대한 질문을 모델에게 줌. - 세 번째:
시각 정보와 언어 정보를 합쳐서 정확한 결과를 얻을 수 있도록 하는 디코더를 사용
- 첫 번째:
언어와 이미지를 모두 처리할 수 있고 대규모 데이터를 활용할 수 있는 transformer detector인 DINO+grounded pre-training을 결합- grounded pre-training
- 큰 언어 모델을 미리 학습한 후, 다양한 실세계 환경과 상호작용하며 특정 도메인에 대해 추가적인 지식을 습득하는 것을 의미합니다.
- 즉, 해당 도메인의 추가 데이터를 이용하여 사전 훈련된 모델을 세밀하게 조정하고 특정 도메인에 대한 지식을 강화합니다.
- 이렇게 하면 기존의 사전 훈련된 언어 모델이 다양한 도메인과 상황에서 더 잘 작동할 수 있습니다.
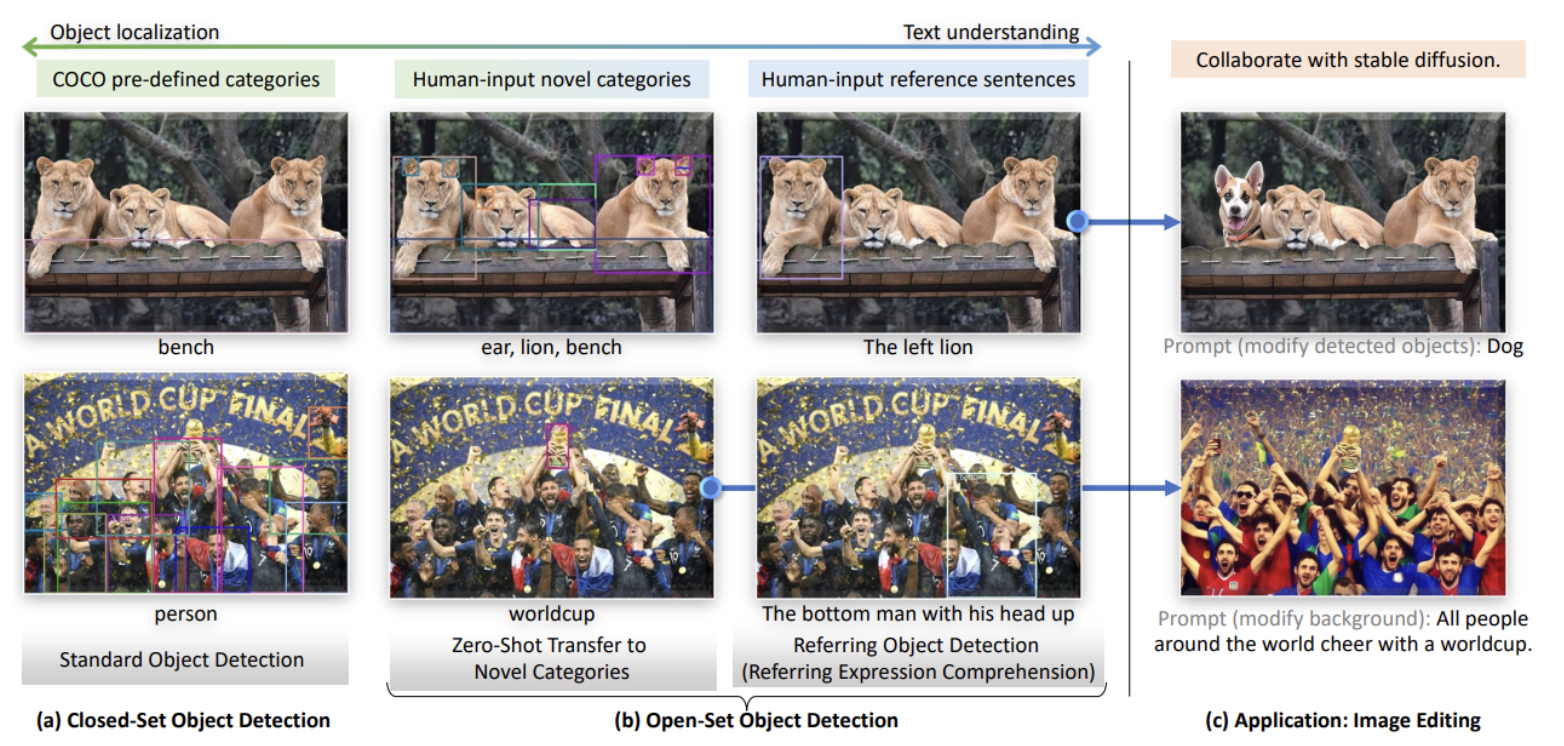
Introduction
- 사람의 언어로 지정한 물체를 감지하는 강력한 시스템("오픈셋 객체 탐지")을 개발하는게 목적
- 오픈셋 객체 탐지의 핵심 아이디어는 이전에 보지 못한 물체에 대한 언어 정보를 활용하는 것
- 예를 들어, GLIP라는 방법은 물체 감지를 언어 문구와 물체 영역을 연결시키는 작업으로 바꾸고, 이 둘 간에 대조적인 학습을 도입합니다.
- 그러나 GLIP은 전통적인 한 단계식 탐지 방법인 Dynamic Head 에 기반하여 만들어졌기 때문에 성능에 제약이 있을 수 있습니다.(transformer을 안씀).
- 우리 연구에서는 DINO를 기반으로 강력한 오픈셋 객체 탐지기를 만듦
- 이 모델은
물체 감지에서 최첨단 성능을 보여주는 동시에다중 수준의 텍스트 정보를 알고리즘에 통합할 수 있는 기능도 제공 - 우리는 이 모델을 "Grounding DINO"라고 부르겠습니다.
- Grounding DINO는 GLIP과 비교해 여러 가지 장점을 가지고 있습니다.
- 모든 이미지와 언어 분석 부분이 Transformers로 구성되어 있어서 다양한 정보를 효과적으로 결합할 수 있음 (모델의 성능을 개선하기 위해 더 많은 특성을 합치는 것이 중요한데, transformer 구조가 적절)
- 구체적으로, 목 단계에서는 자기 어텐션, 텍스트-이미지 교차 어텐션 및 이미지-텍스트 교차 어텐션을 쌓아 특성을 강화시키는 모듈을 설계
- 그리고 헤드 단계에서는 언어로 안내된 쿼리를 초기화하기 위한 방법을 개발
- 또한 이미지와 텍스트 교차 어텐션 레이어를 사용하여 헤드 단계에 교차 모달리티 디코더를 설계하여 쿼리의 표현을 강화
- 모든 이미지와 언어 분석 부분이 Transformers로 구성되어 있어서 다양한 정보를 효과적으로 결합할 수 있음 (모델의 성능을 개선하기 위해 더 많은 특성을 합치는 것이 중요한데, transformer 구조가 적절)
- 이 모델은
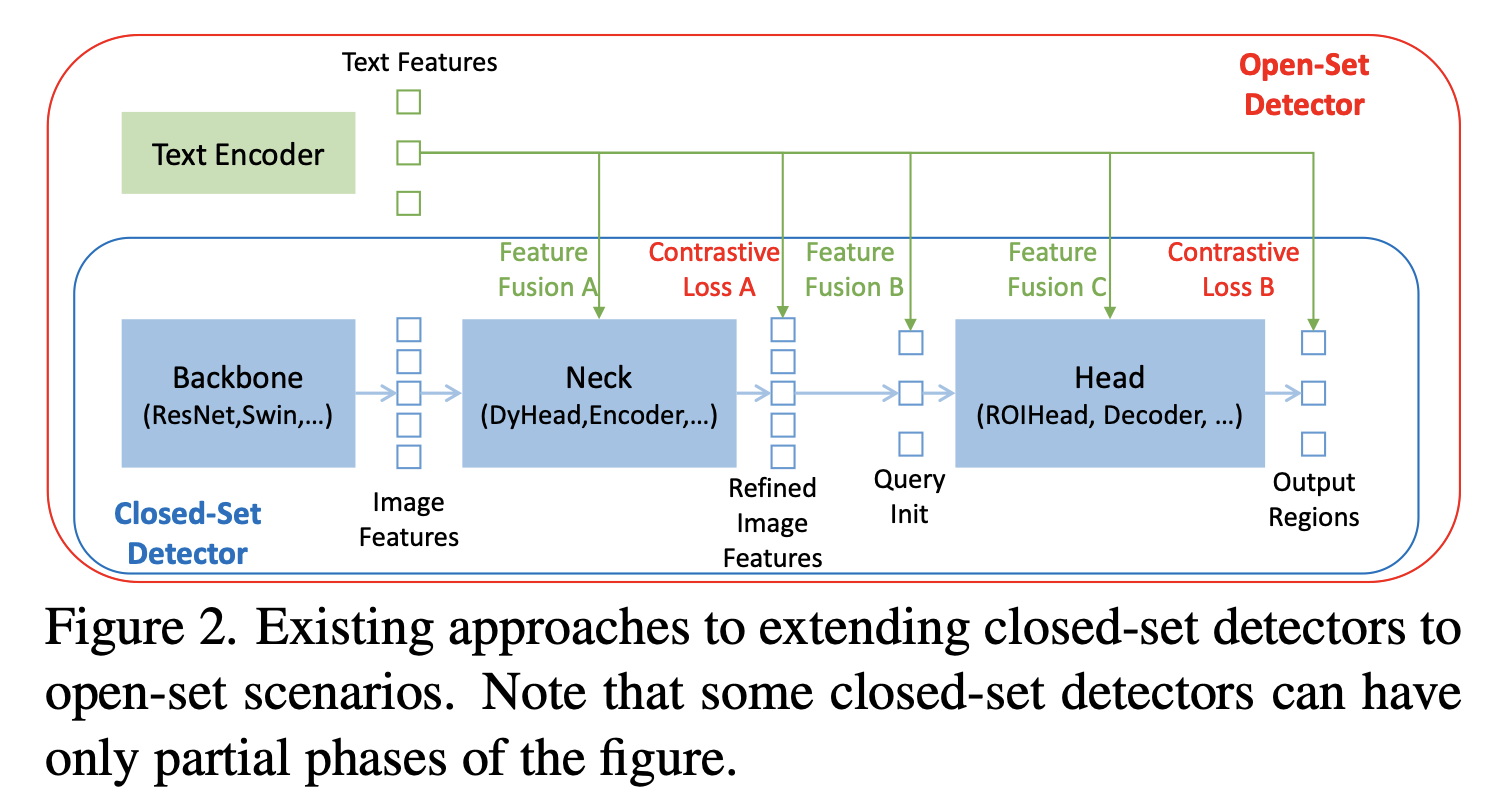
- 기존의 오픈셋 객체 탐지기는 폐쇄셋 객체 탐지기를 언어 정보를 활용한 오픈셋 상황에 맞게 확장한 것
- 이러한 폐쇄셋 객체 탐지기를 활용해 새로운 물체를 탐지하려면
언어 정보를 고려한 영역 표현을 학습해야 함각 영역을, (언어 정보와 연관지어) 새로운 범주로 분류할 수 있도록 학습- 이를 위해 영역 결과와 언어 특성 간의 대조 손실을 사용
Grounding DINO
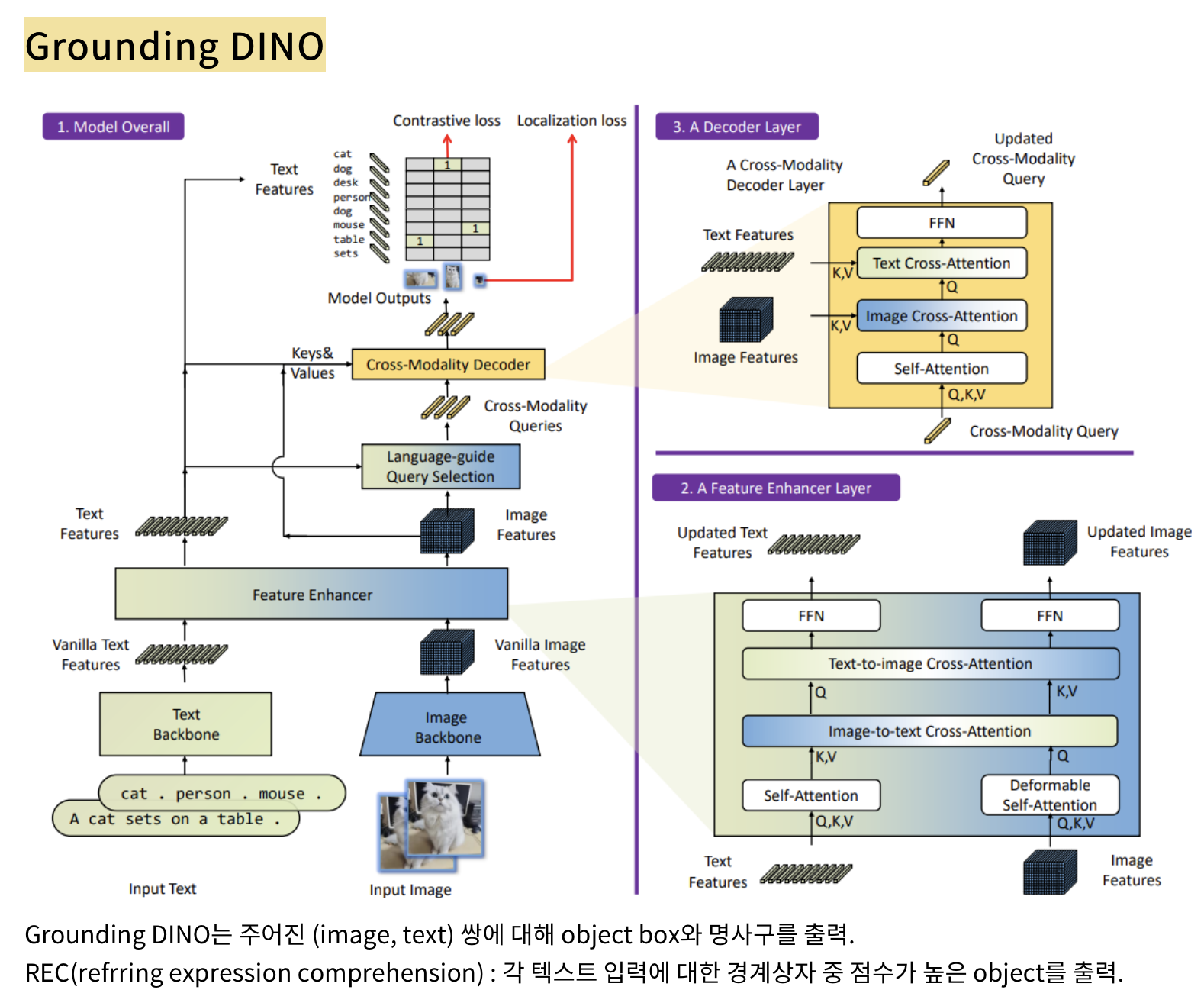
Feature Extraction and Enhancer
- 백본 모델을 통해 multi-scale image, text feature를 추출하고 self attention, cross attention.
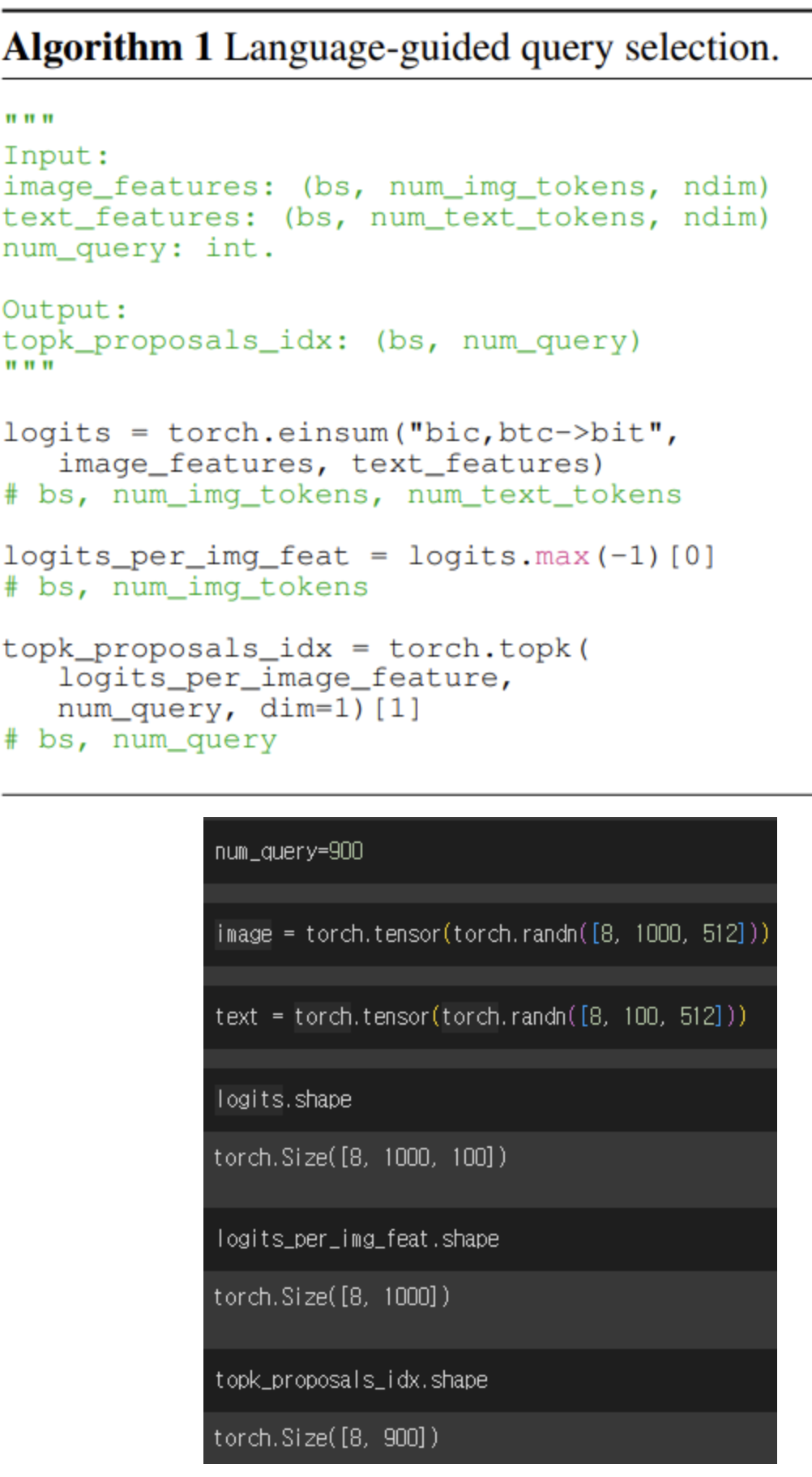
Language-Guided Query Selection
- 이미지 특성과 텍스트 특성 사이의 상호작용 점수를 계산합니다.
- 그런 다음 각 이미지 토큰에 대해 텍스트 토큰과의 최대 점수를 찾아냅니다.
- 마지막으로, 가장 높은 점수를 가진 쿼리 인덱스를 쿼리 수만큼 선택하여 출력합니다.
- 이 과정은 이미지와 텍스트 간의 관련성을 고려하여 쿼리를 선택하는 단계입니다.
- 위 과정으로 뽑은 쿼리를 DINO의 혼합 쿼리 선택의 위치 쿼리로 초기화.
Cross-Modality Decoder
- DINO의 디코더에서 text cross attention 레이어 추가.
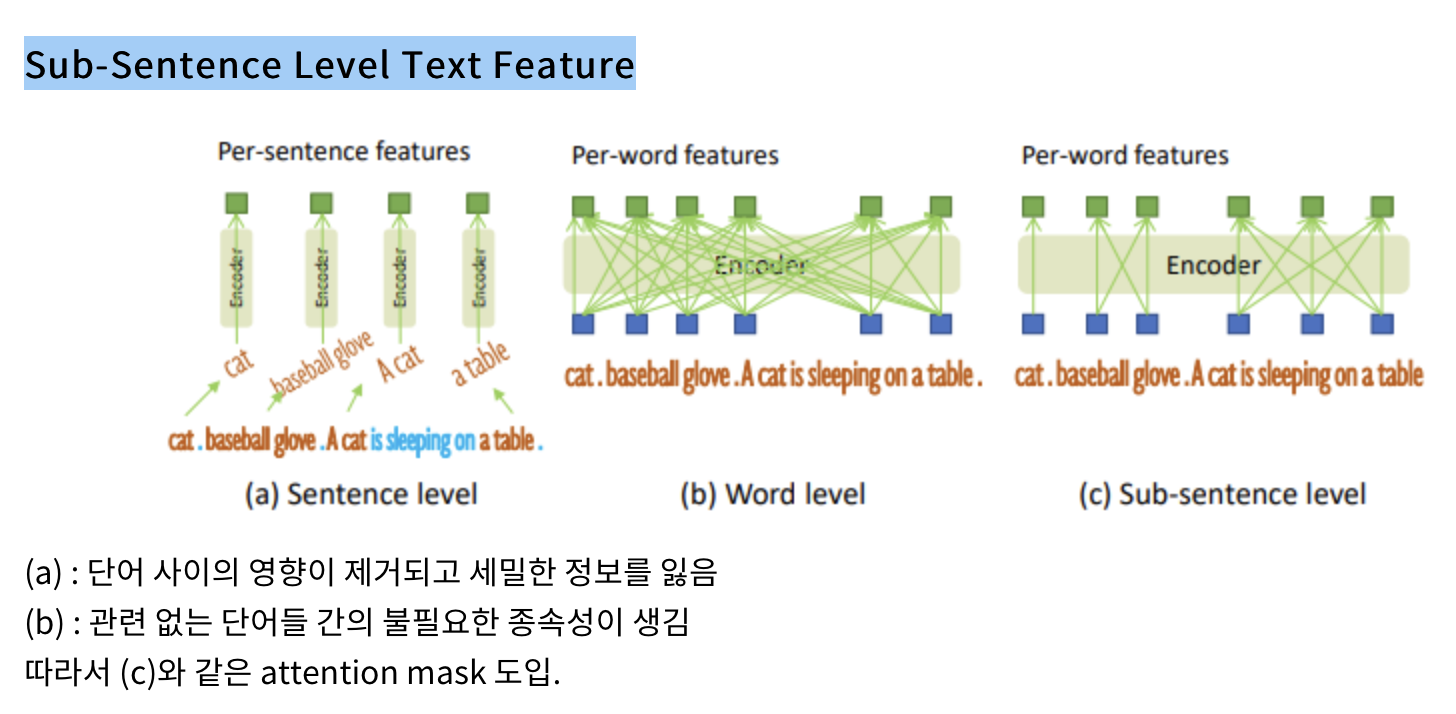
Sub-Sentence Level Text Feature
- text prompts 인코딩 방법. (c)를 택하였다.
- 그 이유는: 서로 다른 카테고리 이름 사이의 영향을 제거하면서 미세한 이해를 위한 단어별 특성을 유지합니다.
Loss Function
- bounding box regression: DETR-like 모델과 같이 L1 loss, GIOU loss,
- 분류: GLIP과 같이, 예측된 물체와 언어 토큰 사이의 Contrastive loss 사용.
- 구체적으로, 각 쿼리를 텍스트 특성과 내적하여 각 텍스트 토큰의 로짓을 예측한 다음, 각 로짓에 대해 포컬 손실 [28]을 계산합니다.
- DETR과 유사한 모델을 따라서, 각 디코더 레이어와 인코더 출력 이후에 보조 손실을 추가합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것