1. 목적
- self-supervised 방식으로 visual encoder를 학습시키는 방법을 소개
- 대량의 이미지를 가지고 모델 학습
2. 알고리즘
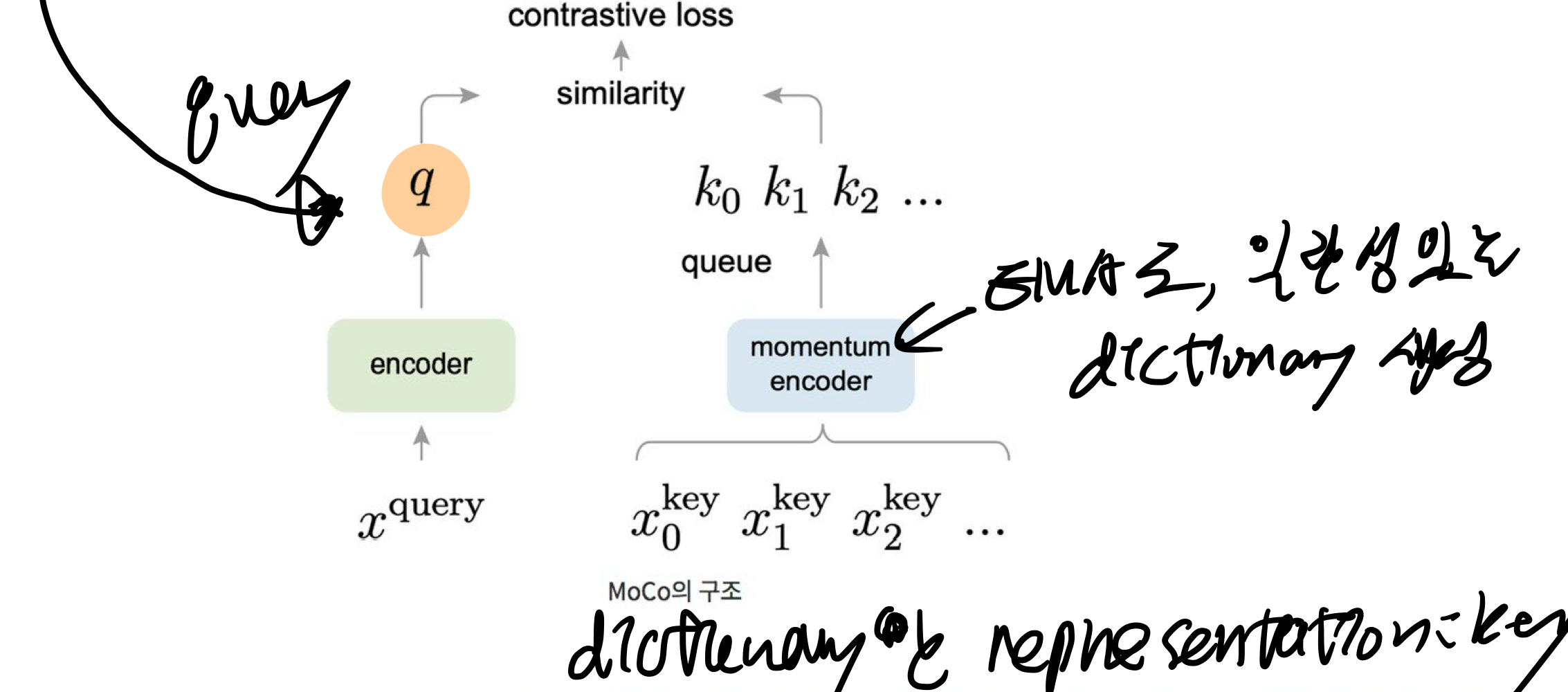
- query로 이미지를 통과시킨 후(왼쪽), 오른쪽에서 여러 positive sample과 negative sample을 통과시킵니다.
- positive sample과 유사도가 커지도록, negative sample과 유사도가 작아지도록 학습합니다.
- (오른쪽) key를 뽑아내는 encoder의 input으로는, 이미지가 들어갈 수도 있고, 이미지의 일부인 패치가 들어갈 수도 있음
- (오른쪽) dictionary란, 이미지들을 위 그림 오른쪽 encoder에 통과시켜서 얻은 representation들의 모음 (k0, k1, k2, ..)
- 효과적으로 학습을 하기 위해서는 dictionary가 클 수록 좋으며 dictionary를 구성하는 key의 representation이 일관적인 것이 좋음
- Dictionary의 크기가 커지면 encoder가 멀리해야할 negative sample들을 한꺼번에 많이 보고 학습할 수 있기 때문에 유리
- key encoder에는 contrastive loss를 흘려주는 대신, query encoder의 weight를 momentum-based moving average 방식으로 key encoder에 흘려주는 방식으로 key encoder를 천천히 학습시키는 방법을 선택
- 즉, Queue와 moving-averaged encoder를 사용해서 거대하고 일관성있는 dictionary를 만들수 있음
- mini-batch를 무한정 쌓아두진 않고, queue 형태로 queue가 꽉 찼다는 가정 하에 가장 들어온지 오래된 mini-batch를 dequeue하고 새로운 mini-batch를 enqueue
3. Loss function

- 위 MoCoLoss를 최소화해야함.
- 위 분모는 극대화하고 싶고, 분자는 최소화하고 싶다.
- 내적으로 유사도를 평가.
- temperature
- 커지면,
- 모델이 양성 쌍과 음성 쌍 사이의 차이를 덜 구분하게 만들어, 더 넓은 범위의 특징을 탐색하도록 합니다.
- 커지면,
- MoCoLoss는 InfoNCE (Information Noise-Contrastive Estimation)을 변형한 것
4. 예시
- 목표: 인코더 학습시키기
- query로
득점 풋살 이미지를 통과시킨 후(왼쪽), 오른쪽에서 여러 positive sample(같은 득점 이미지를 data augmentation 한 것)과 negative sample(득점 장면이 아닌 이미지들)을 통과시킵니다. - 유사한 장면은 유사하도록, 그렇지 않은 장면은 멀어지도록 feature이 출력되는 인코더가 학습됩니다.
- query로

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것