- Scale-Invariant-Feature Transform
- 이미지에서, 특징점을 추출하는 알고리즘
이미지의 scale(크기), Rotation(회전)에 불변하는특징점을 추출하는 알고리즘
1. Scale-space Extrema Detection
1.1. scale-space 만들기
-
이미지의 크기를 다양하게 변화시켜, 극대점/극소점 detection
- 이를 통해 -> keypoint candidates 찾음
-
이렇게 하는 이유
- 이미지 크기변화에 무관하게 같은 keypoint 추출
-

-
scale invariant한 Feature은 다양한 scale에서도 scale invariant해야 한다.
- 아파트를 100m 200m 300m 400m 500m 거리에서 관찰한다고 가정하자. 그러면 여기서 아파트의 모서리는 거리에 상관없이 모서리일 것이다.
- 100m 거리에서 한 아파트를 본다면 그 아파트의 detail까지 볼 수 있을 것이다.
- 하지만 500m 이상부터는 detail이 많이 사라진다. scale이 높아질수록 detail이 blur 된다.
-
하지만, 우리는 하나의 촬영된 이미지만을 가지고 있고, 거기서 특징점을 찾고 싶은 것이다.
-
이미지는 1장 밖에 없으니, blur을 서서히 키우는 방식으로, 스케일을 증가시키는 것과 같은 효과를 낼 수 있다.
- 다양한 scale(sigma)의 Gaussian Filter를 Convolution하면 해결된다!!
- Gaussian Filter: https://velog.io/@hsbc/Gaussian-Filter
- sigma가 커질수록, blur이 심해진다.
-
점차적으로 블러된 이미지를 얻기 위해 σ에 상수 k를 계속 곱해서 Convolution한다.
-
이때 σ가 2배가 될때까지 만들어진 사진들은 한 Octave로 묻고
- 그 다음 이미지를 1/2로 Downsampling한 다음
- 다시 σ에 상수 k를 계속 곱해서 Convolution한다.
-
σ가 2배가 되었을 때 Downsampling하는 이유는 무엇일까? 연산량을 줄이기 위함이다.
- σ가 2배가 되었다는 것의 의미는 우리가 이미지를 2배 먼 거리에서 본 것과 동치이다.
- 그러므로 이미지 크기를 1/2로 줄여도 상관없으며 동시에 연산량이 줄어드는 이점을 얻는다.
-
위 결과로, (다양한 scale값으로 Gaussian 연산처리된)
4 그룹의 옥타브, 총 20장의 이미지를 얻었다.
1.2. Dog(Difference of Gaussian)
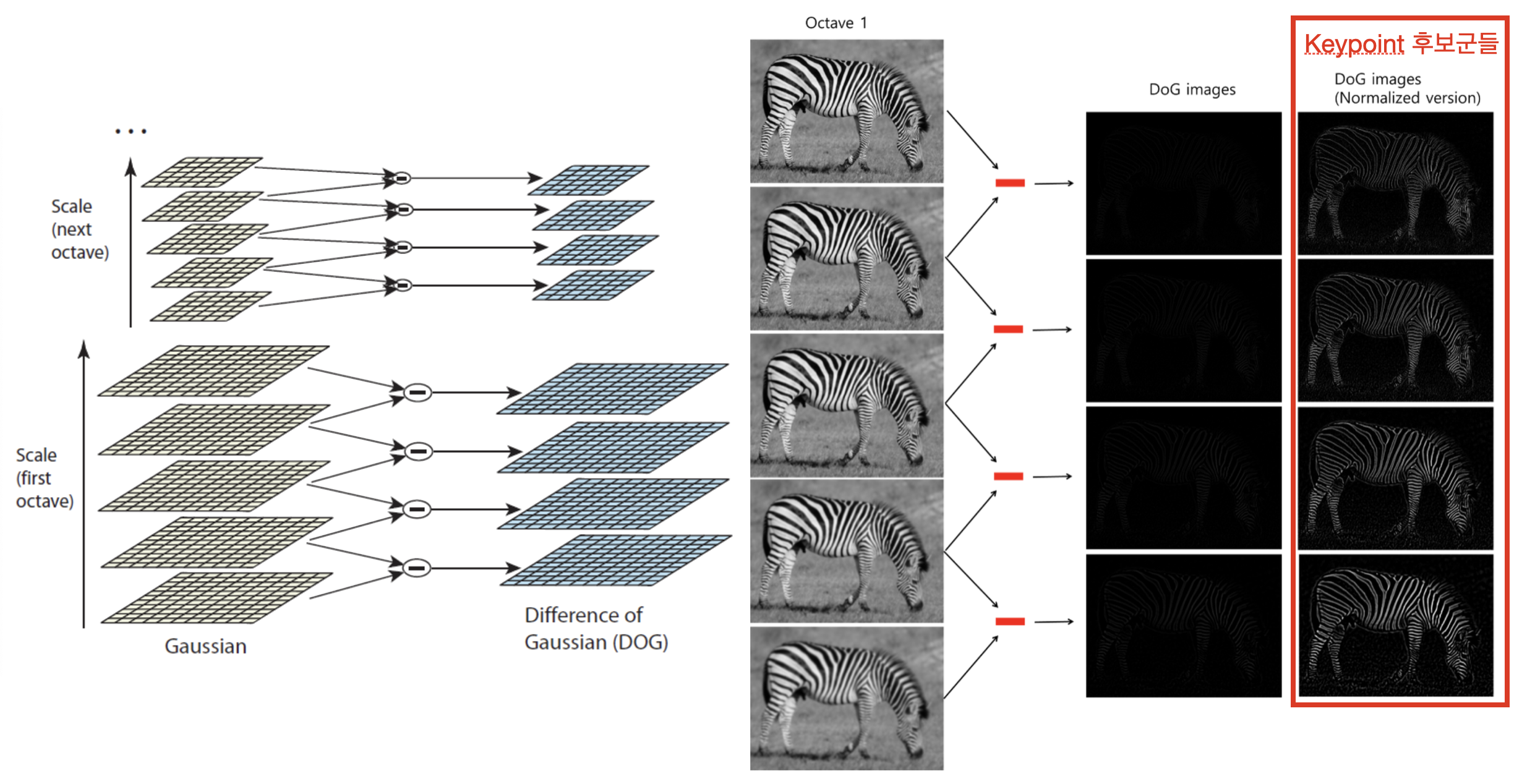
- 각 옥타브 내에서, 5장의 이미지끼리 LoG나 Dog를 이용하면,
- 이미지 내에서 Edge/Corner 같은 Keypoint 후보군들을 추출할 수 있다.
- LoG (Laplacian of Gaussian)
- 많은 연산을 요구
- DoG (Difference of Gaussian)
- LoG에 비해 비교적 간단하면서도 비슷한 성능을 낼 수 있음
- 같은 옥타브 내에서 인접한 두 개의 블러 이미지들끼리 빼주면 된다.
- 각 옥타브마다 4장의 DoG 이미지, 총 4옥타브니까 16장의 DoG이미지를 얻게 된다.
2. Keypoint Localization
- 목적
- keypoint를 정확하게 위치시키는 과정
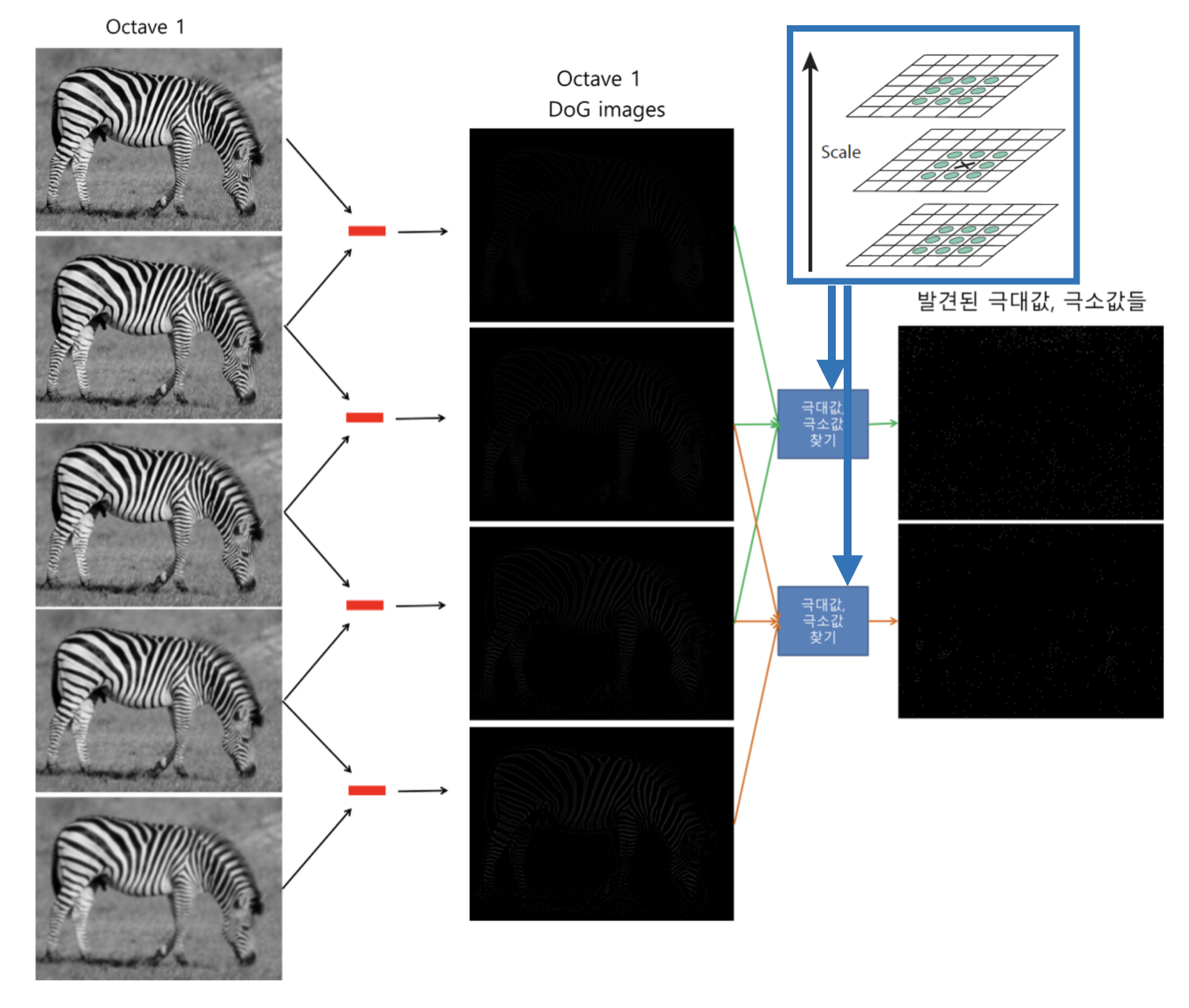
- 위에서 구한 16장의 DoG이미지들에서 keypoint들을 찾아야 한다.
- 먼저 16장의 DoG이미지들에서 -> 극대값,극소값들의 대략적인 위치를 찾는다.
- 아이디어: 같은 옥타브 내, 내 주변
3*3*3 - 1 = 26픽셀보다 Value가 크거나 작으면 극값이다.
- 아이디어: 같은 옥타브 내, 내 주변
- 먼저 16장의 DoG이미지들에서 -> 극대값,극소값들의 대략적인 위치를 찾는다.
- 이 과정을 통해 Octave별로 2장씩, 총 8장의 이미지가 만들어진다.
- TODO: 아래 Talyor 급수 부분 이해가 안됨
- 사실 위 설명은,
극대,극솟값을 찾기 위한 개념적 설명이었다.극대,극솟값은 DoG이미지에 대해 테일러급수를 이용하여 구한다.

3. Bad keypoint 제거
- 목적
- (추후 feature matching 시 불안정할 수 있는)
keypoint 노이즈 제거
- (추후 feature matching 시 불안정할 수 있는)
- 방식
- 위에서 구한
극대,극솟값중, 주변과의 차이가 덜 뚜렷한 keypoint들은 제거한다. - 또한,
Edge 위에 위치한 keypoint들도 제거하여,코너에 위치한 keypoint들만 남겨놓는다.
- 위에서 구한
- 마지막으로, 이렇게 구한 keypoint들 중, 옥타브 2~ N에 있는 친구들은, 원래 이미지 size로 up sampling 해야 함
- 이때, keypoints도 같이 upsampling됨
4~6 들어가기 전에: Rotation Invariant
- Rotation Invariant: 사진을 어떻게 뒤집든, 그 점이 여기에 있다는 것을 특징할 수 있어야 한다.
- 결국,
6. rotation-invariance feature를 구하는 것이 목표!- 사진이 회전하더라도, keypoint(4)와 keypoint 주변 점들(5)의 상대적 방향은 변하지 않는다는 점을 이용하여,
6. rotation-invariance feature을 구함. 5. Keypoint descriptor-4. Orientation Assignment=6. rotation-invariance feature
- 사진이 회전하더라도, keypoint(4)와 keypoint 주변 점들(5)의 상대적 방향은 변하지 않는다는 점을 이용하여,
4. Orientation Assignment
- 위에서 구한 keypoint들의 각 direction, magnitude 을 결정
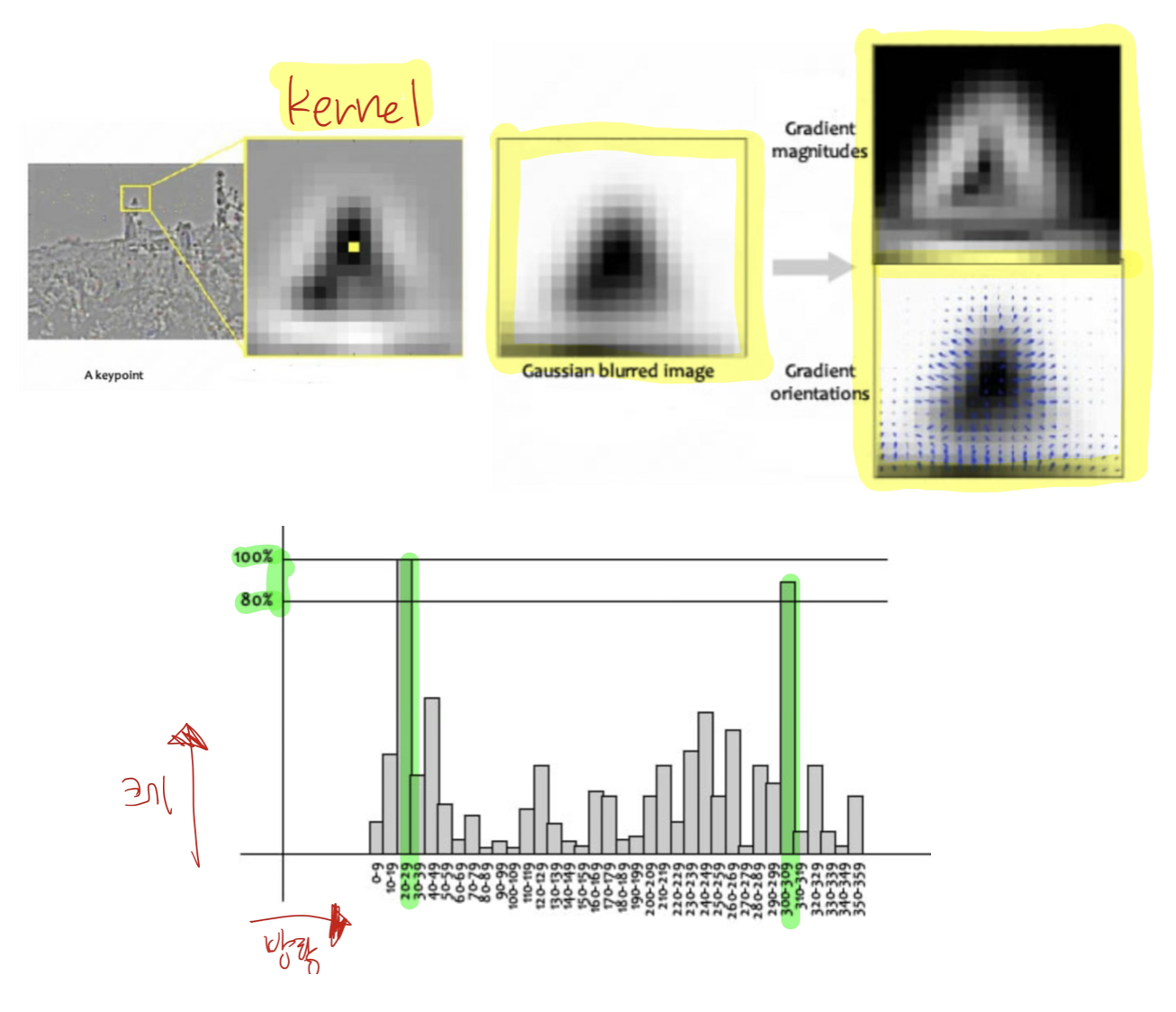
- keypoint 주위의 kernel을 설정한 후,
- 그 kernel 안에 있는 모든 픽셀들 각각의
gradient 크기와 방향을 구한 후, - 모든 픽셀들의
gradient 크기와 방향을 히스토그램으로 그린다. - 히스토그램의 가로축은 방향, 세로축은 크기다.
- 크기가 가장 큰(
max 크기) 방향을 keypoint의 방향으로 설정한다. - 좀 더 구체적으로는,
max 크기* 0.8 ~max 크기에 속하는 모든 벡터를 합쳐서, keypoint의 크기와 방향을 정한다.
- 그 kernel 안에 있는 모든 픽셀들 각각의
5. Keypoint descriptor
- 각 keypoint 주변 픽셀들의 gradient 크기와 방향을 구합니다.
- 각 keypoint를 식별하기 위한, (지문같은 개념의) descriptor을 만든다.
- 아래의 그림처럼 keypoint를 중심으로 16x16 크기의 윈도우를 세팅하고,
- 이 윈도우를 4x4의 크기를 가진 16개의 작은 윈도우로 구성한다.
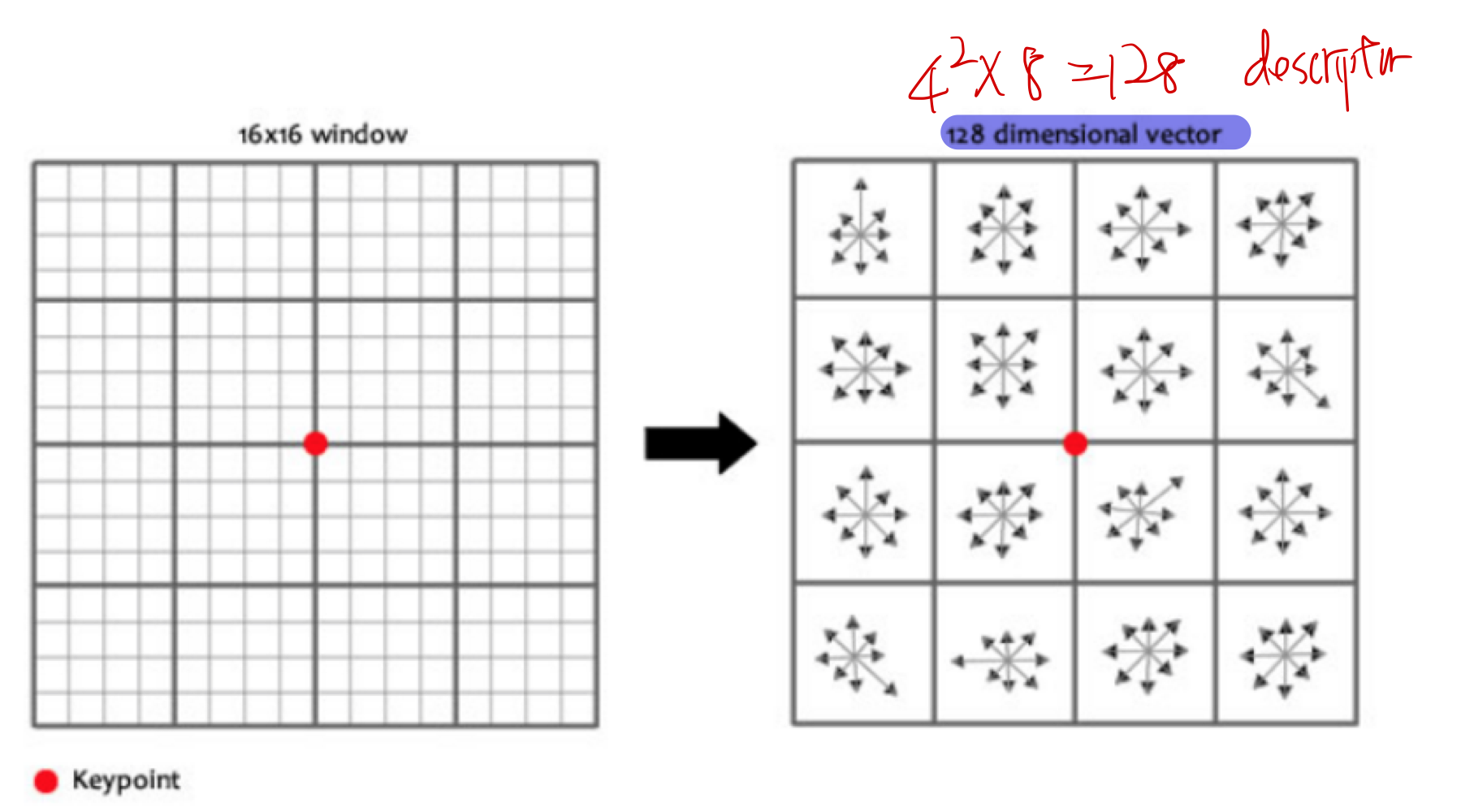
16개의 작은 윈도우에 속한 pixel들의- gradient의 크기와 방향을 계산한다.
- 그리고 8개의 bin을 가진 Histogram을 그린다.
- 결국 16개의 윈도우에 8개의 방향으로 세팅이 되었기 때문에,
- 16x8=
128 개의 feature vector를 가진 descriptor를 만들 수 있다.
- 16x8=
- 이미지가 회전하면 모든 gradient의 방향이 바뀌기 때문에 이 feature vector도 변하게 됩니다.
6. rotation-invariance feature
5. Keypoint descriptor-4. Orientation Assignment=rotation-invariance feature- 위 5번의 16x8=
128 개의 feature vector에서, keypoint의 벡터를 뺀- 128개의 feature vector이, 우리가 구하려 했던
rotation-invariance feature
- 128개의 feature vector이, 우리가 구하려 했던

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것