SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos
action recognition in videos
목록 보기
3/24
abstract
- SoccerNet: Only for action spotting
- 스팟팅 작업: 비디오에서 축구 이벤트의 앵커를 찾는 것으로 정의
- 이 데이터셋은 2014년부터 2017년까지의 세 시즌을 커버하는 유럽 주요 리그의 500개 완전한 축구 경기로 구성되어 있으며, 총 764시간의 기간을 포함합니다.
- 총 6,637개의 시간적 주석:
골, 옐로우/레드 카드, 그리고 교체같은 세 가지 주요 이벤트 클래스에 대해1초 해상도로 제공 - 이 데이터셋은 긴 비디오 내에서
매우 희소한 이벤트의 위치를 찾는 문제에 초점을 맞춤. 분류 작업- ResNet-152와 NetVLAD 풀링을 사용하여 67.8%의 평균 정밀도(mAP) 달성.
스팟팅 작업- 세밀한 주석을 사용하여 49.7%, 약하게 주석된 데이터를 사용하여 40.6%의 평균 정밀도 달성.
- 우리의 기준은
5초에서 60초까지의 허용 오차 범위에서 평균-mAP가 49.7%에 도달
데이터셋과 모델: https://silviogiancola.github.io/SoccerNet- 오디오 feature을 사용하지 않았다.
- 해설자 목소리가 데이터셋에 포함되어 있지 않아서 좋다.
TODO: 의문점
- fact: 우리의 실험은 두 가지 작업에 집중
1분 길이의 청크에 대한 이벤트 분류- input: 1분 길이의 청크
- output: 1분 동안 발생한 class의 종류를 전부 추출
- 위
1분 길이의 청크에서 발생한 이벤트에 대한 Time spotting- input?:1분 청크에 대해, 1초 간격으로 striding한 조각
- output: 어떤 이벤트 발생했냐 (TODO 확인 필요)
Introduction
- 기여.
- (i) 우리는 축구 맥락 내에서 이벤트 스팟팅이라는 작업을 제안
- 우리는 비디오에서 단일 타임스탬프에 고정된 행동으로 이벤트를 정의하고, 따라서 축구 비디오 내에서 이벤트 스팟팅 작업을 정의하고 연구 (섹션 3).
- (iii) 우리는
video chunk classification및event spotting작업에서 우리 데이터셋에 대한 기준을 제공- 우리의 분류기는 67.8% (mAP)의 성능에 도달하고 우리의 이벤트 스팟터는 평균-mAP 49.7%를 달성(섹션 5).
- (i) 우리는 축구 맥락 내에서 이벤트 스팟팅이라는 작업을 제안
Related Work
Activity Recognition (나중에 필요하면 보자.)
- 활동 인식은 비디오를 이해하는 데 초점을 맞추고 있으며, 활동을 탐지하거나 미리 정의된 인간 중심의 행동 클래스에 따라 비디오 세그먼트를 분류합니다. 일반적인 파이프라인은 시간적 세그먼트를 제안하는 것으로 구성됩니다 [9, 11, 28, 64], 이는 차례로 추가로 가지치기되고 분류됩니다 [30, 80]. 활동 분류 및 탐지를 위한 일반적인 방법은 밀집 궤적 [29, 79, 80, 81], 행동 추정 [14, 28, 87], RNN [8, 9, 25], 튜브렛 [40, 63], 수공예 특징 [11, 49, 86]을 사용합니다.
- 비디오 내에서 활동을 인식하거나 탐지하기 위한 일반적인 관행은 로컬 기능을 집계하고 풀링하여 특성의 합의를 찾는 것입니다 [42, 67]. 단순한 접근 방식은 평균 또는 최대 풀링을 사용하는 반면, BOW [15, 68], Fisher Vector (FV) [36, 54, 56], VLAD [4, 37]와 같은 더 정교한 기술은 클러스터링 및 학습을 통해 특징 세트에서 구조를 찾고 이를 구별력을 향상시키는 방식으로 풀링하는 방법을 찾습니다. 최근 작업은 NetFV [46, 55, 74], SoftDBOW [57], NetVLAD [3, 30]와 같은 DNN 아키텍처에 이러한 풀링 기술을 통합함으로써 이러한 풀링 기술을 확장합니다. ActionVLAD [30]는 원시 행동 표현 세트 간의 상관 관계를 찾아 여러 활동 인식 벤치마크에서 최첨단 성능을 보여줍니다.
- 활동 인식을 더욱 향상시키기 위해, 최근의 연구들은 시간적 및/또는 공간적 이웃에서 정보를 나타내고 활용하는 맥락 [10, 16, 50]을 활용하거나, 주변 정보를 활용하기 위해 적응적인 신뢰 점수를 학습하는 주의력 [51]에 집중하고 있습니다. 이 분야에서 Caba Heilbron 등 [10]은 비디오 세그먼트 내의 객체와 장면의 증거를 활용하여 활동 탐지의 효과성과 효율성을 향상시키는 의미론적 맥락 인코더를 개발했습니다. Miech 등 [50], 첫 번째 연례 YouTube 8M 챌린지 [2]의 우승자들은, 인식이 맥락 차단과 결합될 때, 학습 가능한 풀링이 매우 큰 벤치마크에서 최신 인식 성능을 어떻게 생성할 수 있는지 보여줍니다. 더 최근에, 여러 연구들은 비디오 내 활동을 위치시키기 위해 시간적 맥락 [16]을 사용하거나 제안을 생성하기 위해 사용합니다 [28]. 또한, Nguyen 등 [51]은 향상된 동작 인식을 위해 시공간적 주의를 사용하는 풀링 방법을 제시하고, Pei 등 [53]은 RNN 프레임워크에서 이웃 관찰을 관리하기 위해 시간적 주의를 사용합니다. 주의력은 비디오 캡션에도 널리 사용됩니다 [34, 44, 48].
- 활동 인식 및 탐지 방법은 이러한 복잡한 작업에 대해 좋은 결과를 제공할 수 있습니다. 그러나 이러한 방법들은 DNN에 기반하며 모델을 학습하기 위해서는 대규모이고 풍부한 데이터셋이 필요합니다. 이벤트 스팟팅과 축구에 초점을 맞춘 대규모 데이터셋을 제안함으로써, 우리는 이러한 방향으로의 알고리즘 개발을 장려합니다.
Spotting Sparse Events in Soccer
- 이 맥락에서, 우리는 축구 비디오 내의 이벤트와 이벤트 스팟팅 작업을 정의합니다.
이벤트:
요약
우리 연구에서, 우리는 이벤트를 특정 맥락 내에서 특정 규칙을 존중하며 단일 시간 인스턴스에 고정된 행동으로 정의우리는 여러 이유로 모든 행동을 시간적 경계와 함께 정의하는 것이 모호하다고 주장합니다:
본문 (안봐도됨)
- Sigurdsson 등 [65]은 최근 활동의 시간적 경계 개념에 의문을 제기했습니다. 그들은 Charades [66]와 MultiTHUMOS [85] (AMT 사용)을 재주석하고, 각각 평균 72.5%와 58.8%의 tIoU로 기준 사실과의 평균 합의를 도출했습니다. 이는 시간적 경계가 모호함을 분명히 보여줍니다. 하지만, Sigurdsson 등 [65]은 활동 내의 중심 프레임이 주석자들 사이에서 더 많은 합의를 제공한다는 것을 관찰했습니다.
- Chen 등 [14]은 행동과 행동성의 개념을 정의하면서 행동을 정의하는 4가지 필수 측면을 강조합니다: 행위자, 의도, 신체적 움직임, 그리고 부작용. Dai 등 [16]은 활동을 시작과 끝 시간을 가진 일련의 이벤트나 행동으로 정의합니다.
우리 연구에서, 우리는 이벤트를 특정 맥락 내에서 특정 규칙을 존중하며 단일 시간 인스턴스에 고정된 행동으로 정의합니다.우리는 여러 이유로 모든 행동을 시간적 경계와 함께 정의하는 것이 모호하다고 주장합니다:
- 행동은 "남자가 지갑을 떨어뜨린다"나 "남자가 우편함에 편지를 넣는다"처럼 순식간에 일어날 수 있습니다. 이러한 행동에는 잘 정의된 경계가 없지만, 단일 순간이 이러한 이벤트를 명확하게 정의할 수 있습니다.
- 행동은 라이브 비디오 내에서 지속될 수 있으므로 시작과 종료 시점이 불분명합니다. 예를 들어, "밤이 찾아오고 있다"나 "내 유리잔의 얼음이 녹고 있다"와 같은 행동의 비디오 시간 경계는 조명 수준이나 물질 상태의 시각적 변화와 같은 측정 가능한 양에 대한 주관적인 판별에 의존
- 현재 벤치마크인 THUMOS14 [39], ActivityNet [12], Charades [66]는
시간적 경계를 가진 활동에만 초점을 맞추고여러 주석자 간의 합의에 의해 활동을 고정함으로써 모호함을 처리 - 이러한 모호함은
AVA [31] 데이터셋과 같이 최근에 개발된 것들을 자극했는데, 이는짧은 시간 내에 밀도 높은 정밀한 주석을 제공함으로써 행동의 원자적 특성에 대처하려고 시도
- 라이브 축구 방송의 맥락에서, "골을 넣다"나 "파울을 범하다"와 같은 주어진 행동이 시작되고 멈추는 시점은 불분명
- 우리는 스포츠가 잘 확립된 규칙을 존중하고 단일 시간 인스턴스에 고정된 행동 어휘를 정의한다고 주장
- 실제로 축구 규칙은 "골", "파울", "카드", "페널티 킥", "코너 킥" 등을 엄격하게 정의하고 이를 단일 시간에 고정
- 비슷하게, Ramanathan 등 [58]은 "농구 슛" 행동을 3초 활동으로 정의하고, 공이 골대를 넘는 순간을 그 종료 시간으로 정의합니다. 이러한 이벤트 주변에 시작이나 종료 앵커를 정의하거나 그 지속 시간을 고정하는 것은 응용 프로그램에 의해 주관적이고 편향된 것으로 간주될 수 있습니다.
스팟팅
- 비디오 내에서 행동의 경계를 식별하고 주어진 시간적 교차-유니온(tIoU) 내에서 유사성을 찾는 것보다, 우리는 스팟팅 작업을 도입
- 스팟팅은 이벤트를 식별하는
앵커 시간(또는 스팟)을 찾는 것으로 구성 후보 스팟이 목표에 가까울수록 스팟팅은 더 좋으며, 그 능력은 목표로부터의 거리로 측정완벽하게 목표를 스팟팅하는 것은 본질적으로 어렵기 때문에, 후보가 이벤트를 스팟팅(적중)한 것으로 간주되는 허용 오차 δ를 도입- 이벤트 스팟팅이 주어진 허용 오차 내에서 이벤트의 존재만을 식별하는 데 초점을 맞추기 때문에, 탐지보다 더 잘 정의되고 쉽다고 믿음
- 반복적인 과정을 통해
후보 스팟 주변에서 미세 위치 결정 방법을 사용하여 이러한 허용 오차를 원하는 대로 정제할 수 있음
- 평가에 사용될 메트릭을 정의
후보 스팟이 이벤트의 앵커 주변에 정해진 허용 오차 δ 내에 떨어지면 긍정적으로 정의- 각 허용 오차에 대해, 우리는 스팟팅 문제를 매우 작은 tIoU 임계값을 사용하는 일반적인 시간적 탐지 문제로 재구성할 수 있음
- 그 경우, 우리는 각 주어진 클래스에 대한 재현율, 정밀도, 평균 정밀도(AP)를 계산하고, 모든 클래스에 걸친 평균 평균 정밀도(mAP)를 계산할 수 있음
- 일반적인 비교를 위해, 우리는 미리 정의된 δ 허용 오차 집합에 대한 평균-mAP도 정의합니다. 우리의 경우는 분 이하
Experiment
- 우리의 실험은 두 가지 작업에 집중
1분 길이의 청크에 대한 이벤트 분류전체 비디오 내의 이벤트 스팟팅
- 약하게 주석된 데이터 (Weakly Annotated Data):
- 여기서 '약하게'라는 용어는 주석이 1분 해상도로만 제공된다는 것을 의미합니다.
- 즉, 비디오의 각 1분 구간에 대해서만 이벤트 정보가 주어지며, 그보다 더 세밀한 정보는 없습니다.
- 1초 해상도 주석 (One Second Resolution Annotations):
- 이 데이터는 더 세밀하게 주석이 달린 것으로, 비디오의 각 1초마다 이벤트 정보가 주어집니다.
5.1. 비디오 representation(중요)
- 전처리:
게임 시작 시간 부터로 자르고, 224×224 해상도로 크기 조정 및 자르기를 하고, 25fps로 통일 - 실험을 실행하기 전에, 우리는
기준 방법에 의해 사용될 C3D [77], I3D [13], ResNet [32] feature을 비디오에서 추출0.5초마다 feature을 추출
- C3D [77]는 3D CNN 기능 추출기로 16개의 연속 프레임을 쌓고 fc7 레이어에서 4,096 차원의 기능을 출력
- 이것은 Sport-1M [42]에서 사전 훈련된 weight를 사용.
- I3D [13]는 Inception V1 [75]를 기반으로 하며 64개의 연속 프레임을 사용하고 Kinetics [43]에서 사전 훈련
- 이 작업에서, 우리는 합리적인 계산 런타임을 유지하기 위해 PreLogits 레이어의 RGB 기능만 1,024 차원 길이로 추출
- 흐름 기능을 사용할 때 미미한 개선만을 보여주었다고 알려져 있음 [13].
- ResNet [32]은 fc1000 레이어에서 프레임 당 2,048 기능 표현을 출력하는 매우 깊은 네트워크
- 특히, 우리는 ImageNet [22]에서 사전 훈련된 ResNet-152를 사용
ResNet-152는 단일 이미지에 적용되므로 시간 축을 따라 내재적으로 맥락 정보를 포함하지 않음
- 이러한 기능의 feature을 단순화하고 통일하기 위해, 우리는
모델당 추출한 5.5M 기능에 주성분 분석(PCA)을 적용 - 우리는 C3D, I3D, ResNet-152 기능을 512 차원으로 줄이고 각각 94.3%, 98.2%, 93.9%의 분산을 유지
- 벤치마크 목적으로,
우리는 원본과 자른 버전의 비디오뿐만 아니라, 0.5초마다 추출된 모든 기능의 원본과 축소된 버전을 제공
5.2. 비디오 청크 분류 (1분 길이의 비디오 내, multi-classification)
- Similar to the setup in the AVA dataset [31], localization can be cast(설정되다.) as a classification problem for densely annotated chunks of video, especially since we gather webly annotations.
- 우리는
비디오를 1분 길이의 청크로 나누고, 이 1분 내에서 발생하는 모든 이벤트로 주석을 답니다.- 이를 통해 각각 카드, 교체, 골, background에 대해 훈련 데이터셋에서 각각 1246, 1558, 960, 23750 청크를 수집하며, 이 중 115개는 다중 라벨
- We aggregate the
120 features within a minute as inputfor different versions of shallow pooling neural networks.- 2hz 라고 했으므로, 1분에 120 feature인 것 같음.
- 이 네트워크들의
마지막 레이어에서 시그모이드 활성화 함수를 사용함으로써, 우리는 후보들 사이에서 다중 라벨링을 허용
- We use an Adam optimizer that minimizes a multi binary cross-entropy loss for all the classes.
- We used a step decay for the learning rate and an early stopping technique based on the validation set performances.
- 이 분야의 최고 관행에 따라, 이 경우 평가 메트릭은 지정된 테스트 세트에서 세 클래스에 대한 mAP(분류)
- 이어지는 내용에서, 우리는 다양한 비디오 기능, 다양한 풀링 기술을 사용한 강력한 기준 결과를 보고하고, 불균형 데이터셋을 처리하기 위한 솔루션을 비교
- TODO:
아마 120 frame의 각 frame 마다, goal인지에 대한 확률, 교체인지에 대한 확률, 카드인지에 대한 확률을 가각 다 추출하는 것으로 보이는데, 확인 필요
풀링 방법 학습
본문
- 다양한 feature 표현과 여러 풀링 방법의 사용을 조사
- 우리는 120 × 512 차원의 입력 매트릭스를 처리하는 얕은 신경망을 제안
We test a mean and a max pooling operation along the aggregation axis that output 512-long features.- 120을 pooling 하여 압축하는 것 같음.
- 맞춤형 CNN:
우리는 512×20 차원의 커널을 가진 맞춤형 CNN을 사용하여 시간 차원을 따라 이동하고 시간적 맥락을 수집(time 축으로 CNN 돌린다.) - 마지막으로, 고급 풀링 방법으로 우리는 Miech 등 [50]에 의해 제공되는 SoftDBOW, NetFV, NetVLAD 및 NetRVLAD 구현을 사용
- 120개 데이터를, 비슷한 유형끼리 묶어서 clustering
- 이들은 further context gating layer를 활용
- we stack a fully connected layer with a dropout layer (keep probability 60%) that predicts the labels for the minutes of video and prevent overfitting.
- 표 3은 테스트 세트에 적용된 다양한 풀링 방법 간의 성능 비교를 요약
- we notice similar results across features by using mean and max pooling, that only rely on a single representation of the set of 120 features and not its distribution.
- 맞춤형 CNN 레이어를 사용하는 것은 시간적 맥락을 수집하려는 시도로, ResNet-152 > C3D > I3D
- Miech 등 [50]이 제안한 풀링 방법을 사용함으로써 기능 간의 차이가 더 커지는 것을 알 수 있습니다. 이는 시간 차원을 따라 맥락을 내장하는 방법
- 우리는 I3D와 C3D 기능이 이미 프레임 스택 내에서 시간적 특성화에 의존한다고 믿음
- 반면에, ResNet-152는 프레임 내의 공간적 측면에만 초점을 맞춘 표현을 제공
- 우리는 시간적 풀링 방법이 I3D와 C3D에 대해 ResNet-152보다 더 중복적인 정보를 제공한다고 믿음
이러한 이유로, 우리는 ResNet-152 기능이 Miech 등 [50]이 제공하는 어떠한 시간적 풀링 방법과 결합될 때 더 나은 결과를 제공한다고 주장
- 풀링에 초점을 맞추면, VLAD > FV > BoW
- 이러한 개선은 NetVLAD [3]에서 학습된 120개의 기능을 위한 효율적인 클러스터링으로 인한 것으로, 이는 동작 분류 [30]에서 최신 결과를 제공
- NetRVLAD는 각 클러스터링에 대한 평균만을 의존하고 잔여 부분은 사용하지 않아 계산 부하를 줄이므로, NetVLAD와 유사하거나 더 나은 성능 [50].
- 실험의 나머지 부분에 대해서는 ResNet-152 기능만을 사용
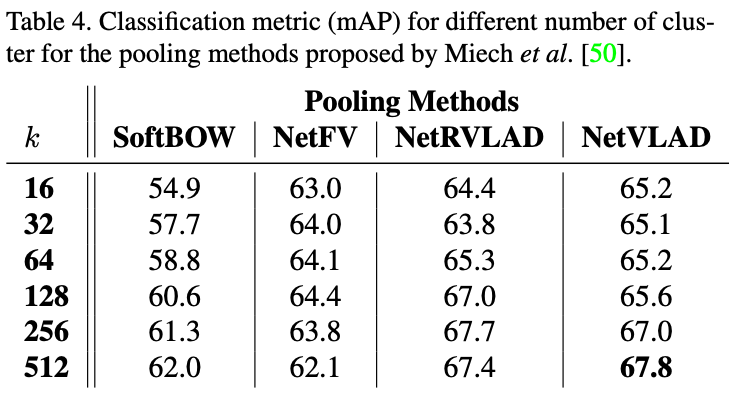
- 다양한 풀링 방법에 대해, 클러스터의 수는 미세 조정될 수 있습니다.
- 표 3에서는 k = 64 클러스터를 사용하는데, 이는 이벤트를 설명하기 위해 학습된 원자 요소의 어휘로 해석될 수 있습니다.
- 직관적으로, 더 풍부하고 큰 어휘가 전반적인 성능을 향상시킬 수 있다고 기대할 수 있습니다 [30].
- 표 4에서는 이 직관이 k 값의 특정 범위 내에서는 사실이지만, 그 이상의 범위에서는 개선이 미미하고 과적합이 발생한다는 것을 보여줍니다.
- 모든 풀링 방법의 성능은 양자화에 사용되는 클러스터가 256개 이상일 때 정체되는 것으로 보입니다.
- NetVLAD를 512 클러스터와 함께 사용했을 때 가장 좋은 결과가 등록됩니다.
- 그러나 클러스터의 수가 증가함에 따라 계산 복잡성은 선형적으로 증가하므로 계산 시간이 급격히 증가합니다.
background 라벨이 가장 많은, data inbalencing 문제 해결법
- 데이터 세트에서 특정 유형의 데이터(예: '배경' 라벨)가 다른 유형보다 훨씬 많을 때 발생하는 문제
- 이 불균형을 처리하기 위한 세 가지 주요 기술을 제시
- 방법 1 ( 성능 향상)
- 희귀한 유형(예: 특정 이벤트)의 데이터에 더 많은 가중치를 주어 학습을 강화
- 긍정적인 예시 학습을 강화하기 위해, 부정적인 샘플의 비율로 이진 교차 엔트로피를 가중치(Weig)를 두는 데 초점을 둡니다.
- 희귀한 유형(예: 특정 이벤트)의 데이터에 더 많은 가중치를 주어 학습을 강화
- 방법 2 (성능 감소)
- 많은 유형(예: '배경')의 데이터를 일부러 줄이거나(다운샘플링), 학습 과정에서 잘못 분류된 데이터(하드 네거티브)를 더 집중적으로 학습
- 또 다른 방법은 가장 빈도가 높은 클래스에 대해 무작위 다운샘플링(Rand)을 적용하거나, 하드 네거티브 마이닝(HNM)을 통해, 즉 이전 에포크에서 가장 많이 오분류된 예시를 샘플링하는 방법
- 방법 3 (성능 향상)
- 희귀한 유형의 데이터를 인위적으로 늘리는 방법
- 이 경우, 우리는 이벤트의 세밀한 주석을 사용하고 이벤트 스팟의 ±20초 내에서 1초 간격으로 분 단위 창을 이동시켜 가장 희소한 이벤트 클래스에 대한 비디오 세그먼트를 더 많이 샘플링합니다.
- 우리는 이벤트 앵커 주변의 ±10초 내 1분 청크가 여전히 이 이벤트를 포함하고 있으며, 풀링 방법이 이를 식별할 수 있어야 한다고 주장합니다.
- 그러나 우리의 데이터 증강은 데이터가 세밀하게 주석되어 있어야 한다는 것을 유의해야 합니다.
- 방법 1 ( 성능 향상)
5.3. 스팟팅
- 우리는 분류 작업에서 훈련된 모델을 사용하고
- 이벤트를 찾기 위해 '슬라이딩 윈도우' 방식을 사용합니다. 이는
비디오를 1초 간격의 작은 부분으로 나누어 각 부분을 분석하는 방법- 이렇게 하면,
각 1초 구간마다 이벤트가 있는지를 평가할 수 있음
- 이렇게 하면,
- 우리는 세 가지 강력한 기준선을 조사합니다:
- (i) 워터쉐드 방법: 이 방법은 비디오를 여러 부분(1초 간격)으로 나누고, 각 부분의 중심 시간을 이벤트 후보(예: 골)로 고려
- (ii) 워터쉐드 세그먼트의 최대값: 여기서는 각 부분(1초 간격)에서 가장 높은 점수를 받은 시간을 이벤트 후보로 사용
- (iii) 로컬 최대값과 최대값 억제(NMS): 전체 비디오에서 이벤트(예: 골) 점수가 가장 높은 지점을 찾고,
1분 간격의 윈도우 내에서가장 높은 점수만을 고려- the local maxima along all the video and apply non-maximum-suppression (NMS) within a minute window.
- 평가 메트릭은 섹션 3에서 정의된 대로 스팟팅에 대한 허용 오차 δ를 가진 mAP이며, 또한 5초에서 60초까지의 허용 범위를 가진 mAP 곡선 아래의 영역으로 표현된 평균-mAP입니다.
스팟팅 기준선 비교
- 우리는 최고의
약하게 훈련된 분류기(앞의 classification network)에 대한 이벤트 스팟팅 결과를 조사하여, 웹 기반으로 파싱된 주석 사용을 활용합니다. - 즉, 우리는 불균형한 1분 해상도 주석 데이터로 훈련하고 데이터 증강을 수행하지 않습니다.
- 구체적으로, 우리는 ResNet 기능을 기반으로 한 k = 512 클러스터의 NetVLAD 모델을 사용하고 워터쉐드 임계값을 50%로 설정합니다.
- 그림 3a는 스팟에 대한 허용 오차 δ의 함수로 각 스팟팅 기준선의 mAP를 표시합니다.
- 예상대로, mAP는 스팟 허용 오차 δ가 증가함에 따라 감소합니다.
- 60초 이상의 허용 오차 δ에서 세 가지 기준선 모두 62.3%에서 정체됩니다.
- 60초 이하에서는 (ii)와 (iii)가 유사하게 성능을 보이며 허용 오차와 선형적으로 감소
반면에, 기준선 (i)는 더 점진적으로 감소하여 평균-mAP가 40.6%로 더 나은 결과를 제공- 모델이 1분 길이의 청크로 훈련되었음에도 불구하고, 모델이 60초 미만의 허용 범위(tolerance)에 대해 좋은 스팟팅 결과를 얻을 수 있는 이유에 대해 설명하고 있습니다. 여기서 주장하는 내용은 다음과 같습니다:
- 모델의 동작 방식:
모델은 어떤 이벤트가 포함된 창(window)을 긍정적으로 예측(positive prediction)이것은 모델이 이벤트가 포함된 구간을 정확하게 식별하고자 하는 것을 의미 - 플래토(plateau) 형성:
플래토란 모델이 어떤 범위 내에 있는 모든 창을 긍정적으로 예측하는 현상을 나타냄- 다시 말해, 모델은 특정 이벤트가 발생한 지점 주변의 여러 창에 대해 예측을 내리고 이 예측들이 일정한 수준을 유지하는 것을 의미
- 이러한 동작 방식으로 인해, 모델은 60초 미만의 허용 범위에서도 스팟팅 작업에서 좋은 결과를 얻을 수 있습니다. 즉, 모델은 이벤트가 실제로 일어난 지점 주변의 여러 창에 대해 긍정적으로 예측하며, 이로써 스팟팅 결과가 일정한 수준을 유지하게 됩니다.
- 더 작은 창에서 훈련하기:
- 여기서, 우리는 60초에서 5초에 이르는 더 작은 청크 크기를 사용하여 섹션 5.2의 분류기를 훈련합니다.
- 우리는 이 모델들이 유사한 방식으로 수행되고, 청크 크기 이하의 허용 오차에 대해 성능(mAP)이
감소할 것으로 예상합니다. - 이러한 분류기를 훈련하기 위해 우리는 세밀하게 주석된 데이터를 사용합니다.
- 그림 3은 허용 오차 δ의 함수로 60, 20, 5초로 훈련된 모델의 스팟팅 mAP를 보여줍니다.
- 모든 모델은 유사한 형태를 가지고 있으며, 훈련된 청크 비디오 길이 이상의 스팟팅 허용 오차 δ에 대해 정체되는 메트릭을 가지고, 그러한 임계값 이하에서 감소하는 메트릭을 가집니다.
20초 청크로 기준선 (i)를 사용하면 평균-mAP가 50%인 최고의 결과를 얻습니다(그림 3b 참조).또한, 5초 청크로 훈련된 모델에서 성능이 감소하는 것을 볼 수 있습니다(그림 3c 참조).
- 우리는 이러한 성능 격차가 이벤트 주변에서 허용하는 맥락의 양과 관련이 있다고 믿습니다.
- 이 실험들을 통해, 우리는 스팟팅 작업에 대한 기준을 설정했지만 최고의 성능은 만족스럽지 못합니다.
- 그럼에도 불구하고, 우리는 새롭게 구성되고 확장 가능한 데이터셋이 특히 새로운 스팟팅 기술과 관련하여 표준화된 평가와 알고리즘 개발에 풍부한 환경을 제공한다고 봅니다.
6. 결론
- 간단히 말해서, 기존 방식은 넓은 범위에서 후보를 찾고 이를 하나하나 분류하는 것에 초점을 맞춘 반면, 새로운 방식은 좀 더 특정 지점에 초점을 맞추어 더 효율적이고 정확하게 활동을 탐지하려는 접근법
- 제안된 새로운 방식: 스팟팅과 주의 집중
- 이 접근 방식에서는 특정 지점(스팟)을 식별하고, 이 지점 주변에 주의를 집중하여 활동의 경계를 정확하게 찾아냄
- 즉, 비디오에서 특정 활동이 발생하는 구체적인 위치를 먼저 식별한 다음, 그 주변을 자세히 분석하여 활동의 시작과 끝을 정확하게 파악
- 동일한 예시를 사용하면, 비디오에서 골이 발생할 것 같은 정확한 순간을 먼저 식별하고, 그 순간의 주변을 분석하여 골 장면의 정확한 시작과 끝을 찾는 것

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것