action recognition in videos
1.CLIP
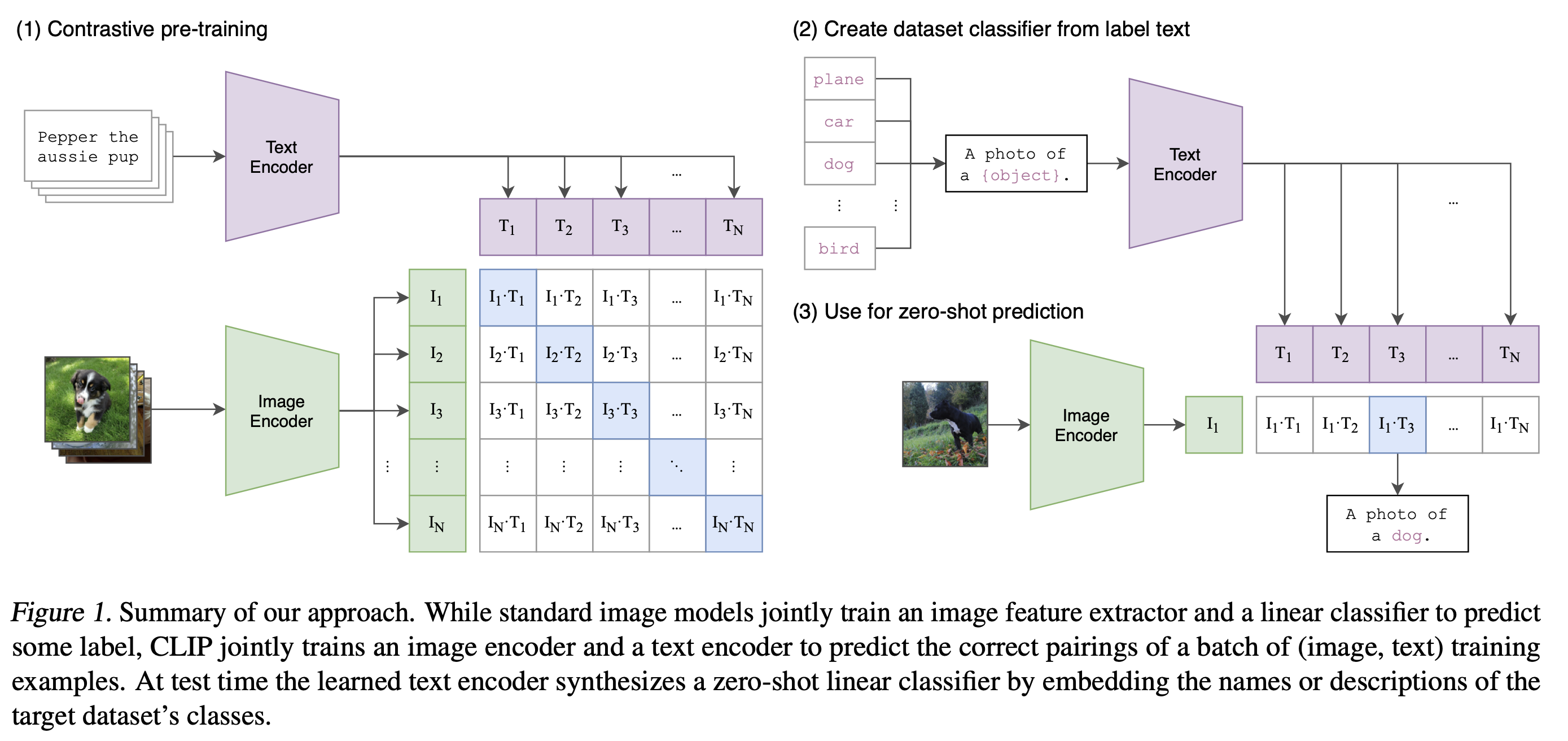
\[Blog] \[Paper] \[Model Card] \[Colab]CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs.
2.SoccerNet-v2: A Dataset and Benchmarks for Holistic Understanding of Broadcast Soccer Videos
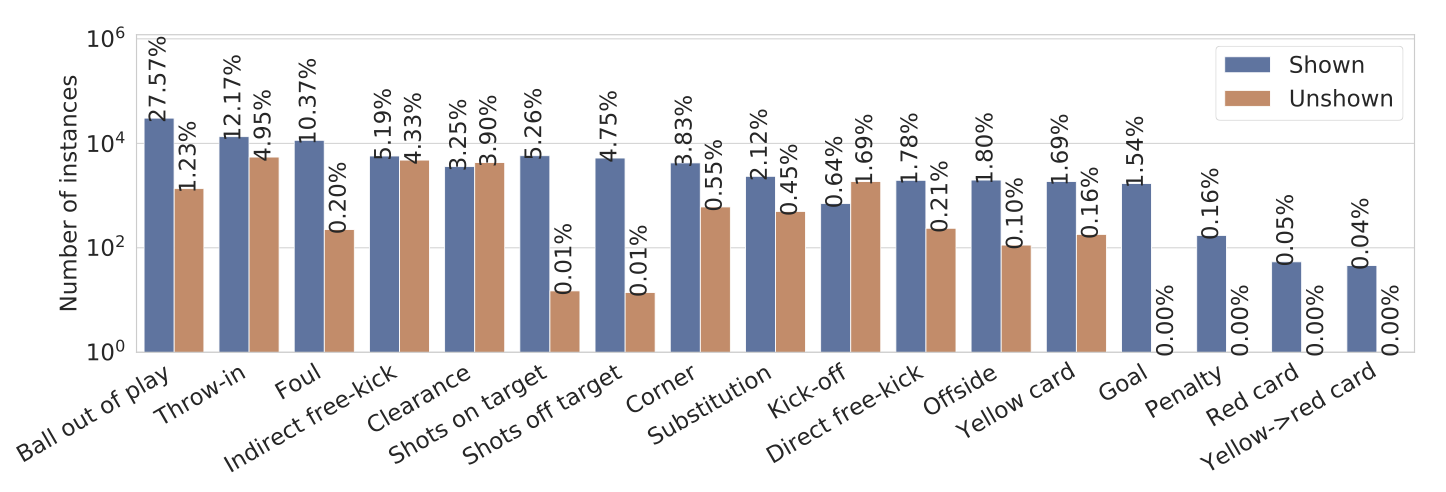
SoccerNet의 500개의 편집되지 않은 방송 축구 비디오 내에서 약 30만 개의 주석을 공개이 분야에서 가장 관련성 있는 작업들의 오픈 소스 적용 버전과 함께 재현 가능재현 가능한 벤치마크 결과와 우리의 코드 및 공개 리더보드를 공개최근 컴퓨터 비전 작업은 축구
3.SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos
SoccerNet: Only for action spotting스팟팅 작업: 비디오에서 축구 이벤트의 앵커를 찾는 것으로 정의이 데이터셋은 2014년부터 2017년까지의 세 시즌을 커버하는 유럽 주요 리그의 500개 완전한 축구 경기로 구성되어 있으며, 총 764시간의
4.볼만한 논문들 정리

https://openaccess.thecvf.com/content_CVPRW_2020/papers/w53/Vanderplaetse_Improved_Soccer_Action_Spotting_Using_Both_Audio_and_Video_Streams_CVPR
5.Action Spotting using Dense Detection Anchors Revisited: Submission to the SoccerNet Challenge 2022
축구 비디오에서 행동을 정확하게 찾아내기 위한 새로운 방법을 소개이 방법은 시간적 정밀도를 높이기 위해 '밀집된 탐지 앵커(densely sampled detection anchors)' 세트를 사용밀집된 탐지 앵커란, 비디오를 매우 자세히 분석하여 각 순간을 정확하게
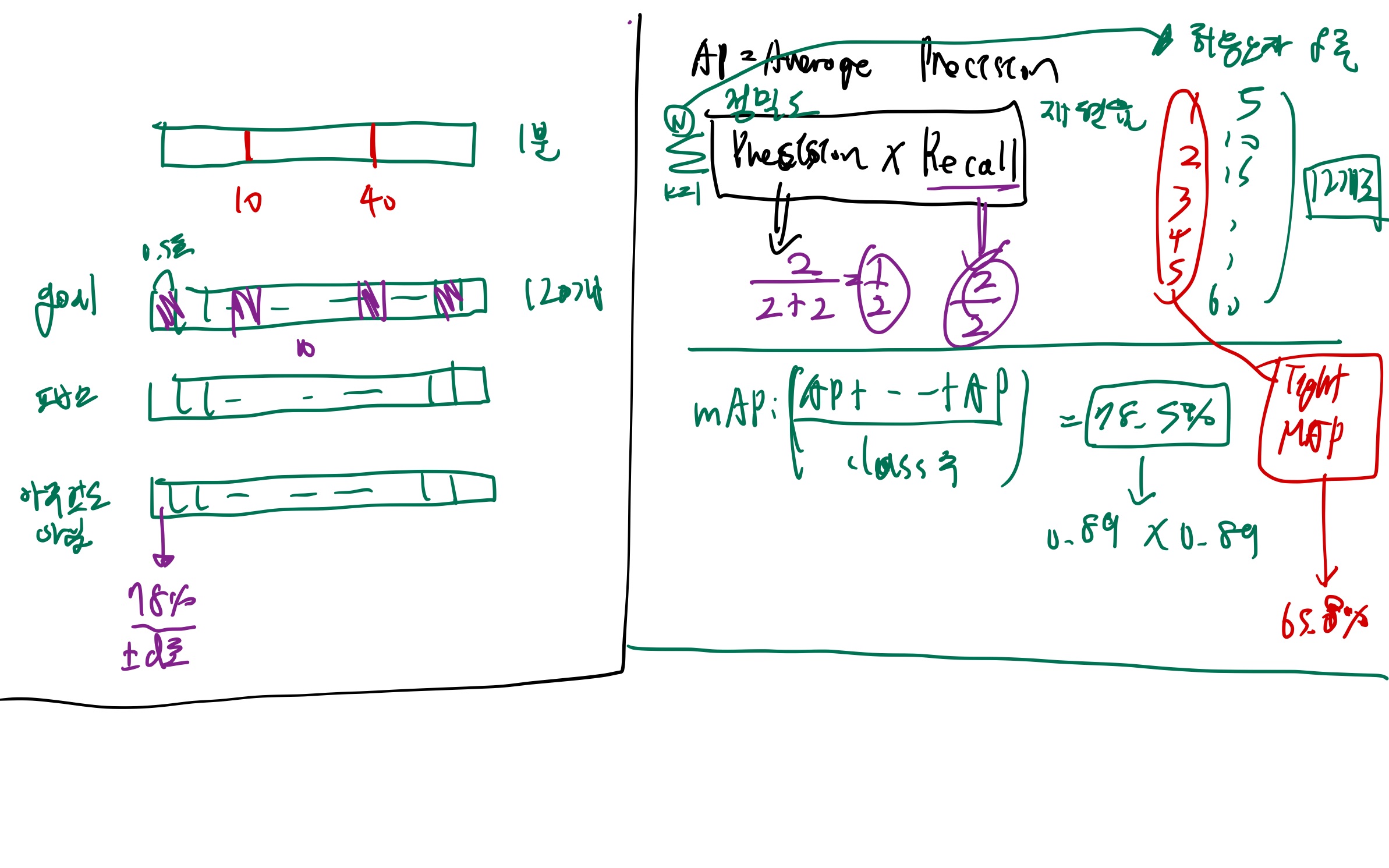
6.AP(Average Precision) / Precision / Recall

Recall도 높고, Precision도 높으면 최고지만,Recall이 더 중요함.(골이라고 예측해서 맞춘 갯수 / 골이라고 예측한 갯수) (골이라고 예측해서 맞춘 갯수 / (예측 시도 중에) 실제 골 갯수)뜻: 맞는걸 맞다고 잘 예측하는 능력mAP는 여러 클래스에 대
7.COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
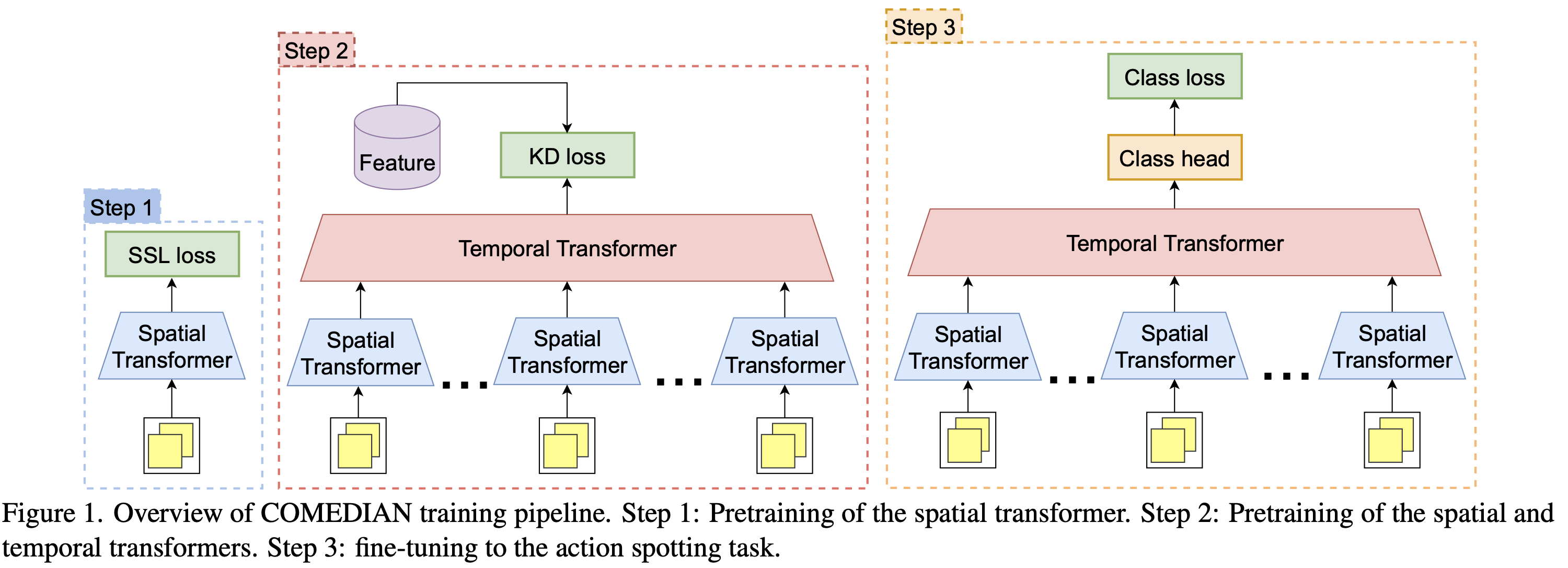
라벨이 없는 비디오 데이터를 활용하여 트랜스포머의 초기화에 관련된 도전을 해결knowledge distillation로 프리트레이닝을 하는 것의 이점에 대한 종합적인 분석을 제공이는 비디오에서 특정 행동을 정확한 시간에 탐지하는 '액션 스팟팅' 작업을 위한 공간적-시간
8.TEMPORALLY PRECISE ACTION SPOTTING IN SOCCER VIDEOS USING DENSE DETECTION ANCHORS
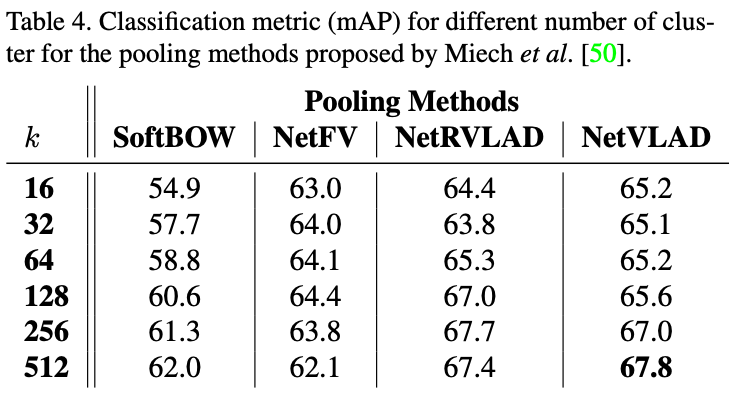
학습 시, 모든 anchor predictions 출력값을 이용해서, (후처리 없이) 바로 loss를 구했음."RESNet-152 + PCA" features 준비https://openaccess.thecvf.com/content/CVPR2021W/CVSpor
9.Temporal Action Localization 논문 모음
2023 인용 xhttps://arxiv.org/pdf/2311.17241v1.pdf2021, 21회 인용https://arxiv.org/pdf/2106.11812v1.pdf2021, 326회 인용https://arxiv.org/pdf/210
10. Highlight Detection
2023, 9회 인용https://openaccess.thecvf.com/content/ICCV2023/papers/Lin_UniVTG_Towards_Unified_Video-Language_Temporal_Grounding_ICCV_2023_paper.pdf
11.[23, 3][367] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
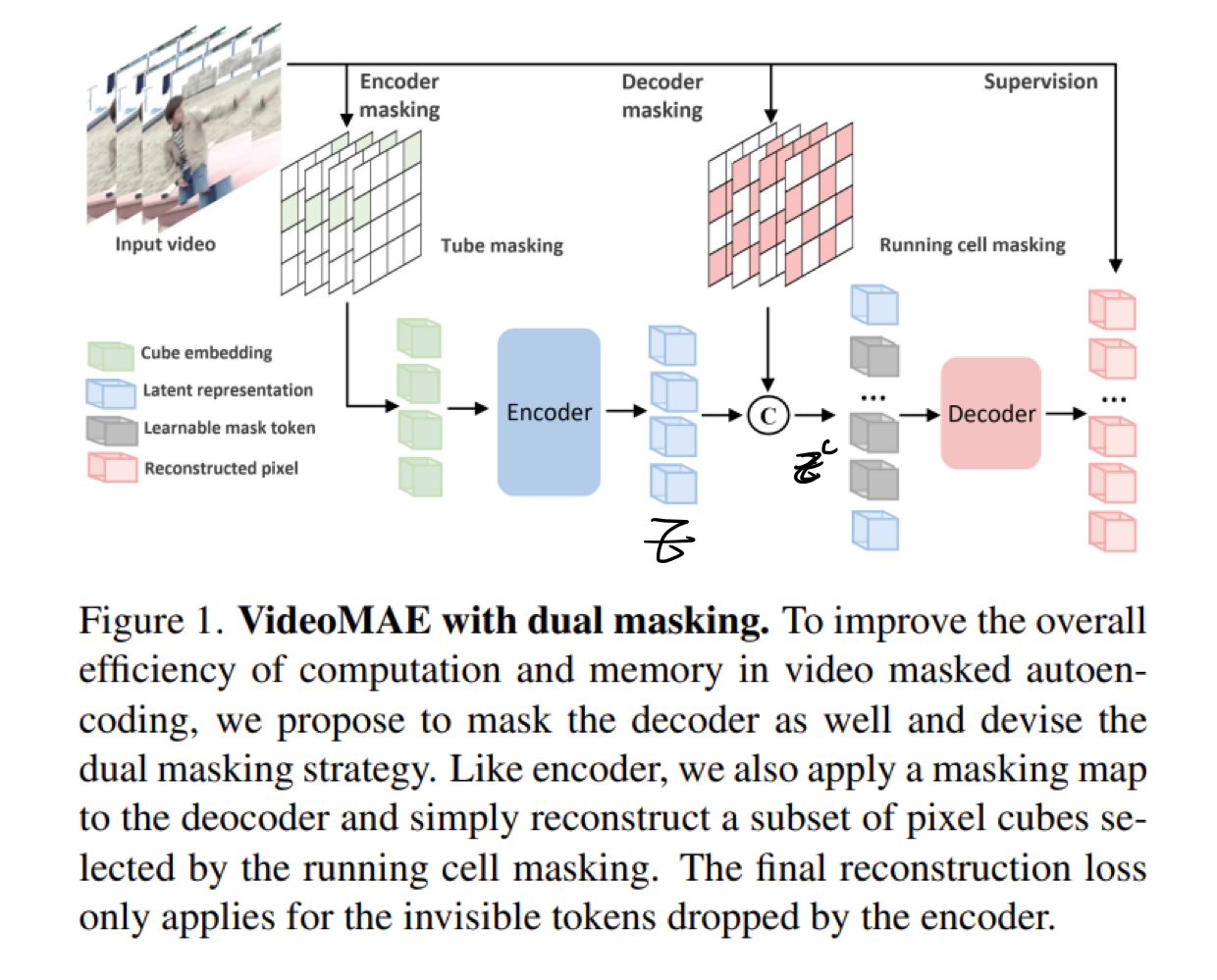
2023, 95회 인용https://arxiv.org/pdf/2303.16727v2.pdf
12.ActionFormer: Localizing Moments of Actions with Transformers
2022, 191회 인용https://arxiv.org/pdf/2202.07925.pdf
13.[22][1010] VideoMAE : Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training

작성중
14.action recognition 논문들
https://arxiv.org/pdf/2212.03191v2.pdf2022, 118회 인용https://arxiv.org/pdf/2212.03229v1.pdf2023, 23회 인용https://arxiv.org/pdf/2303.16058v1
15.[Video foundation model] 논문 공부 리스트
VIDEO FOUNDATION MODEL 1. VideoChat: Chat-Centric Video Understanding 23, 5 566회 인용 https://arxiv.org/pdf/2305.06355 https://github.com/OpenGVLab/Ask-
16.[23, 5][562] VideoChat: Chat-Centric Video Understanding

https://arxiv.org/pdf/2305.06355 https://github.com/OpenGVLab/Ask-Anything 3100 star 1. 관련 논문들 blip2 whisper [34] Robust speech recognition via l
17.QD-DETR 코드 돌리기
QD-DETR (Video+Audio) checkpoint: 존재QD-DETR (Video) checkpoint: 존재SlowFast and Open AI CLIP feature을 가지고 학습한다고 함.RTX 2080Ti GPU로 4시간 이면, 학습이 완료된다고 함.다
18.QD-DETR - dataset
아래 3개 데이터셋을 전부 이용시, 23, 31 논문의 데이터 split 전략을 따랐다.MR, HD 다 라벨링된 데이터셋10000 videos annotated with human-written text queries.dataset (from moment_detr r
19.[논문리뷰] QD-DETR

모먼트 검색(Moment Retrieval)영상 내에서 특정 텍스트 쿼리에 해당하는 순간을 찾아내는 작업하이라이트 검출(Highlight Detection)각 비디오 클립이 주어진 쿼리에 얼마나 부합하는지를 점수로 나타내는 작업하지만 기존의 Transformer 기반
20.[발표] "골 장면 추출" 하는 법 소개
"골 장면 추출" task에는 어떤 고려사항이 있을까?고려사항을 전부 반영할 수 있는 접근법을 선택해야 한다.video task 종류 소개그 중, 적합한 video task 선택 및 선택의 이유 공유접근 방법 2가지image Foundation Model을 가져다 쓰고
21.[발표][sub글]"골 장면 추출" 문제 정의
input/output을 어떻게 정의했는지, 내 깊은 고민이 들어가 있으니 한번 읽어봐주시면 감사!(공이 너무 빠르거나 골기퍼가 가려서) 골대에 공이 들어간 장면이 안보이는 경우도 골로 인지하는 네트워크 개발 희망. 경기 중간에 부상을 입어서 잠시 경기 중단되었을 때,
22.[발표][sub글] 어떤 video task 로 정의하고 해결하는게 적합할까?
작성중
23.[발표][sub글] 골장면 추출을 위한 2가지 딥러닝 기반 접근 방법 소개
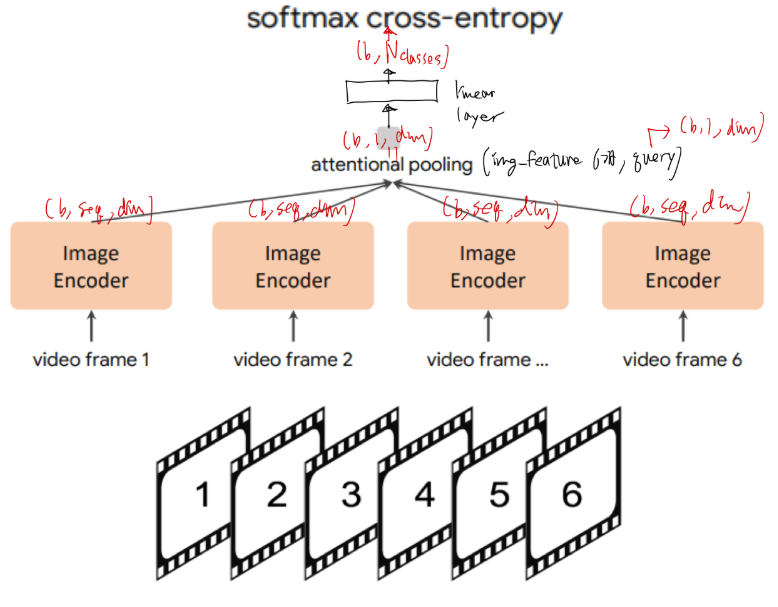
작성중
24.[발표][sub글][~24.3] Video Foundation Model 연구 동향 소개
0. 읽은 논문들 [21ViViT: A Video Vision Transformer](https://velog.io/@hsbc/ViViT-A-Video-Vision-Transformer) [22 VideoMAE : Masked Autoencoders are Data-E