SoccerNet-v2: A Dataset and Benchmarks for Holistic Understanding of Broadcast Soccer Videos
action recognition in videos
목록 보기
2/24
abstract
- https://openaccess.thecvf.com/content/CVPR2021W/CVSports/papers/Deliege_SoccerNet-v2_A_Dataset_and_Benchmarks_for_Holistic_Understanding_of_Broadcast_CVPRW_2021_paper.pdf
- SoccerNet의 500개의 편집되지 않은 방송 축구 비디오 내에서 약 30만 개의 주석을 공개
이 분야에서 가장 관련성 있는 작업들의 오픈 소스 적용 버전과 함께 재현 가능재현 가능한 벤치마크 결과와 우리의 코드 및 공개 리더보드를 공개
Introduction
- 최근 컴퓨터 비전 작업은 축구 방송에서 저수준 비디오 이해에 집중했습니다 [50].
- 예를 들어,
- 필드와 그 선을 정확하게 찾기 [13, 20, 32],
- 선수 감지 [12, 82],
- 그들의 동작 [21, 47],
- 그들의 포즈 [6, 87],
- 그들의 팀 [34],
- 공 [67, 72],
- 패스 가능성 [3]
- 프레임별 정보 이해는 스포츠 시청자의 시각적 경험을 향상시키고 선수 통계를 수집하는 데 유용하지만 [59, 73],
- 자동 편집 목적을 위한 더 높은 수준의 게임 이해에는 미치지 못합니다.
Related Work
비디오 이해 데이터셋
- 최근의 데이터셋은 더 긴 비디오의 미세한 주석을 시간적 [30, 38, 70, 84, 88] 또는 공간적-시간적 수준 [27, 49, 61, 80]에서 제공
- 더 글 있는데, 적지 않았음
축구 관련 데이터셋
- SoccerNet [24]
- 주요 유럽 리그의 500경기와 6천 개의 주석
- 단지 3개의 액션 클래스
- SoccerDB [37]
- SoccerNet의 비디오의 절반과 76개의 추가 게임
- 7개 클래스와 선수 경계 상자를 추가
- Yu et al. [85]
- 액션, 샷 전환 및 선수 경계 상자 주석
- 222개의 축구 경기 절반 데이터셋
- 그들은 몇 가지 주석만 가지고 있으며 어떠한 실험도 수행하지 않고 어떠한 작업도 제안하지 않음
액션 스팟팅
축구 비디오에서, 축구 이벤트의 앵커를 찾는 문제- 게임의 내용 이해를 다룸
- 축구넷의 주요 작업에서 3개에서 17개 액션 클래스로 확장
- 우리는 아래 작업들을 기반으로, 확장된 액션 스팟팅 작업에 대한 벤치마크 결과를 제공
- Giancola et al. [24]
- SoccerNet에서의 액션 스팟팅 작업을 정의
- 시간적 풀링을 기반으로 한 기준을 제공
- Rongved et al. [64]
- 5초 슬라이딩 윈도우 방식으로 비디오 프레임에 직접 3D ResNet을 적용하는 데 중점
- Vanderplaetse et al. [77]
- 시각적 및 오디오 기능을 다중 모드 접근 방식으로 결합
- Cioppa et al. [11]
- 동작 주변의 시간적 컨텍스트를 모델링하기 위해 컨텍스트 인식 손실 함수를 도입
- Vats et al. [78]
- 동작 위치의 불확실성을 고려하는 멀티 타워 CNN을 사용
- Tomei et al. [74]
- 특징 추출기를 미세 조정하고 동작 이후의 프레임에 초점을 맞추기 위해 마스킹 전략을 사용
SoccerNet-v2 데이터셋
개요.
- SoccerNet [24]의 500경기, 764시간 동안의 약 30만 개의 타임스탬프를 수동으로 주석 처리
그림 3. SoccerNet-v2 액션.
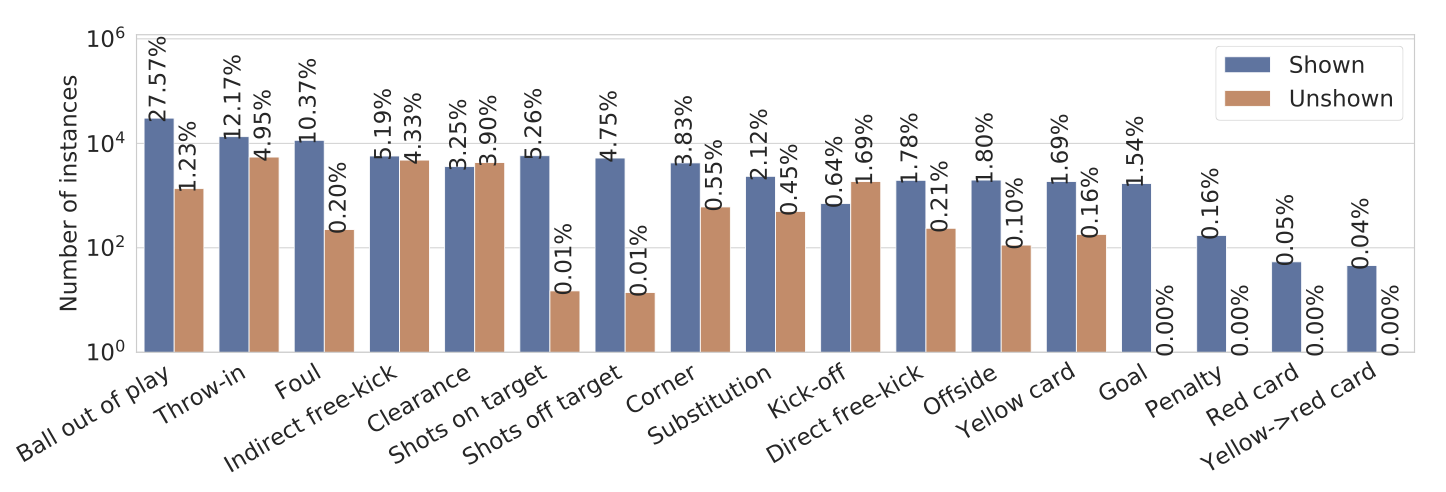
- 17개 클래스 중 보여지는 액션과 보여지지 않는 액션의 로그 스케일 분포, 그리고 각 클래스가 차지하는 비율.
- 데이터셋은 불균형적이며, 가장 중요한 액션 중 일부는 덜 풍부한 클래스에 속합니다.
Ball out of play- Throw-in
- Foul
- Indirect Free-kick
- Clearance
Shots on targetShots off target- Corner
- Substitution
Kick-off- Direct free-kick
- Offside
- Yellow card
Goal- Penalty
- Red Card
- Yellow -> Red Card
액션
- 우리는 축구에서 가장 중요한 17가지 유형의 액션을 식별했으며, 이는 그림 3에 나열되어 있습니다.
[24]를 따라, 우리는 SoccerNet의 500경기 각각의 액션을 축구 규칙에 의해 정의된 단일 타임스탬프로 주석 처리- 예를 들어,
- 코너킥의 경우, 선수의 발과 공이 마지막으로 접촉하는 장면인 마지막 프레임을 주석 처리
- 우리는 주석 지침을 부가 자료에 제공
각 타임스탬프에 방송 비디오에서 해당 액션이 보여지는지 아니면 보여지지 않는지를 나타내는 새로운 이진 가시성 태그를 추가- 예를 들어,
이는 프로듀서가 골키퍼의 클리어런스 샷이 끝난 후에도 목표에서 벗어난 슛의 리플레이를 보여줄 때 발생- 시청자는 TV 방송에 나오지 않았음에도 클리어런스가 이루어졌음을 알 수 있습니다.
- 보여지지 않은 액션을 찾는 것은 게임을 넘어서 프레임 기반 분석을 요구하는 도전적인 일
- 우리는 보여지지 않은 액션의 타임스탬프를 가능한 최선의 시간적 추정으로 주석 처리
- 이러한 액션은 전체 액션의 18%를 차지
SoccerNet [24]과 일관성을 유지하기 위해, 우리는 각 액션이 홈팀 또는 원정팀에 의해 수행되었는지를 주석 처리하지만, 이에 대한 추가 분석은 향후 작업으로 남겨둡니다.
카메라
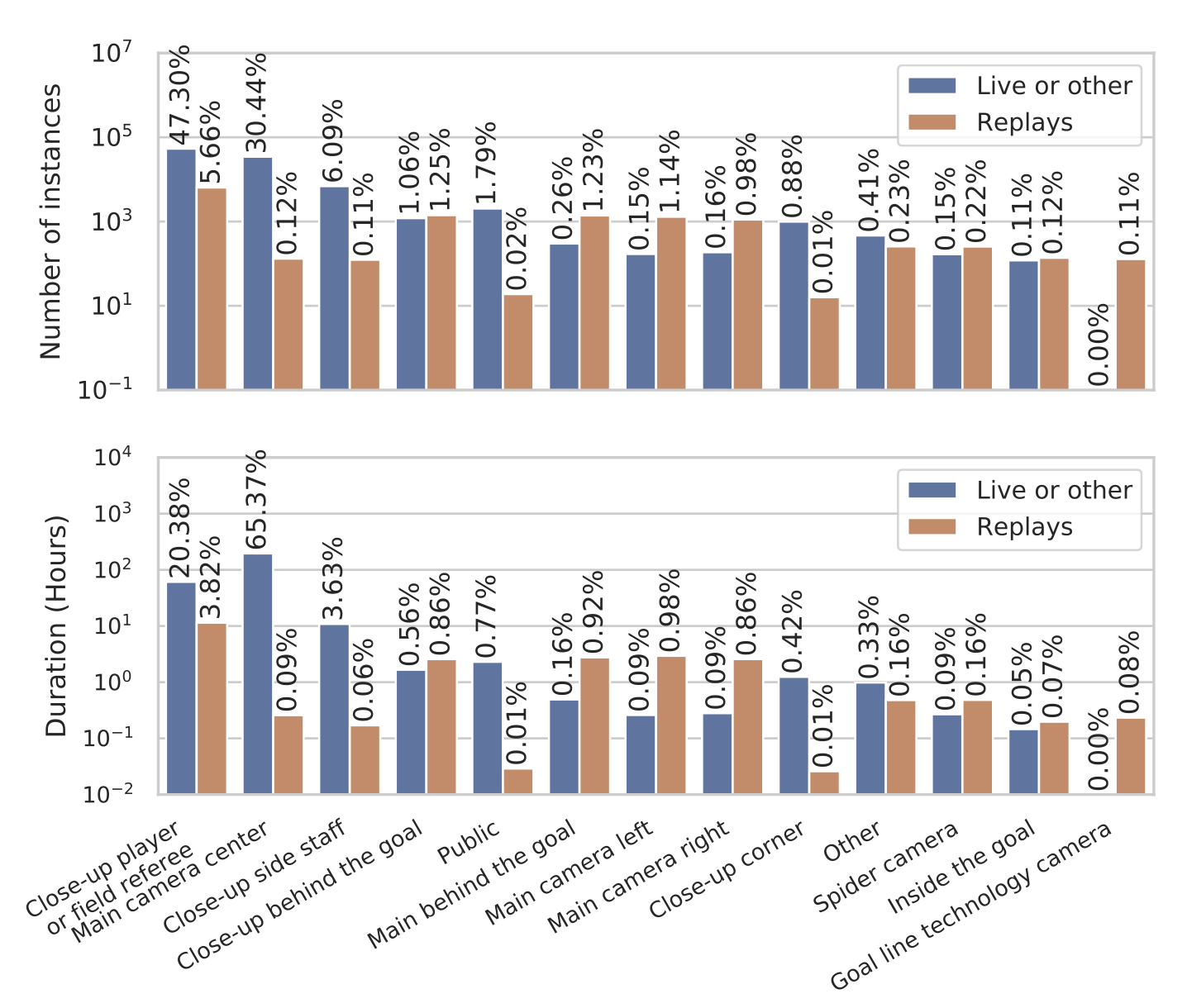
- 우리는 총 158,493개의 카메라 변경 타임스탬프를 주석 처리
- 이 중 116,687개는 200경기의 하위 집합에 대해 포괄적
- 나머지는 게임에서 리플레이 샷을 구분합니다(이하 참조).
- 전체적으로 주석 처리된 게임의 경우, 이는 게임당 평균 583번의 카메라 전환 또는 9초마다 1번의 전환을 의미합니다.
- 이 타임스탬프에는 가장 흔한 13가지 가능성 중에서 보여진 카메라 샷의 유형이 포함
- 우리는 발생 횟수와 총 지속 시간 측면에서 그들의 분포를 표시
- 클래스 불균형은 이 데이터셋의 어려움을 나타내지만, 실제 응용 프로그램에서 사용되는 방송과 일치하는 분포를 나타냄
- 게다가, 한 카메라 샷에서 다음으로 이동하는 데는 다양한 유형의 전환들이 발생하며, 우리는 각 타임스탬프에 이를 추가
- 두 카메라 간의 갑작스러운 변경(71.4%), 프레임 간 페이딩 전환(14.2%), 또는 로고 전환(14.2%)
- 최종적으로, 우리는 카메라 샷이 게임과 관련하여 라이브로 발생하는지(86.7%), 액션의 리플레이를 보여주는지(10.9%), 또는 다른 유형의 리플레이(2.4%)인지를 나타냄
방송 비디오 이해 작업
- 우리는 컴퓨터 비전이 방송 축구 비디오를 더 잘 이해하고 비디오 프로듀서의 편집 부담을 줄이는 데 도움이 될 종합적인 작업 세트를 제안합니다.
- 더 중요한 것은, 이러한 작업들이 다른 분야로 쉽게 옮겨질 수 있어 더 넓은 함의를 가진다는 것입니다.
- 이는 SoccerNet-v2를 비디오 이해의 일반 분야에서 새로운 아이디어를 개발하고 혁신적인 솔루션을 구현하기 위한 이상적인 놀이터로 만듭니다.
- 이 작업에서, 우리는 SoccerNet-v2에서 세 가지 주요 작업을 정의합니다: 액션 스팟팅, 카메라 샷 분할 및 경계 감지, 그리고 리플레이 그라운딩. 이 작업들은 그림 5에서 설명되며, 이후에 더 자세히 설명됩니다.
액션 스팟팅.
방송 축구 경기의 중요한 액션을 이해하기 위해, SoccerNet [24]은 비디오에서 발생하는 모든 액션을 찾는 액션 스팟팅 작업- 축구 이해를 넘어서, 이 작업은 긴 편집되지 않은 비디오에서 특정 의미론적 의미를 가진
순간을 검색하는 더 일반적인 문제를 다룸 - Beyond soccer understanding, this task addresses the more general problem of
re- trieving momentswith a specific semantic meaning in long untrimmed videos. - 이러한 측면에서, 우리는 비디오 감시 또는 비디오 색인 작성 등에서 순간 스팟팅 응용 프로그램을 예상
- As such, we foresee moment spotting applications in e.g. video surveillance or video indexing.
- 이 작업에서,
액션은 활동 위치 지정 [30] 작업과 달리 시작 및 종료 타임스탬프로 구분되는 것이 아니라단일 타임스탬프로 고정됩니다. - In this task, the actions are anchored with a single timestamp,
contrary to the task of activity localization [30],where activities are delimited with start and stop timestamps. - 우리는 알고리즘의 액션 스팟팅 성능을 다음과 같이 정의된 Average-mAP 메트릭으로 평가합니다. 예측된 액션 스팟이 동일한 클래스의 기준 진실 타임스탬프에서 주어진 허용 오차 δ 내에 있으면 긍정적입니다. PR 곡선을 기반으로 하는 Average Precision (AP)이 계산되고 클래스별로 평균(mAP)을 낸 후, Average-mAP은 5초에서 60초 범위의 다양한 허용 오차 δ에서 계산된 mAP의 AUC입니다.
5. 벤치마크 결과
일반적인 코멘트.
- SoccerNet [24]은 500경기의 고화질과 저화질 비디오를 제공
- 더 쉬운 실험을 위해,
2fps에서 계산된 ResNet [29], I3D [8], C3D [76]의 특징들을 PCA로 512차원으로 축소시켜 제공 - [11, 24]을 따라, 우리의 실험에서 우리는
- 초기 실험에서 더 나은 결과를 얻은 압축된 비디오 표현으로서 -> 512차원 ResNet 프레임 특징을 사용
- 우리는 가장 관련 있는 기존 방법들을 적응시켜 SoccerNet [24] 테스트 세트에서 벤치마크 결과를 제공합니다.
우리는 이를 재현하기 위한 코드를 공개하고, 전용 서버에서 리더보드를 호스팅할 예정
5.1. 액션 스팟팅
방법.
우리는 SoccerNet [24]에서 공개 코드를 발표한 모든 방법들을 효율적으로 적응시키거나 재구현
1. MaxPool과 NetVLAD [24].
- SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos
- https://openaccess.thecvf.com/content_cvpr_2018_workshops/papers/w34/Giancola_SoccerNet_A_Scalable_CVPR_2018_paper.pdf
- CVPR 2018
- 이 모델들은 ResNet 특징들을 시간적으로 풀링한 후 분류 계층을 거침
20초의 겹치지 않는 세그먼트들이 어떤 액션 클래스가 포함되어 있는지 분류- 테스트에서,
20초의 슬라이딩 윈도우와 1프레임의 스트라이드를 사용하여시간에 따른 액션 점수를 추론하고,NMS를 사용하여 액션 스팟으로 축소 - 우리는 기본적이지만 가벼운 max 풀링과 64 클러스터를 가진 학습 가능한 NetVLAD 풀링을 고려
- 우리는 17개 클래스로 더 잘 확장하기 위해 원래 코드를 기반으로 이 방법을 재구현
2. AudioVid [77].
- Improved Soccer Action Spotting using both Audio and Video Streams
- https://openaccess.thecvf.com/content_CVPRW_2020/papers/w53/Vanderplaetse_Improved_Soccer_Action_Spotting_Using_Both_Audio_and_Video_Streams_CVPRW_2020_paper.pdf
- CVPR 2020 40회 인용
- 이 네트워크는 NetVLAD를 사용하여
20초 분량의 ResNet 특징들을 시간적으로 풀링하며, 2fps에서 하위 샘플링된 VGGish [31] 동기화 오디오 특징들을 사용- 두 세트의 특징들은 시간적으로 풀링되고, [24]에서처럼 분류 모듈에 연결되고 공급
- 마찬가지로,
스팟팅 예측은 비디오 청크의 중심에 있음 - 우리는 17개 클래스로 분류 모듈을 확장
3. CALF [11].
- A context-aware loss function for action spotting in soccer videos
- 2020 CVPR 78회 인용
- https://arxiv.org/pdf/1912.01326.pdf
- 이 네트워크는
2분 분량의 ResNet 특징들을 다룸 - 그대로 유지된 시공간 특징 추출기, 17개 클래스에 맞게 적응된 시간적 그리고 17개 클래스로 분류된
청크당 최대 15개의 예측을 출력하는 액션 스팟팅 모듈로 구성 - 세그먼트 모듈은 클래스별로 네 개의 컨텍스트 슬라이싱 하이퍼파라미터를 가진 컨텍스트 인식 손실로 훈련
- [11]을 따라, 우리는 베이지안 최적화 [54]를 사용하여 이들에 대한 최적의 값을 결정
- 우리는 기존 코드를 기반으로 방법을 재구현하고, 적절한 훈련 시간을 달성하기 위해 훈련 전략을 최적화
결과.
- 우리는 표 2에서 액션 스팟팅을 위한 벤치마크 결과의 리더보드를 제공합니다. 또한, 가장 가까운 기준 진실 타임스탬프가 보여지는/보여지지 않는 액션인 예측된 스팟에 대한 평균-mAP로 보여지는/보여지지 않는 액션의 성능을 계산합니다. 우리는 그림 6에서 CALF로 얻은 질적 결과를 보여줍니다.
- 풀링 접근 방식인 MaxPool과 NetVLAD는 SoccerNet-v2에서 다른 방법들과 비교하여 부족
- 우리는 MaxPool의 엄격한 프루닝이 단일 완전 연결 계층으로 제한된 학습 능력을 가지고 있다고 생각
- 유사하게, NetVLAD는 특히 Non-Maximum Suppression이 0.5 미만의 신뢰 점수를 가진 결과를 버리는 것과 같이 스팟팅 모듈의 설계에서 최적이 아닌 선택으로 인해 뒤쳐질 수 있습니다.
- AudioVid는 보여지는 인스턴스와 5/17개 액션 클래스에서 우세합니다.
- 오디오 특징을 주입하는 것은 소리가 일반적으로 이미지와 동기화되어 있기 때문에 보이는 액션에 도움이 되는 것으로 보입니다.
- 또한, 이는 심판의 호루라기가 울리기 전후의 액션에서 가장 잘 수행되어, 오디오 특징의 중요성을 강조
- 그러나 오디오 특징은 보여지지 않는 인스턴스에서는 그다지 유용하지 않은 것으로 보입니다.
- CALF는 전반적으로, 보여지지 않는 인스턴스와 대부분의 액션 클래스에서 가장 좋은 성능을 보입니다.
- 컨텍스트 인식 손실은 액션을 찾기 위해 시간적 컨텍스트에 초점을 맞추는데, 이는 이 작업에 유용합니다.
- 이는 액션 주변의 시간적 컨텍스트가 유용한 정보를 포함하고 있음을 강조합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것