Abstract
- SOT, MOT 에 대한 각각의 방법론은
다른 training datasets / 각 task의 tracking objects의 다름때문에 서로 적용되기 어렵다. Unified Transformer Tracker(UTT)제안- 다른 시나리오에서의 tracking 문제들의 하나의 패러다임으로 처리
track transformer- SOT와 MOT의 target을 둘 다 추적한다.
- target을 localize 하기 위해 -> target feature와 tracking frame feature간 상관관계를 이용
- 제안한 모델은 각각의 tasks datasets 모두에 대해, 동시에 end-to-end로 학습된다. -> SOT와 MOT의 objectives 을 최적화하기 위해
Introduction
- SOT
- (어떤 object category 던) 첫 frame 의 annotated traget을 tracking 함.
- The target box in SOT is specified in the first frame.
- 방법론: Siamese architecture(https://velog.io/@hsbc/230602-Siamese-Network)이 널리 적용되어 왔음.
- objects의 discriminative representation에 집중한.
- MOT
- (target categories가 알려진 상태에서) 물체들의 bounding boxes와 ID를 추정함.
- 물체는 도중에 나타나거나 사라질 수 있음.
- 방법론: tracking by detection 방법이 널리 사용되어 왔음.
- 이 방법론은 SOT에 적합하지 않는데,
SOT는 unseen categories의 object를 detect해야하기 떄문 - 어떤 연구들은 MOT에 Siamese tracker을 썼는데, 그 이유는 아래와 같다. (하지만 결과가 별로 좋진 않았다.)
- tracking frames의 targets의 위치를 예측하기 위함
- Siamese 네트워크는 reference frame에서의 대상(즉, 추적하려는 객체)과 tracking frame에서의 대상 사이의 유사성을 측정할 수 있습니다.
- 이를 통해 tracking frame에서 대상의 위치를 예측할 수 있습니다.
- detection boxes와 predicted boxes를 결합하여, detection 성능을 높이기 위함.
- Siamese 추적기는
검출된 상자(즉, 객체 감지 알고리즘에 의해 식별된 영역)와예측된 상자(즉, Siamese 추적기에 의해 예측된 영역)사이의 유사성을 측정할 수 있음. - 이 두 유형의 상자를 결합함으로써, 검출 성능을 높일 수 있습니다.
- Siamese 추적기는
- 성능이 좋지 않았던 이유
- 여러 객체가 겹치거나, 객체가 사라지거나 나타나는 경우 등에서는 Siamese 추적기의 성능이 떨어짐
- tracking frames의 targets의 위치를 예측하기 위함
- Siamese trackers 가 MOT에도 적용되었지만, 그 어떤 연구도 SOT와 MOT 문제를 하나의 통합된 패러다임에서 처리가능하지 않았다.
- 이 방법론은 SOT에 적합하지 않는데,
- UniTrack
- SOT와 MOT를 동시에 해결하려는 첫번째 시도
- backbone을 공유하고, multiple tracking heads를 함께 이용함으로써
- 'tracking heads'는 네트워크에서 객체 추적을 담당하는 부분
- backbone을 공유하고, multiple tracking heads를 함께 이용함으로써
- 문제점
- UniTrack의 'tracking head design' 때문에 큰 규모의 tracking 데이터셋을 효과적으로 학습하는 데 실패
- UniTrack은 다른 tasks에서의 'divergent training datasets'(서로 다른 분포를 가진 데이터셋)를 처리하는 데 문제가 있음
- 예를 들어, SOT와 MOT 작업에서 사용되는 데이터셋은 다른 특성을 가질 수 있습니다.
- 이런 데이터셋을 동시에 처리하는 것은 학습 과정에서 어려움을 초래할 수 있습니다.
- 예를 들어, SOT와 MOT 작업에서 사용되는 데이터셋은 다른 특성을 가질 수 있습니다.
- 이러한 이유에서, UniTrack의 tracking capacity는 한계가 있다.
- SOT와 MOT를 동시에 해결하려는 첫번째 시도
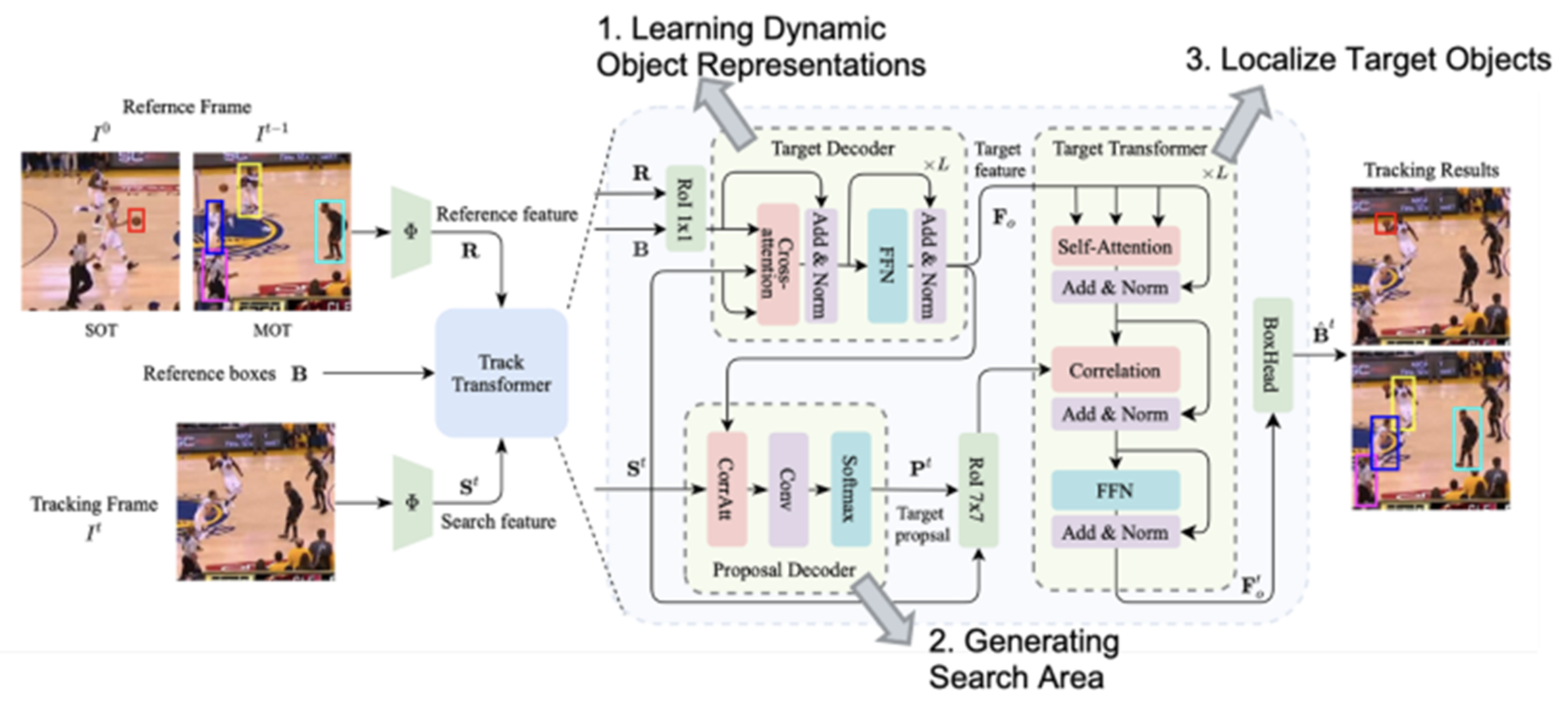
- UTT
추적할 대상은reference frame(예: 이미지 또는 비디오 프레임) 내에 있습니다.- 이 대상은 SOT에서 명시적으로 지정되거나 MOT에서 감지됩니다.
- 이
추적 대상에 대해, 우리는 이전 위치정보를 기반으로 한 작은feature map proposal을tracking frame에 제공합니다.feature map proposal은 이미지 또는 비디오 프레임의 작은 부분을 나타내는 것으로, 이는 추적 대상의 위치를 더 정확하게 예측하는데 도움을 줍니다.
target feature는feature map proposal과 상관 관계를 가지며,- 이를 통해
target representation을 업데이트하고target position를 출력합니다.
- 이를 통해
- 이렇게 함으로써 UTT는 SOT와 MOT에서 객체를 추적하는 데 동일한 설계를 사용할 수 있습니다.
- 업데이트된
target feature는 새로운search feature proposal과 상관 관계를 가집니다.- 이 새로운
search feature proposal은 생성된target position를 기반으로 자른 것입니다.
- 이 새로운
- 이 과정은 추적 대상의 위치를 정제하기 위해 여러 번 반복됩니다.
- 두 작업에서 훈련 샘플을 모두 활용할 수 있도록, 우리는 네트워크를 각 작업의 데이터셋으로 교대로 훈련시킵니다.
- 이 설계는 UTT가 SOT와 MOT에서 동일한 방식으로 작동하면서, 각각의 작업에서 훈련 데이터를 활용할 수 있게 합니다.
- 아래 논문들과 견줄만한 성능을 냈다.
- SOT: LaSOT / TrackingNet / GOT-10k
- MOT: MOT16
Related Work
SOT
- 문제 정의: 초기 위치만 제공되고, 물체의 category는 알려지지 않는다.
- 초기 접근방법:
correlation filter based methodMinimum Output Sum of Square Error(MOSSE) filter
- 중기 접근방법:
Siamese Network based Trackers- 두 이미지 간 cross-correlation을 통해, similarity map을 학습.
- 최근 접근방법:
Transformer - 대부분의 SOT 방법론은 (reference image 상에서,) targets와 tracking frames를 crop 한다. (target representation을 추출하기 위해)
- 하지만, 모든 target과 tracking frame을 crop 하는 것은 -> MOT에서 비효율적이다.
- 이러한 단점을 극복하기 위해,
- 우리 UTT는 high-level feature map 상에서 target representation을 추출한다.
- 그리고, feature maps를 cropping 함으로써 Searching Area를 제한한다.
- 또한 tracking을 위한 target representation을 업데이트 하기 위해,
- (보통의 transformer의 cross attention을 쓰는 대신), 우리는
target feature와search feature을 correlation attention 한다.
- (보통의 transformer의 cross attention을 쓰는 대신), 우리는
MOT
- 문제 정의: 고정된 set의 categories + 알려지지 않은 수의 objects
- tracking by detection 방법론이 대세 였음
- 연속적인 frames 간 detections를 Link 하는 방법론
- 논문 1
- Siamese architecture을 적용하여, objects pairs 간 dissimilarity를 학습
- 논문 2 (Fair-MOT)
- 공통의 backbone으로부터
object detection task와appearance embedding task를 학습하였다. (association accuracy를 높이기 위해)
- 공통의 backbone으로부터
- 논문 3 (CenterTrack)
- objects의 center points를 detect하고,
이전 frame과의 offests을 예측한다.
- objects의 center points를 detect하고,
- 논문 4
- transformer 기반의 detector을 만들어서, frames 간 boxes를 propagate 하는 시도들이 이썽ㅆ다.
- feature representation을 높이기 위해, encoder with self attention이 적용됨
- decoder은
learnable query features와이전 frames의 detected object features간 cross attnetion을 씀.
- UTT
- self attention: multiple target features 에 쓰임
- correlation attention: target feature과 search feature간 attention에 쓰임.
Method
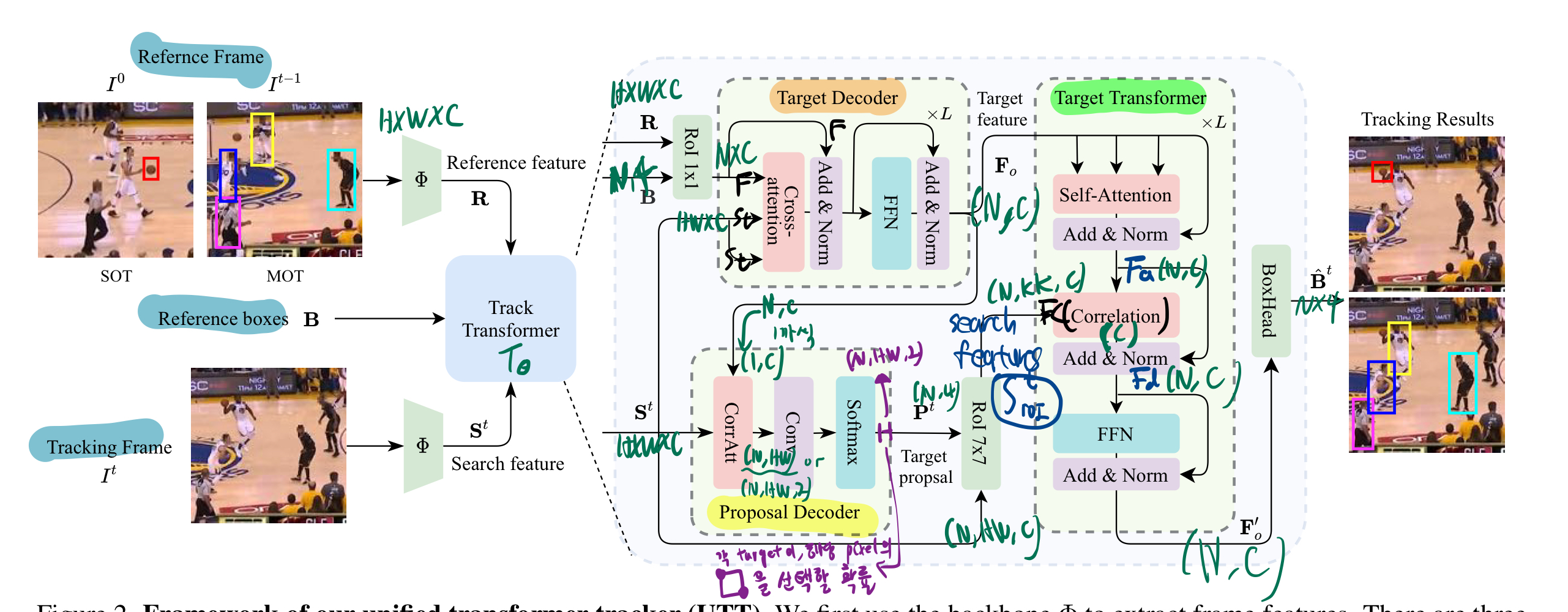
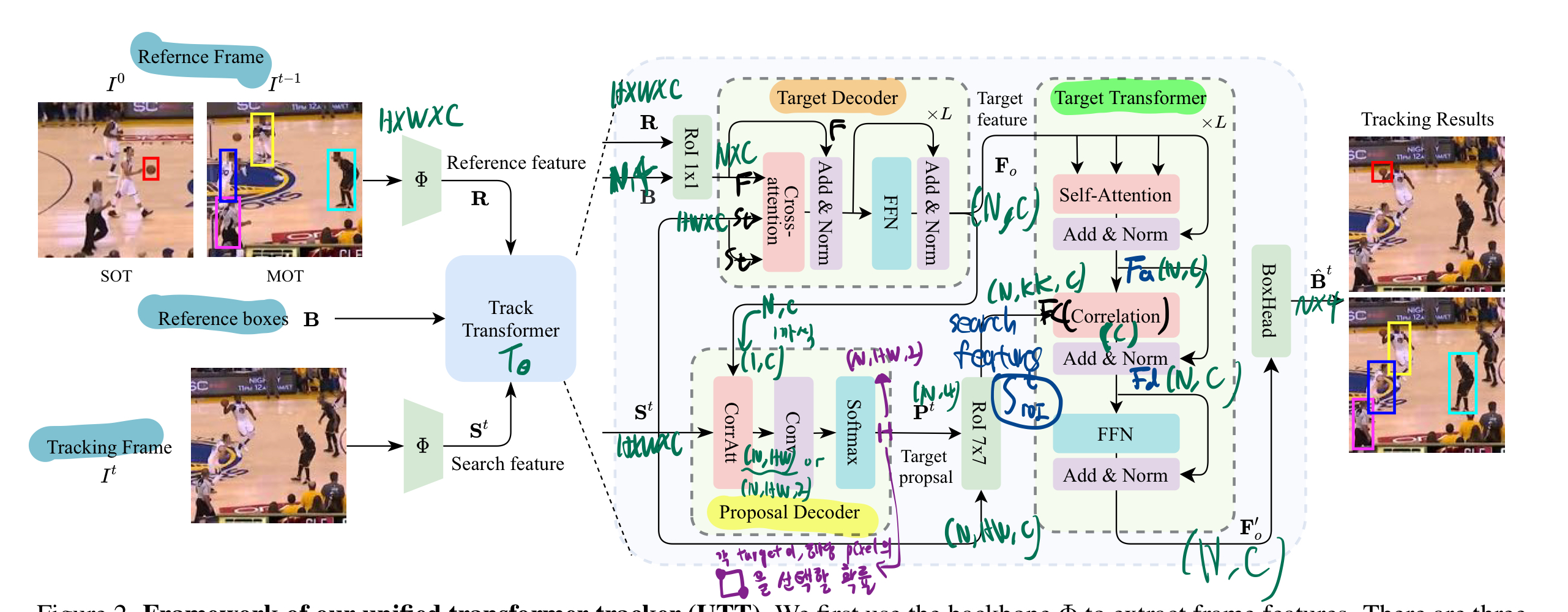
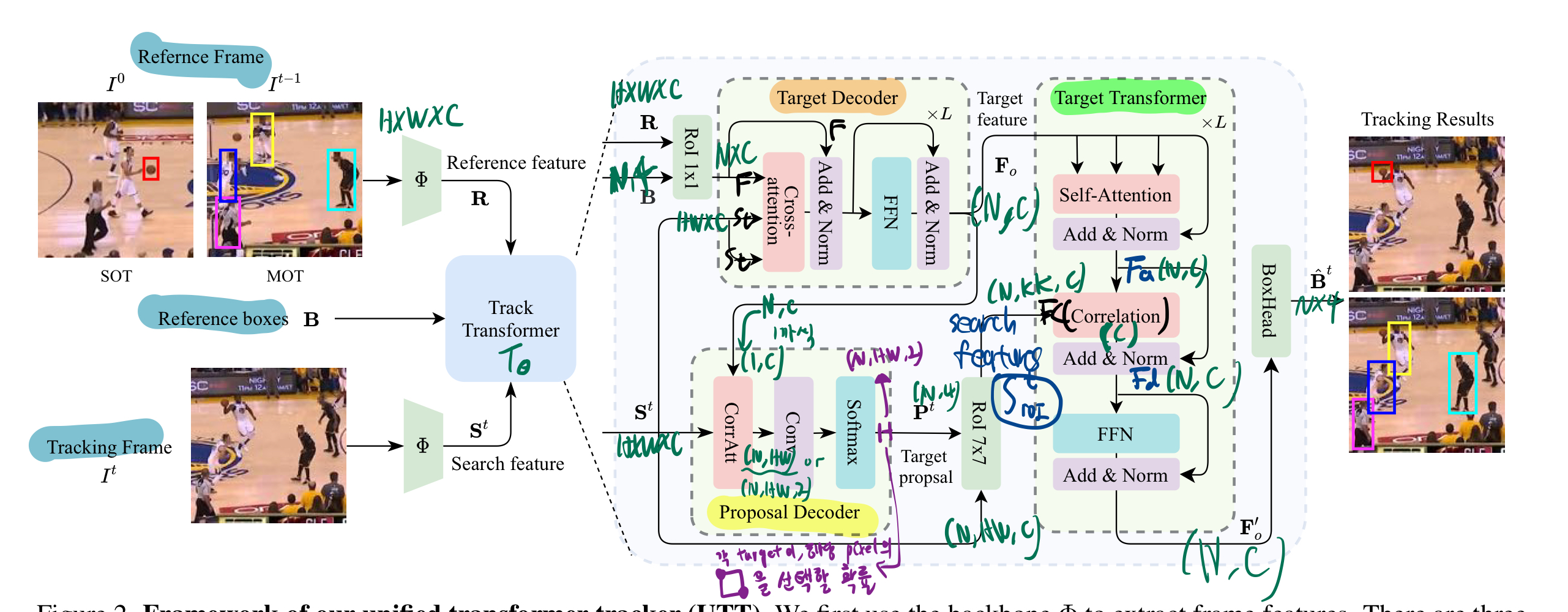
Overview
SOT
- 목표: 모든 T frame에 대해, 아래의 target을 localize
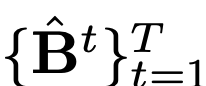
MOT
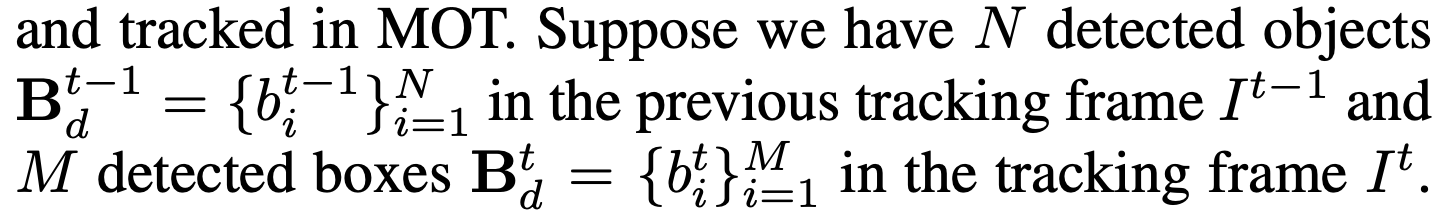
- 위 주어진 상황에서, M개에 N개를 매칭시키기
Target Decoder
- ROIAlign 1*1
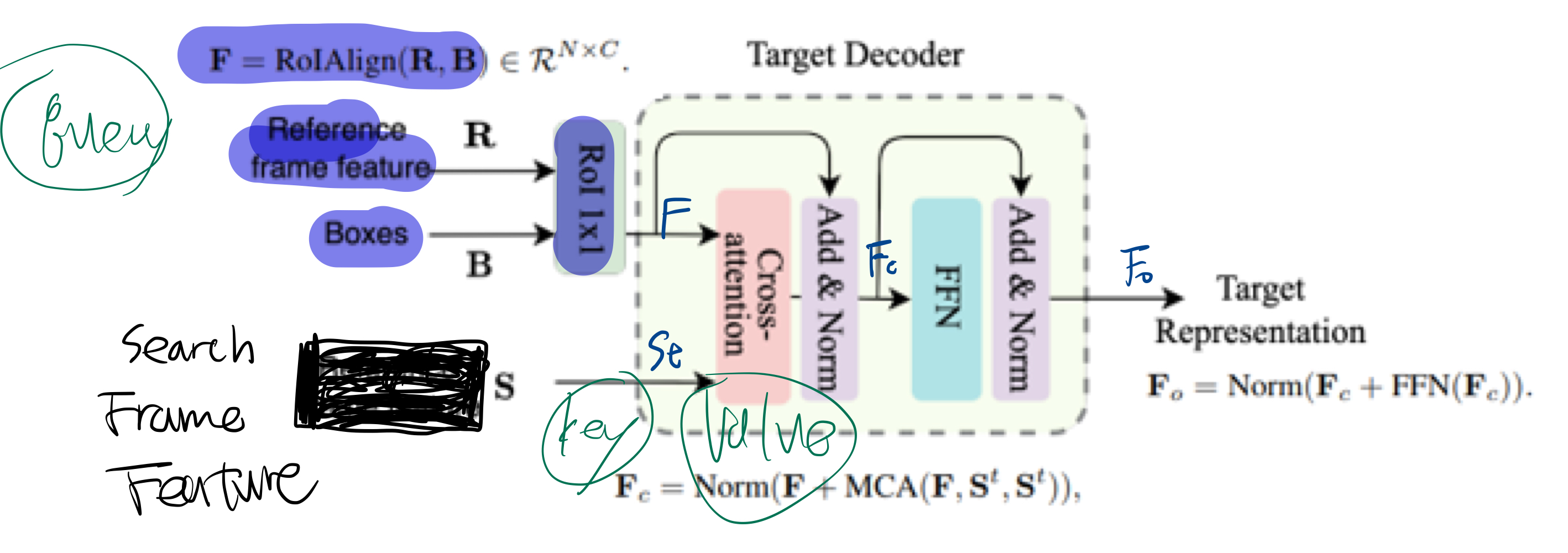
Proposal Decoder
-
-
동기
- 각 target feature을, 전체 frame feature에 연관시키는 것은, 메모리와 계산량에 큰 문제가 생길 수 있다.
- 특히, track frame이 high resolution이거나, tracking 할 물체가 많은 경우
- 각 target feature을, 전체 frame feature에 연관시키는 것은, 메모리와 계산량에 큰 문제가 생길 수 있다.
-
Proposal decoder은 tracking frame에서의
Candidate Search Area정보를 return (현재 object가 있을 법한 지역을 추린다.)- top-left와 bottom-right 좌표의 확률적 분포를 나타낸다.
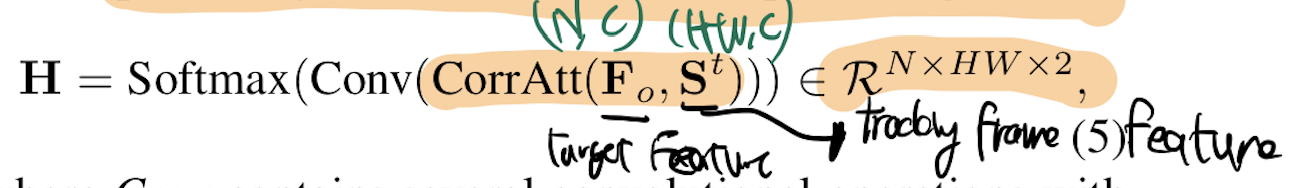

- top-left와 bottom-right 좌표의 확률적 분포를 나타낸다.
-
다른 tracking trasformer 와의 차별점
- 계산 효율적
- cross attention의 O(H2W2NC) 복잡도 -> (proposal decoder 도입으로 인해) -> O(K4NC) 복잡도로 줄 수 있음.
- 계산 효율적
-
cross attention 대신, correlation attention이 쓰임
Target Transformer

반복 & Boxhead
- 해당 구조를 L번 반복
- 마지막 Boxhead: proposal boxes의 delta bias를 출력함.
Training

SOT
-
SOT 학습 시에는, proposal encoder을 학습에 이용했다.

-
3
- 초기에 정의된 모델은 사물 자체의 representation learning 능력이 떨어지기 때문에, 우선 스스로 tracking 하는 것으로 representation을 학습
-
4
- 객체의 위치를 prediction
-
5: IOU Loss + 1-norm Loss
MOT
- Target Proposal (Pt) 학습을 위한
initial candidate search areas를 생성하기 위해, 우리는 proposal decoder을 사용하지 않았다.- 대신,Target Proposal (Pt) 학습을 위해, ground truth boxes에 gausian noise를 주어서
initial proposal을 생성하였다. - 이는 test 상황에서, 이전 frame의 detected box가, 현재 tracking frame의 proposal로 사용되는 것과 유사하다.
- 대신,Target Proposal (Pt) 학습을 위해, ground truth boxes에 gausian noise를 주어서
- 우리가 만약, 모든 objects 에 대해 proposal decoder을 써서 proposal을 생성한다면, 우리 모델은 학습될 수 없다.
- 그 이유는 feature map의 높은 해상도와 MOT의 많은 데이터 수 때문이다.

- 그 이유는 feature map의 높은 해상도와 MOT의 많은 데이터 수 때문이다.
- 3, 4
- detection head를 학습.
- detection model로 DETR을 사용했고, loss function은 DETR에서 사용한 Hungarian Loss (https://velog.io/@hsbc/DETR-PETR)
- 5
- Prediction 수행
Experiment
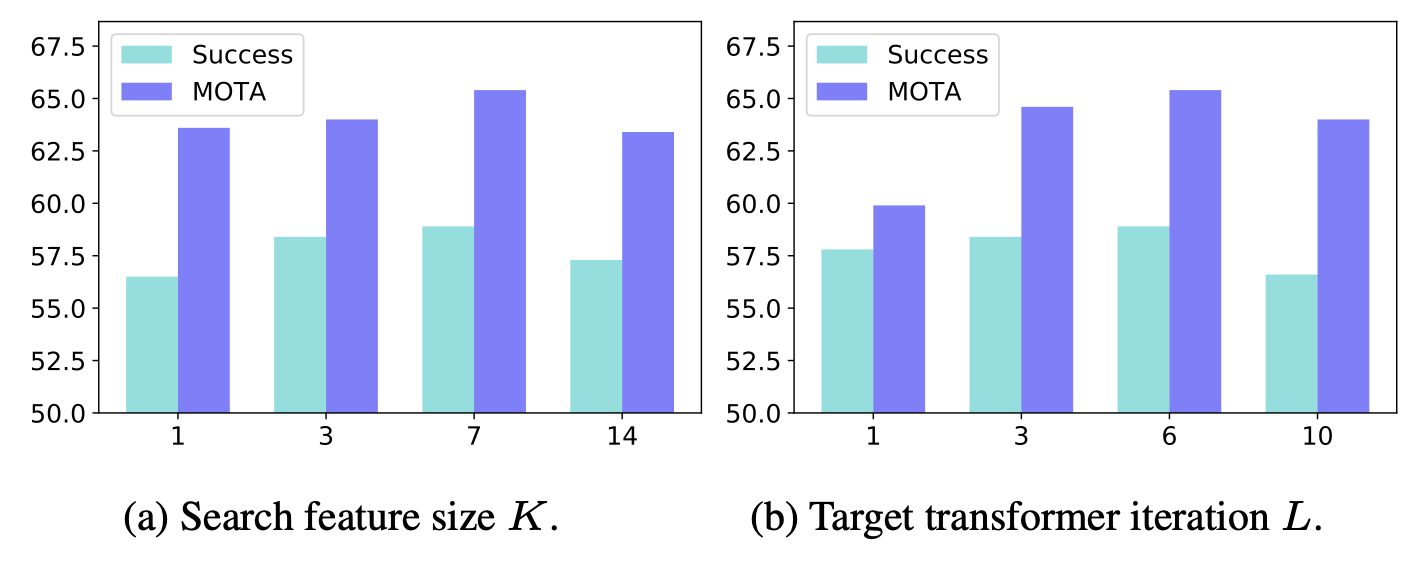
MOTA (Multiple Object Tracking Accuracy)
- MOTA 값은 1에서 시작하여 각 오류 유형에 대한 패널티를 뺍니다. 따라서 MOTA 값이 높을수록 추적 성능이 더 좋다는 것을 의미합니다.
- MOTA는 추적 오류를 측정하는 지표입니다. 이는 거짓 양성, 미탐지, 그리고 ID 스위치를 고려하여 계산됩니다. MOTA의 수식은 다음과 같습니다:
MOTA = 1 - (FP + FN + IDS) / GT- IDS는 ID 스위치(ID Switches)의 수를 나타냅니다. 동일한 객체에 대해 추적기가 서로 다른 ID를 할당한 경우를 의미합니다.
- GT는 Ground Truth, 즉 실제 객체의 수를 나타냅니다.
IDF1 (ID F1 Score)
- IDF1 점수는 객체의 ID가 시간에 걸쳐 얼마나 일관되게 유지되는지를 측정합니다. IDF1 점수가 높을수록 객체 ID의 일관성이 더 높다는 것을 의미합니다.
- IDF1은 객체 식별의 정확성을 측정하는 지표입니다. 이는 Precision과 Recall의 조화 평균인 F1 점수를 기반으로 합니다. IDF1의 수식은 다음과 같습니다:
IDF1 = 2 * IDTP / (GT + Output)- IDTP는 ID True Positives의 수를 나타냅니다. 이는 추적기가 올바르게 탐지하고 식별한 객체의 수를 의미합니다.
- GT는 Ground Truth, 즉 실제 객체의 수를 나타냅니다.
- Output은 추적기가 탐지한 객체의 수를 나타냅니다.
Training Recipe
- 모델은 SOT에서 COCO, LaSOT, GOT10K, TrackingNet 데이터셋에서 훈련되며,
- MOT에서는 CrowdHuman과 MOT16 데이터셋에서 훈련됩니다.
- 이 모든 데이터셋은 통합 훈련 모드에서 사용됩니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것