기본 개념
- Pseudo labelling:
학습된 모델을 사용하여레이블이 없는 데이터에 대해 예측을 수행하고,- 이 예측값을 마치 실제 레이블인 것처럼 활용하여 모델을 다시 학습시키는 것
- 이 과정에서 생성된 가짜 레이블을 'pseudo label'이라고 함
작동 방식
- 초기 모델 학습: 레이블이 있는 데이터를 사용하여 모델을 훈련
- 가짜 레이블 생성:
- 훈련된 모델을 사용하여 레이블이 없는 데이터에 대한 예측을 수행
- 이 때, 높은 확신을 가지고 예측된 데이터 포인트들에 대해 가짜 레이블을 할당
- 데이터 풀 확장:
- 원래의 레이블이 있는 데이터에 가짜 레이블이 붙은 데이터를 추가
- 재학습:
- 확장된 데이터 세트를 사용하여 모델을 다시 학습
- 이 과정을 반복함으로써 모델은 점차 더 많은 데이터에서 학습할 수 있으며, 이는 일반적으로 성능의 향상으로 이어짐
장점 및 단점
장점
- 데이터 활용 극대화: 레이블이 없는 데이터를 효과적으로 활용하여, 더 많은 데이터에서 학습할 수 있습니다.
- 비용 절감: 추가적인 레이블링 비용 없이 기존의 데이터 자원을 최대한 활용할 수 있습니다.
- 성능 향상: 특히 레이블 데이터가 부족할 때, 모델의 성능을 향상시킬 수 있습니다.
단점
- 오류의 전파:
- 초기 모델의 오류가 pseudo label을 통해 새로운 학습 데이터에 전파될 수 있습니다.
- 이는 잘못된 정보가 모델에 피드백되어 성능 저하로 이어질 수 있습니다.
- 오버피팅 위험:
- 모델이 가짜 레이블의 패턴에 과적합될 수 있어, 실제 레이블이 있는 데이터에서의 성능이 오히려 떨어질 수 있습니다.
소개
기존 pseudo labelling 을 이용한 방법
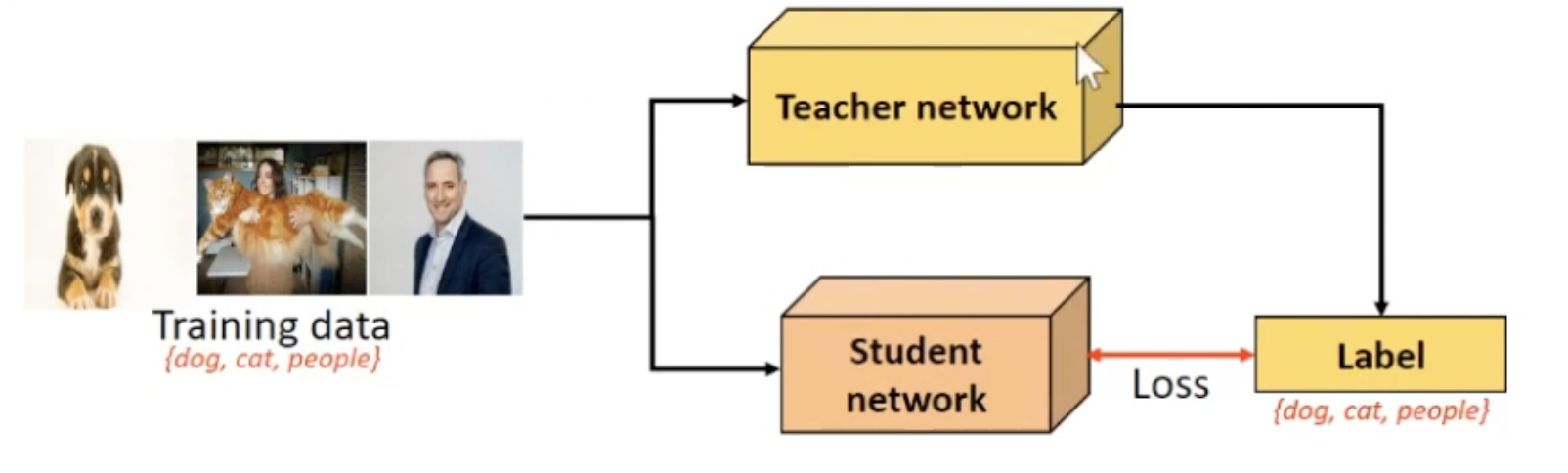
- teacher network
- GT가 있는 데이터셋으로 학습한 네트워크
- student network 학습 과정
- 라벨이 없는 축구장 데이터들을 teacher network를 통과시키고, threshold 이상인 라벨들만 pseudo label로 설정합니다.
- 기존 GT가 있는 데이터셋과, pseudo label dataset을 이용해서, student nework를 학습시킵니다.
- 이때, teacher network의 output을 GT로 간주하고 loss를 게산합니다. (TODO: 확인 필요)
- 한계점
- GT dataset에 있는 라벨 외의 class는 분류하는 능력을 가질 수 없습니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것