들어가기 전에
- "backbone", "neck", "head"는 각각 다른 역할을 수행하며, 함께 동작하여 복잡한 이미지 기반 태스크를 수행하는 데 필수적인 요소
- 이 구조적인 분할은 모델의 모듈성을 높여 다양한 설정과 태스크에 쉽게 적용할 수 있게 만들어 줍니다.
1. Backbone
개념
- Backbone은 모델의 기본적인 특징 추출기(feature extractor)로 기능합
- 입력 이미지로부터 저수준(low-level) 및 고수준(high-level)의 특징을 추출하는 데 사용
- 예를 들어, 이미지 분류, 객체 탐지, 세그멘테이션 등의 태스크에서 이러한 특징들이 중요한 역할
- ViT (Vision Transformer) / Swin Transformer / DETR (Detection Transformer)
역할
- 특징 추출: 입력 이미지로부터 유용한 정보를 추출하여 복잡한 패턴을 인식할 수 있는 특징 맵(feature maps)을 생성
- 다운 샘플링: 효율성과 추상화를 높이기 위해 입력 데이터의 차원을 점진적으로 줄여나감
- 다양한 태스크에 재사용: 같은 backbone 구조가 다양한 모델과 작업에 재사용될 수 있습니다.
- 예를 들어, ResNet, VGG, MobileNet 등이 backbone으로 널리 사용됩니다.
2. Neck
개념
- Neck은 backbone에서 추출된 특징들을 더욱 정제하고, 이를 다양한 down-stream 작업에 더 적합하게 만드는 중간 계층의 구조
Neck은 선택적으로 사용되며, 모델의 성능을 향상시키기 위한 추가적인 특징 통합 및 조정을 목적
역할
- 특징 통합:
다양한 스케일에서 추출된 특징을 효과적으로 통합하여 down-stream 작업에서 더욱 유용하게 만듦 - 특징 재배열: 특징들을 조정하고 재배열하여, 최종 태스크에 더 최적화된 형태로 제공
- 추가적인 처리:
예를 들어, FPN(Feature Pyramid Network)은 여러 스케일의 특징을 조합하여 더욱 정밀한 객체 탐지를 가능하게 함.
3. Head
개념
- Head는 모델의 마지막 부분으로, 구체적인 태스크(예: 분류, 탐지, 세그멘테이션 등)에 직접적으로 적용되는 구조
- 이 부분에서는 최종 출력을 생성하기 위해 특징 맵을 사용
역할
- 태스크별 처리:
각각의 태스크에 맞춰 특징 맵을 처리 - 예를 들어,
- 분류 작업에서는 softmax 활성화 함수를 사용하는 반면,
- 객체 탐지에서는 bounding box의 위치와 클래스를 예측합니다.
- 결과 생성:
- 최종적인 결과를 출력하는 역할을 합니다.
- 예를 들어, 객체 탐지의 경우 각 객체의 위치, 크기, 분류 등의 정보를 포함한 출력을 생성합니다.
1. 본론
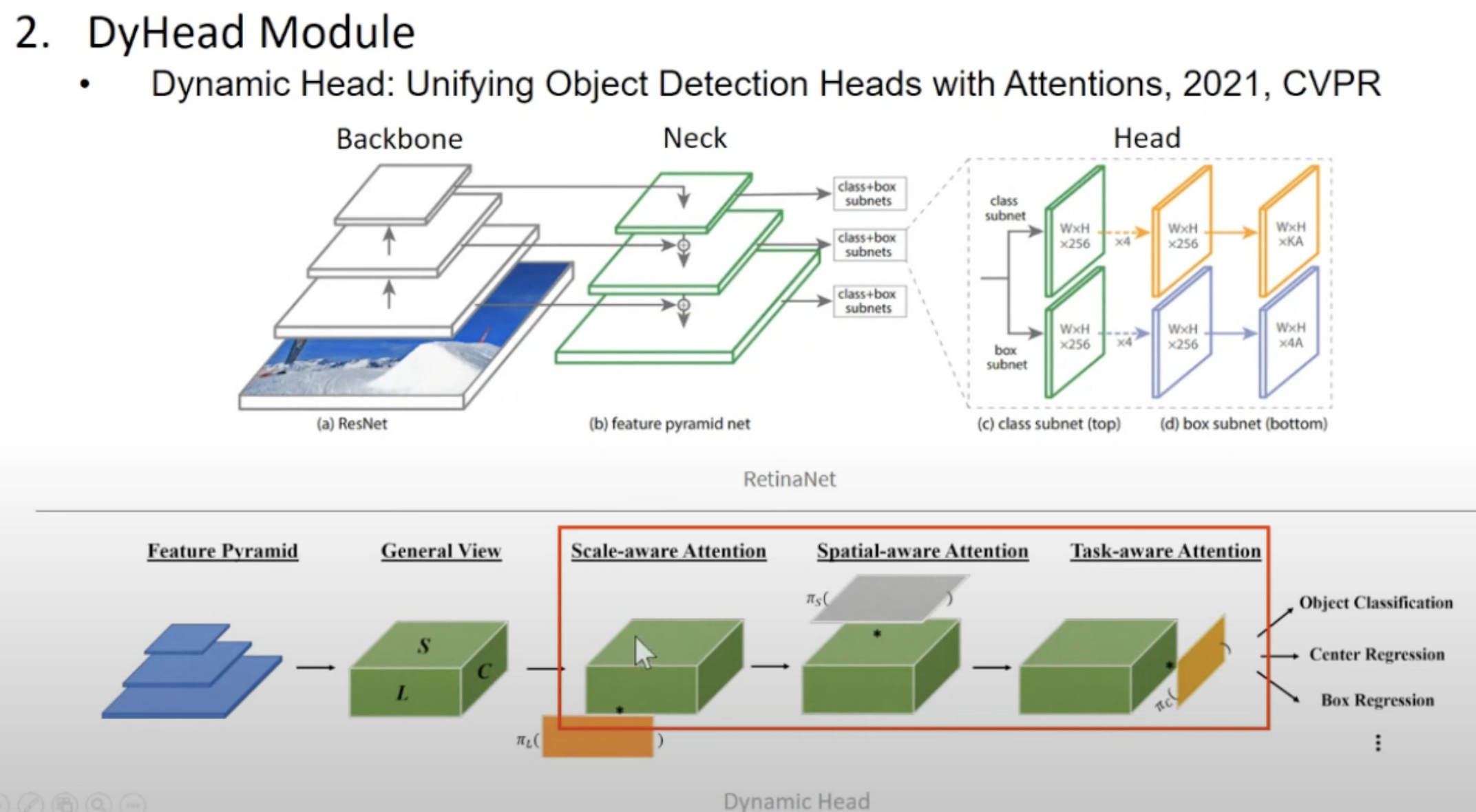
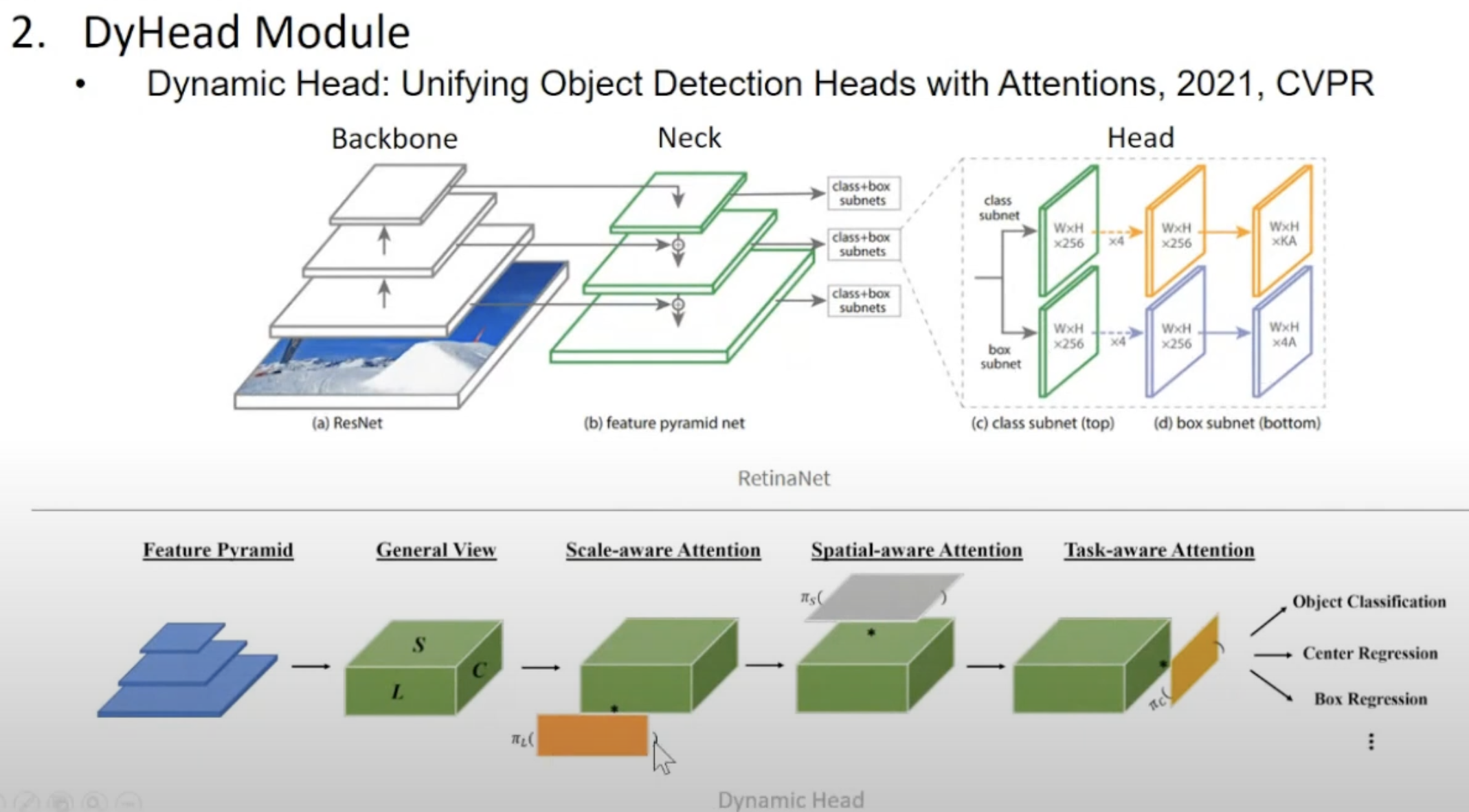
- object detector의 궁극적인 head는,
- 어떤 객체의 크기나 형태나, 수행하고자 하는 task와 관계 없이,
- object에 있는 정보를 잘 추출해낼 수 있어야 함
- 위 박스쳐진 내부 3개 attention을 합쳐서
unified object detection block을 만듦- GLIP 논문에서는
DyHead Module이라고 설명함.
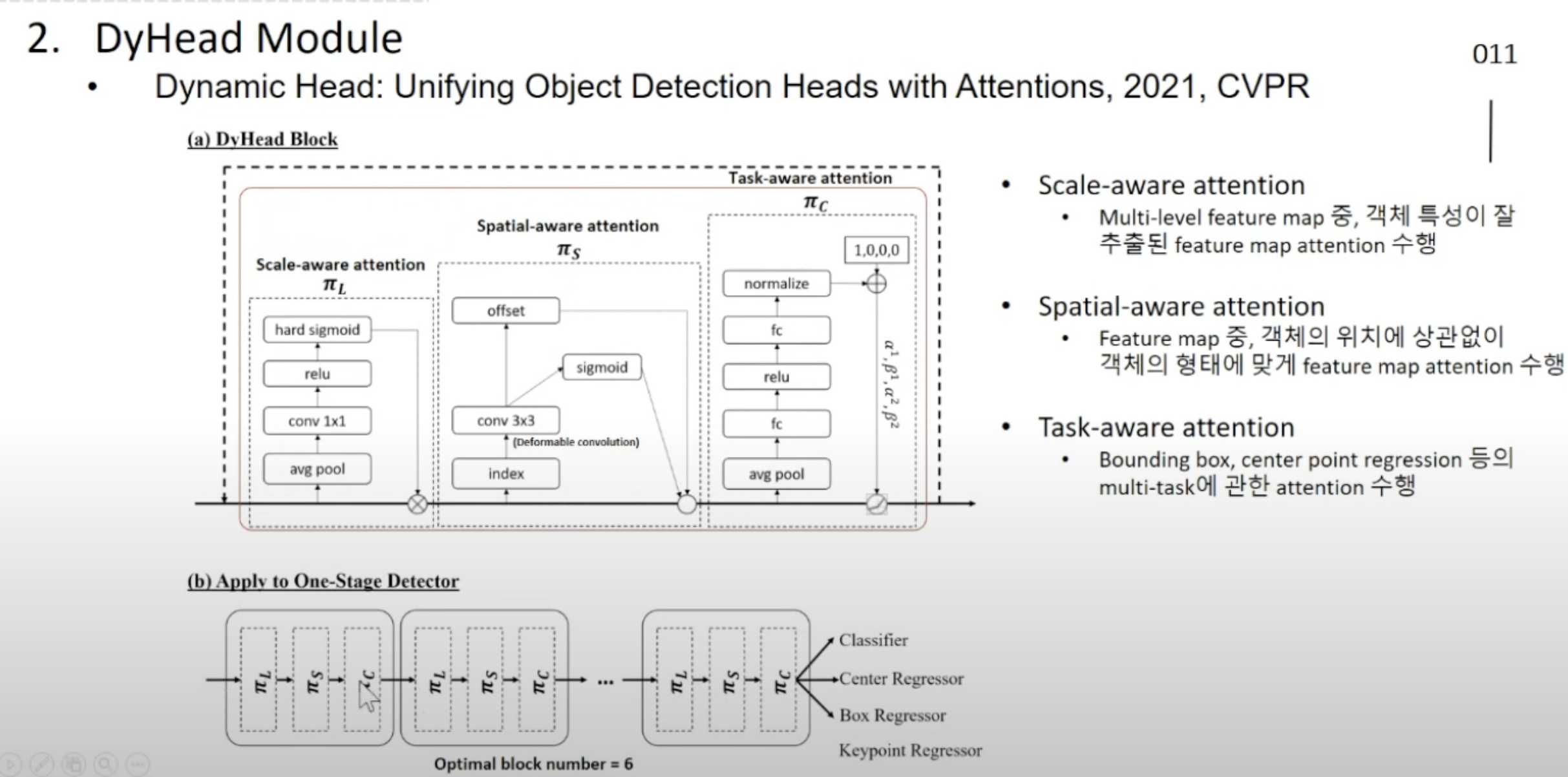
- 입력 벡터와 출력 벡터의 shape이 같음

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것