[2017 CVPR] Feature Pyramid Network for Object Detection
Info
paper: Feature Pyramid Networks for Object Detectionauthor: Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongiesubject: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Abstract
-
Feature pyramids는 다양한 scale에 대해 object를 detecting하는 recognition system의 basic component임.
-
하지만 compute and memory intensive이기 때문에
최근 deep learning object detector들은 pyramid representation을 쓰지 않음. -
이 논문에서는 multi-scale에 좋은 deep conv network의 pyramidal hierarchy를 소개할 것이다.
- A top-down architecture with lateral connection은 모든 scale에 대해
high-level semantic feature maps을 만들 수 있도록 개발되었음.
이 architecture를Feature Pyramid Network (FPN)이라고 부름.
- A top-down architecture with lateral connection은 모든 scale에 대해
1. Introduction
- computer vision에서 매우 다양한 scale의 object를 recognizing하는 것은 기본적인 challenge이다.
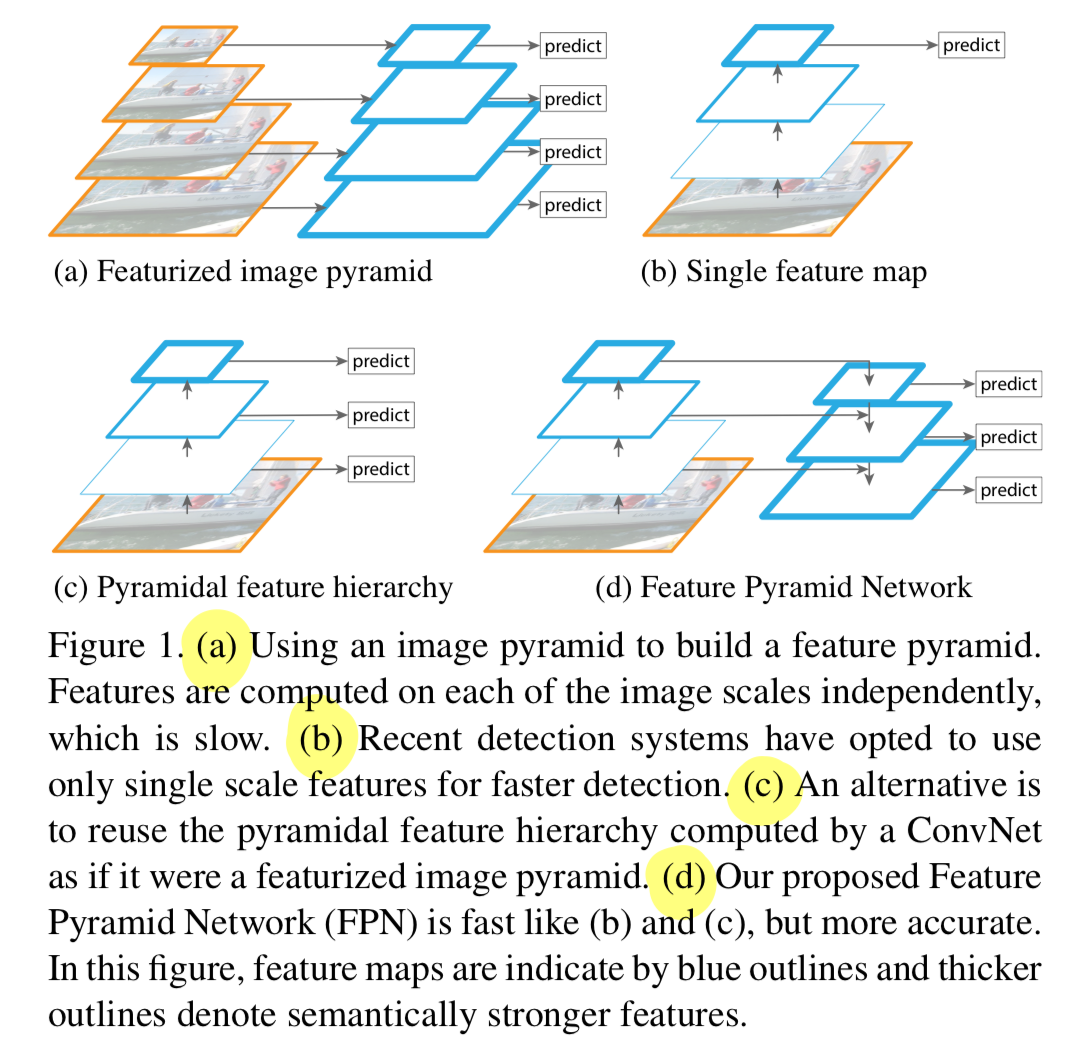
(a):
Feature pyramids built upon image pyramids(=featurized image pyramids)는
object의 scale 변화가 그것의 pyramid 내에서 level을 이동함으로써 보정된다는 의미에서
scale-invariant하다.
featurized image pyramid는 era of hand-engineered features에서 아주 잘 사용되었었는데,
각 image의 scale에서 독립적으로 feature들이 계산되어야 하기 때문에 매우 느리다.
따라서 deep convolutional networks(ConvNets)으로 대체되었다.(b):
Recent detection systems(ConvNets)도 variance에 robust하고,
single input scale에 대해서 recognition을 잘 한다.
하지만, ImageNet과 COCO detection callenges에서는 multi-scale testing을 하기 때문에
아직은 더 accurate results가 필요하다.(c):
featurizing each level of an image pyramid의 주요 이점으로는
all levels에서 semantically strong하다.
그럼에도 불구하고 명백한 단점이 있다.
inference time이 상당히 증가한다는 것이다.
또한 image pyramid를 사용하여 end-to-end로 network를 train시키는 것은
memory 측면에서 infeasible하다.
그래서 이를 활용하는 경우, image pyramid는 inference time에서만 사용된다.
이는 train/test 시간 inference 간의 inconsistency를 만든다.
또한image pyramids는 multi-scale feature representation을 계산하기 위한 방법으로만 사용되지 않는다.
deep ConvNet은 layer마다 feature hierarchy를 계산하고,
subsampling layer로 feature hierarchy에는 내재적인 multi-scale, pyramidal shape이 있다.
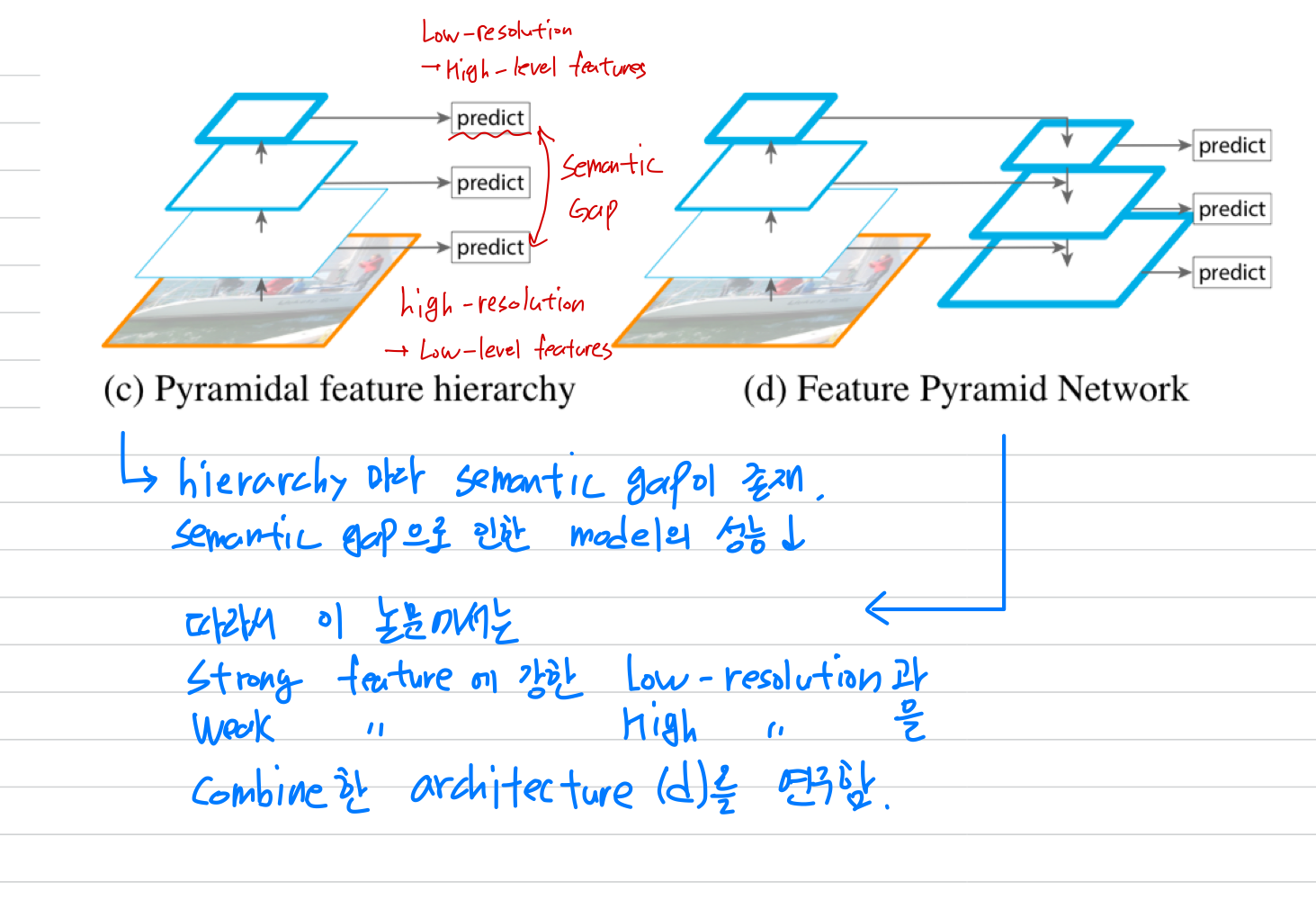
이 network 안의 feature hierarchy는 different spatial resolution의 feature map을 생성하지만,
서로 다른 depth로 인한 큰 semantic(의미적) gap을 만든다.
high-resolution maps는 object recognition을 위한 representational capacity를 손상시키는 low-level feature를 갖고 있음.
(즉, 초기 high-resolution maps을 갖는 초기 conv layer에서 low-level feature가 model의 성능을 해칠 수 있음)
SSD model에서 ConvNet's pyramidal feature hierarchy를 처음으로 사용했음.
SSD는 위에서 말한 high-resolution maps이 low-level feature를 갖고 있어서
model의 성능을 해치는 단점을 극복하기 위해 low-level feature 사용을 하지 않았음.(d):
이 논문의 목표는 pyramidal shape of a ConvNet's feature hierarchy을 자연스럽게 활용하면서,
모든 scale에 strong semantic을 갖도록 하는 feature pyramid를 만드는 것임.
우리는 우리의 method를Feature Pyramid Network(FPN)이라고 부른다.
our pyramid structure는 모든 scale에 대해서 end-to-end train이 가능하고
train/test time에 memory-infeasible하게 지속될 수 있다.
또한 single-scale baseline에 비해 testing time 증가 없이 start-of-the-art를 달성했다.
2. Related Work
Hand-engineered features and early neural networks
- SIFT features, HOG features, ...
Deep ConvNet object detectors
- OverFeat, R-CNN, Fast R-CNN, Faster R-CNN ...
하지만 Multi-scale detection still performs better, especially for small objects.
Methods using multiple layers
-
Several other approahces(HyperNet, ParseNet, ION ....) concatenate features of multiple layers before computing predictions
-
There are recent methods exploiting lateral/skip connections that associate low-level feature maps across resolutions and semantic levels, including U-Net [31] and Sharp- Mask [28] for segmentation, Recombinator networks [17] for face detection, and Stacked Hourglass networks [26] for keypoint estimation.....
- 비록 위 method들은 pyramidal shape을 적용했지만,
prediction이 모든 level에서 독립적으로 이루어지는 featurize된 image pyramid와는 다르다.
실제로, Figure 2(top)의 pyramidal architecture에서는
여전히 여러 scale에서 object를 인식하기 위해 image pyramid가 필요하다.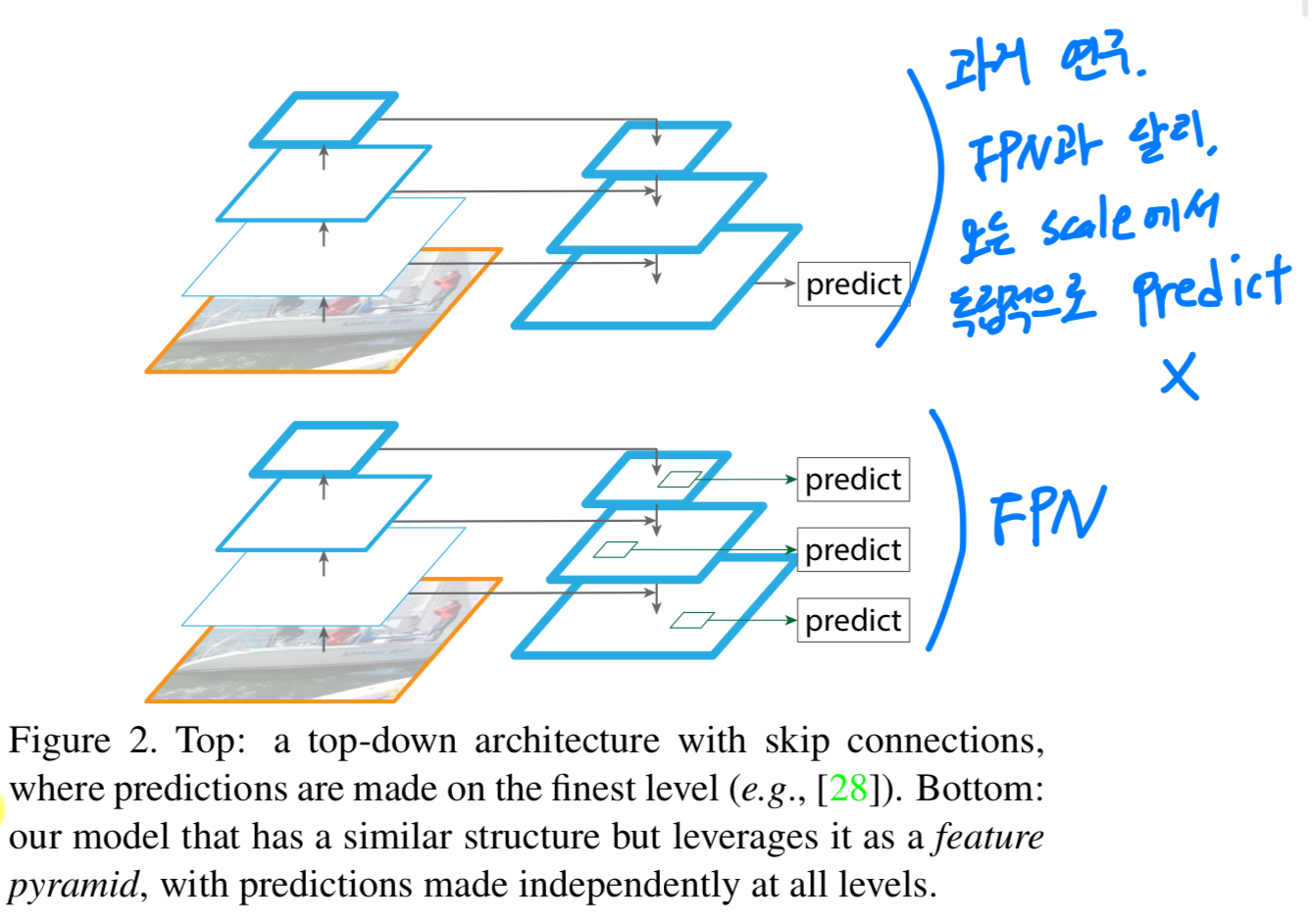
3. Feature Pyramid Networks
-
우리의 목표는 ConvNet의 pyramidal feature hierarchy를 활용하여,
low level부터 high level까지 semantics(의미론적 특징)을 갖추고 있는 feature pyramid를 만드는 것이다. -
우리의 Feature Pyramid Network는 arbitrary(임의의) size의 single-scale image를 convolutional network에 입력하여,
multiple levels에 적절하게 size된 feature maps을 출력하는 network이다. -
이 process는 backbone convolutional architecture에 독립적이다.
그리고 이 논문에서는 ResNet을 사용했다. -
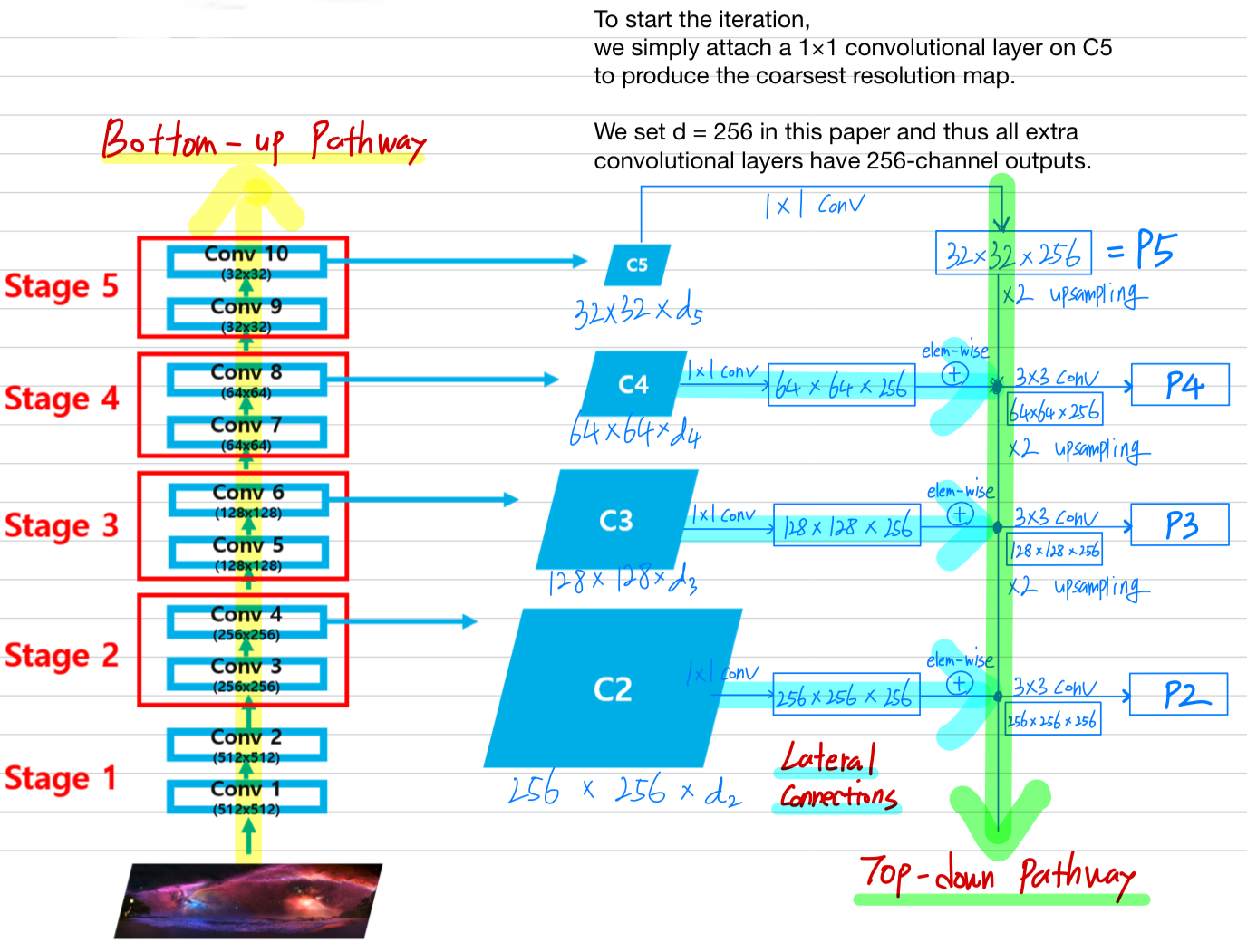
FPN 구조는
bottom-up pathway,top-down pathway,lateral connections로 구성되었다.
Bottom-up pathway
bottom-up pathway는 backbone ConvNet의 feedforward computation이고,
scaling step of 2로 만들어진 몇 가지 scale을 갖는 feature map으로 구성되어 있다.

- There are often many layers producing output maps of the same size
and we say these layers are in the same networkstage. - We choose the output of the last layer of each stage
asour reference set of feature maps, which we will enrich to create our pyramid. - we use
the feature activation output by each stage's last residual block.
We denote the output of these last residual blocks
as {} for conv2, conv3, conv4, conv5,
and note that they have strides of {} pixels with respect to the input image.
- There are often many layers producing output maps of the same size
Top-down pathway and lateral connections
top-down pathway는 공간적으로 coarser(굵다)하지만,
의미적으로 더 강한 feature maps from higher pyramid levels을
upsampling하여 higher resolution features을 만들어낸다.
* simplicity를 위해 nearest neightbor upsampling 방법으로
spatial resolution을 2배로 upsamplling한다.
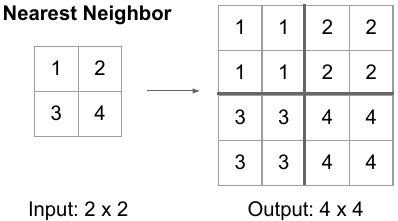
- 그런 다음에,
이 features들은lateral conection으로 인해
bottom-up pathway로부터의 feature가 강화된다.- each lateral connection들은 bottom-up pathway와 top-down pathway로부터
same spatial size의 feature maps을 merge한다. - upsampled map은 channel dimension을 줄이기 위해
1×1 conv layer를 거친 bottom-up map과 element-wise addition을 통해 merge된다. - 이 과정은 finest resolution map이 생성될 때까지 반복된다.
- To start the iteration,
we simply attach a 1 x 1 conv layer on to produce the coarsest resolution map. - Finally, we append a 3 x 3 conv on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling.
- This final set of reature map is called {}
- feature pyramid의 모든 featuer map은 동일한 classifier/regressor를 공유하므로,
모든 Feature map의 dimension 으로 세팅.

- To start the iteration,
- each lateral connection들은 bottom-up pathway와 top-down pathway로부터
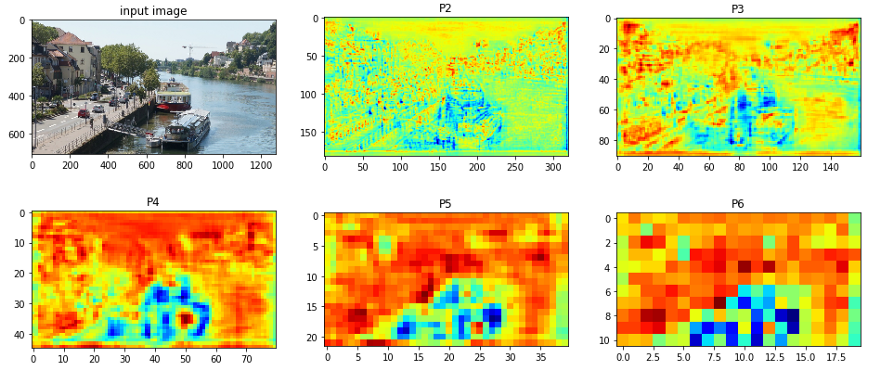
- 위의 과정을 통해 FPN은 single-scale image를 입력하여 4개의 서로 다른 scale을 가진 feature map을 얻을 수 있다.
(사진 출처 : https://herbwood.tistory.com/18)