[2020 ECCV] (DETR) End-to-End Object Detection with Transformers
[Paper Review] 2D Object Detection
목록 보기
12/21
Paper Info.

이 논문의 핵심 내용
Abstract
-
이 논문은 처음으로 object detection을 a direct set prediction problem으로 바라보는 방법을 제안한다.
저자들의 approach는 "effectively removing the need for many hand-designed components like a NMS suppression procedure or anchor generation" -
제안하는 framework를 DEtection TRansformer (DETR)이라고 부른다.
DETR의 핵심 ingrdients는 "a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture."이다.
문제 제기
- object detection의 목표는 원래 "to predict a set of bounding boxes and category labels for each object of interest"인데...
Modern detector들은 this set prediction task를 an indirect way로 다루고 있었다.
예를 들어, a large set of proposals, anchors, or window centers를 정의함으로써 indirect way로 다루고 있었음
제안
- 그래서 "we propose a direct set prediction approach ... "
- object detection을 direct set prediction problem으로 바라봄으로써 training pipeline을 간소화함.
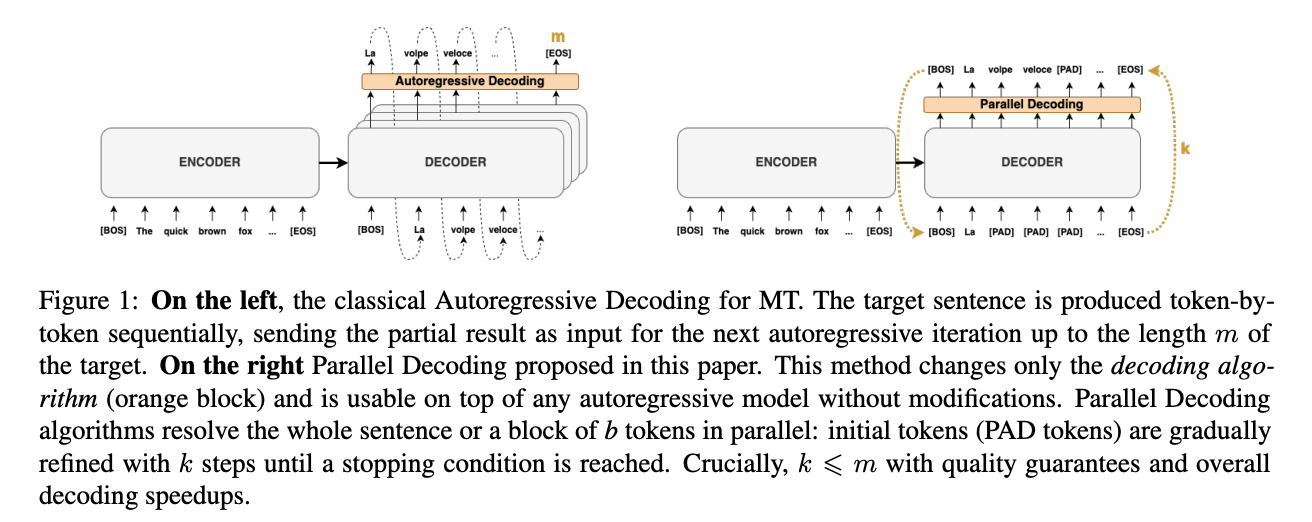
그러기 위해, "We adopt an encoder-deecodere architecture based on transformers"
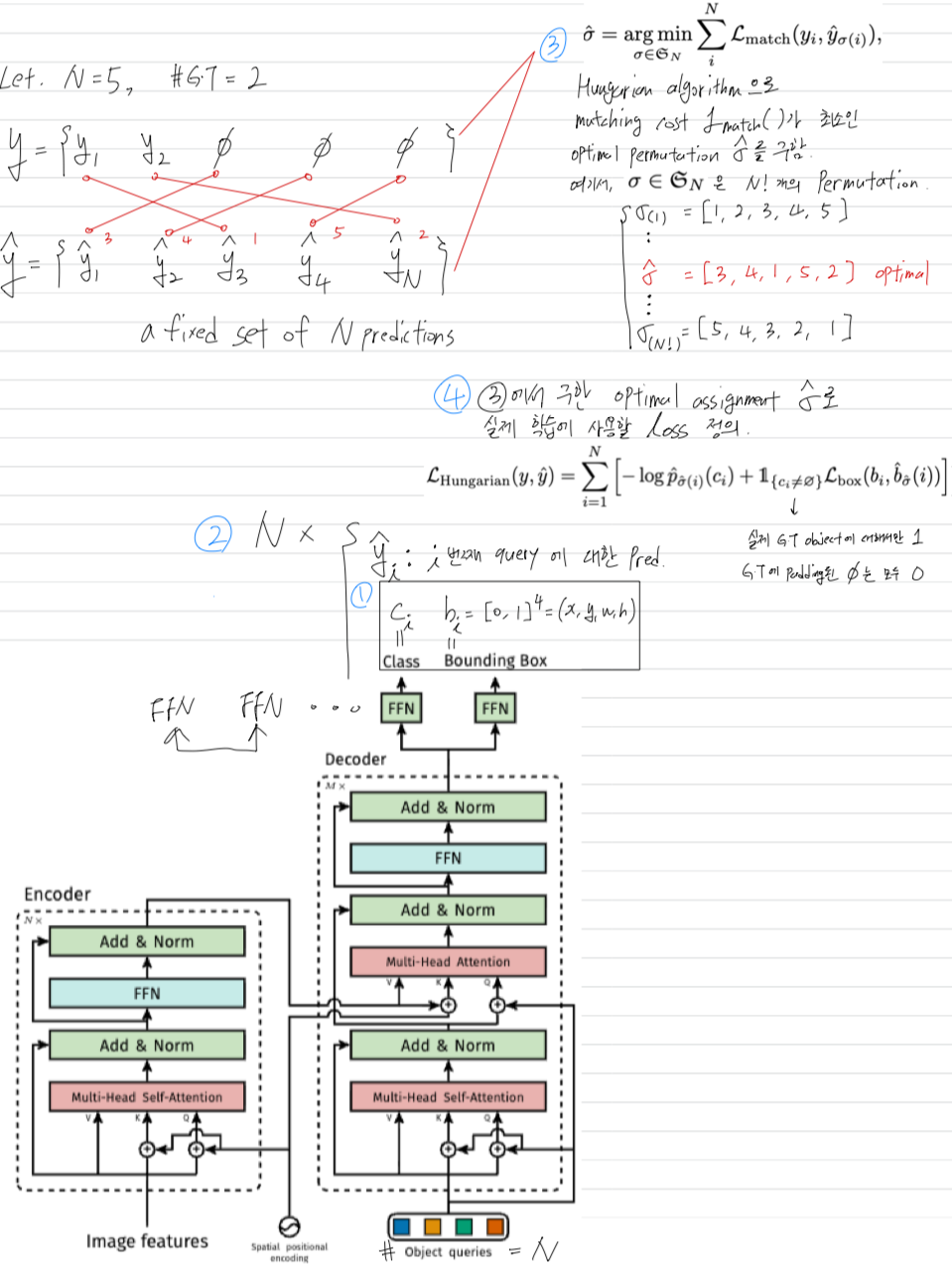
- 현대 detector들은 near-duplicates를 없애기 위해 NMS과 같은 postprocessing을 했지만,
우리가 하려는 것은 direct set prediction은 postprocessing이 제거되어야 한다.
그런데, sets을 directly predict하는 정석적인 deep learning model은 존재하지 않음.
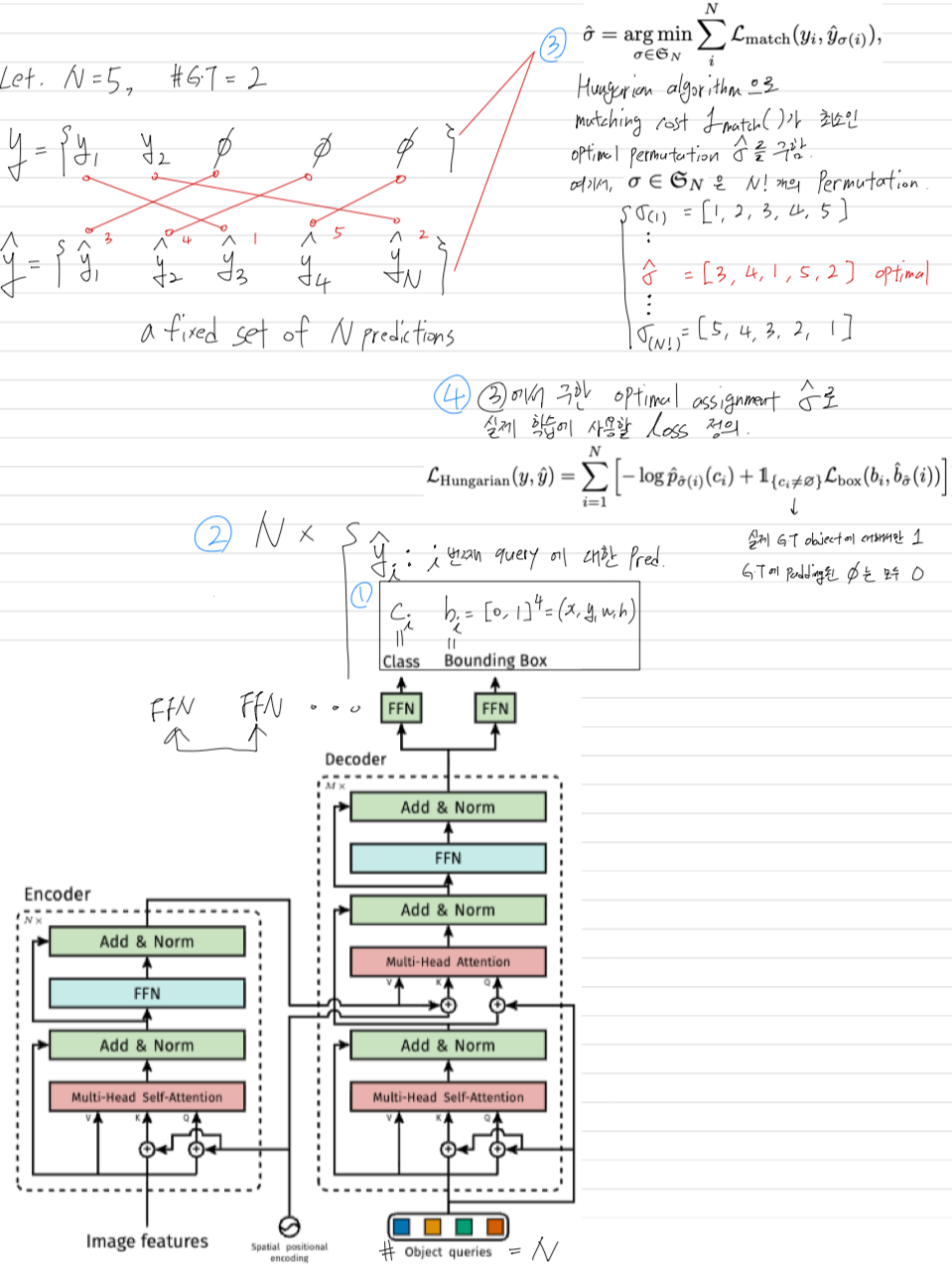
이를 위한 usual solution은 "The usual solution is to design a loss based on the Hungarian algorithm [20], to find a bipartite matching between ground-truth and prediction.
This enforces permutation-invariance, and guarantees that each target element has a unique match.
We follow the bipartite matching loss approach.
In contrast to most prior work however, we step away from autoregressive models and use transformers with parallel decoding, which we describe below."
(hungarian algorithm으로 prediction과 GT를 1:1=bipartite matching을 하여 한 쌍을 만듦.
prediction의 순서가 바껴도 똑같은 optimal 1:1=bipartite matching을 구할 수 있기 때문에 permutation-invariance함.
그리고 autoregressive model과 달리, transformers with parallel decoding을 활용함.)
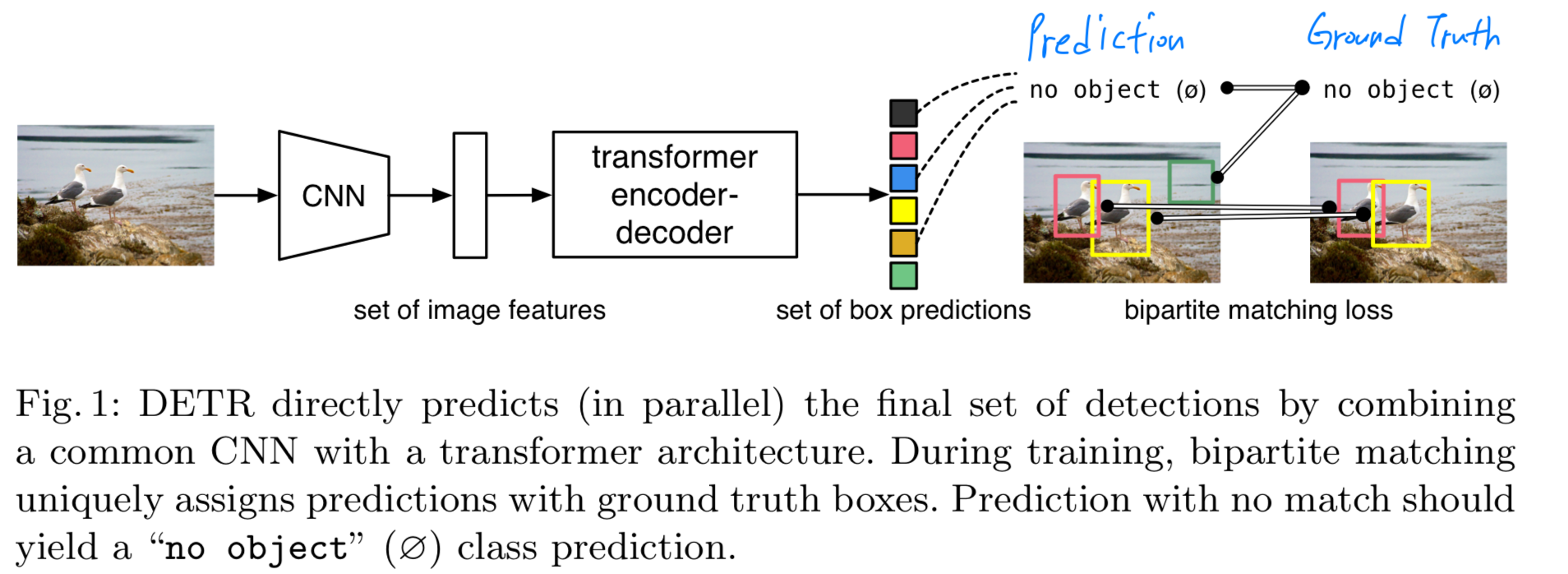
autoregressive X, parallel O decoding?
- 왜 autoregressive X parallel decoding O ?
(above figure is referened by https://arxiv.org/pdf/2305.10427)- objecet detection을 set prediction으로 봤지, sequence generation으로 본게 아니라 autoregressive에 제약을 둘 이유가 없음.
- autoregressive decoding은 단계가 필요 (은 object query 개수).
즉, inference cost가 높음.
Parallel decoding은 한 번에 모든 query를 decoder에 넣어 동시 예측하므로 - autoregressive decoding 방식은 순서를 강제하기 때문에 permutation invariance를 보장하지 못함.
DETR은 Hungarian matching을 이용해서 prediction set과 GT set을 1:1 matching하기 때문에, 순서를 강제할 필요 없이 set prediction이 가능.
set prediction loss
- DETR은 decodr를 통해 한 번의 single pass 동안, a fixed-set of predictions을 inference함.
(여기서 은 한 image에서 일반적으로 가지는 objects의 개수보다 큰 값으로 함.
그래야 1:1=bipartite matching이 가능하기 때문)

Efficient Deep Learning