[중단] [2020 ECCV] Feature Pyramid Transformer
Paper Info.

Abstract
(배경)
- space and scales 전반에 걸친 Feature interactions은 beneficial visual context를 제공하기 때문에 modern visual recognition systems을 돕는다.
전통적으로, spatial contexts는 CNN의 receptive field가 커지면서 수동적으로 내포되거나, non-local convolution을 통해 능동적으로 encoding되어 왔다.
(문제)
- 그러나 기존의 non-local spatial interactions은 scales 간 상호작용을 고려하지 않기 때문에,
서로 다른 scale에 위치한 non-local contexts of objects를 capture하지 못한다.
(제안)
-
이를 해결하기 위해, 우리는 both space and scales에 대해서 fully active feature inteaction을 하는, Feature Pyramid Transformer (FPT)를 제안한다.
FPT는 any feature pyramid를 same size를 갖지만 richer contexts를 갖는 another feature pyramid로 transform된다.
이 과정은 다음 세 가지 방식의 transformer로 구성된다:- self-level interaction
- top-down interaction
- bottom-up interaction
-
FPT는 a generic visual backbone으로 사용할 수 있으며, computational overhead도 적절한 수준으로 유지된다.
(실험)
- 우리는 FPT를 object detection, instance segmentation, pixel-level segmentation에
다양한 backbone and head networks에 적용해 실험을 진행하였고,
모든 baseline 및 SOTA methods 대비 consistent improvement를 확인하였다.
1. Introduction
(background)
-
modern visual recognition systems는 context에 기반한다.
Fig. 1 (a)에 있는 CNN의 hierarchical structure 때문에 pooling, stride, or dilated convolution을 함으로써
contexts는 점진적으로 larger receptive fields (초록 점선 사각형)에 encoded된다.
따라서 the prediction from the last feature map은 본질적으로 the rich contexts에 기반한다 -
예를 들어, small object (예: mouse)에 대해 단 하나의 "feature pixel"만 존재하더라도, larger contexts (예: table and computer)를 인식하기 때문에 여전히 인식이 가능하다. (?)
(동의할 수 없음. raw image의 mouse는 가장 마지막 layer에서 뭉개지면서 recognition이 어려울 것 같음.)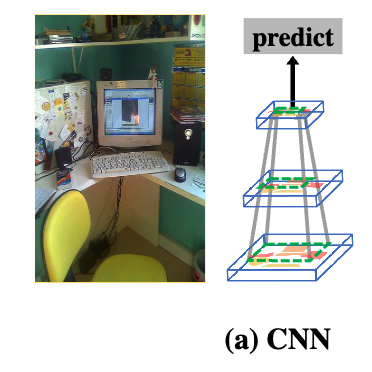
-
Scale도 중요하다 - mouse를 인식하려면 the last feature map으로부터 단 하나의 feature pixel이 아니라, 더 많은 feature pixels이 필요하다.
하지만 the last feature map은 small objects를 쉽게 놓칠 수 있다.
전통적인 solution은 the same image에 대해 image pyramid를 쌓는 것이다.
여기서 higher/lower levels은 각각 lower/higher resolutions의 imges를 의미한다.
이 방식은 서로 다른 크기의 objects를 해당 levels에서 인식하도록 한다.
예를 들어, mouse는 lower levels (high resolution)에서, table은 higher levels (low resolution)에서 인식된다.
그러나 image pyramid는 각 resolution마다 time-consuming CNN forward pass가 필요하므로 연산 비용이 많이 든다.
다행히도, CNN은 network 내에서 자체적으로 feature pyramid를 제공한다.
즉, lower/higher-level feature map은 각각 high/lower resolution visual content without computational overhead를 나타낸다.
Fig. 1 (b)에서 보듯이, 우리는 서로 다른 level의 feature map을 활용하여 다양한 크기의 objects를 인식할 수 있다.
예를 들어, small objects (computer)는 lower-levels에서, large objects (chair and desk)는 higher-levels에서 인식된다.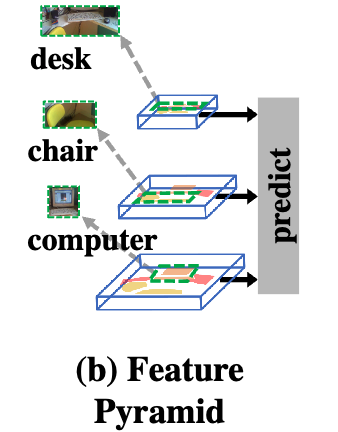
- semantic segmentation과 같이 pixel-level labeling을 위한 recognition은 특히 multiple scales로부터 contexts를 combine하는 것이 필요하다
Fig. 1 (c)에서 예를 들어, monitor가 있는 frame area의 pixels을 labels하기 위해서는, lower levels에서 얻은 local context만으로도 충분할 수 있다.
그러나 screen area의 pixels을 정확히 분류하려면 local context과 함께 higher levels의 global context도 활용해야 한다.
그 이유는, monitor screen의 외형이 TV screen과 유사하기 때문에, 이를 구별하려면 keyboard나 mouse와 같은 주변 장치가 포함된 장면 (context) 정보를 활용해야 하기 때문이다.
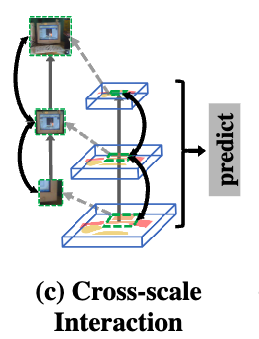
- 이러한 non-local context에 대한 접근은, 단순히 여러 계층의 feature map을 수동적으로 쌓는 방식이 아닌,
최근에는 이를 보다 명시적이고 능동적인 방식으로 modeling하는 방법이 제안되고 있다.
예를 들어, non-local convolution이나 self-attention이 대표적이다.
이러한 spatial feature interaction은, 여러 object가 co-occurring (공존하는) patterns을 상호적으로 학습하는 데 도움이 된다.
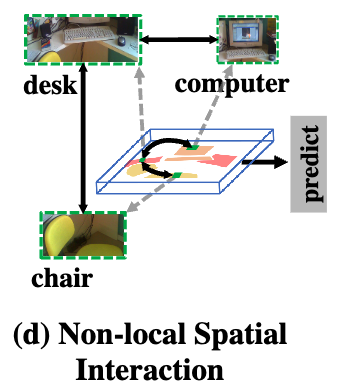
Fig. 1 (d)에서 볼 수 있듯이, desk 위에는 computer가 있을 가능성이 높고, road 위에는 computer가 있을 가능성이 낮기 때문에,
한 object의 인식이 다른 object의 인식에도 도움이 되는 식으로 상호 보완적인 관계가 형성된다.
(motivation)
- context와 scale에 대한 이야기는 계속되며, 우리의 key motivation이다.
특히, 우리는 Fig. 1 (d)에서의 non-local spatial interactions에서는 Fig. 1 (c)에 나타난 cross-scale interaction이 생략되어 있다는 점에 주목했다.
또한, 우리는 non-local interaction 자체는 상호작용하는 objects (또는 parts)가 존재하는 대응되는 scale에서 이루어져야 하며,
기존 방법들처럼 단일하고 균일한 scale에서만 일어나는 것은 바람직하지 않다고 생각한다.
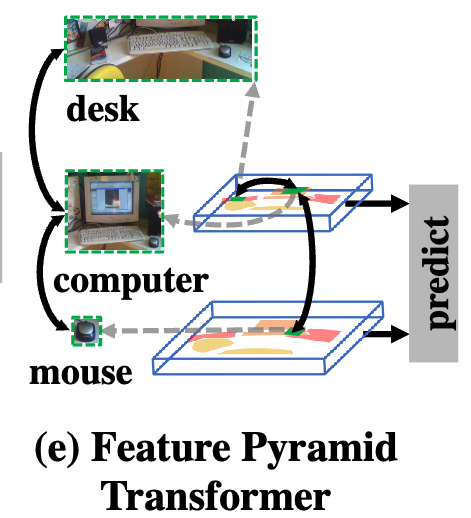
Fig. 1 (e)는 이러한 scale 간의 expected non-local interactions을 보여준다:
low-level의 mouse는 high-level의 computer와 상호작용하고, 이 computer는 같은 scale의 desk와 다시 상호작용한다.
(제안)
- 이를 위해 우리는 Feature Pyramid Transformer (FPT)라는 새로운 FPN을 제안한다.
FPT는 instance-level (i.e., object detection and instance segmentation)과 pixel-level segmentation tasks에 사용된다.
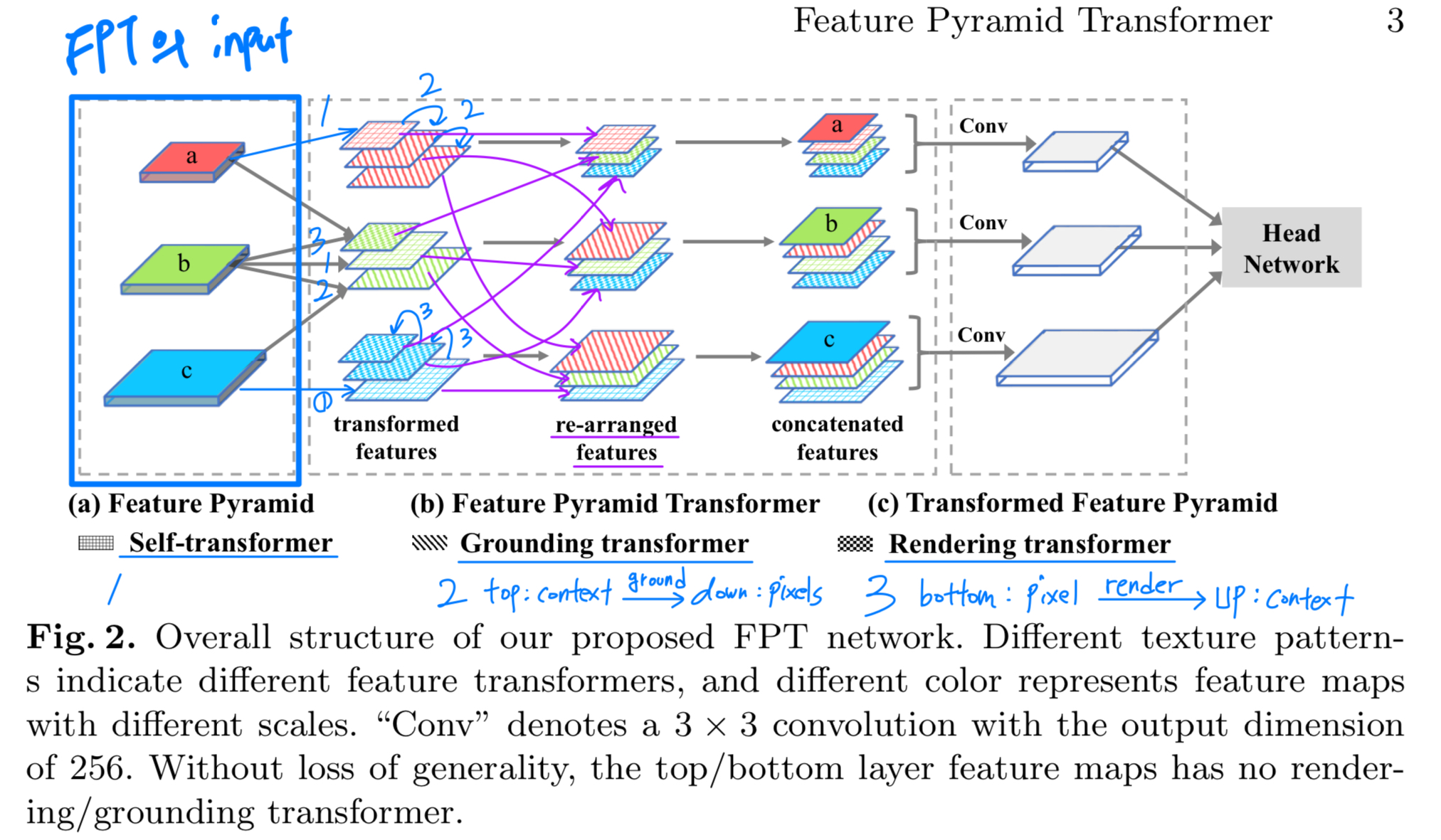
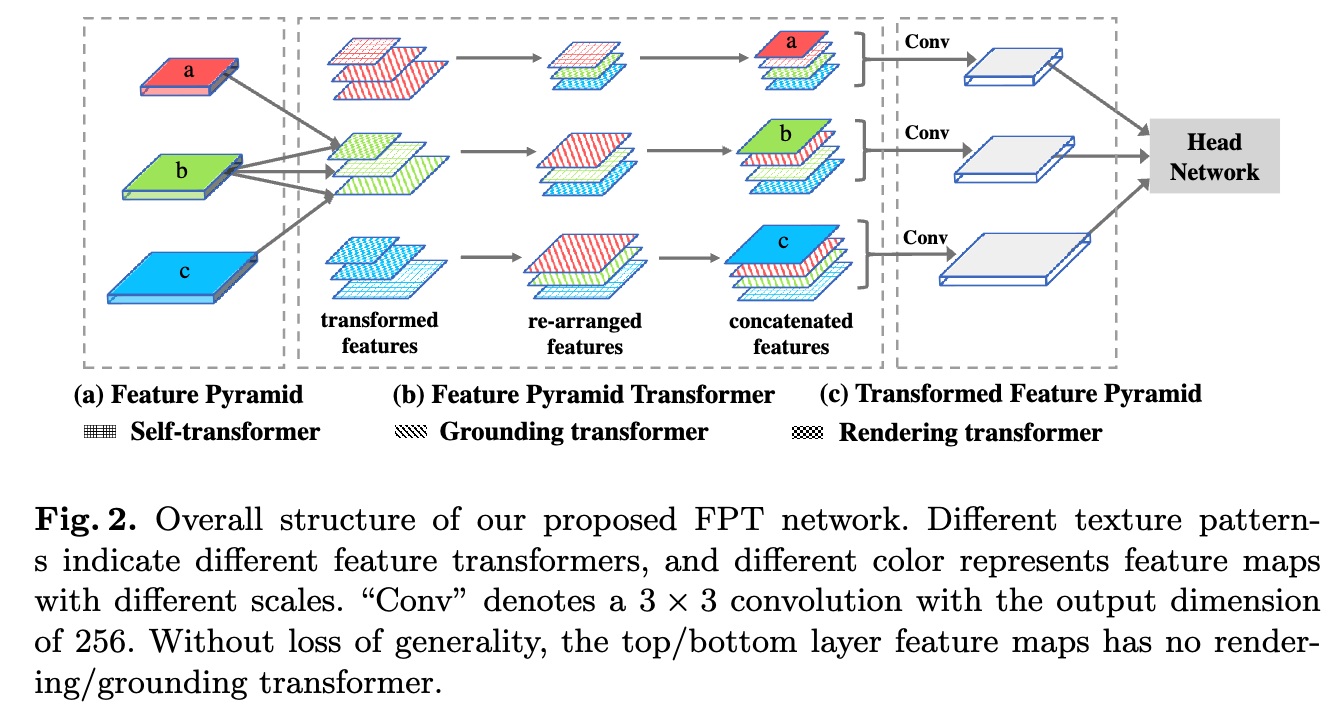
간단히 말해, Fig. 2에 나타난 것처럼 FPT의 입력은 기존의 FPN이며, 출력은 변형된 feature pyramid이다.
여기서 각 pyramid level은 spatial 및 scale 전반에 걸친 non-local interactions을 encoding한 a richer feature map으로 구성된다.
이러한 feature pyramid는 이후 any task-specific head network에도 연결될 수 있다.
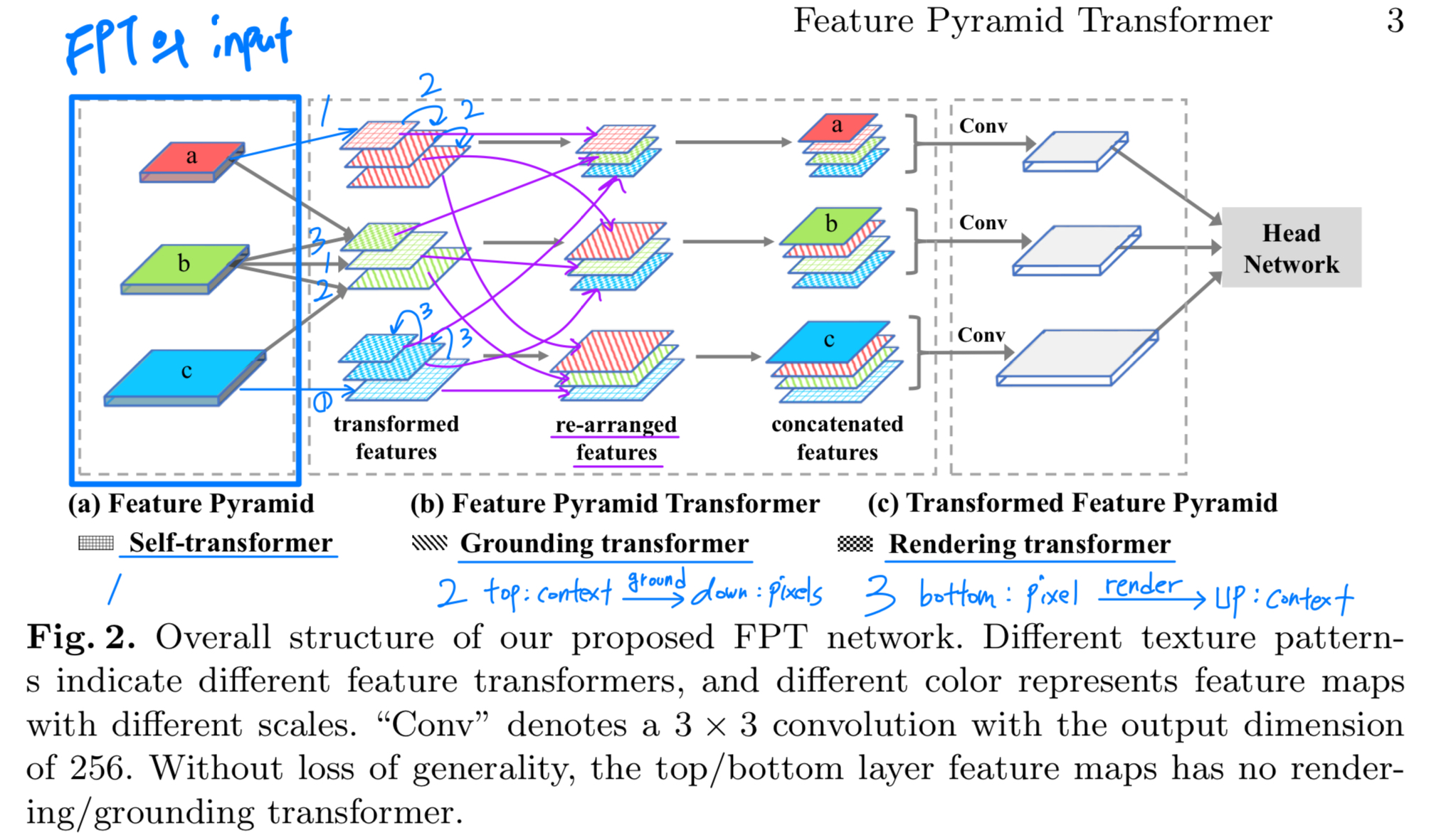
(처음에 Fig. 2. 이해를 하나도 못 하겠어서, 내가 보충해서 그림... 다음에 보면 또 이해 못 할까봐)
(왜 처음에 이해가 어려웠나?)
(1. 우선 a와 (a)는 다른 거임. a는 feature map이고, (a)는 FPT의 입력인 Feature Pyramid임. 즉, backbone의 output이라 생각하면 됨)
(2. (a) Feature Pyramid와 Self-transformer가 위아래로 딱 붙어있지만 서로 하나도 연관되지 않은 독립적인 notation임.)
-
이름에서 알 수 있듯이, FPT의 interaction은 transformer-style을 채택한다.
즉, 효과적인 informative long-range interaction을 위한 qeury, key, value 연산을 수행하며, (Section 3.1)
이는 우리가 추구하는 적절한 scales에서의 non-local interaction 목표에 부합한다.
또한, 다른 transformer models들과 마찬가지로 TPU를 사용하여 computation overhead를 완화할 수 있다. (Section 4.1) -
Our technical contributions은 Fig. 2에 FPT breakdown으로 그려져있다,
FPT는 three transformers로 설계되었다:
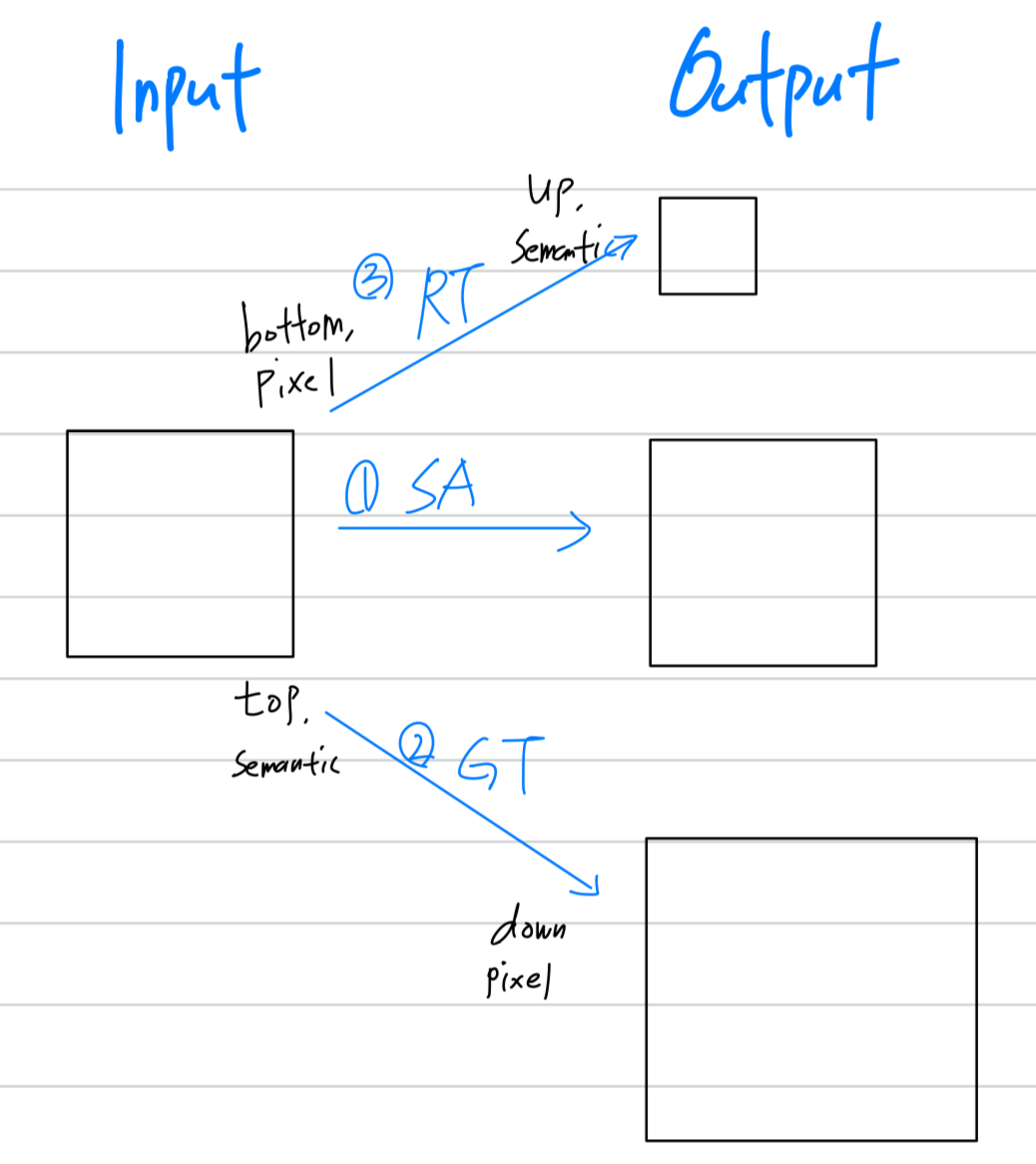
Self-Transformer (ST)
ST는 same level feature map 내에서의 the classic non-local interaction을 기반으로 하며,
output은 input과 same scale을 갖는다.Grounding Transformer (GT)
GT는 top-down 방식으로 동작하며, output은 lower-level feature map과 동일한 scale을 갖는다.
직관적으로, the "concept" of the higher-level feature maps을 the "pixels" of the lower-level feature maps에 연결 (grounding)하는 역할이다.
특히, objects를 segment하기 위해 global information을 반드시 필요하지 않으며, local region 내의 context가 경험적으로 더 유용하다는 점을 바탕으로,
locality-constrained GT를 설계하여 efficiency and accuracy를 둘 다 향상시켰다.Rendering Transforemr (RT)
bottom-up 방식으로 동작하며, output은 higher-level feature map과 동일한 scale을 갖는다.
직관적으로, lower-level "pixels"의 visual attributes를 higher-level "concept"에 rendering하는 과정이다.
이 과정은 local interaction으로, 멀리 떨어진 object의 pixel로 다른 object를 rendering하는 것은 의미가 없기 때문이다.
2. Related Work
- FPT는 다양한 범위의 CV tasks에 적용될 수 있다.
이 연구에서는 two instance-level tasks: object detection, instance segmentation,
one pixel-level task: semantic segmentation
에 집중한다.
Feature pyramid
- feature pyramid (Bottom-up Feature Pyramid (BFP))는 흔하게 사용된다.
또 다른 feature pyramid 생성 방법은 pyramidal pooling or dilated/atrous convolutions을 사용한다.
Our approach는 BFP에 기반한다.
Feature interaction
-
cross-scale feature interaction에 대한 intuitive approach는 FPN과 PANet처럼 점진적으로 multi-scale feature maps을 합치는 것이다.
구체적으로, FPN과 PANet은 모두 BFP을 기반으로 한다.
FPN은 top-down path를 추가하여 semantic information을 low-level feature map으로 전달하고,
PANet은 FPN을 기반으로 bottom-up path를 추가하여 이를 확장했다. -
특히, within-scale의 feature interaction을 위해 일부 최근 연구에서는 non-local operation과 self-attention을 활용하여
동일 장면 내에서 함께 등장하는 object (co-occuruent object) features를 capture하고자 했다.
하지만 우리는 just one uniform scale의 feature map에서 수행되는 non-local interaction만으로는 context를 충분히 표현할 수 없다고 주장한다.
따라서 본 연구에서는, non-local interaction 자체를 interaction하는 object의 해당 scales에서 수행하는 것을 목표로 한다. (?)
3. Feature Pyramid Transformer
-
input image가 주어지면, 우리는 feature pyramid를 extract한다.
feature pyramid는 low/high levels에 각각 fine-/coarse-grained feature maps이 있다.
우리는 low-level fine-grained feature map을 라 하고
high-level coarse-grained feature map을 라 한다. -
Feature Pyramid Transformer (FPT)는 feature들이 space 및 scales를 전반적으로 interact할 수 있게 한다.
FPT는 구체적으로 세 가지 transformers로 구성된다: self-transformer, grounding transformer, and rendering transformer.
transformed feature pyramid는 original feature pyramid와 same size를 갖지만 richer contexts를 포함한다.
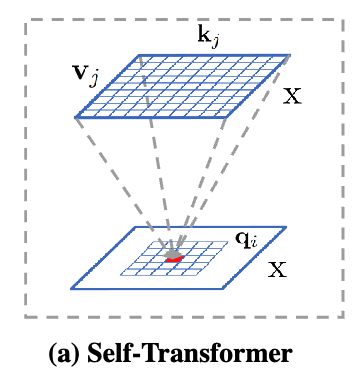
3.1 Non-Local Interaction Revisited
- 전형적인 non-local interaction은 a single feature map 에 대해서
queries(Q), keys(K), and values(V)로 계산된다.
output은 transformed version 이고, 와 same scale이다.
이 non-local interaction은 다음과 같이 정의된다:
(흔히 아는 self-attention 과정을 정의한 것임.)

3.2. Self-Transformer
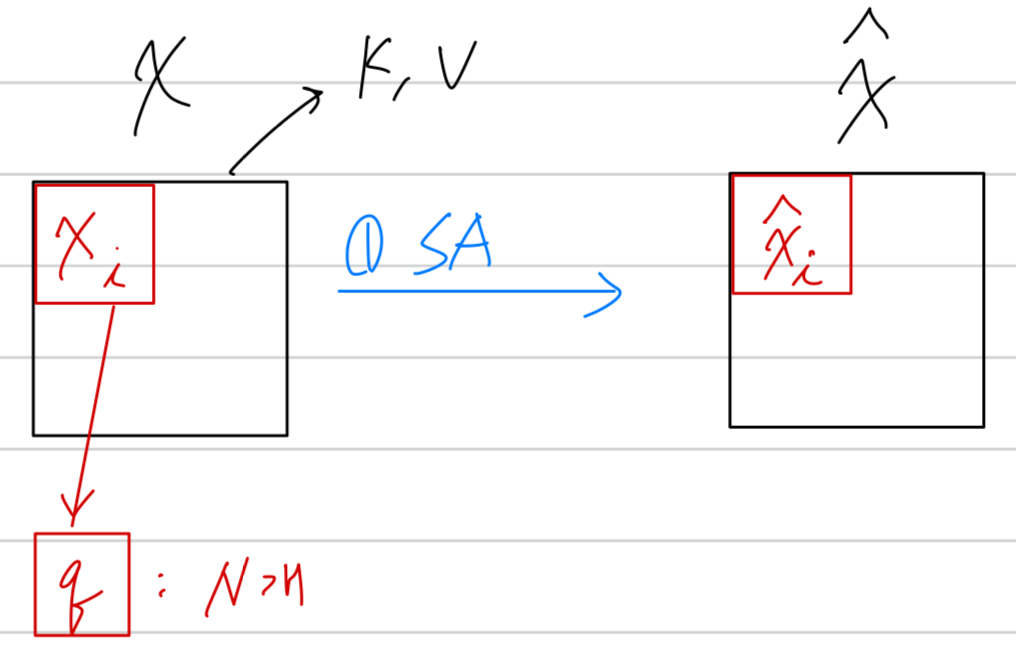
- Self-Transformer (ST)는 one feature map에 대해서 the co-occurring object features를 capture하는 것을 목표로 한다.
Fig. 3 (a)에 그려진 것처럼, ST는 하나의 수정된 non-local interaction이며, output feature map 는 its input 와 same size를 갖는다.
(그림을 잘못 그렸나... 왜 가 안보이지?, 그림 이해가 아예 안됨..)
- 한 가지 주요 차이점은 normalizing function을 라는 the Mixture of Softmaxes (MoS)를 사용했다는 것이다.
는 the standard Softmax ()보다 더 효과적이라고 밝혀졌다.
구체적으로, 우리는 와 를 개의 parts로 divide한다.
그리고나서, 우리는 을 이용하여 모든 pair (예: , )에 대해서 similarity score 를 계산한다.
MoS-based normalizing function 는 다음을 따른다:

3.3. Grounding Transformer
-
[Critique, 중단 이유] section의 이유로 논문 리뷰를 중단하고,
얻어갈 수 있는 Intuition만 짧게 작성하겠다. -
"Moreover, it has been empirically shown that the negative value of the euclidean distance is more effective in computing the similarity than dot product when the semantic information of two feature maps is different [42]."
3.4. Rendering Transformer
3.5. Overall Architecture
4. Experiments
Critique, 중단 이유
-
figure 2 정말 못 그렸다고 생각함.
- a와 (a)가 같은 것인줄 알았음. 이건 내가 잘 못 이해한걸 수도 있는데, 왜 굳이 a와 (a)로 했을까?
a가 high-level feature니까 h로 해서, h와 (a)로 했으면 덜 헷갈리지 않았을까? - SA(within), GT(top-down), RT(bottom-up) 연산이 다 다르고 입력과 출력의 scale이 다른데, 왜 빗금으로 대체해서 끝냈을까? 너무 불친절한 시각적 설명이다.
- (a)에서의 a와 (c)에서의 a는 똑같은 a인데 그림이 다름. 구체적으로, (a)의 a는 3차원이고 (c)의 a는 2차원임...
- a와 (a)가 같은 것인줄 알았음. 이건 내가 잘 못 이해한걸 수도 있는데, 왜 굳이 a와 (a)로 했을까?
-
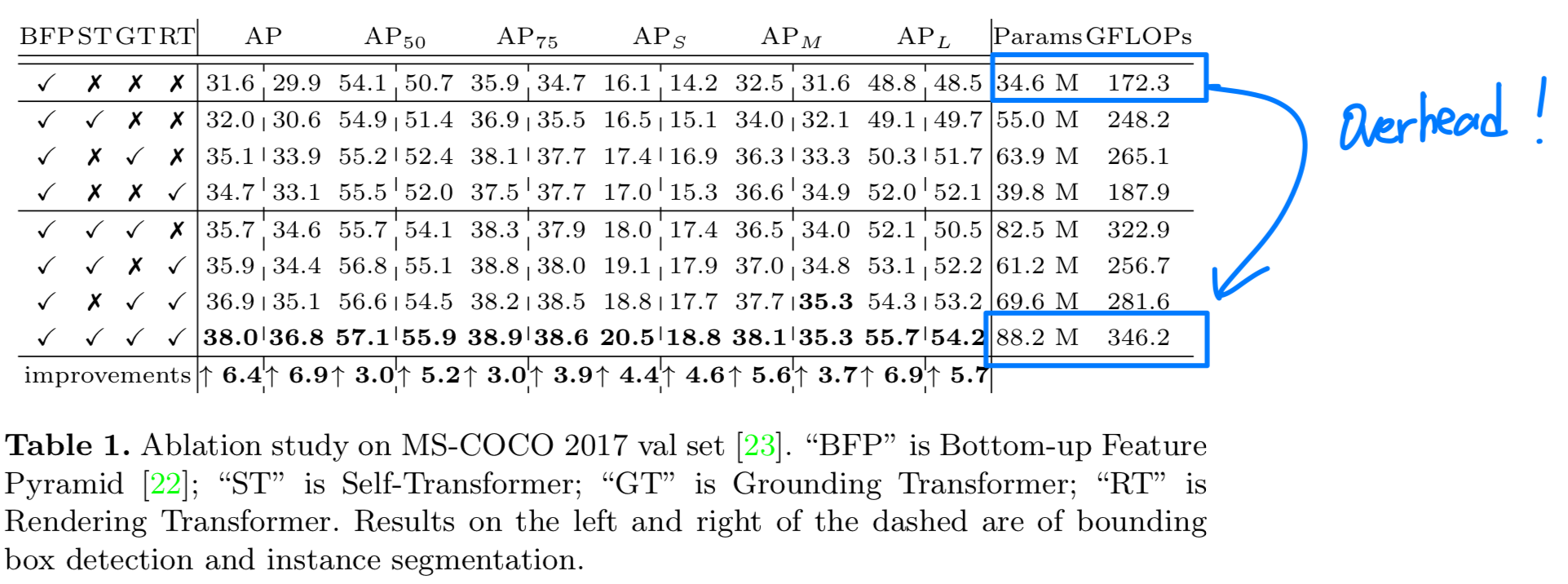
3개의 attention 연산으로 이루어졌는데(Self-Transformer, Grounding Transformer, Rendering Transformer),
당연히 Parameter와 GFLOPs가 2~3배 늘어남.
object detection과 segmentation은 application에 사용될 model들이라 경량화도 중요한 요소인데 이를 아예 무시해버림.
Introduction에서 TPU 언급을 딱 한 번 하긴 하는데, 얼만큼의 accelerating 되는지? 등 실험에서 구체적인 수치와 분석이 아예 없음.
