[2021 IEEE Access] Adaptive Feature Pyramid Networks for Object Detection
Paper Info.
https://ieeexplore.ieee.org/document/9497077

Abstract
(문제점)
-
Ghiasi et al.에 의해 제안된 feature pyramid network는 a simple fusion method를 채택했고, 이는 the fusion feature context를 고려하지 않아 실패했다.
게다가, tranditional upsampling을 통한 the fusion of multi-scale features directly는 feature misalignment and loss of details하는 경향이 있다. -
이 논문에서는,
앞서 말한 potential problems을 완화할 수 있는 feature pyramid network 기반의
an adaptive feature pyramid network를 제안한다
an adaptive feature pyramid network는 two major designs, 즉 adaptive feature upsampling and adaptive feature fusion을 포함한다.- adaptive feature upsampling은
some models을 통해 각 pixel의 a group of sampling points를 predict하고,
이러한 sampling points의 feature combination에 의해 feature representation of the pixel을 구성한다. - adaptive feature fusion은
attention mechanism을 통해 fusion features들 사이의 pixel-level fusion weights를 구성한다.
- adaptive feature upsampling은
1. Introduction
- 현재, FPN은 object detection algorithms의 an essential module이 되고 있다.
하지만, FPN이 OD에 널리 적용되기에는 아직 certain defects가 남아있다.
(문제점 1)
- FPN은 high-level low-resolution features의 upsampling을 통해 high-resolution features를 얻을 수 있고,
그리고 나서 means of addition에 의해 low-level high-resolution features들과 fuse된다.
traditional upsampling에서,
각 target point 주변의 four similar points는 보통 sampling points로 선택되어지고,
the features of target points는 linearly combining the features of sampling points로 얻어질 것이다.
이러한 sampling mode는 spatial relationship에만 의존하기 때문에, boundary (경계 영역)이나 some details의 points가 unrelated pixels에 의해 쉽게 영향을 받을 수 있다.
따라서 spatial coordinates만을 기반으로 하는 upsampling mode는 fine features를 얻는 것이 어렵다.
(문제점 2)
- Deep CNN은 multiple downsampling을 거치게 된다.
downsampling 이후 upsampling을 통해 features를 복원할 때, feature misalignment가 발생하기 쉬우며,
이는 upsampling을 통해 복원된 feature와 downsampling 없이 유지된 primitive (원본) features 간의 differences and even ambiguities (차이 또는 모호성)을 초래할 수 있다.
(문제점 3)
-
FPN은 simple addition and fusion을 사용한다.
하지만 backbone의 서로 다른 level에서 가져온 feature 간에는 differences가 존재하기 때문에,
direct addition은 두 level의 feature representations을 손상시킬 수 있다.
게다가, 이러한 direct fusion은 the areas of some details, the detection of small objects, and accurate object localization에 적합하지 않을 수 있다. -
위 문제들을 해결하기 위해,
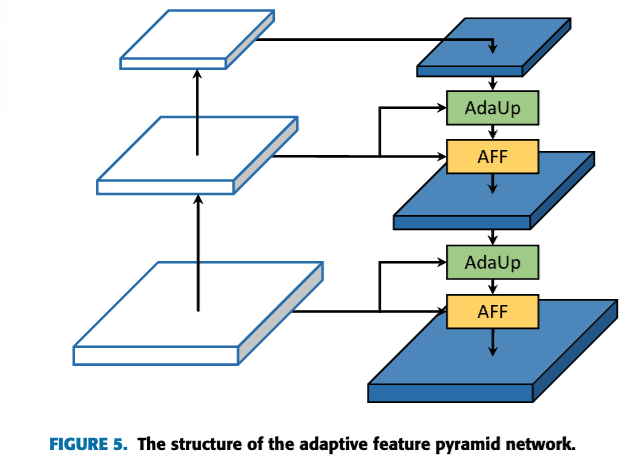
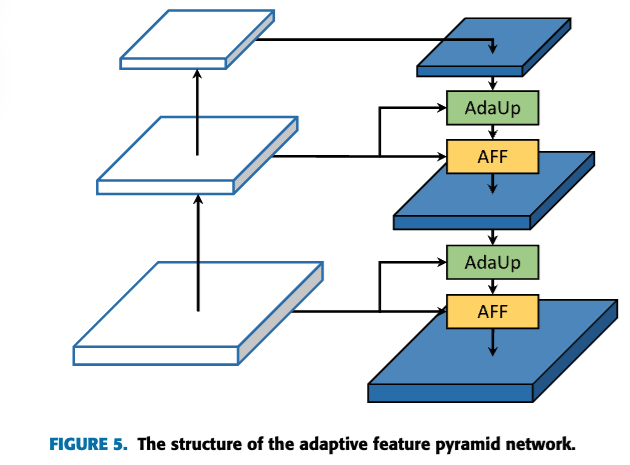
adaptive feature pyramid network (AdaFPN)을 제안한다.
기존의 FPN과 비교하여, AdaFPN은 feature upsampling과 multi-scale feature fusion 관점에서
각각 adaptive feature upsamling (AdaUp)과 adaptive feature fusion (AFF)를 도입한다.- AdaUp은 기존 방식처럼 spatial coordinates에만 의존하지 않고, semantic information도 활용한다.
즉, low-level high-resolution features를 spatial references로 사용하고,
이를 high-level low-resolution features와 combine하여
각 target point의 a series of related sampling points의 coordinate offset을 predict한다.
이를 통해, sampling points의 (continuous) coordinates를 target points의 coordinate offset과 the coordinates로 얻을 수 있다.
이후, 모든 sampling points의 features를 bilinear interpolation을 사용하여 계산하고, 이를 combine하여 최종적으로 target points의 features를 구성한다.
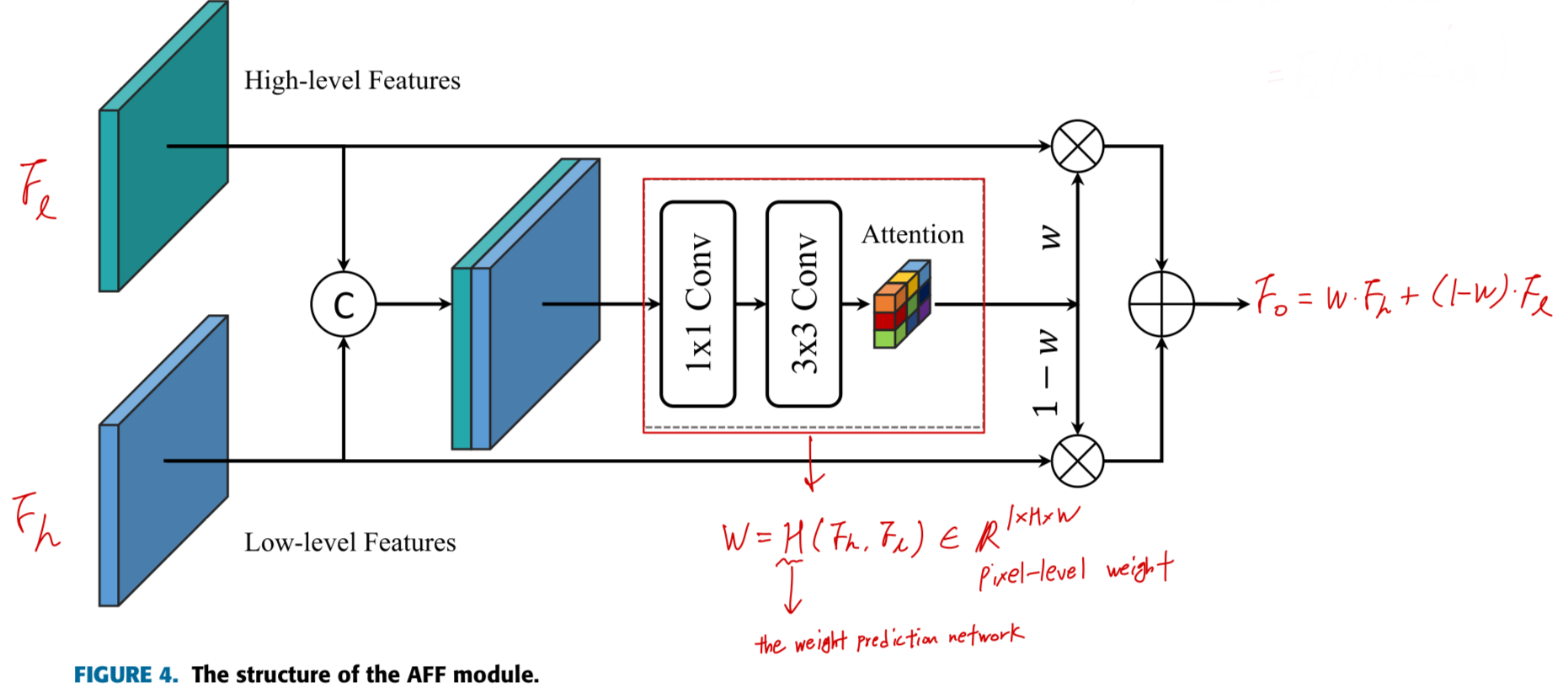
more flexible and can dynamically adjust the samplint point location of interpolation based on input features and spatial location. - AFF는 attention mechanism의 개념을 차용하여, high-level 및 low-level features를 이용해 pixel-level fusion weight를 predict한다.
이를 통해, 각 pixel은 feature fusion ratio를 dynamically 조정할 수 있다.
기존의 direct addition of features at two levels과 비교하면,
adaptive fusion은 각 pixel의 features에 대한 weight allocation을 고려하여 more accurate feature representation을 제공한다.
- AdaUp은 기존 방식처럼 spatial coordinates에만 의존하지 않고, semantic information도 활용한다.
2. Related Work
skip
Image OD
FPN
3. Method Proposed In This Paper
Feature Pyramid Network
-
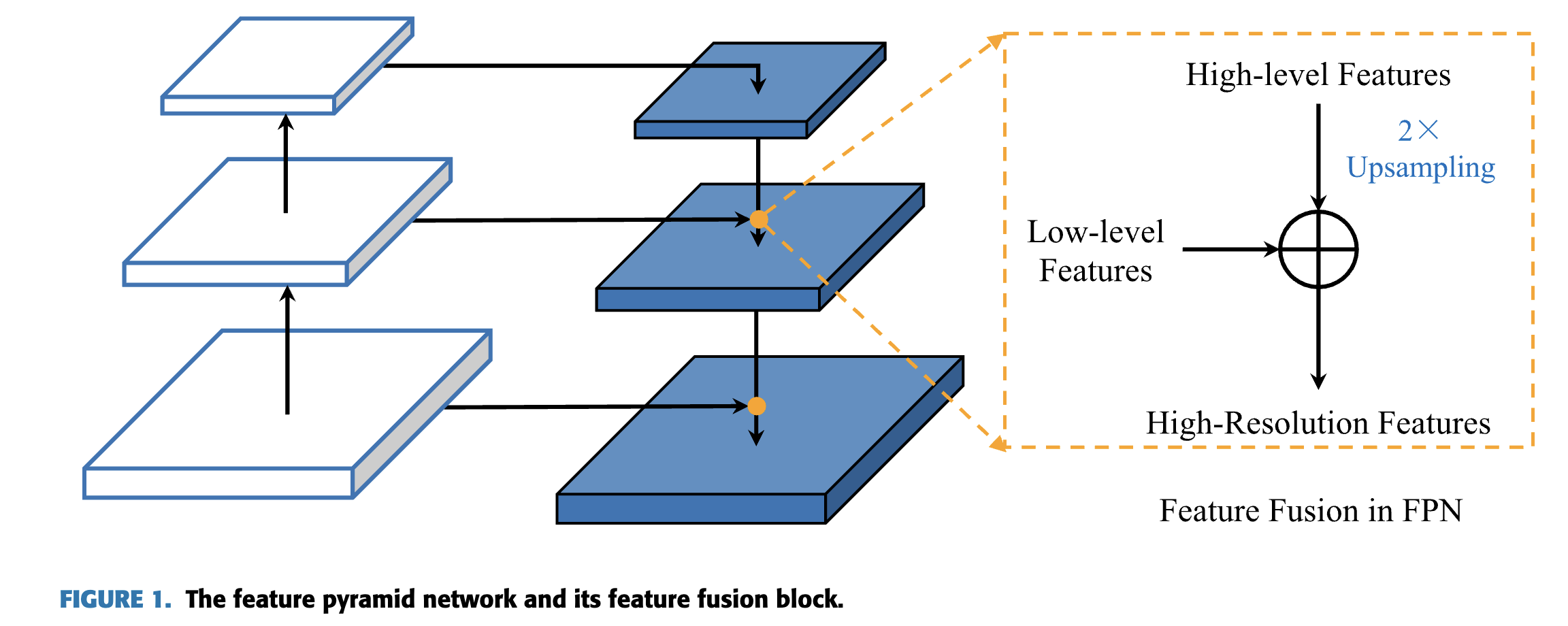
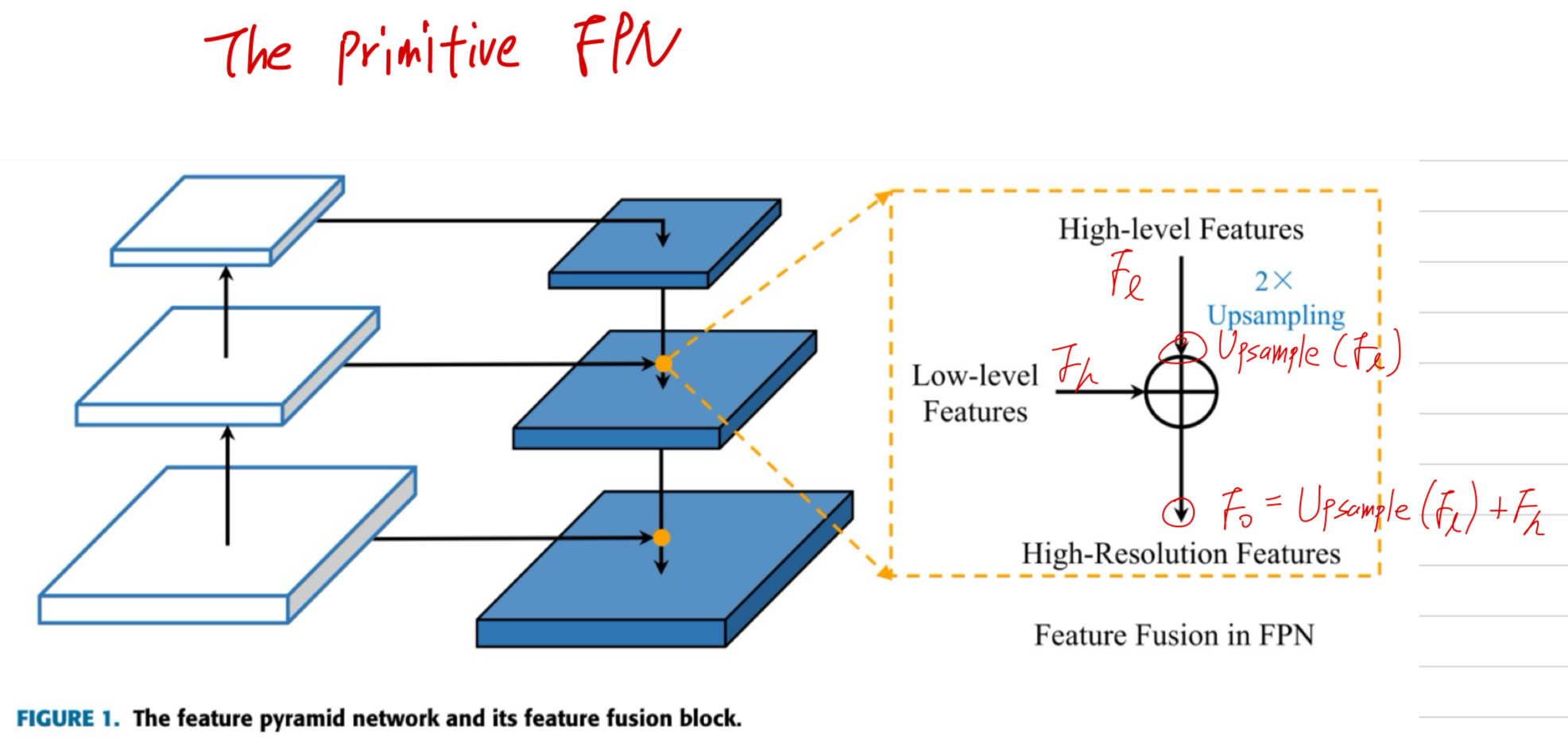
Fig.1에서처럼,
feature가 backbone에서 extracted되고 나서,
FPN은 연속해서 a top-down manner로 the resolution of high-level features를 향상시키고,
그들을 low-level feature와 fuse한다.
-
The primitive (원래의) FPN은 오로지 traditional interpolation method and multi-level feature fusion by addition에 의해서만 feature upsampling을 수행했다.
The fused feature 는 Eq.1에 따라 다음과 같이 얻어진다.
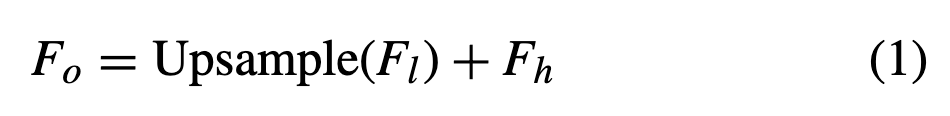
 하지만 backbone에서 서로 다른 levels의 features들이 derived되기 때문에,
하지만 backbone에서 서로 다른 levels의 features들이 derived되기 때문에,
만약 이 features들이 re-upsampling된다면 feature misalignment가 발생할 수 있다.
이 paper에서, the primitive FPN에 대해서,
feature upsampling 관점에서 문제를 해결하기 위한 adaptive feature upsampling과
feature fusion 관점에서 문제를 해결하기 위한 adaptive feature fusion을 제안한다.
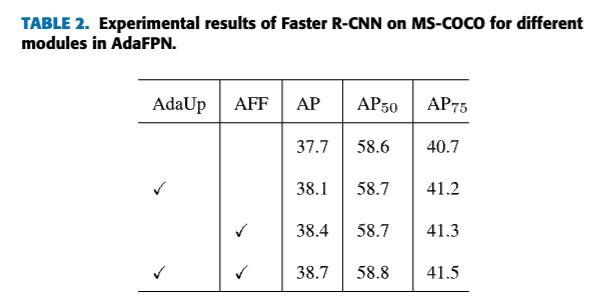
Adaptive Feature Upsampling (AdaUp)
-
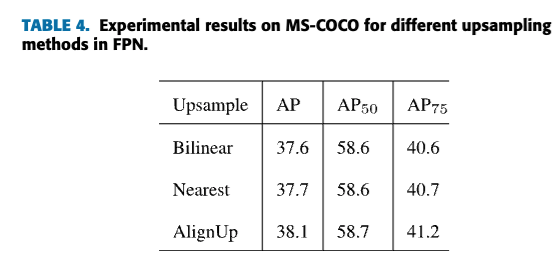
현재, images의 upsampling을 하기 위해서
보통은 bilinear interpolation and nearest interpolation이 사용되고 있다.
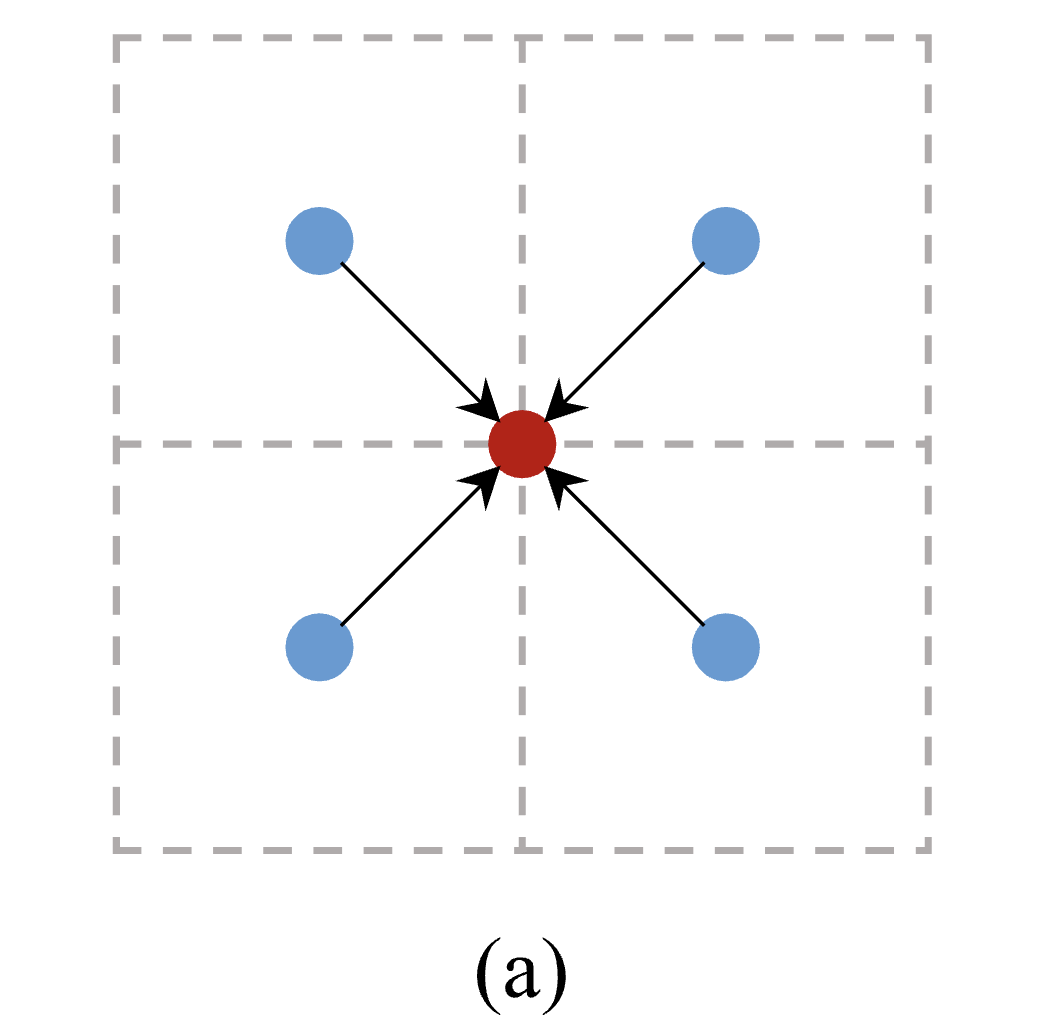
Fig.2(a)에서 보이는 것처럼, these interpolation methods는 only depend on spatial contraint한다.
sampled pixels의 location이 fixed되고, 이는 the input feature information의 consideration 없이 단지 neighborhood relationship에만 의존한다.
-
이 논문에서,
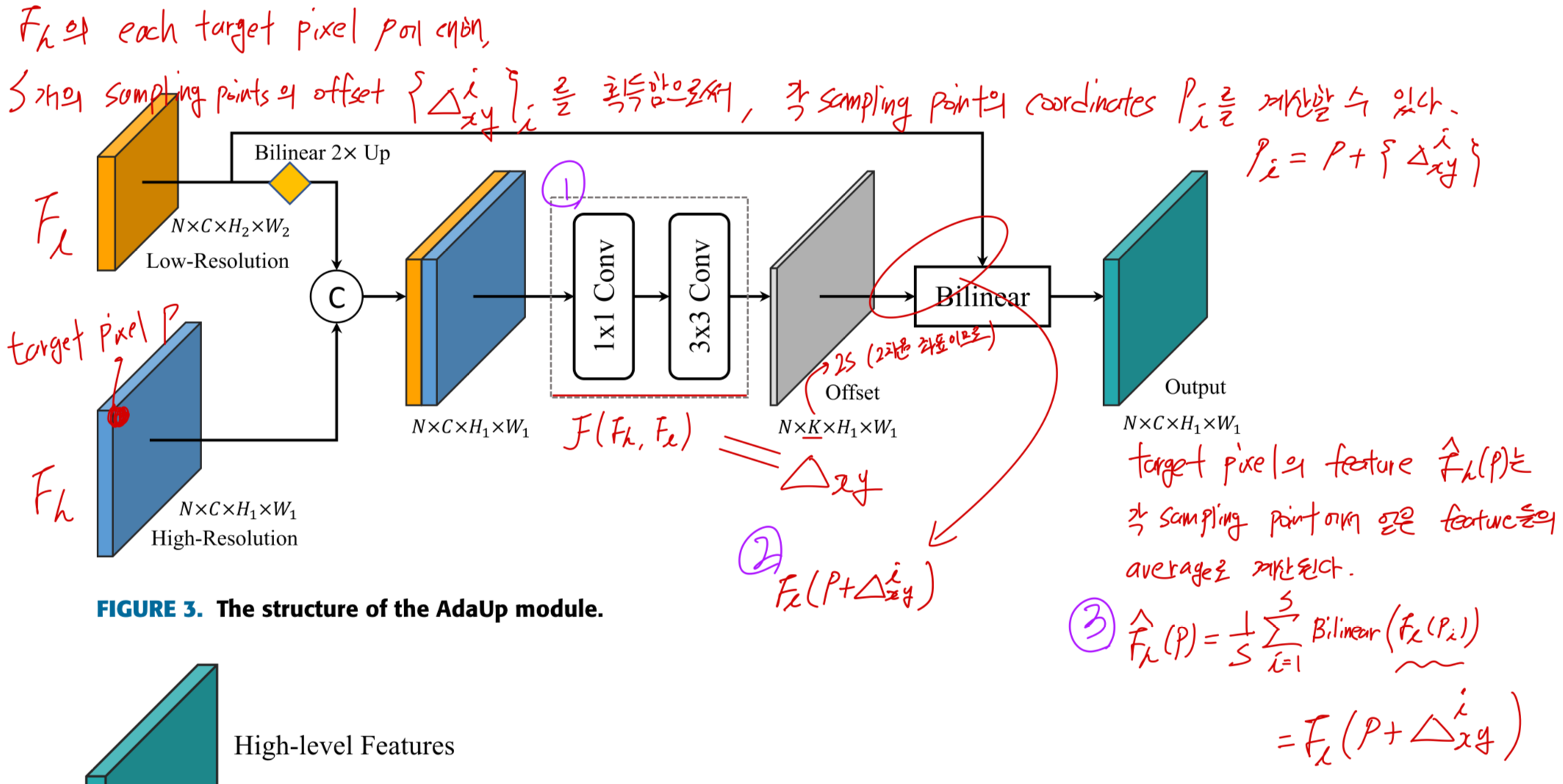
an adaptive upsampling method (AdaUp)을 제안한다.
AdaUp은 upsampling 이후 features를 획득할 때 더 이상 fixed coordinates를 사용한 interpolation에 의존하지 않는다.
대신, shallow high-resolution features를 spatial reference로 활용하여,
model을 통해 interpolation에 사용될 sampling point coordinates의 offset을 예측하는 방식을 채택했다.
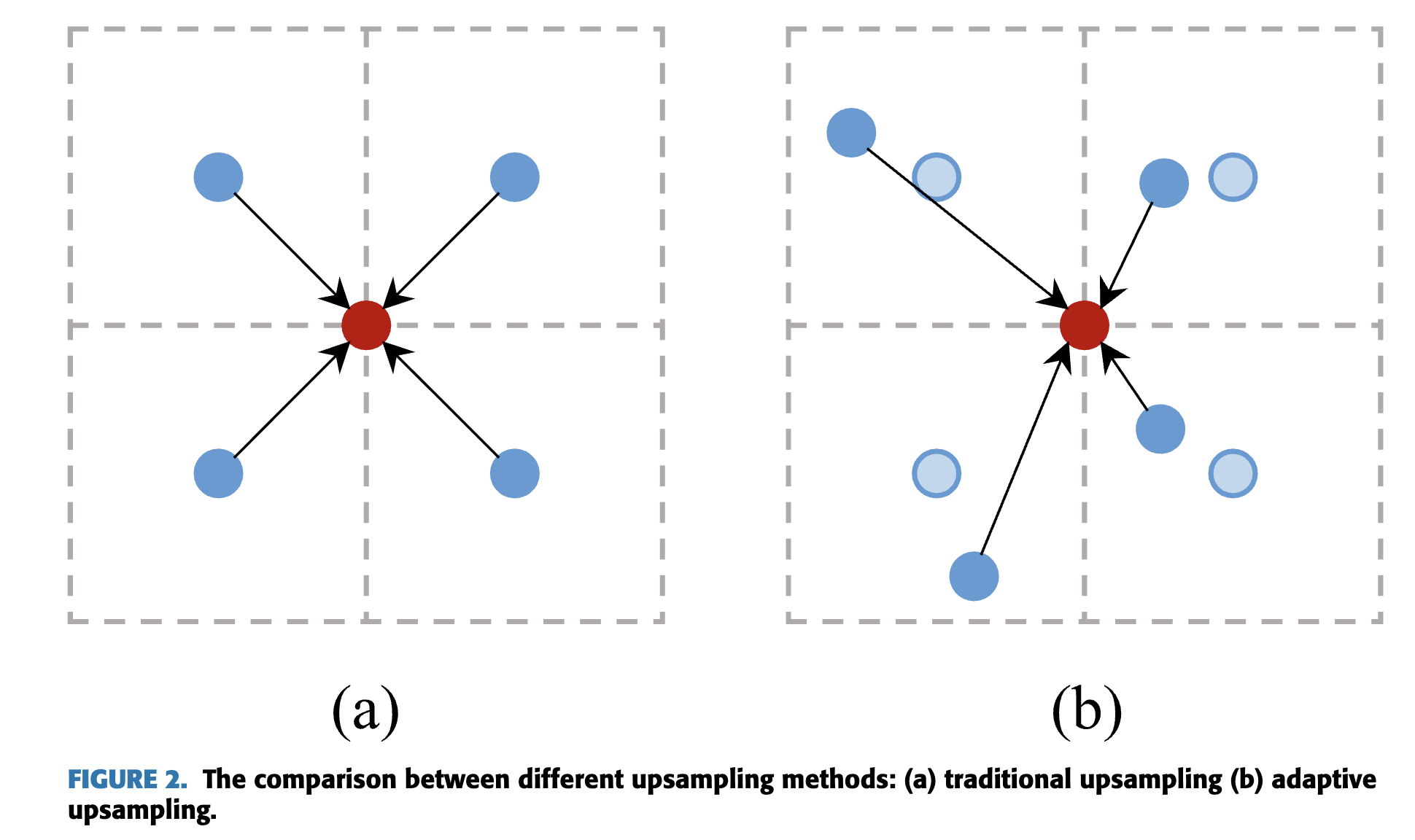
Fig. 2(b)에 나타난 바와 같이, AdaUp은 현재 upsampling이 필요한 feature와 model을 이용하여,
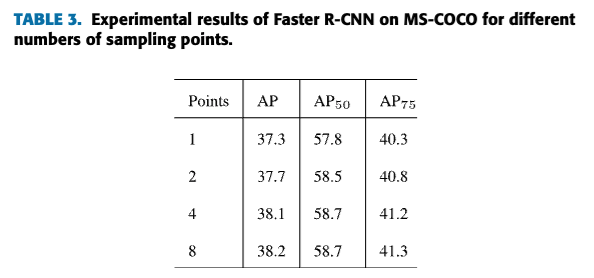
각 target (high-resolution features) pixel에 대해 개의 a series of sampling points를 예측한다.
traditional feature upsampling과 비교했을 때, AdaUp은 more flexible하며,
서로 다른 scale의 features 간에 발생하는 misalignment 문제 및 offset 문제를 완화할 수 있다.
(내 생각: 각 pixel마다 4개의 offset을 예측해야 하는 model을 만든다면 추가적인 parameter가 발생하고 computation budget이 더 발생하겠네?) -
deep low-resolution input feature 과
reference용 shallow high-resolution feature 가
주어졌을 때,
AdaUp은 reference high-resolution features와 low-resolution features를 기반으로
a series of sampling points의 relative coordinates 를 predict한다.
이는 Eq.2.에서 설명되며,
은 the offset prediction model을 의미하며,
이는 a simple conv network를 통해 구현된다.
여기서 sampling point의 coordinates는 continuous values이므로,
integer coordinates로 직접 features를 얻는 것이 불가능하다.
따라서, Bilinear Interpolation을 활용하여 continuous sampling point의 feature를 추출하였으며,
the output feature 이 AdaUp을 통해 얻어진 high resolution feature이다.
Adaptive Feature Fusion (AFF)
Adaptive Feature Pyramid Network (AdaFPN)
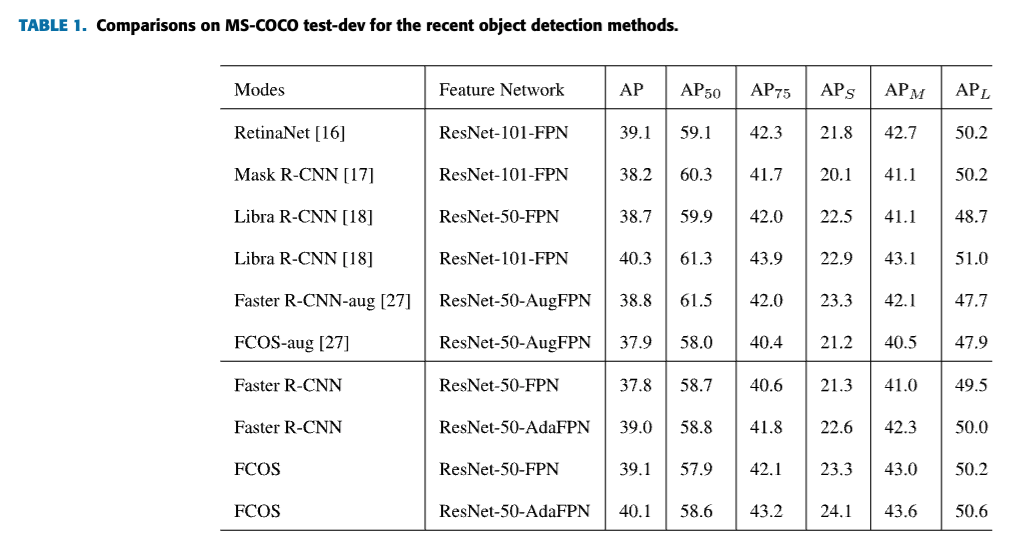
4. Experiment