[2021 CVPR] (Simple Review) VirTex: Learning Visual Representations from Textual Annotations
[Paper Review] VLM to LMM
이 논문을 읽게 된 이유
- CLIP 논문에서 주 관련연구로 VirTex에 대한 언급을 많이 했음.
CLIP 논문에서 주 관련 연구 중 하나로, VirTex를 많이 언급한다.
그래서 VLM에 대한 이해와 background를 넓히고자 읽게 되었다.
아래는 실제 CLIP 논문에서 언급한 VirTex에 대한 내용이다.

Abstract
(background)
- vision tasks에서 사실상의 de-facto approach는 ImageNet에서 supervised training을 통해 pretrained visual representations을 사용하는 것이다.
최근 방법들은 대규모 unlabeled images로 scale(확장)하기 위해 unsupervised pretraining을 탐구해왔다.
(contribution, method)
- 이에 반해, 우리는 fewer images로부터 high-quality visual representations을 학습하는 것을 목표로 한다.
이를 위해 우리는 supervised pretraining을 revisit하며,
classification-based pretraining의 efficient alternatives를 모색한다.
(method)
- 우리는 VirTex를 제안한다.
VirTex는 semantically dense caption을 활용하여 visual representations을 학습하는 a pretraining approach이다.
(Experiments)
- 우리는 COCO Captions dataset에서 CNN을 처음부터 학습시키고,
이를 image classification, object detection, instance segmentation을 포함한 downstream recognition tasks에 transfer한다.
모든 작업에서 VirTex는 ImageNet 기반의 supervised or unsupervised와 비교해 최대 10배 적은 images를 사용하고도 동등하거나 더 뛰어난 성능을 보여준다.
1. Introduction
(background: CV에서는 보통 image classification model을 pretrain하고, 이 feature를 이용하여 여러 down stream tasks로 transfer하는 접근 방식을 사용한다.)
- visual representations을 학습하는 데 있어 널리 사용되는 paradigm은 먼저 CNN을 ImageNet에서
image classification하도록 pretrain한 뒤,
learned features를 downstream tasks로 transfer하는 방식이다.
이러한 approach는 큰 성공을 거두고 있으며, object detectino, semantic and instance segmentation, image captioning 등
다양한 CV problems에서 상당한 발전을 이끌었다.
(supervised learning의 문제와 관련 연구 unsupervised learning)
- 그러나 이러한 방법은 pretraining step에서 human workers가 annotated한 image를 필요로 하기 때문에 scale하는 데에 비용이 많이 든다는 한계가 있다.
이러한 이유로, unlabeled images를 활용하여 visual representations을 학습하고 이를 downstream task에 transfer하는 unsupervised pretrainin methods에 대한 관심이 커지고 있다.
최근 몇몇 approach는 ImageNet에서의 supervised pretraining에 match or exceed하는 결과를 보이기도 하며,
수 백만 수 억만 images로 scaled되기도 했다.
(하지만 우리는 unsupervised learning과 다른 방향: 더 적은 image로 효율적인 supervised learning.
이를 위한 방법은 text annotations을 이용한 visual representations을 pretraining.)
- 그러나 우리는 fewer images로도 high-quality visual representations을 학습할 수 있는 다른 pretraining 방식이 있는지 질문해볼 수 있다.
이를 위해 우리는 supervised pretraining을 revisit하고,
각 image를 더 효율적으로 활용할 수 있는 traditional classification pretraining에 대한 alternative를 모색한다.
(제안 방법: 텍스트 주석으로 visual representation을 학습하는 pretraining 방식)
- 본 논문에서는 TEXtual annotations로부터 VIsual Representations을 학습하는 (VirTex)를 제안한다.
VirTex는 straightforward(단순)하다.- 먼저 ConvNet과 Transformer를 from scratch로 jointly train하여
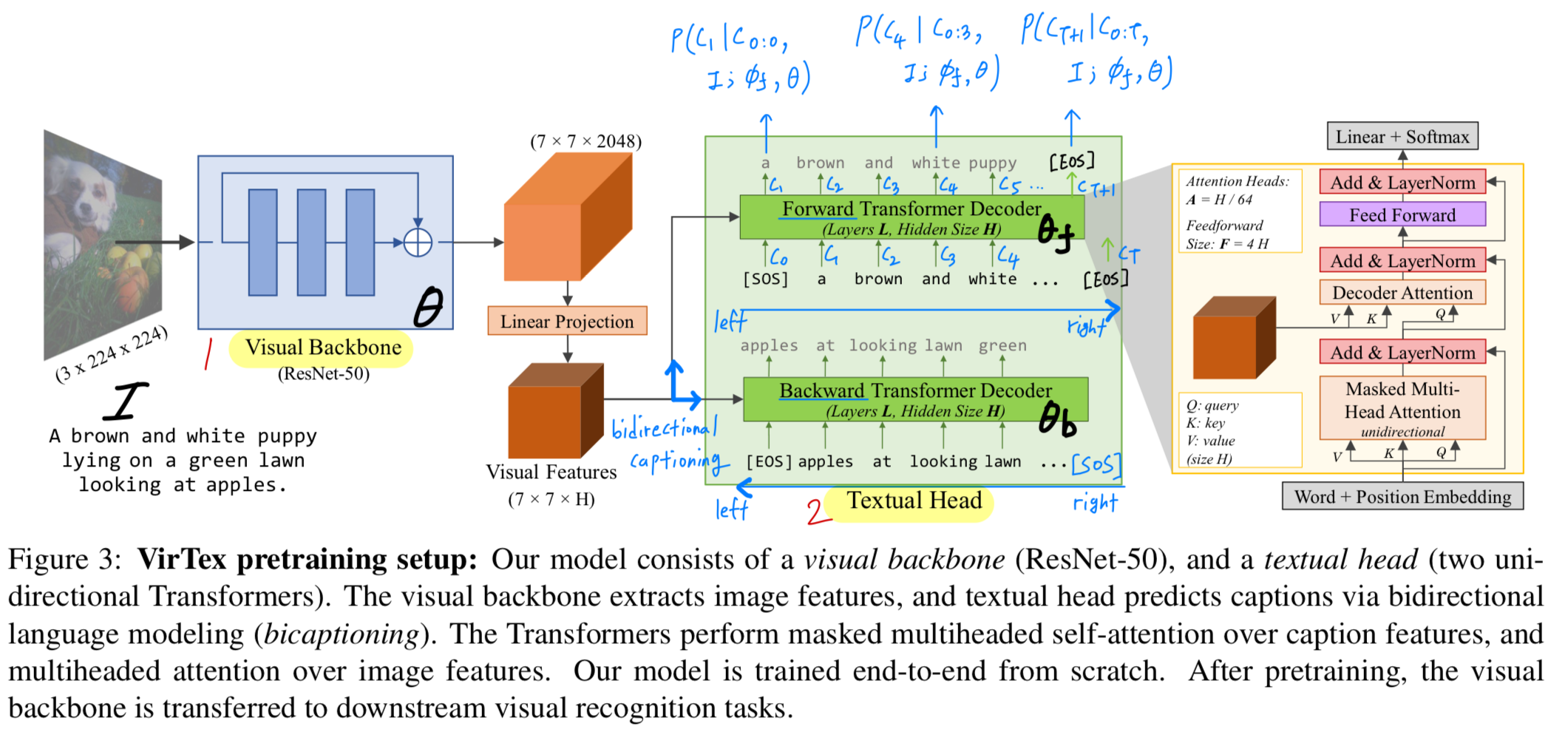
natural language captions for images를 생성하도록 한다. - 이후 learned features를 downstream visual recognition tasks에 transfer한다. (Figure 1)
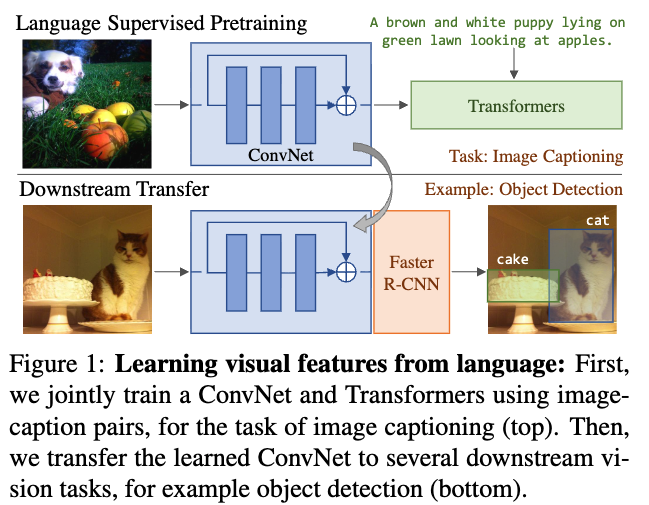
- 먼저 ConvNet과 Transformer를 from scratch로 jointly train하여
(language supervision의 장점 1: semantically dense learning signal)
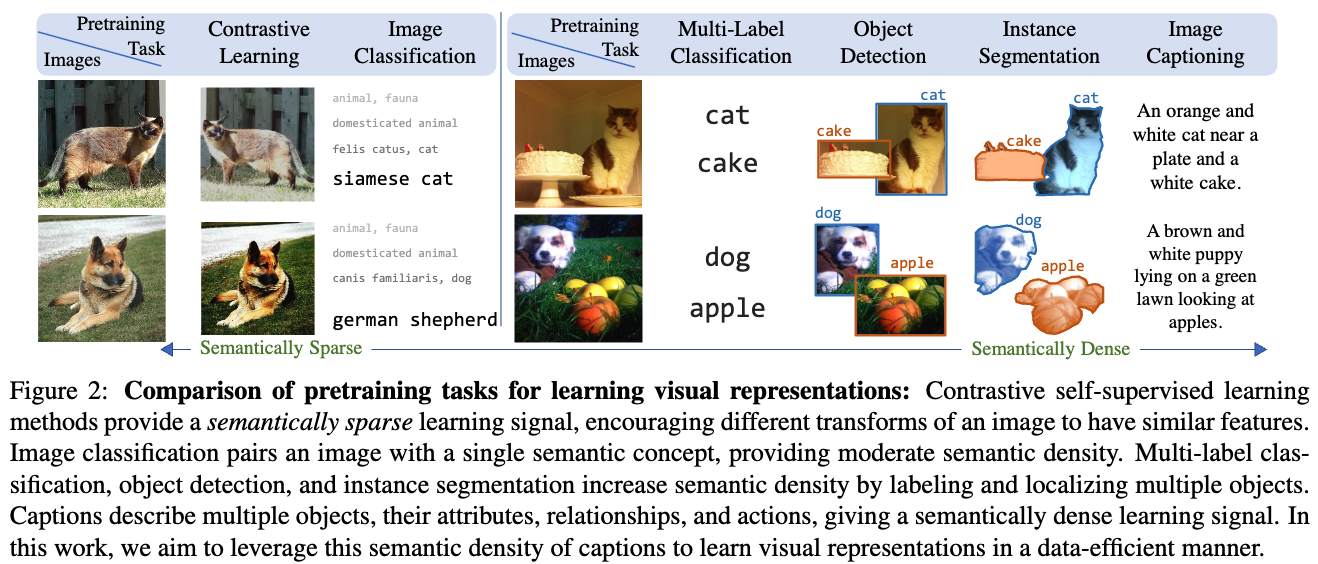
- language supervision을 사용하는 것은 semantic density 때문이라는 점에서 매력적이다.
Figure 2는 visual representations 학습을 위한 다양한 pretraining tasks를 비교한 것이다.
caption들은 unsupervised contrastive methods와 supervised classifiction보다 a semantically denser learning signal을 제공한다.
따라서 textual features를 사용해 visual features를 학습하면 다른 approaches보다 fewer images로도 충분할 것이라고 기대할 수 있다.
(language supervision의 장점 2: data collection의 단순화)
- textual annotation의 또 다른 benefit은 data collection이 단순화된다는 것이다.
classification labels을 수집하기 위해서는 일반적으로 human experts가 먼저 categories의 ontology를 구축한 뒤,
complex crowdsourcing pipelines을 통해 non-experts users들로부터 label을 수집한다.
반면, natural language descriptions은 explicit ontology를 필요로 하지 않으며, non-expert workers도 쉽게 작성할 수 있어 data collection pipeline이 단순해진다.
또한, internet image로부터 많은 양의 weakly aligned image and text를 쉽게 얻을 수 있다.
(실험)
- our main contribution은 natural language가 다른 approches보다 better data-efficiency로
transferable visual representations을 위한 supervision을 제공할 수 있음을 보인 것이다.
우리는 COCO Captions dataset으로 model을 scratch부터 학습하고,
그 learned features를 다양한 downstream tasks (image classification, object detection, instance segmentation, and low-shot recognition 등)에서 evaluate한다.
모든 tasks에서 VirTex는 ImageNet에서의 기존 supervised or unsupervised pretraining 방법들과 비교해 최대 적은 images로도 동등하거나 더 나은 성능을 달성한다.
https://github.com/kdexd/virtex
2. Related Work
- 우리 연구는 ImageNet 기반의 supervised pretraining을 넘어, 다른 data sources or pretraining tasks를 이용하려는 recent efforts와 밀접한 관련이 있다.
Weakly Upservised Learning
- Weakly supervised learning은 quality보다 quantity 접근 방식을 통해, web service로부터 얻은 nosy labels로부터 많은 images를 학습해 supervised pretraining보다 더 크게 scale한다.
Li et al. [40]은 user-provided tags가 달린 100M 개의 Flickr images를 포함하는 YGCC-100M dataset으로 visual N-gram models을 학습했다.
최근 연구들은 automatic labeling of images from web signals로 구축된 JFT-300M dataset도 활용한다.
또한, 3.5B instagram images에 대해 hashtags를 label로 사용하는 weakly-supervised learning도 존재한다.
이러한 접근법들은 low-quality labels이 달린 large quantities of images(대규모 이미지)로 visual representations을 학습한다.
반면, 우리는 high-quality annotations이 달린 few images를 사용하는 데 초점을 둔다.
Self-Supervised Learning
-
Self-supervised learning은 unlabeled images에 대해 pretext tasks를 풀면서 visual representations을 학습한다.
(pretext tasks란? unlabeled data로부터 유용한 feature를 학습하기 위해 인위적으로 만들어낸 task.
진짜로 풀고 싶은 문제 즉, downstream tasks르 위한 사전 연습 문제.)
초기 연구들은 context prediction, colorization, solving jigsaw puzzles, ... , generative modeling 등
다양한 hand-crafted pretext tasks를 제안했다.
최근의 연구들은 주로 contrastive learning을 기반으로, single input image에 대해 random transformations을 적용한 뒤
image feature들의 similarity를 높이도록 학습시킨다.
기타 approaches들은 context prediction, mutual information maximization, predicting masked regions, and clustering 등을 활용한다. -
이러한 methods들은 low-level visual cues (color, texture)에 의존하기 때문에 semantic understanding이 부족하지만,
우리는 textual annotations을 활용하여 semantic understanding을 부여한다.
또한 internat images로 scaled될 경우, text와 같은 additional meta-data도 활용 가능한 점이 차별점이다
Vision-and-Language Pretraining
-
Vision-and-Language Pretraining은 image-text paired data를 사용해 multimodal downstream tasks에
transfer할 수 있는 joint representations를 학습하는 것을 목표로 한다.
대표적인 downstream tasks로는 VQA(Visual Question Answering), visual reasoning, referring expressions, and language-based image retrieval 등이 있다.
BERT의 성공에 영감을 받아, 최근 연구들은 Transformer를 활용하여 transferable joint representations of images and text를 학습한다. -
이들 방법은 complex pretraining pipeline을 사용한다:
1. ImageNet-pretrained CNN에서부터 시작
2. [74]를 따라 Visual Genome [73] dataset으로 fine-tuned된 object detector를 사용하여 region features 추출
3. 선택적으로, BERT [64]와 같은 pretrained language model 사용
4. (2)와 (3)의 model을 결합하여 Conceptual Captions [37]로 multimodal Transformer train
5. (4)의 model을 downstream task에 fine-tune
이 pipeline에서, 모든 vision-and-language tasks는 결국 ImageNet에서 학습된 initial visual representation에 의존하는 구조를 가진다.
반면, 우리 방식은 image captioning을 통해 pretrain을 수행하고, 그 후 vision-and-language pretraining의 downstream으로 둔다.
Concurrent Work
-
우리 연구는 Sariyildiz et al. [75]처럼 image conditioned masked language modeling을 통해 caption으로부터 visual representations을 학습하는 연구와 가장 가깝다.
하지만 큰 차이는 다음과 같다:
우리는 entire model을 scratch로 학습하는 반면, 그들은 textual features를 위해 pretrained BERT에 의존한다.
또한 우리는 object detection and instance segmentation 등 추가적인 additional downstream tasks에도 평가를 수행한다. -
또한 Stroud et al. [76]와 같은 textual metadata를 활용해 video representations을 학습하는 연구와도 밀접하게 관련되지만, 그들은 video tasks에만 초점을 맞춘다는 점에서 다르다.
3. Method
-
a dataset of image-caption pairs가 주어졌을 때, 우리의 목표는 visual recognition tasks로 transferred할 수 있는 visual representations을 학습하는 것이다.
Figure 2에서 보이는 바와 같이, caption에는 image에 대한 rich semantic information이 담겨 있다.
예를 들어, objects의 존재 (cat, plate, cake), objects의 속성 (orange and white cat), objects 간의 spatial arrangement (cat near a plate), 그리고 their actions (looking at apples) 등이 포함된다.
이러한 rich semantics를 capture하는 visual representations은 다양한 downstream vision tasks에 유용할 것이다.
-
이를 위해 우리는 image로부터 captions을 예측하는 image captioning model을 학습한다.
Figure 3와 같이, model은 two components로 이루어진다: (1) a visual backbone and (2) a text head.
visual backbone은 input image 로부터 visual features를 extract한다.
textual head는 these visual features를 입력받아, caption 을 token by token으로 predict한다.
여기서 , 는 문장의 시작과 끝을 나타내는 special token이다.
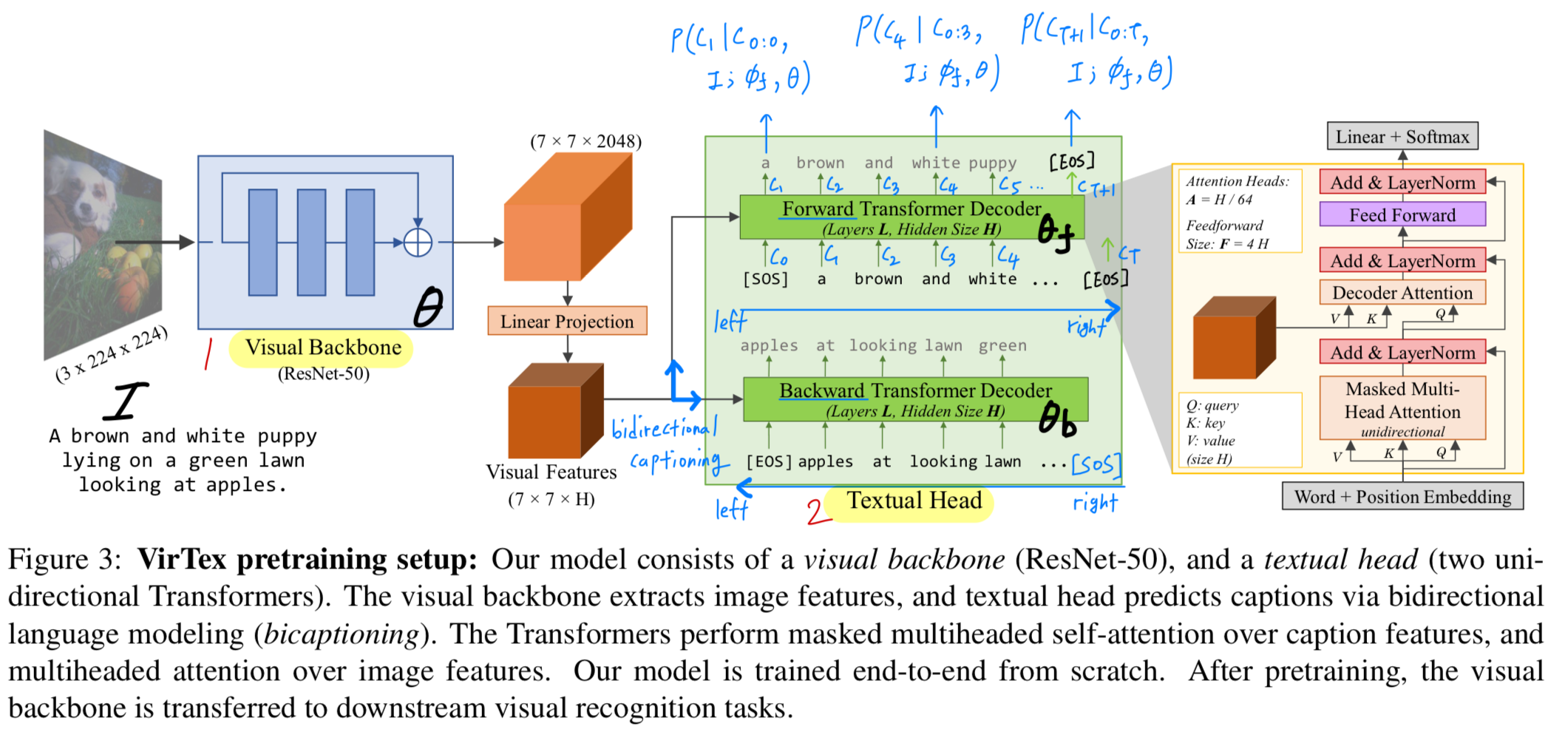
- textual head는 bidirectional captioning (bicaptioning)을 수행한다.
즉, left-to-right로 token을 생성하는 forward model,
right-to-left로 token을 생성하는 backward model로 구성된다.
모든 model components는 randomly initialized되며, 올바른 caption tokens의 log-likelihood를 maximize하도록 jointly trained된다.

여기서 , , and 는 각각
the parameters of the visual backbone, forward, and backward models이다.
(내 생각 : 위 Eq. (1)에서 Backward Transformer Decoder가 만들어내는 log-liklihood term에서 으로 해야 되지 않나? 싶음.. 내가 이해를 잘 못하고 있는 거일 수도..)
- (bidirectional captioning이란?)
GPT 답변: image 한 장에 대해 두 개의 caption generation model을 동시에 학습하는 방식.
forward captioning은 L2R 방향으로 caption 생성. 즉, "[SOS] A cat sits on the table [EOS]"
backwrad captioning은 R2L 방향으로 caption 생성. 즉, "[EOS] table the on sits cat A [SOS]"
전통적 captioning model은 L2R 방향으로만 문장을 생성하므로, 초반 단어를 생성할 때 뒤에 올 단어 정보가 없다.
반면, bicaptioning에서는 이전 단어(forward)와 이후 단어(backward), 두 방향 모두에서 의미적 단서를 학습하게 되어,
visual features에 대한 supervised signald이 더 풍부해짐.
이는 BERT(Bidirectional Encoder Representations from Transformers)가 MLM(Masked Language Model)을 통해 문장의 양방향 정보를 학습하여 "semantic-rich representation"을 얻는 것처럼,
bicaptioning도 유사하게 두 방향 language supervision을 통해 visual representations에 semantic-rich 정보를 주입하는 효과가 있다.
Language Modeling
- 우리의 pretraining task는 image captioning이다. (image classification이 아님)
이는 vision-and-language model에서 널리 연구된 task이지만,
그 동안은 vision-based pretraining 이후의 downstream task로 취급되어 왔다.
우리는 NLP에서 language modeling을 pretraining task로 사용해 transferable text representations을 학습하는 최근 연구로부터 영감을 받았다.
이러한 접근은 massive language model을 training하는 것으로, undirectional 또는 bidirectional model을 사용해 token을 one by one (하나씩) predicting한다.
하지만 BERT [64] 이후의 많은 large-scale model들은 masked language models (MLM)을 사용한다.
즉 일부 token을 randomly masked하고, model이 이를 prediction하도록 한다.
우리는 MLM에 대한 preliminary experiments를 수행했으나, [64, 84]에서 보고된 바와 마찬가지로 MLM은 directional model보다 converge가 느리다는 것을 확인했다.
또한 MLM은 각 caption의 일부 token만 prediction하므로 sample efficiency가 떨어진다. (?)
반면 bidirectional models은 bidirectional model은 all tokens을 prediction한다. (?)
computational constraints로 인해 우리는 directional models에 집중하며, MLM은 future work로 남겨둔다.
(내가 이해한 내용:
MLM은 한 caption의 일부 token만 예측함.
즉, 10개 단어 중 2~3개만 예측하므로 데이터의 정보 활용도가 낮다는 의미인 듯 하다. supervision도 풍부하지 못 해서 convergence도 느릴 것임.
bicaptioning은 forward와 backward captioning model 둘 다 모든 token을 예측하므로 MLM보다 sample efficiency가 좋다고 주장하는 듯.
모든 token이 supervision을 받기 때문에 convergence도 빠른 것 같다.)
Visual Backbone
-
Visual backbone은 image를 입력받아 visual features를 계산하는 conv network이다.
inputs은 raw image pixels이며,
outputs은 a spatial grid of image features이다. -
pretraining 동안 이 feature들은 caption을 prediction하는 데 사용된다.
-
downstream task에서는 visual backbone에서 extracted된 feature 위에 linear models을 train하거나,
visual backbone 전체를 end-to-end fine-tuning한다.
원칙적으로 visual backbone으로 어떤 CNN architecture든 사용할 수 있다.
experiments에서는 baseline methods들과 비교를 용이하게 하기 위해 standard ResNet-50을 사용한다.
ResNet-50은 image를 입력받아 final conv layer 이후 grid of 2048-dimensional features를 출력한다.
pretraining 시에는 decoder가 visual features에 attention할 수 있도록 이 visual features에 linear projection layer를 적용한다.
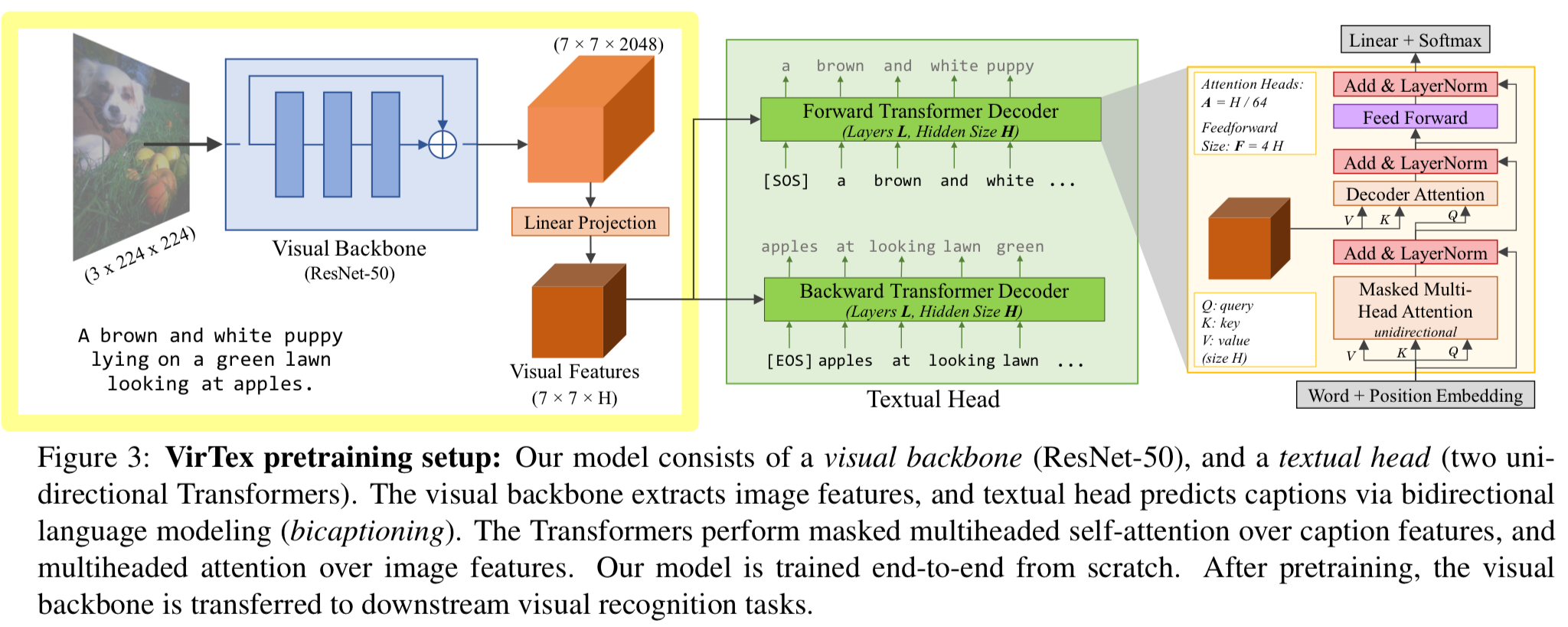
Textual Head
-
Textual head는 visual backbone에서 추출된 feature를 입력받아 image의 caption을 prediction한다.
이는 pretraining 동안 visual backbone에 learning signal을 제공한다.
우리의 궁극적인 목표는 high-quality captions이 아니라, transferable visual features를 학습하는 것이다. -
textual head는 각각 forward and backward direction으로 caption을 predict하는
two identical language model로 구성된다.
최근 language modeling의 발전에 따라, 우리는 Transformer를 사용하며,
이는 caption tokens의 sequence 내에서 information을 propagate하고
visual feature와 textual feature를 fusion하기 위해 multiheaded self-attention을 사용한다.
우리는 [29]의 Trnasformer decoder 구조를 따르되, [64, 79]를 참고하여 ReLU 대신 GELU [85]를 사용한다.
전체 구조는 Figure 3에서 확인할 수 있다.
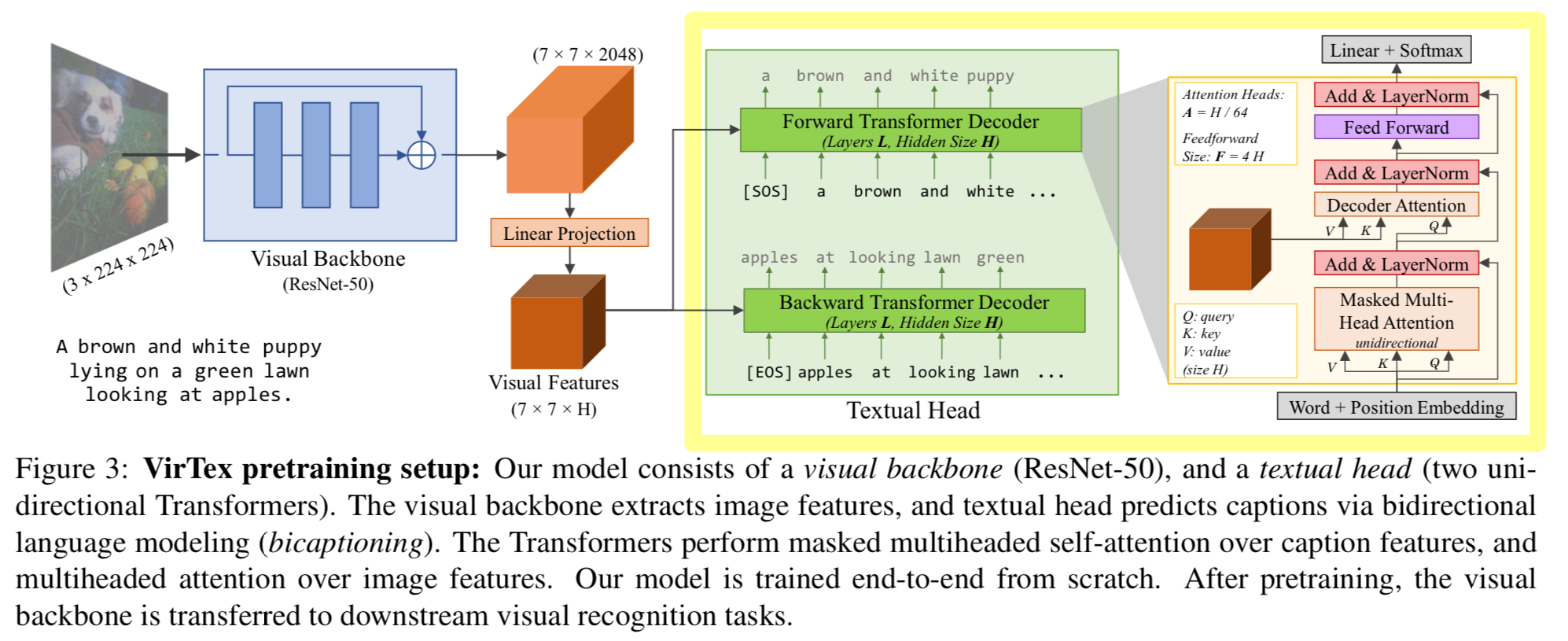
-
학습 시 forward model은 두 가지 입력을 받는다: (1) image feature from the visual backbone, and (2) a caption during describing the image
image features는 a matrix of shape 이며,
이는 the final layer of the visual backbone의 positoins 각각에 대해 a -dimensional vector를 의미한다.
caption 는 총 개 tokens으로 이루어져 있고, 여기서 and 이다.
model은 부터 시작하여 을 token-by-token (token 단위로) prediction하도록 trained된다.
prediction 는 causal하며, past prediction and visual features에만 의존한다.
(causal predction이란? 말 그대로 인과적 예측이라는 뜻. language model에서 미래를 보지 않고, 과거 정보(원인)만 사용해 다음 단어(결과)를 예측하는 방식. 즉, autoregressive prediction과 동일) -
우리는 먼저 의 token들을 learned token and positional embedding을 더해 vector로 변환한 뒤,
element-wise sum, layer normalization [86], dropout [87]을 적용한다.
이 vector들은 a sequence of Transformer layers를 통과한다.
Figure 3에서 보이듯 ,각 layer는 (1) masked multiheaded self-attention over token vectors, (2) token vectors와 image vectors 사이의 multiheaded attention, (3) a two-layer FC network를 거친다.
각 operations들은 dropout과 residual connection 뒤 layer normalization이 뒤따른다.
self-attention에서는 masing을 통해 causal structure of the final predictions을 유지한다.
the last Transformer layer 이후 각 token vector에 linear layer를 적용해 token vocabulary에 대한 unnormalized log-probabilities를 predict한다. -
forward와 backward model은 independent Transformer layers로 구성되지만,
동일한 token embedding matrix를 공유하며, 이는 각 model의 output layers에서도 공유된다.
-
4. Experiments
4.1. Image Classification with Linear Models
-
Table 1:
VirTex의 가장 중요한 결과는 dataset을 사용하여
pretraining한 model이 다른 방식의 pretraining 방법들보다 뛰어나다는 것.
동일한 image(COCO)를 사용하더라도, caption을 사용하여 학습한 VirTex가 다른 anootation 형태(multi-labels classification, instance segmentation mask)를 사용한 model들보다 적은 비용으로 더 높은 성능을 달성한다는 것.
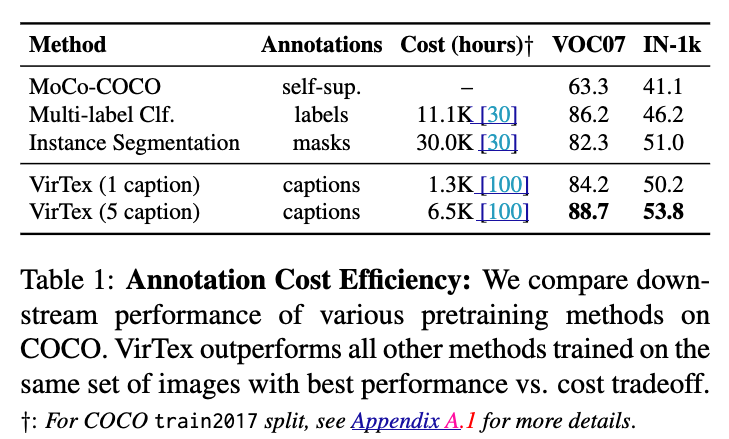
-
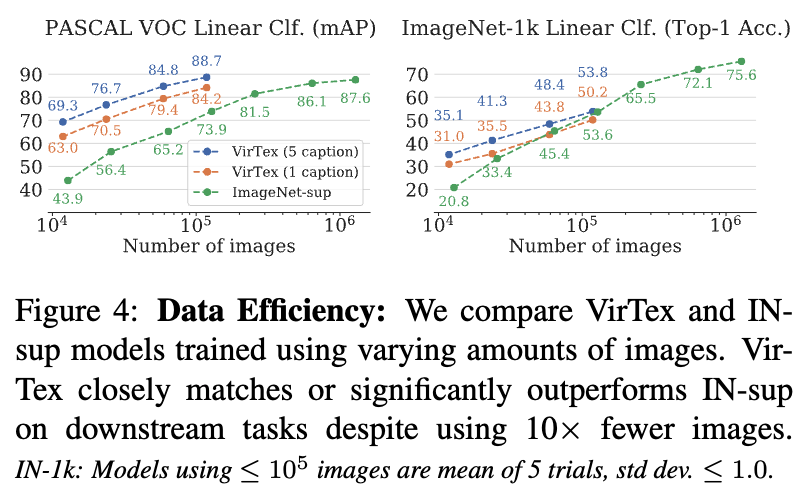
Figure 4:
VirTex가 data efficiency가 매우 뛰어나다.
훨씬 적은 수의 image를 사용하고도 ImageNet supervion model(IN-sup)과 matches or 살짝 outperform.
-
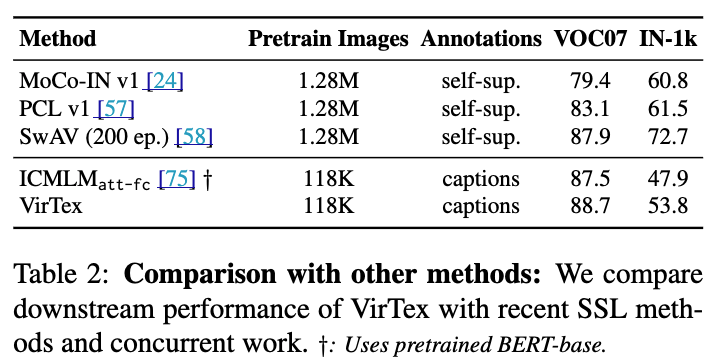
Table 2: VirTex와 최신 Self-Supervised Learning(SSL) 방법들(MoCo, SwAV 등) 및 concurent 연구(ICMLM)의 성능을 비교
4.2. Ablations
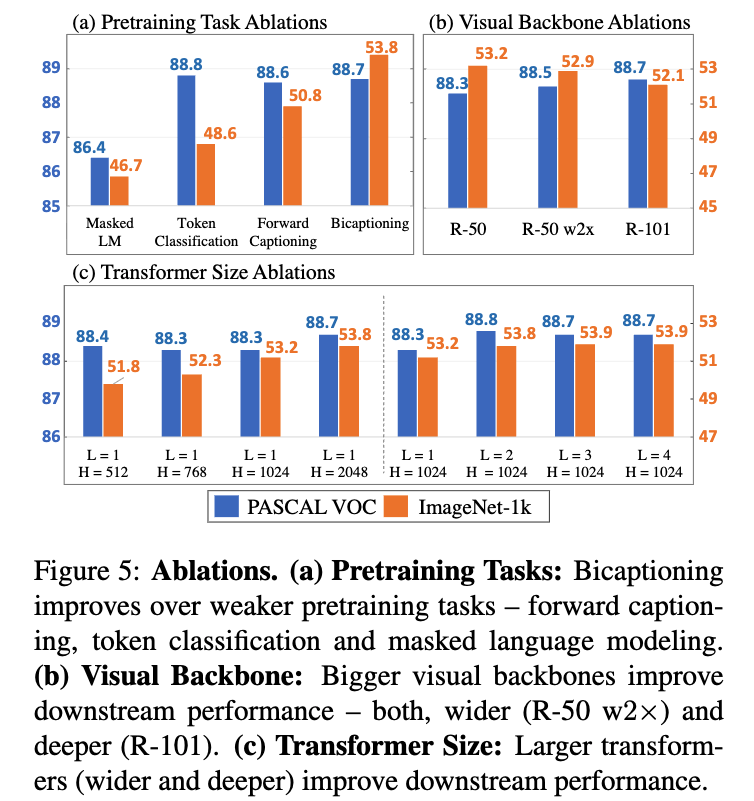
- Figure 5:
VirTex의 성능에 영향을 미치는 세가지 주요 요소 분석
(a) pretrainint task: Bicaptioning이 MLM, Token Classification, forward captioning(단방향)보다 visual representation learning에 뛰어남.
(b) Visual Backbone: visual backbone(ResNet)의 width, depth를 scale할수록 downstream 성능이 향상되는 경향
(c) Transformer Size: textual head이 Transformers의 #layers(depth), #hiddens(width)를 scale할수록 downstream 성능이 향상되는 경향
4.3. Fine-tuning Tasks for Transfer
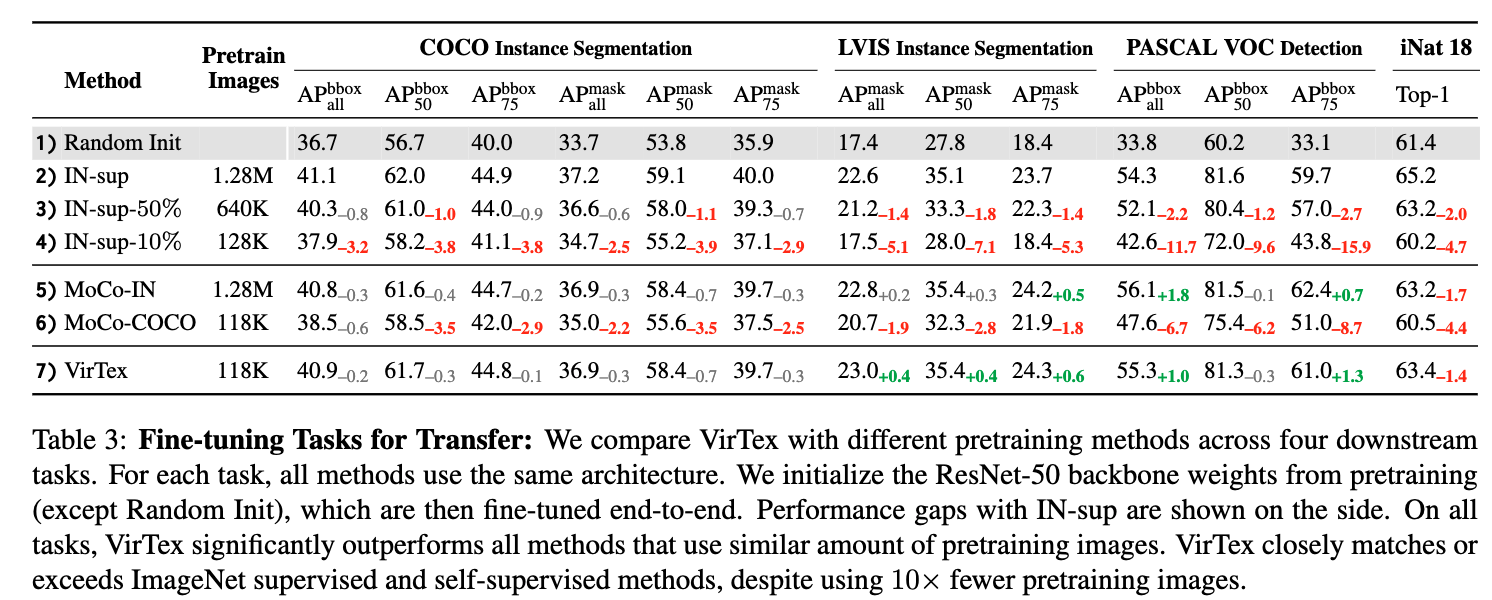
- Table 3: Feature를 freeze하지 않고 전체 backbone을 end-to-end fine-tuning 설정에도 VirTex가 뛰어남.
4.4. Image Captioning
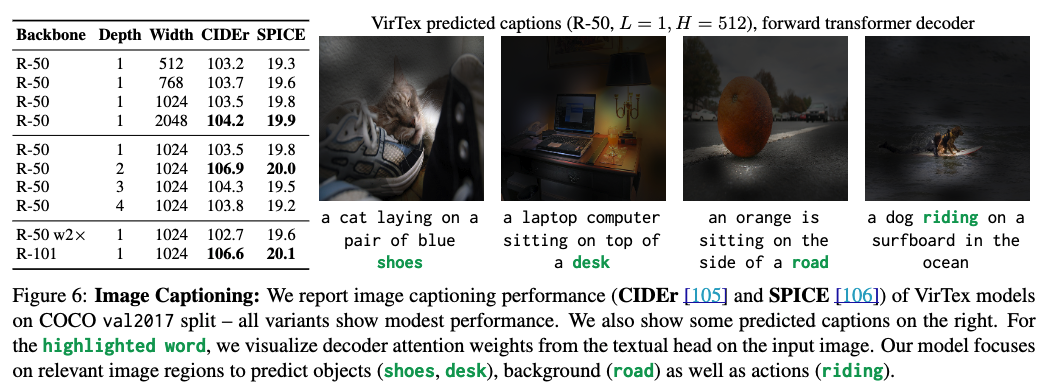
- Figure 6: Image Captioning & Attention Visualization
이 논문의 핵심
- VirTex 논문의 핵심은
기존에 image classification으로 pretraining(supervised learning)해서 downstream task로 transfer했었는데,
image classification labels 또는 다른 방식들(unsupervised learning, self-supervised learning) 말고,
caption(textual annotations)을 prediction하도록 CNN을 pretraining하면,
더 적은 data로도 ImageNet supervised learning에 대등하거나 능가하는 high-quality visual representations을 학습할 수 있어,
다양한 downstream task로 transfer할 수 있다는 것.
