[Paper Review] VLM to LMM
1.VLM(Vision-Language Model) to LMM(Large Multimodal Model)

VLM에서 LMM으로 변해가는 context를 대략적으로 정리해본다현재 여기 까지 읽었음 (25.12.15)
2.[2021 CVPR] (Simple Review) VirTex: Learning Visual Representations from Textual Annotations
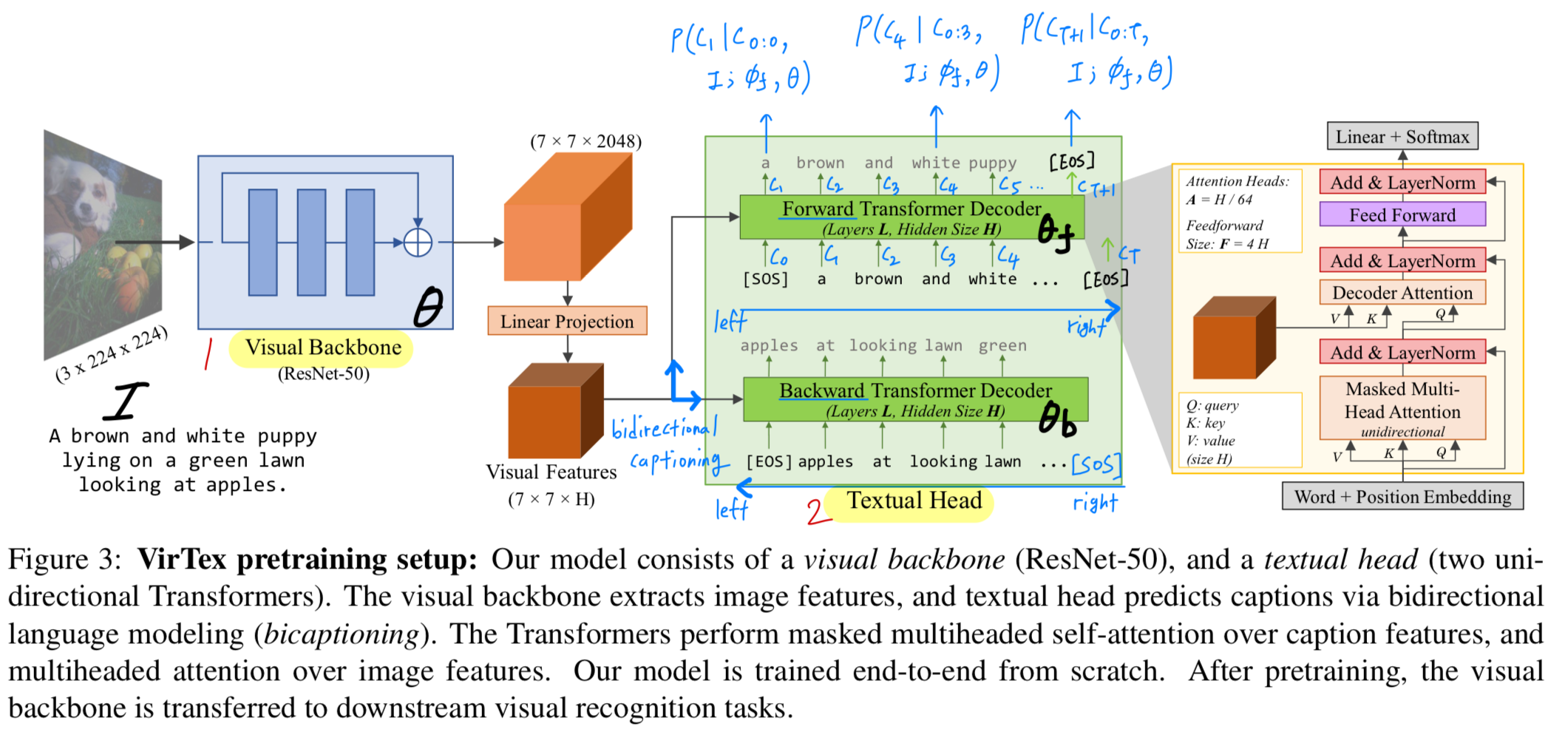
CLIP 논문에서 주 관련연구로 VirTex에 대한 언급을 많이 했음.CLIP 논문에서 주 관련 연구 중 하나로, VirTex를 많이 언급한다.그래서 VLM에 대한 이해와 background를 넓히고자 읽게 되었다.아래는 실제 CLIP 논문에서 언급한 VirTex에 대
3.[2022 MLHC] [Simple Review] (ConVIRT) Contrastive Learning of Medical Visual Representations from Paired Images and Text
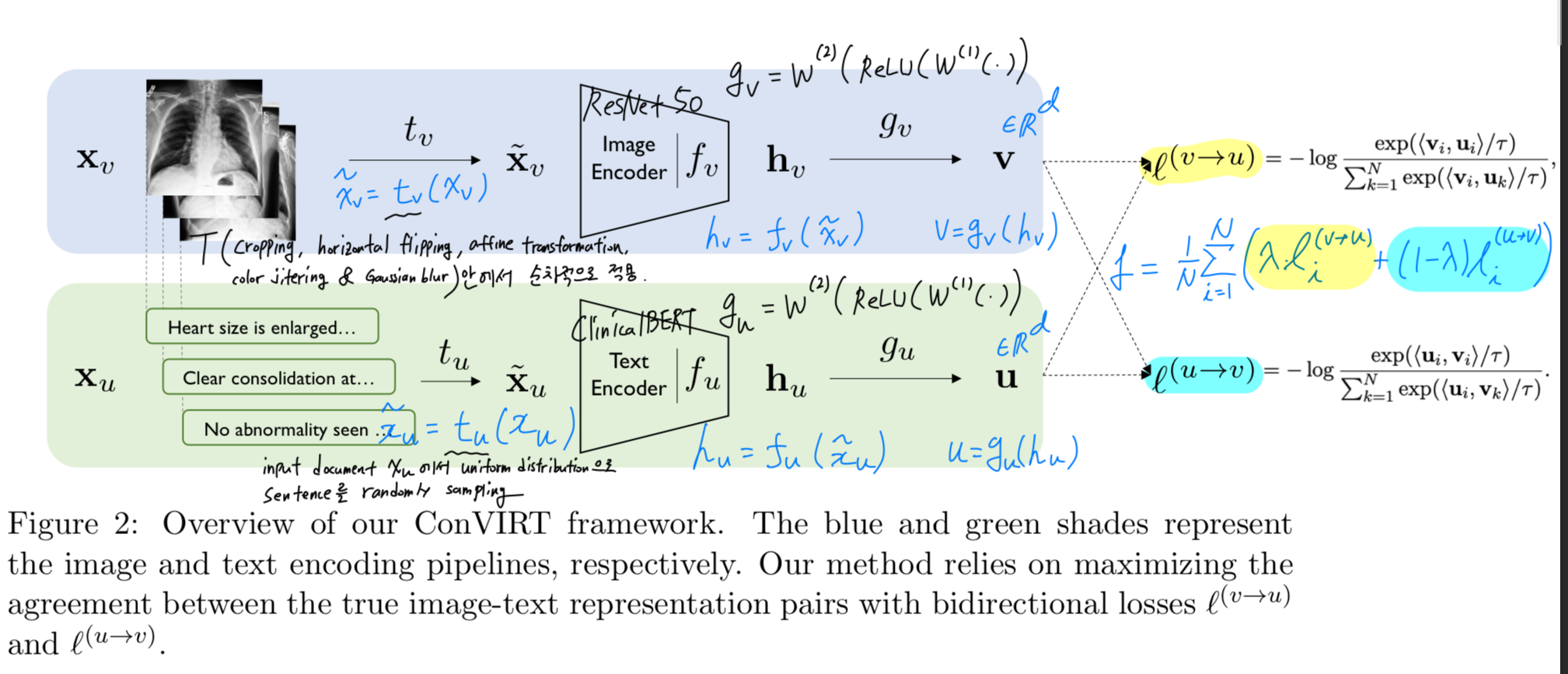
CLIP 논문에서 이 논문(CoVIRT)을 기반으로 연구했다고 많이 언급되어, VLM에 대한 이해, background를 넓히고자 읽게 되었다.
4.[2021 ICML] (CLIP) Learning Transferable Visual Models From Natural Language Supervision

Abstract
5.CLIP은 ConVIRT를 어떻게 단순화했는가?
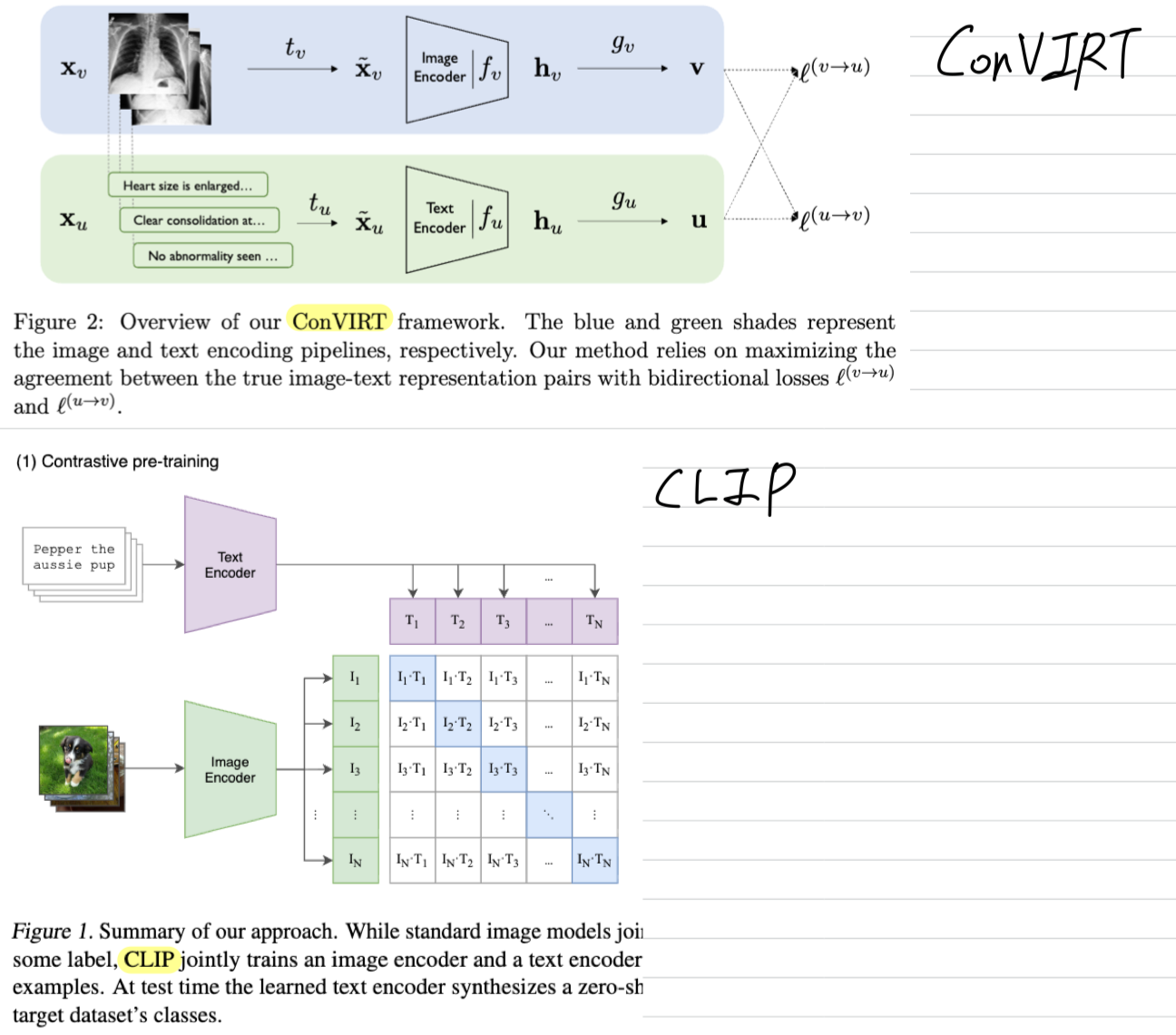
ConVIRT: Zhang, Yuhao, et al. "Contrastive learning of medical visual representations from paired images and text." Machine learning for healthcare co
6.[2021 ICML] [simple review] (ALIGN) Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
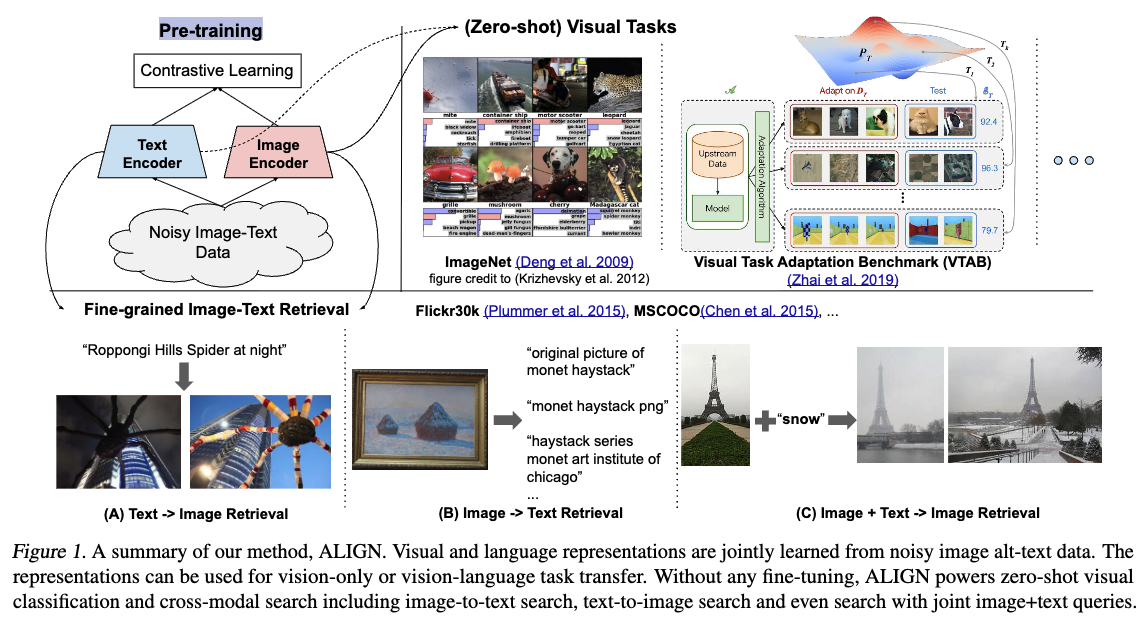
Jia, Chao, et al. "Scaling up visual and vision-language representation learning with noisy text supervision." International conference on machine lea
7.[2022 ICML] (Simple Review) BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
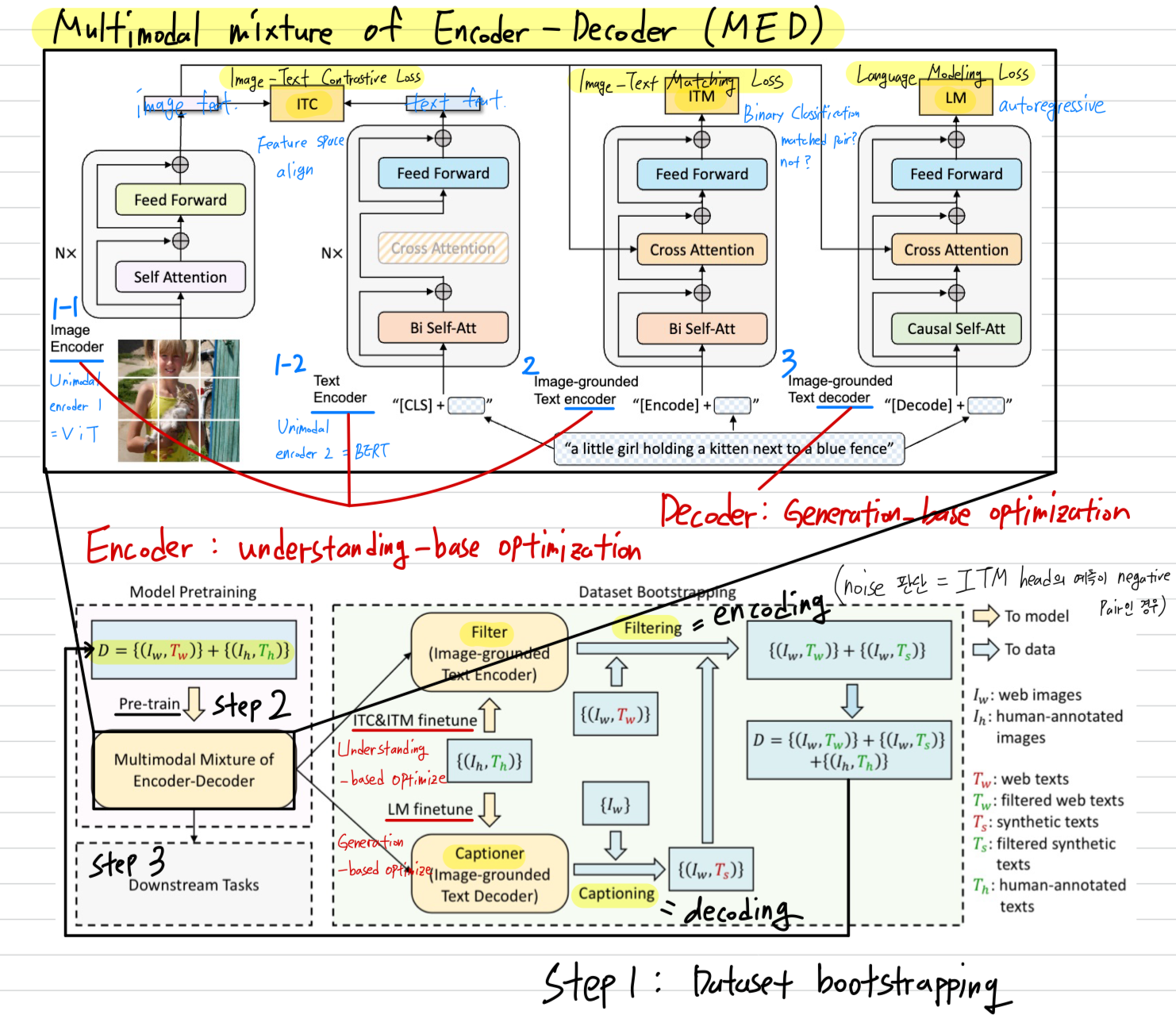
Paper Info Abstract (Background) Vision-Language Pre-training (VLP)는 많은 vision-language tasks에서 성능을 향상시켜 왔다. (문제 1) 하지만, 대부분의 pre-trained models은 u
8.[2022 TMLR] (simple review) CoCa: Contrastive Captioners are Image-Text Foundation Models
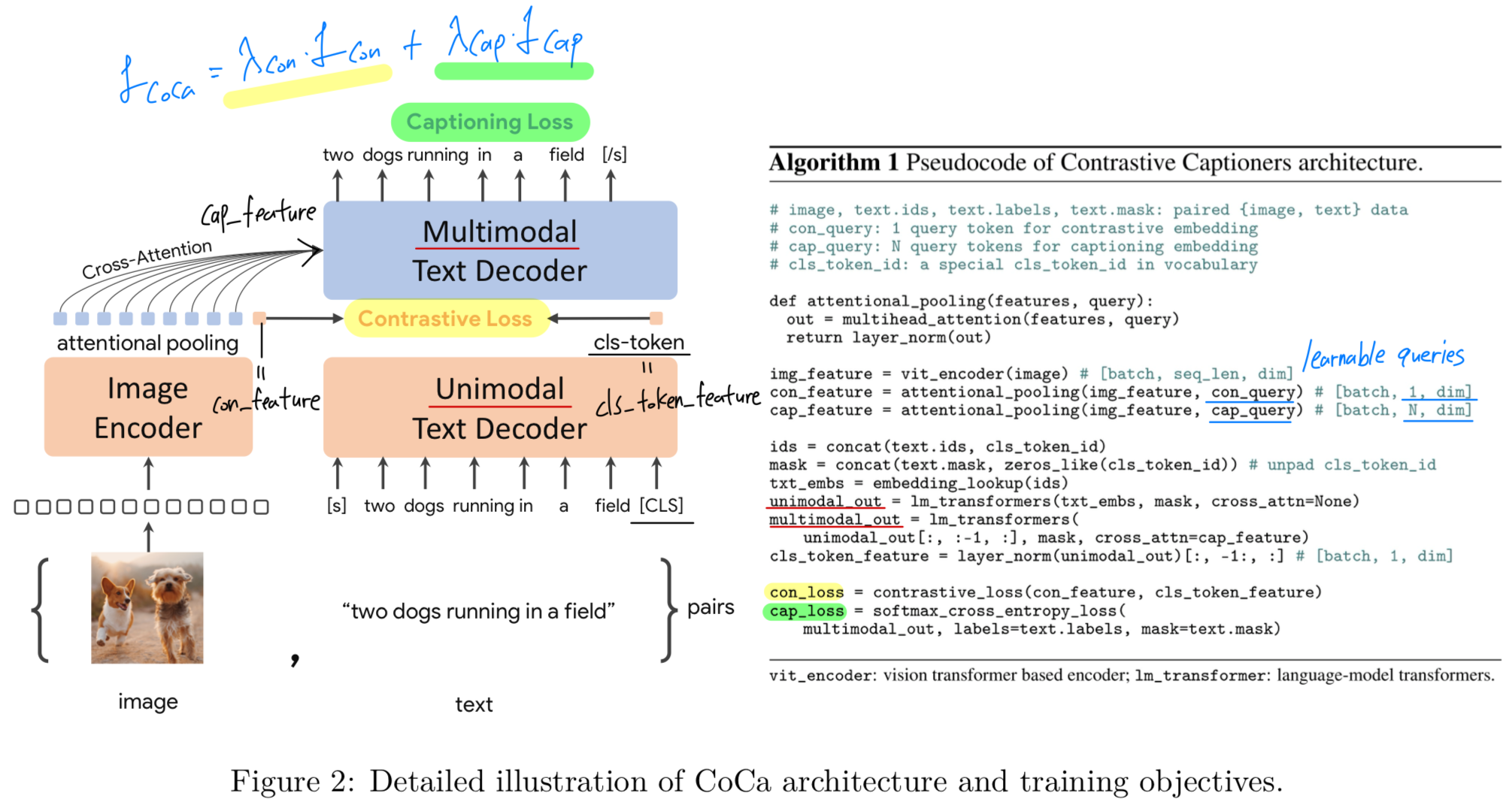
https://openreview.net/forum?id=Ee277P3AYC(제안: encoding=understanding과 decoding=generating을 동시에 수행할 수 있게 contrasitve loss와 captioning loss로 joint
9.[2022 NeurIPS] (simple review) 🦩Flamingo: a Visual Language Model for Few-Shot Learning
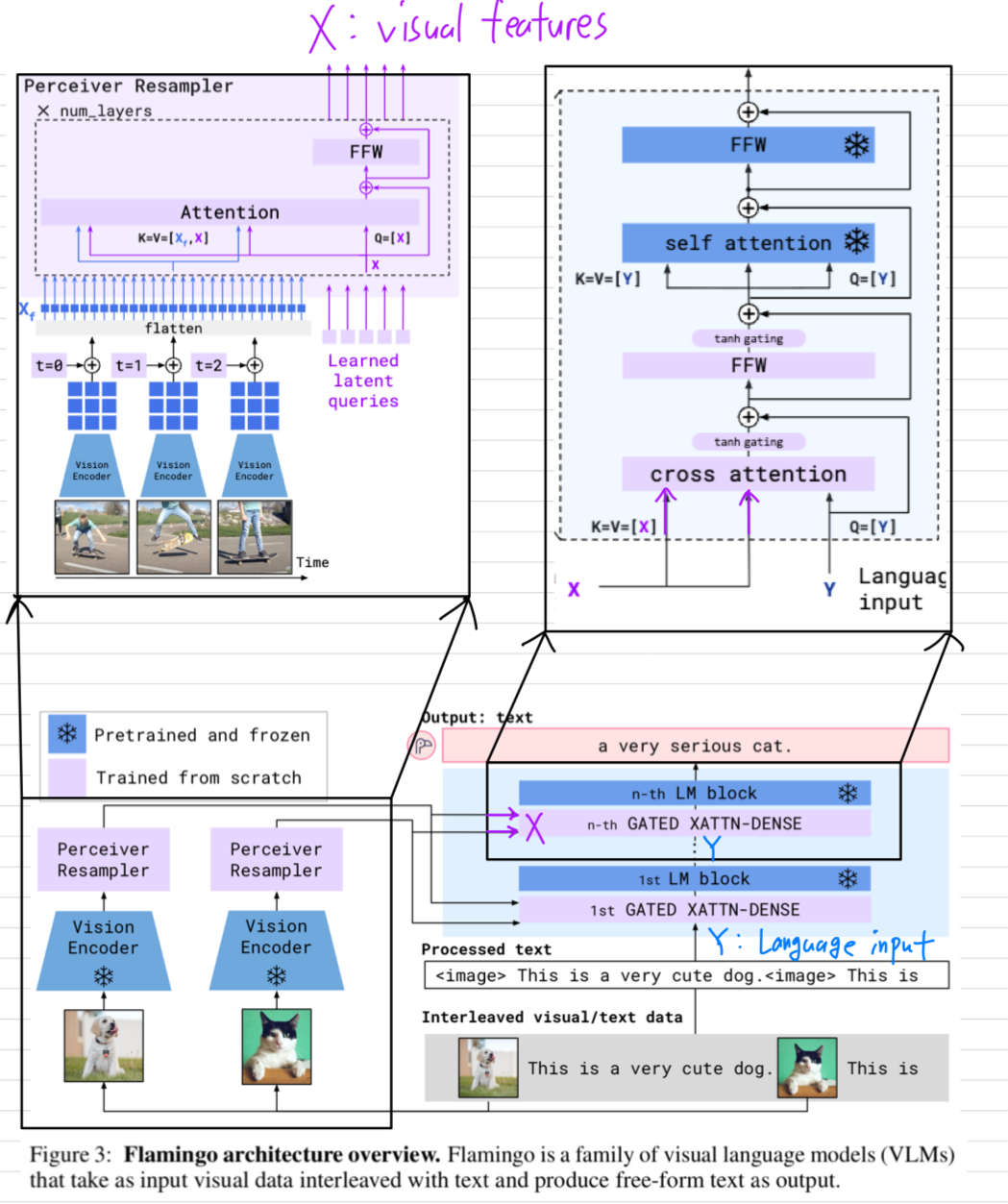
Paper Info. openreview: https://openreview.net/forum?id=EbMuimAbPbs neurips proceedings: https://proceedings.neurips.cc/paper_files/paper/2022/file/9
10.[2023 ICML] (Simple Review) BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
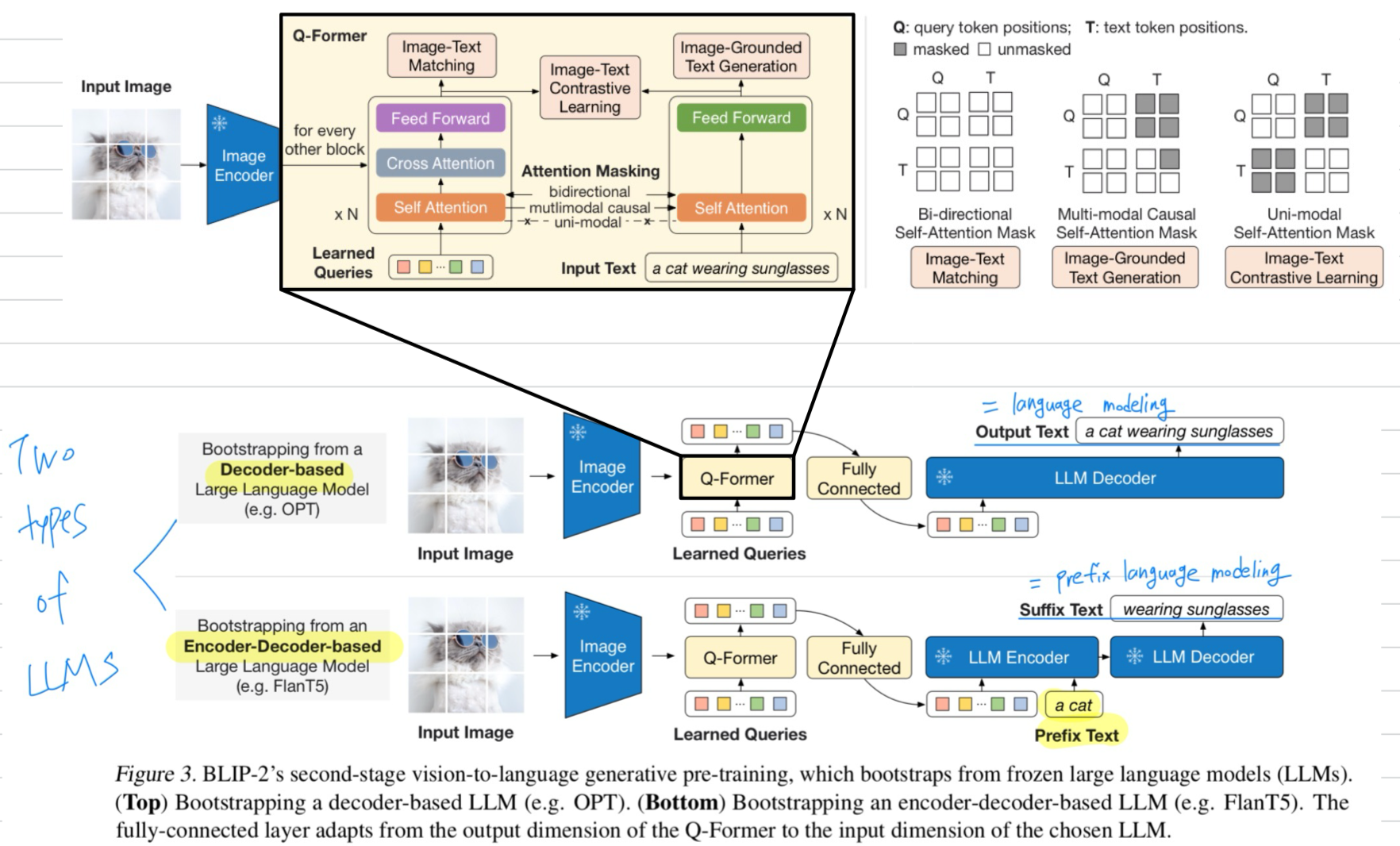
https://arxiv.org/abs/2301.12597