[2022 MLHC] [Simple Review] (ConVIRT) Contrastive Learning of Medical Visual Representations from Paired Images and Text
[Paper Review] VLM to LMM
이 논문을 읽게 된 이유
- CLIP 논문에서 이 논문(CoVIRT)을 기반으로 연구했다고 많이 언급되어, VLM에 대한 이해, background를 넓히고자 읽게 되었다.
- 아래는 실제 CLIP 논문에서 언급한 ConVIRT에 대한 내용이다.

Paper Info.

Abstract
(background와 문제 제기)
- medical images (e.g., X-rays)의 visual representations을 학습하는 것은 medical image understanding의 핵심이지만,
Human annotations의 부족으로 인해 발전이 제한되어 왔다.
기존 연구는 흔히 ImageNet pretraining에서부터 fine-tuning하는 방식을 사용하지만,
image characteristics이 서로 너무 달라 suboptimal하며,
또는 medical images와 함께 존재하는 textual report로부터 rule-based label extraction하는 방식을 사용하는데, 이는 inaccurate and hart to generalize하다.
(unsupervised constrative learning는 유망하지만 medical images에 대해 적용되기 힘들다.)
- 한편, 최근 연구들은 natural images에 대해 unsupervised contrastive learning을 적용해 고무적인 성과를 보여줬지만,
우리는 이러한 방법들이 medical images에서는 high inter-class similarity (class 간 시각적 차이가 거의 없음)이기 때문에 큰 효과가 없다는 것을 발견했다.
한편, 최근 연구들은 자연 이미지에 대해 비지도 대비 학습(contrastive learning)을 적용해 고무적인 성과를 보여줬지만, 우리는 이러한 방법들이 의료 영상에서는 클래스 간 시각적 차이가 매우 작기 때문에 큰 효과가 없다는 것을 발견했다.
(제안)
- 우리는 ConVIRT를 제안한다.
이는 medical visual representations과 자연스럽게 존재하는 paired descriptive text를 활용하여 medical visual representation을 학습하는
an alternative unsupervised strategy이다.
우리가 제안하는 pretraining 방식은 두 modalities 간 bidirectional contrastive objective를 사용하며,
domain-agnostic하고 어떠한 additional expert input도 필요로 하지 않는다.
(실험)
-
우리는 ConVIRT를 통해 pretrained weights를
4개의 medical image classification tasks와
2개의 zero-shot retrieval tasks에
transferring하여 test하였다.
그 결과, 대부분의 settings에서 strong baseline을 크게 outperform하는 image representations을 얻을 수 있음을 보였다. -
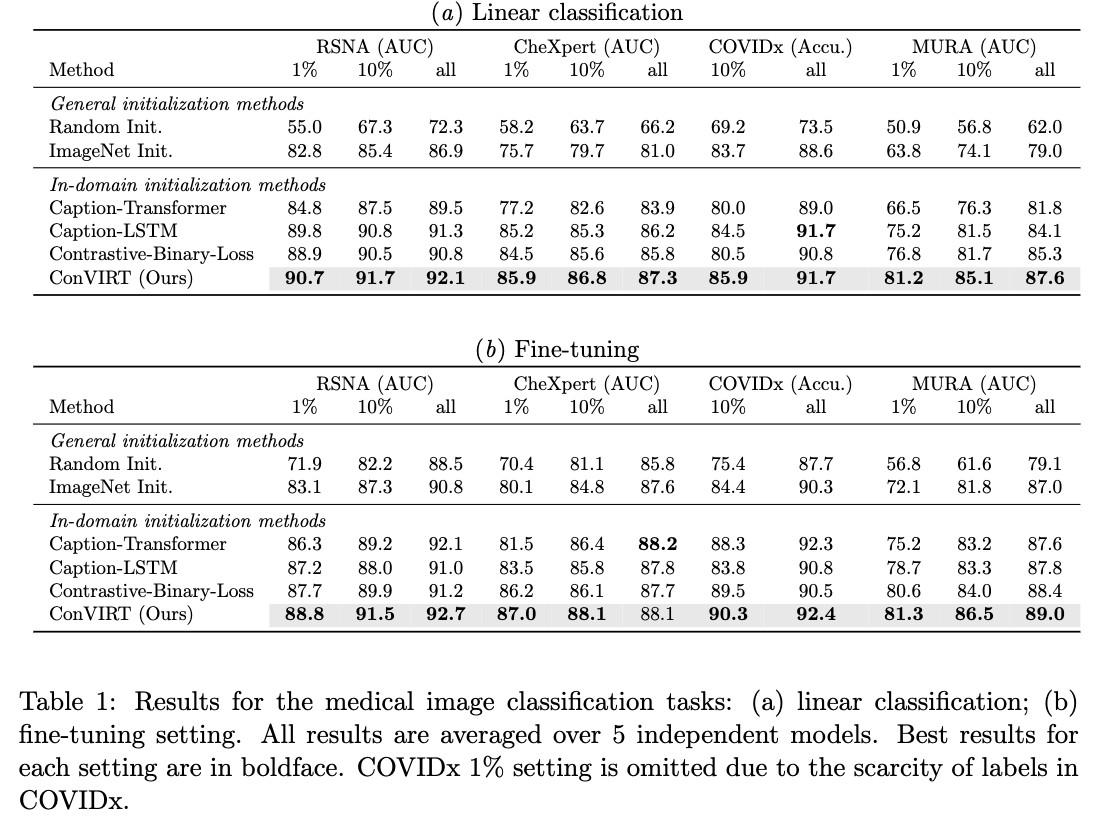
특히, 4개의 모든 classification tasks에서, 우리 방법은 ImageNet으로 initialized couterpart보다
단 10%의 labeled training data만으로도 better or comparable performance를 달성하여,
superior data efficiency를 보여준다.
(data efficiency란? 얼마나 적은 양의 labeled data로 좋은 성능을 낼 수 있는가?를 뜻함.
예를 들어, model A는 label 1000장을 써야 얻는 성능을 model B가 100장만으로도 낼 수 있다면, model B는 더 data-efficient하다고 함.)
1. Introduction
(background: deep learning을 이용한 medical image understanding은 여전히 문제가 많다.)
- medical image understanding은 healthcare를 혁실할 potential이 있으며 deeplearning 발전에 힘입어 빠르게 성장해 왔다.
그러나 아직, 일부 분야와 특정 조건에서만 expert-level performance가 달성되었을 뿐,
medical image understanding은 여전히 어려운 문제로 남아 있다.
이는 overall similar images(전체적으로 비슷해보이는 이미지들) 속에서 subtle visual distinctions (미세한 시각적 차이)를 기반으로
classification해야 하기 때문이다.
여기에 더해 annotated data의 extreme scarcity (극심한 부족)이 문제를 더 악화시킨다.
(background: 기존의 deep learning을 이용한 medical image understanding의 대표적인 두 가지 방식을 소개,
각각의 방식에 대한 문제점)
- existing work는 medical imaging tasks를 위한 annotations을 얻기 위해 크게 two general approaches를 사용해 왔다.
- 첫 번째 approach는 high-quality annotations created by modical experts를 사용하는 것이다.
그러나 the high cost of this approach로 인해, ImageNet과 같은 natural image datasets보다 훨씬 더 적은 규모의 datasets만 존재하게 되었다.
이를 보완하기 위해 많은 기존 연구들은 ImageNet에서 pretraining된 model weights를 transferring하는 방식에 의존해 왔다.
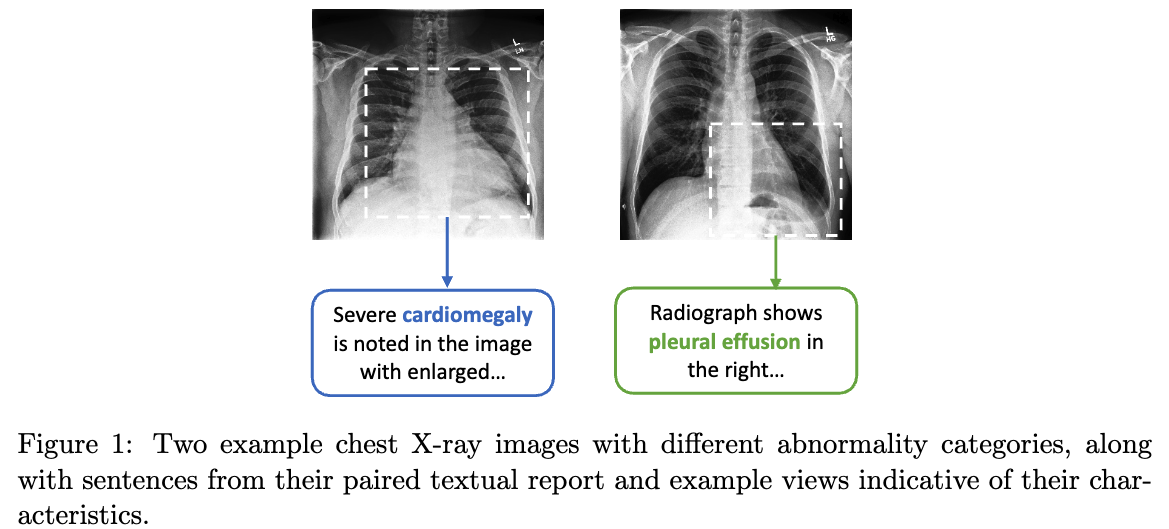
하지만 Figure 1에서 보듯, medical image understanding은 natural images과는 전혀 다른, very fine-grained visual features의 representation이 필요하다.
그 결과 Raghu et al. (2019)은 ImageNet pretraining이 simple random initialization과 비교해 별다른 이점을 제공하지 못하는 경우가 많다고 보고되었다. - 두 번째 popular approach는 image에 함께 존재하는 textual reports에서 expert-crafted rules 방식으로 labels을 extract하는 것이다.
이 방식은 medical experts들이 그들의 routine workflow로 the text data paired with medical images를
자연스럽게 생성하므로 일반적인 병원의 IT system에서는 text-image pair가 매우 풍부해서
더 큰 규모의 datasets을 만들 수 있다는 장점이 있다.
그러나 이러한 rule-based label extraction approach에는 two key limitations이 있다:- rule들은 종종 부정확하며 일부 categories에만 적용되므로 textual report data를 inefficient use하게 만든다.
- rule들은 domain-specific하고 the style of the text에 민감하기 때문에
cross-domain and cross-institution generalization difficult 문제가 있다.
- 첫 번째 approach는 high-quality annotations created by modical experts를 사용하는 것이다.
(contrastive learning에 대한 background: image view-based contrastive methods는
medical images에서 잘 동작되지 않음.
이는 medical image는 image 간의 아주 미세한 차이만 존재하기 때문임)
- unlabeled image data를 더 효율적으로 활용하기 위한 노력으로,
several recent studies는 natural images로부터 contrastive representation learning을 적용해 promising results를 보여왔다.
그러나 본 논문에서 보이듯, 이러한 image view-based contrastive methods를 medical images에 그대로 적용하면,
ImageNet pretraining 대비 얻는 이점이 매우 제한적이다.
이는 Figure 1에서 보이듯, medical images class 차이가 매우 미세(high inter-class similarity)하기 때문이다.
(제안)
-
이 연구에서는 abundant textual data의 장점과 unsupervised statistical approaches의 장점을 결합하여
medical images의 visual representation learning을 개선하는 새로운 방법을 제안한다.
우리는 Contrastive VIsual Representation Learning form Text (ConVIRT)를 소개하며,
이는 자연적으로 생성되는 image-text pairs를 활용하여 visual representation을 학습하는 framework이다. -
ConVIRT는 true image-text pairs와 random pairs를 구분하도록
image modality와 text modality 사이에 bidirectional contastive objective를 사용해 visual representations을 개선한다. -
ConVIRT를 medical image encoders의 pretraining에 적용한 결과,
medical image understanding에 필요한 the subtelty of visual features를
더 잘 capture하는 higher-quality in-domain image representations이 학습되는 것을 확인했다.
- exisitng methods와 비교했을 때, ConVIRT는 다음과 같은 장점을 가진다:
(1) medical specialty에 구애받지 않는 방식으로 paired text data 활용.
(2) requiring no additional expert input
(실험)
- 이를 통해 pretrained encoder weights를 2개의 medical specialties에 걸친 4가지 medical image classification tasks에
transferring하여 evaluate했다.
그 결과 ConVIRT는 널리 사용되는 ImageNet pretraining은 물론,
text-image pairs를 활용하는 strong baselines보다도 성능이 우수했다.
(내가 이해한 내용: text-image pairs를 활용하는 strong baselines은 위에서 기존 연구의 두 번째 방식. 즉, constrative learning을 활용한게 아니라, larger dataset을 이용하여 pretraining한 것을 의미하겠지?)
또한 SimCLR(Chen et al., 2020a), MoCo v2(Chen et al., 2020b) 등 image-only supervised learning methods보다도 더 나은 성능을 보였다.
특히, 4가지 모든 classification tasks에서 ConVIRT는 ImageNet initialized counterpart보다 필요로 하는 labeled training data의 10%만으로도 동등하거나 더 좋은 성능을 달성했다.
추가로, an image-image and a text-image retrieval task에서도 ConVIRT가 all baselines보다 superior함을 확인했다.
(concurrent works: ConvIRT는 처음에 2020년에 나왔고, publish는 2022에 됐다. 그 사이에 ConVIRT를 활용한 다양한 연구들이 있었다.)
- 또한 2020년 ConVIRT가 처음 발표된 이후,
이 방식은 CLIP(Radford et al., 2021), ALIGN(Jia et al., 2021)과 같은 후속 연구에 직접적인 영감을 주었으며,
이 model들은 ConVIRT-style pretraining을 much larger scale로 확장하여
SOTA general visual recognition capabilities를 달성했다.
future research를 위해, 우리는 model and the collected retrieval datasets을 공개했다.
https://github.com/yuhaozhang/convirt
2. Related Work
-
우리의 연구는 medical image classification과과
medical images로부터 textual report generation을 다루는 기존 연구와 가장 밀접한 관련이 있다.
이 분야의 많은 연구는 medical encoders를 initializing하기 위해
ImageNet과 medical image 간의 image 특성이 많이 다름에도 불구하고,
ImageNet에서 pretrained된 encoder weights를 사용하는 접근을 택해왔다. -
우리는 이러한 문제를 해결하기 위해 medical imaging에 in-domain(특화된) pretraining strategy를 제안하고,
medical reports와 image 쌍을 활용하는 여러 pretraining approaches와 비교한다. -
우리 연구는 최근의 image view-based contrastive learning에서 영감을 받았지만,
text modality를 활용한 contrastive learning을 사용한다는 점에서 근본적으로 다르다.
section 6에서 보이듯, text가 제공하는 추가되는 semantics 덕분에 constrative learning이 medical images의 high-quality representations 학습을 더 효과적으로 돕는다.
우리가 알기로는, 이러한 방향의 the first systematic attempt이다.
(vision-linguistic representation learning 연구와 ConVIRT가 다른 점)
- 또 다른 관련 분야는 vision-linguistic representation learning이다.
이 중 Ilharco et al. (2021)와 Gupta et al. (2020)은 우리와 유사한 cross-modality contrastive objective를 탐구했지만,
각각 visual-linguistic models 분석과 phrase grounding(문장 속 특정 phrase가 image의 어디를 가리키는지 찾아내는 기술)을 위한 것이었다.
우리 연구는 기존의 visual-linguistic pretraining과 다음의 중요한 차이점이 있다:- 기존 연구는 text-image pairs를 사용하더라도 binary contrastive prediction task 기반으로 visual representations 학습했지만,
우리는 새로운 cross-modality NCE objectives가 visual representations을 크게 향상시킴을 보여준다.
(NCE objectives란? Noise Contrastive Estimation. positive sample과 noise=negative sample을 구분하는 확률을 최대화하여 model을 학습하는 방법.
기존에는 image-image modality 또는 text-text modality의 NCE였는데, ConVIRT에서는 image-text modality에 대한 NCE. 즉, cross-modality NCE objecties로 학습시킴.) - 기존 연구는 preprocessing steps에서 image segmentation models로부터 추출된 object representations에 주로 의존했는데,
anatomical(해부학적) 구조에 대한 segmentations을 얻는 것이 매우 어렵기 때문에 이러한 방식은 medical image understanding tasks에는 적용성이 떨어진다. - 또한 기존 연구는 주로 visual question answering(VQA) 같은 visual-linguistic tasks에서 평가를 진행해 왔지만,
우리는 medical image understanding research의 핵심에 해당하는 classification과 retrieval tasks에 초점을 맞추어 평가한다.
- 기존 연구는 text-image pairs를 사용하더라도 binary contrastive prediction task 기반으로 visual representations 학습했지만,
(ConVIRT와 동시대 연구들)
- several concurrent paper들은 general-domain image problems에서 text data로부터 visual representation을 학습하는 문제를 다뤄왔다.
특히, 우리의 작업이 처음 공개된 이후 ConVIRT는 larger scale로 확장하여 다양한 general visual recognition studies에 적용되었는데,
그 예로 ConVIRT 방식을 단순화한 형태인 CLIP(Radford et al., 2021)과 ALIGN(Jia et al., 2021) 같은 model이 있다.
CLIP
이러한 성공적인 사례들은 ConVIRT가 human-written descriptive text를 활용해 visual representations을 학습하는 a promising strategy이며,
향후 vision recognition tasks의 SOTA를 한층 더 발전시킬 potention이 있음을 입증한다.
(ConVIRT 이후 연구들)
- 또한 이후 많은 연구들이 medical-domain image problems에 ConVIRT 방식을 확장했다.

3. Methods
3.1. Task Definition
-
우리는 먼저 우리의 representation learning setting을 정의하면서 시작한다.
paired input 라 가정하는데,
여기서 는 one or a group of images를 의미하며,
는 에 포함된 the imaging information을 설명하는 a text sequence이다. -
우리의 goal은 image 를 a fixed-dimensional vector로 mapping하는 parameterized image encoder function 를 학습하는 것이다.
이후 이 학습된 image encoder function 를 classification or image retrieval과 같은 downstream tasks에 transferring하는 데 관심이 있다.
본 연구에서는 image encoder 를 CNN으로 modeling한다. -
paired image-text data 는 많은 medical domains에서 주목할 필요가 있다.
예를 들어, radiologists(방사선과)와 같은 medical experts들은 많은 routine workflow에서 images에 대한 textual descriptions을 작성하며,
이러한 text 중 일부는 공개된 형태로 제공되기도 한다.
3.2. Constrastive Visual Representation Learning from Text
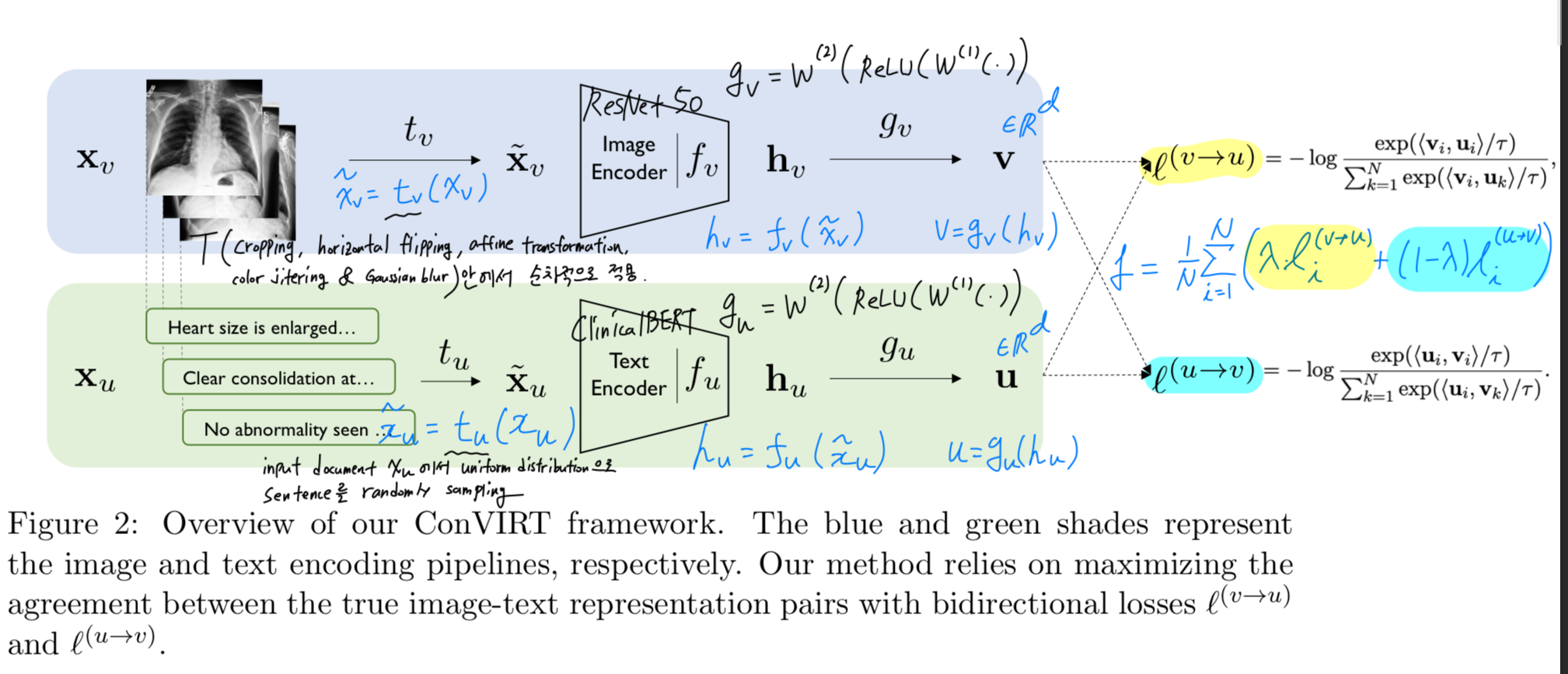
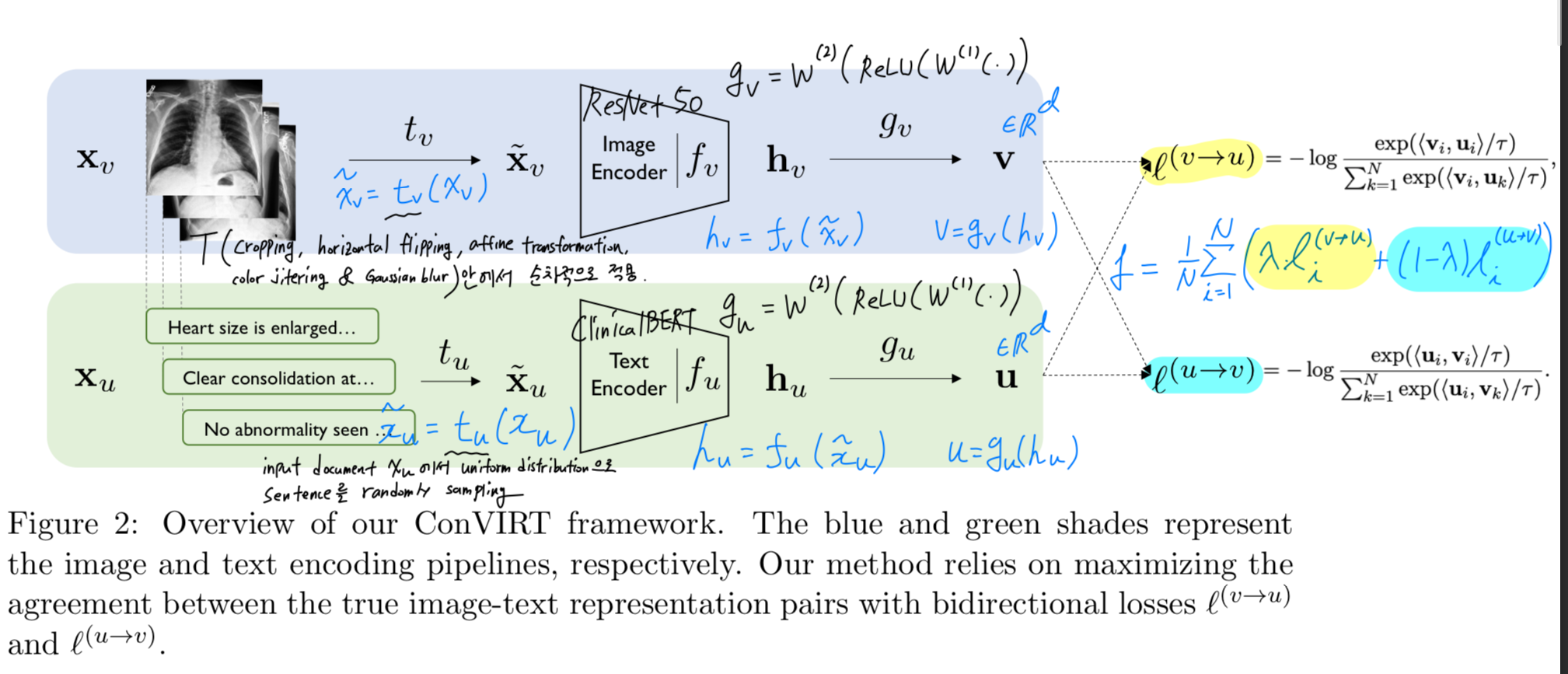
- 우리의 방법 ConVIRT가 를 어떻게 학습하는지에 대한 overview는 Figure 2에 나와있다.
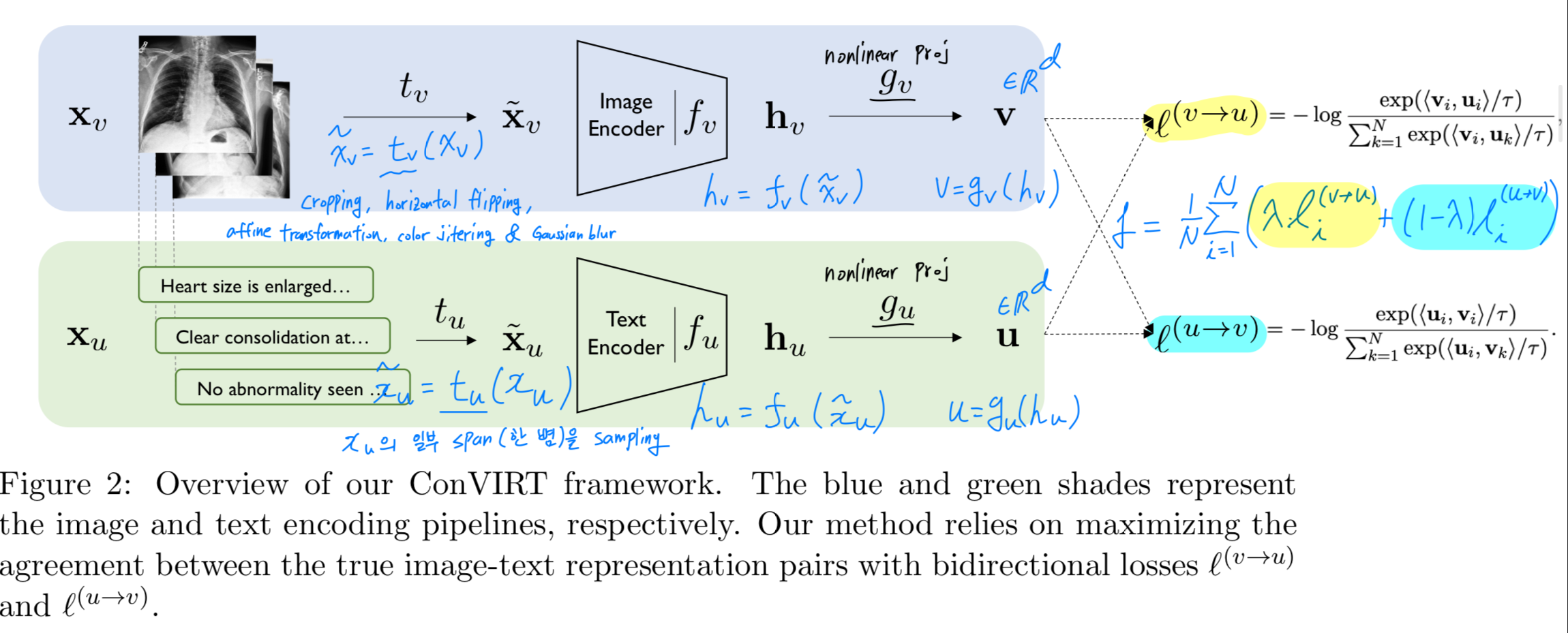
-
상위 단계에서 설명하자면,
우리의 방법은 각 input image 와 text 를
각각 동일한 -dimensional vector representations 와 로 변환하며,
두 경우 모두 similar processing pipeline으로 구성된다.input image:
각 input image 에 대해, 먼저 a sampled transformation function 를 이용해 로부터 random view 를 생성한다.
여기서, 는 a family of stochastic image transformation functions이다.
(나중에 나오지만 는 sequential applications of five random transformations: cropping, horizontal flipping, affine transformation, color jittering and Gaussian blur 을 사용했다고 한다.)
(그냥 image preprocessing & augmentation이라고 생각하면 될 듯)
이후 encoder function 가 를 a fixed-dimensional vector 로 변환하고,
a non-linear projection 을 통해 를 vector 로 다시 변환한다:
여기서 이다.

text input:
유사하게, text input 에 대해서는 sampling function 를 이용해 a span 를 얻고,
text encoder 와 projection function 를 통해
text representation 를 얻는다.
여기서 이다.
(span이란? (GPT 답변) text 내에서 연속된 token을 의미.
즉, 는 의료 보고서 전체 text에서 연속된 일부 span을 random하게 sampling하는 함수라고 생각하면 될듯.
-
projection function 와 는 두 modalities의 representations을 동일한 -dimensional space로 projection하여
contrastive learning이 가능하도록 한다.
- training time에는, training data로부터 개의 input pairs 를 minibatch로 sampling하고,
이들의 representation pairs 를 계산한다.
는 -th pair를 의미한다.
ConVIRT의 training objective는 두 가지 lss functions으로 구성된다.image-to-text contrastive loss:
the first loss function은 image-to-text contrastive loss for the -th pair 이다:
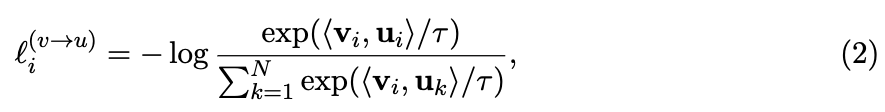
여기서 은 cosine similarity, 즉 로 정의된다.
는 a temperature parameter이다.
이 loss는 InfoNCE(Oord et al., 2018)의 형태와 동일하며, 이를 minimizing하면 representation functions에서 true pairs 간의 mutual information을 최대한 유지하는 encoders를 학습하게 된다.
직관적으로, 이는 가 true pair인지 predicting하도록 하는 -way classifier의 log loss이다.
이전 연구들이 same modality 간 contrasitve loss를 사용한 것과 달리, 우리의 image-to-text contrastive loss는 modality 간 asymmetric(비대칭적)이다.
(asymmetric하기 때문에 바로 밑에서 text-to-image contrastive loss도 동일한 방식으로 구하여, 두 loss를 weighted sum하여 symmetric하게 만들어주는 듯함.
image encoder와 text encoder가 모두 symmetric하게 학습될 수 있도록..)
(의 의미: image 를 기준으로 하여 올바른 text 를 찾는 -way classification 문제.
즉, "이 image에 맞는 text는?" 을 학습)text-to-image contrastive loss:
그러므로 우리는 second loss function으로, 다음과 같이 유사한 text-to-image contrastive loss도 정의한다:
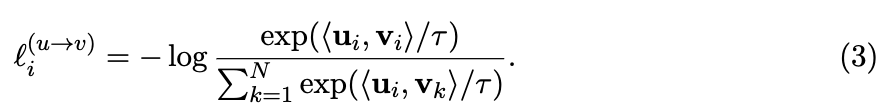
(이 의 의미: text 를 기준으로 하여 올바른 image 를 찾는 -way classification 문제.
즉, "이 text에 맞는 image는?" 을 학습)
- Our final loss는 다음과 같이 minibatch 내 all positive image-text pairs에 대해 두 loss의 weighted combination으로 계산된다:
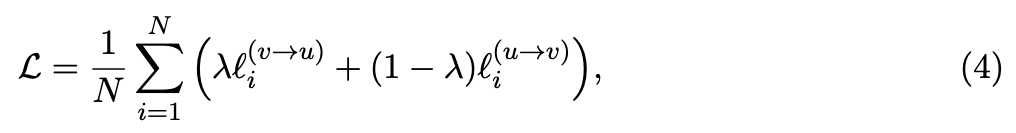
여기서 는 a scalar weight이다.
3.3. Realization
-
앞에서 정의한 ConVIRT framework가 image and text encoders, transformations, and prpojection layer에 대해서는 agnostic함을 강조한다.
이전 연구를 따라, 우리는 와 를 separate learnable single-hidden-layer neural networks로 modeling한다.
즉, .
도 마찬가지. -
image encoder 로는 모든 실험에서 ResNet50 architecture 사용.
text encoder 로는 BERT encoder를 사용.
모든 output vectors에 대해 max-pooling layer를 적용.
우리는 a suite of clinical NLP tasks에서 SOTA를 달성한 MIMIC clinical 기록으로 pretrained된 ClinicalBERT weights로 encoder를 initialize했다.
학습 시에는 BERT encoder의 embedding과 첫 6개의 transformer layer는 freeze하고, 마지막 6개의 layer만 fine-tuning하여 contrastive task에 맞게 적응하도록 한다. -
image transformation family 에 대해서(이 안에서 가 sampled됨)는 5가지 random transformations을 순차적으로 적용한다:
cropping, horizontal flipping, affine transformation, color jittering, Gaussian blur.
최근 contrastive visual learning 연구(Chen et al., 2020a,b)와는 달리, medical image는 보통 흑백이기 때문에
color jittering에서는 밝기(brightness)와 대비(contrast) 조정만 적용한다.
text transformation funtion 에 대해서는 input document 에서 setence를 uniform dsitribution으로 randomly sampling하는 단순한 방식 (즉, 는 매 minibatch마다 한 문장을 random하게 선택한 것)을 사용한다.
more aggressive transformation을 사용하지 않은 이유는 sentence level의 sampling이 text span의 semantic meaning을 더 잘 보존하기 때문이다.
section 3.2.와 section 3.3.의 내용을 아래 figure 2에 그려보면, 대략 아래와 같은 구조로 되어 있음.
4. Experiments
전반적으로 실험 세팅에 대한 설명.
실제 실험 결과는 section 5.에서 함
4.1. Data for Pretraining
(skip)
- two separate image encoders using two separate image-text datasets을 pretraining하여 ConVIRT를 evaluate함
4.2. Evaluation Tasks & Data
- "We evaluate our pretrained image encoders on three medical imaging tasks:
image classification, zero-shot image-image retrieval and zero-shot text-image retrieval."
4.3. Baseline Methods
- We compare ConVIRT against the following standard or competitive initialization methods:
- Random Init
- ImageNet Init
- Caption-LSTM
- Caption-Transformer
- Contrastive-Binary-Loss
5. Results
5.1. Classification Tasks
5.2. Retrieval Tasks
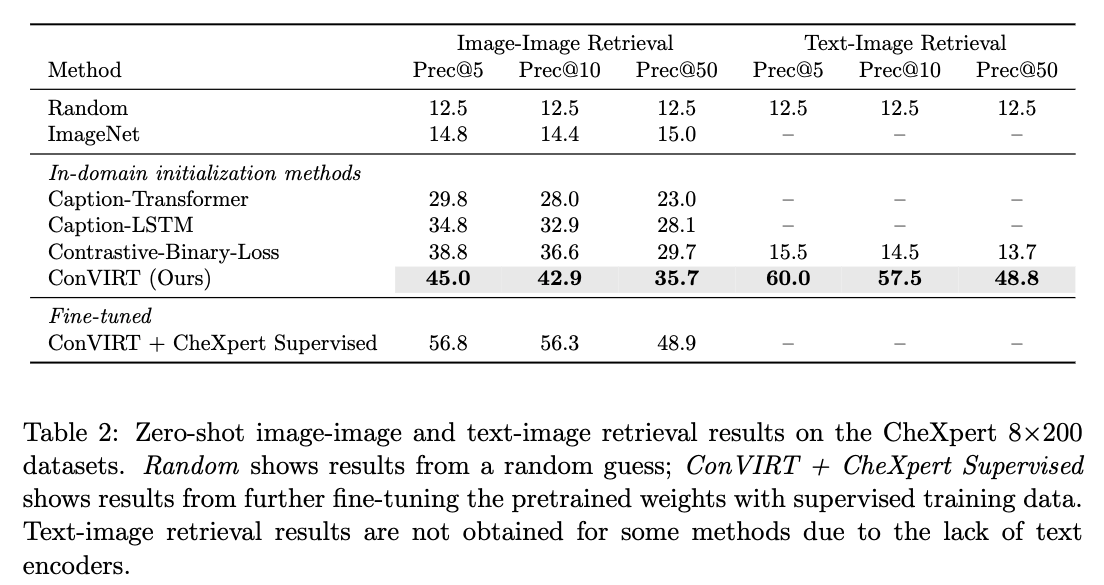

6. Analysis and Discussion
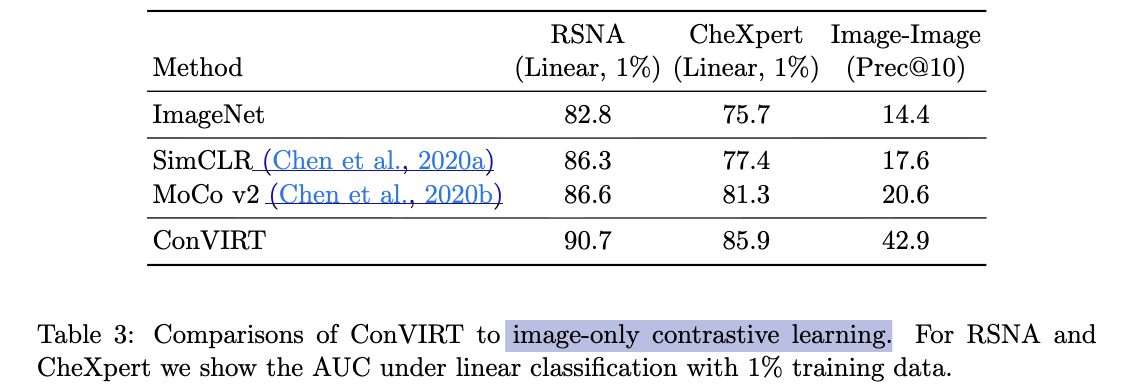
Comparisons to Image-only Contrastive Learning
- image only contrastive learning에서도 적당한 성능 향상이 있었지만,
우리의 image-text contrastive learning이 더 효과적임.
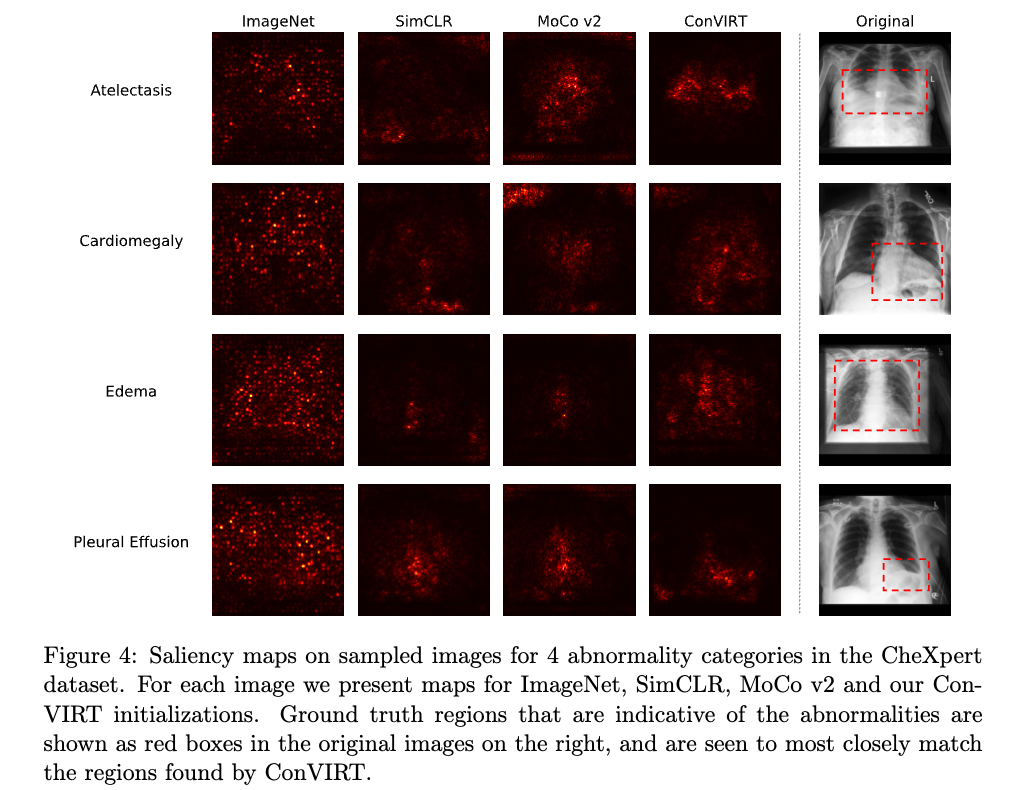
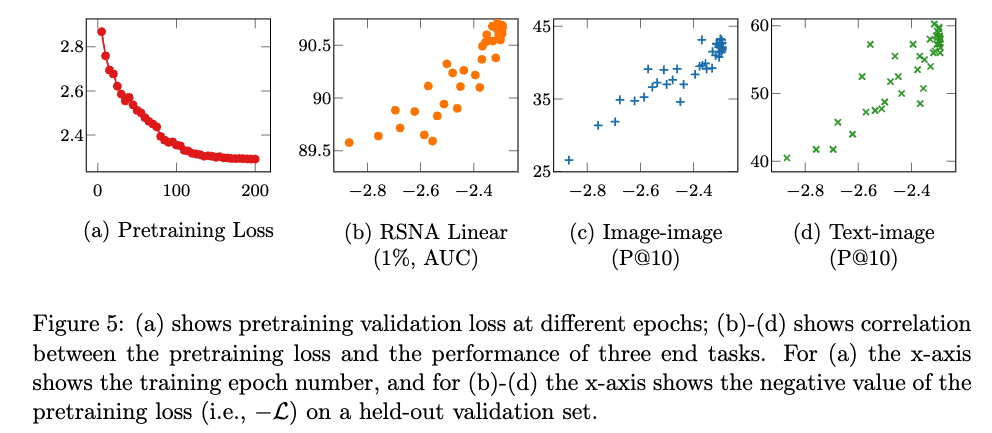
Correlation Between Contrastive Loss and End Task Performance
Limitations
- 이 연구는 주로 ConVIRT를 기존의 ImageNet initialization, image captioning-based initialization, and SimCLR과 MoCo를 포함한 image-only contrastive learning approaches와 비교하여,
image-text pretraining의 data efficiency and effectiveness를 입증하는 데 초점을 둔다.
우리는 이후 연구들, 예를 들어 ConVIRT를 확장한 LoVT or GloRIA와는 비교하지 않았다.
이러한 비교는 해당 후속 연구들에 이미 포함되어 있기 때문이다.
이 논문의 핵심
- 이 논문은 medical image와 그에 paired되는 text report data를 활용한
image-text contrastive learning을 통해,
전문가의 labeling없이도 medial visual representation을 효과적으로 pretraining하는 ConVIRT framework 제안.
특히나 image 간의 미묘한 차이만 존재하는 medical image의 특성에 대해, image-text contrastive learning이 효과적임을 보여줌.
