[2021 ICCV] CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Paper Info.

Abstract
- 최근 ViT는 CNNs에 비교하여, image classification에서 promising resutls를 달성하고 있다.
이 연구에서, 우리는 image classification을 위한 transformer models 에서의 multi-scale feature representations을 학습하는 방법을 연구한다.
이를 위해, 우리는 stronger image features를 만들기 위한 서로 다른 sizes의 image patches (i.e., tokens in a transformer)를 결합하는 a dual-branch transformer를 제안한다.- 우리의 방법은 small-patch와 large-patch를 서로 다른 computational complexity를 가진 two separate branches로 처리하며,
이러한 patch들은 서로를 complement (보완)하기 위해 여러 번 purely (순수하게) attention만으로 결합된다. - 추가로, computation을 줄이기 위해, 우리는 a simple yet effective token fusion module based on cross attention을 개발했다.
token fusion module은 각 branch에서 a single token을 query로 사용하여 other branches와의 information 교환을 수행한다. - Our proposed cross-attention은 다른 quadratic time을 갖는 연산들을 대신하여, computational and memory complexity 둘 다 linear time만 필요로 한다.
- 우리의 방법은 small-patch와 large-patch를 서로 다른 computational complexity를 가진 two separate branches로 처리하며,
1. Introduction
(배경)
-
NLP tasks의 sequence-to-sequence modeling은 big leap forward를 이끌었다.
The greate success of transformers 덕분에
vision community에서도 dominant CNN based architectures such as ResNet and EfficientNet에 비해
transformers가 strong competitor가 될 수 있는지에 대한 부분적인 관심이 sparked되었다. -
Vision Transformer (ViT)는 첫 convolution-free transformers로,
a sequence of embedded image patches를 input으로 하여 standard transformer에 입력되었다.
하지만, ViT는 ImageNet21K and JFT300M과 같이 very large datasets을 필요로 한다.
다음으로, DeiT는 data augmentation과 model regularization이 high-performance ViT models을 fewer data로 학습가능하게 했다.
그 이후로, ViT는 다른 측면으로 [ReFs...] its efficiency and effectiveness를 발전시키기 위한 several attempts가 시작되었다.
(동기 & 제안)
-
본 연구는 stronger vision transformers를 만드는 연구의 동일 선상으로,
우리는 how to learn multi-scale feature representations in transformer models for image recognition을 연구한다.
Multi-scale feature representations은 many vision tasks에서 유익하다고 증명되어 왔다.
하지만 vision transformers에서의 potential benefit은 아직 증명되지는 않았다.
Big-LittleNet and Octave convolutions과 같은 multi-branch CNN architectures의 effectiveness에 motivated되어,
우리는 image classification을 위해 stronger visual features를 만들어내는 서로 다른 sizes의 image patches를 결합하는 a dual branch transformer를 제안한다. -
Our approach는 small and large patch tokens을 갖고 있어, 서로 다른 computational complexities를 갖는 two separate branches를 만들고,
이 tokens들은 서로 보완하기 위해 multiple times (몇 번) fusion된다.
Our main focus of this work는 vision transformers에 적합한 feature fusion methods를 개발하는 것으로, 이는 우리가 아는 한 아직 다뤄진 바가 없다.
이를 위해 우리는 efficient cross-attention module을 제안한다.
이 module에서는 각 transformer branch가 non-patch token을 agent로 생성하여, attention을 통해 다른 branch와 information을 exchange한다.
이러한 방식은 일반적으로 quadratic time이 소요되는 attention map 생성을 linear time으로 할 수 있게 한다.
또한 각 branch의 computational loads를 적절히 조절한 결과, our proposed approach는 DeiT 보다 FLOPs와 model parameters의 소폭 증가에도 불구하고 성능이 2% 이상 향상되었다.
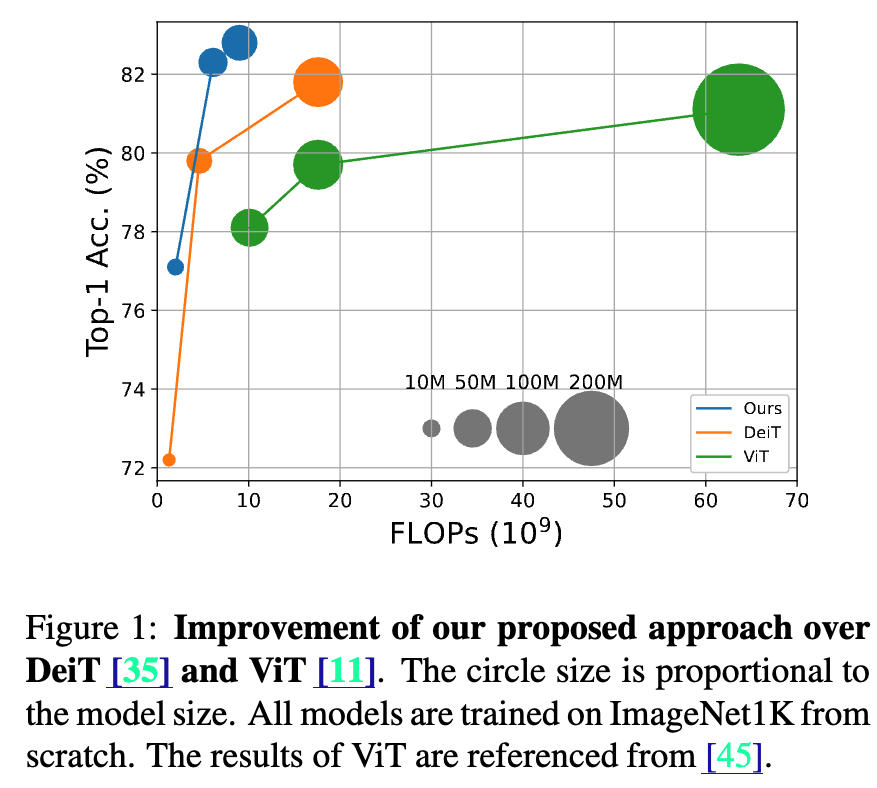
-
The main contributinos of our work are as follows:

이 연구에서 하고자 하는 것:
vision transformer에서 더 나은 image recognition을 위해, multi-scale feature representation을 사용한다.
그래서 서로 다른 scale의 두 feature(branch) 사이의 token fusion scheme based on efficient cross-attention을 도입하였다.
2. Related Works
CNN with Attention
-
몇 연구에서는 its complexity로 인해 attention scope를 local region으로 제한함.
-
LambdaNet [2]은 최근에 both content and position-based interactions에 대한 an efficient global attention을 제공했다.
-
이 연구는 앞선 mix convolution with self-attention과 반대로,
built on top of pure self-attention network like vision Transformer로 만들어졌다.
(왜 굳이? mix convolution with self-attention가 pure self-attention network보다 더 좋으면, pure self-attention network를 고집해서 만드는게 불필요하지 않나?
기존 연구에 대한 문제를 해결하기 위한 제안은 아닌듯함.)
Vision Transformer
- [ReF]...
Unlike these approaches, we propose a dual-path architecture to extract multi-scale features for better visual representation with vision transformers.
Multi-Scale CNNs
- [ReF]...
While multi-scale features have shown to benefit CNNs, it’s applicability for vision transformer still remains as a novel and largely under-addressed problem.
3. Method
- Our method는 vision transformer를 기반으로 만들어졌다.
그래서 우리는 ViT에 대한 a brief overview를 설명하고
our proposed method (CrossViT) for learning multi-scale features for image classification를 설명하겠다.
3.1. Overview of Vision Transformer
-
ViT는 먼저 an image를 a certain patch size로 잘라서 a sequence of patch tokens을 만들어낸다.
그 다음 each patch에 linearly projecting해서 tokens으로 만든다.
original BERT에서 했던 것처럼, the sequence에 additional classification token (CLS)를 추가한다.
또한, transformer encoder의 self-attention은 position-agnostic하고 vision applications은 position information이 매우 필요로 하기 때문에 each token에 position embedding을 추가한다.
이후, 모든 tokens들은 stacked transformer encoders를 통과하고, 최종적으로 classification을 위해서 CLS token이 사용된다.
A transformer encoder는 feed-forward network (FFN)를 포함한 multiheaded self-attention (MSA)로 구성된 each block의 sequence로 구성되어 있다.
FFN은 two-layer multilayer perceptron with expanding ratio at the hidden layer를 포함하고,
one GELU non-linearity가 the first linear layer 이후에 적용된다.
Layer normalization (LN)과 residual shortcuts은 every block 이후에 적용된다.
The input of ViT, 는 -th block의 processing에서 다음과 같이 표현된다 :
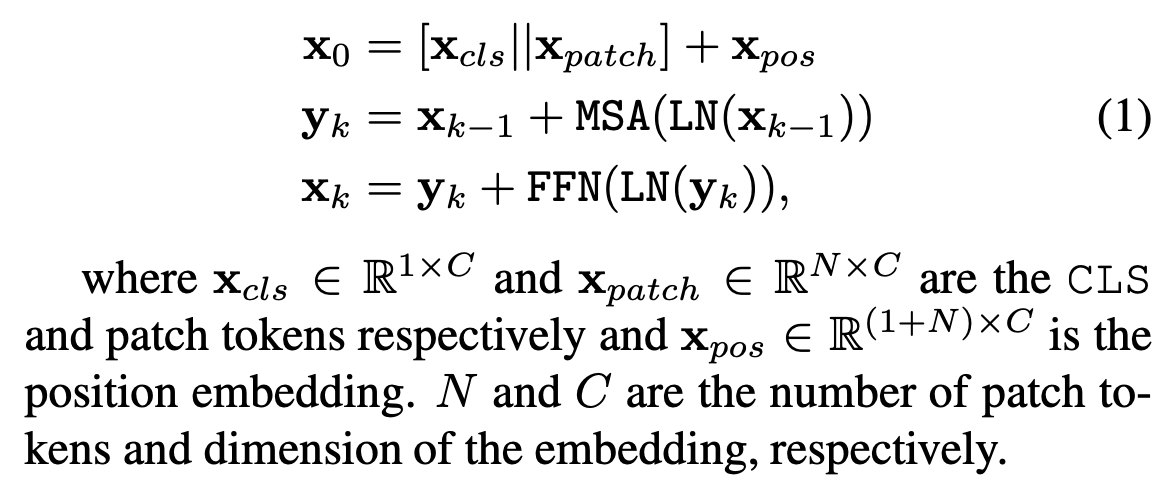
-
ViT와 CNN의 one very different deisgn은 CLS token이라는 점을 주목해야 한다.
CNN에서는 일반적으로 모든 spatial locations의 features들을 averaging함으로써 finaly embedding을 얻는 반면,
ViT는 각 transformer encoder에서 patch tokens들과 interacts하는 CLS token을 final emedding으로 사용한다.
따라서 우리는 CLS를 모든 patch tokens을 summarize하는 agent로 간주하며,
이에 따라 the proposed module은 a dual-path multi-scale ViT를 만들기 위해 CLS를 기반으로 설계되었다.
3.2. Proposed Multi-Scale Vision Transformer
- patch size의 granularity (세밀함)은 ViT의 accuracy and complexity에 영향을 미친다.
fine-grained patch size를 사용하면, ViT의 성능이 향상될 수 있지만, 그만큼 FLOPs와 memory consumption이 증가한다.
예를 들어, patch size가 16인 ViT는 patch size가 32인 ViT보다 성능이 6% 더 높지만,
전자는 후자보다 4배 더 많은 FLOPs를 필요로 한다.
이에 motivated되어, 본 논문에서는 more fine-grained patch sizes에서 오는 장점을 활용하면서도 complexity를 유지하려는 접근 방법을 제안한다.
구체적으로, 서로 다른 scale (or patch size in the patch embedding)에서 작동하는 두 개의 branch를 갖는 a dual-branch ViT를 도입한 뒤, 이들 branch 간 information을 fusion할 수 있는 simple yet effective module을 제안한다.
-
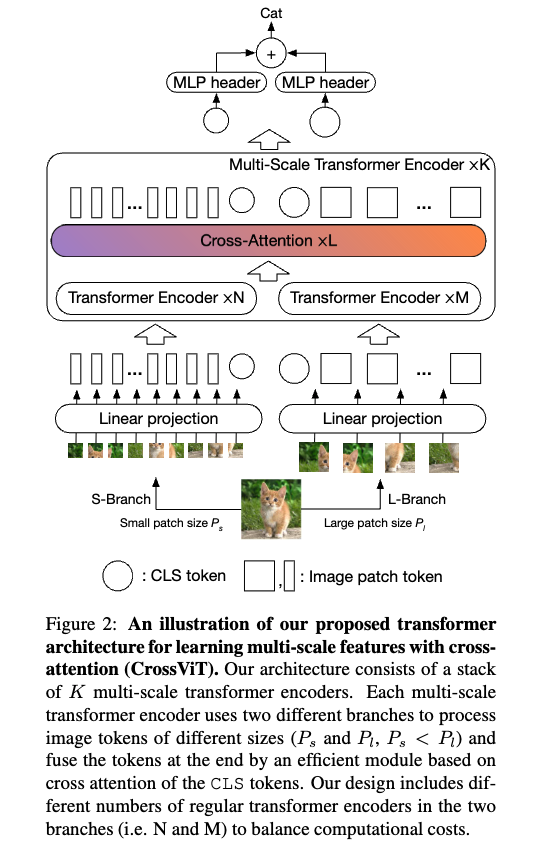
Figure 2는 our proposed Cross-Attention Multi-Scale Vision Transformer (CrossViT)의 network architecture를 설명한다.
Our model은 two branches(1. L-Branch, 2. S-Branch)로 구성된 개의 multi-scale transformer encoders로 구성된다.
(1) L-Branch는 a large (primary) branch로, more transformer encoders와 wider embedding dimensions을 사용하며, coarse-graind patch size ()을 활용한다.
(2) S-Branch는 a small (complementary) branch로, fewer transformer encoders and smaller embedding dimensions을 사용하며,
fine-grained patch size ()을 활용한다.
이 두 branch는 총 번에 걸쳐 fusion되며, 마지막에는 두 branch의 CLS token이 prediction에 사용된다.
또한 ViT와 마찬가지로, 각 branch의 모든 token에는 multi-scale transformer encoder에 입력되기 전에 position information을 학습하기 위해 learnable position embedding이 추가된다.
-
Effective feature fusion은 multi-scale feature representations 학습의 key이다.
우리는 four different fusion strategies에 대해서 탐구하였다:
three simple heuristic approaches and the proposed cross-attention module as shown in Figure 3.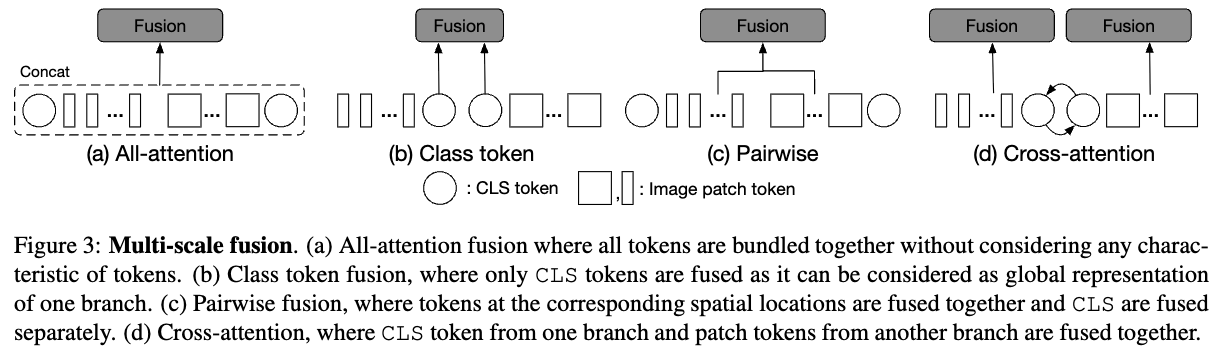
3.3. Multi-Scale Feature Fusion
- 를 branch 의 token sequence (both patch and CLS tokens)라 하자,
는 large (primary) branch 또는 small (complementary) branch에서 또는 가 될 수 있다.
과 는 각각 CLS와 branch 의 patch tokens을 나타낸다.
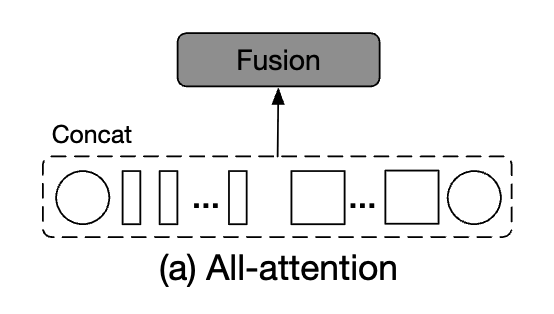
All-Attention Fusion
- 직관적인 방법은 간단하게 두 branches로부터 나오는 모든 tokens을 각 token의 property를 고려하지 않고 concatenate하는 것이다.
그리고 self-attention module로 information을 fusion한다.
이 방법은 모든 tokens들이 self-attention module을 통과하기 때문에 quadratic computation time을 필요로 한다.
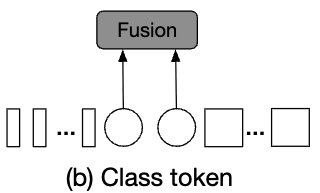
Class Token Fusion
- CLS token은 prediction에서 the final embedding으로 사용되기 때문에
CLS token을 abstract global feature representation of a branch로 간주할 수 있다.
그러므로, a simple approach는 two branches의 CLS tokens을 합치는 것이다.
이 방법은 only one token만 처리되는 데 필요하기 때문에 very efficient하다.
CLS tokens이 fusion되면, information은 patch tokens at the later transformer encoder로 passed back될 것이다.
더 공식화하면, output of this fusion module은 다음과 같이 표현된다:
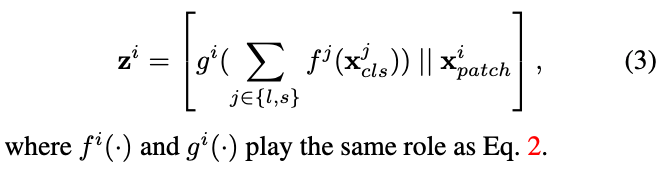
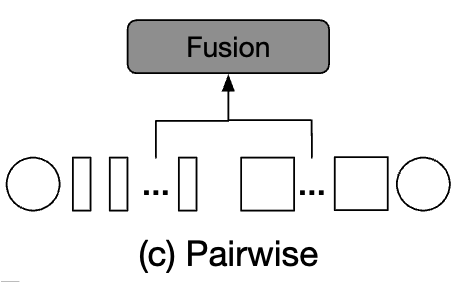
Pairwise Fusion
- Figure 3(c)는 pairwise fusion에서 두 branches가 어떻게 fusion되는지 보여준다.
두 branch의 patch tokens들은 서로 다른 spatial location of an image에 위치하기 때문에,
fusion을 위한 a simple heuristic way는 그들을 그들의 spatial location에 기반하여 combine하는 것이다.
하지만, 두 branches들은 서로 다른 sizes로 process되므로, 서로 다른 patch tokens 수를 갖는다.
그래서 우리는 먼저 spatial size를 align하기 위해 interpolation을 수행하고, 그리고 나서 pair-wise manner에서 both branches의 patch tokens을 fusion한다.
반면에, 두 CLS은 독립적으로 fusion된다.
The output of pairwise fusion of branch 과 는 다음과 같이 표현된다
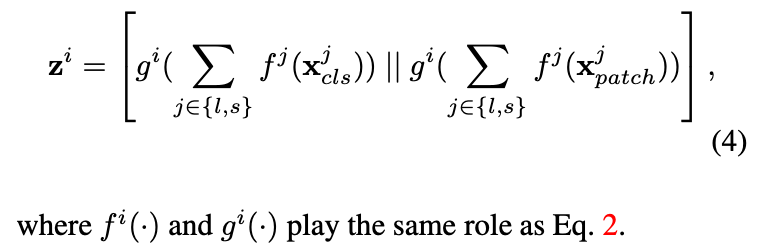
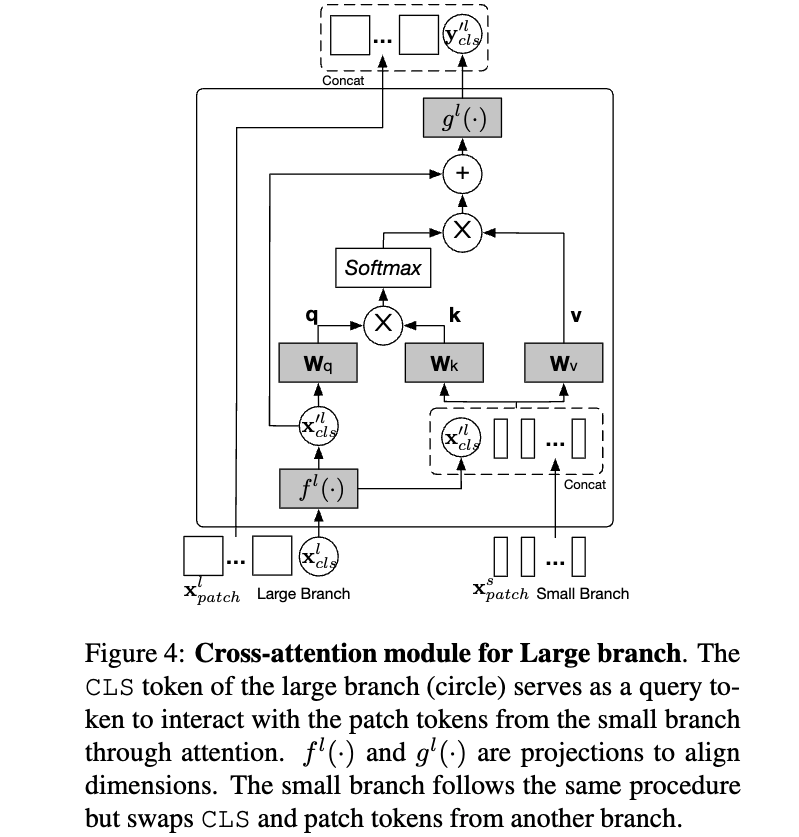
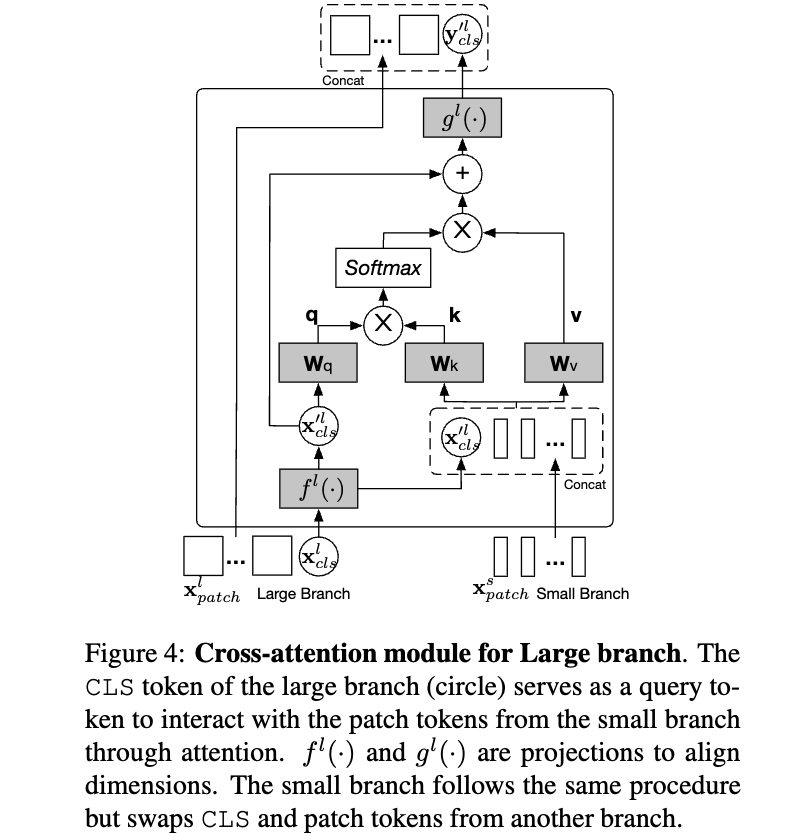
Cross-Attention Fusion (Ours)
(구체적인 ours 설명)
- Figure 3(d)는 our proposed cross-attention의 basic idea를 보여준다.
여기서의 fusion은 한 one branch의 CLS token과 the other branch의 patch tokens 간의 fusion을 포함한다.
구체적으로, multi-scale features를 보다 효율적이고 효과적으로 fusion하기 위해, 각 branch의 CLS token을 an agent to exchange information으로 사용하여 다른 branch의 patch tokens들과 먼저 상호작용하게 하고, 이후 자신의 branch로 다시 back project한다.
CLS token은 이미 자신의 branch 내 모든 patch token의 abstract information을 학습하고 있기 때문에,
다른 branch의 patch tokens들과 상호작용함으로써 다른 scale의 정보를 포함할 수 있다.
이후, 다른 branch와의 fusion을 마친 CLS token은 다음 transformer encoder에서 자기 branch의 patch tokens들과 다시 interaction하며,
이 과정을 통해 다른 branch로부터 학습된 information이 자기 branch의 patch tokens에 전달되어 각 token의 representation이 강화된다.
이후에는 cross-attention module을 large branch (L-branch)에 대해 설명하며, small branch (S-branch)에 대해서도 index 과 를 바꾸는 것만으로 동일한 절차가 적용된다.
내가 이해한 핵심 :
아래 Figure 4는 Large branch에 대해서 적용한 그림이고, 마찬가지로 Small branch에서도 동일한 연산이 진행됨.
각 branch들의 CLS token은 상대 branch로 가서 정보를 취득해 오는 agent 역할이고,
가서 상대 branch에 대한 정보를 학습한 것을 원래 자신의 branch로 복귀하여 자신의 patch tokens들에게 배운 것을 전파함.
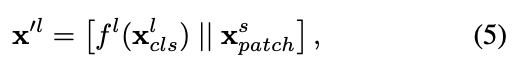
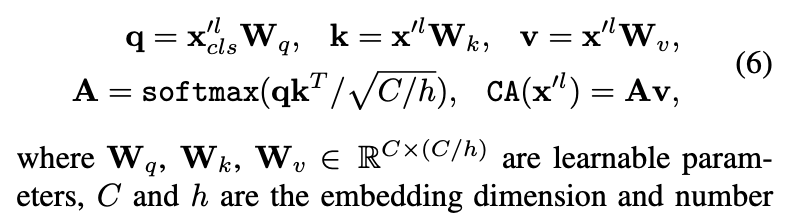
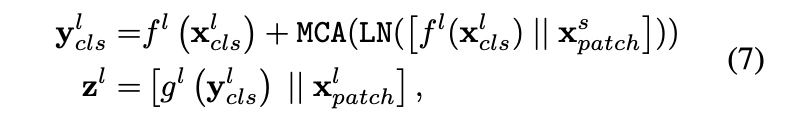
4. Experiments
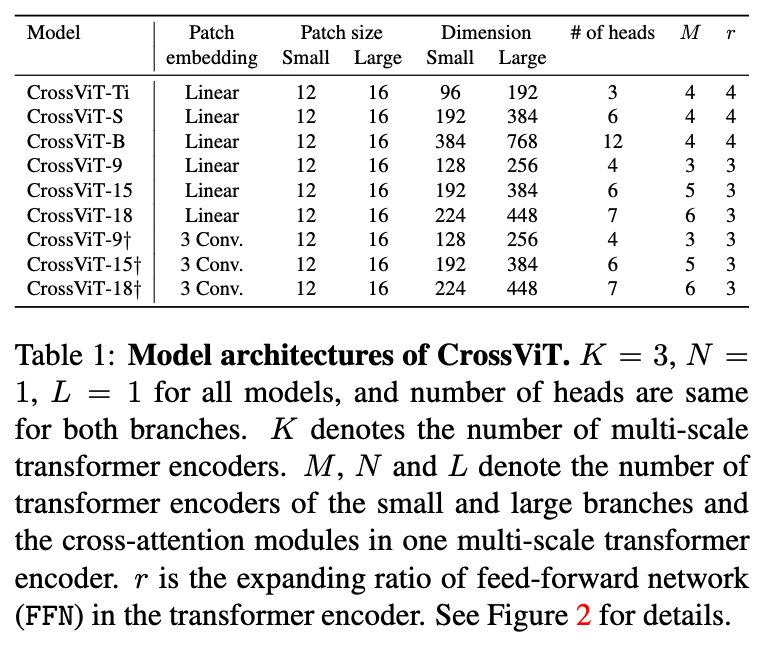
- model architectures 정의
- Main Result