[2021 ICLR] [Simple Review ] ( CompOFA) COMPOFA: COMPOUND ONCE-FOR-ALL NETWORKS FOR FASTER MULTI-PLATFORM DEPLOYMENT
[Paper Review] Efficient and Scalable
목록 보기
32/32
1년 전 2020 ICLR에 나온 Once-For-All (OFA) network의 문제를 개선한 논문인 것 같아서 간단히만 읽음
OFA에 대해 review한 post
Paper Info.

Abstract
(background & related works)
- 기존 Once-For-All (OFA)는 a constant training cost 하에서,
한 번에 several models을 jointly train하는 approach를 제안했었다.
(문제 제기)
- 기존 OFA는
- remains 40-50 GPU days의 training cost 존재
- a combinatorial explosion of sub-optimal model configurations
(제안: CompOFA)
- we reduce this search space and the training budget
- We incorporate insights of compound relationships between model dimensions to build CompOFA, a design space smaller by several orders of magnitude.
(실험)
- skip
1. Introduction
(Background)
- skip
(Related Work: OFA)
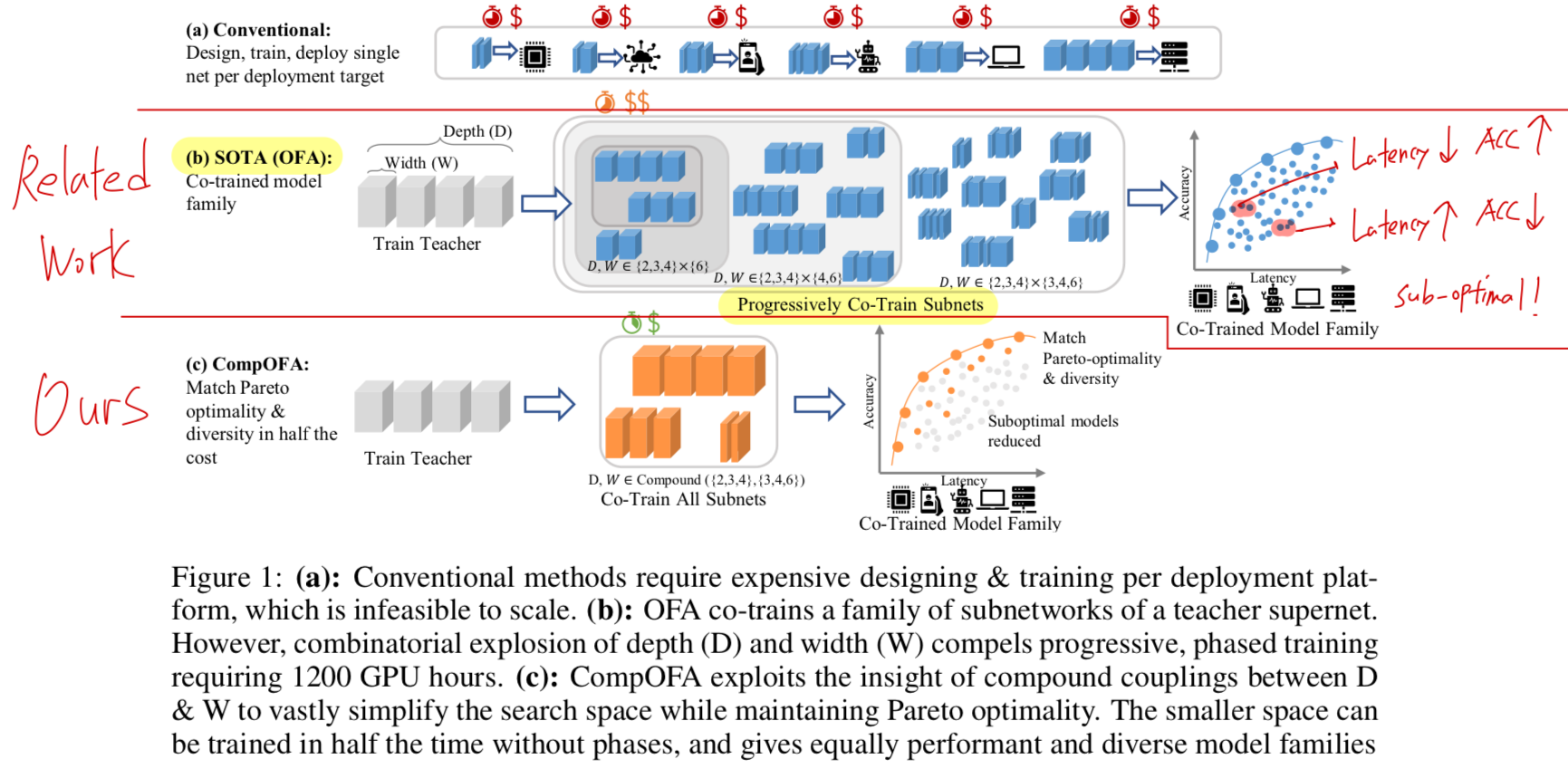
- "Repeating such intesive processes for each deployment target is prohibitively expensive."
그래서 이 challenge를 해결하기 위해 Once-For-All (OFA)에서는
a novel progressive shrinking algorithm을 통해 serach and training phase를 decoupling하였다.
OFA는 a family of models of varying depth, width, kernel size, and image resolution을 만들었다.
이 model들은 그들의 intersectinv weights를 sharing함으로써 single-shot으로 jointly trained되었다.
(Limitations of OFA)
- OFA가 trained되면, search techniques으로 specific deployment targets에 만족하는 specialized sub-networks를 추출해야 한다.
이러한 massive search space는 여전히 prohibitively expensive한 training cost를 유도한다.
비록 이 cost가 여러 deployment targets에 걸쳐 분산될 수는 있지만, 그럼에도 불구하고 OFA의 경우 1200 GPU hours에 달할 정도로 상당하다.
이러한 search space는 가능한 모든 model combination을 학습하는 데서 비롯되며,
이들 중 상당수는 Figure 1(b)에 나타난 accuracy-latency pareto frontier보다 훨씬 아래에 위치한다.
이러한 exhaustive approach는 이렇게 vast space에서 accuracy- or latency- guided exploration(탐색)의 기회를 놓치게 되어, clear inefficiency를 초래한다.
(가설)
- 반면, 우리는 이러한 large search space가 unnecessary하다고 주장한다.
그 이유는 두 가지이다.- 첫째,
기존의 관행 및 경험적 연구들에 따르면,
depth, width, and resolution과 같은 model dimension들은 서로 orthogonal(독립적)이지 않으며,
이들 사이에 compound coupling을 따르는 model들이 unconstrained setting을 가진 model들보다
better accuracy-latency trade-off를 보인다는 점이 밝혀졌다.
직관적으로 말하면, model capacity를 한 dimension(예: depth)에서 증가시킬 때에는 다른 dimension(예: width)에서도 이에 대응하는 증가가 accompanying(동반)될 때 더 잘 향상된다. - 둘째,
practical systems deployment 관점에서는 약 1ms 수준의 훨씬 coarser latency granularity(단위)만으로도 충분하다.
- 첫째,
(제안: CompOFA)
- we propose CompOFA - a model design space leveraging compound couplings between model dimensions, and demonstrate the following:

2. Related Work
Skip
3. Motivation
3.1. Design Space Parameterization
3.2. Compound Relation of Model Dimensions
4. Compound OFA
4.1. Coupling Heuristic
4.2. Training Speedup

Efficient Deep Learning