[Paper Review] Efficient and Scalable
1.[2016 ICLR] Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding

Paper Information Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding authors : Song Han, Huizi
2.[2017 ICLR] Pruning Filters for Efficient Convnets
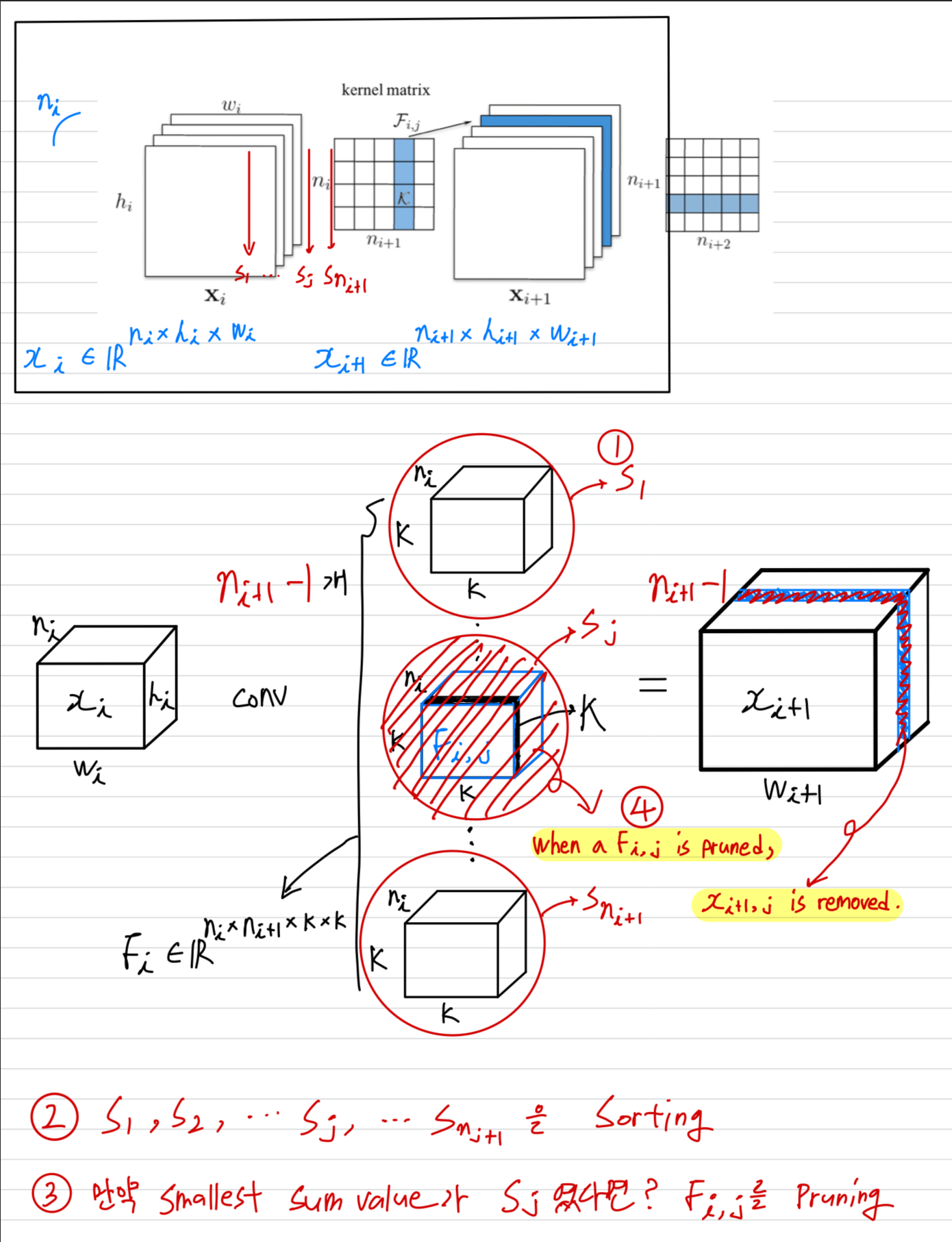
paper : Pruning Filters for Efficient ConvNetsPublished as a conference paper at ICLR 2017authors : Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet,
3.[CVPR 2017][ResNeXt] Aggregated Residual Transformations for Deep Neural Networks
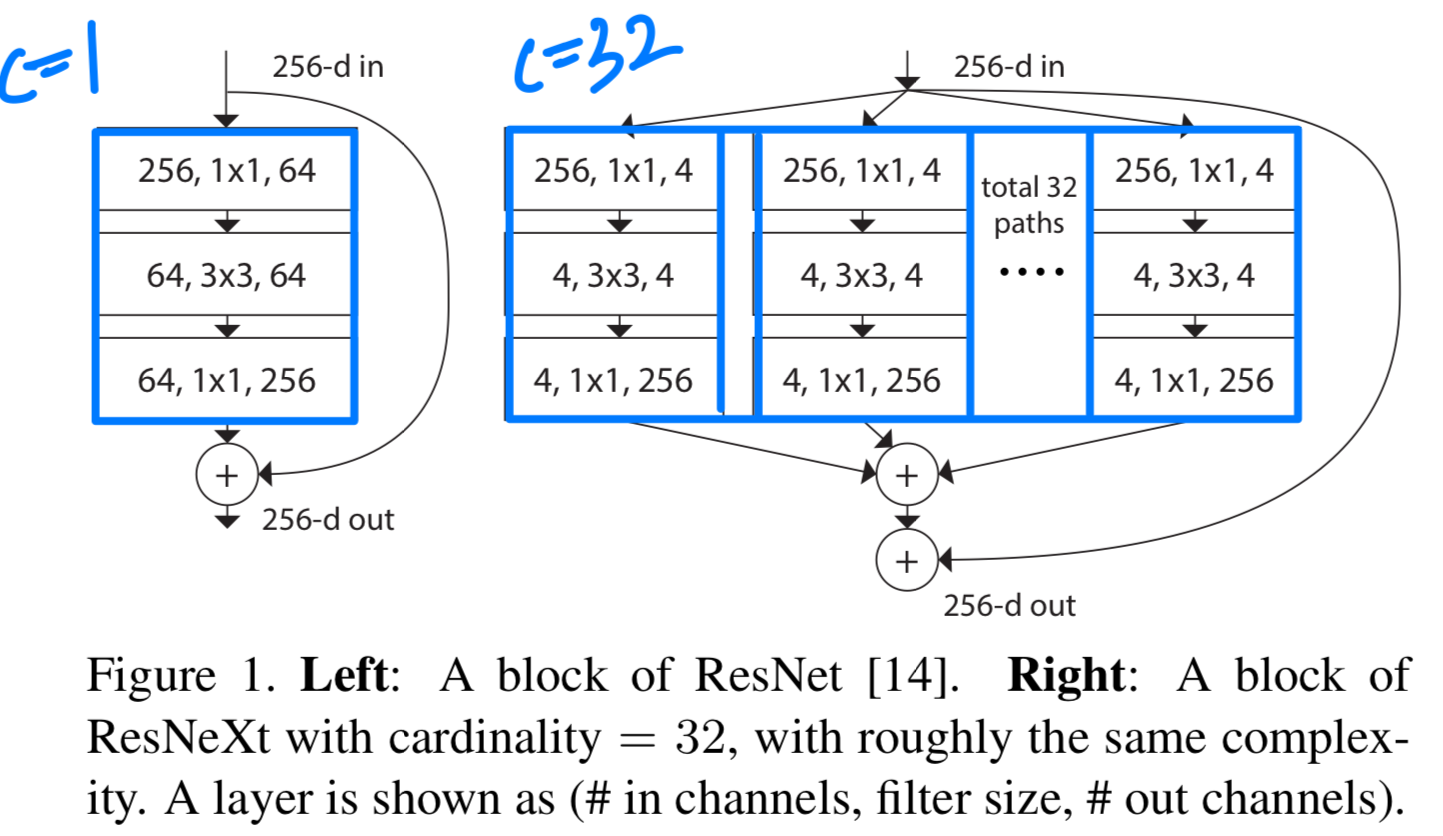
CVPR 2017우리는 image classification을 위한 간단하고, 잘 modularized된 network architecture를 제안한다.이 network는 동일한 topology를 가진 a set of transformations을 aggregate한
4.[2017 ICLR] OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
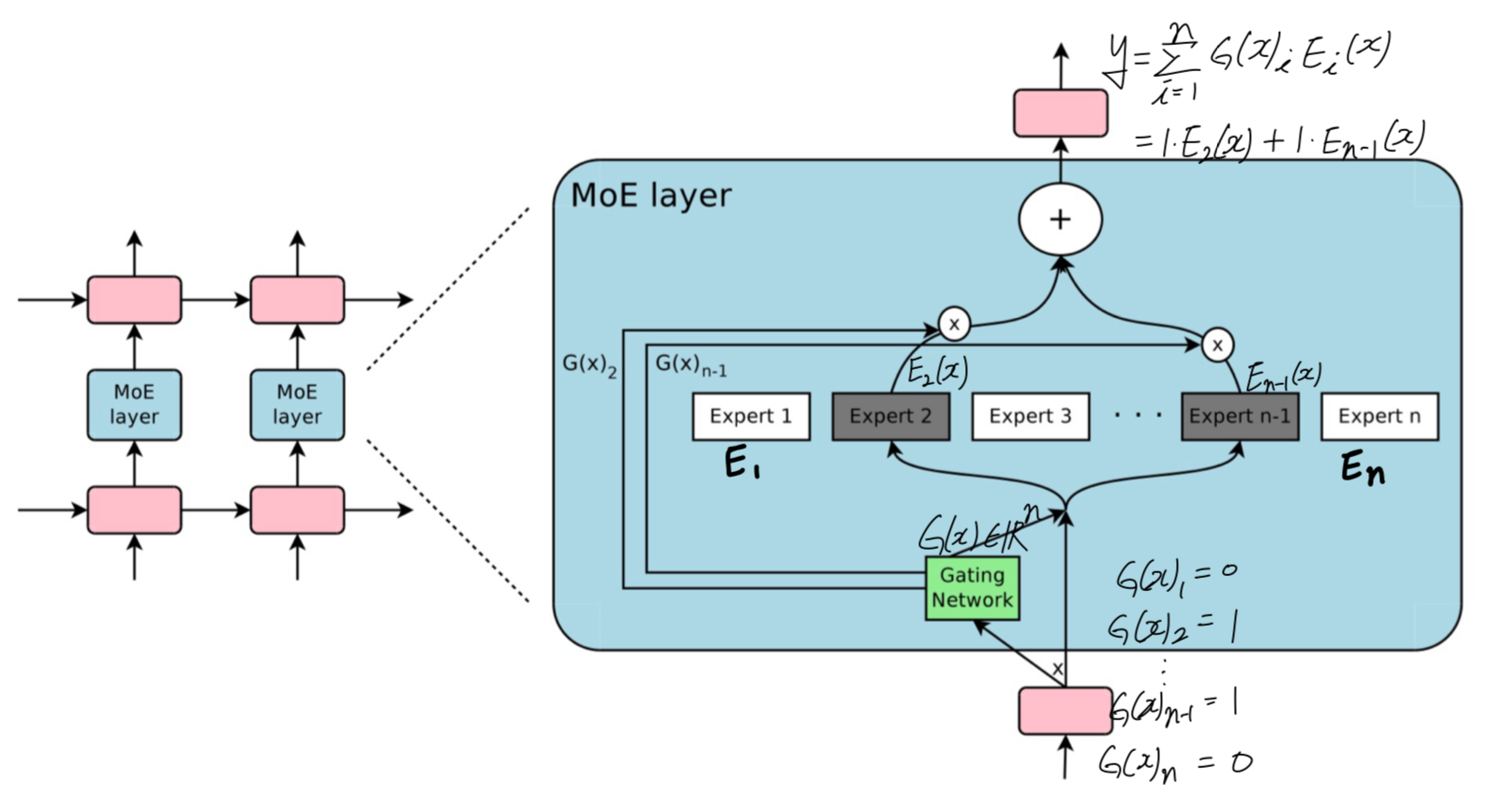
Paper Info. Abstract (문제 제기) information을 받아들이기 위한 neural network의 capacity는 그 network의 #parameter에 의해 제한된다. per-example에 기반한 network의 일부분(parts)만
5.[2017 CVPR] Hard Mixtures of Experts for Large Scale Weakly Supervised Vision

CVPR 2017이 연구에서 a simple hard MoEs model을 사용하여 large scale hashtag (multilabel) prediction tasks에서 효율적으로 train될 수 있음을 보여준다.MoE models은 새로운 개념이 아니지만, 과
6.[2018 CVPR] BlockDrop: Dynamic Inference Paths in Residual Networks
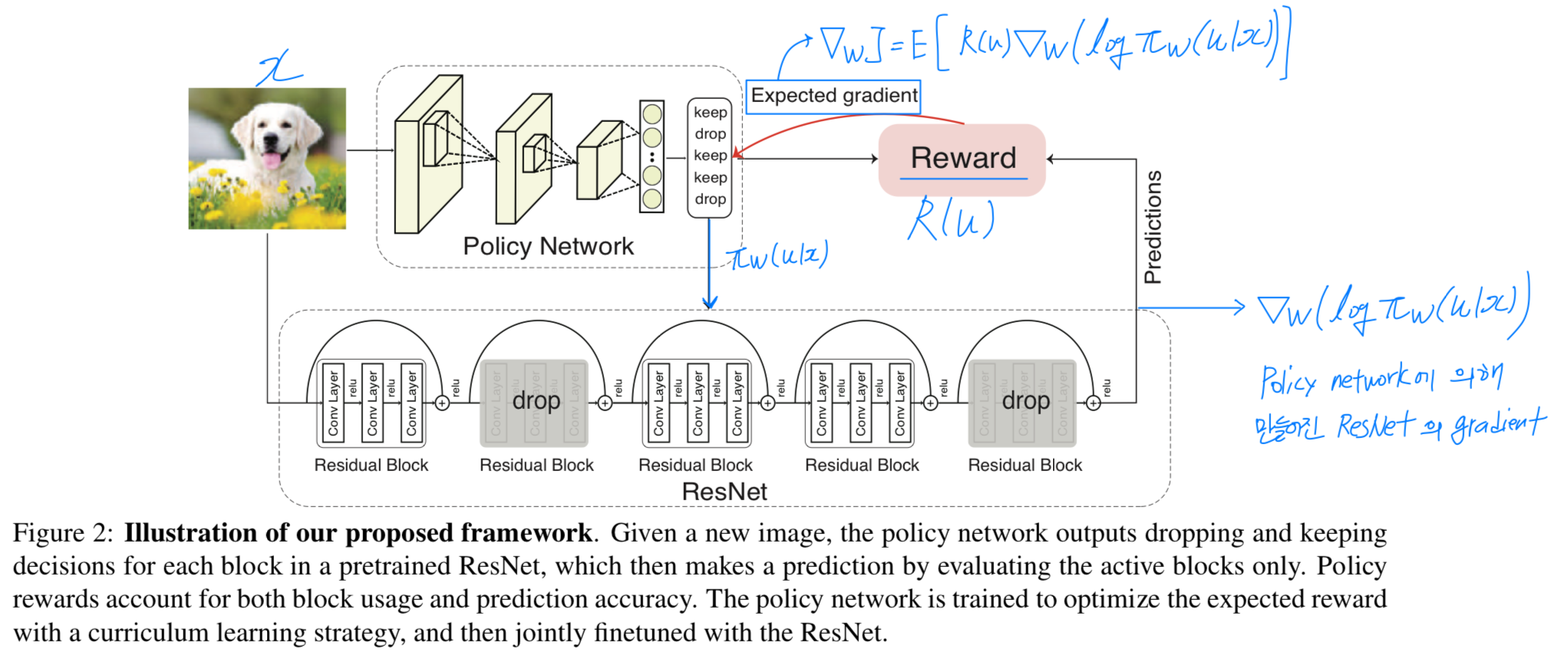
Authors : Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar, Steven Rennie, Larry S. Davis, Kristen Grauman, Rogerio Ferissubject : Proceedings of the IEEE
7.[2018 CVPR]ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
CVPR 2018computation-efficient CNN architecture named ShuffleNet을 소개한다.ShuffleNet은 mobile devices with very limited computing power를 위해 설계되었다.ShuffleN
8.[2019 ICLR] Slimmable Neural Networks
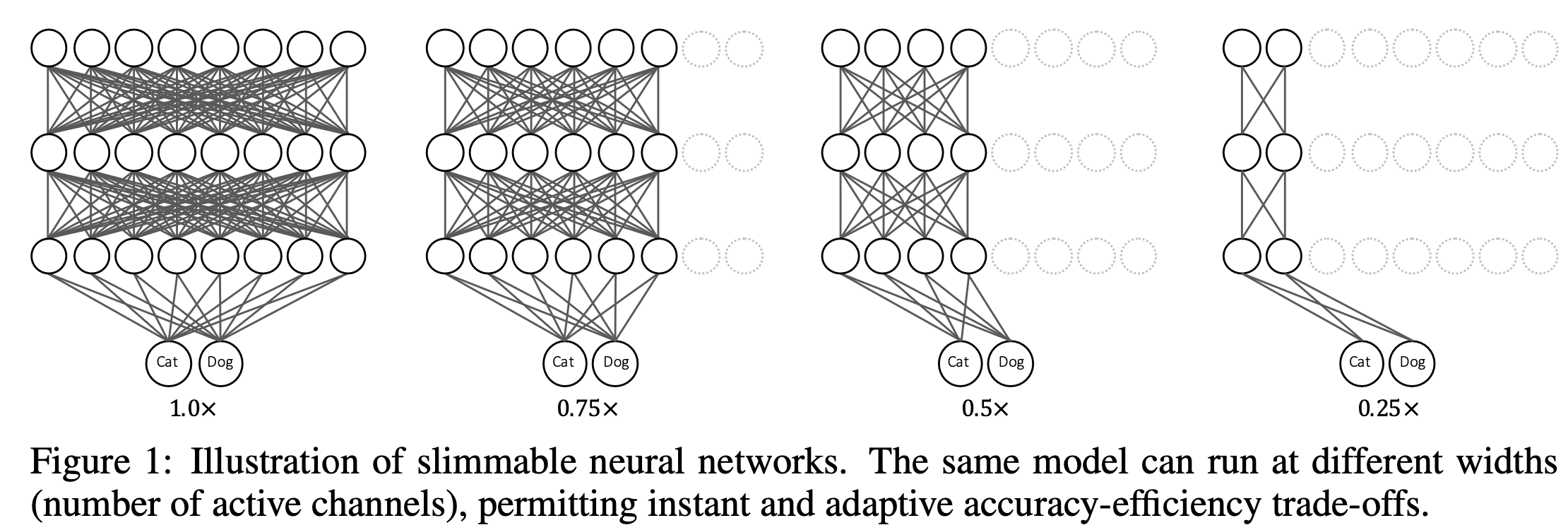
https://github.com/JiahuiYu/slimmable_networksObject Detection의 Neck에서 width를 줄이는 연구를 하고 있는데, 다양한 width configuration을 하나의 single network에서 조화롭게
9.[2019 ICCV] Universally Slimmable Networks and Improved Training Techniques

https://github.com/JiahuiYu/slimmable_networks현재(24.10.28) Object Detection의 Neck에서 width를 줄이는 연구를 하고 있는데, 다양한 width configuration을 하나의 single ne
10.[2019 NeurIPS] CondConv: Conditionally Parameterized Convolutions for Efficient Inference
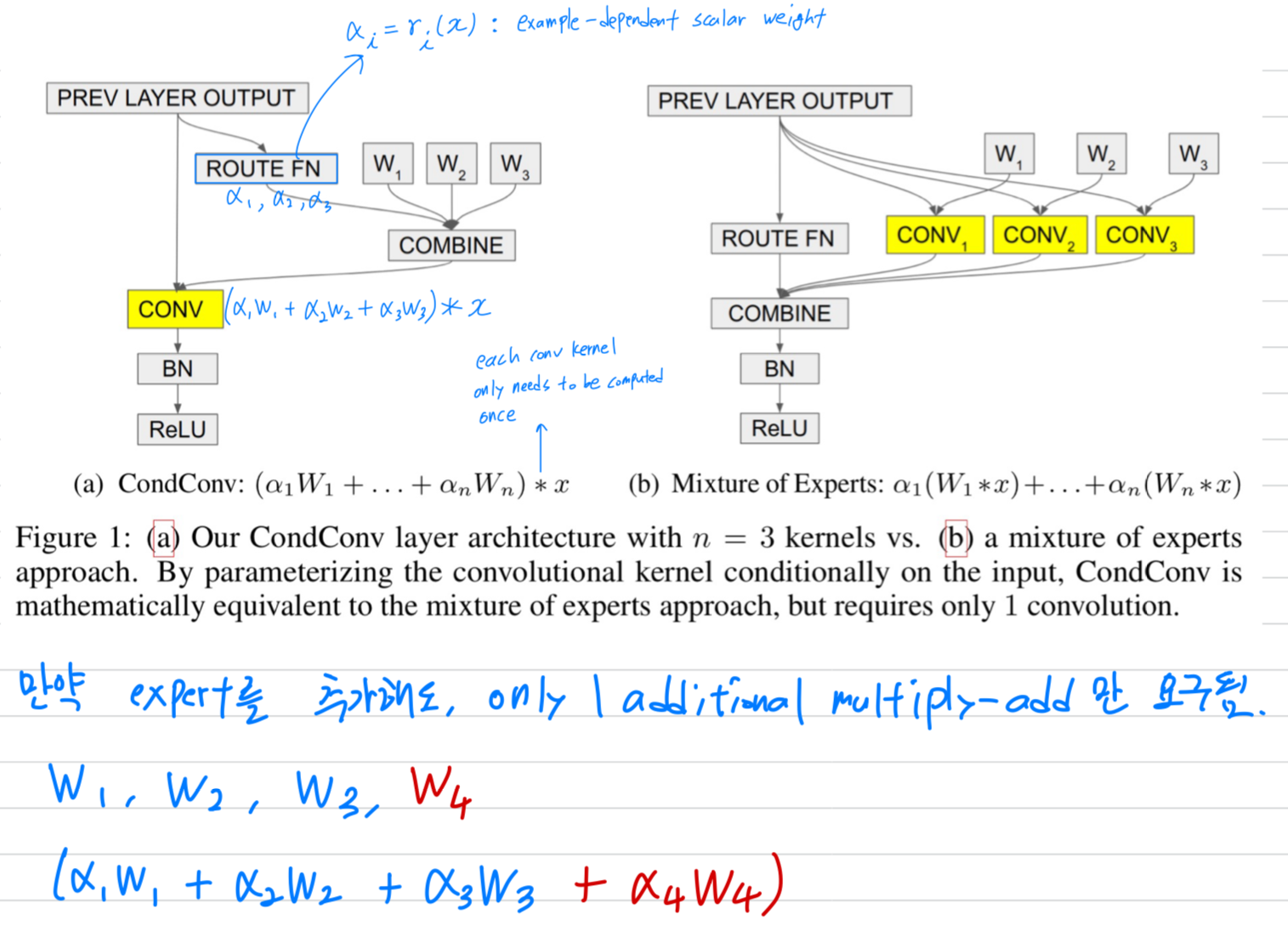
Conv layers는 modern deep NN에서 basic building blocks 중 하나임.이에 대한 한가지 기초적인 assumption은 conv kernels이 한 dataset의 모든 examples에 대해서 공유되어야 한다는 것임.We propose
11.[2020 CVPR] Resolution Adaptive Networks for Efficient Inference
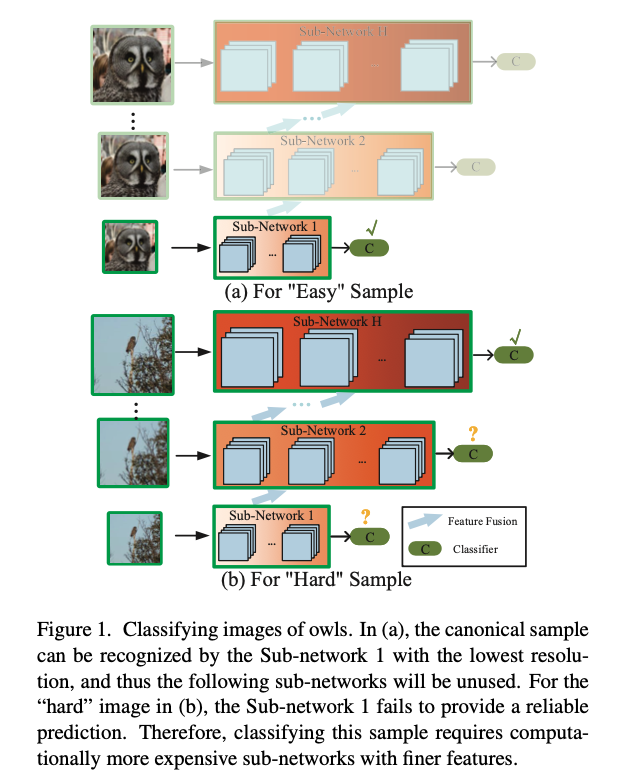
https://openaccess.thecvf.com/content_CVPR_2020/papers/Yang_Resolution_Adaptive_Networks_for_Efficient_Inference_CVPR_2020_paper.pdfYang, Le, et
12.[2020 ICLR] AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
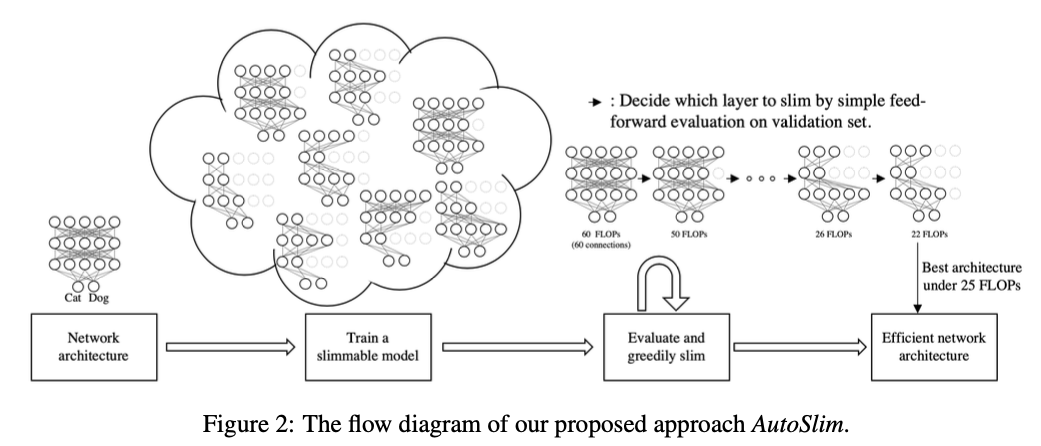
우리는 제약된 자원(e.g., FLOPs, latency, memory footprint, model size) 하에서 더 나은 정확도를 달성하기 위해 neural network의 channel 수를 설정하는 방법을 연구했다.이를 위해 simple and one-sho
13.[2020 CVPR] EfficientDet: Scalable and Efficient Object Detection
Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and efficient object detection." Proceedings of the IEEE/CVF conference on comput
14.[2020 PMLR] Deep Mixture of Experts via Shallow Embedding
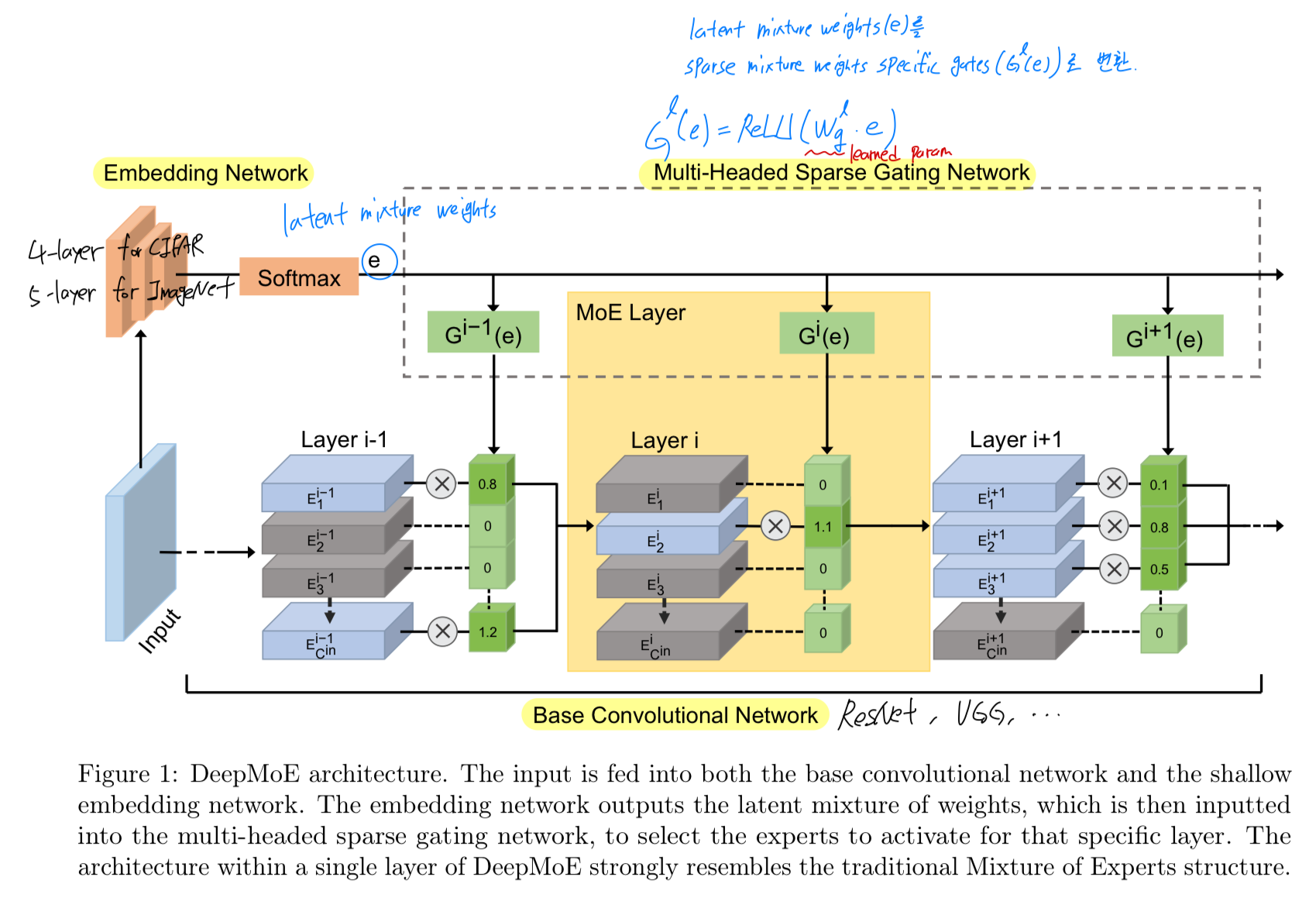
2020 PMLR (Proceedings of Machine Learning Research)Larger networks는 일반적으로 greater representational power를 갖지만, 그 대가로 computational complexity도 증가한다.이
15.[2021 NeurIPS] Scaling Vision with Sparse Mixture of Experts
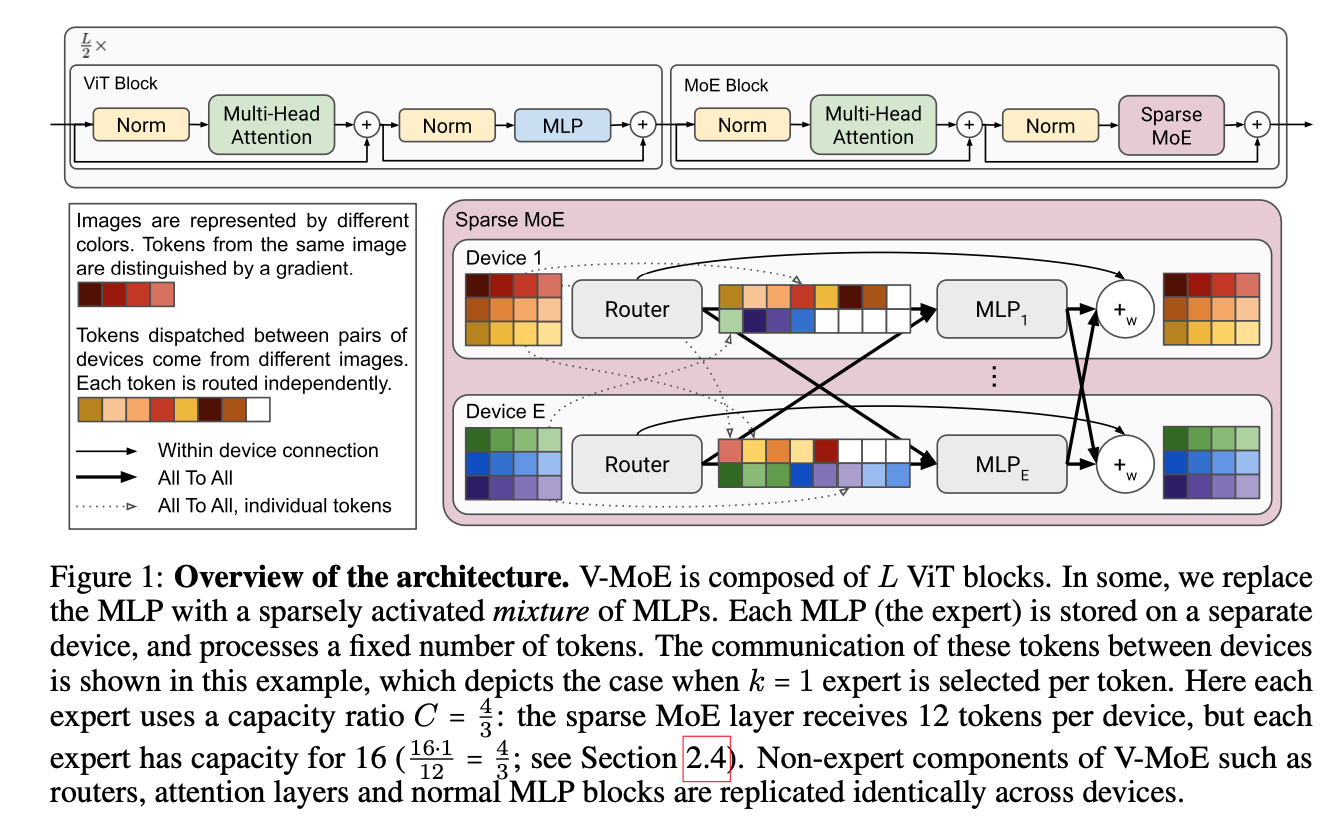
Paper Info NeurIPS 2021 Abstract Sparsely-gated MoEs networks는 NLP에서 excellent scalability를 입증해왔다. 하지만 Computer Vision에서, 모든 performant networks는 "d
16.[2021 NeurIPS] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification

Rao, Yongming, et al. "Dynamicvit: Efficient vision transformers with dynamic token sparsification." Advances in neural information processing systems
17.[Simple Review] [2022 CVPR] Restormer: Efficient Transformer for High-Resolution Image Restoration
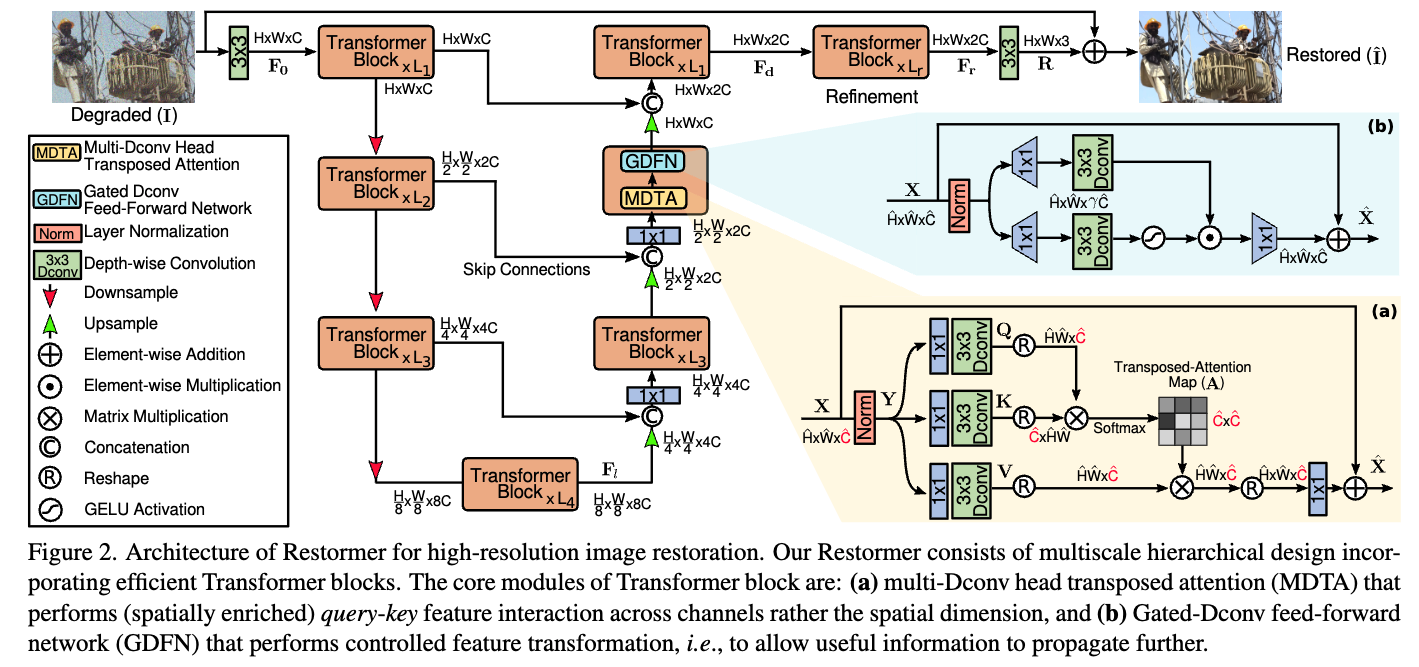
Paper Info. https://openaccess.thecvf.com/content/CVPR2022/papers/ZamirRestormerEfficientTransformerforHigh-ResolutionImageRestorationCVPR2022paper.p
18.[2022 ICLR] COSFORMER: Rethinking Softmax In Attention
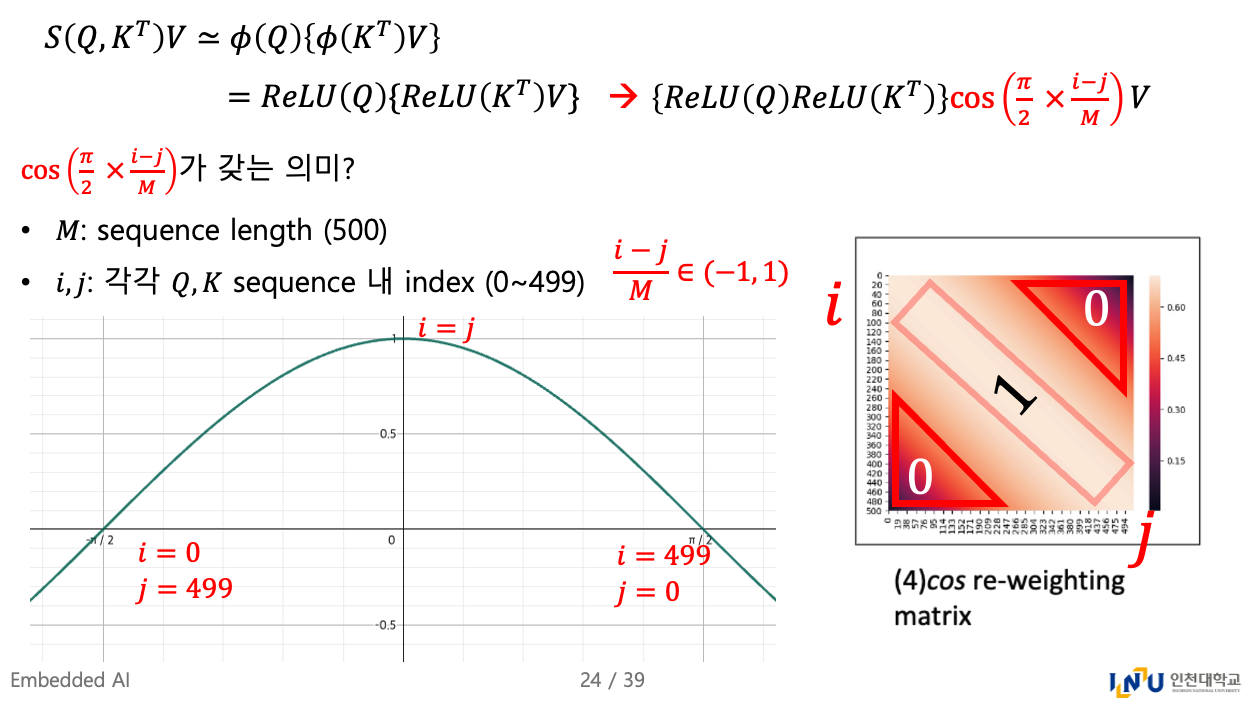
https://arxiv.org/pdf/2202.08791Transformer는 NLP, CV, and audio processing에서 great successes를 보여주고 있다.core components로, softmax attention은 long-r
19.[2022 NeurIPS] EfficientFormer: Vision Transformers at MobileNet Speed
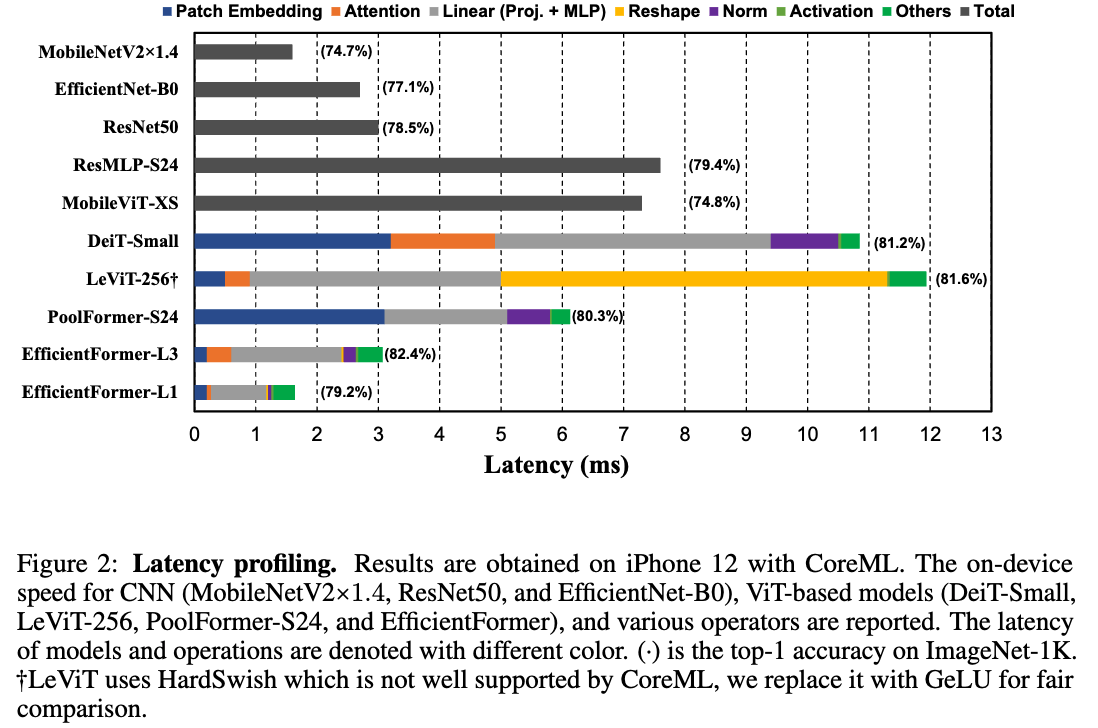
https://proceedings.neurips.cc/paper_files/paper/2022/file/5452ad8ee6ea6e7dc41db1cbd31ba0b8-Paper-Conference.pdfViT는 CV task에서 빠르게 발전하며 다양한 bench
20.[2022 CVPR] (중단) A-ViT: Adaptive Tokens for Efficient Vision Transformer

CVPR2022우리는 서로 다른 complexity를 가진 image에 대해 ViT의 inference cost를 adaptively 조정하는 방법인, A-ViT를 제안한다.\*\*A-ViT는 network에서 inference가 진행됨에 따라 ViT의 이 작업을 위해
21.[2022 ICLR][EViT] Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
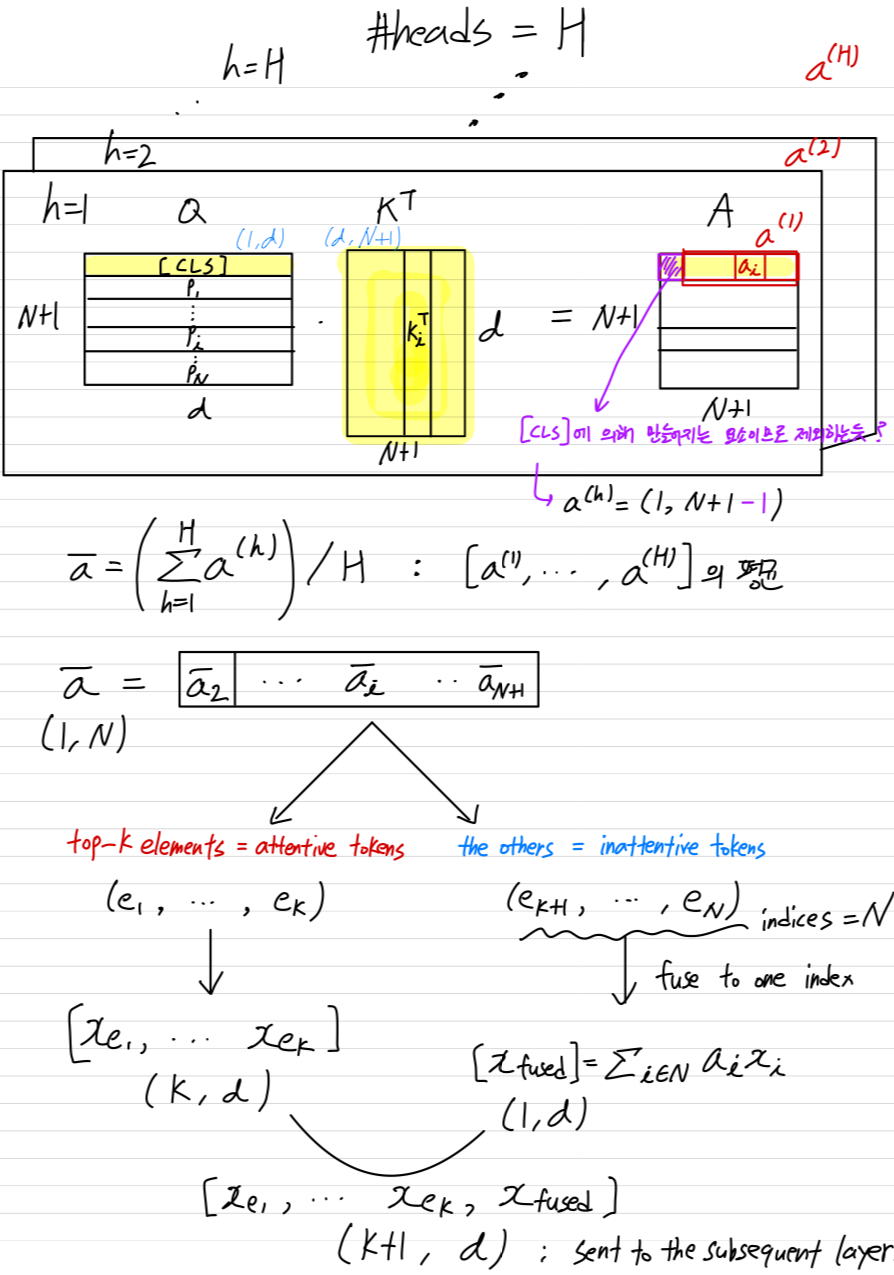
Paper Info. Abstract ViTs은 image patches를 모두 token 취급하고 이들 간에 multi-head self-attention(MHSA)을 구성한다. 그러나 이러한 image token을 완전히 활용하는 것은 redundant comp
22.[2022 JMLR][simple review] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity

Paper Info JMLR 2022 Abstract DL에서, model은 일반적으로 모든 inputs에 same parameters를 사용한다. 하지만 MoEs models은 이를 따르지 않고 각 example에 대해 different parameters를 선
23.[2023 CVPR] DynamicDet: A Unified Dynamic Architecture for Object Detection
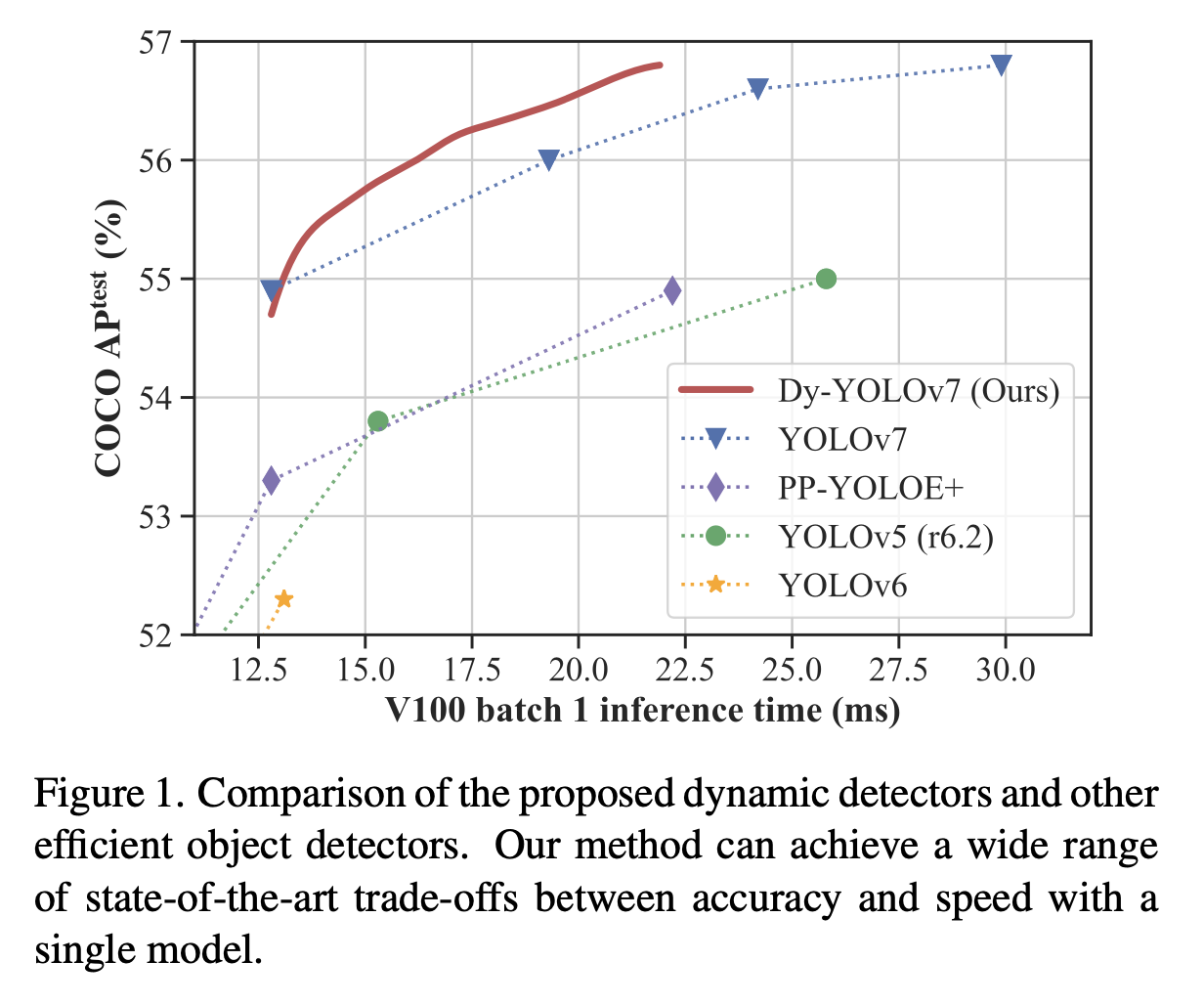
https://openaccess.thecvf.com/content/CVPR2023/papers/Lin_DynamicDet_A_Unified_Dynamic_Architecture_for_Object_Detection_CVPR_2023_paper.pdfLin,
24.[2023 CVPR] Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
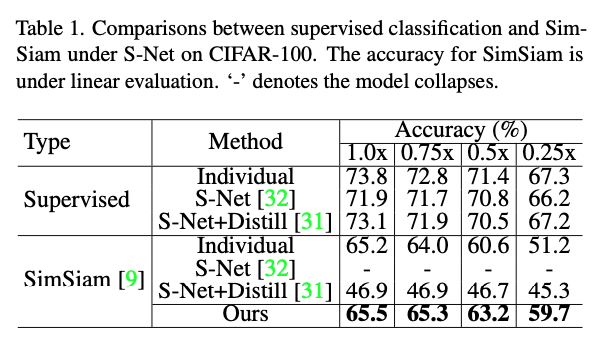
Cao, Yun-Hao, Peiqin Sun, and Shuchang Zhou. "Three guidelines you should know for universally slimmable self-supervised learning." Proceedings of the
25.[2023 ICCV] EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction
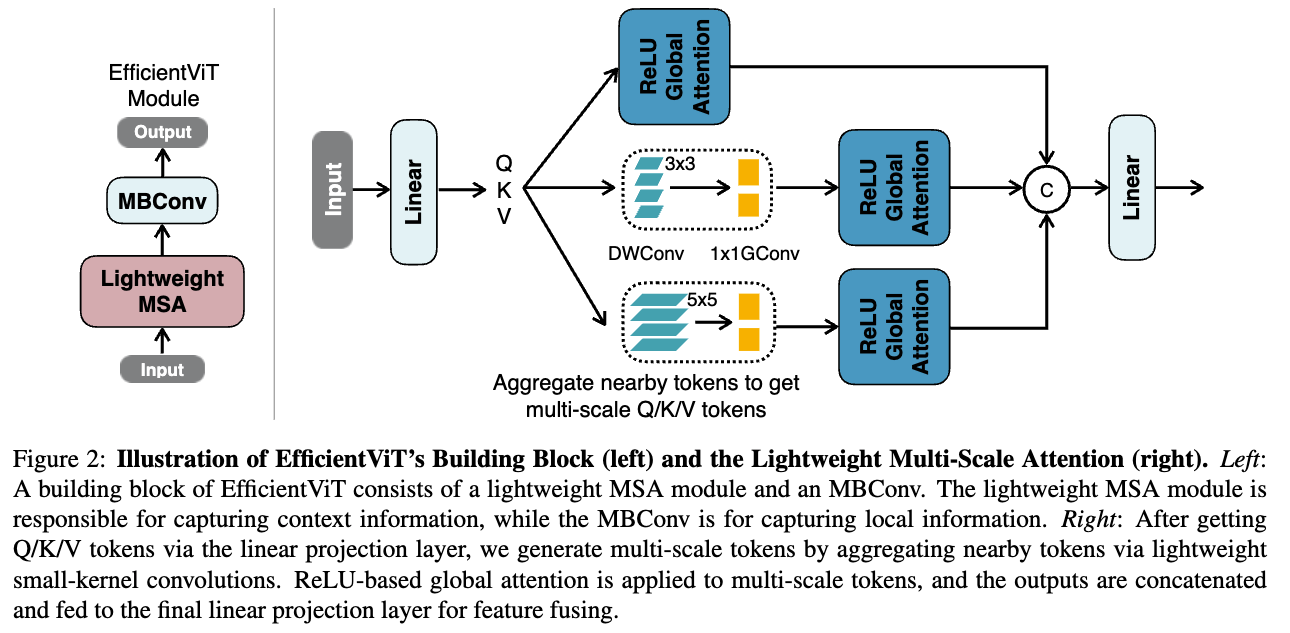
https://openaccess.thecvf.com/content/ICCV2023/papers/Cai_EfficientViT_Lightweight_Multi-Scale_Attention_for_High-Resolution_Dense_Prediction_ICC
26.(2023ICCV)EfficientViT, (2022ICLR)CosFormer를 읽고 이해한 Linear Attention
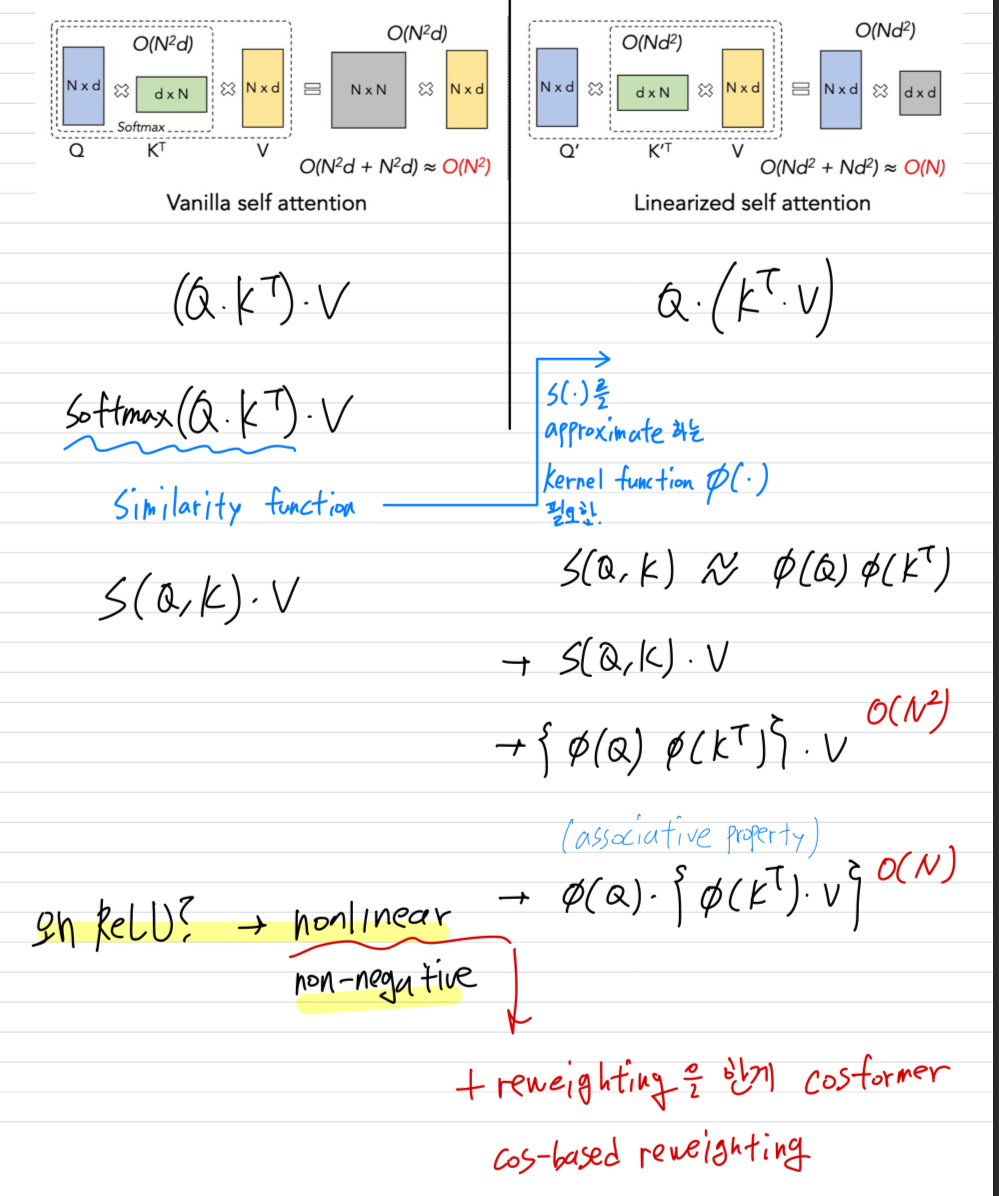
softmax-based similarity function이 갖는 특정1\. attention matrix are non-negative, -> negatively-correlated information은 포함하지 않음2\. non-linear re-weightin
27.[2023 ICCV][중단] Robust Mixture-of-Expert Training for Convolutional Neural Networks

DL architecture로 떠오르고 있는, Sparsely-gated MoE는high-acc and ultra-efficient model inference를 가능하게 하는 유망한 방법으로 입증되어 왔다.MoE 인기 성장에도 불구하고, 특히 convolutional
28.[2024 NeurIPS] Adaptive Depth Networks with Skippable Sub-Paths
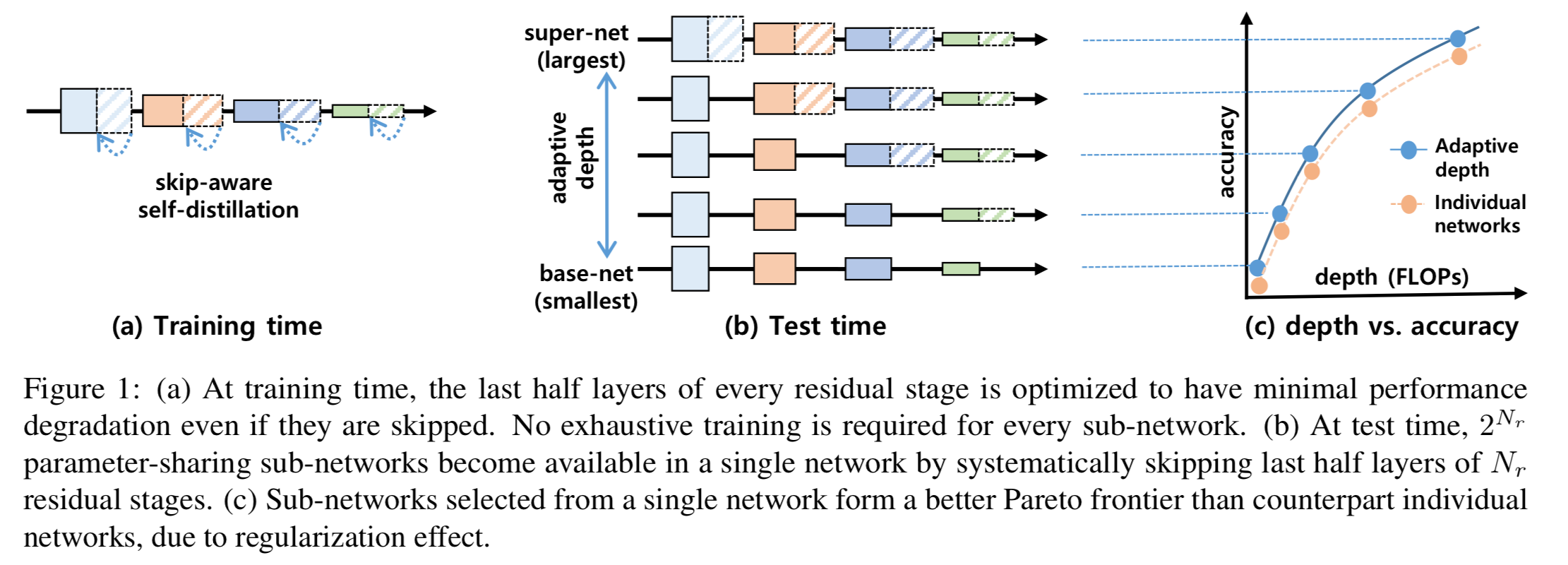
Anonymous Authors(이전의 depth adaptive network에 대한 문제점 지적)network depth의 체계적인 adaption은 inference latency를 효과적으로 제어하고다양한 devices의 resource 조건을 충족시키는 효과적
29.[2024 AICAS] An Efficient and Fast Filter Pruning Method for Object Detection in Embedded Systems
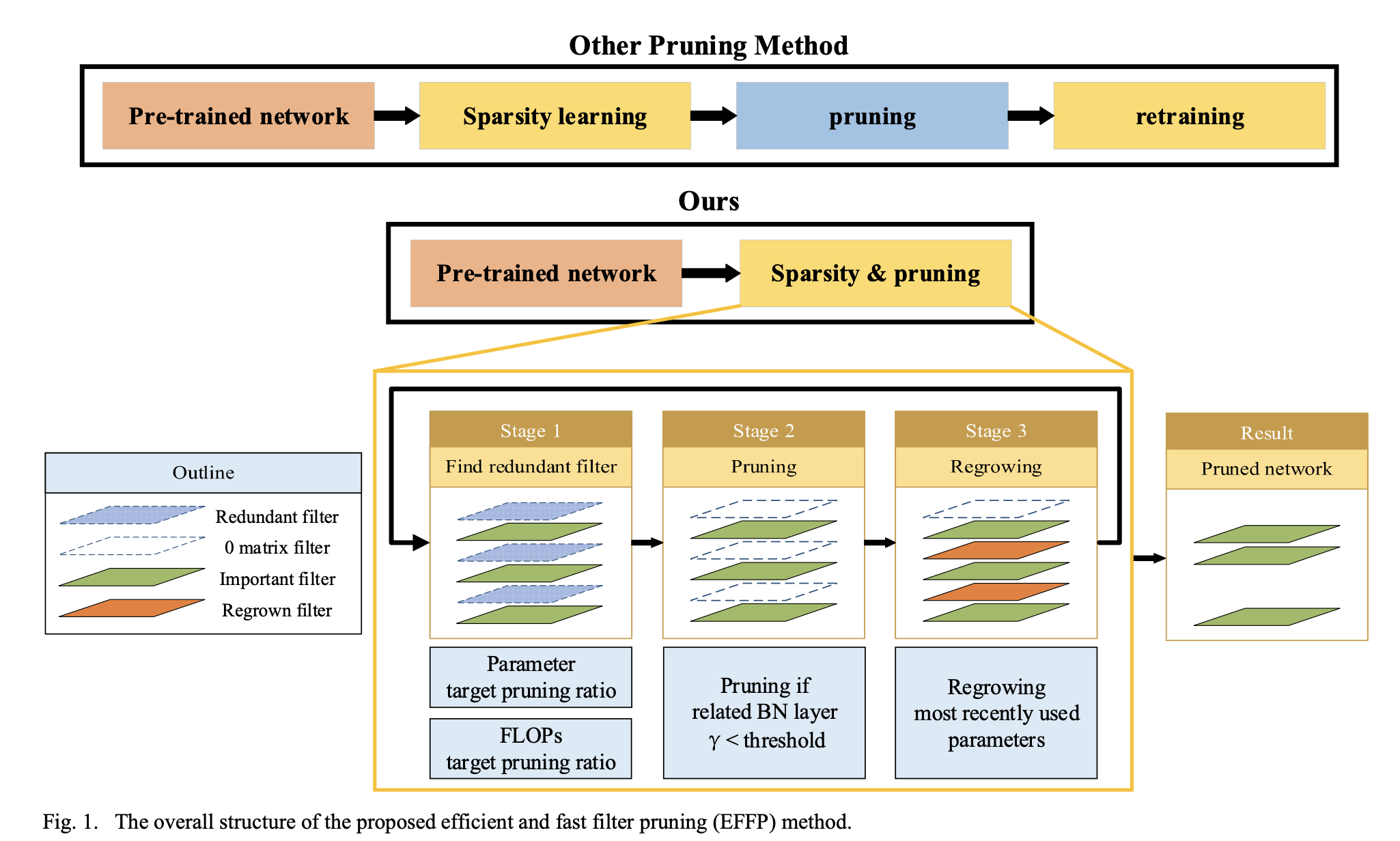
H. Ko, J. -K. Kang and Y. Kim, "An Efficient and Fast Filter Pruning Method for Object Detection in Embedded Systems," 2024 IEEE 6th International Con
30.[2024 WACV][Simple Review][SViT] Revisiting Token Pruning for Object Detection and Instance Segmentation
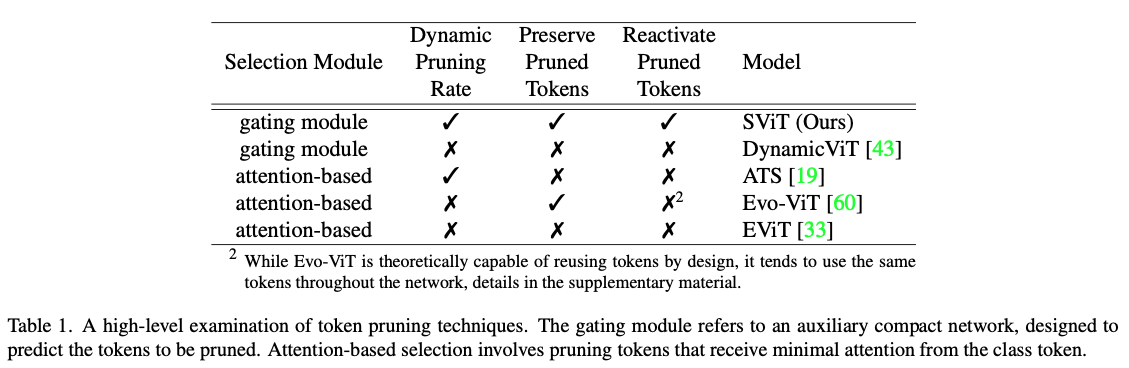
ViTs는 computer vision에서 인상적인 성능을 보여줬으나,quadratic in the nubmer of tokens으로 high computational cost로 인해 computation-constrained applications에 적용하기에 제한되
31.[2020 ICLR] (OFA) ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE-CIALIZE IT FOR EFFICIENT DEPLOYMENT
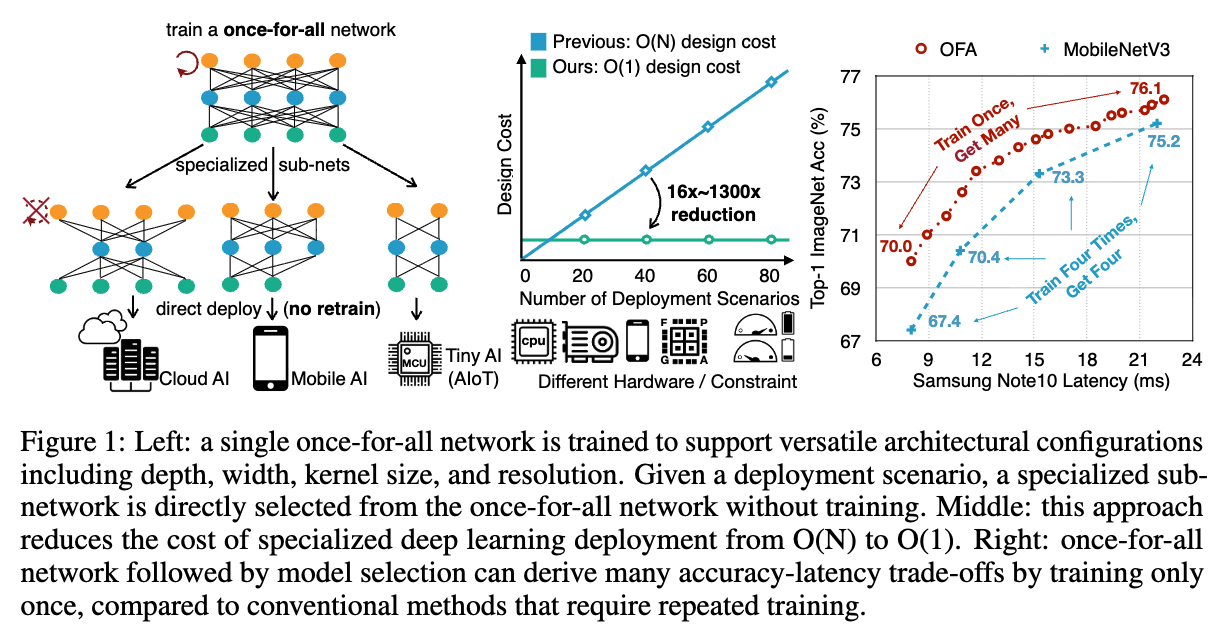
https://arxiv.org/pdf/1908.09791(B.G.)우리는 특히 edge devices에서와 같이 resource constraints에서 efficient inference의 문제를 도전한다.(Related Works)기존의 방법들은 manu
32.[2021 ICLR] [Simple Review ] ( CompOFA) COMPOFA: COMPOUND ONCE-FOR-ALL NETWORKS FOR FASTER MULTI-PLATFORM DEPLOYMENT

https://arxiv.org/pdf/2104.12642