[2020 ICLR] (OFA) ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE-CIALIZE IT FOR EFFICIENT DEPLOYMENT
[Paper Review] Efficient and Scalable
Paper Info.

Abstract
(B.G.)
- 우리는 특히 edge devices에서와 같이 resource constraints에서 efficient inference의 문제를 도전한다.
(Related Works)
-
기존의 방법들은 manually design하거나 specialized neural network를 찾기 위해 Neural Architecture Search (NAS)를 사용해서 각각의 case마다 scratch부터 train시킨다.
이는 computationally prohibitive하다. -
본 연구에서, 우리는 cost를 줄이기 위해,
training and search를 decoupling함으로써
diverse architectural settings을 돕는 a once-for-all (OFA) network를 학습시키는 것을 제안한다.
(제안: OFA network와, OFA network 학습을 위한 PS algorithm)
-
효율적으로 OFA networks를 학습시키기 위해,
우리는 a novel progressive shrinking(PS) algorithm을 제안한다.
PS는 pruning보다 더 다양한 dimensions에서의 model size를 줄일 수 있다 (depth, width, kernel size, and resolution). -
PS로 학습한 OFA는 다양한 HW platforms and latency constraints에 fit할 수 있는 a large number of sub-networks ()를 포함할 수 있다.
(실험)
- OFA is the winning solution for the 3rd Low Power Computer Vision Challenge (LPCVC),
DSP classification track and the 4th LPCVC, both classification track and detection track.
https://github.com/mit-han-lab/once-for-all
1. Introduction
(Background)
- With different HW resources (e.g., on-chip memory size, #arithmetic units),
the optimal neural network architecture varies significantly.
그래서 HW platforms and efficiency constraints가 주어졌을 때,
researcher들은 compact models specialized for mobile을 design하거나
efficient deployment를 위해 existing models을 compression해야 한다.
(문제 제기)
-
"However, designing specialized DNNs for every scenario
is engineer-expensive and computationally expensive, either with human-based methods or NAS." -
"Since such methods need to repeat the network design process and retrain the designed network
from scratch for each case. Their total cost grows linearly as the number of deployment scenarios
increases, which will result in excessive energy consumption and CO2 emission."
(제안 1: Once-for-all = OFA networks)
-
이 paper는 이러한 challenge를 해결하기 위한 new solution을 제안한다.
training cost를 늘리지 않고 diverse architectural configurations에 directly deployed할 수 있는 once-for-all network를 designing하는 것이다.
inference는 OFA network 중 only part만 selecting함으로써 수행된다.
OFA는 retraining 없이 depths, widths, kernel sizes, and resolutions을 flexibly supports한다. -
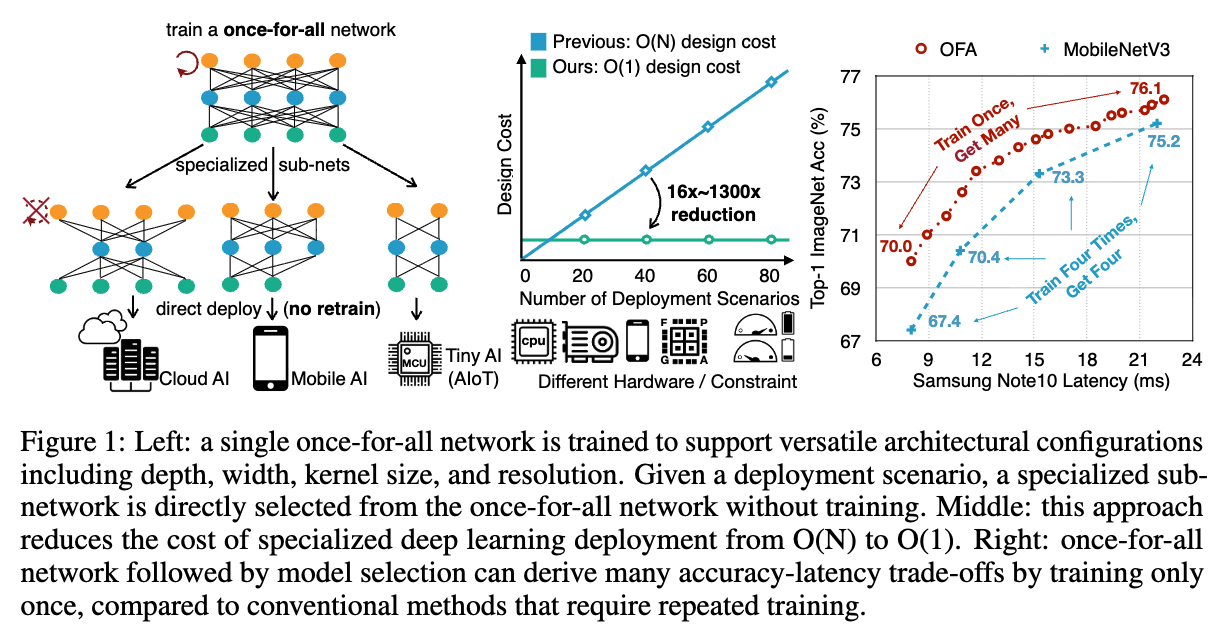
OFA의 Simple example은 Fig.1(left)에 있다.
구체적으로,
우리는 model training stage와 NAS stage를 decouple한다.- In the model training stage,
우리는 OFA의 different parts를 selecting함으로써 all sub-networks의 acc를 향상시키는 데 집중한다. - In the model specialization stage,
우리는 accuracy predictor and latency predictors를 학습하기 위한 a subset of sub-networks를 sampling한다.
- In the model training stage,
(제안 2: OFA 학습을 위한 progressive shrinking = PS)
- OFA를 학습시키는 것은 a large number of sub-networks의 accuracy를 유지시킬 수 있는 weights를
joint optimization해야 하기 때문에, 결코 쉬운 일은 아니다.
To address this challenge, we propose a progressive shrinking algorithm for training the once-for-all network.
Instead of directly optimizing the OFA network from scratch,
we propose to first train the largest neural network with maximum depth, width, and kernel size,
then progressively fine-tune the OFA network to support smaller sub-networks that share weights with the larger ones.
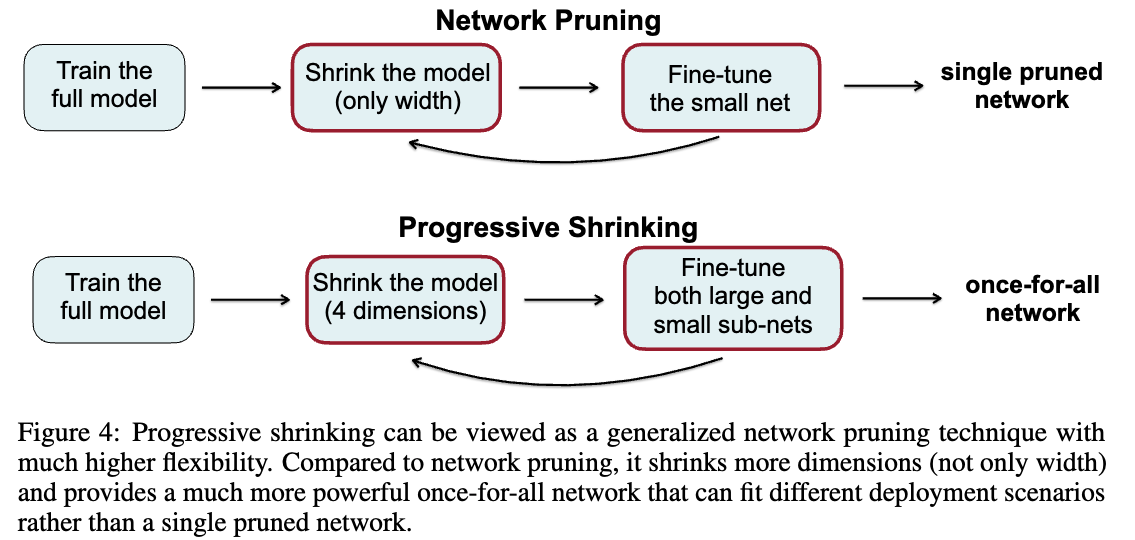
그래서 어떻게 보면, PS는 a generalized network pruning method라고 볼 수도 있다.
pruning은 only the width dimension을 shrink하지만,
PS는 multiple dimensions(width, depth, kernel size, and resolution)을 shrink한다.
"Besides, PS targets on mainintaining the accuracy of all sub-networks rather than a single pruned network"
(실험)
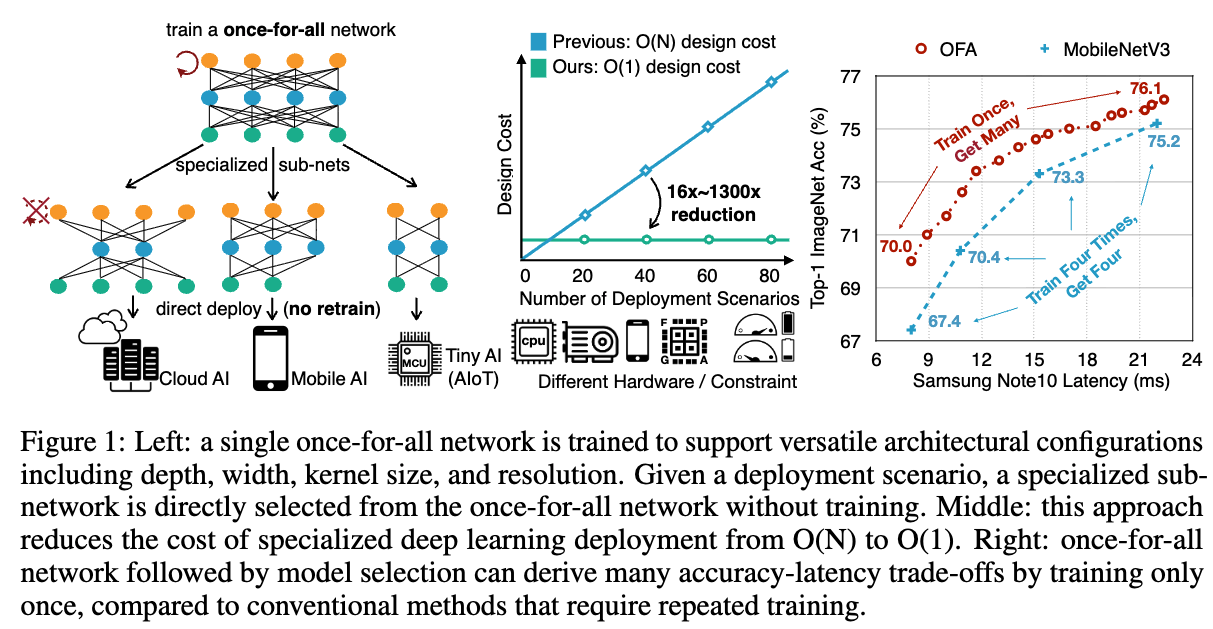
- "We extensively evaluated the effectiveness of OFA on ImageNet with many hardware platforms (CPU, GPU, mCPU, mGPU, FPGA accelerator) and efficiency constraints."
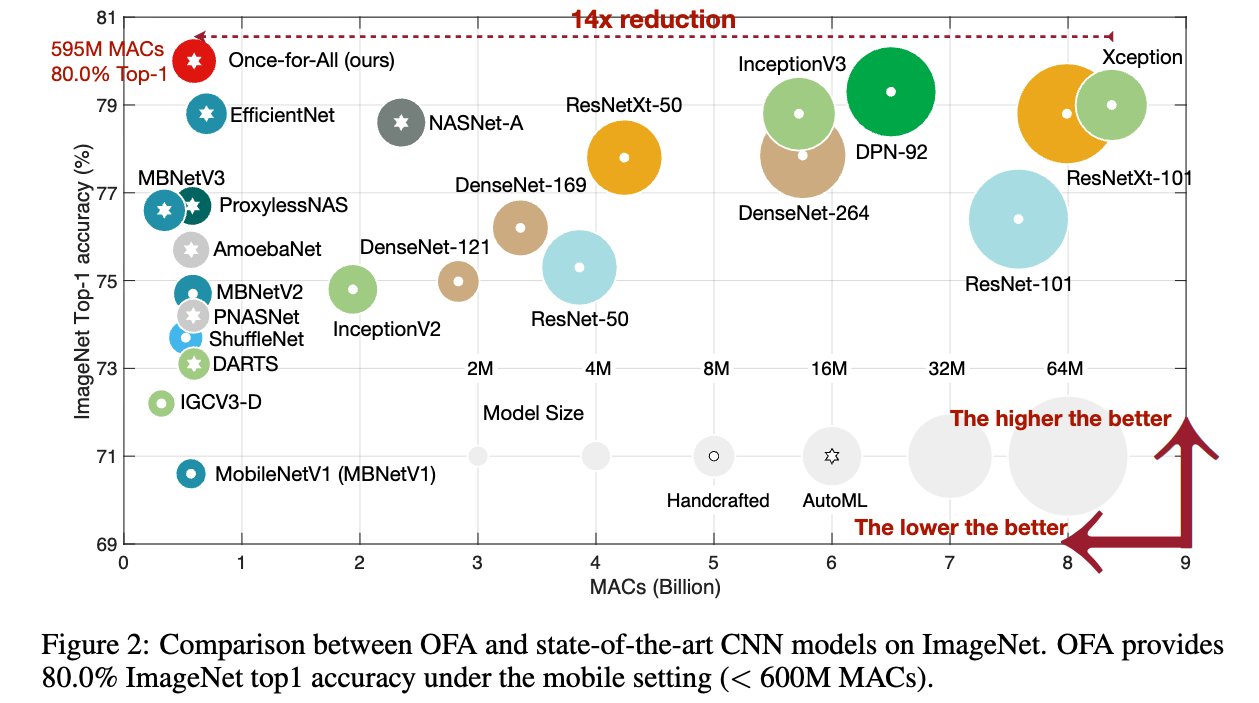
2. Related Work
skip
3. Method
3.1. Problem Formalization
- OFA network의 weights를 라 하고,
architectural configurations를 라 할 때,
problem을 다음과 같이 formalize할 수 있다:
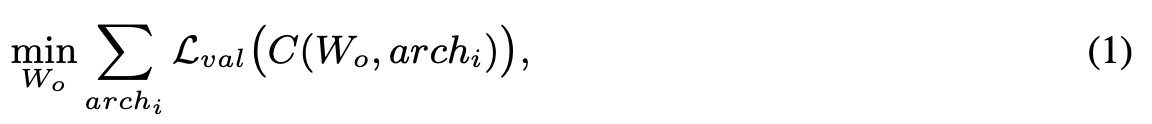
- 여기서 는 OFA network 로부터 sub-network with architectural configuration 를 선택하는 selection scheme이다.
- The overall training objective는
를 optimize하여,
OFA network가 지원하는 각각의 sub-network가 same architectural configuration으로 독립적으로 학습했을 때와 동일한 수준의 accuracy를 유지하도록 만드는 것이다.
3.2. Architecture Space
- OFA network는 one model을 제공하지만,
CNN architectures의 four important dimensions(depth, width, kernel size, and resolution)을
cover하는 many sub-networks of different sizes를 제공한다.- elastic depth:
- each unit이 arbitrary numbers of layers를 갖도록 허용
- the depth of each unit is chosen from
- elastic width:
- each layer마다 arbitrary numbers of channels을 갖도록 허용
- the width expansion ratio in each layer is chosen from
- elastic kernel size:
- arbitrary kernel sizes를 갖도록 허용.
- the kernel size is chosen from
- elastic resolution:
- arbitrary input image sizes를 갖도록 허용.
- the input image size ranges from to with a stride 4 (128, 132, ..., 220, 224)
- elastic depth:
- Since all of these sub-networks share the same weights (i.e., ),
we only require 7.7M parameters to store all of them.
Without sharing, the total model size will be prohibitive.
3.3. Training the Once-For-All Network
Naive Approach
- OFA network는 multi-objective problem으로 취급할 수 있다.
each objective는 one sub-network에 해당한다.
-
위 관점에서, a naive training approach is
directly optimize the OFA network from scratch using the exact gradient of the overall objective.
하지만 이 방식의 cost는 #(sub-networks)에 대해 linear하게 증가하기 때문에 computationally prohibitive한 문제가 있다. -
another naive training approach is
to sample a few sub-networks in each update step rather than enumerate all of them, which does not have the issue of prohibitive cost.
하지만 이 방식은 significant accuracy drop의 문제를 겪는다.
- 위 1., 2. 의 naive approach의 문제를 해결할 수 있는 progressive shrinking을 제안한다.
Progressive Shrinking
-
OFA network는 large sub-networks 안에 중첩되어 있는 small sub-networks들로 이루어져 있는데,
sub-networks들끼리 상호 간의 interference (방해, 간섭)을 막기 위해,
우리는 large sub-networks부터 small sub-networks progressive한 순서로 training하도록 했다.
우리는 this training scheme을 progressive shrinking (PS)라 부른다. -
PS의 training process는 Figure 3 and Figure 4에 제공되어 있다.
- 먼저 maximum kernel size (7), depth (4), and width (6)을 갖는 the largest neural network를 training한다.
- 그 다음, sampling space에 gradually smaller sub-networks들을 포함시키는 방식으로 network를 progressively fine-tune하여,
smaller sub-networks들을 지원하도록 만든다 (이 과정에서도 larger sub-networks가 sampled될 수 있다.) - 구체적으로, the largest network의 학습이 끝난 뒤에서 먼저 elastic kernel size를 지원하도록 확장하며,
이때 각 layer의 kernel size는 중에서 선택될 수 있고, depth and width는 여전히 maximum values로 유지된다.
이후, Figure 3에서처럼 elastic depth elastic width순으로 support한다.
input resolution은 whole training process 동안 항상 elastic하게 유지되며,
이는 각 batch마다 서로 다른 image sizes를 sampling하는 방식으로 구현된다. - 또한, the largest neural network를 training한 이후에는 knowledge distillation technique을 사용하여,
the largest neural network가 제공하는 soft labels와 real labels를 사용하여 two loss terms을 combine한다.

-
naive approach와 비교했을 때,
PS는 small sub-networks가 large sub-networks의 학습을 방해하는 문제를 방지한다.
이는 OFA network가 small network를 지원하도록 fine-tuning되기 전에,
large sub-network가 이미 충분히 잘 학습되어 있기 때문에
large sub-network의 the most important weights로 initialize될 수 있기 있다.
이로 인해 training process가 빨라질 수 있다.
(내 생각: small network 학습하면서 large network가 조금은 망가질 것 같은데...
저자들이 small network의 sampling space에 large network를 추가했기 때문에 망가지는 것을 완화한 것 같음.
만약 large network를 sampling space에 넣지 않았어도 large network의 성능이 유지되었을까???)
Figure 4에서 network pruning과 비교하면, PS 역시 전체 model을 먼저 training하는 것에서 시작하지만,
단순히 width만 줄이는 것이 아니라 depth, kernel size, resolution까지 포함한 여러 dimensions에서 model을 shrink시킨다.
-
이제 PS training flow의 details을 다음과 같이 설명한다:
-
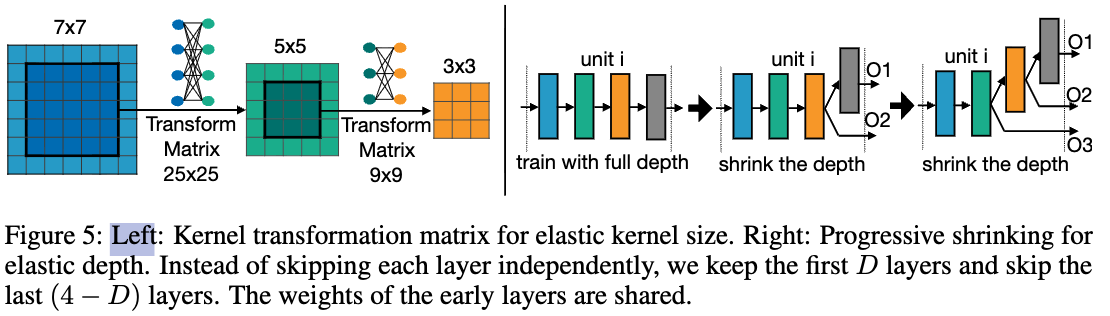
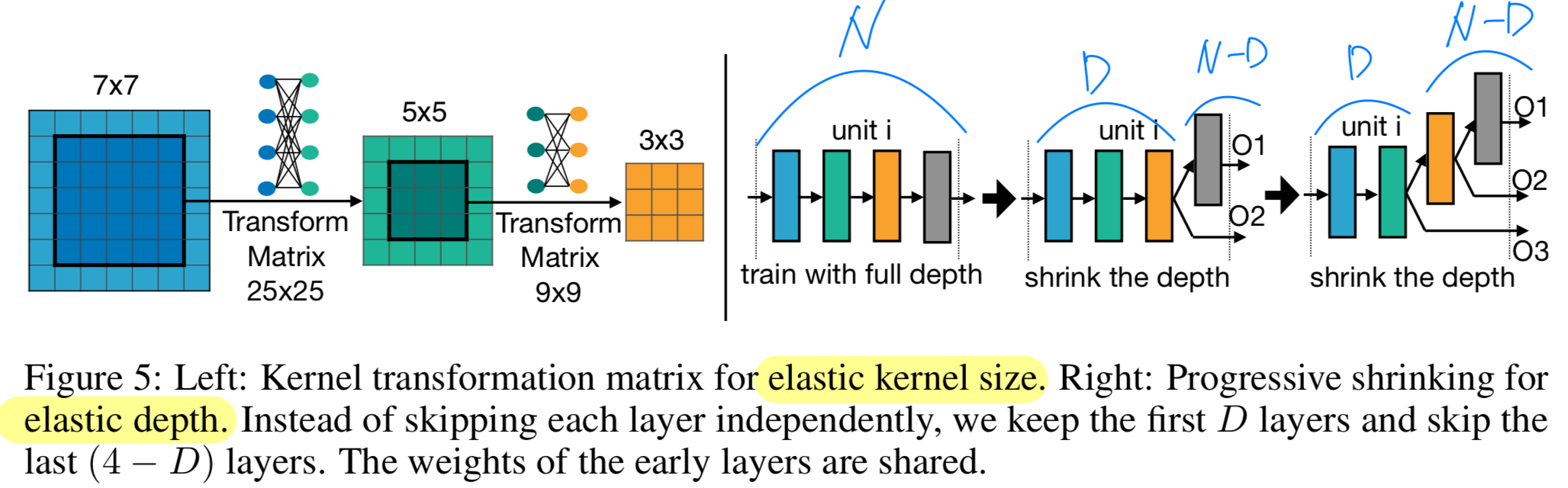
Elastic Kernel Size:
우리는 conv kernel의 center를 kernel로 사용할 수도 있고,
kernel의 중심은 다시 kernel로도 사용될 수 있게 했다.
이로써 kernel size는 elastic(확장성 있는)해진다.
이때의 challenge는 centering sub-kernels (e.g. and )이 shared되고 multiple roles을 수행해야 한다는 점이다.
즉, 이들은 independent kernel로도 역할을 해야 하고 part of a large kernel의 역할도 동시에 수행해야 한다는 점이다.
그러나 이러한 서로 다른 role에 따라, sub-kernels은 서로 다른 distribution or magnitude를 가져야 할 수도 있다.
이를 강제로 동일하게 만들면 some sub-networks의 performance가 degrades된다.
이를 해결 하기 위해, 우리는 Kernel weights를 sharing할 때, kernel transformation matrix를 도입한다.
각 layer마다 서로 다른 kernel transformation matrices를 사용하며,
하나의 layer 내에서는 이 transformation matrices를 모든 channels이 공유한다.
이 방식에서는 layer당 개의 extra parameters만 필요하며, 이는 negligible하다.
(내 생각: 각 conv layer당 706개의 parameter니까 전체 layer마다 있다고 생각하면 negligible이 아닌 거 같은데...?)
-
Elastic Depth:
To derive a sub-network that has layers in a unit that originally has layers,
we keep the first layers and skip the last layers.
-
Elastic Width:
we first train a full-width model.
Then we introduce a channel sorting operation to support partial widths.
It reorganizes the channels according to their importance, which is calculated based on the L1 norm of a channel’s weight.
Larger L1 norm means more important.

-
3.4. Specialized Model Deployment with OFA Network
-
Since OFA decouples model training from neural architecture search, we do not need any training cost in this
stage.
Furthermore, we build neural-network-twins to predict the latency and accuracy given a neural network architecture, providing a quick feedback for model quality.
It eliminates the repeated search cost by substituting the measured accuracy/latency with predicted accuracy/latency (twins).
(acc/latency를 "측정"하는게 아니라, "예측") -
구체적으로, 우리는 서로 다른 architectures와 input image sizes를 갖는 16K sub-networks를 randomly sampling한 뒤,
original training set에서 sampling한 10K validation images에 대해
이들으 accuracy를 측정한다.
이렇게 얻은 [architecture, accuracy] pairs를 이용하여, 주어진 architecture와 input image size에 대해 model의 acc를 predicting하는
accuracy predictor를 train한다.
또한 각 target HW platform에 대해 latency lookup table을 구축하여, model의 latency를 predicting한다.
주어진 target HW와 latency constraints가 주어지면, 우리는 accuracy/latency(twins) predictor를 기반으로
evolutionary search를 수행하여 a specialized sub-network를 얻는다.
neural-network-twins를 사용한 searching cost는 negligible하기 때문에, data pairs를 수집하는 데 필요한 비용은 단 40GPU hours에 불과하며,
이 비용은 #(deployment scenarios)와 무관하게 일정하게 유지된다.
4. Experiments
4.1. TRAINING THE ONCE-FOR-ALL NETWORK ON IMAGENET

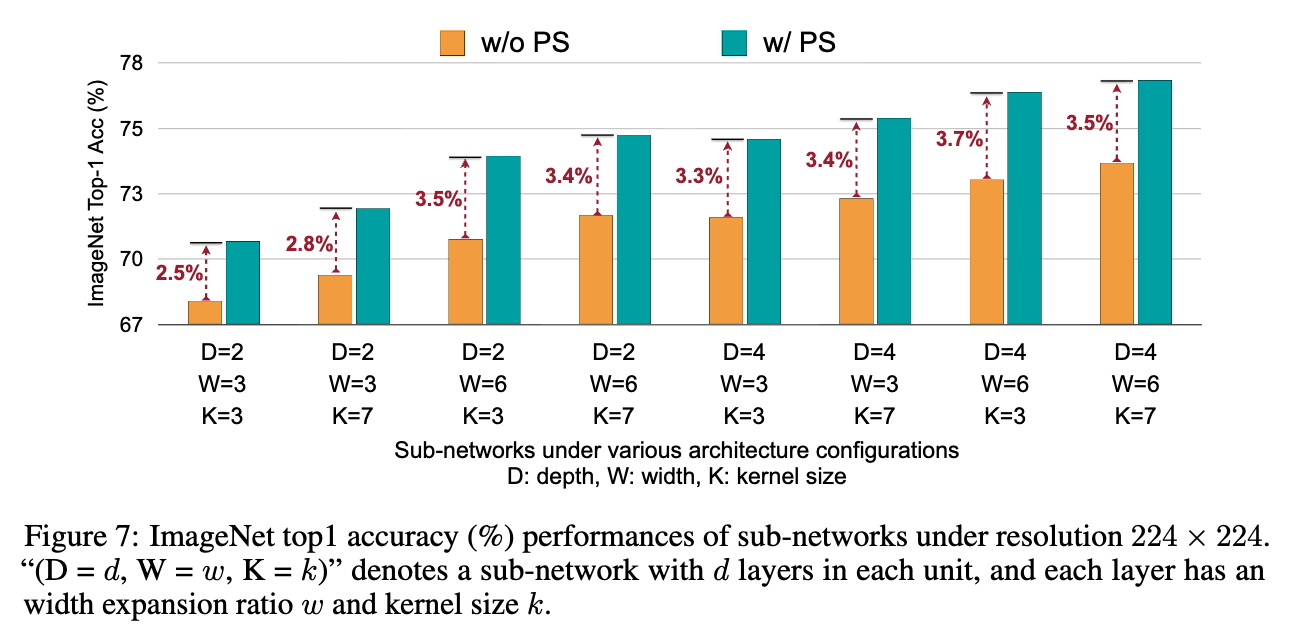
Comparison with NAS on Mobile Devices.
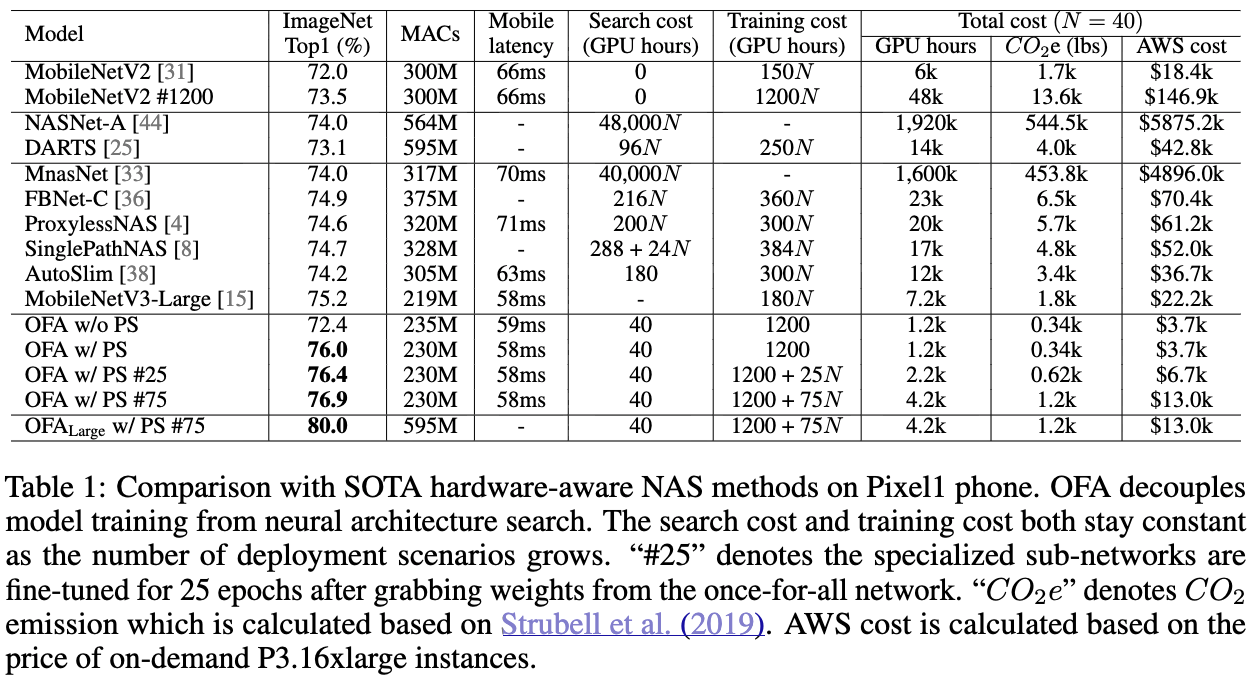
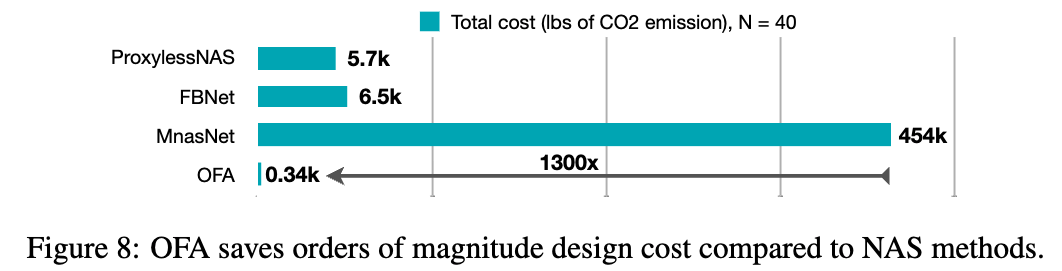
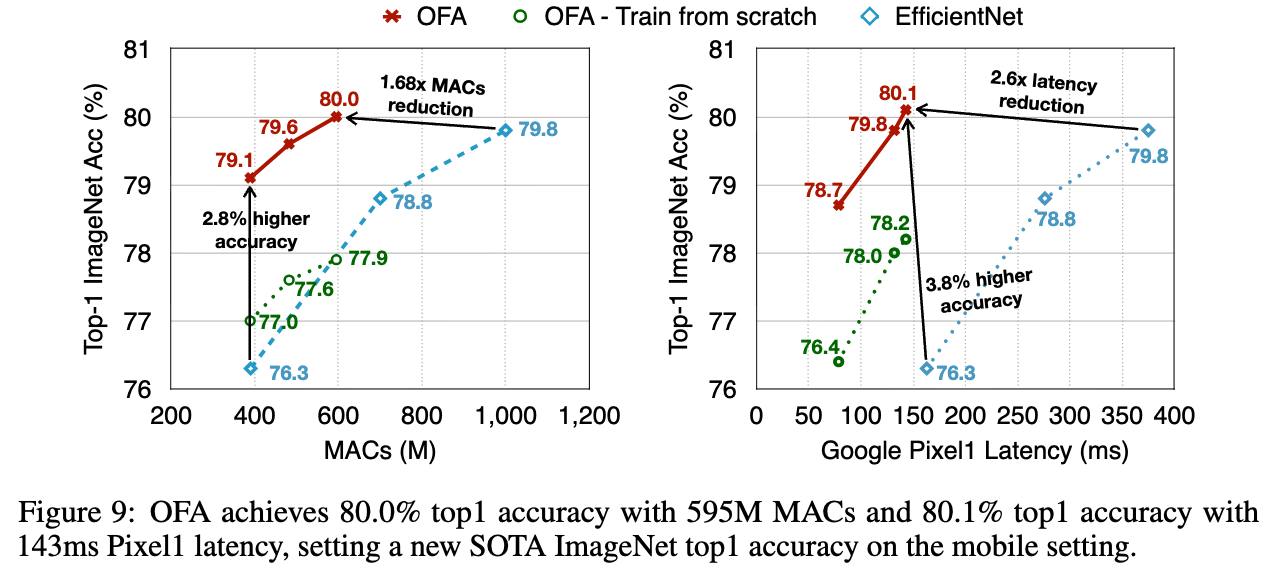
OFA under Different Computational Resource Constraints.
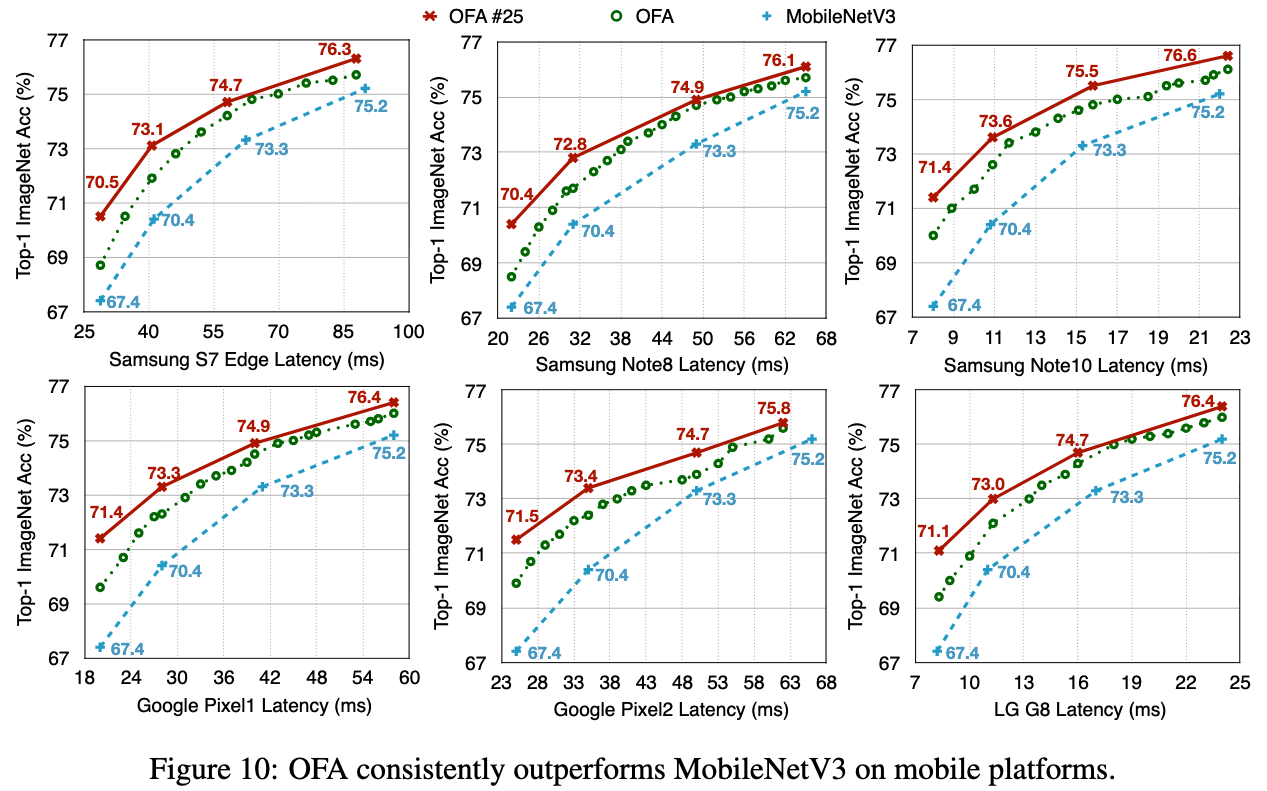
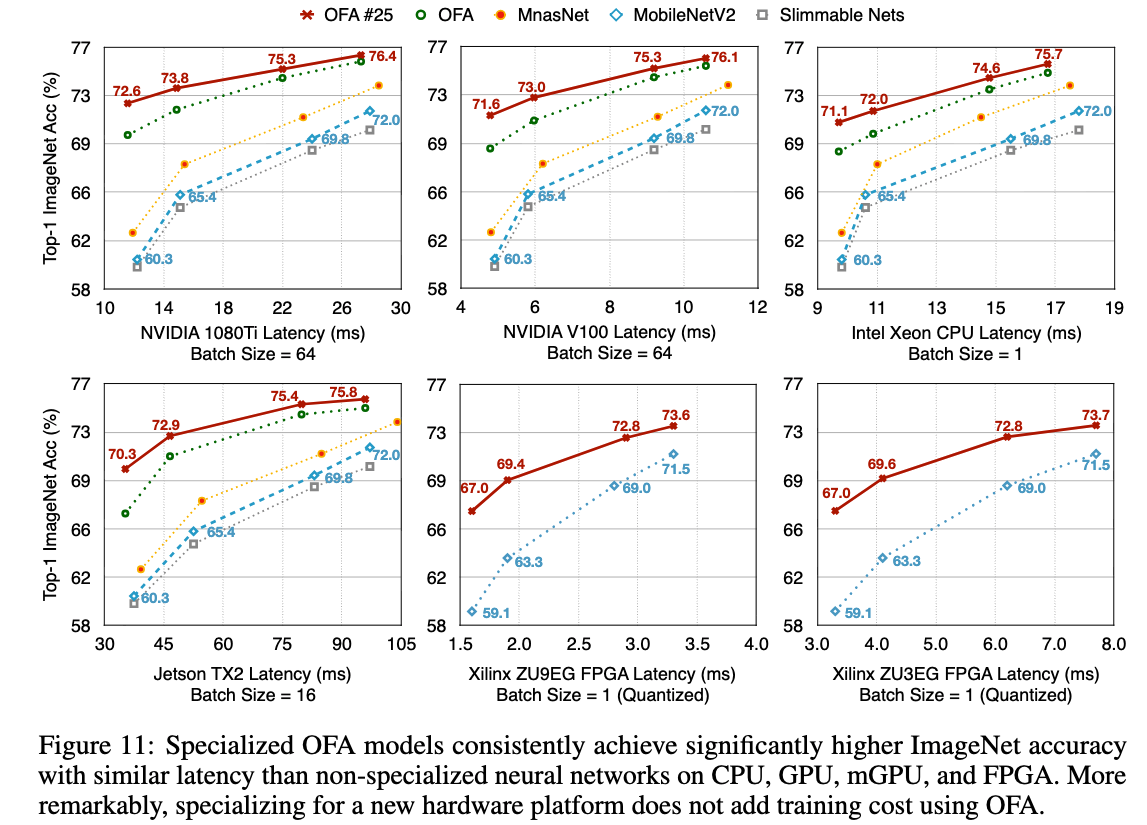
OFA for Diverse Hardware Platforms.
Critique
- Progressive shrinking의 과정은 총 3번의 fine-tuning(elastic resolution은 모든 training 과정 동안 random sampling되어 적용된다고 했으니) 과정이 필요한 거네?
(resolution, kernel size, depth, width에 대한 각각의 fine-tuning)
이 또한 training cost가 상당할 것이라 생각.
