[2021 WACV] Effective Fusion Factor in FPN for Tiny Object Detection
Paper Info.

Abstract
-
FPN-based detectors는 tiny object detection과 같은 certain app scenarios에서 실패한다.
-
이 논문에서는 FPN의 top-down pathway가 tiny object detection에 갖는 two-side influences (not only positive)를 주장한다.
-
그리고 deep layers에서 shallow layers로의 information을 control할 수 있는 fusion factor를 제안한다.
1. Introduction
-
FPN-based detectors는 commonly used object detection datasets, e.g., MS COCO, PASCAL VOC, and CityPersons에서는 great success를 달성하고 있다.
하지만, perform poorly on tiny object detection, e.g., TinyPerson and Tiny CityPersons.
An intuitive question arises: -
why current FPN-based detectors unfit tiny object detection and how to adapt them to tiny object detection.
위 질문에 대한 motivation은 FPN을 이용한 tiny object detection에 대한 experimental results를 분석하던 중 발견한 흥미로운 현상에서 비롯되었다.
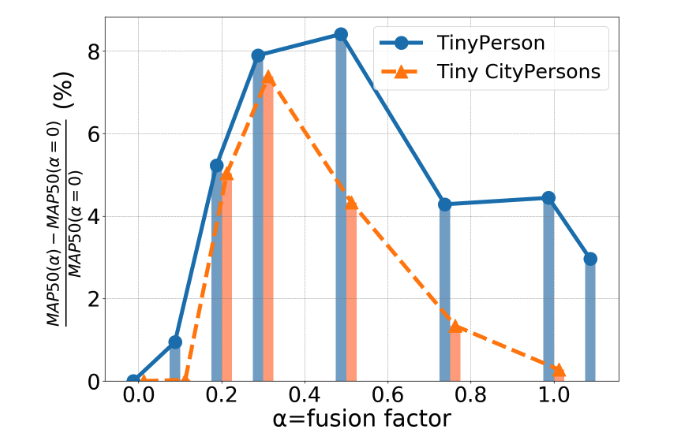
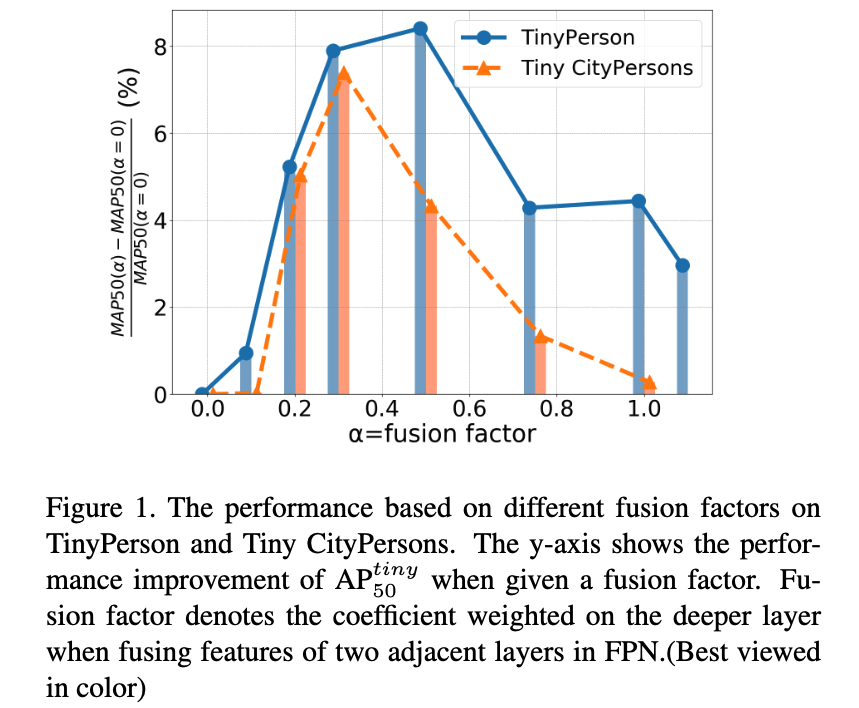 Fig. 1에서 볼 수 있듯이, deep layers에서 shallow layers로 전달되는 정보가 증가함에 따라 성능이 처음에는 증가하다가 이후에는 감소하는 현상이 나타난다.
Fig. 1에서 볼 수 있듯이, deep layers에서 shallow layers로 전달되는 정보가 증가함에 따라 성능이 처음에는 증가하다가 이후에는 감소하는 현상이 나타난다.
우리는 FPN에서 두 개의 인접한 (adjacent) layers를 fusing할 때, deepr layer에 weighted를 곱해주는 coefficient를 fusion factor라고 정의한다.
(내 해석: high level feature가 low level feature에 주는 정보의 양이라고 보면 될 듯하다.) -
위와 같은 현상이 왜 발생하는지 더 자세히 알아보기 위해, 우리는 FPN의 작동원리를 분석했다.
그 결과, 인접한 layer 간의 fusion operation으로 인해 multi-task learning을 수행하고 있다는 사실을 발견했다.
좀 더 구체적으로, FPN에서 top-down connection을 없앤다면, 각 layer는 자신과 가장 관련 있는 크기의 object를 detecting하는 데에만 집중할 수 있다.
예를 들어, shallow layers는 small objects를 학습하고, deep layer는 large objects를 학습하는 식이다.
하지만, FPN에서는 각 layer가 다른 layer의 loss로부터 indirectly (간접적으로) supervised되기 때문에,
사실상 모든 layer가 all size object를 학습해야 하며, 심지어 deep layers도 small objects를 학습해야 한다. -
tiny object detection의 경우, 고려해야 할 두 가지 사실이 있다.
첫 번째는 small object들이 dataset에서 대부분을 차지한다는 점이고,
두 번째는 dataset의 크기가 크지 않다는 점이다.
따라서 각 layer는 자신의 scale에 해당하는 object에만 focus on 할 수 없고, 더 많은 training samples을 얻기 위해 다른 layers로부터의 도움도 필요하다.
이때 fusion factor는 이 두 요구사항 간의 priorities를 조절하여 balance를 잡는 역할을 한다.
기존의 FPN은 fusion factor가 1인 경우에 해당하며, 이는 tiny object detection에는 부적절하다. -
이러한 점을 바탕으로 우리는 먼저, tiny object detection을 위한 FPN의 성능을 향상시키기 위해 여러 관점에서 an effective value of fusion factor를 명시적으로 학습하는 방법을 탐색한다.
particular dataset에 대한 an effective value of fusion factor는 각 layer에 분포된 #objects를 기반으로 한 statistical method를 통해 estimate된다.
그 다음으로 우리는 fusion factor가 학습이 가능한지에 대해서도 두 가지 관점에서 추가 분석을 진행한다.
마지막으로, 우리는 gradient backpropagation의 관점에서 tiny object detection에 적합한 fusion factor 를 designing하는 rationality (타당성)을 설명한다. -
우리의 주요 기여는 다음과 같다:

2. Related Work
2.1. Dataset for Detection
- "In this paper, we focus on the tiny person detection,
and the TinyPerson and Tiny CityPersons are used for experimental comparisons."
2.2. Small Object Detection
-
small object detection에 대해서도 다양한 연구가 활발히 진행되어 왔다.
- [33]에서는 scale matching 기법을 제안, pretrain dataset의 object 크기를 target dataset의 크기와 align함으로써,
신뢰성있는 tiny-object feature representation을 가능하게 함. - SNIP [25]과 SNIPER [26]는 다양한 resolution의 image에서 object 크기를 일정 범위 내에 유지하기 위해 scale regularization strategy를 사용.
특히 SNIPER는 region sampling 기법을 적용하여 학습 효율을 더욱 향상. - Super Resolution, SR은 low resolution object의 정보를 복원하는 데 활용되며, 이에 따라 small object detection에도 도입되었다.
- Noh et al. [22]는 high-resolution object features를 supervision signals로 활용하고,
input과 object features의 관련 receptive fields를 align하는 feature-level super-resolution 기법을 제안. - Chen et al. [3]는 feedback-driven data provider를 제안하여 small object에 대한 loss를 균형 있게 조.
- TridentNet [14]은 서로 다른 receptive field를 가진 parallel multi branches를 구성하여, more discriminative small object's features로 성능 향상.
- [33]에서는 scale matching 기법을 제안, pretrain dataset의 object 크기를 target dataset의 크기와 align함으로써,
-
이러한 방법들은 모두 어느 정도 small object detection 성능 향상에 기여함.
2.3. Feature Fusion for Object Detection
-
deep network에서
shallow layer는 일반적으로 semantic information은 부족하지만 geometric details은 풍부한 반면,
deep layer는 그와 반대의 특성을 갖는다.
FPN [15]은 이러한 shallow layer와 deep layer의 feature를 top-down 방식으로 결합하여 feature pyramid를 구축.
PANet [19]은 bottom-up 방식을 제안하여, deep layer의 object recognition을 shallow layer의 detailed features로 도와준다.
Kong [13]은 global attention와 local reconfiguration 방법을 제안하여, high-level semantic features와 low-level representation을 결합해 feature pyramid를 reconstruct한다.
MHN [2]은 multi-branch 구조와 high-level semantic network를 통해, 서로 다른 feature map을 결합할 때 발생한느 semantic gap 문제를 해결하고, 특히 small-scale objects의 detection 성능을 크게 높혔다.
Nie [21]는 feature enrichment 기법을 통해 multi-scale contextual features을 생성.
HRNet [27]은 repeated cross parallel convolution을 통해 feature representation을 향상.
Libra-RCNN [23]은 모든 feature layer의 fusion 결과를 활용하여 feature map 간의 unbalance를 완화.
ASFF [18]는 feature fusion 시, self-adaptive mechanism을 통해 서로 다른 layer의 feature의 weight를 predict.
Tan [28]은 BiFPN에서 피처 융합의 학습 가능한 가중치(learnable weight) 를 제안했다. -
이러한 접근법들은 각기 다른 관점에서 feature fusion 성능을 향상시켰지만, feature fusion이 dataset의 scale distribution에 의해 영향을 받는다는 점은 간과했다.
3. Effective fusion factor
-
tiny perosn detection을 위한 FPN의 성능에 영향을 미치는 두 가지 주요 요소는 downsampling factor와 adjacent feature layer 간의 fusion proportion이다.
이전 연구에서는 첫 번째 요소에 대해 탐구하였으며, downsampling factor가 낮을수록 성능이 좋아진다는 결론을 내렸지만, computational complexity가 증가한다는 단점이 있다. -
그러나 두 번째 요소인 fusion proportion은 지금까지 간과되어 왔다.
FPN은 adjacent feature layers를 다음과 같은 방식으로 aggregate한다:

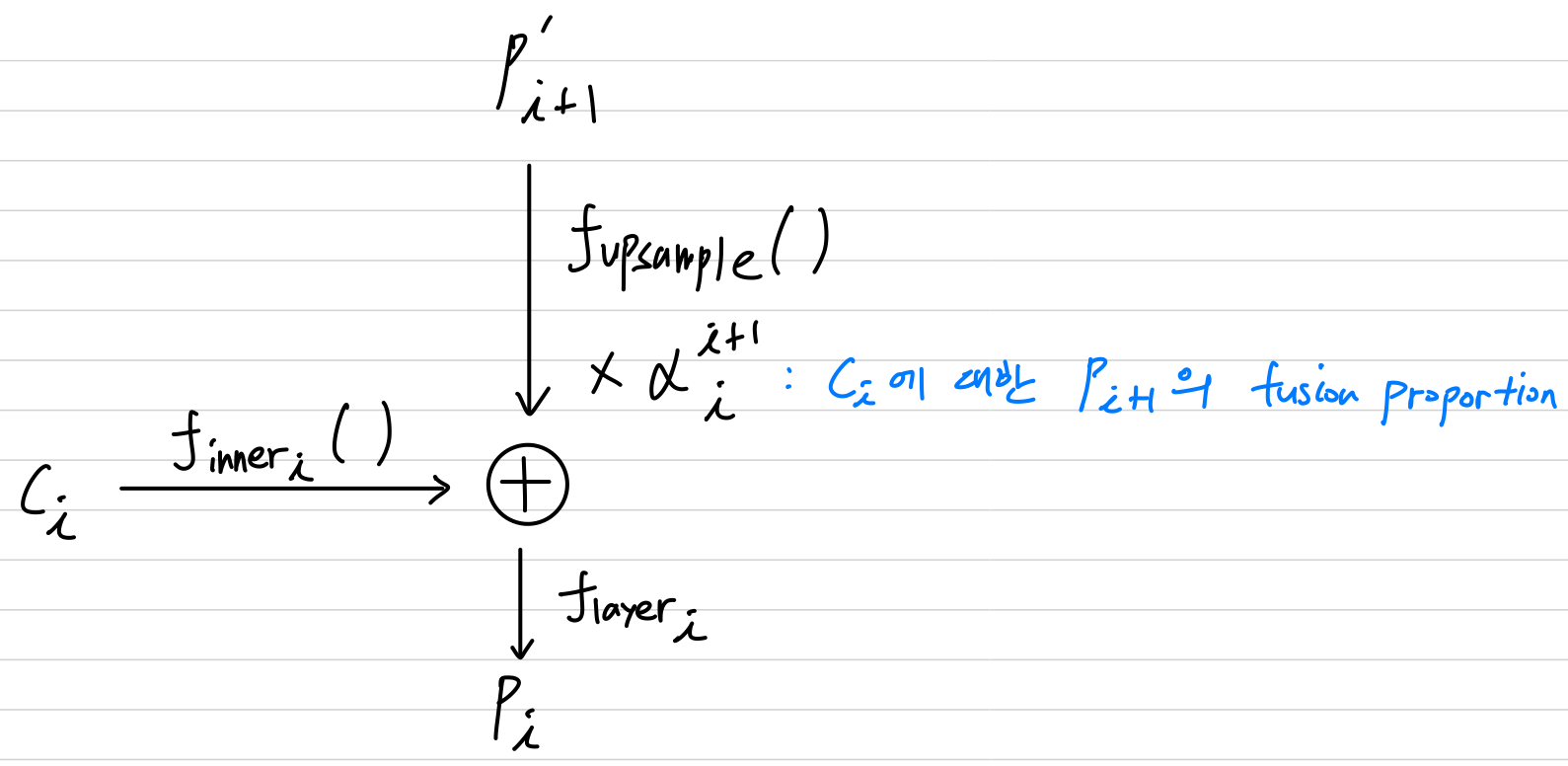
3.1. What affect the effectiveness of fusion factor?
-
effective 를 구하기 위해, 우리는 먼저 어떤 요소들이 fusion factor의 effectiveness에 영향을 미치는지 조사했다.
우리는 dataset의 네 가지 attributes가 에 영향을 줄 수 있다고 가정했다.
(1) The absolute size of objects
(2) The relative size of objects
(3) The data volume of the dataset
(4) The distribution of objects in each layer in FPN -
먼저 다양한 dataset에서 fusion factor의 효과를 평가하기 위한 실험을 수행했고, 결과는 Fig.2에 제시.
서로 다른 dataset은 fusion factor에 따라 서로 다른 경향을 보이며, 예를 들어 성능 곡선의 최고점 (the curve peak value)이 다르게 나타남.
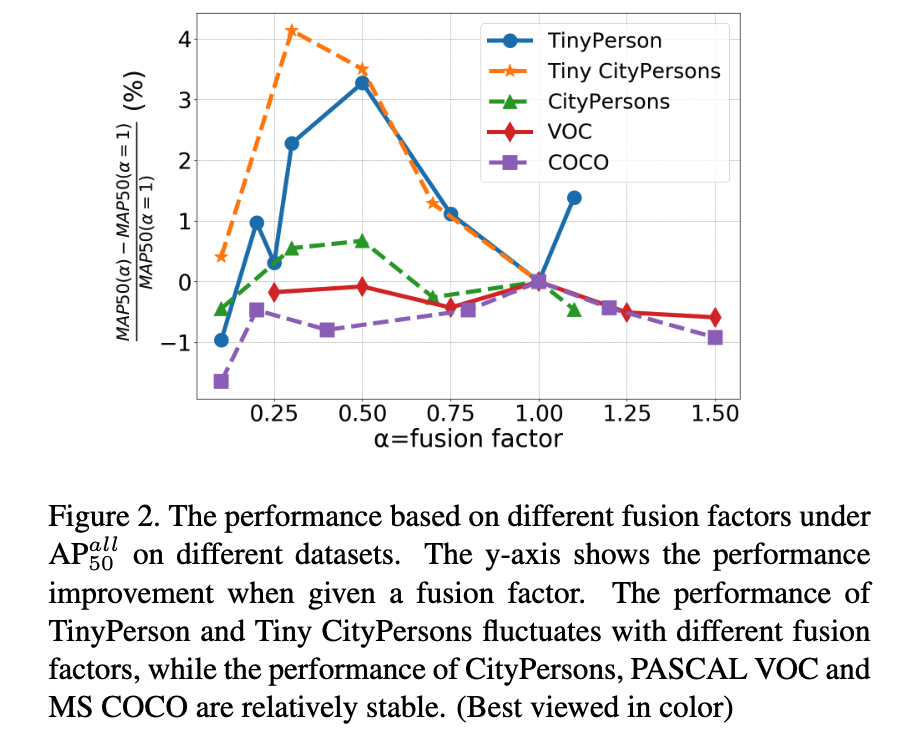
- CityPersons, VOC, COCO와 같은 cross-scale datasets은 값이 변화해도 큰 영향을 받지 않았으며,
단, (즉, feature fusion이 아예 없는 경우) 에만 성능이 급격히 하락하였다. - 하지만 TinyPerson 및 Tiny CityPersons에서는 가 증가함에 따라 성능이 먼저 상승하고, 이후 감소하는 pattern을 보였다.
이것은 fusion factor가 성능에 결정적인 요소이며, 최적의 값 범위가 존재한다는 것을 의미.
이 논문에서는 TinyPerson, Tiny CityPersons, CityPersons에서 수렴이 어렵기 때문에 > 1.1인 경우는 실험하지 않았다.- TinyPerson과 Tiny CityPersons의 공통점은 object의 the average absolute size of instances가 20 px 이하라는 것으로,
이는 network 학습에 큰 challenge가 된다.
따라서 CityPersons와 COCO의 image를 resize하여 서로 다른 dataset을 생성하였다(CityPersons는 2배, 4배 축소, COCO는 4배, 8배 축소).
Fig. 3에 나타난 바와 같이, the absolute size of the objects가 작아질수록 성능이 의 변화에 따라 보이는 경향이 TinyPerson과 유사해졌다.
Tiny CityPersons와 CityPersons는 객체의 상대 크기와 데이터 양은 같지만, fusion factor가 증가함에 따라 성능 변화 경향은 다르게 나타났다.
(이는 dataset 내 object의 absolute size가 fusion factor에 영향을 주는 요인이라는 의미인듯)
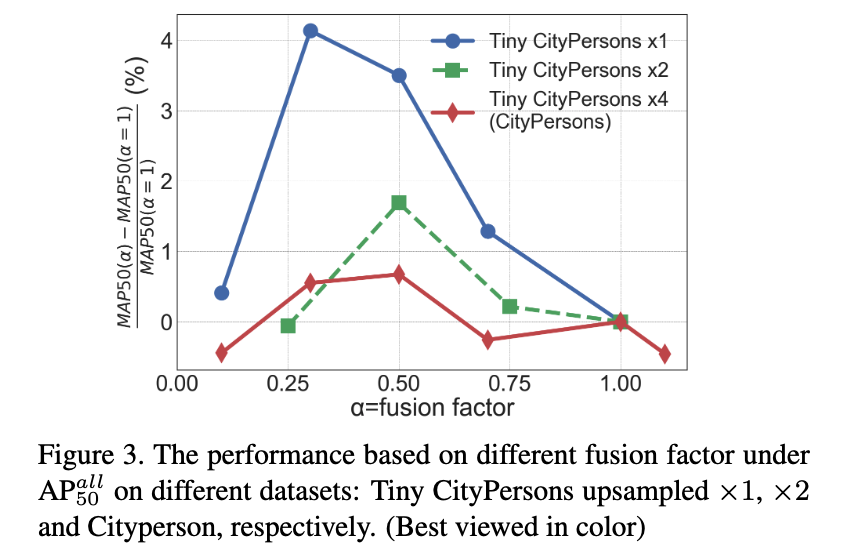
- TinyPerson과 Tiny CityPersons의 공통점은 object의 the average absolute size of instances가 20 px 이하라는 것으로,
- CityPersons, VOC, COCO와 같은 cross-scale datasets은 값이 변화해도 큰 영향을 받지 않았으며,
-
FPN의 각 layer에 object가 어떻게 분포되어 있는지는 각 layer의 training samples 수에 직접적인 영향을 주며, 이는 해당 layer의 feature representation에도 영향을 준다.
CityPersons는 TinyPerson 및 Tiny CityPersons와 유사한 계층 구조(stratification) 를 공유한다.
Tiny CityPersons는 CityPersons의 image를 4배 축소하여 생성되었지만,
Tiny CityPersons의 anchor도 4배 축소되었기 때문에 계층 구조는 여전히 유사하다.
예를 들어, 많은 수의 tiny objects들이 P2와 P3 layer에 집중되어 있으며,
FPN의 deep layer에는 학습에 충분한 objects가 부족하다.
하지만 변화에 따른 성능의 추세는 CityPersons와 Tiny 계열 dataset들 사이에 차이를 보인다. -
따라서 우리는 fusion factor의 효과에 결정적인 영향을 주는 요소는 the absolute size of objects라고 결론내린다.
이를 바탕으로 왜 그리고 어떻게 가 동작하는지를 설명하면 다음과 같다.- 는 gradient back propagation 과정에서 loss를 reweighting함으로써, FPN의 deep layer가 shallow layer 학습에 어느 정도 관여할지를 결정한다.
- Tiny-size object가 많은 dataset에서는, 각 layer의 학습 자체가 어려워지며,
deep layer는 shallow layer를 도울 여유가 없어진다.
즉, FPN에서 deep layer와 shallow layer 간의 supply-demand 관계가 변하였고,
이에 따라 는 낮아져야 하며, 각 layer는 본인 layer의 학습에 더 집중해야 한다는 것을 의미한다.
3.2. How to obtain an effective fusion factor?
- an effective fusion factor를 얻는 방법은 네 가지로 design했다.
- A brute force solution, which enumerates
- A learnable manner. 를 learnable parameter로 세팅하고 loss function에 의해 optimizegka
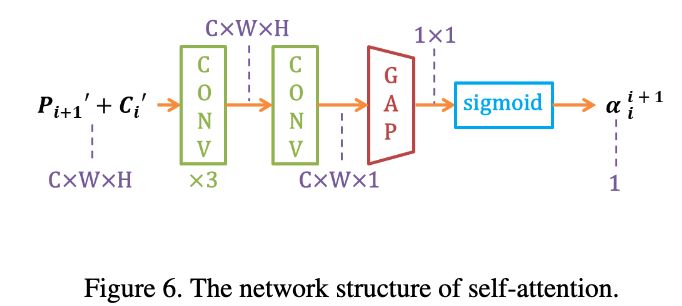
- A attention-based manner. Fig.6에서처럼 self-attention module에 의해 를 생성.
- A statistic-based solution.
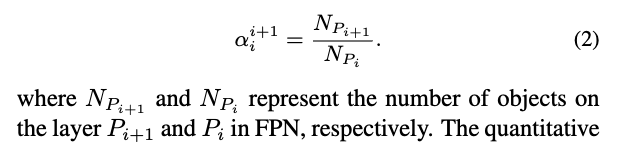
- A brute force solution, which enumerates
-
the statistic-based approach만이 brute force에 대해 경쟁력 있는 성능을 보임.
the statistic-based method, named as S-는 FPN에서 인접한 layer 간 object 수의 비율에 따라 를 설정하는 방식이며, 이는 Eq (2)에 나타나 있다.
object 수는 전체 dataset을 기준으로 집계된다.
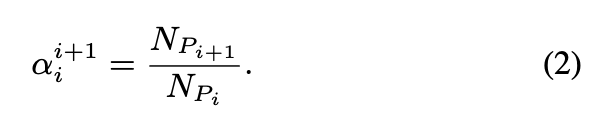
-
우리는 tiny object detection에서는 각 layer가 detection task에 적합한 representative features를 학습하기 어려워지고,
이로 인해 layer 간의 competition이 심화된다는 점에 기반하여 이 수식을 설계했다.
좀 더 구체적으로, multi head 구조의 각 layer는 shared parameters를 통해 자신의 detection task에 적합한 feature를 학습하려고 시도한다.
그러나 일부 layer는 다른 layer보다 training sample 수가 훨씬 적을 수 있으며,
이 경우 shared parameter를 update할 때 이들 layer의 gradient가 다른 layer에 의해 불리해지는 문제가 발생한다.
따라서 (다음 layer의 #objs)가 작거나 (현재 layer의 #objs)가 크면,
해당 layer 의 detection task에서 발생하는 gradient를 줄이기 위해 작은 값이 설정된다.
(반대의 경우는 값이 커짐)
이는 각 layer의 detection task가 균등하게 학습될 수 있도록 유도한다. -
의 statistic procedure 및 계산 방식은 다음과 같다:
1. IoU를 기준으로, 각 image에서 GT (Ground Truth) 와 largest IoU를 가지는 anchor를 positive sample로 선택한다.
2. 선택된 positive anchor들과 각 layer의 predefined anchor 개수를 바탕으로, 각 layer의 GT 개수()를 계산한다.
3. dataset의 모든 image에 대해 1~2단계를 반복하여 통계적 결과를 얻고,
Eq (2)에 따라 를 계산한다.
이 계산 과정은 Fig. 4의 left dashed box에 나타나 있다.
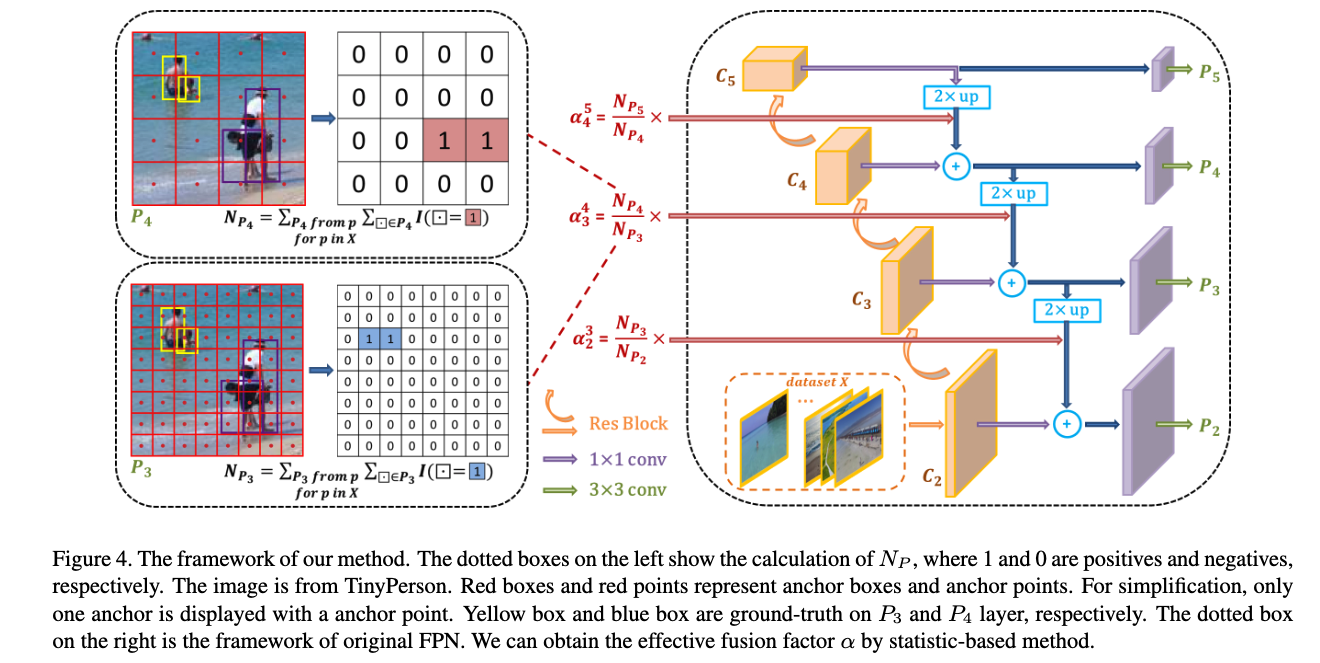
자세한 절차는 Algorithm 1에.
4. Experiment

Intuition
Tiny OD에서는 low level feature가 detection에 중요한 역할을 하므로 high level feature가 fusion 시에 low level feature에 미치는 영향을 scaling해야 한다.
근데 그 scaling factor를 statistics or learnable parameter로 정하는 방법을 제안한다.
