[Simple Review] [2022 CVPR] Restormer: Efficient Transformer for High-Resolution Image Restoration
[Paper Review] Efficient and Scalable
Paper Info.

Abstract
(배경)
- CNNs은 large scale data로부터 generalizable image priors을 잘 학습할 수 있기 때문에,
image restoration and related tasks에 널리 활용되어 왔다.
최근에는 Transformer라는 또 다른 형태의 neural architectures 구조가 NLP 및 high-level vision tasks에서 significant performance gains을 보여주며 주목받고 있다.
(문제 제기)
- Transformer model은 CNN의 한계 (즉, limited receptive field and inadaptability to input content)를 보완할 수 있지만,
spatial resolution이 높아질수록 computational complexity가 quadratically 증가하기 때문에 대부분의 high-resolution images restoration 작업에는 적용이 어렵다는 문제가 있다.
(제안)
-
본 연구에서는 several key designs in the building blocks (multi-head attention and feed-forward network)을 만듦으로써,
an efficeint Transformer model을 제안한다.
이 model은 long-range pixel interactions을 capture하면서도, 여전히 large images에 applicable하도록 만들었다. -
제안된 model은 Resotration Transformer (Restormer)로 이름지으며, 다음과 같은 image restoration task에서 SOTA를 달성했다:
- image deraining
- single-image motion deblurring
- defocus deblurring
- image denoising
- real-time denoising
1. Introduction
(배경)
- Image Restoration은 noise, blur, rain drops 등의 degradation 요소가 포함된 input image로부터 high-quality image를 reconstructing하는 작업이다.
이 문제는 ill-posed (잘 정의되지 않은) 특성을 가지므로 매우 어렵고, 효과적인 복원을 위해서는 strong image priors가 필요하다.
CNN은 large-scale data로부터 generalizable priors을 잘 학습할 수 있기 때문에, conventional restoration approaches보다 더 선호되었다.
CNN의 basic operation은 'convolution'이며, 이는 local connectivity와 translation equivariance를 제공한다.
이러한 특성은 CNN의 efficiency and generalization을 높이지만, 다음과 같은 two main issues를 야기한다:- The convolution operator has a limited receptive field, thus preventing it from modeling long-range pixel dependencies.
- The convolution filters have static weights at inference, and thereby cannot flexibly adapt to the input content.
- 이러한 shortcomings을 해결하기 위해 more powerful and dynamic alternative으로 Self-Attention (SA) mechanism이 제안되었다.
SA는 a given pixel의 response를 a weighted sum of all other positions으로 계산할 수 있다.
Self-Attention은 Transformer model의 core component며, parallelization and effective representation learning을 위해 최적화되었다.
NLP에서 SOTA를 보여줬고, 최근에는 high-level vision problems에서도 우수한 성과를 거두고 있다.
(문제, motivation)
- 그러나 Self-Attention은 spatial resolution에 대해 complexity가 quadractically 증가하기 때문에, high-resolution images를 다루기에는 부적합하다.
최근 몇몇 연구에서는 Transformer를 image restoration에 적용하려는 시도가 있었지만, 계산량을 줄이기 위해 다음과 같은 제약을 둔다:
특정 위치 주변의 8x8 small sindow 내에서만 SA적용, input image를 48x48 patch로 나누고 각 patch 내에서 독립적으로 SA 적용
하지만 이러한 방식은 Self-Attention의 본질인 long-range pixel relationships을 포착하는 능력과는 모순되며, 특히 high-resolution images에 있어서 근본적인 한계를 드러낸다.
(제안)
-
이 논문에서는 large images에 applicable하면서도 global connectiviy를 modeling할 수 있는 efficient Transformer for image restoration을 제안한다.
구체적으로, 기존의 multi-head Self-Attention (SA) 대신 linear complexity를 갖는 multi-Dconv head 'transposed' attention (MDTA) block(Sec. 3.1.)을 도입한다.
MDTA는 spatial dimension이 아닌 feature dimension에서 Self-Attention을 수행한다.
즉, pairwise pixel interactions을 직접 modeling하는 대신, input features (=key and query projected)로부터 attention map을 얻기 위해 cross-covariance across feature channels을 생성한다.
이는 1x1 von and channel-wise aggregation of local context using efficient depth-wise convolutions을 활용한 pixel-wise aggregation of cross-channel context를 통해 달성된다.
이 strategy는 two key advantages를 제공한다.- spatially local context을 강조하면서 convolution operation의 strength를 통합한다.
- covariance-based attention maps을 계산하는 과정에서, the contextualized global relationships을 보장한다.
-
A feed-forward network (FN)은 Transformer의 또 다른 핵심 구성 요소이다.
이는 two fc layers with a non-linearity in between으로 구성된다.
본 논문에서는 the first linear transformation layer in the regular FN을 a gating mechanism으로 reformulate하여 information flow를 개선한다.
this gating layer는 the element-wise product of two linear projection layers, one of which is activated with the GELU non-linearity로 구성된다.
Our gated-Dconv FN (GDFN)도 MDTA와 마찬가지로 local content mixing 방식을 적용하여, spatial context에 대한 균형 있는 강조를 실현한다.
Gating mechanism은 유용하지 않은 특성을 억제하고, 중요한 특성만 다음 layer로 전달하여, more refined image attributes과 high-quality outputs으로 이어지게 한다. -
위의 architectural novelties 외에도, 이 논문에서는 Restormer의 progressive learning의 effectiveness를 입증한다. (Sec. 3.3)
early epochs에는 small patches와 large batches로 학습하고,
점차 large image patches and small batches로 전환한다.
이러한 training strategy는 model이 large images로부터 context를 학습하는 데 효과적이며, test quality performance improvements로 이어진다. -
The main contributions of this work are summarized below:
- We propose Restormer, an encoder-decoder Transformer for multi-scale local-global representation learning on high-resolution images without disintegrating them into local windows, thereby exploiting distant image context.
- We propose a multi-Dconv head transposed attention (MDTA) module that is capable of aggregating local and non-local pixel interactions,
and is efficient enough to process high-resolution images. - A new gated-Dconv feed-forward network (GDFN) that performs controlled feature transformation,
i.e., suppressing less informative features, and allowing only the useful information to pass further through the network hierarchy.
2. Background
Image Restoration
- 최근 몇 년 간, data-driven CNN architectures는 기존의 restoration approaches보다 뛰어난 성능을 보여주고 있다.
convolution designs 중에, encoder-decoder based U-Net architectures는 their hierarchical multi-scale representation while remaining computationally efficient 덕분에 restoration에서 많이 연구되었다.
... skip
Vision Transformer
-
However, the computational complexity of SA in Transformers can increase quadratically with the number of image patches, therby prohibiting its application to high-resolution images.
One potential remedy is to apply self-attention within local image regions [44, 80] using the Swin Transformer design [44].
However, this design choice restricts the context aggregation within local neighbourhood,
defying the main motivation of using self-attention over convolutions,
thus not ideally suited for image-restoration tasks.
... skip -
그래서 우리는 a Transformer model that can learn long-range dependencies while remaining computationally efficient.
3. Method
- Our main goal은 high-resolution images를 처리할 수 있는 efficient Transformer model을 개발하여 image restoration tasks에 활용하는 것이다.
computational bottleneck을 완화하기 위해, 우리는 multi-head SA layer와 a multi-scale hierarchical module that has lesser computing requirements than a single-scale network에 핵심적인 designs을 도입한다.
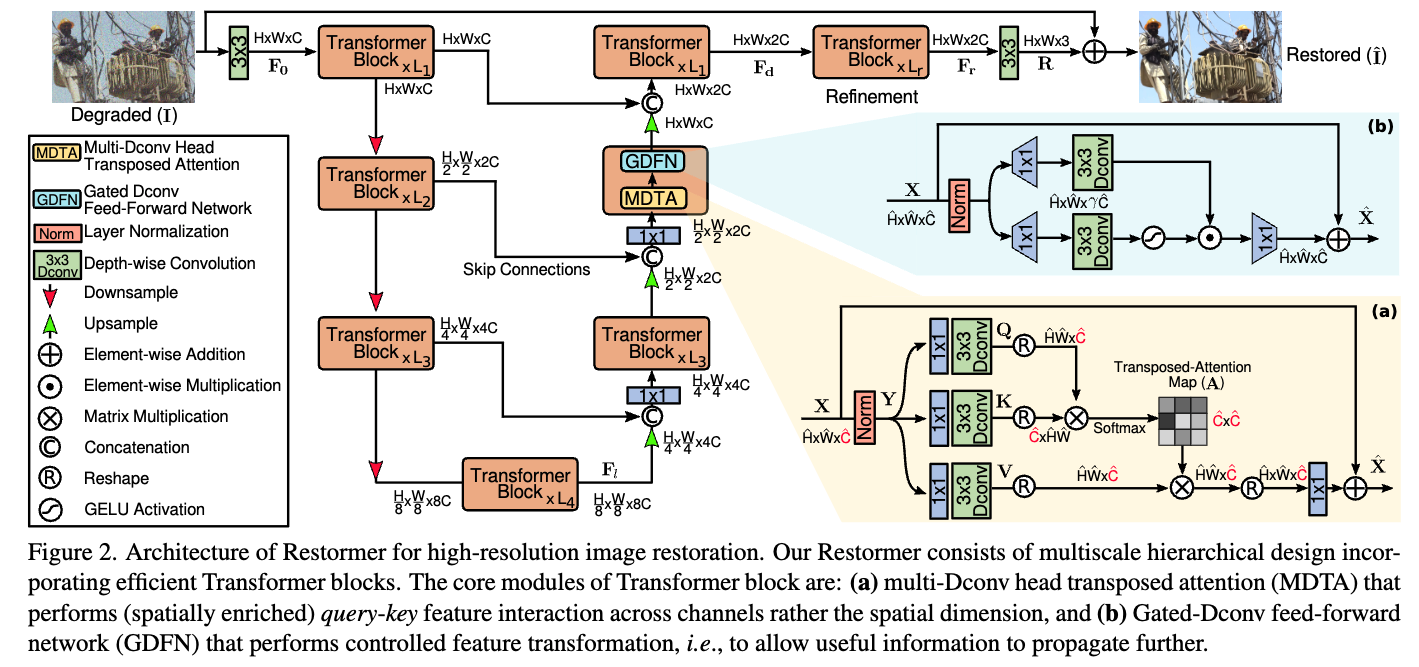
먼저, Restormer architecture의 overall pipeline을 소개한다 (Fig.2).
그 다음, 제안된 Transformer block의 핵심 구성 요소인:
(a) multi-Dconv head transposed attention (MDTA)와
(b) gated-Dconv feed-forward network (GDFN)을 설명한다.
마지막으로, image statistics을 효과적으로 학습하기 위한 progressive training scheme의 details을 제공한다.
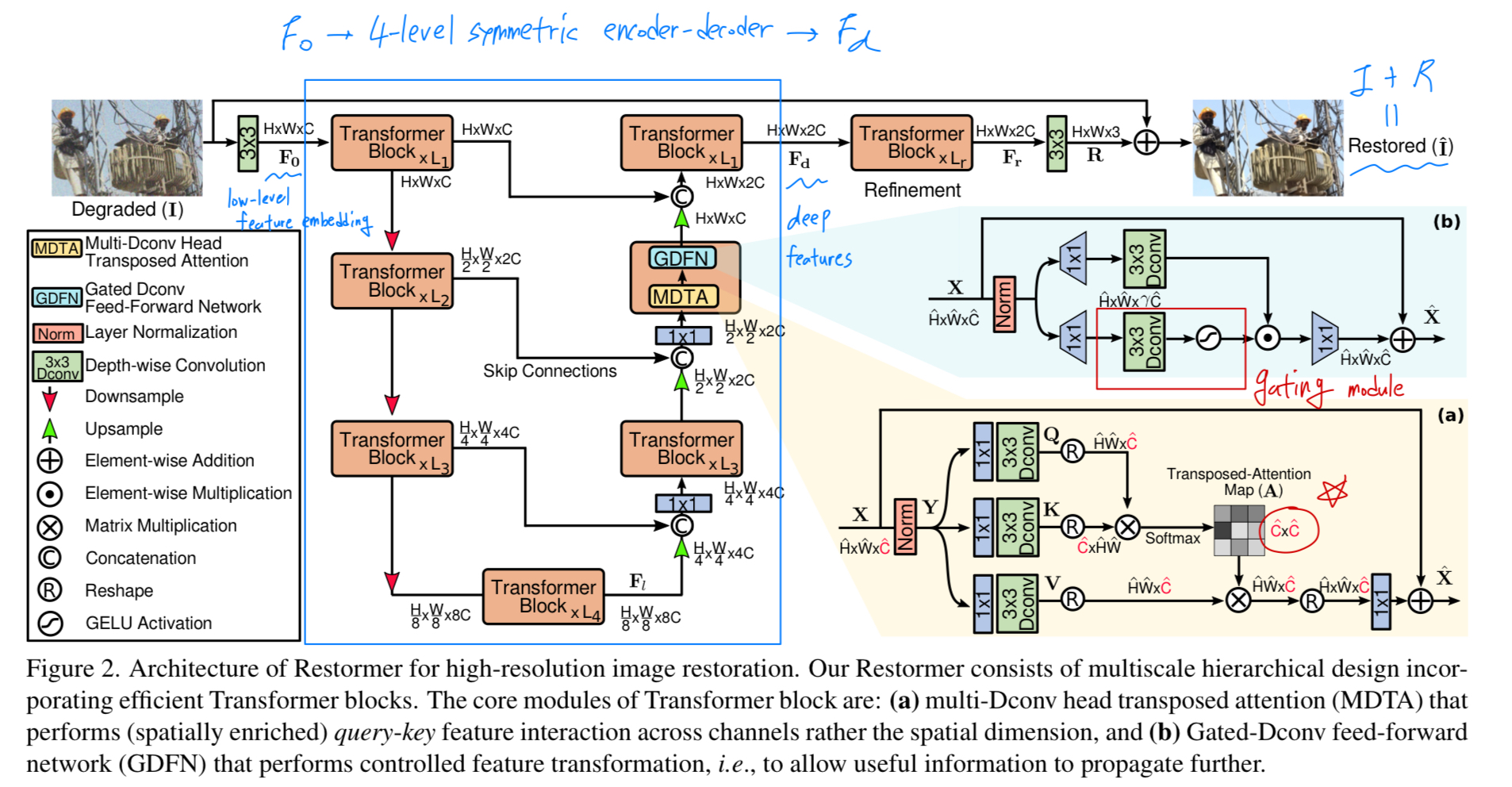
Overall Pipeline
-
a degraded image 가 주어졌을 때,
Restormer는 먼저 convolution을 활용하여 low-level feature embeddings 를 생성한다.
그 다음, 이 shallow features 는 4-level symmetric encoder-decoder에 들어가고 deep features 로 transformed된다.
Each level of encoder-decoder는 multiple Transformer blocks을 포함하고, #blocks은 top에서 bottom으로 갈수록 efficiency를 유지하기 위해 증가된다.
high-resolution input으로부터 시작하여, encoder는 spatial size를 줄이는 동시에, channel capacity를 확장한다.
decoder는 low-resolution latent features 을 input으로 받아 high-resolution representations을 점진적으로 recover한다.
feature downsampling and upsampling을 위해 각각 pixel-unshuffle and pixel-shuffle operations 연산을 사용한다. -
the recovery process를 보조하기 위해, encoder features는 skip connections을 통해 decoder feature와 연결된다.
이 연결된 feature는 1x1 conv를 통해 #channels을 절반으로 줄이며, 이는 the top level을 제외한 모든 level에서 적용된디ㅏ.
level-1에서는, Transformer block이 encoder의 low-level image features와 decoder의 high-level features를 aggregate하도록 하여,
restored images로부터 fine structural and textural details을 보존하는 데 도움을 준다.
그 후, deep feature 는 high spatial resolution에서 작동하는 refinement stage에서 추추가적으로 풍부하게 처리된다.
이러한 design choices는 sec. 4에서 확인할 수 있듯이 성능 향상에 기여한다.
마지막으로, refined featrues에 residual image 을 생성하고, 이를 원래의 degraded image에 더하여 restored image: 을 얻는다. -
다음으로 우리는 Transformer block에 대해 설명한다.
skip
몰랐던 것, pixel-(un) shuffle = (down)upsampling
- pixel (un)shuffle: https://docs.pytorch.org/docs/stable/generated/torch.nn.PixelUnshuffle.html
 (그림 참고)https://www.researchgate.net/figure/Illustration-of-pixel-shuffle-and-pixel-unshuffle-From-left-to-right-is-pixel-shuffle_fig2_373517112
(그림 참고)https://www.researchgate.net/figure/Illustration-of-pixel-shuffle-and-pixel-unshuffle-From-left-to-right-is-pixel-shuffle_fig2_373517112
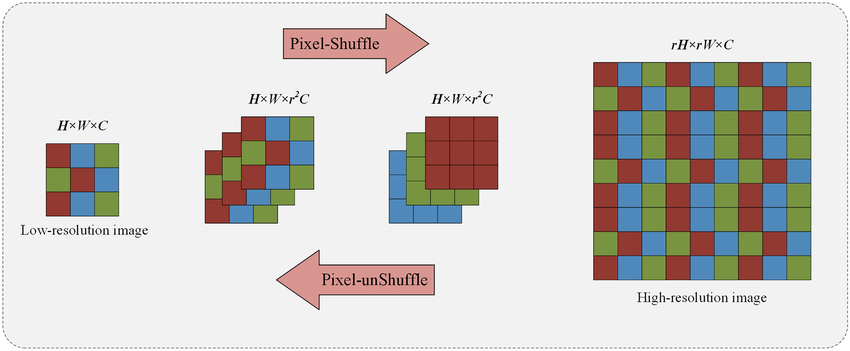
- pixel-shuffle: upsampling
pixel-unShuffle: downsampling
- pixel-shuffle: upsampling
