[2023 ICCV] EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction
[Paper Review] Efficient and Scalable
Paper Info.

Abstract
-
high-resolution dense prediction은 computational photograpy, autonomous driving, etc 등 다양한 real-world applications에 매우 유용하다.
하지만 SOTA high-resolution dense prediction models은 the vast (막대한) computational cost로 인해 HW device에 deploying하기 어렵다.
본 연구에서는 EfficientViT, a new family of high-resolution vision models with novel lightweight multi-scale attention을 제안한다. -
기존의 high-resolution dense prediction models들은 good performance를 달성하기 위해,
heavy self-attention, HW inefficient large-kernel convolution, or complicated topology structure에 의존하는 반면,
EfficientViT의 lightweight multi-scale attention은
global receptive field과multi-scale learning이라는 high-resolution dense prediction에서 중요한 두 가지 요소를,
only lightweight and HW-efficient operations만으로 달성했다. -
이러한 설계 덕분에 Efficient ViT는 mobile CPU, edge GPU, cloud GPU 등 다양한 HW platform에서 기존 SOTA model보다 눈에 띄는 performance gains과 speedup을 보여준다.
1. Introduction
(배경)
- High-resolution dense prediction은 CV의 fundamental task이고 real-world scenarios에 다양하게 적용되고 있다.
하지만 SOTA high-resolution dense prediction models은 필요로 하는 computational cost와 the limited resources of HW devices 간의 큰 차이가 있다.
특히. high-resolution dense prediction models은 high-resolution images와 strong context information extraction ability를 필요로 하므로,
image classification에서 efficient model design을 그대로 가져오는 것은 적합하지 않다.
(제안 & 이전 연구의 문제점)
- 본 논문에서는 efficient high-resolution dense prediction을 위한 a new family of models, EfficientViT를 제안한다.
EfficientViT의 핵심은 a novel lightweight multi-scale attention module that
enablesa global receptive fieldandmulti-scale learning with HW-efficient operations이다.
이 module은 prior SOTA high-resolution dense prediction models에서 영감을 받았다.
그들은 multi-scale learning, and global receptive field가 performance 향상에 중요하다는 점을 보여줬다.
하지만 이 model들은 설계 시 HW efficiency를 고려하지 않았는데, 이는 real-world applications에서 중요한 요소이다.- 예를 들어,
SegFormer [51]는 global receptive field를 확보하기 위해 backbone에 self-attention을 도입했지만,
이는 input resolution에 대해 computational complexity가 quadratic하므로 high-resolution images를 효율적으로 처리할 수 없다.
SegNeXt [18]는 large-kernel (최대 21)을 사용하는 a multi-branch module을 제안하여 a large receptive field and multi-scale learning을 달성하려 했다.
그러나 large kernel convolution은 good efficiency를 달성하기 위해 exceptional support on HW를 필요로 한다.
- 예를 들어,
(제안 방법 디테일)
-
따라서, 본 연구에서 제안하는 module의 design principle은 HW-inefficient operations을 피하면서 다음의 two critical features를 가능하게 한다.
구체적으로,- a global receptive field를 얻기 위해 inefficient self-attention을 lightweight ReLU-based global attention으로 대체한다.
matrix multiplication의 associative property (결합 법칙)을 활용함으로써, ReLU-based global attention은 기능을 유지하면서 computational complexity를 quadratic에서 linear로 줄일 수 있다.
또한, softmax와 같은 HW-inefficient operations을 사용하지 않아 HW deployment에 더욱 적합하다. - 우리는 ReLU-based global attention에 기반한 a novel lightweight multi-scale attention module을 제안한다.
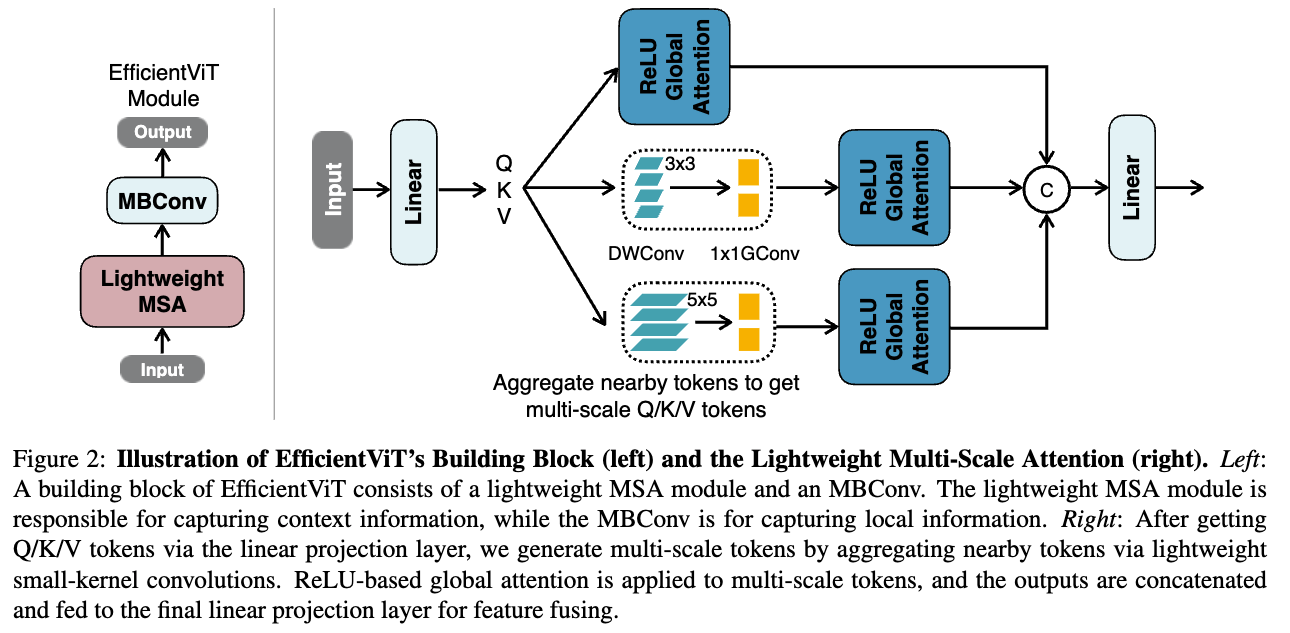
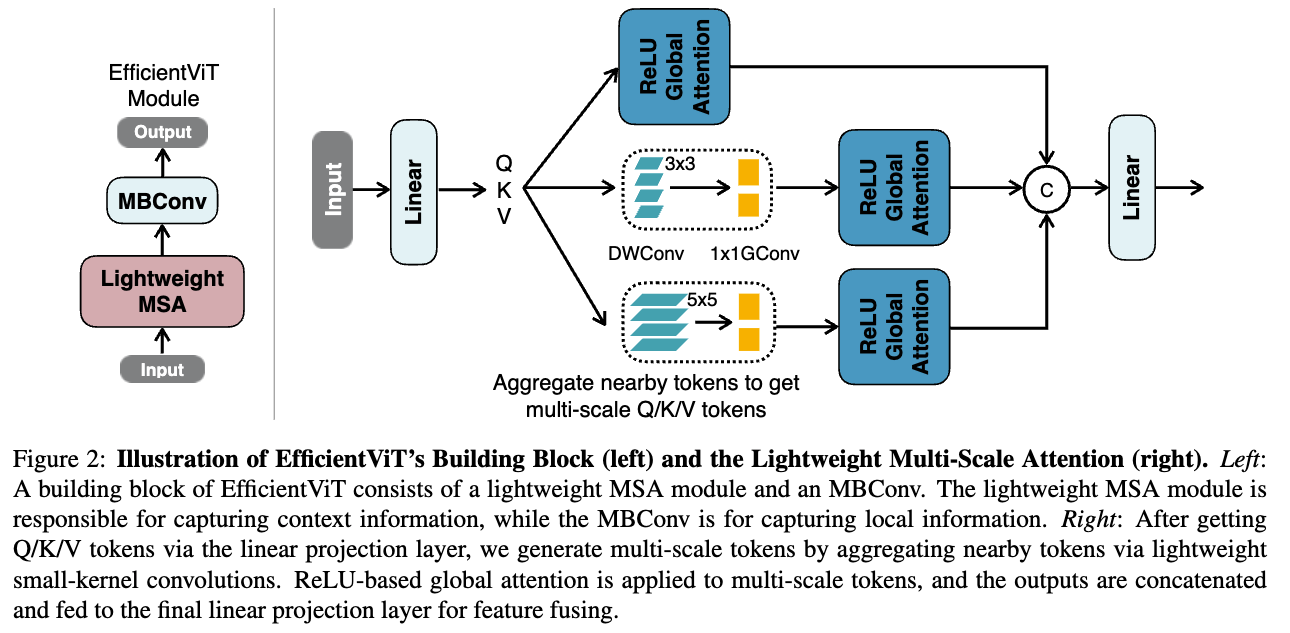
구체적으로, small-kernel convolutions을 통해 nearby(인접한) tokens을 aggregate하여 multi-scale tokens을 생성하고,
이 multi-scale tokens에 대해 ReLU-based global attention을 수행한다.
이를 통해 global receptive field와 multi-scale learning을 결합할 수 있다.
Table 1에서는 prior SOTA high-resolution dense prediction models과 our work를 비교하여 요약했다.

- a global receptive field를 얻기 위해 inefficient self-attention을 lightweight ReLU-based global attention으로 대체한다.
-
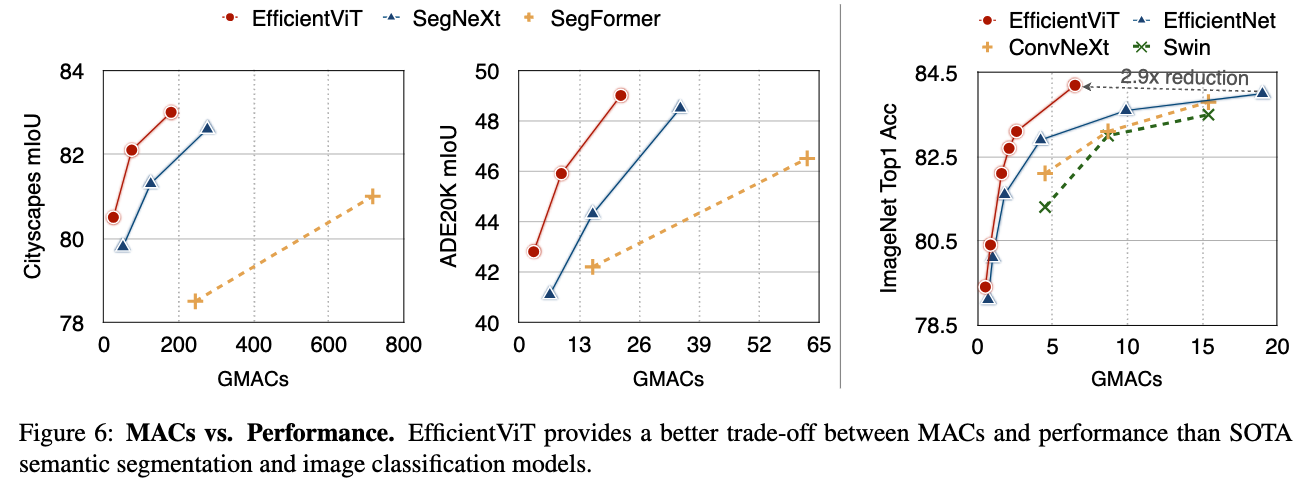
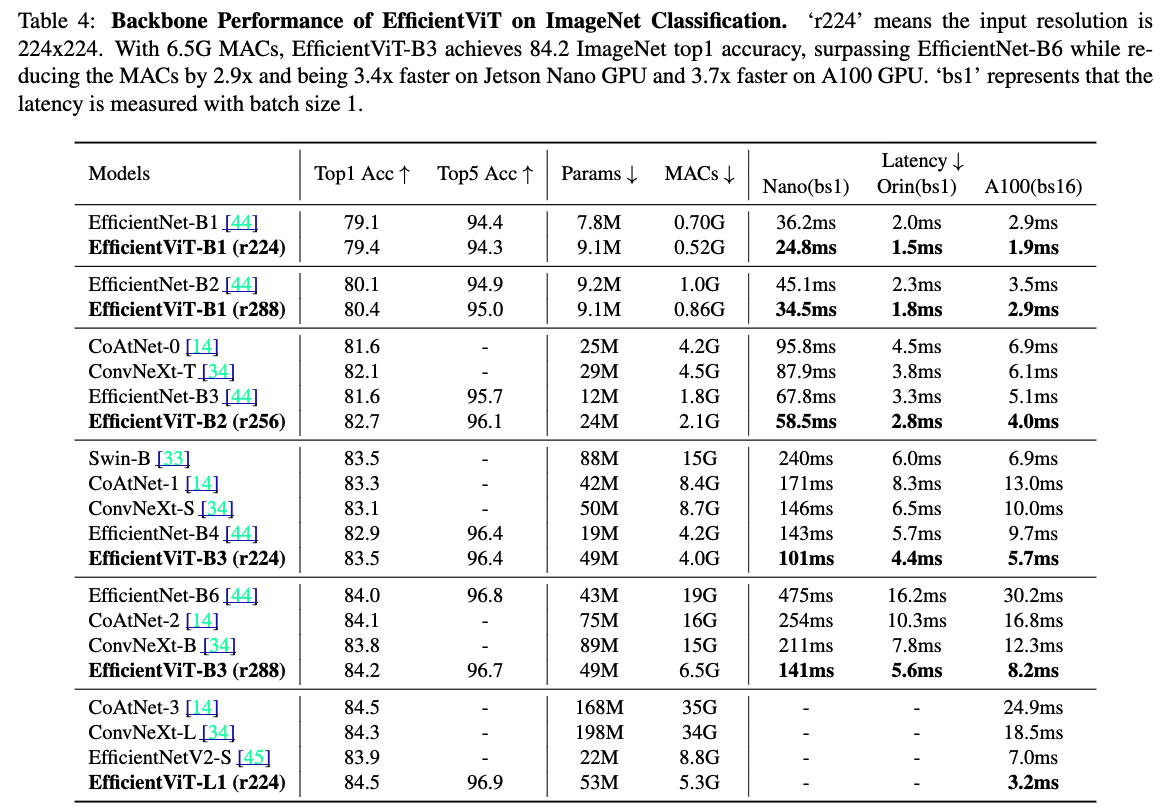
우리는 EfficientViT를 두 가지 대표적인 high-resolution dense prediction tasks: semantic segmentation and super-resolution에서 evaluate했다.
EfficientViT는 기존 SOTA high-resolution dense prediction models보다 significant performance boost를 보여준다.
더욱 중요한 점은, EfficientViT가 HW-inefficient operations을 포함하지 않기 때문에,
FLOPs 감소가 실제 HW devices에서 latency 감소로 직접 이어질 수 있다는 점이다.
We summarize our contributions as follows:

2. Method
- 이 section에서는 첫번째로 lightweight Multi-Scale Attention (MSA)를 소개한다.
prior works와 다르게, our lightweight MSA module은 a global receptive field and multi-scale learning with only HW-efficient operations을 달성할 수 있다.
그리고나서, MSA module에 기반하여, a new family of vision models named EfficientViT for high-resolution dense preidction을 소개한다.
2.1. Lightweight Multi-Scale Attention
-
Our lightweight MSA module은 two crucial aspects of efficient high-resolution dense prediction을 balances한다. 즉, performance and efficiency
특히, a global receptive field and multi-scale learning은 performance 측면에서 필수적이다.
이전의 SOTA high-resolution dense prediction models은 이 features들로 strong performances를 제공할 수 있었지만 good efficiency를 제공하는 데에 실패했다.
우리의 module은 약간의 capacity를 희생하는 대신, significant efficiency improvements를 통해 이 문제를 완화한다. -
제안하는 lightweight MSA module은 Figure 2 (right)에 나타나 있다.
특히, 우리는 무거운 self-attention 대신, the global receptive field를 가능하게 하기 위해 lightweight ReLU-based attention [28]을 사용한다.
ReLU -based attention 및 기타 linear attention modules들은 other domains에서 연구된 바 있지만, high-resolution dense prediction에 성공적으로 적용된 적은 없었다.
우리가 아는 한, EfficientViT는 high-resolution dense prediction에서 ReLU-based attentions's effectiveness를 입증한 최초의 연구이다.
Enabling Global Receptive Field with Lightweight ReLU-based Attention.
-
input 가 주어졌을때, self-attention의 일반적인 form은 다음과 같다:
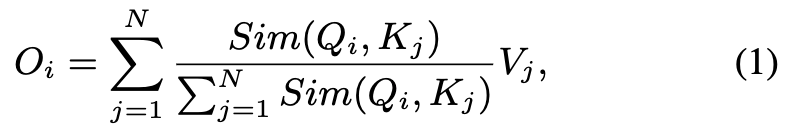 여기서 , , 이고 는 learnable linear projection matrix이다.
여기서 , , 이고 는 learnable linear projection matrix이다.
는 i-th row of matrix 를 나타낸다.
은 similarity function이다.
teh similarity function 일 때, Eq. (1)은 the original self-attention이 된다. -
외에도, 다른 similarity function을 사용할 수 있다.
이 연구에서, 우리는 both the global receptive field and linear computational complexity를 달성하기 위해 ReLU-based global attention을 사용했다.
ReLU-based global attention에서, the similarity function은 다음과 같이 정의된다:
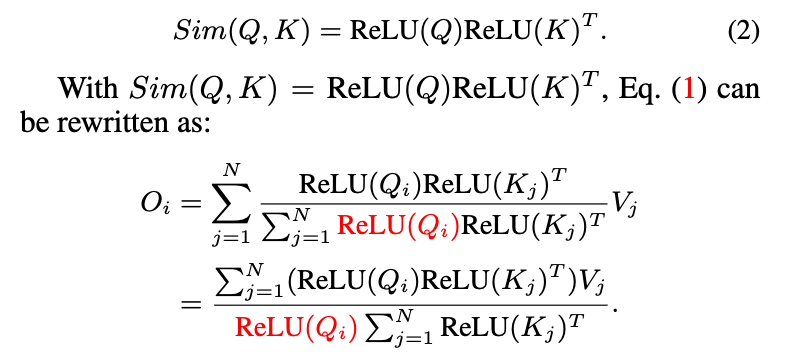 그리고 나서, 우리는 the computational complexity를 줄이기 위해서 the associative property(결합법칙) of matrix multiplication을 수반할 수 있고
그리고 나서, 우리는 the computational complexity를 줄이기 위해서 the associative property(결합법칙) of matrix multiplication을 수반할 수 있고
memory footprint from quadratic to linear without changing the functionality를 수반할 수 있다:
 ReLU-based global attention의 another key는 softmax처럼 HW-unfriendly operations을 포함하지 않는다는 것이고, 이는 HW에서 more efficient하게 만든다.
ReLU-based global attention의 another key는 softmax처럼 HW-unfriendly operations을 포함하지 않는다는 것이고, 이는 HW에서 more efficient하게 만든다.
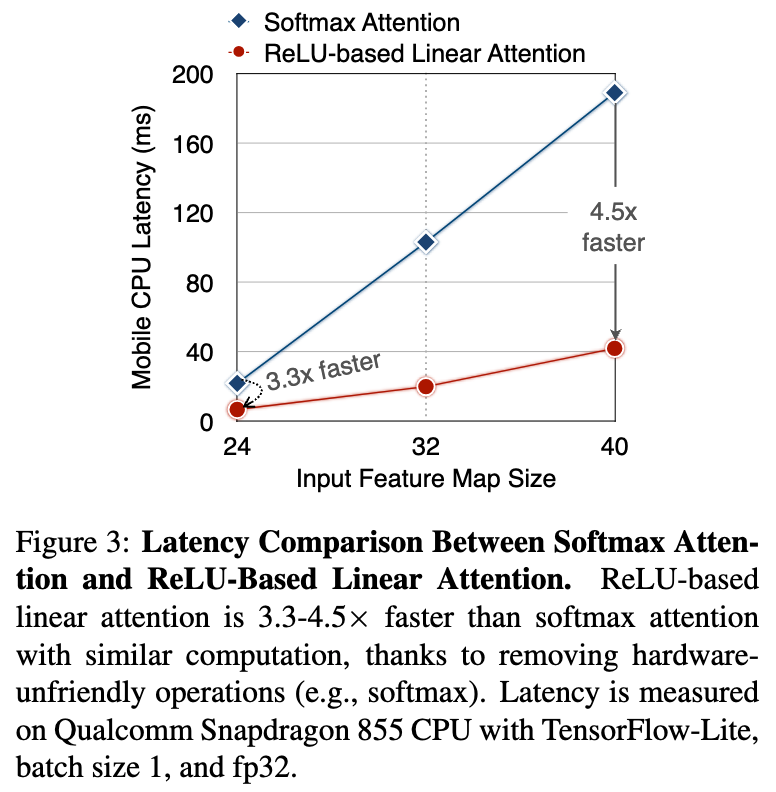
예를 들어, Fig. 3에서 softmax attention and ReLU-based linear attention의 latency comparison을 보여준다.
similar computation으로, ReLU-based linear attention은 mobile에서 softmax attention보다 훨씬 빠르다.
Generate Multi-Scale Tokens.
- ReLU-based attention만으로는 model capacity가 제한적이다.
이 limitation을 극복하기 위해, 먼저 depthwise convolution을 결합하여 local information extraction ability를 향상시킨다.
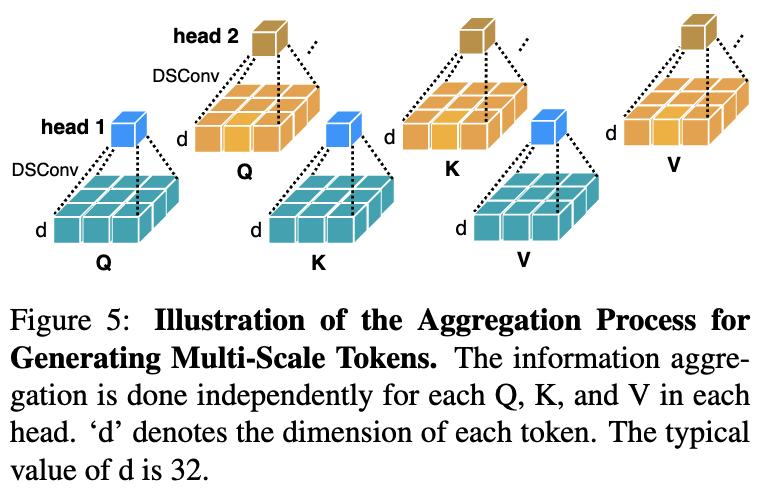
또한, multi-scale learning ability를 향상 시키기 위해, 인접한 Q/K/V tokens로부터 정보를 aggregate하여 multi-scale tokens을 생성하는 방식을 제안한다.
이 aggregation process는 Figure 5에 설명되어 있으며, 각 head의 Q, K, V마다 독립적으로 수행된다.
HW efficiency를 해치지 않기 위해 small-kernel convolutions만 사용한다.
실제 구현에서는, 이러한 aggregation operations들을 독립적으로 수행하면 GPU 상에서 inefficient하다.
따라서 우리는 modern DL frameworks infra를 이용하여 모든 Depthwise Convolution(DWConv)는 a single DWConv로 병합되고,
모든 Conv는 하나의 group convolution으로 결합된다.
이때 group의 수는 #heads이며, 각 group의 channel 수는 이다.
multi-scale tokens을 얻은 후에는, global attention을 수행하여 multi-scale global features를 추출한다.
마지막으로, 각 scales에서 추출된 features들을 head dimension으로 concatenate한 뒤, 이를 final projection layer에 전달하여 features를 fuse한다.
2.2. EfficientViT Architecture
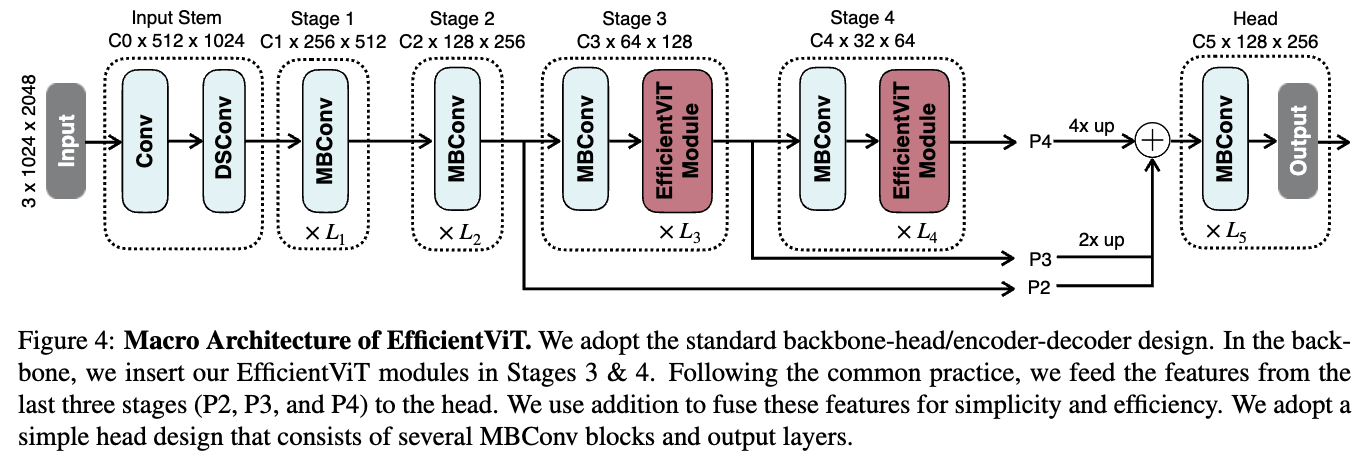
- The core building block은 Figure 2 (left)에 있음.
EfficientViT module은 a lightweight MSA module and an MBConv(MobileNetV2)로 구성됨.
lightweight MSA module은 context informatino extraction으로 활용되고, MBConv는 context information extraction을 위해 사용된다.
3. Experiments
4. Related Work
(skip)
5. Conclusion
