[2023 ICML] (Simple Review) BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
[Paper Review] VLM to LMM
Paper Info.
https://arxiv.org/abs/2301.12597


Abstract
(문제)
- vision-language pre-training은 large-scale models을 end-to-end training으로 학습해야 하기 때문에 점점 감당하기 어려운 수준이 되고 있다.
(제안)
-
본 논문에서는 frozen pre-trained image encoders와 frozen LLMs을 활용하여
vision-language pre-training을 bootstrap하는, generic and efficient pre-training strategy인 BLIP-2를 제안한다. -
BLIP-2의 lightweight Querying Transformer를 통해 modality gap을 bridging하며,
이 module은 two stages의 pre-training 과정을 통해 학습된다.- first stage에서는 frozen image encoder를 기반으로 vision-language representation learning을 bootstrap한다.
- second stage에서는 frozen LM을 활용하여 vision-language generative learning을 bootstrap한다.
(실험)
- BLIP-2는 기존 방법들에 비해 fewer trainable parameters를 가짐에도 불구하고, 다양한 visoin-language tasks에서 SOTA를 달성한다.
예를 들어, BLIP-2는 zero-shot VQAv2에서 Flamingo-80B보다 54배 적은 trainable parameter를 사용하면서도 8.7% 더 높은 성능을 보인다.
또한, natural language instructions을 따를 수 있는 zero-shot image-to-text generation 능력도 함께 보여준다.
1. Introduction
(배경: VLM pre-training은 너무 비용이 많이 든다)
- 최근 몇 년간 Vision-Language Pre-training (VLP) 연구는 빠르게 발전..
그러나 SOTA VLM은 high computation cost during pre-training을 요구.
(가설, 문제 제기:
unimodal pre-trained model 간의 간극을 해소하는게 VLP에 좋을 것이다.
간극을 해소하기 위한 기존 연구들은 충분하지 않다.)
-
vision-language research는 vision과 language의 intersection에 위치해 있으므로,
vision-language model이 이미 각각의 분야에서 잘 학습된 unimodal models을 활용하는 것이 자연스러운 기대이다.
본 논문에서는 기존에 공개된 pre-traind vision models과 language models을 활용하여 bootstrapping하는,
generic and compute-efficient VLP method를 제안한다. -
Pre-trained vision models은 high-quality visual representation을 제공하며,
Pre-trained LLMs은 strong language generation and zero-shot trasnfer abilities를 제공한다.
computation cost를 줄이고 catastrophic forgetting(재앙적 망각. 즉 새로운 data 또는 task를 학습할 때, 이전에 학습했던 능력을 급격히 잃어버리는 현상) 문제를 완화하기 위해,
이러한 unimodal pre-trained models은 pre-training 동안 frozen 상태로 유지된다. -
pre-trained unimodal models들을 VLP에 효과적으로 활용하기 위해서는 cross-modal alignment가 핵심적이다.
그러나 LLM은 unimodal pre-training 동안에 images를 본 적이 없기 때문에,
이를 frozen 상태로 유지하면 vision-language alignment는 특히 더 어려운 문제가 된다.
이러한 이유로 기존 방법들(예: Frozen, Flamingo)은 image-to-text generation loss에 의존해 왔지만,
본 논문에서는 이러한 방식이 modality gap을 bridge하기에 충분하기 않다는 것을 보인다.
(제안: 두 frozen unimodal models의 modality gap을 줄이기 위해, two-stage pre-training으로 학습되는 Q-Former을 제안)
- frozen unimodal models을 사용하면서도 effective vision-language alignment를 달성하기 위해,
본 논문에서는 a new two-stage pre-training strategy로 학습되는 Querying Transformer (Q-Former)를 제안한다.
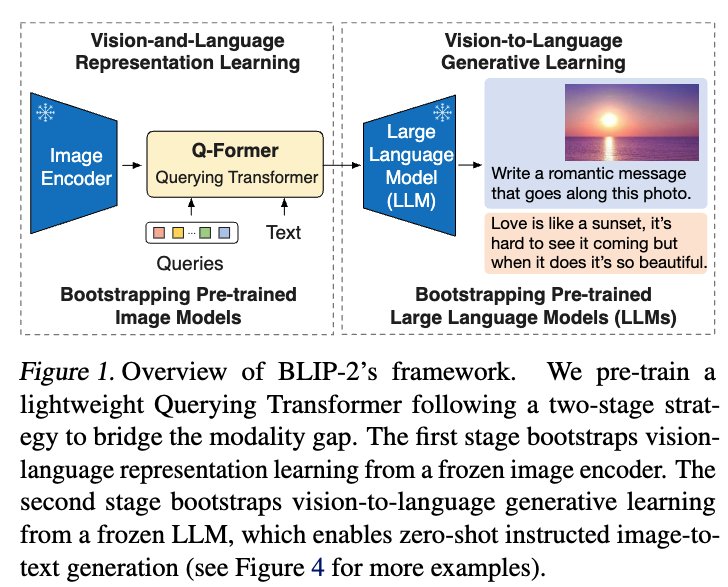
Figure 1에 나타난 바와 같이, Q-Former는 a set of learnable query vectors를 사용하여
frozen image encoder로부터 visual features를 추출하는 lightweight transformer이다.
Q-Former는 frozen image encoder와 Frozen LLM 사이에서 information bottleneck 역할을 하며,
LLM이 원하는 text를 생성하는 데 most useful visual feature만을 선별해 전달한다.
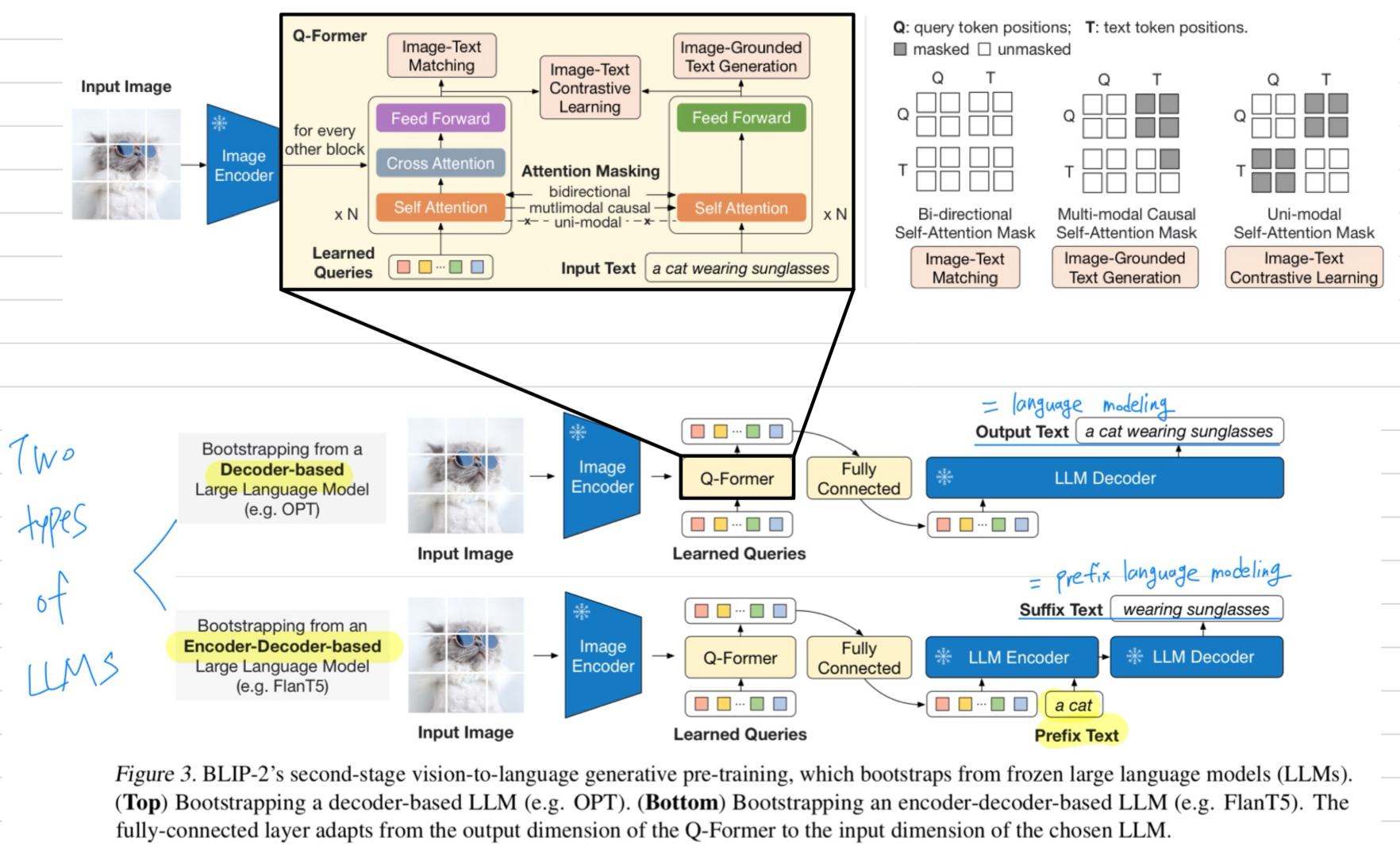
- the first pre-training step에서,
vision-language representation learning을 수행하여,
Q-Former가 text와 가장 관련성이 높은 visual representation을 학습하도록 한다. - the second pre-training step에서,
Q-Former의 output을 frozen LLM에 연결하여,
vision-to-language generative learning을 통해 Q-Former가 자신의 output visual representation이 LLM에 의해 해석될 수 있도록 학습된다.
- the first pre-training step에서,
(장점)
- 이와 같은 VLP framework를 BLIP-2: Bootstrapping Language-Image Pre-training with frozen unimodal models 라고 명명한다.
BLIP-2의 key advantages는 다음과 같다:- BLIP-2는 frozen 상태의 pre-trained image models and language models을 효과적으로 활용.
representation learning stage와 generative learning stage로 구성된 two-stages의 Q-Former pre-trained를 통해
the modality gap을 성공적으로 bridge.
그 결과, BLIP-2는 VQA, image captioning, and image-text retrieval 등 다양한 vision-language tasks에서 SOTA를 달성. - LLM(예: OPT, FlanT5)을 기반으로, BLIP-2는 natura language instructions을 따르는 zero-shot image-to-text generation이 가능하며,
이를 통해 visual knowledge reasoning, visual conversation, 등과 같은 emergent capability를 보여준다. - frozen unimodal models과 lightweight Q-Former를 사용함으로싸, BLIP-2는 기존 SOTA 방법들에 비해 compute-efficient하다.
예를 들어, BLIP-2는 zero-shot VQAv2에서 Flamingo(Alayrac et al., 2022)보다 8.7% 높은 성능을 보이면서도 trainable parameters는 54 더 적게 사용한다.
- BLIP-2는 frozen 상태의 pre-trained image models and language models을 효과적으로 활용.
2. Related Work
2.1. End-to-end Vision-Language Pre-training
-
related work 소개... (skip)
-
문제 1: Most VLP methods perform end-to-end pre-training using large-scale image-text pair datasets.
As the model size keeps increasing, the pre-training can incur an extremely high computation cost. -
문제 2: Moreover, it is inflexible for end-to-end pre-trained models to leverage readily-available unimodal pre-trained models, such as LLMs.
2.2. Modular Vision-Language Pre-training
- 이 연구와 비슷한 method는 pre-trained models을 VLP 동안에 그대로 frozen하여 활용하는 것이다.
- 일부 방식은 image encoder를 frozen 상태로 유지하는 전략을 사용.
여기에는 object detector를 frozen 상태로 사용하여 visual features를 extract했던 초기 연구들과,
pre-trained image encoder를 frozen 상태로 사용하여 CLIP을 pre-training하는 최근의 LiT가 포함된다. - 또 다른 일부 방법들은 LLM이 보유한 knowledge를 vision-to-language generation tasks에 활용하기 위해 language model을 frozen 상태로 유지한다.
frozen LLM을 사용하는 데 있어 key challenge는 visual features를 text space에 align하는 것이다.
이를 해결하기 위해, Frozen(Tsimpoukelli et al., 2021)은 image encoder를 fine-tuning하고 그 outputs을 LLM의 soft prompt로 직접 사용한다.
Flamingo(Alayrac et al., 2022)는 LLM 내부에 new cross-attention layers를 삽입하여 visual features를 inject하고,
이 new layer들만을 수십억 개의 image-text pairs로 pre-train한다.
이 두 방법 모두, image에 conditioned된 text를 generating하도록 하는 language modeling loss를 사용한다.
- 일부 방식은 image encoder를 frozen 상태로 유지하는 전략을 사용.
- 기존 방법들과 달리, BLIP-2는 frozen image encdoer와 frozen LLMs을 모두 효과적이면서도 효율적으로 활용하여
다양한 vision-language tasks를 수행할 수 있으며, lower computation cost로 stronger performance를 달성할 수 있다.
3. Method
- 우리는 BLIP-2, a new VLP method that bootstraps from frozen pre-trained unimodal models을 제안한다.
modality gap을 줄이기 위해, 우리는 two-stages로 Pre-trained되는 Querying Transformer (Q-Former) 를 제안한다:- vision-language representation learning stage with a frozen image encoder
- vision-language generative learning stage with a frozen LLM
- 우리는 먼저 Q-Former의 model architecture를 소개하고 나서,
two-stage pre-training procedures를 정확히 설명하겠다.
3.1. Model Architecture
-
우리는 a frozen image encoder와 a frozen LLM 간의 gap을 줄이기 위한 trainable module로 Q-Former를 제안한다.
Q-Former는 input image resolution과 독립적으로, image encoder로부터 a fixed number of output features를 추출한다.
Figure 2에서 볼 수 있듯이, Q-Former는 same self-attention layers를 공유하는 two transformer submodule로 구성되어 있다.- visual feature extraction을 위해, the frozen image encoder와 interacts(cross-attention)하는 an image transformer.
- both a text encoder and a text decoder를 모두 수행하기 위한 a text transformer
-
우리는 image transformer에 input으로 a set number of learnable query embeddings을 생성하고,
cross-attention layers(매 transformer block에 insert함)를 통해 frozen image features와 interact한다.
image transformer와 text transformer는 동일한 self-attention layer를 사용하기 때문에
이 leanable queries들은 self-attention layers를 통해 text와도 추가적으로 interact할 수 있다.
pre-training task에 따라 query-text interaction을 조절할 수 있도록 서로 다른 self-attention masks를 적용했다.
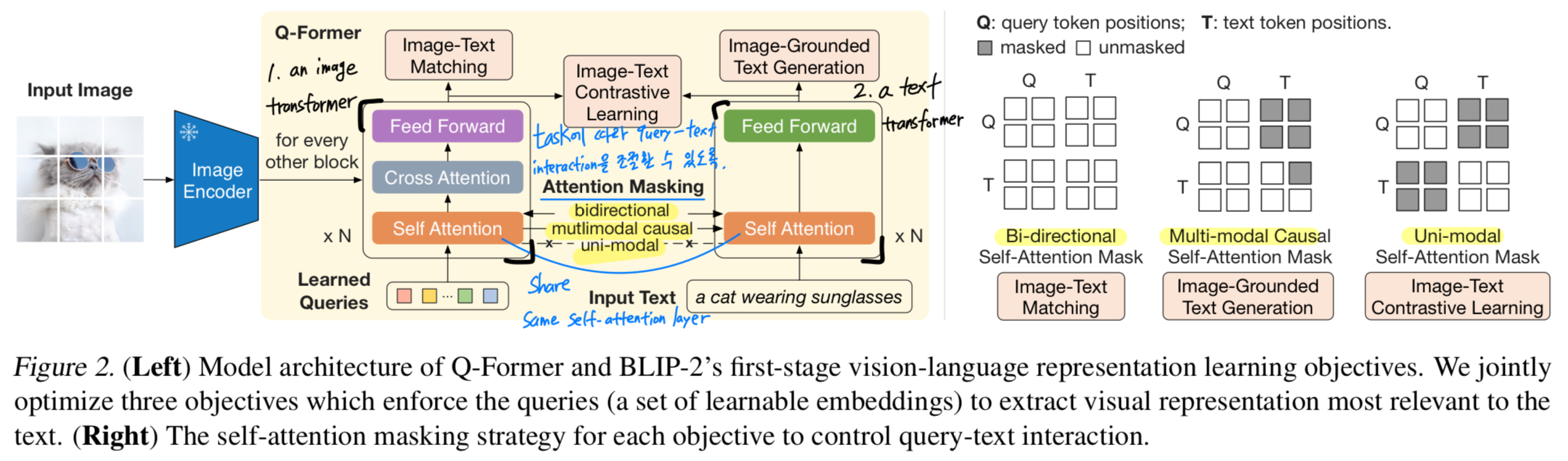
-
실험에서, 각 768 dimension을 갖는 32개의 queries를 사용함.
우리는 output query representation을 라 denote한다.
The size of 은 the size of frozen image features (e.g., for ViT-L/14)보다 훨씬 작다.
이러한 bottleneck architecture는 우리의 pre-training objectives와 함께 작동하여,
queries들이 text에 가장 관련성 높은 visual information을 extract할 수 있도록 강제한다.
3.2. Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
- representation learning stage에서는,
Q-Former를 a frozen image encoder에 연결하고, image-text pairs를 사용하여 pre-training을 수행한다.
이 단계의 목표는 queries들이 text에 대해 가장 많은 정보를 담고 있는 visual representation을 추출할 수 있도록 Q-Former를 학습시키는 것이다.
BLIP에서 영감을 받아, 우리는 same input format and model parameters를 share하는 three pre-training objectives를 jointly optimize한다.
각 objectives는 queries와 text 간의 interaction을 제어하기 위해 서로 다른 attention masking strategy를 사용한다.
Image-Text Contrastive Learning
-
Image-Text Contrastive Learning (ITC)는 image representation과 text representation이 mutual information을 maximized되도록 align시키는 것을 목표로 한다.
이를 위해 positive pair의 image-text similarity를 negative pairs들의 similarity와 대비시키는 방식으로 학습을 수행한다. -
우리는 image transformer에서 나온 query representation 와 text transformer에서 나온 text representation 를 align시키는데,
여기서 는 token의 output embedding이다.
는 여러 개의 output embedings (각 query마다 하나씩)을 포함하고 있으므로, 각 query output과 사이의 pairwise similarity를 먼저 계산한 뒤,
그 중 highest one을 image-text similarity로 선택한다.
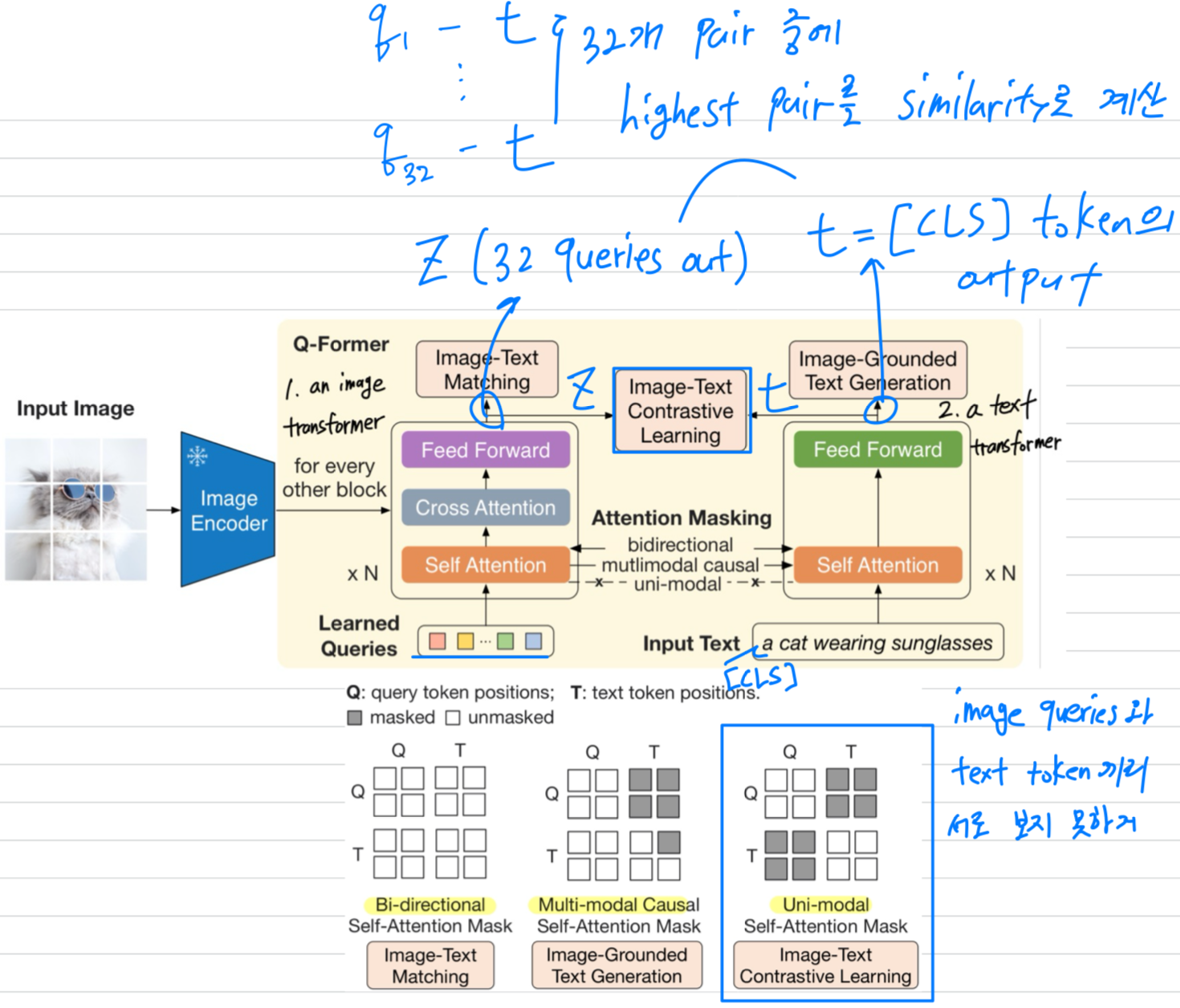
- information leak을 방지하기 위해, unimodal self-attention masking을 사용하여 query와 text가 서로 볼 수 없도록 한다.
또한 frozen image encoder를 사용하기 때문에, end-to-end 방식에 비해 GPU 당 more samples을 처리할 수 있다.
이에 따라 BLIP에서 사용한 momentum queue(encoder) 대신 in-batch negatives를 사용한다.
Image-grounded Text Generation
- Image-grounded Text Generation (ITG) loss는 input image에 conditioned된 texts를 생성하도록 Q-Former를 학습시킨다.
Q-Former의 구조상 frozen image encoder와 text tokens 간에 direct interactions이 불가능 하므로,
text generating을 위해 필요한 정보는 먼저 queries들이 추출된 뒤, self-attention layer를 통해 text token으로 전달되어야 한다.
따라서 queries들은 text에 관한 모든 정보를 capture하는 visual features를 추출하도록 강제된다. (?)
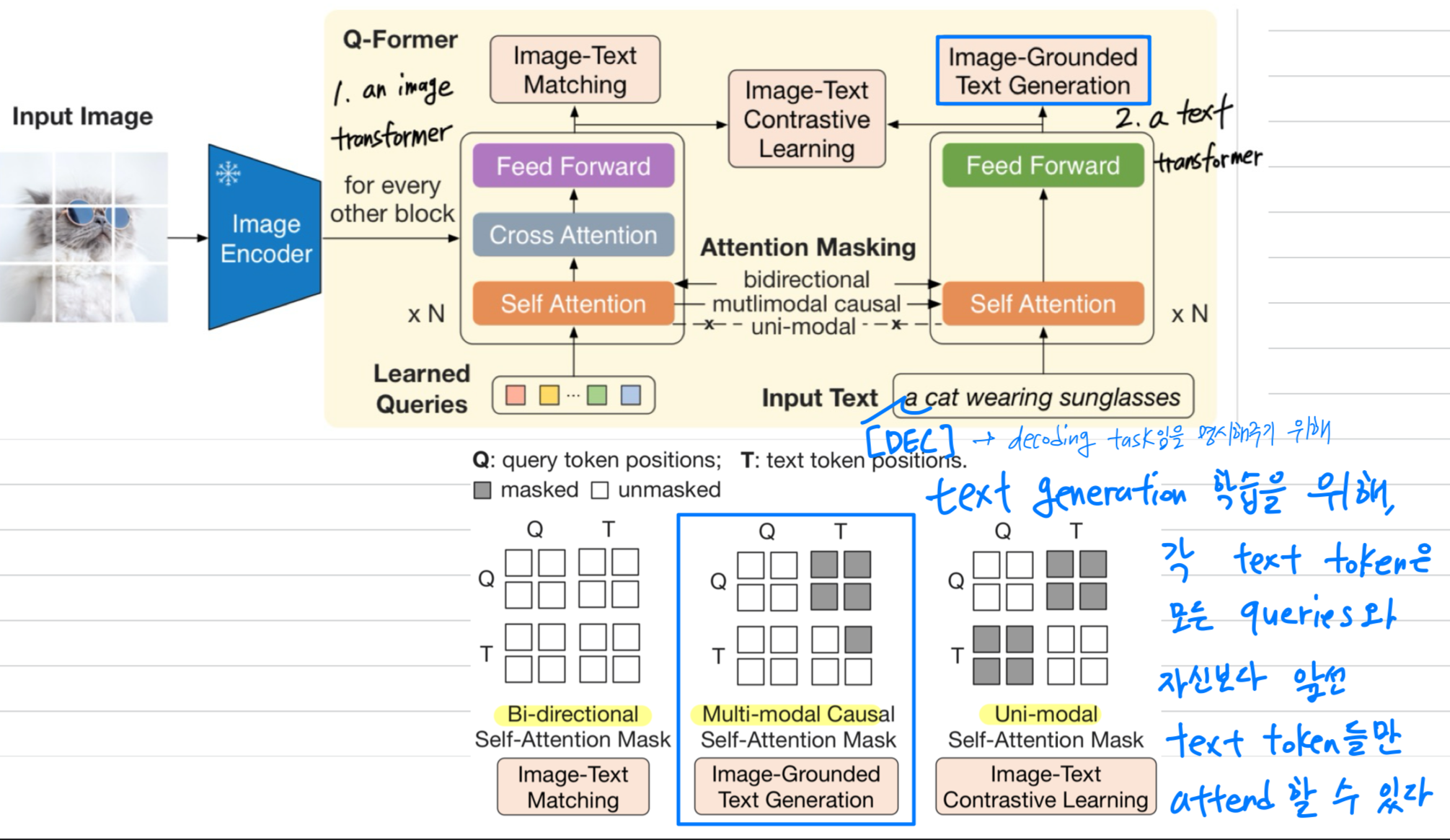
- 우리는 UniLM(Dong et al., 2019)에서 사용된 방식과 유사하게, query-text interaction을 제어하기 위한 multimodal causal self-attention mask를 사용한다.
이 mask 하에서 query들은 서로를 attend할 수 있지만 text token을 attend할 수 없으며,
각 text token은 모든 queries들과 자신보다 앞선 text tokens을 attend할 수 있다.
또한 Decoding 작업임을 명시적으로 나타내기 위해, token을 새로운 token으로 대체하여 first text token으로 사용한다.
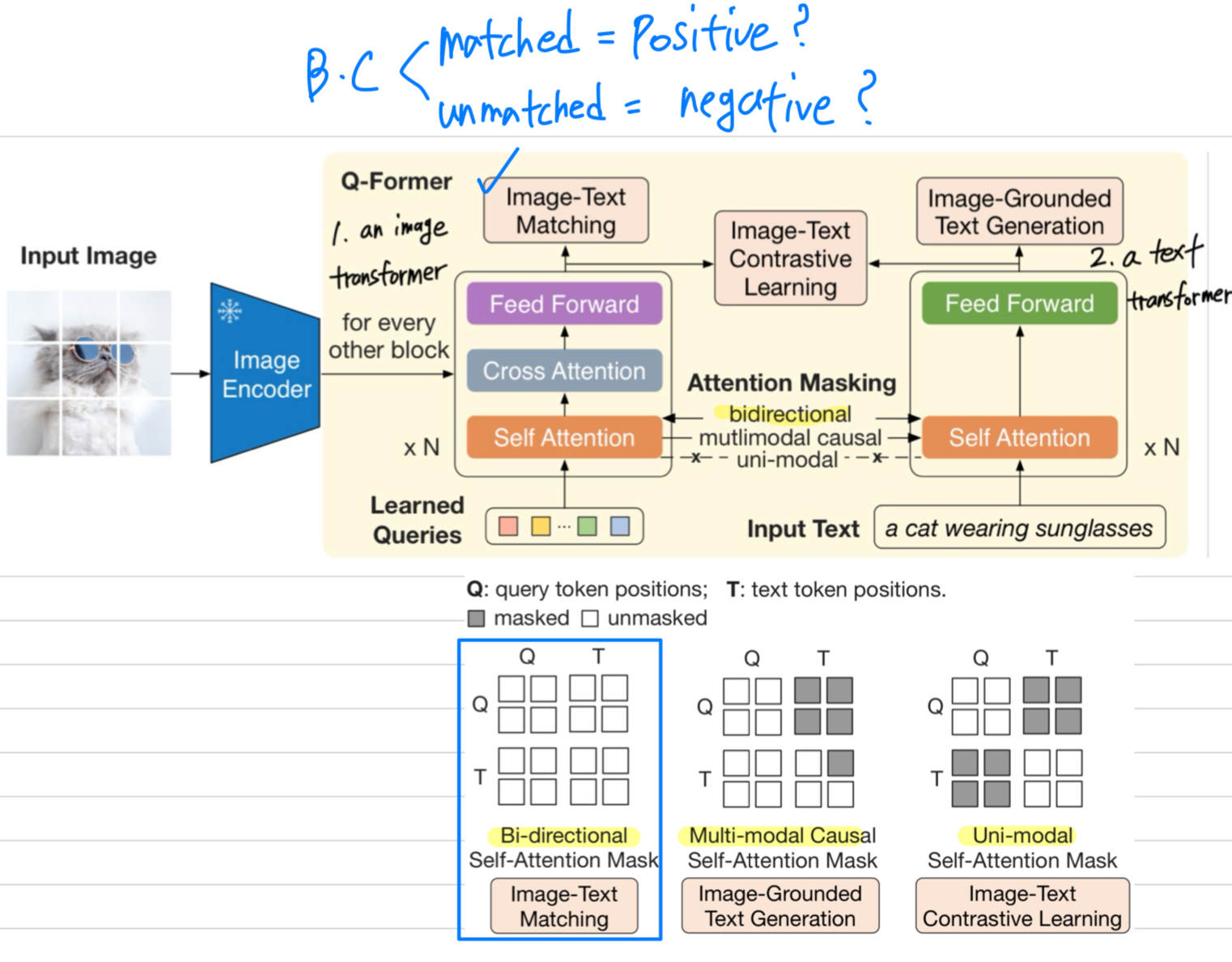
Image-Text Matching
- Image-Text Matching(ITM)은 image and text representation 간의 fine-grained alignment를 위해 학습된다.
이는 binary classification task로, model은 주어진 image-text pair가 positive(matched)인지, 혹은 negative(unmatched)인지를 예측하도록 학습된다.
이를 위해, 모든 query와 text가 서로 attend할 수 있는 bi-directional self-attention mask를 사용한다.
그 결과, output query embeddings 는 multimodal information을 함께 담는 representation이 된다.
우리는 각 output query embedding을 two-class linear classifier에 입력하여 logit을 얻고, 모든 queries에서 나온 logits을 평균하여 matching score로 사용한다.
우리는 각 출력 쿼리 임베딩을 2-클래스 선형 분류기에 입력하여 로짓(logit)을 얻고, 모든 쿼리에서 나온 로짓을 평균하여 최종 매칭 점수로 사용한다.
또한, informative negative pairs를 생성하기 위해, Li et al. (2021; 2022)에서 hard negative mining strategy를 채택한다.
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
-
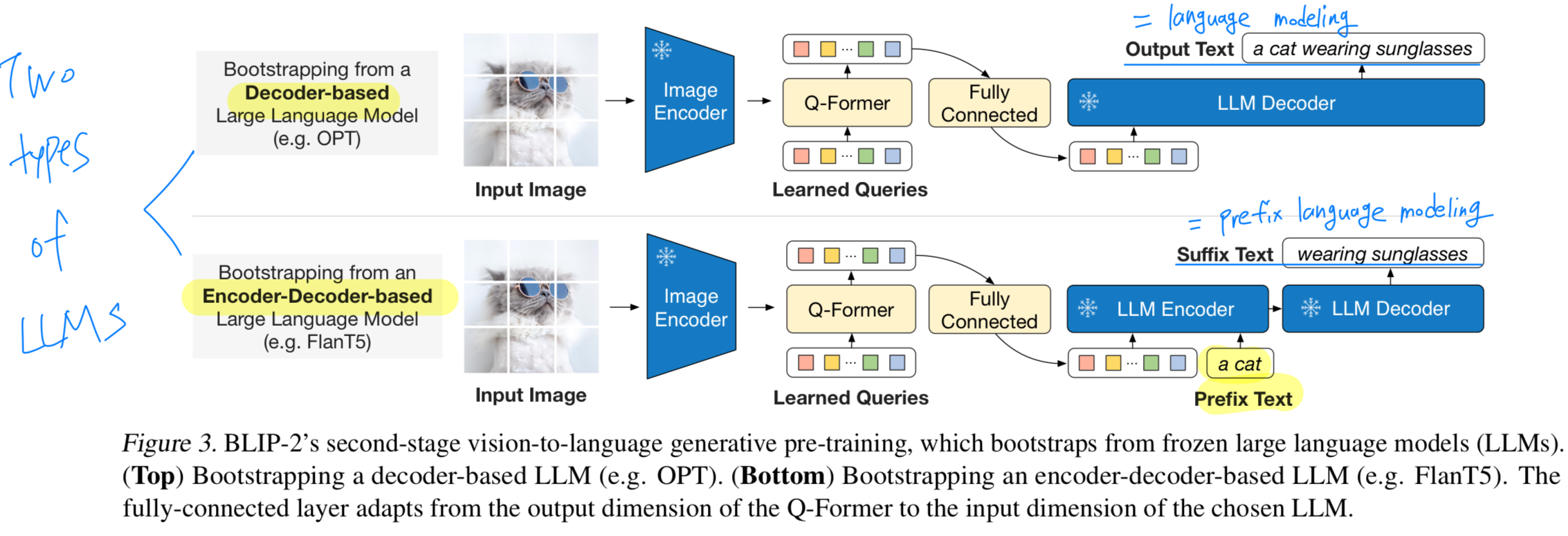
generative pre-training stage에서, frozen image encoder가 연결된 Q-Former를 frozen LLM과 결합하여 LLM의 generative language capability를 활용한다.
Figure 3에 나타난 바와 같이, 우리는 fC layer를 사용하여 output query embeddings 를 LLM의 text embedding과 동일한 dimension으로 linearly project한다.
The projected query는 input text embeddings 앞에 prepending되며, Q-Former가 추출한 visual representation을 기반으로
LLM을 condition화하는 soft visual prompts로 작동한다.
Q-Former는 language-informative visual representation을 추출하도록 pre-trained되어있기 때문에,
LLM에 most useful information만을 전달하고 irrelevant visual information을 제거하는 information bottleneck 역할을 효과적으로 수행한다.
이는 LLM이 vision-language alignment를 학습해야 하는 부담을 줄여 주며, 결과적으로 catastrophic forgetting 문제를 완화한다. -
우리는 두 유형의 LLM을 실험했다: decoder-based LLMs and encoder-decoder-based LLMs
- decoder-based LLMs:
decoder-based LLMs의 경우,
frozen LLM이 Q-Former로부터 전달된 visual representation에 conditioned된 text를 generate하도록
language modling loss를 사용하여 pre-train을 수행한다. - encoder-decoder-based LLMs:
반면, encoder-decoder-based LLMs의 경우,
text를 두 부분으로 분할한 뒤 prefix language modeling loss를 사용하여 pre-train한다.
이때, prefix text는 visual representation과 결합되어 LLM's encoder에 입력되며, suffix text는 LLM's decoder의 generation target이 된다.
- decoder-based LLMs:
3.4. Model Pre-training
Pre-training data.
-
우리는 BLIP과 동일한 pre-training dataset(총 129M images)을 사용했다.
이 dataset은 COCO, Visual Genome, CC3M, CC12M, SBU and (LAION400M dataset으로부터 115M images)를 모두 포함한다. -
우리는 web images에 대해 synthetic captions을 생성하기 위한 BLIP의 CapFilt method도 적용했다.
Pre-trained image encoder and LLM
- frozen image encoder에 대해서, 우리는 two SOTA pre-trained ViT models을 실험했다.
우리는 ViT의 마지막 layer를 없애고 second last layer's output features를 사용하는게, slightly better performance를 유도함을 발견했다.- ViT-L/14 from CLIP
- ViT-g/14 from EVA-CLIP
- frozen language model에 대해서,
decoder-based LLMs을 위해 unsupervised-trained OPT model family,
encoder-decoder-based LLMs을 위해 instruction-trained FlanT5 model family
를 실험했다.
Pre-training settings
- 이하 skip....
BLIP-2 arthitecture의 overview: Q-Former + 두 LLM type 중 하나 (decoder-based LLM or encoder-decoder-based LLM)