[2022 NeurIPS] (simple review) 🦩Flamingo: a Visual Language Model for Few-Shot Learning
[Paper Review] VLM to LMM
Paper Info.
- openreview: https://openreview.net/forum?id=EbMuimAbPbs
- neurips proceedings: https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Supplemental-Conference.pdf

Abstract
(배경)
- a handful of (소수의) annotated examples만을 사용하여 novel tasks에 빠르게 적응할 수 있는 model을 구축하는 것은
multimodal ML research에서 open challenge이다.
(제안)
- 본 논문에서는 이러한 능력을 갖춘 Flamingo, a family of Visual Language Models (VLMs)을 소개한다.
우리는 다음과 같은 key architectural innovations을 제안한다:- powerful pretrained vision-only and language-only models
- visual data와 text data가 임의의 순서로 섞여 있는 sequence를 처리할 수 있는 방법
- images or videos를 inputs으로 자연스럽게 수용할 수 있는 방법
(장점)
- 이러한 flexibility 덕분에, Flamingo model은 text와 image가 임의로 섞여 있는 large-scale multimodal web corpora에서 학습될 수 있으며,
이는 in-context few-shot learning capabilities를 부여하는 데 핵심적인 역할을 한다.
(실험)
- 우리는 model의 성능을 다각도로 평가하여, 다양한 image and video tasks에 대해 얼마나 빠르게 적응할 수 있는지를 분석하고 측정한다.
이러한 task에는 visual question-answering과 같은 open-ended tasks, a sene or an event를 설명하는 captioning tasks, 그리고 multiple-choice visual question-answering과 같은 close-ended tasks가 포함된다.
이 spectrum 어디에 위치한 task이든, a single Flamingo model은 task-specific examples를 prompting으로 제공하는 것만으로도
few-shot learning에서 a new SOTA를 달성할 수 있다.
여러 benchmark에서 Flamingo는 수천 배 더 많은 task-specific data를 사용해 fine-tuned model들보다도 outperform한다.
1 Introduction
(배경, 문제제기: CV에서 short instruction으로 학습하는 연구들의 한계점)
- intelligence의 one key aspect 중 하나는 a short instruction만 주어졌을 때 new task를 빠르게 학습하여 수행할 수 있는 능력이다.
CV에서 이와 유사한 능력을 향한 initial progress가 있었지만, 현재 가장 널리 사용되는 paradigm은 여전히 대규모의 supervised data로 pretraining을 수행한 뒤, 관심 있는 task에 대해 fine-tuning을 하는 방식이다.
그러나 successful fine-tuning을 위해서는 종종 수천 개 이상의 annotated data points가 필요하다.
또한 per-task hyperparameter tuning이 요구되며, resource intensive하다.
(배경, 문제제기: contrastive learning만으로 학습하는 VLM 연구들의 한계점)
- 최근에는 contrastive objective만으로 학습된 multimodal visoin-language model들이 fine-tuning 없이도 novel tasks에 대한 zero-shot adaptation을 가능하게 했다.
그러나 이러한 model들은 단순히 text와 image 간의 similarity score만 제공하기 때문에,
사전에 정해진 a finite set of outcomes이
classification과 같은 limited use cases에만 적용될 수 있다.
특히 language를 generate하는 ability가 부족하여, captioning or visual question-answering과 같은 more open-ended tasks에는 적합하지 않다.
(배경, 문제제기: language generation에 대한 연구들도 있었지만, 많은 data가 필요)
- 한편, visual-conditioned language generation에 대한 연구들도 이루어져 왔지만, low-data regime(환경)에서는 아직 충분한 성능을 보이지 못하고 있다.
(제안하는 model의 실험 결과: Flamingo가 어떤 면에서 좋은 점이 있는지?)
- 본 논문에서는 Flamingo를 소개한다.
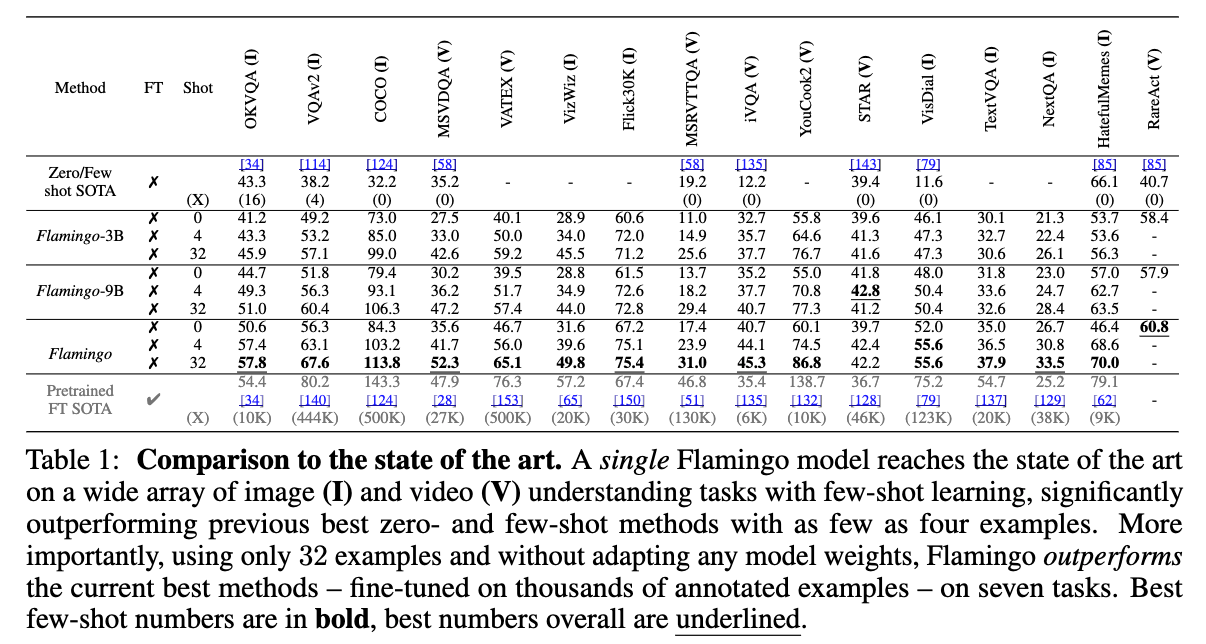
Flamingo는 input/output examples만을 prompt로 제공하는 것만으로도 다양한 open-ended vision and language tasks에서 few-shot learning의 SOTA를 달성하는 Vision-Language model(VLM)이다. (Figure 1)
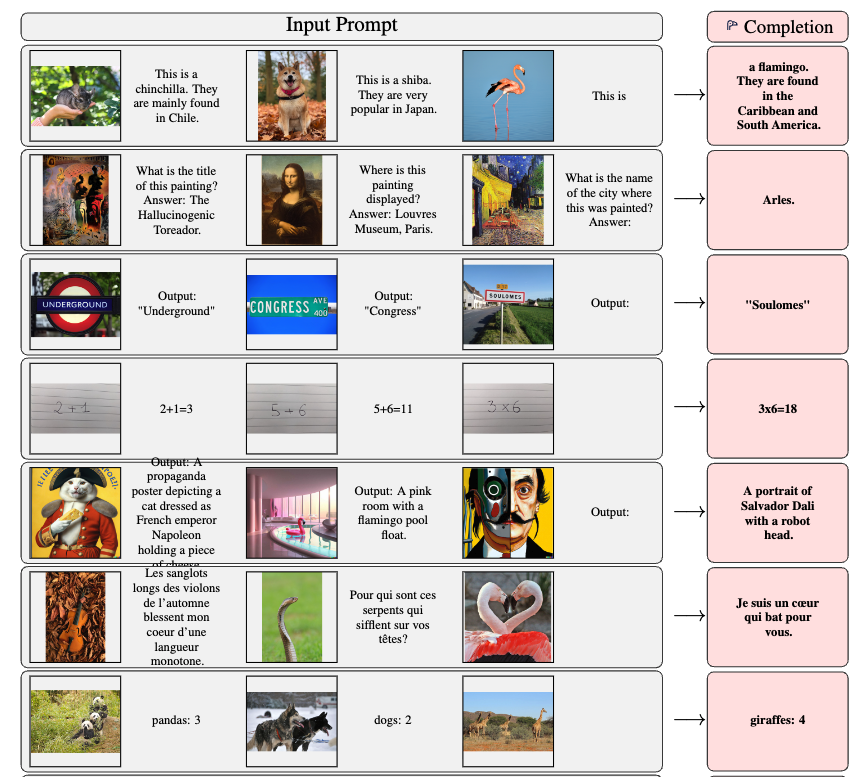


(제안하는 model의 실험 결과: Flamingo가 어떤 면에서 좋은 점이 있는지?)
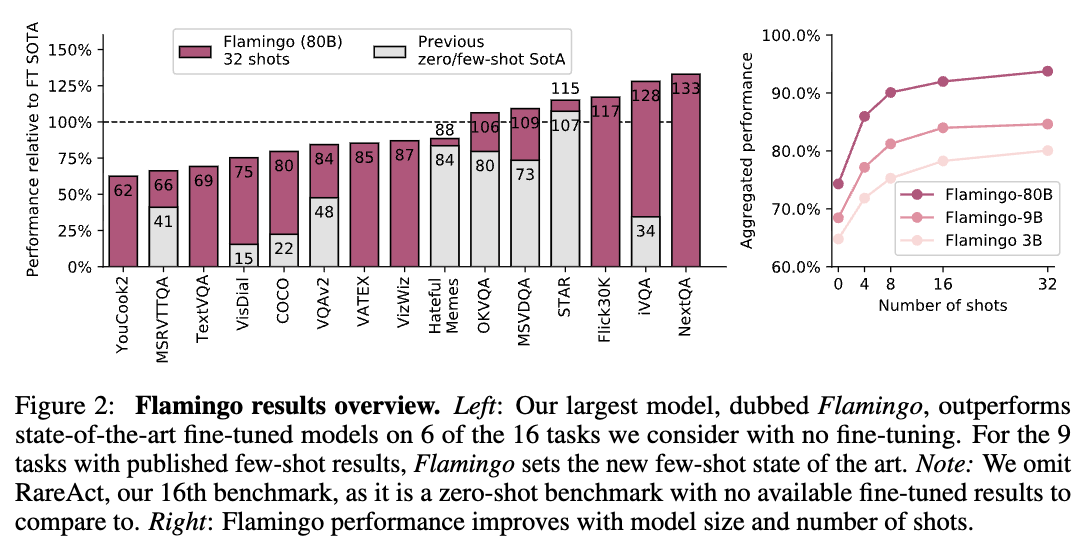
- 우리가 고려한 16가지 Tasks 중 6개 과제에서는, Flamingo가 task-specific training data를 훨씬 적게 사용함에도 불구하고 기존의 fine-tuned SOTA를 능가한다. (Figure 2)
(제안: Flamingo는 LM의 "query input에 대한 predicted output을 이어서 생성하는 것"에 영감을 받음.)
- 이를 위해, Flamingo는 최근 few-shot 학습에 강점을 보인 LLM에 관한 연구들로부터 영감을 받았다.
A single LLM은 text interface만을 사용해도 다양한 Tasks에서 strong performance를 보일 수 있다.
즉, task에 대한 a few examples을 prompt로 제공하고 qurey input을 함께 주면,
model은 해당 query에 대한 a predicted output을 생성하는 형태로 text를 이어서 생성한다.
우리는 이와 동일한 접근이 classification, captioning, or question-answering과 같은 image and video understanding tasks에도 적용될 수 있음을 보인다.
이러한 task들은 text prediction problems with visual input conditioning으로 정식화될 수 있다.
(제안: Flamingo는 LM과 달리, 구체적으로 어떻게 작동되는지?
LM과 유사하지만 input이 다름.
Flamingo는 input으로 text token과 image and/or videos token이 임의로 섞여 있는 입력을 받는다는게 다름. text를 출력한다는 것은 동일.)
- LM과의 차이점은, model이 text와 images and/or videos가 interleaved된(임의의 순서로 섞여 있는) multimodal prompt를 입력으로 처리할 수 있어야 한다는 점이다.
Flamingo model은 이러한 capability를 갖추고 있다.
즉, a sequence of text tokens interleaved with images and/or videos를 받아 text를 출력하는,
visaully-conditioned autoregressive text generation models이다.
Flamingo는 두 개의 complementary pre-trained and frozen model을 활용한다:
(1) 하나는 visual scenes을 "perceive"할 수 있는 vision model이며,
(2) 다른 하나는 basic form of reasoning을 수행하는 LLM이다.
이 두 model 사이에는, 계산 비용이 큰 pretraining 과정에서 accumulated된 knowledge를 최대한 보존하면서
두 model을 연결할 수 있도록 하는 Novel architecture components가 추가된다.
또한 Flamingo는 Perceiver-based architecture를 활용하여,
variable number of(많은 수의 가변) visual input features로부터
a small fixed number of visual tokens per image/video를 생성할 수 있기 때문에
high-resolution images or videos를 ingest(입력으로 처리)할 수 있다.
(training dataset: a carefully chosen mixture of complementary large-scale multimodal data coming only from the web)
- LLM 성능에 있어 crucial aspect 중 하나는 a large amount of text data이다.
이러한 학습을 통해 LM은 소수의 task examples을 prompted해주면 잘 동작하는 general-purpose generation capabilities를 갖추게 된다.
비슷하게, 본 연구에서는 Flamingo model이 최종 성능이 학습 방식에 크게 의존함을 보인다.
Flamingo model은 any data annotated for ML purposes를 전혀 사용하지 않고,
a carefully chosen mixture of complementary large-scale multimodal data coming only from the web 만을 이용해 학습했다.
학습 이후, Flamingo model은 any task-specific tuning 없이도 simple few-shot learning만으로 다양한 vision tasks에 적응할 수 있다.
(contributions)
- 요약하자면, 우리의 contributions은 다음과 같다:
- 우리는 a few input/output examples만으로도 image captioning, visual dialogue(대화), or visual question-answering과 같은 다양한 multimodal tasks를 수행할 수 있는 Flaimngo family of VLMs을 제안한다.
Flamingo는 architectural innovations을 통해 arbitrarily interleaved(임의의 순서로 혼합되어 있는) visual and text data를 효율적으로 처리할 수 있으며, open-ended manner로 text 생성이 가능하다. - (skip... 실험에 관한 내용)
- (skip... 실험에 관한 내용)

- 우리는 a few input/output examples만으로도 image captioning, visual dialogue(대화), or visual question-answering과 같은 다양한 multimodal tasks를 수행할 수 있는 Flaimngo family of VLMs을 제안한다.
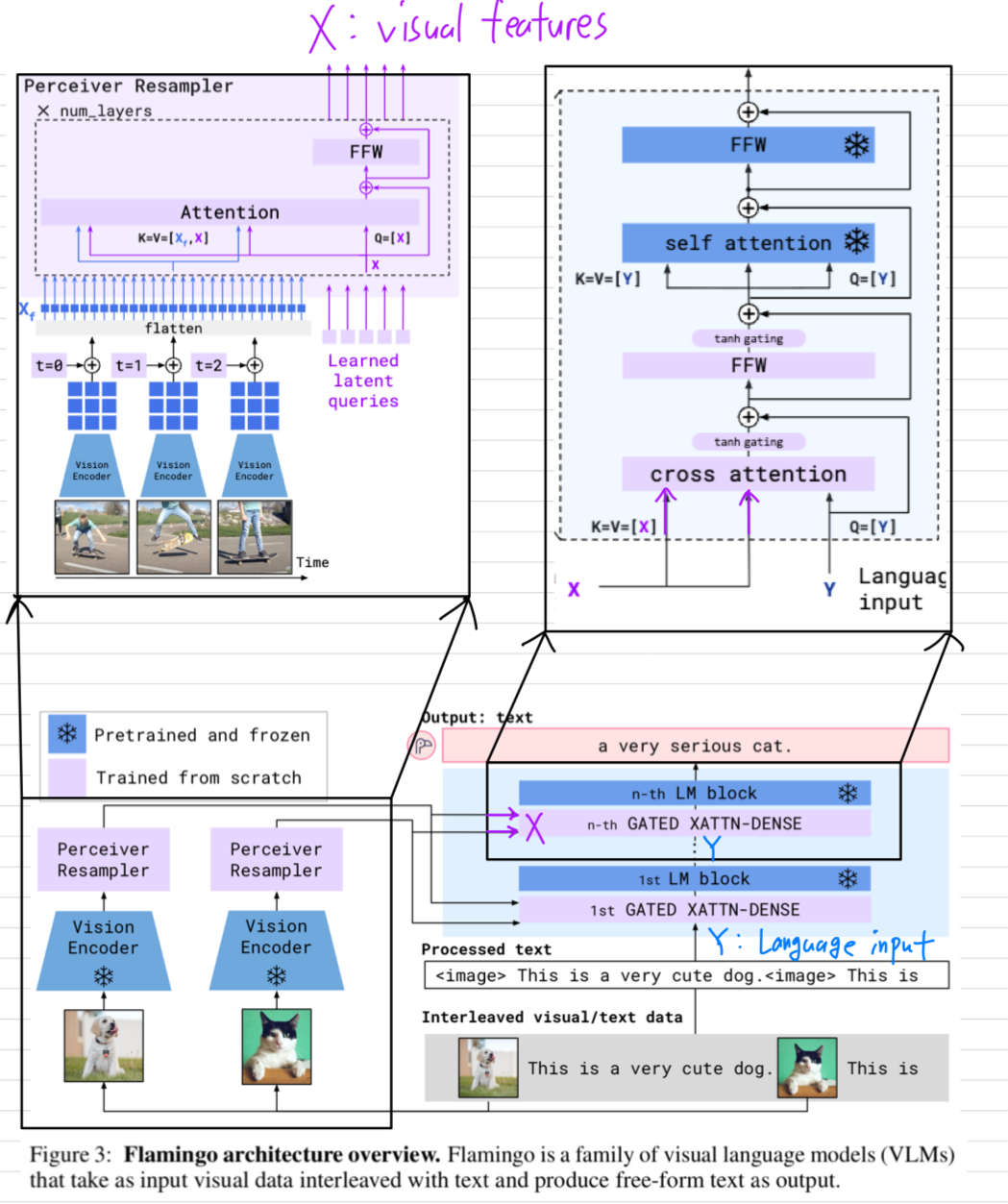
2 Approach
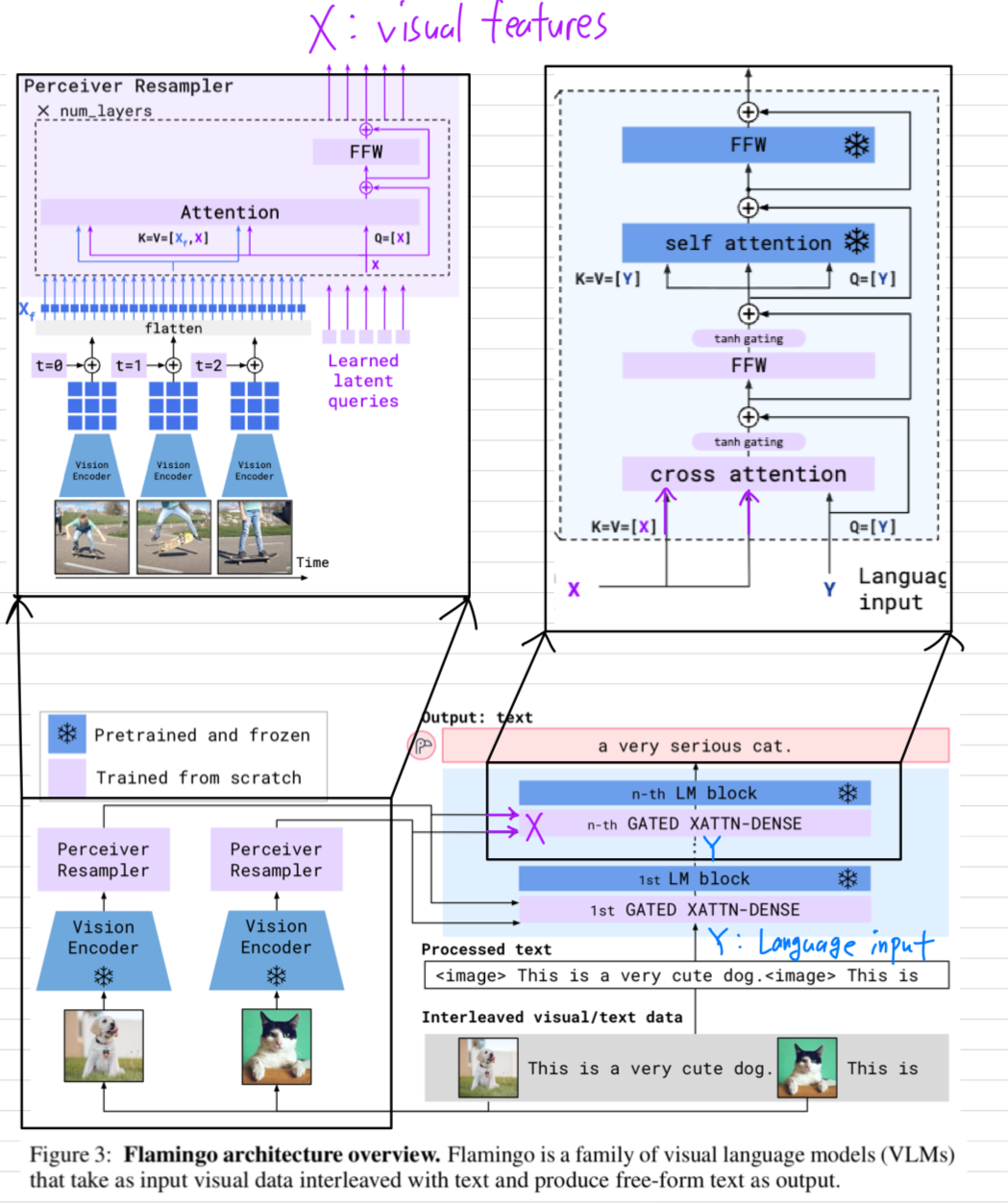
- 이 section에서 Flamingo를 설명하겠다: a VLM that accepts text interleaved with images/videos as input and outputs free-form text.
pretrained vision models과 pretrained LMs을 선택하고 두 model을 효과적으로 bridge할 수 있게 하는
key architectural components는 Figure 3에 있다.
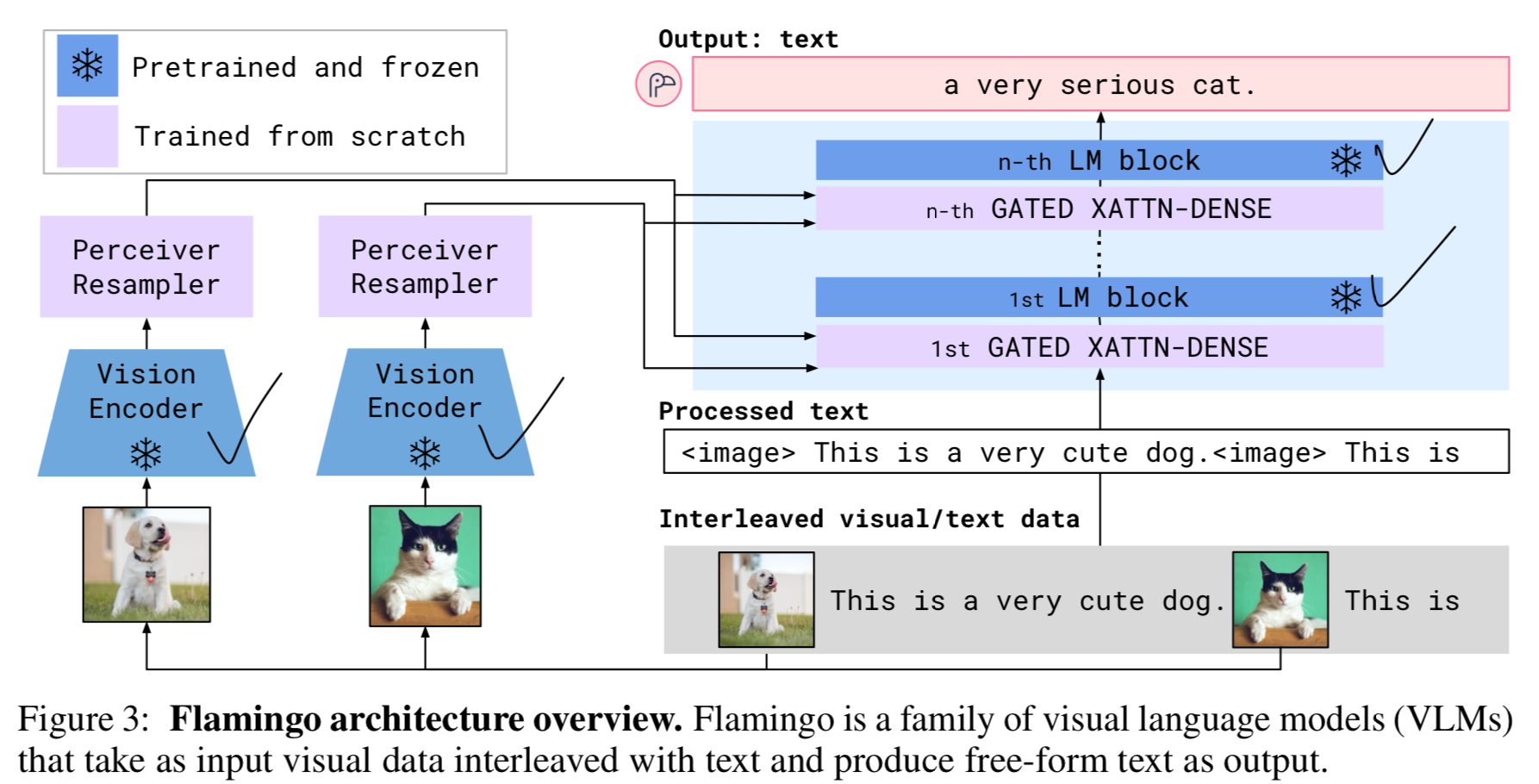
- 먼저, Perceiver Resampler (Section 2.1)은
Vision Encoder로부터 spatio-temporal features를 입력받고,
a fixed number of visual tokens을 output한다. - 그 다음, 이 visual tokens들은 freshly initialised(새로 초기화된) cross-attention layers(Section 2.2)를 사용한 frozen LM의 condition으로 사용되며,
이 cross-attention layers들은 pre-trained LM의 layer들 사이에 interleaved 방식으로 삽입된다.
이러한 new layers들은 next-token prediction tasks 과정에서 LM이 visual information을 효과적으로 incorporate할 수 있도록 하는 an expressive way를 제공한다.
Flamingo는 interleaved images and video 가 주어졌을 때, the likelihood of text 를 다음과 같이 modeling한다:
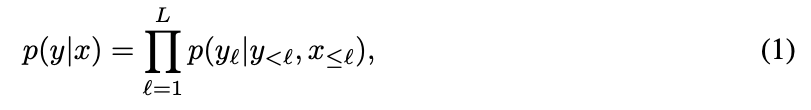 여기서 은 -th language token of the input text이고,
여기서 은 -th language token of the input text이고,
은 the set of preceding(앞서 예측된) tokens,
은 the set of images/videos preceding token in the interleaved sequence,
는 a Flamingo model의 parameter이다. - interleaved text and visual sequences를 처리할 수 있는 능력(Section 2.3)은 Flamingo model을 in-context few-shot learning에서 자연스럽게 활용할 수 있도록 하며,
이는 GPT-3가 few-shot text prompting을 하는 것과 유사하다. - Flamingo model은 Section 2.4에 설명되어 있는 a diverse mixture of datasets에 의해 trained되었다.
- 먼저, Perceiver Resampler (Section 2.1)은
2.1 Visual processing and the Perceiver Resampler
Vision Encoder: from pixels to features.
-
our vision encoder는 frozen Normalizer-Free ResNet (NFNet)을 pretrained했다 - 우리는 F6 model을 사용했다.
vision encoder는 image-text pairs로 구성된 dataset을 이용하여 contrastive objective 방식으로 pretrain되었으며,
CLIP(Radford et al. [85])에서 제안한 two-term contrastive loss를 사용한다.
우리는 final stage의 output을 사용하며, 이는 2D spatial grid의 features이고, 이후 1D sequence로 flattened된다. -
video inputs의 경우, frame을 1FPS로 sampling한 뒤 각 frame을 독립적으로 encoding하여 3D spatio-temporal grid를 얻는다.(시간 순서, 즉 temporal dimension이 추가되었으므로 3D grid인 듯.)
이후 학습 가능한 temporal embeddings을 추가하고, Perceiver Resampler에 입력되기 전에 feature들을 1D로 flattened한다. -
contrastive training과 dataset mixing strategies으로 인한 성능에 대한 details은 각각 Appendix B.1.3과 Appendix B.3.2에 제시되어 있다.
- Contrastive training (Appendix B.1.3)

- dataset mixing strategies for contrastive pretraining (Appendix B.3.2)
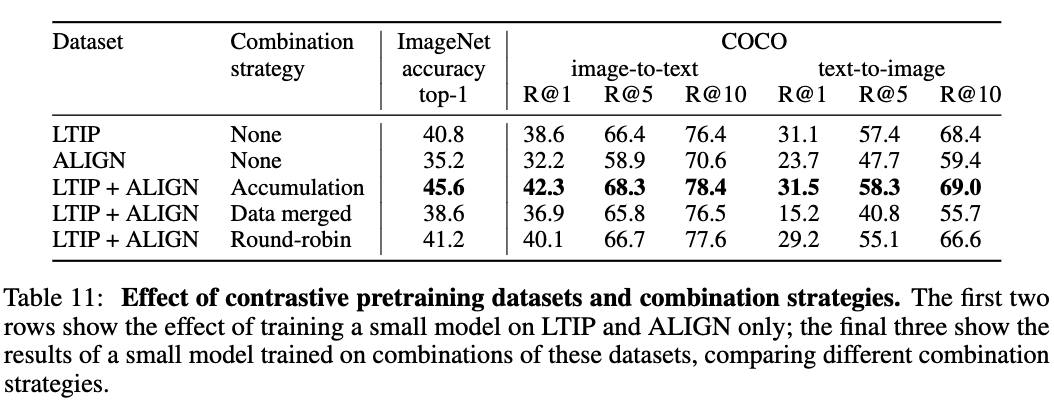
- Contrastive training (Appendix B.1.3)
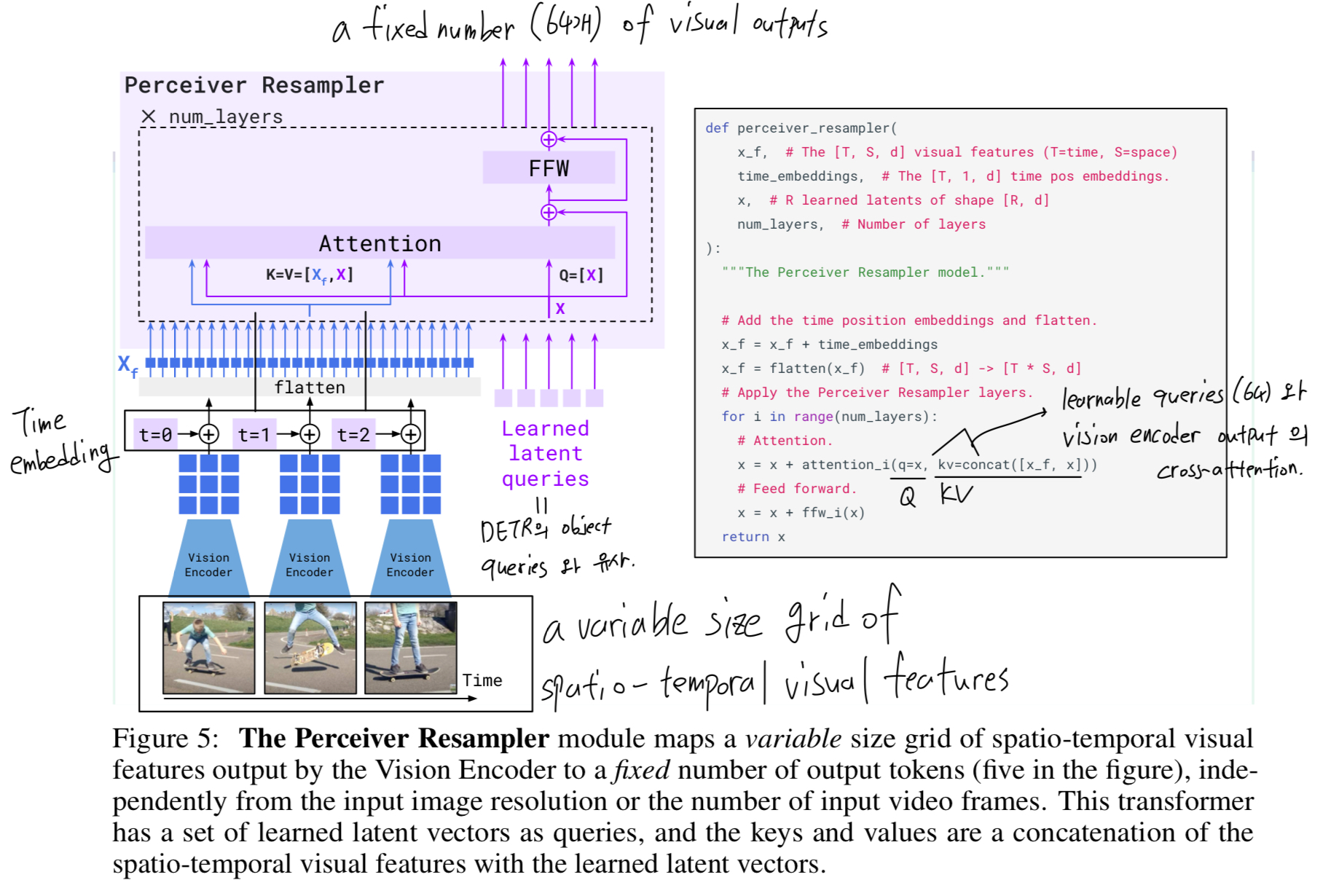
Perceiver Resampler: from varying-size large feature maps to few visual tokens.
-
Perceiver Resampler module은 Figure 3에 나타난 것처럼 vision encoder와 frozen LM을 연결하는 역할을 한다.
Perceiver Resampler는 vision encoder로부터 입력되는 a variable number of image or video frames를,
a fixed number (64개) of visual outputs을 생성함으로써
vision-text cross-attention의 computational complexity를 감소시킨다. -
Perceiver 및 DETR과 유사하게, 우리는 predefined number of latent input queries를 학습하며,
이 queries들은 Transformer에 입력되어 visual feature에 대해 cross-attention을 수행한다.
Ablation study(Section 3.3)를 통해, 이러한 vision-language resampler module을 사용하는 것이
a plain Tranasformer and an MLP를 사용하는 방식보다 우수한 성능을 보임을 확인하였다.
해당 module에 대한 illustration, more architectural details, pseudo-code는 Appendix A.1.1에 제공되어 있다.
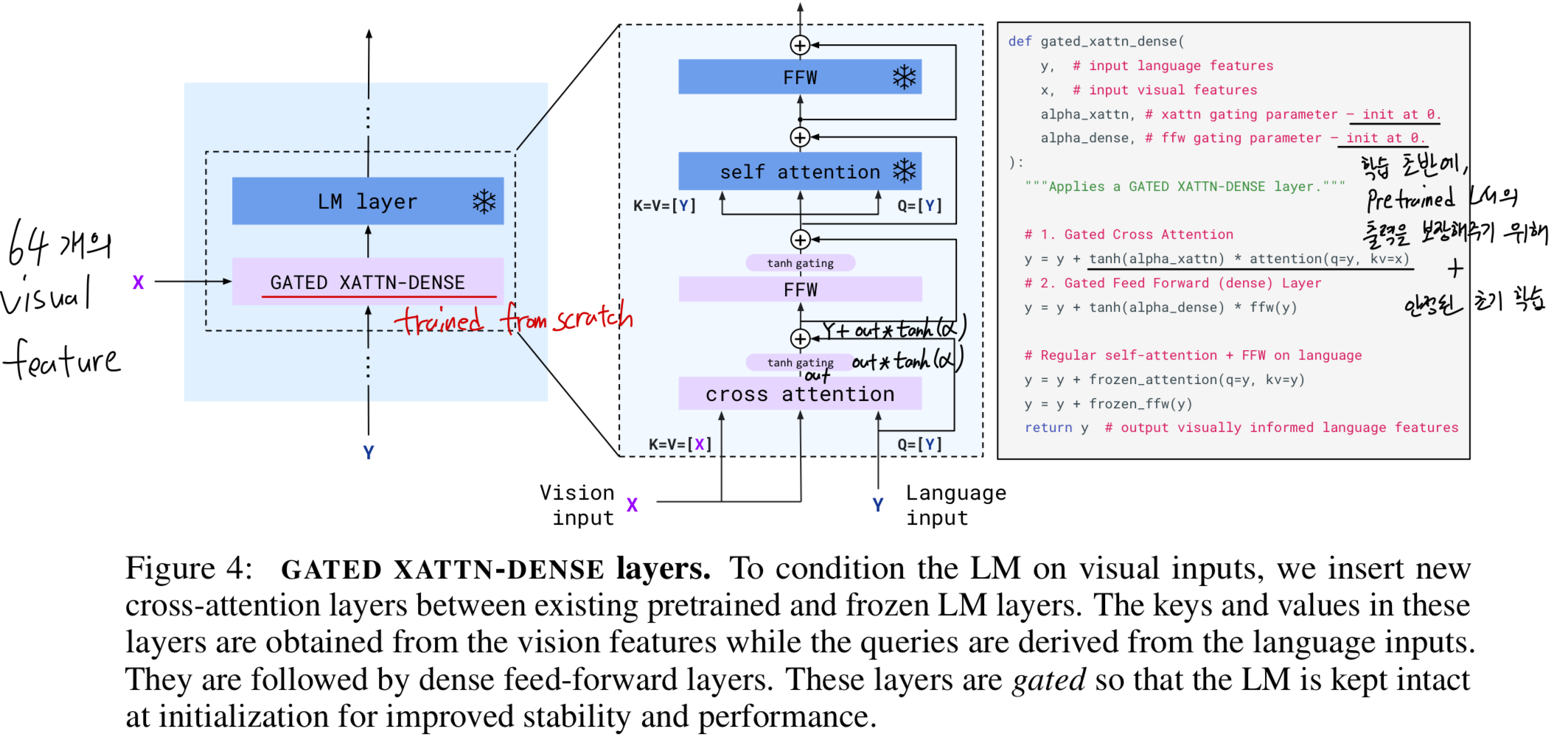
2.2 Conditioning frozen language models on visual representations
- Text generation은 Perceiver Resample에 의해 생성된 visual representations에 conditioned된 Transformer decoder에 의해 수행된다.
우리는 pretrained and frozen text-only LM blocks들과,
Perceiver Resampler의 visual output 간의 cross-attention을 수행하도록
scratch부터 training되는 blocks들을 interleave(교차)하여 구성한다.
(이게 바로 뒤에 나오는 new GATED XATTN-DENSE layers인 듯)
Interleaving new GATED XATTN-DENSE layers within a frozen pretrained LM.
- 우리는 pretrained LM blocks을 freeze하고, 그 사이에 gated cross-attention dense blocks (Figure 4)를 삽입하여 해당 block들만 scratch부터 train한다.
conditioned model이 original LM과 동일한 results를 생성하도록 보장하기 위해, tanh-gating mechanism을 사용한다.
이 방식에서는 새로 추가된 layer의 출력을 로 곱한 뒤, residual connection을 통해 input representation에 더한다.
여기서 는 0으로 initiazlied된 layer-specific learnable scalar parameter이다.
그 결과, initialization에서는 model output이 pretrained LM의 Output과 정확히 일치하게 되며, 이는 training stability and final performance를 모두 향상시킨다.
Ablation study(Section 3.3)에서는 제안한 GATED XATTN-DENSE layer를 최근 제안된 alternatives [22, 68]과 비교하고,
이러한 additional layers를 얼마나 자주 insert할지에 따른 efficiency and expressivity 간의 Trade off를 분석한다.
보다 자세한 내용은 Appendix A.1.2에 제시되어 있다.
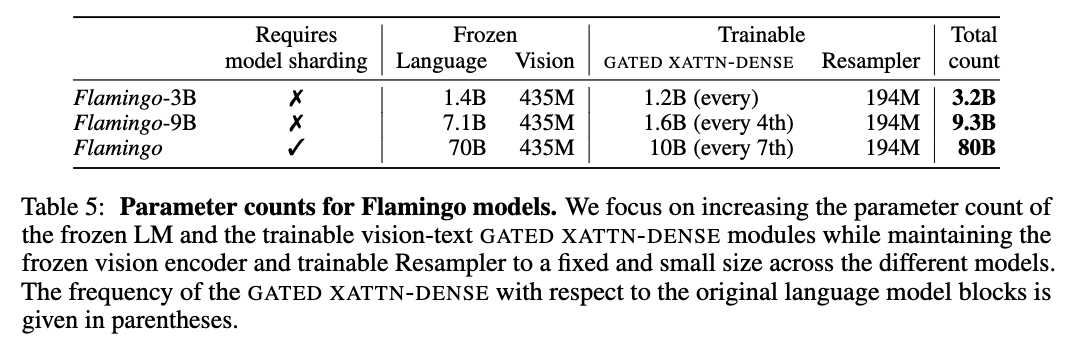
Varying model sizes
-
We perform experiments across three models sizes, building on the 1.4B, 7B, and 70B parameter Chinchilla models [42]; calling them respectively Flamingo-3B, Flamingo-9B and Flamingo-80B.
For brevity, we refer to the last as Flamingo throughout the paper. -
While increasing the parameter count of the frozen LM and the trainable vision-text GATED XATTN-DENSE modules,
we maintain a fixed-size frozen vision encoder and trainable Perceiver Resampler across the different models (small relative to the full model size).
See Appendix B.1.1 for further details.
여기까지, Flamingo architecture의 윤곽을 정리하자면 다음과 같다.
2.3 Multi-visual input support: per-image/video attention masking
-
Equation (1)에서 소개된 image-causal modeling은 full text-to-image cross-attention matrix를 masking함으로써 구현되며,
이를 통해 각 text token 시점에서 어떤 visual tokens에 접근할 수 있는지를 제한한다.
특정 text token에 대해, model은 interleaved sequence에서 해당 token 바로 이전에 등장한 image에 대응하는 visual tokens에만 attend하며,
그 보다 앞서 등장한 모든 image들에는 직접적으로 attention을 수행하지 않는다.

-
비록 model이 한 시점에서 a single image에 대해서만 직접적으로 cross-attention을 수행하더라도,
LM 내부의 self-attention mechanism을 통해 이전에 등장한 모든 image에 대한 dependency는 간접적으로 유지된다.
이러한 single-image cross-attention scheme은 학습 시 사용된 image 수와 무관하게, 임의의 개수의 visual inputs으로 자연스럽게 generalise할 수 있도록 해준다는 점에서 매우 중요하다.
실제로 우리는 interleaved datasets으로 학습할 때 only up to 5 images per sequence만 사용하지만, evaluation 단계에서는 최대 32 pairs(or "shots")의 image/videos와 이에 대응하는 text로 구성된 Sequence에서도 model이 효과적으로 성능을 발휘함을 확인하였다.
Section 3.3에서는 이러한 방식이 model이 이전의 모든 image에 대해 직접 cross-attention을 허용하는 접근법보다 더 효과적임을 보여준다.
2.4 Training on a mixture of vision and language datasets
이하 skip...
2.5 Task adaptation with few-shot in-context learning
- Flamingo는 한 번 trained되면, multimodal interleaved prompt로 model을 conditioning함으로써 다양한 visual task를 수행한다.
우리는 GPT-3와 유사한 방식으로 in-context learning을 활용하여, new tasks에 대해 얼마나 빨리 adapt할 수 있는지를 평가한다.
이를 위해 또는 형태의 support example pairs를 prompt 내에 interleaving한 뒤,
그 다음에 query visual input을 배치하여 prompt를 구성한다. (자세한 내용은 Appendix A.2 참조).- GPT-3의 in-context learning은 구체적으로 어떻게 하는건가?
- 우리는 open-ended evaluations에서는 beam search를 사용하여 decoding을 수행하며,
close-ended evaluations에서는 model이 각 가능한 답변에 대해 계산한 log-likelihood를 이용해 정답을 선택한다.
또한, image 없이 text로만 구성된 두 개의 예시를 사용해 model을 prompting함으로써 zero-shot generalization 능력을 탐구한다.
평가에 사용된 hyperparameter와 추가적인 details는 Appendix B.1.5에 제시되어 있다.- open-ended evaluation이란?
open-ended evaluation이란 정답 candidate가 정해져 있지 않고, model이 자유롭게 Text를 generating하는 평가 방식.
image captioning, visual diaglogue, VQA와 같은 task. - close-ended evaluation이란?
model은 text를 generation하지만, evaluation은 정해진 답 중 하나를 고르는 문제로 처리. - Flamingo model이 현재 주어진 task가 open-ended evaluation인지? close-ended evaluation인지? 어떻게 알까?
prompt로 출력 형식을 암시하면, model은 그 형식을 따르는 것을 학습으로 익혀왔기 때문에 해당 형식에 맞게 대답함.
예를 들어, 를 주고, Q. "Describe the image." 라고 promping하면, Flamingo는 Open-ended task prompt라 파악하고 text를 generation하기 시작.
다른 예로, 를 주고, Q. "Is the door open?" 라고 prompting하면, Flamingo는 Close-ended task prompt라 파악하고 yes/no와 같은 Classification으로 대답함. - in-context few-shot learning에서, model은 전부 frozen 상태인데 어떻게 소수 example을 줘서 학습시킬 수 있지?
내가 LLM에 대한 이해가 없기 때문에 이 질문을 한 듯함.
LLM에서는 답을 내놓기 전에, 입력된 모든 context를 훑어봄.
예를 들어, Flamingo에서
1-shot: ": 이건 귀여운 고양이야.",
2-shot: ": 이건 무서운 사자야.",
inference: ": 그럼 이건 뭘까?
라고 입력하면 Frozen LLM에서는 에 대한 답을 생성하려는 순간, attention mechanism이 앞서 입력된 context를 attend하여 패턴을 실시간으로 파악할 수 있는 것임. - beam search란?
beam search는 text generation의 decoding 방식 중 하나.
Greedy decoding은 매 step마다 가장 확률 높은 단어 1개 선택.
beam search는 매 step마다 상위 K개 후보 문장(beam) 유지.
전체 문장 확률이 높은 최종 candidate를 선택.
- open-ended evaluation이란?
3. Experiments
3.1 Few-shot learning on vision-language tasks
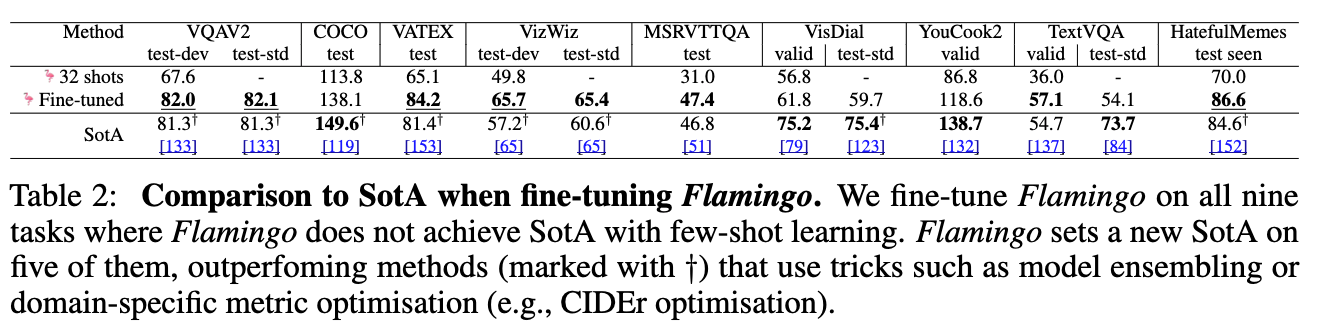
3.2 Fine-tuning Flamingo as a pretrained vision-language model
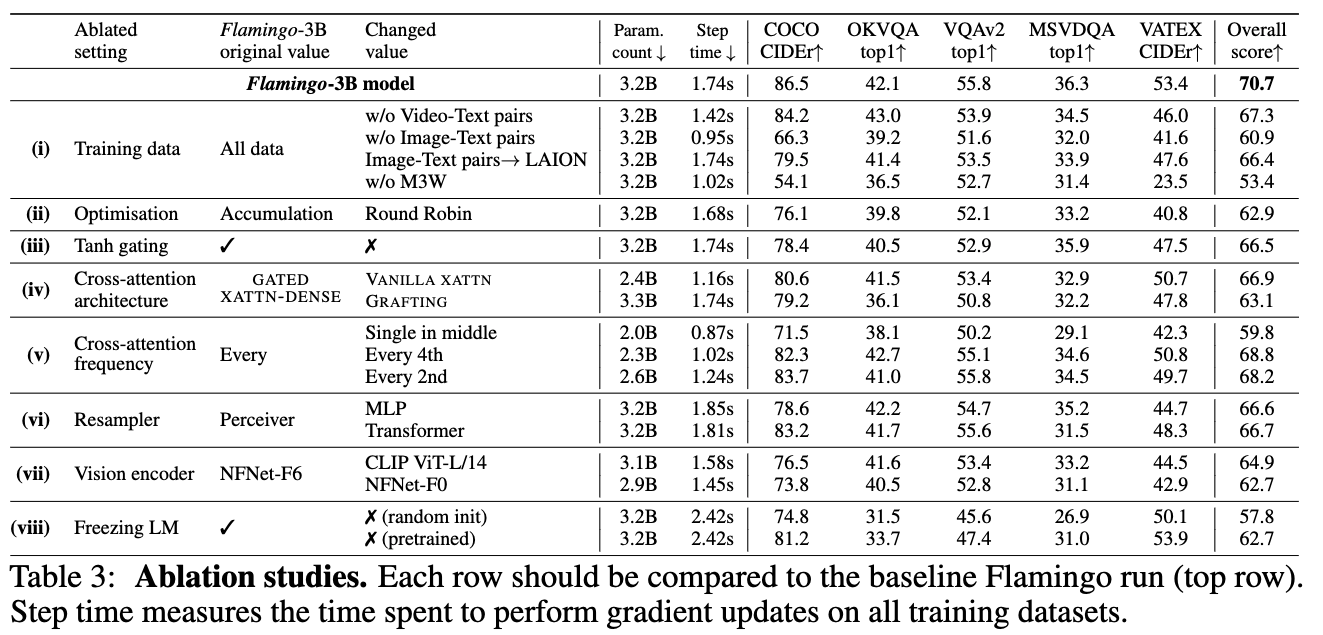
3.3 Ablation studies
4. Related Work
Language modelling and few-shot adaptation
When language meets vision
Web-scale vision and language training datasets
5. Discussion
Limitations
Societal impacts
Conclusion
이 논문의 핵심 (BLIP/CoCa와 비교하며)
-
사용 방식
- BLIP/CoCa는 다른 task를 수행하려면 fine-tuning을 해야 SOTA를 찍을 수 있음.
- Flamingo는 fine-tuning 없이, few-shot learning(in-context) 만으로 SOTA 달성 가능.
즉, prompt로 몇 개의 example을 보여주면 바로 task 수행 가능.
BLIP/CoCa는 fine-tuning을 통해 특정 task를 잘하기 위한 foundation model이고,
Flamingo는 zero/few-shot 대화를 통해 general-purpose로 문제를 해결하려는 AI agent 느낌.
-
text model
- BLIP/CoCa는 trainable
- Flamingo는 chinchilla 같은 high-performance LLM을 forzen하여 사용.
이미 똑똑한 LLM을 freeze한 채, Perceiver Resampler로 visual information을 요약하고,
Gated Cross-Attention으로 visual information을 주입하여,
언어 지능을 유지한 채 눈을 달아주는 것.
-
training data
- BLIP/CoCa는 (image, text) pairs
- Flamingo는 Interleaved data. 즉 text와 image/video가 섞인 web page 전체
궁금한 점, 몰랐던 것
모든 답변은 ChatGPT의 답변...
-
open-ended evaluation이란?
open-ended evaluation이란 정답 candidate가 정해져 있지 않고, model이 자유롭게 Text를 generating하는 평가 방식.
image captioning, visual diaglogue, VQA와 같은 task. -
close-ended evaluation이란?
model은 text를 generation하지만, evaluation은 정해진 답 중 하나를 고르는 문제로 처리. -
Flamingo model이 현재 주어진 task가 open-ended evaluation인지? close-ended evaluation인지? 어떻게 알까?
prompt로 출력 형식을 암시하면, model은 그 형식을 따르는 것을 학습으로 익혀왔기 때문에 해당 형식에 맞게 대답함.
예를 들어, 를 주고, Q. "Describe the image." 라고 promping하면, Flamingo는 Open-ended task prompt라 파악하고 text를 generation하기 시작.
다른 예로, 를 주고, Q. "Is the door open?" 라고 prompting하면, Flamingo는 Close-ended task prompt라 파악하고 yes/no와 같은 Classification으로 대답함. -
in-context few-shot learning에서, model은 전부 frozen 상태인데 어떻게 소수 example을 줘서 학습시킬 수 있지? = GPT-3의 in-context learning은 구체적으로 어떻게 하는건가?
내가 LLM에 대한 이해가 없기 때문에 이 질문을 한 듯함.
in-context learning(ICL)은 "learning"이라는 용어가 오해를 부르지만, 실제로는 학습 없이 inference 과정에서 행동을 바꾸는 mechanism.
LLM에서는 오직 다음 token의 probability만 modeling함.
이때, LLM의 self-attention에서는 앞서 입력된 모든 context를 훑어봄.
예를 들어, Flamingo의 frozen LLM에서
1-shot: ": 이건 귀여운 고양이야.",
2-shot: ": 이건 무서운 사자야.",
inference: ": 그럼 이건 뭘까?"
라고 입력하면 Frozen LLM에서는 에 대한 답을 생성하려는 순간, attention mechanism이 앞서 입력된 context를 attend하여 패턴을 실시간으로 파악할 수 있는 것임.

-
그러면 Flamingo 이전(CLIP, ALIGN, BLIP, CoCa)에는 text encoder, decoder로 LLM을 안썼나?
Flamingo 이전에도 LLM을 쓰긴 했지만, Flamingo처럼 그대로 frozen LLM을 핵심 generator로 쓰는 방식은 아니었음.
Flamingo에서는 이미 잘 pretrained된 LLM을 그대로 사용하고,
vision encoderr에서 LLM으로 연결되는 연결부(Perceiver Resampler)와 multimodal cross-attention layer만 학습.
따라서 LLM의 in-context learning을 language(uni) modal에서만 가능한게 아니라, vision-language(multi) modal에서도 가능하게 확장함. -
beam search란?
beam search는 text generation의 decoding 방식 중 하나.
Greedy decoding은 매 step마다 가장 확률 높은 단어 1개 선택.
beam search는 매 step마다 상위 K개 후보 문장(beam) 유지.
전체 문장 확률이 높은 최종 candidate를 선택.
