[2024 AICAS] An Efficient and Fast Filter Pruning Method for Object Detection in Embedded Systems
[Paper Review] Efficient and Scalable
H. Ko, J. -K. Kang and Y. Kim, "An Efficient and Fast Filter Pruning Method for Object Detection in Embedded Systems," 2024 IEEE 6th International Conference on AI Circuits and Systems (AICAS), Abu Dhabi, United Arab Emirates, 2024, pp. 204-207, doi: 10.1109/AICAS59952.2024.10595873. keywords: {Training;Computational modeling;Redundancy;Object detection;Search problems;Software;Loss measurement;CNN;Network compression;Filter pruning;Object detection;Inference time},
Abstract
-
networks가 deeper and wider일수록, real-time embedded 환경에 model을 적용하는 것은 힘들다.
이 단점을 극복하기 위해, filter pruning은 neural network compression에서 널리 연구되고 있다.
Filter pruning은 CNN의 filter를 제거하고 특별한 SW나 HW 없이 inference를 가속화하기 때문에 어떠한 speical HW or SW가 필요하지 않다. -
이 논문에서, 우리는 efficient and fast filter pruning(EFFP)를 제안했으며,
이는 training에 필요한 computation resources를 줄이고 최적의 pruning network를 탐색하는 데 중점을 둔다.
EFFP의 성공은 다른 pruning 방법에 비해두 가지 주요 개선 사항에서 비롯된다.- Short training time :
pruning 단계에서 redundant filter를 0으로 만들어 output feature map이 lightweight model과 동일하게 만들고, - adjust the change of redundancy using regrowing :
redundant filter를 한 번에 pruning하는 것으로는 optimal pruned moel을 얻기 어렵기 때문에, 중요하지 않은 filter를 점진적으로 제거하여 중요한 filter를 영구적으로 제거하지 않도록
pruning/regrowing 방법을 사용하여 optimal pruned model을 얻는다.
- Short training time :
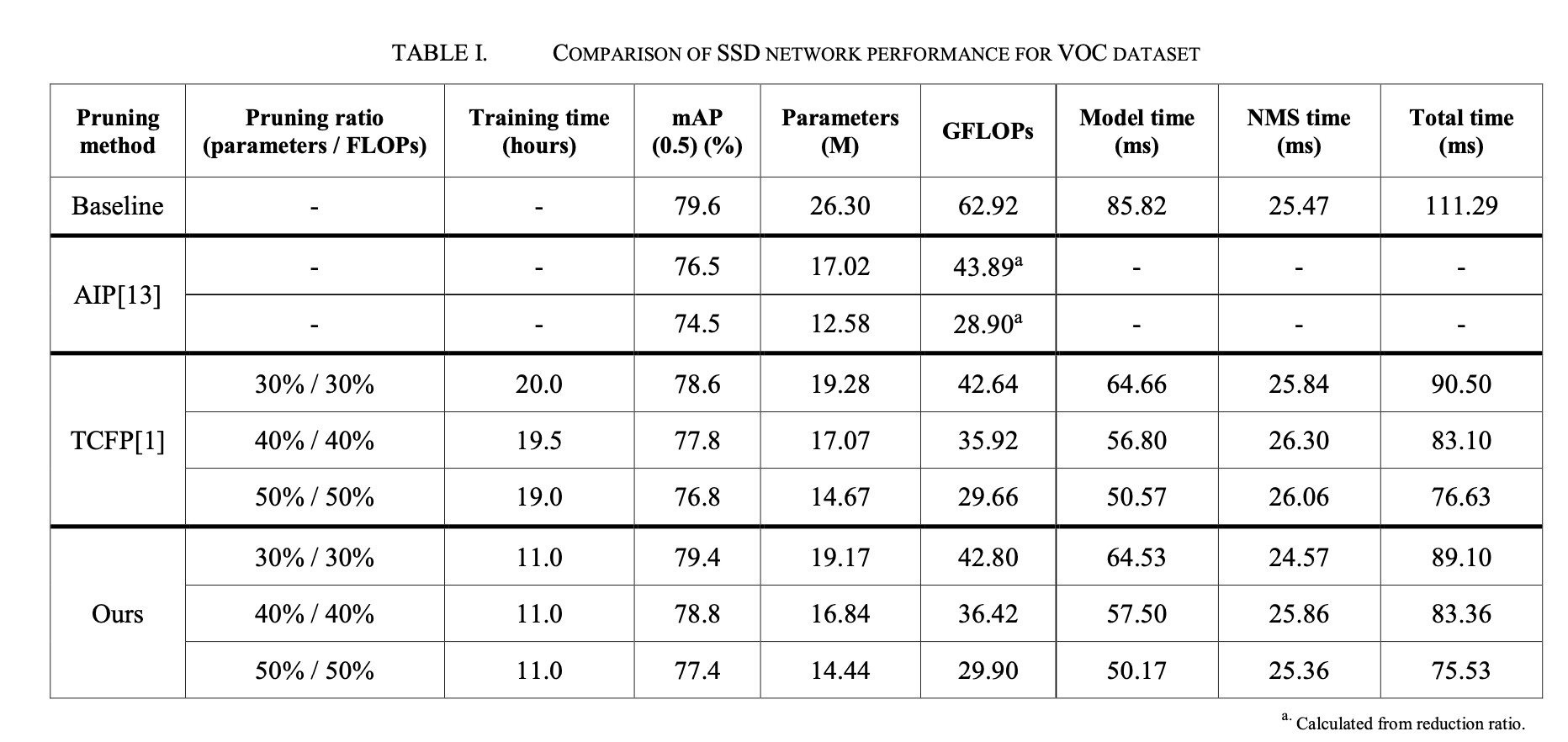
- 실험 결과, EFFP는 object detection model에서 다른 pruning 방법보다 더 효율적이고 빠르게 FLOPs와 parameter를 줄일 수 있음을 보였다.
inference time은 NVIDIA Jetson Xavier NX에서 측정되었으며, 그 결과 다른 pruning 방법에 비해 mAP와 inference time이 최대 45% 향상되었다.
1. Introduction
- Pruning method는 CNN을 경량화하고 network에서 redundant weights를 제거하여 embedded system에서 inference를 최적화하는 방식이다.
pruning method는 일반적으로 sparsity learning을 통한 importance meaure를 사용하고,
덜 중요한 parameter를 pruning하여 lightweight model을 얻은 후
performance와 accuracy를 maximize하기 위해 fine-tune을 수행한다.
하지만 두 번의 training cycles이 필요하기 때문에, pruned model을 얻는 데 많은 time-consuming and resource-intensive하다.
-
본 논문에서는 efficient and fast filter pruning(EFFP)를 제안한다.
이는 target capacity filter pruning(TCFP)를 single learning process로 단순화하고,
pruning으로 인한 importance 변화를 학습하도록 개선하였다.
이 방법을 적용하여 parameter와 floating point operations(FLOPs)를 50% 줄였을 때,
TCFP 방법에 비해 mAP가 0.78% 향상되었고, inference time은 1.43% 개선되었다.
또한, training time은 TCFP 방법에 비해 42% 단축되었다. -
본 논문의 contribution은 다음과 같다.
- pruning method를 적용하면서 filter의 redundancy 변화로 인한 importance 변화를 반영하기 위해
pruning과 regrowing 과정을 사용하는 efficent and fast filter pruning(EFFP) 방법을 제안했다.
추가로, 여러 번 training session이 필요한 기존의 pruning 방법을
single training session으로 줄여 lightweight network를 얻는다. - 기존 pruning 방법들은 classification에 적용되었지만,
object detection model에서는 성능을 보장할 수 없다.
본 논문에서는 제안한 filter pruning 방법을 object detection model에 적용했다. - 제한된 resource를 가진 embedded board에서 성능 향상을 검증하기 위해 NVIDIA Jetson Xavier NX에서 inference speed를 측정하였으며,
pruning 전 model 및 다른 방법으로 pruned model에 비해 inference 시간이 개선되었다.
- pruning method를 적용하면서 filter의 redundancy 변화로 인한 importance 변화를 반영하기 위해
- Section 2에서는, SSD[8]와 이전 pruning method에 대해 설명한다.
Section 3에서는 NVIDIA GPUs에서 training time을 최소화하여 detection network를 가속화하기 위한
efficient and fast filter pruning(EFFP)를 소개한다.
section 4에서는 EFFP의 실험 결과를 분석하고,
section 5에서는 본 논문의 결론을 제시한다.
2. Background
A. Single Shot Multibox Detector(SSD)
-
object detection network는 two-stage와 one-stage로 나뉜다.
two-stage object detection networks는 classification과 localization을 별도로 진행하기 때문에
느린 inference speed와 복잡한 구조로 인해 학습이 어려운 단점이 있다.
반면, one-stage object detection는 classification과 localization을 동시에 수행하므로 빠른 inference speed를 갖는 장점이 있다. (대표적으로 SSD[8]와 YOLO) -
SSD는 주로 backbone network, auxiliary network, 그리고 prediction network로 나뉜다.
- backbone network는 VGG-16[10] network를 사용하여 feature map을 추출하고,
- auxiliary network는 더 작은 feature map을 추출하여 large objects를 detection한다.
- prediction network는 CNN을 사용하여 classification과 localization을 수행한다.
B. Pruning
-
structured pruning은 per-filter or per-channel 단위로 importance를 분석하여
불필요한 filter나 channel을 제거함으로써 model의 구조를 유지하면서 압축할 수 있다.
이는 general inference environment에서 #computations을 줄여주며, inference speed를 향상시킬 수 있다. -
structured pruning을 위한 다양한 방법들이 제안되었으며, importance를 측정하는 기준에 따라 차이가 있다.
[6]에서는 각 filter의 L1-norm을 importance로 사용하고, 값이 낮은 순서대로 filter를 제거했다.
사용자는 각 layer의 filter pruning ratio를 결정해야 한다.
[4]는 각 CNN layer의 output feature map의 rank를 이용해 importance를 측정하고,
predefined된 pruning ratio를 제거했다.
[5]는 adaptive BN을 사용하여 후보 성능을 예측했다.
이러한 단점을 해결하기 위해 한 번의 training만으로 필요한 방법들이 제안되었다.
[3]은 Zero Invariant Groups(ZIGs)을 사용하여 중요하지 않은 channel과 그에 연결된 weight를 0으로 만들어 결과적으로 lightweight network와 동일한 feature map을 얻을 수 있도록 학습했다.
[2]는 Column Subset Selection(CSS)를 통해 filter의 independece를 결정하고,
중복된 filter를 0으로 만들어 lightweight network의 결과를 예측했다.
이 방법은 filter의 importance가 변화하는 것을 고려하여 pruning/regrowing process를 사용했다. -
이러한 노력에도 불구하고 대부분의 방법들은 각 layer마다 pruning ratio를 맞춰야 하는 한계를 갖고 있으며, 주로 classification model에 적용되고 실험되었다.
본 논문에서는 sparsity learning과 fine-tuning을 통합하여 한 번의 학습만으로 object detection model의 training time을 줄이는 simple learning method를 제안한다.
3. Proposed Method
A. Overall Proposed Method
-
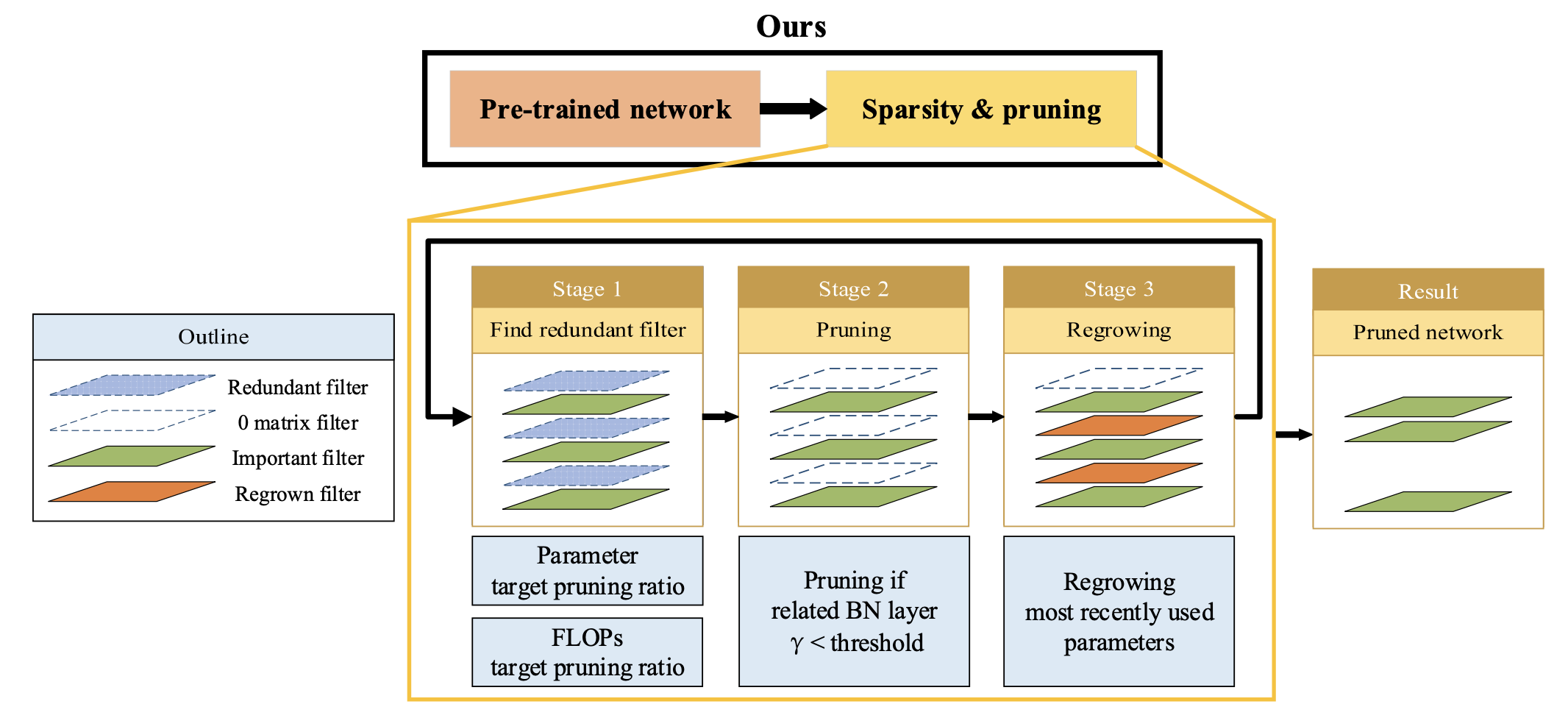
제안된 방법은 Fig.1.에 나와있다.
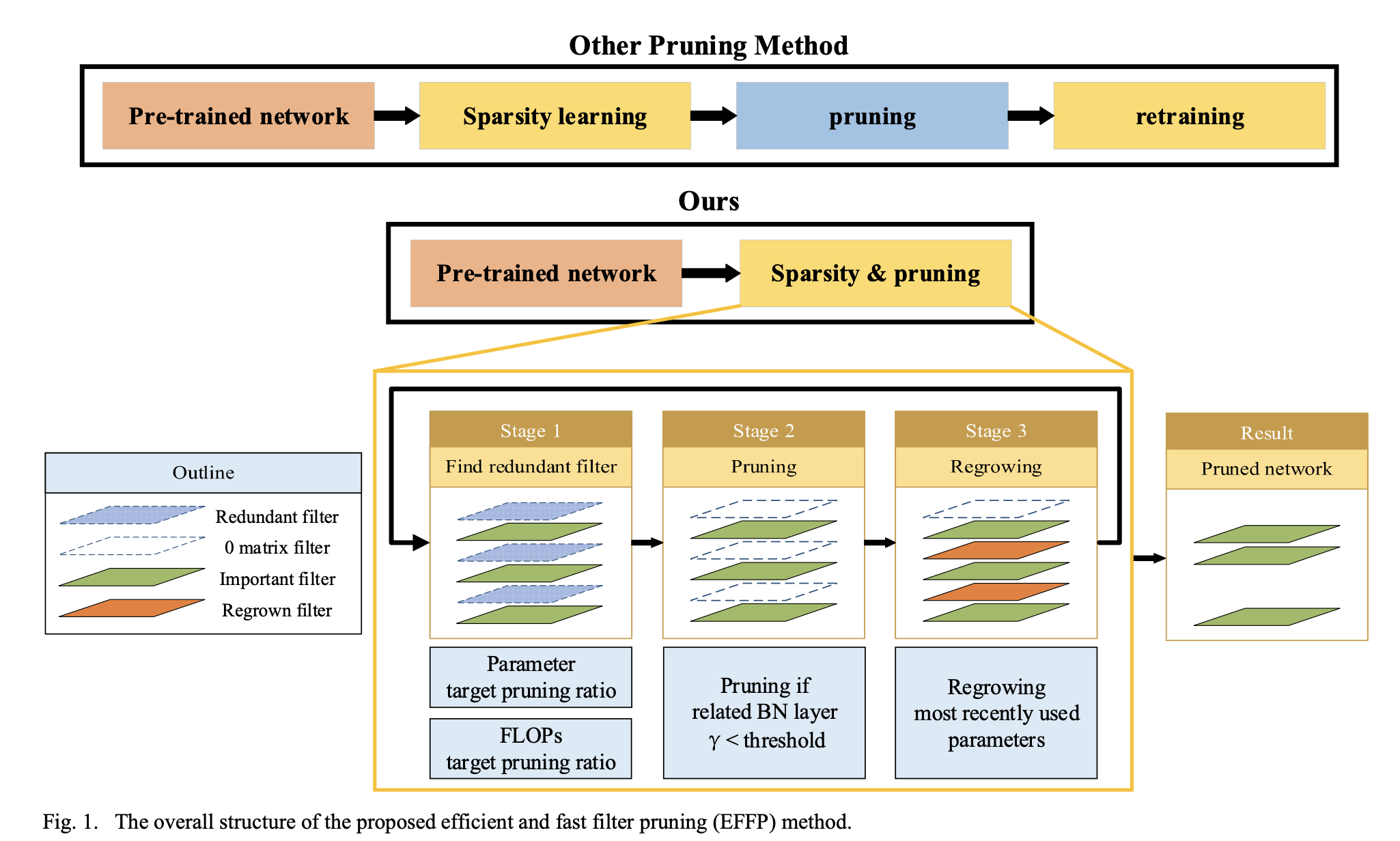 기존 방법에서 pruned model을 얻기 위해 필요한 sparsity learning and training이라는
기존 방법에서 pruned model을 얻기 위해 필요한 sparsity learning and training이라는
두 번의 training session을 하나의 training session으로 간소화했다.
또한 pruning으로 인해 각 filter의 importance가 변하는 것을 고려하기 위해 pruning/regrowing 방법을 적용했다. -
추가로, parameter와 FLOPs의 target pruning ratio를 별도로 설정하여 원하는 규모의 pruning model을 쉽게 얻을 수 있다.
이 과정에서 redundant filters를 찾기 위해 기존 network loss에 pruning loss를 추가하여 학습을 진행한다.
몇 번의 iterations 후 redundant filter가 발견되면, unimportant filter와 관련된 parameter를 0으로 설정하여 output feature map이 pruned model과 동일하게 만든다.
그 후 일부 pruning filter를 다시 복구하며, regrowing되는 filter의 수는 현재 training iteration에 따라 선형적으로 감소한다.
B. Pruning Loss
- prunig loss는 Fig. 1의 stage 1에서 사용되었다.
 target pruning filter를 결정하는 기준은 를 사용한 indicator function()이다.
target pruning filter를 결정하는 기준은 를 사용한 indicator function()이다.
값이 threshold 보다 작으면 해당 filter는 pruning될 수 있다.
loss function을 만들기 위해 original model의 total FLOPs(F)와 parameters(P),
현재 pruned model의 FLOPs()와 parameters(),
그리고 target pruned model의 FLOPs()와 parameters()을 계산해야 한다.
현재 pruned model의 FLOPs와 parameters를 계산하기 위해 식 (1)과 (2)를 사용한다.
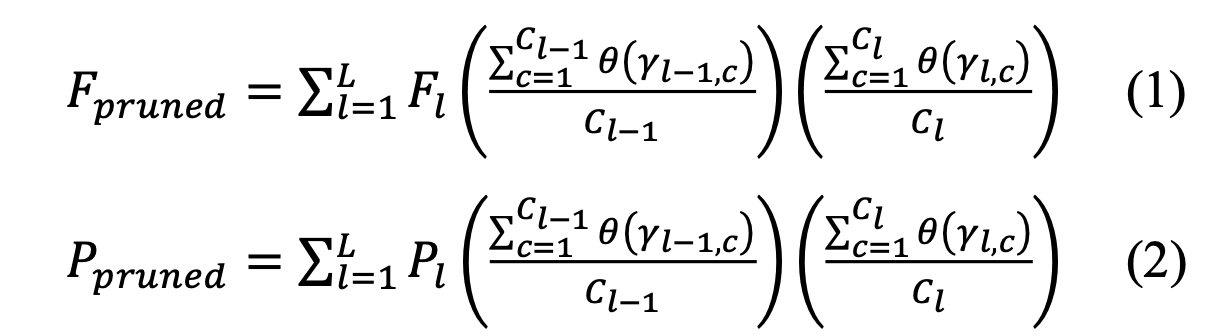 은 #layers이고,
은 #layers이고,
은 -th layer의 #channels,
은 -th layer의 #FLOPs,
은 -th layer의 #parameters
첫번째 ()은 이전 layer로부터 pruned channels의 효과를 의미한다.
두번째 ()은 현재 layer의 효과를 의미한다.
Pruning loss는 (3)에서 (1)과 (2)를 사용함으로써 생성될 수 있다.
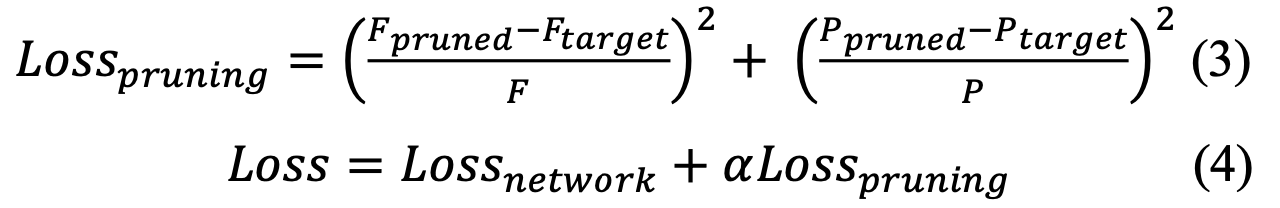 (4)처럼, Pruning loss(3)는 network loss()에 더해짐으로써 적용된다.
(4)처럼, Pruning loss(3)는 network loss()에 더해짐으로써 적용된다.
는 pruning loss의 strength를 조절하기 위한 scaling factor이다.
C. Pruning
- pruning은 Figure 1의 stage 2에서 수행된다.
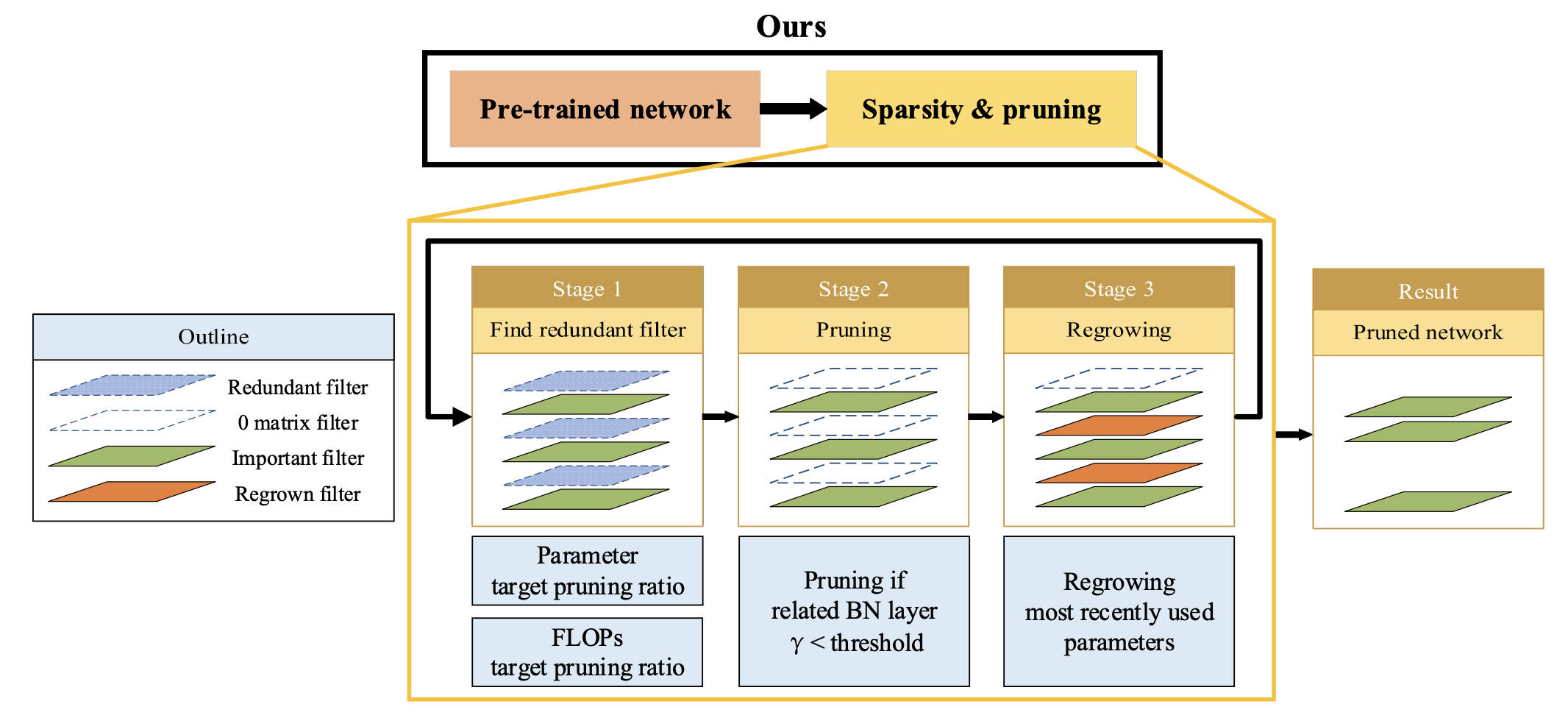 일반적인 CNN은 convolution, BN, activation layer가 반복적으로 구성된다.
일반적인 CNN은 convolution, BN, activation layer가 반복적으로 구성된다.
또한, BN layer의 수는 이전 convolution의 output feature maps 개수와 동일하며, 이는 filter 개수와도 동일하다.
따라서 stage 1에서 indicator function으로 얻은 pruning target을 사용하여 관련된 filter를 제거할 수 있다.
본 논문에서는 해당 filter를 0으로 고정하여 그 layer의 output feature map이 pruned model과 동일한 값을 갖도록 하여, 최종 pruning 후 0으로 설정된 filter를 제거해도 성능에 영향을 미치지 않도록 했다.
이렇게 하여 최종적으로 pruned model을 얻고, important filter는 stage 2 pruning에서 발생하는 performance degardation을 최소화하도록 학습된다.
D. Regrowing
- pruning 방법에서 사용된 assumption은 filter가 얻은 특징이나 역할이 다른 filter에도 존재하여 redundancy가 발생한다는 것이다.
따라서 일부 중복된 filter를 제거하면 비슷한 성능을 유지하면서도 inference speed를 줄이는 효과를 얻을 수 있다.
그러나 pruning은 남아 있는 filter들의 redundacny를 변화시킨다.
이는 한 번의 pruning으로는 optimal pruned model을 보장할 수 없다는 것을 의미한다.
그래서 Figure 1의 stage 3에서, stage 2에서 제거된 filter 중 일부를 복구하고,
pruning으로 인해 변화한 filter의 redundancy를 완전히 반영하기 위해 학습을 진행한다.
target pruning ratio을 점진적으로 달성하기 위해, 학습이 진행됨에 따라 복구되는 filter의 수는 점차 감소하도록 설계되었다.
filter 복구는 pruning 직전에 학습된 최신 parameter를 사용하여 이루어진다.
E. Implementation of SSD network
4. Experiments