[2024 WACV][Simple Review][SViT] Revisiting Token Pruning for Object Detection and Instance Segmentation
[Paper Review] Efficient and Scalable
Abstract
-
ViTs는 computer vision에서 인상적인 성능을 보여줬으나,
quadratic in the nubmer of tokens으로 high computational cost로 인해 computation-constrained applications에 적용하기에 제한되었다.
그러나 이 많은 수의 token이 모두 필요한 것은 아니다.
모든 token이 똑같이 중요한 것은 아니기 때문이다.
본 논문에서는 image classification task에서의 이전 연구를 확장하여
object detection과 instance segmentation을 위한 inference acceleration을 위해 token pruning을 연구한다. -
extensive experiments를 통해 다음 네 가지 insights를 제공한다.
- token이 완전히 pruned되어 버려져서는 안 되며, 나중에 사용할 수 있도록 feature map에 보존되어야 한다
- 이전에 제거된 token을 reactivating하면 model 성능이 더욱 향상될 수 있다.
- fixed pruning rate보다 image에 기반한 dynamic pruning rate이 더 낫다.
- lightweight 2-layer MLP가 복잡한 gating networks와 비슷한 accuracy를 유지하면서도 simpler design으로 효과적으로 token을 제거할 수 있다.
- COCO dataset에서 이러한 design decision의 효과를 평가한 결과, 기존의 token pruning 방법과 비교해 box 및 mask에서 약 1.5 mAP에서 0.3 mAP까지 성능 저하를 줄이는 접근 방식을 도입했다.
모든 token을 사용하는 dense couterpart와 비교할 때, 본 방법은 inference speed가 최대 34% 빨라졌으며, backbone network에서는 46% 향상되었다.
(Code: https://github.com/uzh-rpg/svit/)
1. Introduction
-
ViTs가 처음 소개되고, 많은 vision tasks에서 빠르게 자리잡으며 활발하게 사용되고 있다.
pair-wise token attention을 통한 global reasoning을 수행하기 위한 unique ability를 가지고 있으며, 이것은 장점이자 단점이 될 수 있다.
이는 architectures의 representational power를 향상시키면서 computational foot-print의 상당한 증가를 초래한다.
이는 resource-constrained settings에 ViTs 적용을 제한한다. -
큰 계산 비용을 줄이기 위한 실행 가능한(viable) 전략 중 하나는 input space에서 less critical features를 pruning하여 input-aware inference를 수행하는 것이다.
이 전략은 이전에 CNN에 적용되어 FLOP 측정을 개선했지만, convolution 연산의 the intrinsic regularity(고유한 규칙성) 때문에 HW에서 눈에 띄는 speedup을 얻기는 어려웠다.
하지만 ViT의 등장으로 input-space pruning 방식이 가능해졌다.
ViT의 MLP는 pointwise로 작동하고, self-attention은 본질적으로 임의의 수의 token을 처리할 수 있기 때문에 token을 제거하는 방식이 HW 수정 없이도 상당한 speedup을 달성할 수 있다. -
초기 연구에서는 gating network를 활용해 less significant token을 식별하거나 class token으로부터 minimal attention을 받는 token을 제거하는 방법이 제안되었다.
이러한 방법들은 효과적이었으나, image classification에만 적용되었으며, object detection과 instance segmentation과 같은 다른 task에 적용된 사례는 거의 없었다.
dense tasks에서의 token pruning에 대한 연구는 여전히 부족한 상태이다. -
이 논문에서는,
ViTs에서 token pruning을 활용한 object detection and instance segmentation을 다루며,
기존 image classification과 dense tasks 간의 거리를 좁히기 위한 목적이다.
우리의 preliminary 실험에서, 기존의 방법을 dense tasks에 적용하는 것이 상당한 성능 저하를 이끈다는 것을 발견했다.
광범위한 실험을 통해 성능을 개선하고 model design을 간소화하는 데 유용한 네 가지 key insights를 도출했다.
이 insights를 기반으로 기존 token pruning 방법보다 훨씬 우수한 성능을 보여주는 방법을 개발했다. -
Our insights are as follows:
- Token preserving on dense tasks.
classification과는 달리 object detection과 같은 dense prediction tasks에서는 제거된 token을 영구적으로 삭제하는 대신,
이를 feature maps에 보존하여 detection head에서 나중에 활용하는 것에 이점이 있다. - Token reactivation as needed.
token을 preserving(보존하는 것) 외에도, backbone에서 필요할 때 제거된 token을 reactivating하면
layer-wise attention에 적응하고 mis-pruned token을 복구하게 됨으로써 model의 성능을 향상시킬 수 있다.
한 번 제거된 token은 이후 layer, 특히 바로 다름 layer에서 재사용될 수 있는 flexibility를 갖는다. - Pruning with a dynamic rate.
이전에 classification에서 제안된 dynamic pruning rate 개념은 복잡한 image에는 더 많은 token을 할당하고 simple image에는 더 적은 token을 할당하여 동일한 computation resource 내에서 model 성능을 최적화했다.
이는 dense prediction tasks에서 token reactivation과 결합될 때 추가적인 효과를 발휘한다. - 2-layer MLP is sufficient.
lightweight MLP는 어떤 token을 pruning할지 선택하는 데 충분하며, classification에서 사용된 더 복잡한 gating network와 거의 동일한 정확도를 보인다.
- Token preserving on dense tasks.
-
우리는 이러한 design choices들을 평가하고 이를 기반으로 token을 선택적으로 pruning하는 straightforward model을 만들었다.
이를 SViT라고 부른다.
이 model은 기존의 SOTA token pruning models보다 성능이 뛰어나며, box와 mask에서 mAP 손실을 약 ~1.5에서 약 ~0.3으로 줄이고,
dense counterpart의 inference speed를 전체 network에서 최대 34%, backbone에서 46%까지 가속화했다.
2. Related Work
Vision Transformer
- Transfomers는 NLP community에서 시작되었으며,
최근에는 [22, 28]과 같은 long-range relations을 포착하는 능력 덕분에 computer vision에서도 인기를 얻고 있다.
ViTs에 대한 초기 연구는 large-scale datasets에서 pretrained할 경우, SOTA classification 성능을 달성하는 것을 보여줬다.
그 이후로 ViT architectuure에는 여러 가지 개선이 제안되었다.
여기에는 향상된 tokens' aggregation schemes, multi-scale hierarchical designs, and hybrid architectures combining CNNs가 포함된다.
design 향상 외에도 연구자들은 보다 복잡한 vision task에 VITs의 활용을 연구해왔다.
이 논문은 이러한 두 연구 분야 사이에 위치하며, arhictecture design choice에 중점을 두는 것뿐만 아니라,
object detection 및 instance segmentation과 같은 dense prediction tasks로 그 활용을 확장하고자 한다.
Transformer Acceleration
- Transformer의 high computational cost를 최적화하기 위한 다양한 방법이 탐구되었다.
여기에는 lightweight attention formulations, removing unnecessary network modules, approximating attention multiplications with low-rank decompositions, distilling knowledge into a more efficient student network, and extending network quantization techniques for Transformers.
게다가, ViTs에 특화된 acceleration techniques이 제안되었다[19, 33, 40, 43, 46, 60, 62],
이는 input patches의 redundancy를 활용하여 token을 early drop함으로써 연산을 절감하는 방법이다.
Input Space Pruning
-
Input image의 모든 영역이 동일하게 중요한 것은 아니므로, redundant areas를 제거함으로써 연산을 줄일 수 있으며,
명백한 accuracy loss 없이도 이를 수행할 수 있다.
Spatially ACT는 CNN에서 pixel을 제거하는 방법을 제안한다.
ViT에 대한 다양한 token pruning 기법들이 classification에서 개발되었으며,
여기에는 gating networks, attention scores, reinforcement learning 및 기타 방법 등이 포함된다.
이 중 ToMe[2]는 token을 제거하는 대신 merge하는 방식을 제안한다. -
몇몇 연구들은 dense tasks도 고려했다.
SparseViT는 pyramid transformers에 대해 coarse window를 제거하는 반면, isotropic(등방성) transformers에 대해 finer-grained(더 세밀한) token을 제거한다.
SparseDETR은 DETR architecture의 효율성을 개선하는 데 중점을 두는 반면,
우리는 transformer-based backbone의 개선에 집중한다.
STViT-R은 token을 반복적으로 몇 개의 semantic tokens으로 clustering한 뒤 spatial resolution을 복원하는 방식이지만,
우리는 spatial resolution을 유지하며 자세한 position information을 보존한다.
3. Token Pruning on dense prediction tasks
3.1. Revisit prior token pruning approaches
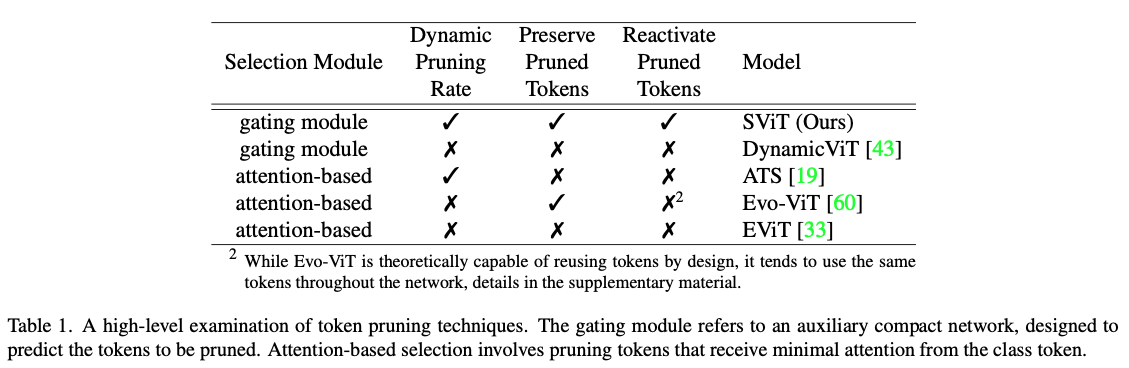
- 우리는 token pruning 기법의 대부분을 검토하며, 그들의 workflows에서 high-level distinctions(차이점)을 설명한다.
Table 1에서 보이듯, 이러한 접근 방식은 네 가지 차원에서 분류할 수 있다 :- the selection module
- use of dynamic pruning rate
- preservation of pruned tokens
- reactivation of pruned tokens
- token pruning의 overall workflow는 Figure 2에 나타나 있으며, 다음과 같이 요약할 수 있다.
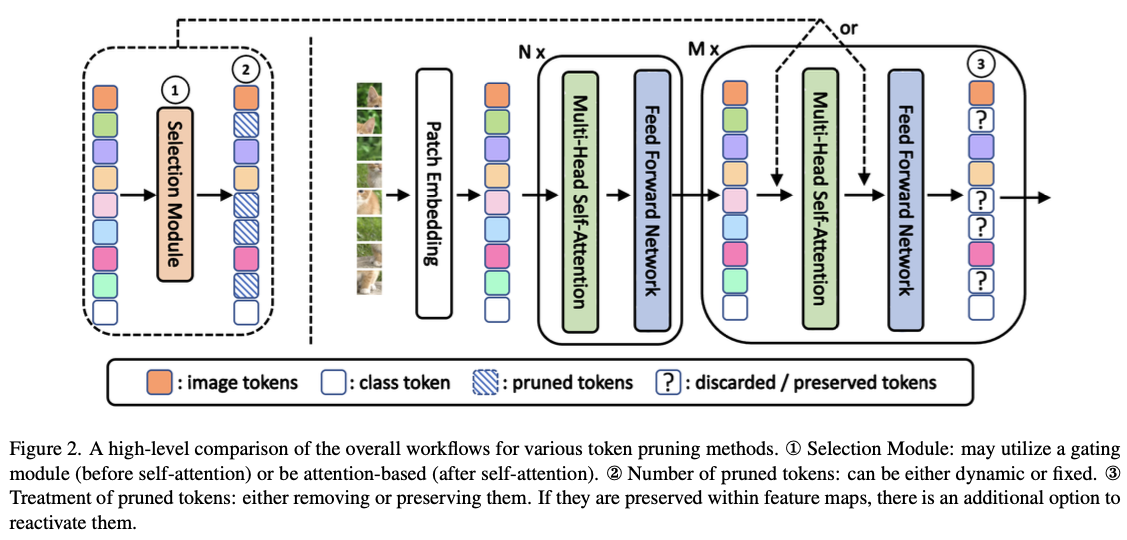 먼저 input image를 non-overlapping patches로 나누고, 이를 linearly transformed하여 token으로 만든 후,
먼저 input image를 non-overlapping patches로 나누고, 이를 linearly transformed하여 token으로 만든 후,
초기 ViT blocks에서 처리하여 충분히 포괄적인 feature representations을 얻는다.
그 다음으로 token selection module을 도입하여 pruning할 token을 식별하고, 이에 따라 token 수가 줄어들어 연산이 가속화된다.
여기서 주목할 점은, self-attention이 수정 없이도 적은 수의 token을 적응적으로 처리할 수 있어 가속화가 자동으로 이루어진다는 것이다.
3.2. Insights and Observations
Preserve pruned tokens within feature maps.
-
classification과 dense prediction tasks 간의 주요 차이점 중 하나는 pruned tokens을 어떻게 처리하느냐에 있다.
classification에서는 token pruning 방법이 종종 token을 영구적으로 제거한다.
왜냐하면 pruned token이 더 이상 결과에 영향을 미치지 않기 때문이다.
이는 classification이 항상 유지되는 class token에만 의존하기 때문이다. -
그러나 dense prediction tasks에서는 pruned token이 backbone에서 더 이상 update되지 않더라도 이후의 detection head에서 여전히 활용될 수 있다.
따라서 pruned token의 이미 계산된 features를 나중에 사용할 수 있도록 유지하는 것이 유리하다.
pruned token을 보존하지 않을 때는 남아있는 token을 원래 위치에 배치하고, pruned token은 zero-pad하여 dense feature map을 복원한다. [61]
반면, pruned token을 보존하는 경우에는 updated token을 대체하면서 pruned token을 그대로 유지하여 점진적으로 feature map을 구축한다.
삭제된 token을 보존하는 것은 제거하는 것만큼 빠르며(Table 2 참조), 다양한 model에서 dense tasks의 성능을 향상시킨다.
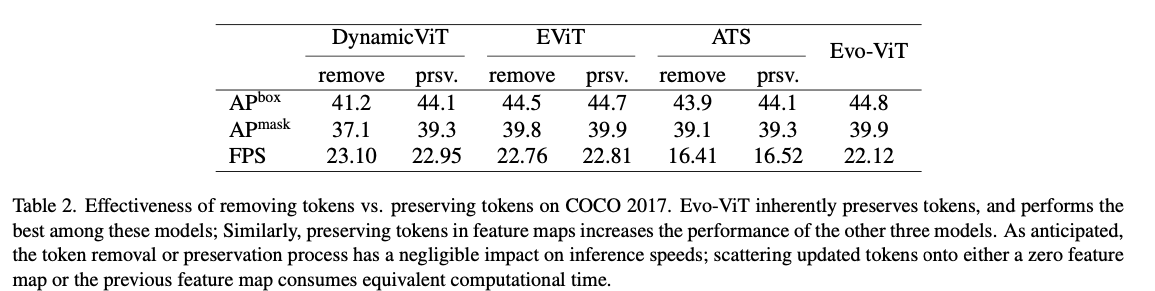
Reuse preserved tokens on demand.
-
pruned token이 feature maps에서 보존되면, 이를 다시 사용해야 하는지 자연스럽게 고려하게 된다.
이 논문에서 "token preserving"은 pruned tokens을 detection head만 사용하는 것을 의미하는 반면,
"token reactivation"은 이러한 token을 backbone의 이후 layer에서 다시 사용할 수 있도록 하는 것을 의미한다.
token reactivation에 대한 반론은 ViT가 가능한 한 많은 computing resource를 유용한 token에 우선적으로 할당해야 한다고 주장할 수 있다. [60]
따라서 pruned token을 reactive하는 것은 이 원칙을 악화시킬 수 있다. -
그러나 "informative"의 정의는 각 layer마다 다를 수 있다.
ViT는 각 layer에서 서로 다른 regions에 집중할 수 있기 때문이다. (see supplementary material)
따라서 pruend token을 reactive하는 기능은 ViT가 각 layer에서 서로 다른 region에 집중할 수 있게 하여,
model이 현재 필요한 token에 집중한 후, 다음 block에서 다시 관련된 token으로 돌아갈 수 있게 한다.
또한, 이는 잘못 pruned된 token이 다시 reactivating될 기회를 제공함으로써 token pruning을 더 견고하게 만든다.
이러한 이점은 동일한 block 당 token 사용량 내에서 token의 전체적인 활용을 더욱 효과적으로 만든다.
Section 4에서 우리는 model이 스스로 pruned tokens을 reuse할지 여부와 시기를 학습할 수 있도록 하고,
이 기능이 model의 accuracy를 box AP에서 0.4, mask AP에서 0.3만큼 향상시킬 수 있음을 보여준다.
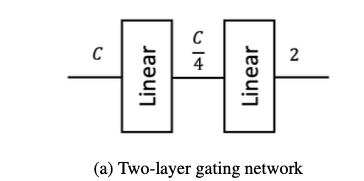
A 2-layer MLP can substitute complex gating networks for pruning tokens.
- 기존의 token pruning 방법들은 복잡한 gating network를 사용하여 pruning될 token을 예측하는 경향이 있다.
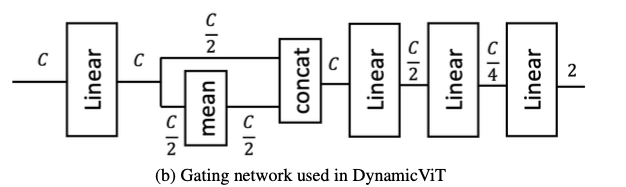
DynamicViT에서는 여러 개의 MLP가 mean and concatenation 연산과 함께 사용되어,
어떤 token을 pruning할지 결정하기 위해 token-specific and global information을 학습했다(Figure 3b).
- SPViT에서는 각 head에 대한 score weights를 계산하기 위해 추가의 head branch를 통합하는 더 복잡한 gating network를 도입했다.
그러나 Section 4.1에서, 우리의 연구는 Figure 3a에 제시된 간단한 2-layer MLP가 동일하게 잘 작동하며 architecture design을 단순화한다는 것을 보여준다.
A dynamic pruning rate is better than a fixed pruning rate.
- 여러 연구에서는 classification과 관련하여 dynamic pruning rates를 구현하여 inference 중 input image에 따라 가변적인 수의 token을 적응적으로 pruning했다.
우리는 object detection 및 instance segmentation의 맥락에서 그 효과를 추가로 검증하며, Section 4에서 최적의 성능을 달성하기 위한 주요 요소 중 하나임을 보여준다.
3.3. SViT: Selective Vision Transformer
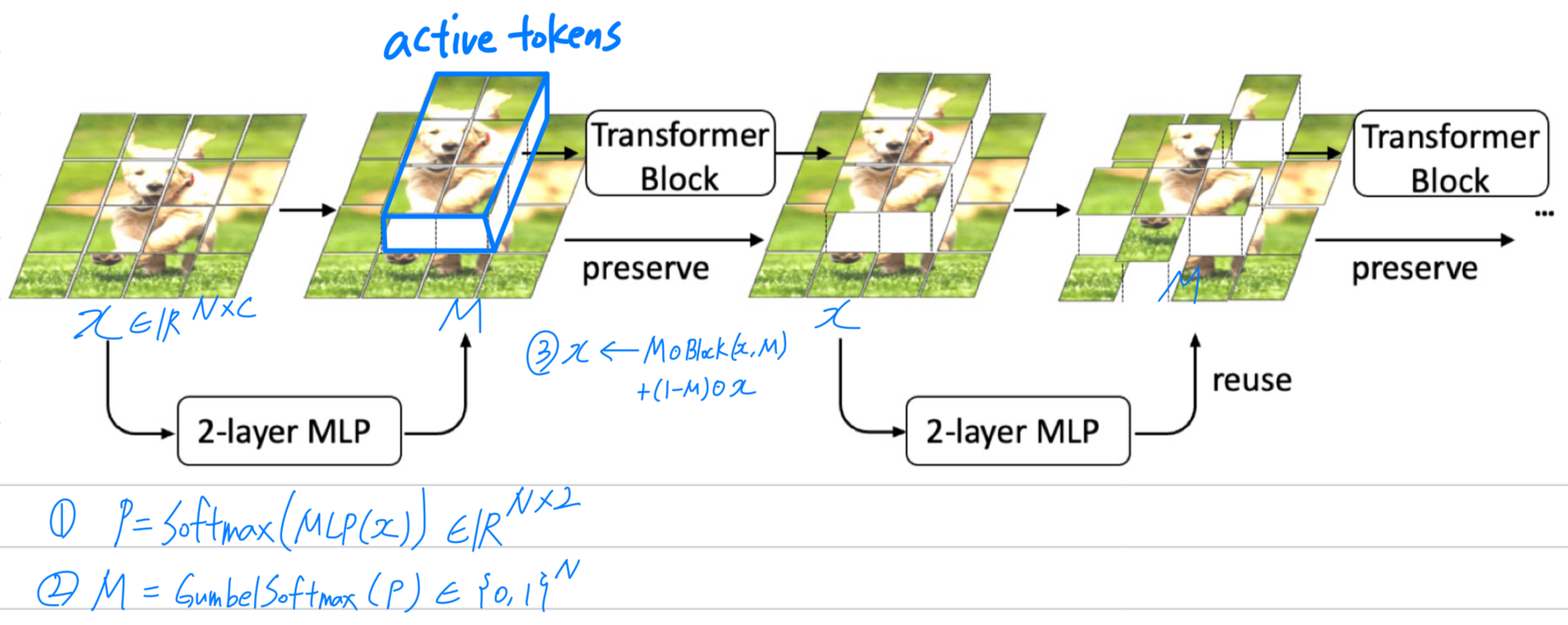
- 이러한 insights를 바탕으로, 우리는 기존의 모든 발견(all prior findings)을 통합한 간단하면서도 효과적인 token pruning model인 Selective Vision Transformer(SViT)를 소개한다.
SViT는 Figure 1에 묘사되어 있다.
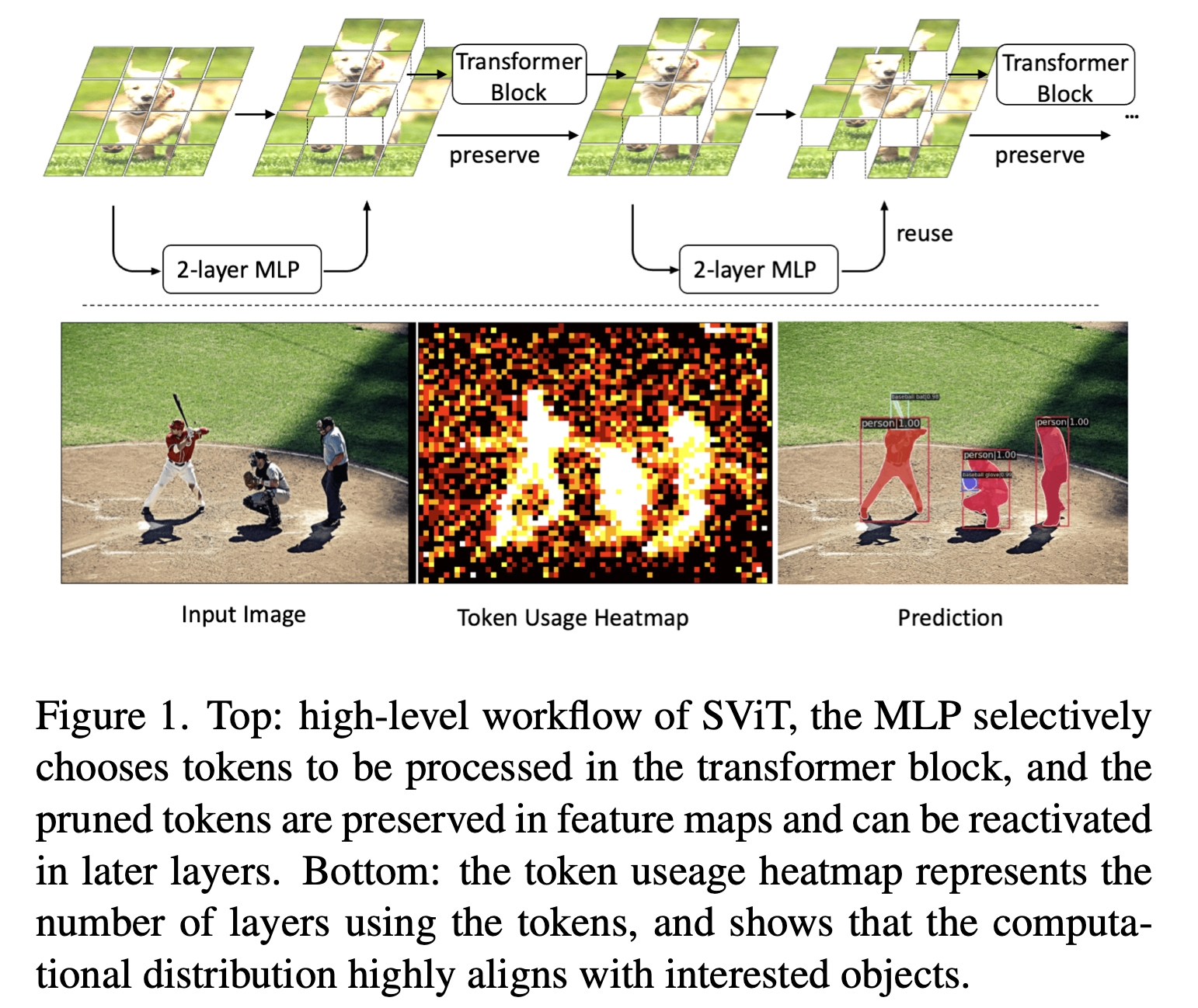 selection module로는 2-layer perceptron을 사용하며,
selection module로는 2-layer perceptron을 사용하며,
Gumbel Softmax를 통해 discrete decision을 differentiable하게 만든다. (Eq(1) 참조)
이 selection module을 전체 ViT block 앞에 배치함으로써, Transformer encoder의 self-attention과 MLP 모두에서 acceleration을 촉진할 수 있다.
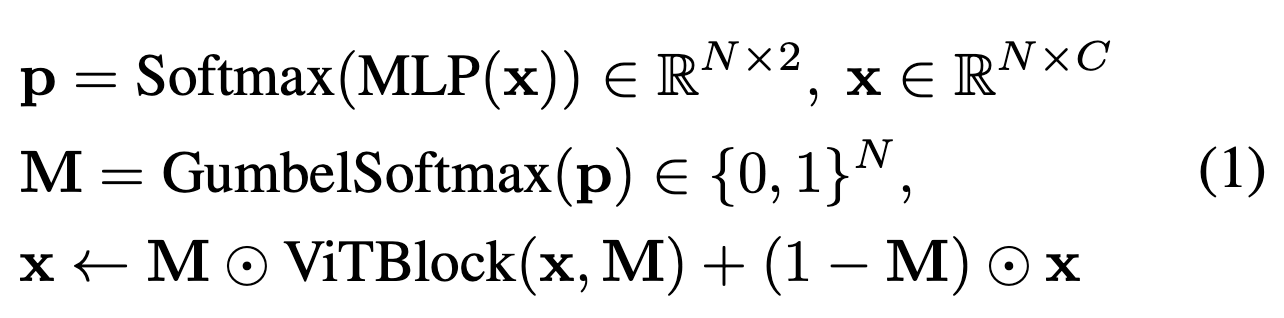 는 input tokens,
는 input tokens,
는 intermediate sampling probability,
은 token masks,
그리고 는 hadamard product를 의미한다.
(1-1) MLP는 token dimensions을 에서 로, 에서 2로 변환한다.
(1-2) ViT Block은 Masks 을 입력받아 training 중에 pruned tokens이 다른 tokens에 미치는 영향을 제거하기 위해
(1-3) attention matrix의 해당 columns을 0으로 설정한다.
inference시에는 단순히 active tokens을 모아 현재의 ViT Block에 입력한 후, 다시 이전 feature map으로 token을 scatter한다.(분산시킨다)
- pruned tokens의 수를 제어하기 위해,
[31]과 유사하게 training 중에 dynamic pruning ratio loss를 사용한다.(Eq (2)) :
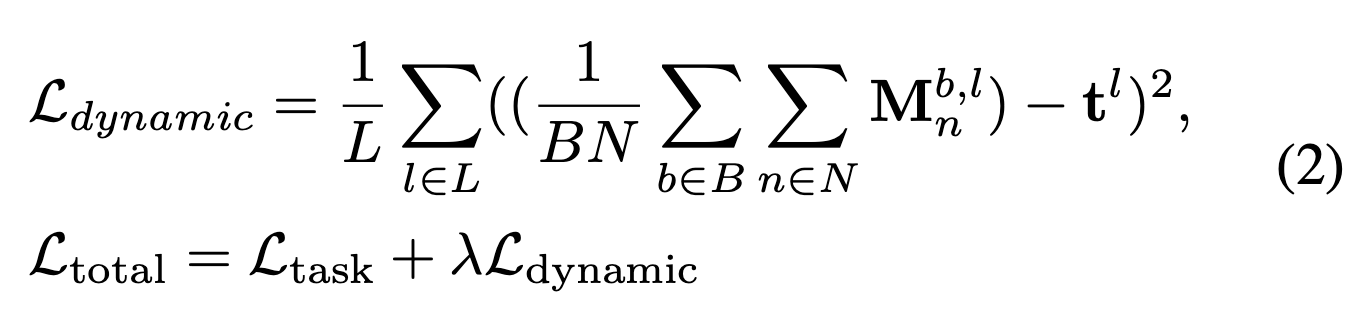 은 batch 와 layer 에서 -th token,
은 batch 와 layer 에서 -th token,
은 layer 의 target keeping ratio,
는 weight losses에 대한 hyper-parameter를 의미한다.
주목할 점은 이 모든 token뿐만 아니라 batch 내의 image 전체에서도 averaged된다는 것이다.
이는 token usage와 accuracy 사이의 trade-off를 인식하게 되어,
complex image에는 더 많은 token을 할당하고 simple image에는 더 적은 token을 할당하는 결과를 가져온다.
fixed pruning ratio loss와의 비교는 Section 4.1을 참조.
