BatchNorm vs. LayerNorm vs. RMSNorm
Zhu, Jiachen, et al. "Transformers without normalization." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
위 논문을 읽으면서, normalization layer에 대한 정리가 필요하다고 느껴 간단히 정리한 글
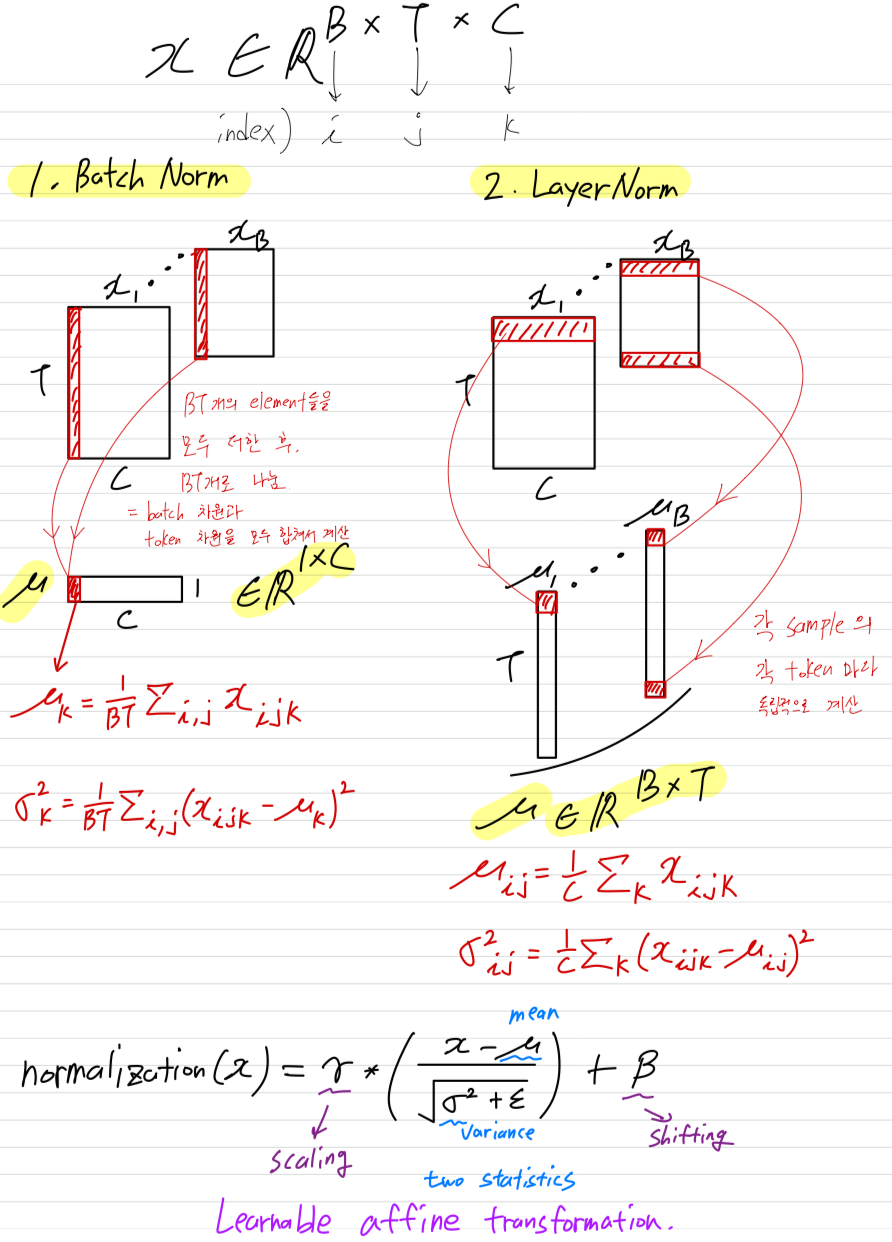
BatchNorm:- Batch normalization
- CNN에서 잘 사용되는 normLayer
- batch dimension과 token dimension에 대해 statistics(mean and variance)를 구함 (이게 무슨 말인지는 아래 그림에서)
LayerNorm:- Layer normalization
- Transformer에서 자주 사용되는 normLayer
- 각 sampmle에서 각 token에 대해 statistics(mean and variance)를 구함 (이게 무슨 말인지는 아래 그림에서)
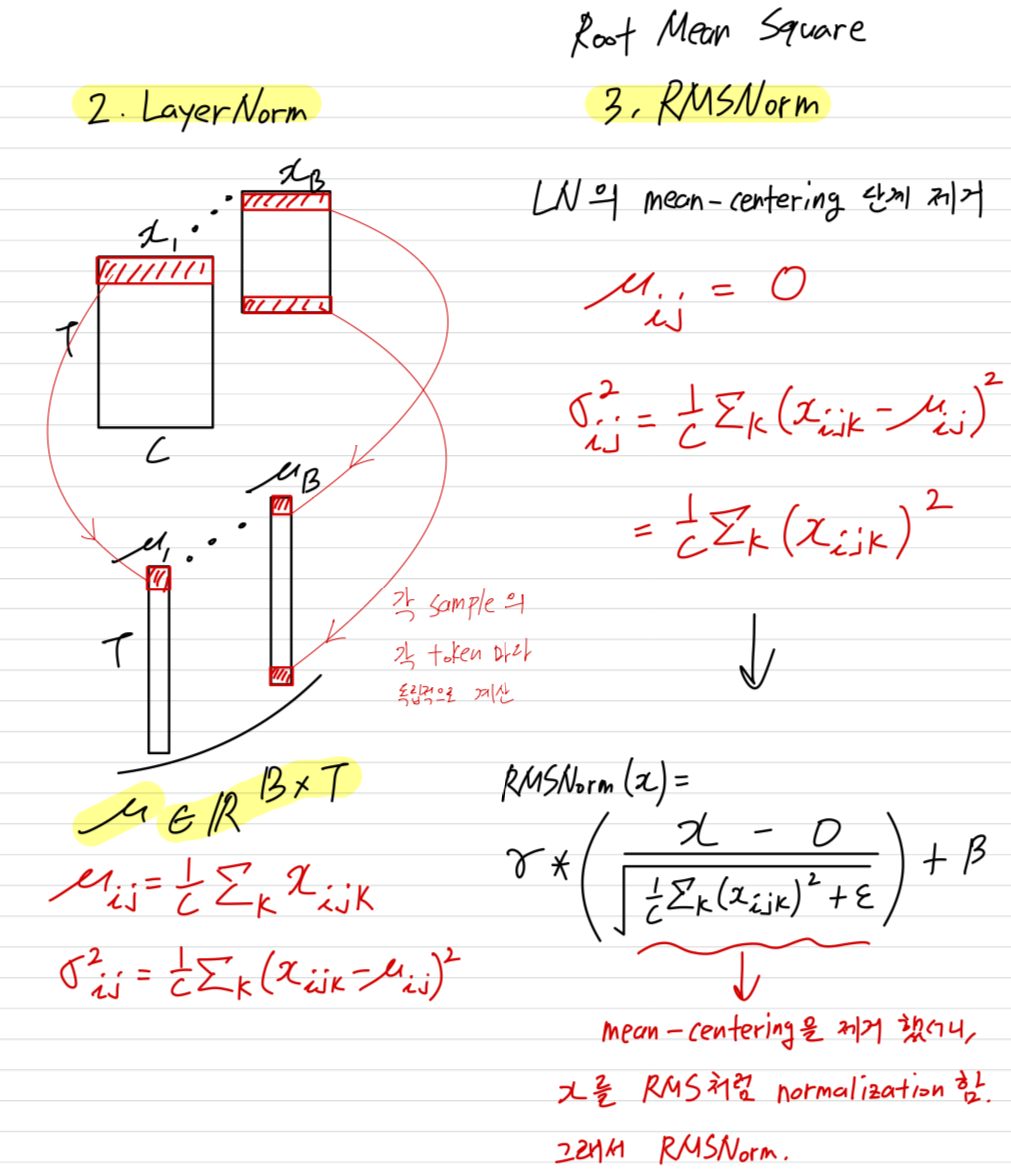
RMSNorm:- Root Mean Square Normalization
- Transformer에서 자주 사용되는 normLayer (최근에 특히, language model에서 인기가 많아지고 있음)
- LayerNorm에서 mean을 구하는 과정을 생략. 즉, mean-cetering step을 제거.
- 각 sampmle에서 각 token에 대해 statistics(mean and variance)를 구함 (이게 무슨 말인지는 아래 그림에서)
BN vs. LN
LN vs. RMSNorm
(질문) : Transformer에서 특히 RMSNorm이 많이 사용되고 있다고 했는데, 왜 Transformer에서만 특히 많이 사용될까?
(AI 답): Transformer는 residual connection이 많아서, mean-centering이 크게 중요하지 않다. 그래서 mean-centering을 빼도 충분히 안정적으로 학습될 뿐더러 더 단순하고 빠르다.

Efficient Deep Learning