[Simple Review] First-Generation Inference Accelerator Deployment at Facebook
Paper Info
- Anderson, Michael, et al. "First-generation inference accelerator deployment at facebook." arXiv preprint arXiv:2107.04140 (2021).
Abstract
-
많은 ML wordloads(작업)는 sparse memory accesses, large model size, high compute, memory and network bandwidth requirements 등과 같은 고유한 특성을 가지고 있다.
-
이러한 requirements들을 기반으로 high-performance, energy-efficient inference accelerator platform을 공동 설계했다.
이는 HW와(Open Compute Platform)와 SW framework 및 Tooling(PyTorch/cafe/Glow 등)을 포함한다.
이 ecosystem의 특징 중 하나는 다양한 vendor의 AI accelerators를 지원할 수 있도록
처음부터 개방성을 유지했다는 점이다.
이 platform은 6개의 저전력 accelerator cards와 single-socket host CPU를 통해
high complexity의 model을 효율적으로 실행할 수 있게 한다.
또한, 이 platform이 Facebook의 실제 트래픽을 처리할 수 있게 하는 다양한 성능 최적화 방법을 platform 및 accelerator 수준에서 설명한다. -
마지막으로
deployment challenges, 성능 최적화 과정에서 얻은 교훈, 그리고 향후 inference hardware co-design을 위한 guidance를 공유할 것이다.
1. Introduction
-
Fackebook의 ML model들은 data center에 점점 더 많은 부담이 되고 있으며,
이 Data center들은 주로 CPU 기반으로 운영되고 있다. -
2년 동안 ML inference를 위한 server의 수가 5~7배 증가했고,
앞으로도 유사한 속도로 증가할 것으로 예상된다.
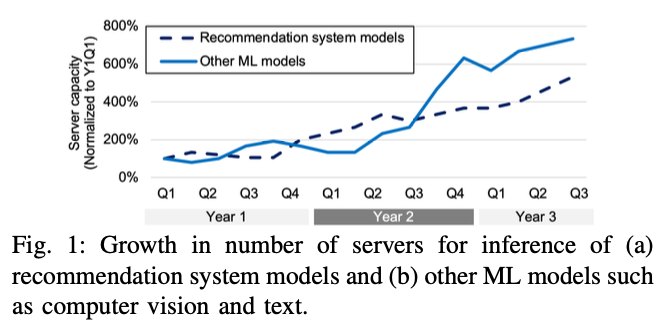
-
더불어 Model들은 FLOPs와 model size 측면에서 더욱 복잡해지고 있다.
이러한 복잡한 model을 CPU에서 추론하는 것은 latency budgets을 늘릴 수 있다.
따라서 Facebook은 Model의 latency 및 throughput 요구를 충족시키기 위해 inference accelerators를 배포하고 있다.
-
Facebook의 inference accelerator program을 위해서,
HW and SW platform이 모두 처음부터 개발되고 우리의 요구에 맞게 공동 설계될 수 있다.- system은 다양한 ML application을 대상으로 높은 성능/전력비를 달성할 수 있어야 함
- system은 성능을 희생하지 않고도 large recommendation system model을 지원할 수 있어야 함.
(이러한 Model들은 large memory와 fast lookup(빠른 조회)를 위한 high bandwidth가 필요함) - system은 빠르게 변화하는 ML framework(e.g. Caffe2에서 PyTorch로)와 다양한 공급업체의 inference accelerator 제품에 적용할 수 있어야 함.
-
이러한 문제(1., 2., 3.)를 해결하기 위해,
우리는 system의 HW와 SW를 co-design(공동 설계)했다.
우리는 고성능 TOPS/W를 가진 저전력 accelerator card를 기본 단위로 시작했다.
이 card는 workload에 따라 다양한 주파수에서 30-45 TOPS (int8) 또는 4-6 TFLOPS (FP16)의 최고 성능을 제공하며,
16GB의 LPDDR memory를 갖추로 13W만 소비한다.
memory capacity, memory bandwidth, 시스템의 계산 능력을 증가시키기 위해
우리는 PCIe 스위치를 통해 6개의 card를 연결했습니다.
이 6개의 card는 독립적인 요청을 처리하거나,
대안적으로 180-270 TOPS (int8) 또는 24-36 TFLOPS (FP16)의 최고 성능과
96GB의 LPDDR 메모리를 갖춘 대형 시스템으로 작동할 수 있으며,
PCIe 스위치를 포함하여 91W를 소비한다.
이 통합 시스템은 추천 시스템 워크로드를 처리하기에 충분한 크기이며,
추천 시스템에 특화된 맞춤형 다중 카드 분할 전략을 사용하면 된다.
전체 하드웨어의 최고 효율성은 2.0-3.0 TOPS/W이다.
-
우리는 처음부터 개방성을 중점으로 Facebook inference accelerator ecosystem을 구축하고 있다.
HW사양은 OCP(Open Compute Project)를 통해 제공되며, 다양한 AI accelerator를 지원하는 데 중점을 두고 있다.
PyTorch, Caffe2 등의 Framework와 Glow, onnxifi 등의 AI accelerator 도구는 open source SW로 제공되며,
이미 여러 execution platform과 accelerator를 지원하고 있다.
이러한 opnness(개방성)을 중점으로 하는 것은 Facebook과 AI community 모두에게 이익을 주며,
HW accelerator에서 AI compilation, model definition에 이르기까지 innovation을 위한 공통 ecosystem을 창출하여
AI accelerator에서 SOTA 기술을 발전시키고, higher quality의 larger model을 만들어 결과의 질적 향상을 도모한다. -
high performance를 위한 SW를 공동 설계하기 위해, 다양한 optimizations을 수행했다.
model level:
연산을 위한 quantization과 data-type 변경,
inference cards에서의 Expensive ops를 피하기 위한 co-designcard-level:
graph level optimization(card 간 model partitioning, resource allocation, parallelization across cores and placement of ops to cores, batching to improve the performance of individual operators)op-level:
개별 operator들의 성능을 향상시키기 위한 optimization을 수행.system-level:
accelerator로의 communication을 최소화하고,
host CPU utilization을 개선하며 PCIe traffic optimizatoins을 포함한 변경 사항을 적용.
- 그 결과,
우리는 applicatoin의 latency requirements를 충족하면서도
accelerator에서 복잡한 model을 제공할 수 있게 되었다.- recommendation system의 경우,
현재 Model보다 GLOPS측면에서 5배 더 복잡하고 parameter가 2배 더 많은 model을 제공할 수 있음 - computervision model에서도 효율적으로 처리
- NLP의 경우, 복잡한 XLM-R variant model은 현재 model보다 GFLOPS 측면에서 6배 더 많은 연산을 필요로 하지만,
accelerator에서 지연 시간 요구 사항을 충족함
- recommendation system의 경우,
- 이 논문의 구성은 다음과 같다.
- Section 2 : facebook의 inference workloads에 대한 설명
- Section 3 : system과 개별 card 수준에서 개발한 HW system을 설명
- Section 4 : SW 설계를 설명
- Section 5 : quantization and numerics(수치 연산)을 포함한 성능 고려사항을 살펴봄
- Section 6 : model, card 및 system 수준에서의 Optimization을 다룸
- Section 7 : optimized system에서 복잡한 model을 실행한 성능 결과를 보여줌
- Section 8 : 미래의 AI task 부하에 맞게 inference HW 설계가 어떻게 조정되어야 하는지에 대한 insight를 공유
- Section 9 : 관련 연구
- Section 10 : 결론
Section 2. Inference Workloads at Facebook
- 우리가 실행하고 있는 workloads는 네 가지로 분류됨
- personalized recommendation models based on prior user interactions
- computer vision models for image classification and object detection
- language understand models that feed into applications such as integrity use-cases
- video understanding models
- computational 관점에서,
위 model들의 전반적인 특징은 Table 1에 분석하여 list했다.
 workload의 넓은 범주는 이전 연구에서 설명된 이후로 변하지 않았지만, model의 구체적인 사항은 변화했다.
workload의 넓은 범주는 이전 연구에서 설명된 이후로 변하지 않았지만, model의 구체적인 사항은 변화했다.-
Recommendation system의 Latency 시간 요구 사항은 이전 연구에서 batch 당 요구 사항을 보고했기 때문에 크게 변하지 않았다.
-
전반적인 embedding table 크기는 3년의 기간 동안 수십억 개에서 수백억 개의 parameter로 증가했다.
NLP model의 latency 시간은 nearline processing로 인해 latency 요구 사항이 완화되었고, model architecture는 GRU/LSTM에서 Transformer로 변경되었다.이후 section에서 이러한 model에 대한 자세한 설명이 제공될 것임
-
A. Recommendation System Workloads
(skip)
B. CV WOrkloads
Use cases
-
computer vision model은 image classification과 object detection task를 위해
depp learning을 사용한다. -
image classification은 ResNeXt와 최근에는 더 복잡한 RegNet model을 사용하며,
특히 RegNetY Model은 훨씬 많은 parameter와 computation을 필요로 하여
accelerator가 없이는 latency constraint로 인해 service될 수 없다. -
object detection은 최근 FBnetv3 architecture를 사용하여
channelwise conv layer와 regular conv layer를 혼합한 연산으로 Region을 proposal하고 classification을 수행한다.
Characteristics and impact on accelerator design
-
이 model들은 computation 측면에서 상당히 무겁다.
주로 높은 arithmetic intensity를 가진 convolution으로 구성되지만,
groupwise/channelwise convolution도 포함되어 있어 arithmetic intensity가 줄어들 수 있다. -
RegNetY model은 다른 model들에 비해 훨씬 크다.
quantized된 형태에서도 약 1GB에 이르는 RegNetY는 on-chip memory에 적합하지 않으며,
따라서 memory bandwidth performance에 더욱 민감하다.
C. NLP Workloads
Use cases
- NLP model은 transformer based model로 전환되어 SOTA accuracy를 달성하고 있다.
우리는 cross-language를 지원하는 XLM-R model을 사용하며,
이는 수 TB의 data를 학습하고 다양한 NLP task에 활용된다.
XLM-R model은 24개의 layer와 558M개의 parameter로 이루어져 있다.
Characteristics and impact on accelerator design
-
transformer based NLP model들은 matrix multiply 계산에서 많은 시간을 할애하며,
AI accelerators에 적합하지만 memory bandwidth의 제약을 받는다. -
sequence length 또는 문장의 token 개수는 application에 따라 다양하며,
static shapes of inputs을 요구하는 accelerator는 input을 padding하고 다양한 크기의 network를 compile해야 한다. -
model이 점점 더 커지고 복잡해지면서,
현재 사용 중인 XLM-R model조차 on-chip memory에 적합하지 않다.
더 큰 NLP model을 deploy에 있어 주요 장애물은 계산 비용이며,
고성능 inference accelerator를 사용해야 적절한 latency와 cost를 달성할 수 있다.
이러한 큰 model들을 single machine의 여러 accelerator cards 또는 여러 machine에 분산시켜야 할 필요가 있다.
D. Video Workloads
(skip)
3. Hwardware Design
-
우리의 inference workloads의 독특한 요구 사항으로 인해
efficiency를 극대화하기 위해 system을 공동 설계하게 되었다. -
이에 따라 여러 inference accelerator cards를 포함한 host CPU로 구성된 자체 system을 설계했다.
이 system 및 구성 요소의 사양한 Open Compute Platform에 공개되어있다.
platform과 accelerator card design에 대해 아래에서 설명한다.
A. System Design
-
system의 componenets에 대해서 설명하겠습니다.
6개의 M.2 accelerator와 host CPU로 구성됨.
host CPU는 64GB RAM의 Intel Xeon D.
이 Node들은 2개의 set로 구성되어 Yosemite v2 sled에 설치되며,
multi host NIC를 통해 TOR switch에 연결된다.
전체적인 co-design 목표인 high perf/W을 달성하기 위해 system이 설계되었다. -
각 M.2 module은 약 13W의 전력을 소비하고, host CPU의 전력을 6개의 card로 분산된다.
큰 추천 및 NLP model을 위한 충분한 memory bandwidth를 제공하기 위해 충분한 card LPDDR memory 용량을 제공한다.
각 card는 16GB의 LPDDLR memory를 제공하며, Host의 64GB와 함께 6개의 card는 대부분의 model을 처리하는 데 충분할 것으로 예상한다. -
각 card와 Host memory는 model 실행 시 host 및 accelerator 사이에서 net를 분할하여 동시에 사용할 수 있다.
이러한 multi-card ssetup으로 인해 card 간 model weight를 분산할 수 있으며,
효율성을 위해 single card에 맞는 model에도 local memory에 맞출 수 있다. -
Card들은 PCIe switch를 통해 서로 연결되며,
이는 Host와 x16 PCIe lane을 통해 연결된다.
PCIe switch는 13W를 소비한다.
각 card는 x4 PCIe connection을 갖고 있으며, PCIe switch를 통해 host를 거치지 않고 card 간 통신이 가능하다.
즉, 다른 Inference에서 생성된 Tensor를 참조하는 경우 accelerator card 간의 data 전송이 조정된다.
이로 인해 모든 card가 동시에 통신할 때 x16 link 및 host memory bandwidth의 bottleneck을 피할 수 있다.
이는 대부분의 사용 사례에 대해 PCIe bandwidth가 bottleneck이 되지 않도록 충분한 bandwidth를 제공한다.
또한 data ingestion(흡수)에서 발생할 수 있는 잠재적인 NIC bottleneck을 피하기 위해 system은 node 당 upgrade된 50 Gbps bandwidth로 구성되어 있다.
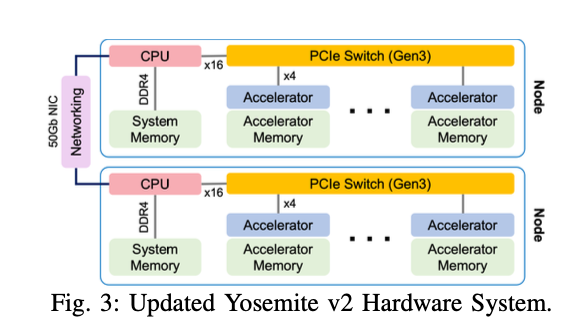
B. Accelerator Card
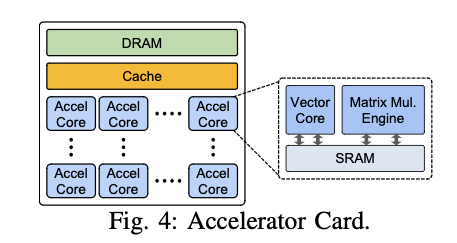
- Accelerator card는 최대 30~45 TOPS(int8) 또는 4-6 TFLOPS(FP16)의 성능을 가지고 있다.
card에는 각 accel core 안에 local SRAM memory와 공유 Cache가 있으며,
Network의 weight와 activation을 저장하는 데 사용될 수 있다.
system의 밀접한 상호 연결성은 우리가 model weight를 Card 간에 분할하여 모든 card의 LPDDR 및 SRAM을 활용할 수 있는 밀접한 solution을 가능하게 한다.
4. Software Design
-
우리는 accelerator system에서 대상 application을 효율적으로 실행하기 위해 SW system을 설계했다.
이를 위해 몇 가지 고려 사항을 갖고 flexible을 보장하고, 개발자에게 tranparent(투명성)을 제공하며, programmable system을 만들어야 했다. -
일반적으로 AI ASIC 업체에서 제안하는 SW stack(Tensorflow or PyTorch)은 flexibility를 제공하지만 대규모 배포에 필요한 transparency(투명성)과 programmability를 제공하지 못하는 문제가 있다.
-
우리는 이를 개선하기 위해 Glow compiler를 사용하여 intermediate representation을 최적화하고,
Glow runtime을 사용하여 장치에서 실행을 관리했다.
이를 통해 우리는 투명성을 향상시키고, 개별 HW backend에 종속된 최적화를 여러 backend에 재사용할 수 있었습니다.
Glow는 float16 및 bfloat16을 포함한 여러 data type을 제공한다.
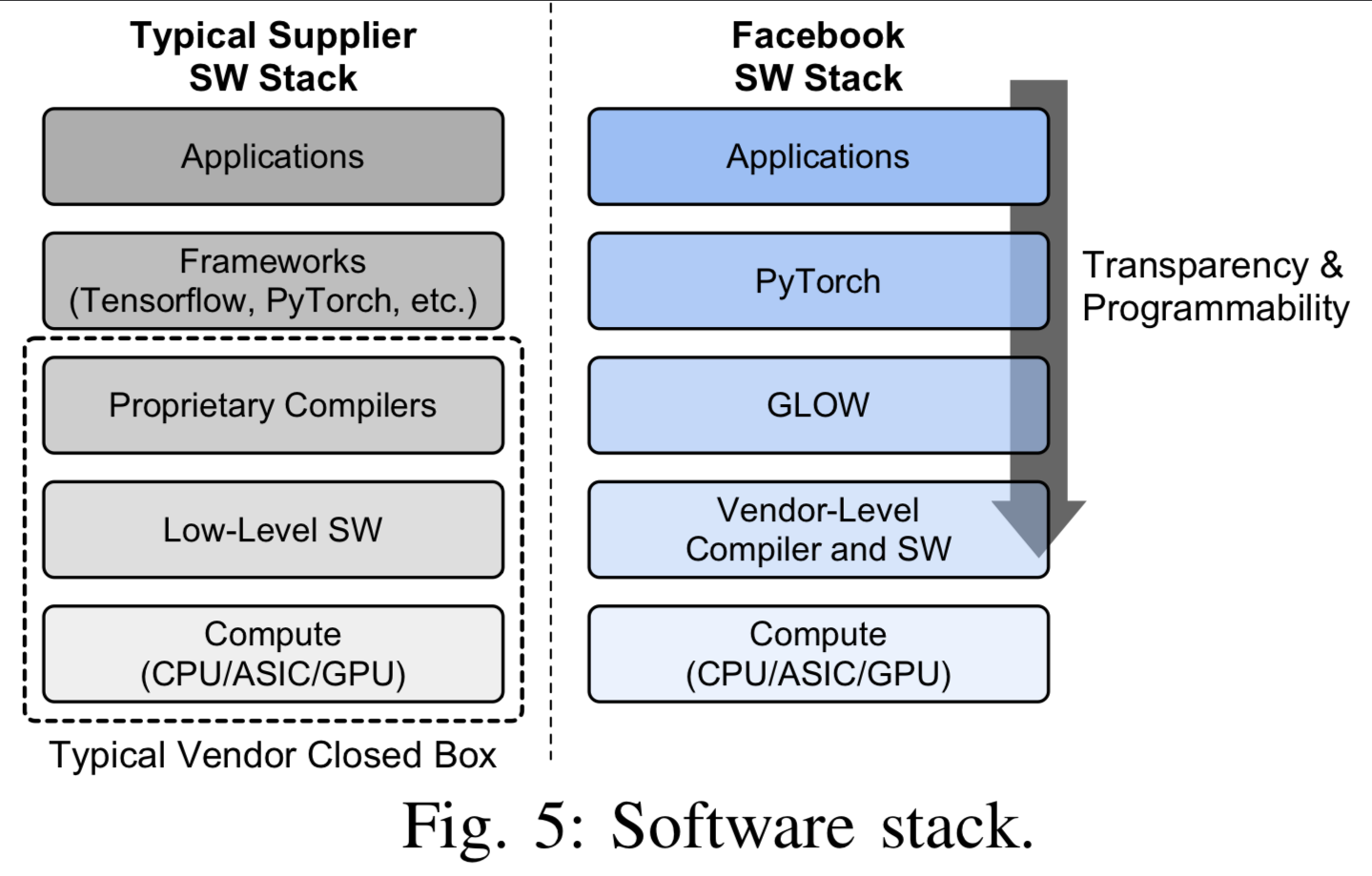
A. Application Level
- 추천 시스템 model은 현재 Caffe2로 구현되어 있고,
contents understanding model은 PyTorch로 구현되어 있다.
runtime에서는 이전에 Compile된 network를 사용하여 요청에 응답하고 추론을 실행하는 서비스를 구현하는 사용자 정의 binary file이 있다.
B. AI Framework Level
-
Caffe2와 PyTorch는 Glow를 통해 accelerator로의 computation graph를 특수화하는 Mechanism을 갖고 있다.
Caffe2의 경우, 이 절차를 Onnxifi라고 하며,
가속화된 부분은 ONNX 형식으로 컴파일되어 Glow에서 런타임에 하나의 대규모 연산으로 실행된다.
PyTorch의 경우에는 특정 모듈을 Glow를 통해 가속기로 특수화하고,
이러한 모듈을 런타임에서 가속기에서 실행할 로직으로 대체할 수 있는 to_backend 인터페이스를 사용한다. -
일부 경우에는 CV Detection model이나 NLP app과 같이 특정 연산자가 가속기에서 지원되지 않거나 성능이 좋지 않은 경우가 있다.
이러한 경우에는 이러한 연산을 가속기로 특수화하지 않고 호스트 CPU에서 실행한다. -
accelerator와 Glow는 compile 시에 shape information을 필요로 하기 때문에,
이러한 특수화 단계에서 shape inference를 수행한다.
또한, model 자체의 일부로 shape information을 사용하는 PyTorch model을 수용하기 위해,
예를 들어 unsample output shape을 계산하는 경우와 같이 이러한 값을 compile된 Network에 대해 상수로 취급하고 최종 accelerator network를 compile하기 전에 이러한 값에 대한 계산을 propagate한다.
runtime에서 shape이 변하는 경우에는 여러 Compile된 Network 사이를 전환하거나 compile 시에 상한 값을 설정하고 필요한 경우 input tensor를 Padding하는 전략을 사용.
C. Glow Level
모르는 용어
-
TOPS/W?
1Watt 전력 소모당 AI 산술연산 횟수를 의미- TOPS : Trillion Operations Per Second
- W : Watt
-
accelerator card?
GPU, FPGA와 같이 특정 작업(ML)을 위해서 컴퓨팅 성능을 향상시키기 위해 설계된 HW device. -
LPDDR memory?
Low Power Double Data Rate.
메모리는 저전력 소모를 특징으로 하는 메모리 유형으로, 주로 모바일 장치 및 임베디드 시스템에서 사용.
LPDDR 메모리는 전통적인 DDR 메모리에 비해 전력 소비가 적고, 효율적인 데이터 처리를 위해 설계되었다. -
PCIe switch?
PCIe(Peripheral Component Interconnect Express) Switch는 PCIe 장치들 간의 통신을 관리하고 조정하는 HW 장치.
PCIe는 고속 직렬 컴퓨터 확장 버스로, CPU와 고속 장치(GPU, 네트워크 카드, SSD 등) 간의 데이터 전송 속도를 최적화.
PCIe 스위치는 여러 개의 PCIe 장치를 마더보드의 하나의 PCIe 슬롯에 연결하여 동시에 사용할 수 있도록 도와줌.
이를 통해 시스템의 확장성을 높이고,
여러 장치 간의 고속 데이터 전송을 효율적으로 관리할 수 있다.
특히 데이터 센터와 같은 고성능 컴퓨팅 환경에서 많은 PCIe 장치를 효율적으로 활용하기 위해 PCIe 스위치가 자주 사용된다.
Critique
-
요약
이 논문은 facebook의 ML workloads(추천 시스템, CV, NLP, video)는 sparse한 memory 접근, 대규모 model size, high computation 및 memory bandwidth 요구 등의 특징을 갖고 있습니다. 이러한 요구 사항들을 위한 고성능 및 에너지 효율적인 inference accelerator platform을 공동 설계하였습니다. -
비평
-
강점 :
기술의 발전으로 점차 model의 크기가 커지고 있는 시점에서 페이스북의 실제 ML Workloads에도 부하가 늘어나고 있는 것은 사실입니다. 페이스북은 이에 대응하여 발빠르게 자신들의 HW & SW를 강화하고 생태계를 구축하고 있다는 점에서 좋은 접근을 했다고 생각합니다. -
약점 :
논문은 주로 페이스북 내부에서의 workloads 경험에 초점을 맞추고 있기 때문에, 다른 기업이나 산업에서의 적용 가능성, 확장성에 대한 부분이 부족할 수 있을 것이라 생각합니다.
-
