[2017 CVPR] Hard Mixtures of Experts for Large Scale Weakly Supervised Vision
Paper Info
CVPR 2017

Abstract
- 이 연구에서 a simple hard MoEs model을 사용하여 large scale hashtag (multilabel) prediction tasks에서 효율적으로 train될 수 있음을 보여준다.
MoE models은 새로운 개념이 아니지만, 과거에는 data fragmentation(분할) 문제를 해결하기 위해 연구자들이 sophisticated(복잡한) methods를 고안해야 했다.
- 우리는 현대의 weakly supervised data sets이 충분히 커서
data point를 single expert에게 할당하는 단순한 partitioning scheme을 지원할 수 있음을 실험적으로 증명했다.
왜냐하면 Experts들은 독립적이기 때문에 parallel하게 training시키는게 쉽고, model size에 비해 evaluation이 cheap하다.
또한, 모든 experts에 대해 single decoding layer를 사용할 수 있어 unified feature embedding spcae를 제공할 수 있음을 보여준다.
이를 통해 standard CNN architectures로는 현실적으로 train하기 어려운 훨씬 더 큰 models을 train하는 것이 가능하며,
이러한 extra capacity가 현재의 datasets에서도 잘 활용될 수 있음을 입증했다.
1. Introduction
-
Large annotated image datasets은 CV에서 혁명을 이끌어 왔다.
하지만 hand annotation은 laborious(노동 집약적)이다.
매일 web과 social media에 게시되는 수벡민 장의 image와 비교했을 때 ImageNet dataset은 너무 작다.
그래서 최근에는 hand-annotated data 대신 weakly supervised data를 사용해 vision model을 구축할 수 있음을 보여줬으며,
이를 통해 진정으로 gigantic(거대) datsets의 가능성이 열리게 되었다. -
data 규모가 커짐에 따라, model 역시 확장할 수 있고 더 나은 features를 얻을 수 있을 것으로 기대할 수 있다.
하지만 심지어 최근의 SOTA CNN models도 현재의 weakly supervised data의 크기를 수용할 수 없다.
현재의 optimization technology와 HW를 사용하더라고, 사진 공유 사이트에서 하루 동안 게시되는 image의 양은 SOTA CNN architectures의 training pipeline을 통해 처리할 수 있는 양을 훨씬 초과한다.
게다가 여러 연구에서 제시된 증거에 따르면, 이러한 구조는 이미 수백만 장의 image로 구성된 dataset에서도 underfitting되고 있다. -
model을 단순하게 확장하는 방법으로 잘 알려진 approach는 "mixture" architectures를 사용하는 것이다.
여기서 하나의 model은 "gater" 역할을 하며, data를 특정 "expert" classifiers로 routing하여 final decision을 update한다.
본 연구에서는 two contributions을 제시한다.- trained CNN의 feature space에 각 expert가 하나의 cluster와 연관되는 매우 간단한 mixture architecture를 제안한다.
이때 CNN은 gater 역할을 수행한다.
또한 모든 experts가 동일한 decoder를 공유하여 expert의 feature space가 transfer tasks에서도 의미를 가질 수 있도록 하는 variant도 설명한다. - large datasets을 이용하여 weakly supervised tag prediction 환경에서, 기존의 CNN model이 underfitting되고 있음을 증명했다.
반면, 우리 approach의 simplicity에도 불구하고, 이 환경에서 훨씬 더 powerful models을 효율적으로 training할 수 있게 함으로써 test accuracy를 상당히 개선할 수 있음을 보였다.
- trained CNN의 feature space에 각 expert가 하나의 cluster와 연관되는 매우 간단한 mixture architecture를 제안한다.
2. Models
-
target outputs을 갖는
labeled training set of images를 라고 denote -
[7] MoEs model의 basic idea는
a set of expert classifiers 와, a gating classifier 가 있음
model을 evaluate하기 위해서, input 는 에 의해 processed되어지고,
coordinates를 갖는 a probability vector 를 outputting함.
그러면 model의 output은 다음과 같음.
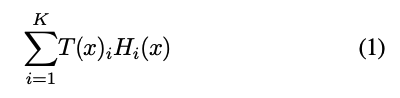 여기서, 와 는 convolutional networks.
여기서, 와 는 convolutional networks.
게다가, 우리는 각 에 대해 는 one coordinate(단일 좌표)에서만 nonzero인 simple situation을 고려할 것임.
우리의 model은 experts distirbution 대신 a single expert distribution을 선택하므로, 우리의 models은 "hard" mixtures로 분류된다. -
이 연구에서, 우리는 our models을 end to end로 train하지 않을 것이다.
즉, 우리는 final classification loss를 최소화하기 위해 를 experts에게 할당하는 를 직접적으로 optimize하려고 시도하지 않는다.
대신, 를 다음과 같은 방식으로 구성한다:
먼저, 로부터 를 만들기 위해 개 layers를 갖는 standard supervised CNN 를 학습시킨다.
의 optimization이 만족되었다면, , 즉 를 decoder 바로 이전의 의 마지막 hidden layer의 output으로 설정한다.
그리고 우리는 에 대한 K-means clsutering을 수행하여, cluster centers 를 얻는다.
이로부터 를 다음과 같이 정의한다:
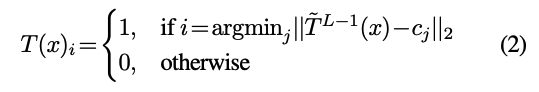
-
따라서, 우리의 model은 "local" architecture이다.
이는 이 정의하고 있는 feature space 내의 location이 expert classifier를 선택하는 방식으로 대응함을 의미한다.
각 cluster에 속하는 image의 수를 균등하게 맞추려고 시도하지는 않는다.
- 를 구성한 후, 즉 input 에 대해 expert 를 출력하는 가 정의된 후, model의 나머지를 구성하는 두 가지 방법을 사용할 수 있다.
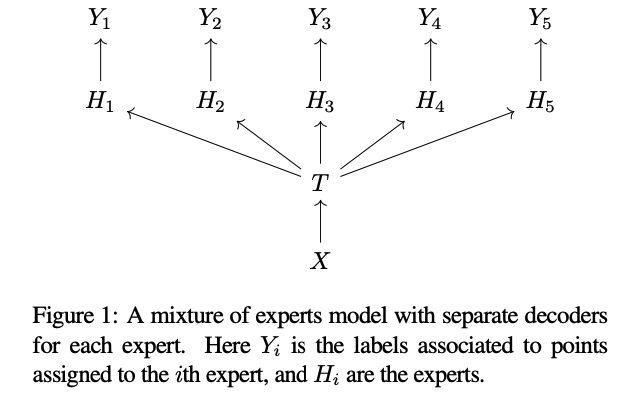
가장 간단한 version에서는 각 가 에 대한 distribution을 출력하여, Figure 1과 같은 model이 생성된다.
이 경우, 각 를 자신의 training data를 독립적으로 최적화할 수 있다.
이 model은 test시 label 를 예측하는 것이 유일한 목표라면 유용하다.
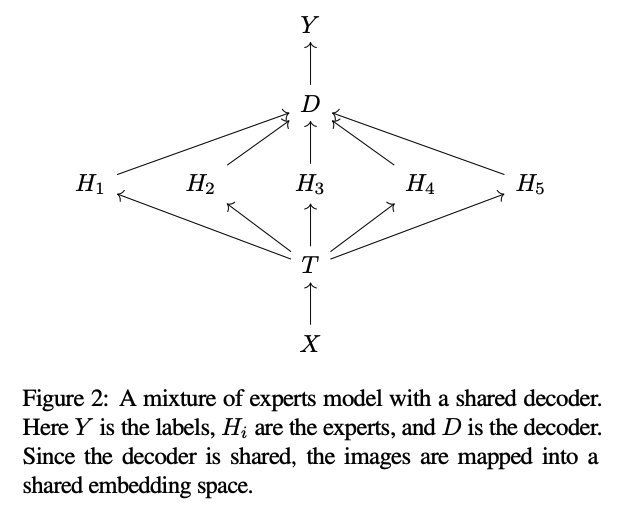
 그러나 model을 학습하는 주된 이유가 label prediction보다는, decoder 이전 마지막 layer의 feature를 얻는 데 있다면,
그러나 model을 학습하는 주된 이유가 label prediction보다는, decoder 이전 마지막 layer의 feature를 얻는 데 있다면,
각 를 독립적으로 유지하되, label에 대한 probabilities 대신 feature vector를 출력하도록 한다.
그런 다음, model에 a shared decoder 를 추가한다(Figure 2).
두 model 모두에서 각 expert의 output은 전체 가능한 labels의 set에 대한 distribution이다.
shared decoder를 사용하는 model을 학습하는 것은 independent decoders를 사용하는 model보다 복잡하지만,
class 수가 많을 경우 에서 로의 gradient가 상대적으로 sparse하다.
이 환경에서는 를 보유하는 하나의 machine과 를 보유하는 machine 각각을 사용한다.
2.1. Advantages and liabilities of hard mixtures of experts versus standard CNN’s
-
위에서 제안된 model은 배 많은 feature map을 가진 standard CNN에 비해 중요한 scalability advantages를 갖고 있다.
이러한 model은 train and test 시 parameter 당 실행 시간(wall clock time) 측면에서 효율적이다.
각 가 독립적으로 학습되므로 parallelize가 더 용이하다.
또한, 의 개수와 무관하게, input 로부터 output을 찾는 평가 시간 비용은 를 계산하는 비용과 단일 에 대해 를 계산하는 비용의 합이다.
반면, 배 많은 feature map을 가진 large CNN의 경우, 단순한 forward pass는 배의 비용이 들 수 있다. -
한편, 여기서 설명된 model은 parameter 당 modeling 능력과 data 사용 측면에서 standard CNN에 비해 비효율적이다.
각 는 다른 와 독립적으로 작동하기 때문에, 의 parameter는 의 parameter와 상호작용하지 않는다.
이는 모든 parameter가 서로 상호작용할 수 있는 standard CNN과는 대조적이다.
게다가, training data가 expert들 사이에 분리되므로 각 parameter는 학습 중 전체 data의 일부만 보게 된다.
2.2. Advantages and liabilities of no end-to-end training
-
end-to-end training은 더 정확한 model을 이끌어낼 수 있으며, test시 이러한 system들은 이 논문에서 제시된 system만큼 효율적으로 만들 수 있다.
그러나 이 논문에서 논의된 scale에서는, mixture model의 end to end training은 여전히 뛰어난 engineering 기술을 요하며,
이를 실현하기 위한 cmoputing infra는 아직 널리 보급되지 않았다. -
반면, 이 논문에서 설명된 기법들은 간단하며, expert가 독립적으로 학습하기 때문에 GPU를 보유한 any lab에서도 사용할 수 있다.
expert들은 trunk보다 훨씬 빠르게 학습되므로, 총 소요 시간은 serial로 학습하더라도 trunk를 학습하는 시간의 몇 배의 불과하다.
요약 & 비평
-
이 논문은 large weakly supervised data sets에 대해 효율적인 학습을 위한 hard MoE model을 제안.
그래서 실험에서는 ImageNet dataset에서는 MoE model이 baseline model보다 개선되지 않음을 보여주며,
large dataset에 특화된 model architecture의 필요성을 강조. -
router T를 공동으로 training시키는 end to end training을 하지 않기 때문에, model 성능을 제한할 수도 있을 것 같음...
