KD-DETR: Knowledge Distillation for Detection Transformer with Consistent Distillation Points Sampling

Abstract
-
DETR는 규모를 확장할 때 기존 감지기를 크게 능가하는 혁신적인 end-to-end transformer architecture object detector이다.
이 논문에서는 knowledge distillation을 통해 DETR compression에 초점을 맞추고 있다.
기존 detector에서는 knowledge distillation이 잘 연구되어 있지만,
DETR에서 효과적으로 작동하게 만드는 방법에 대한 연구는 아직 부족하다. -
우리는 먼저 실험적 및 이론적 분석을 통해 DETR distillation의 주요 과제가
the lack of consistent distillation points라는 점을 지적한다.
Distillation points는 student가 모방해야 할 predictions의 corresponding inputs을 말하며,
CNN detector와 DETR에서는 그 공식이 다르고, 신뢰할 수 있는 distillation을 위해서는 teacher와 student 사이에서 일관된 충분한 distillation points가 필요하다.
-
이러한 관찰에 기반하여,
우리는 homogeneous and heterogeneous distillation 모두를 위해
일관된 distillation points sampling을 사용하는 DETR을 위한
first general knowledge distillation paradigm(KD-DETR)을 제안한다. -
구체적으로,
우리는 DETR을 위한 distillation points를 구성하기 위해
a set of specialized object queries를 도입함으로써
detection task와 distillation task를 분리했다.
또한 KD-DETR의 extensibility(확장 가능성)을 탐색하기 위해
general-to-specific distillation points sampling strategy를 제안한다. -
광범위한 실험을 통해 KD-DETR의 효과와 일반화 능력을 검증했다.
single-scale DAB-DETR and multi-scale Deformable DETR and DINO 모두에서,
KD-DETR은 student model의 성능을 2.6%에서 5.2%까지 향상시켰다. -
우리는 또한 KD-DETR을 heterogeneous distillation으로 확장하여
DINO에서 Faster R-CNN with ResNet-50으로 KD한 결과, 2.1%의 성능 향상을 달성했으며,
이는 homogeneous distillation methods과 비교했을 때 경쟁력있는 결과이다.
1. Introduction
-
지난 몇년간, [2]는 Detection Transformer(DETR)이라는 혁신적인 end-to-end 를 제안하여,
hand-crafted anchors and NMS의 필요성을 없앴다.
[43][14][19][41]은 DETR의 scalability and potential에 대한 놀라운 발전을 이뤄내어, classic detector들을 크게 능가하였다. -
classic detectors들과 달리,
DETR은 object detection을 bipartite matching을 사용하는 end-t-end set
prediction problem으로 해석한다.
A set of learnable object queries를 도입하여 각 query는 특정 instance를 담당한다.
object queries는 encoder에서 추출한 feature와 상호작용하여
box location and categoreis에 대한 final predictions을 수행한다.
-
인상적인 성능에도 불구하고,
model scale이 커지면서 computation budge requirement가 제한된 real-world applications에 DETR을 deploy하는 데에 어려움이 있다.
이 문제를 해결하기 위해 현재 연구들은 efficient DETR architecture를 설계하는 데 집중하고 있다.
cross-attention module에서 사용되는 encoder tokens 수를 줄여 computation cost를 절감하거나 [24],
RPN의 dense prior(밀집된 사전 정보)를 활용하여 decoder layer를 축소하는 방법[36] 등이 제안되었다. -
본 연구에서는 large-scale DETER model을 knowledge distillation 방법을 통해 compressing하는 데 집중한다.
KD는 model compression과 accuracy boosting에 유망한 기술로,
large and cumbersome(크고 복잡한) DETR models에서 학습된 지식을
small and efficient(작고 효율적인) DETR models로 transfer하여,
student model이 teacher model의 predictions(logits or internal activations)을 모방하도록 강요한다.
그러나 현대의 지식 증류 방법은 CNN-based detectors 하에서 설계되었으며,
이를 일반적인 DETR compression으로 확장하는 연구는 제한적이다. -
우리는 DETR에 classic logit-based distillation을 적용하는 실험에서 시작하여,
DETR distillation의 key point를 조사했다.
실험을 통해 관찰한 결과, critical challenge는 DETR과 classic detectors 간의 다른 공식이 있다는 것을 알게 되었다.
classic detectors와 비교했을 때, DETR의 set-prediction 방식은 자연적으로 일관된 distillation points가 적다는 것이다.
distillation point는 KD에서 모방할 predictions의 corresponding input(대응 입력)을 나타내며,
distillation points의 sufficiency and consistency(충분성과 일관성)은 KD의 기반을 형성한다.
구체적으로, teacher와 student model 간에 consistent를 유지하는 abundant distillation points는 효과적인 distillation을 위해 필수적이다.
-
Figure 1a에서 볼 수 있듯이, classic detectors는 image의 sliding window locations에서 생성된 a set of region proposal을 예측한다.
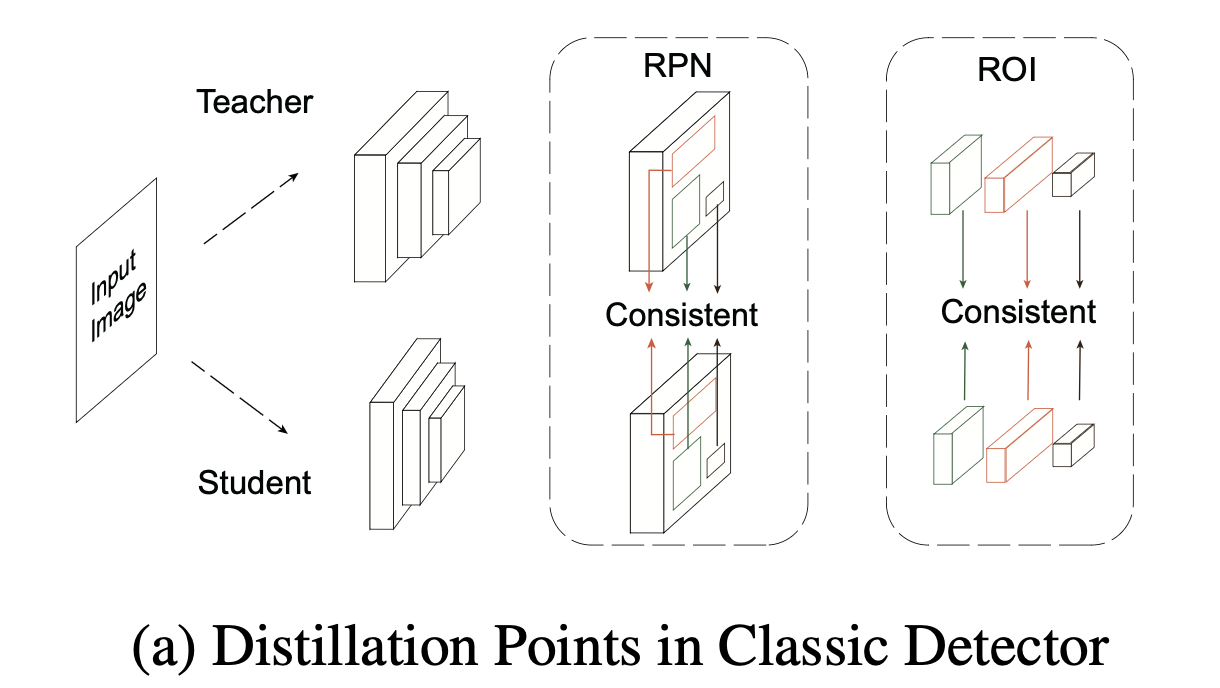 이 패턴은 teacher와 student model이 만든 다수의 proposals, 심지어 negative proposals with low confidence 사이에서도 엄격한 spatial correspondence를 보장하여,
이 패턴은 teacher와 student model이 만든 다수의 proposals, 심지어 negative proposals with low confidence 사이에서도 엄격한 spatial correspondence를 보장하여,
모방할 수 있는 충분한 수의 consistent distillation points를 제공한다. -
DETR에서는 Figure 1b에서 보여주듯이,
distillation points가 실제로 image와 object queries로 구성된다.
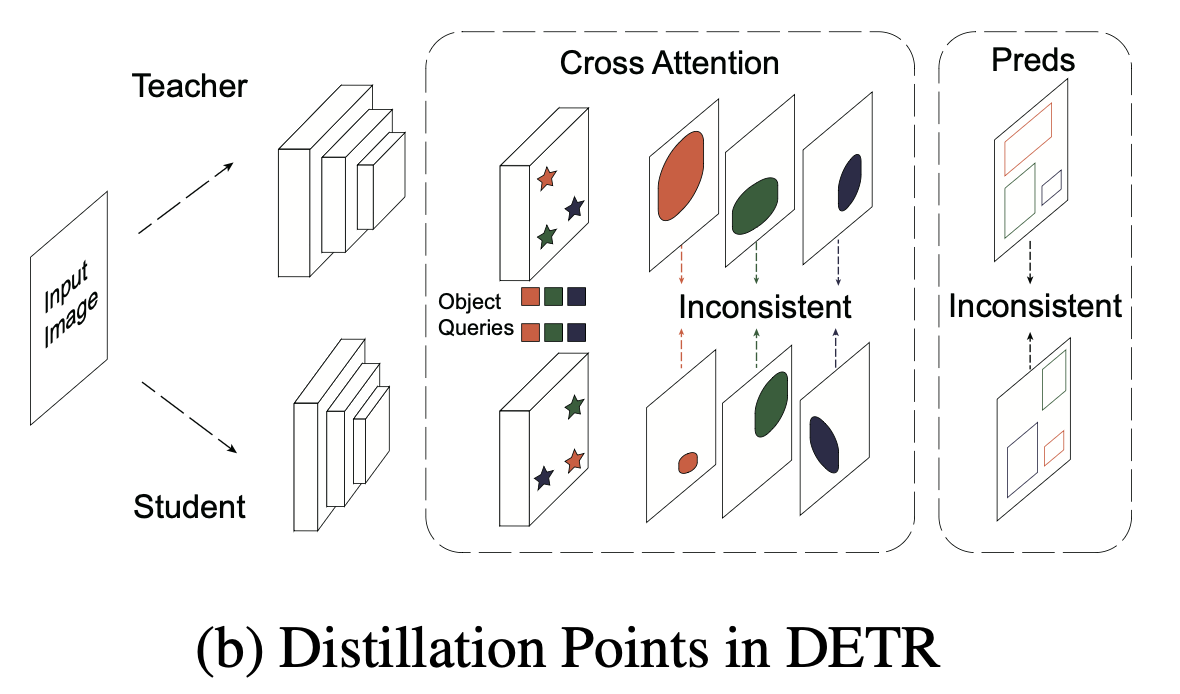 하지만 teacher와 student model의 object queries는 egocentric(자기중심적)이고,
하지만 teacher와 student model의 object queries는 egocentric(자기중심적)이고,
그 수가 다를 수 있어 definite(명확한) correspondence가 부족하며,
특히 bipartite matching에서 redundant negative queries들이 문제이다.
DETR에서 distillation points는 일관성이 없고 충분하지 않기 때문에, teacher로부터 얻은 prediction은 student가 모방하기에 신뢰할 수 없거나 유용하지 않다.
이러한 관찰은 몇가지 문제를 제기한다 :
"how to obtain sufficient and consistent distillation points for DETR distillation?"
이전 연구[3]는 teacher와 student의 object queries 간의 bipartite matching을 활용하여 이 문제를 명시적으로 완화했다.
그러나 bipartite matching은 안정적이지 않으며,
matched된 object queries들은 비슷할 뿐 일관성이 부족하고,
sufficiency and extensibility를 갖추지 못했다. -
이문제를 직접 해결하기 위해,
우리는 consistent distillation point sampling을 가진 DETR을 위한 general knowledge distillation paradigm(KD-DETR)을 제안한다.
Figure 1c에 나와 있듯이,
KD-ETR에서 우리는 detection task와 distillation task를 분리하여,
distillation point를 구성하기 위해 a set of specialized object queries를 도입했다.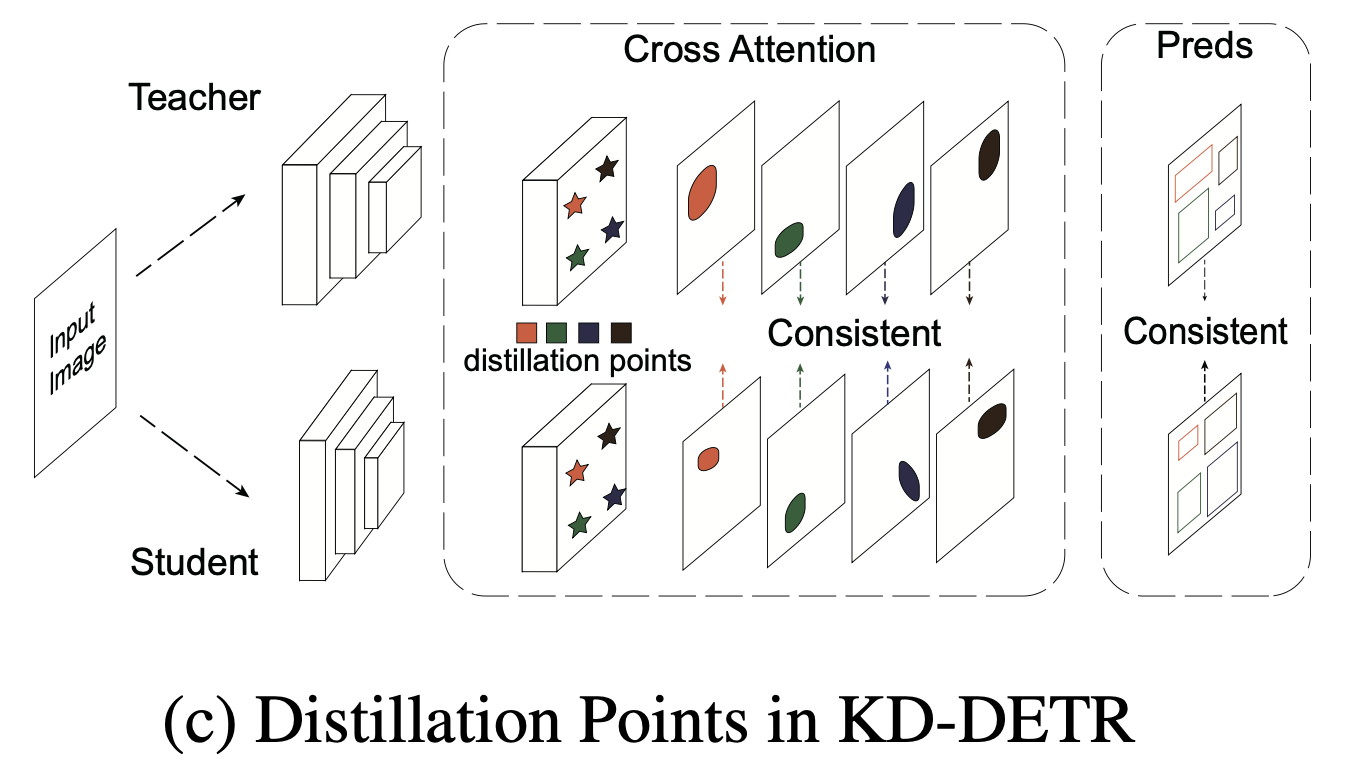 이 distillation points는 unlearnable(학습되지 않으며), teacher와 student 간에 공유되며,
이 distillation points는 unlearnable(학습되지 않으며), teacher와 student 간에 공유되며,
teacher model의 "dark knowledge"를 탐색한다.
이렇게 하면 customized quantities(맞춤형 수량)을 가진 consistent distillation points를 확보할 수 있다. -
KD-DETR paradigm을 통해 우리는 teacher model의 포괄적인 knowledge를 탐색하기 위해
general-to-specific distillation points sampling strategy를 제안한다.
또한 DETR과 CNN detector 간의 heterogeneous distillation로 KD-DETR을 확장하기 위해 coordination-based(협력 기반의) distillation points sampling strategy를 제안한다.
2. Related Work
2.1. Classic Object Detection
-
CNN을 사용하는 Classic detectors는 object detection을
a verification task with a sliding window on the image to generate anchors라고 본다. -
The mainstream detectors는 one-stage detectors와 two-stage detectors로 나누어 볼 수 있다.
- One-stage detecor인 RetinaNet, YOLO and FCOS들은
feature map의 각 pixel에서 anchors의 category and regression을 직접 예측한다. - 반면에 Faster-RCNN 및 그 variants와 같은 Two-stage detectors들은
제안된 region을 생성하기 위해 Region Proposal Networks(RPN)을 도입하고,
RoIPool 또는 ROIAlign을 사용하여 추가적인 classification and regression refinement를 위한 각 region proposal의 feature를 추출한다.
One-stage와 Two-stage detector 모두 중복된 예측을 제거하기 위해
NMS와 같은 post-processing을 필요로 한다.
- One-stage detecor인 RetinaNet, YOLO and FCOS들은
2.2. Detection Transformer
-
[2]에서 처음으로 어떠한 post-processing이 없는 end-to-end transformer-based detector를 제안했다.
classic object detection과 달리, DETR은 object detection을 bipartite matching을 사용한 set prediction 문제로 해석했다. -
많은 후속 연구들은 DETR의 slow convergence에 초점을 맞추었다.
- Deformable DETR[43]은 query elements의 reference points를 생성하여,
각각이 전체 feature map의 소수 위치만 집중하도록 하는 deformable attention module을 도입했다. - 또 다른 방법으로는 decoder에서 object queries에 더 많은 prior information(사전 정보)를 추가하는 것이다.
Conditional-DETR[20]은 object queries에서 context와 position을 분리하고
spatial location에 의한 position features를 생성한다. - DAB-DETR[19]는 positional features에 width and height information를 추가해다.
- Anchor DETR[31]은 object queries로 anchor points를 여러 패턴으로 encoding하고,
memory cost를 줄이기 위해 row-column decouople attention을 설계했다. - 최신 연구인 DINO[41]는 기존의 혁신적인 tecnique들을 결합하고
model과 dataset의 규모를 확대함으로써 DETR의 잠재력을 더욱 보여줬다.
- Deformable DETR[43]은 query elements의 reference points를 생성하여,
-
또한 DETR에서 또 다른 문제는 model scale and computation cost이다.
현재 연구들은 더 효율적인 DETR architecture를 설계하여 이 문제를 해결하고 있다.- Sparse DETR[24]는 encoder token을 희소화하여 computation cost를 줄였다.
- Efficient DETR[36]은 RPN을 도입하여 object queries를 생성하고,
DETR의 cascading decoder layer를 제거했다. - PnP DETR[30]은 poll 및 pool sampling module을 사용하여 sampled feature의 length를 줄였다.
2.3. Knowledge Distillation
-
KD는 a large cumbersome teacher model을 small student에게 knowledge를 transferring함으로써
model compression and accuracy boosting을 위해 널리 사용되는 method이다. -
[11]은 처음으로 knowledge distillation의 개념을 제안했으며,
여기서 student가 teacher의 soft predictions을 mimic한다.
KD는 the objective of mimicking(모방 목표)에 따라 세 가지 categories로 나눌 수있다 : response-based[42], feature-based[10][35] and relation-based[37][38]이며,
각각 logit, intermediate activation and the relation of features in different layers를 distillation 한다. -
여러 연구는 KD를 object detection에 적용하는 것에 집중했다[8][4][12].
[4]는 neck, classification head, regression head에서 feature를 성공적으로 distill한 반면,
[15]는 RPN head에서 logits and features를 distill하기로 선택했다.
[29]는 fg와 bg의 imbalance를 극복하기 위해, GT bbox에 가까운 영역에 집중하는 fine-grained mask를 도입하였고,
[6]은 teacher와 student가 prediction에서 나뉘는 region 더 주목했다.
➡️ 하지만 현대의 KD methods는 CNN-based detector architecture에 구축되어 있으며,
완전히 다른 transformer architecture를 사용하는 DETR에는 적합하지 않다.
[3]은 hungarian matching을 사용하여 DETR에 response-based and feature-based distillation을 직접 도입했다.
이전 연구와 달리, 우리는 KD에서 set prediction 형식의 한계를 분석하고,
homogeneous and heterogeneous DETR distillation 모두를 위한 general paradigm을 제안한다.
3. A Closer Look at DETR Distillation
3.1. Revisiting DETR
DETR review했던 글 : https://velog.io/@hseop/DETR-End-to-End-Object-Detection-with-Transformers

3.2. Consistent Distillation Points
-
KD의 core idea는 student model이 teacher model의 prediction을 모방하도록 강제하는 것으로,
이는 student와 teacher의 mapping function이 일정한 a set of distillation points를 통해
일치하도록 만드는 것으로 해석될 수 있다.
Distillation points는 prediction의 corresponding input 를 의미하며, 에서 는 model을 나타낸다.
이 관점에서 distillation points는 효과적이고 신뢰할 수 있는 matching을 위해
충분한 수량과 teacher 및 student model 간의 일관성을 유지해야 한다.
그러나 CNN-based detector와 DETR의 구성 방식을 비교해 보면, DETR distillation에서의 중요한 과제는 the lacking of consistent distillation points이다. -
Classic detector는 object detection을 classification과 regression을 결합한 검증 문제로 축소하여, 검증할 영역을 지정하기 위해 anchor set를 도입했다.
이 방식에서 distillation point의 구성은 image와 anchor의 위치 및 크기로 나타낼 수 있다. ()
anchor는 sliding window 전략을 통해 handcrafted shapes으로 만들어지며, anchor의 위치와 크기는 model architecture에 사전 정보로 암묵적으로 포함된다.
student와 teacher model이 동일하거나 유사한 architecture를 공유하기 때문에,
teacher와 student model이 생성하는 많은 수의 object proposal은 strict spatial correspondence을 자연스럽게 가지며,
심지어 background regions with low confidence에서도 마찬가지이다.
CNN의 inductive bias로 간주할 수 있는 이러한 spatial correspondence을 통해 classic detector는 충분한 수의 일관된 distillation points를 보장할 수 있다.
반면, DETR은 object detection을 set prediction problem으로 구성한다.
따라서 distillation points는 image와 object queries의 조합()가 된다.
그러나 다양한 model의 object queries는 자율적이며, 독립적으로 초기화 및 최적화된다.
object queries는 특정 instance의 feature를 probing(탐색)하고 pooling하는 역할을 하기 때문에,
각 model에서의 concentration preferences(집중 선호도)가 일관되지 않다.
그 결과, DETR의 구성은 teacher와 student model 간에 strict consistency를 가진 충분한 distillation points를 제공할 수 있는 능력이 부족하며,
teacher로부터 획독한 prediction은 student가 모방하기에 유용하거나 신뢰할 수 없다.
3.3. Distillation with Inconsistent Distillation Points
- 위에서 분석한 distillation point의 충분성과 일관성이 DETR distillation에서 본질적인 challenge라는 점을 검증하기 위해,
우리는 먼저 classic detector에서 사용된 원래의 logit-based distillation method[4]를 DETR에 적용했다.
이 방법은 teacher model의 category와 box location logits prediction을 모방하는 것이다.
우리는 세가지 distillation points strategies를 실험했다 : Inconsistent, Similar Foreground, and Similar General.- Similar Fg에서는 bipartite matching에서 GT와 matching된 object queries만을 distillation point로 사용하고, GT label의 순서에 맞춰 재배치되었다.
- Similar General은 bipartite matching에서 negative object queries의 평균을 general background distillation point로 간주하여 distillation point의 수를 늘렸다.
실험은 DAB-DETR에서 수행되었고 MS COCO2017 dataset에서 평가되었으며, ResNet18을 student model로, ResNet-50을 teacher model로 사용했다.
Table 1.에 나타난 바와 같이,
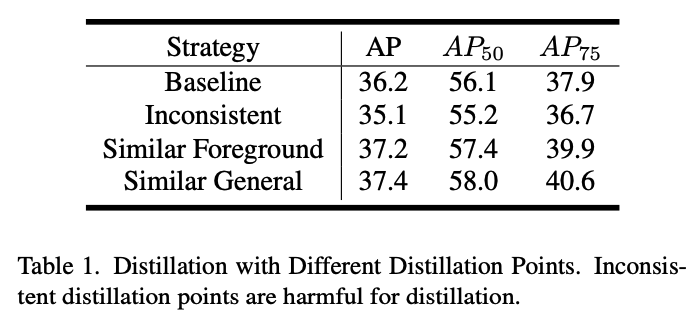
Inconsistenet distillation points는 teacher model로부터 신뢰할 수 없는 knowledge를 전달받아 student model의 성능이 크게 저하되었다.
반면, Similar Fg는 의미적으로 유사한 Fg distillation points를 사용하여 이 문제가 완화되었고,
Similar General은 general bg features를 사용해 distillation points의 수를 늘려 추가적인 성능 향상을 이루었다.
이러한 초기 실험은 distillation points의 충분성과 일관성이 DETR distillation에서 student model의 성능을 향상시키는 데 매우 중요하다는 것을 검증한다.
4. KD-DETR
- lack of concsistent distillation points in DETR 문제를 해결하기 위해서,
우리는 DETR을 위한 general knowledge distillation paradigm을 제안하며,
이는 consistent distillation points를 특징으로 한다.
Figure 2에 나타난 것처럼,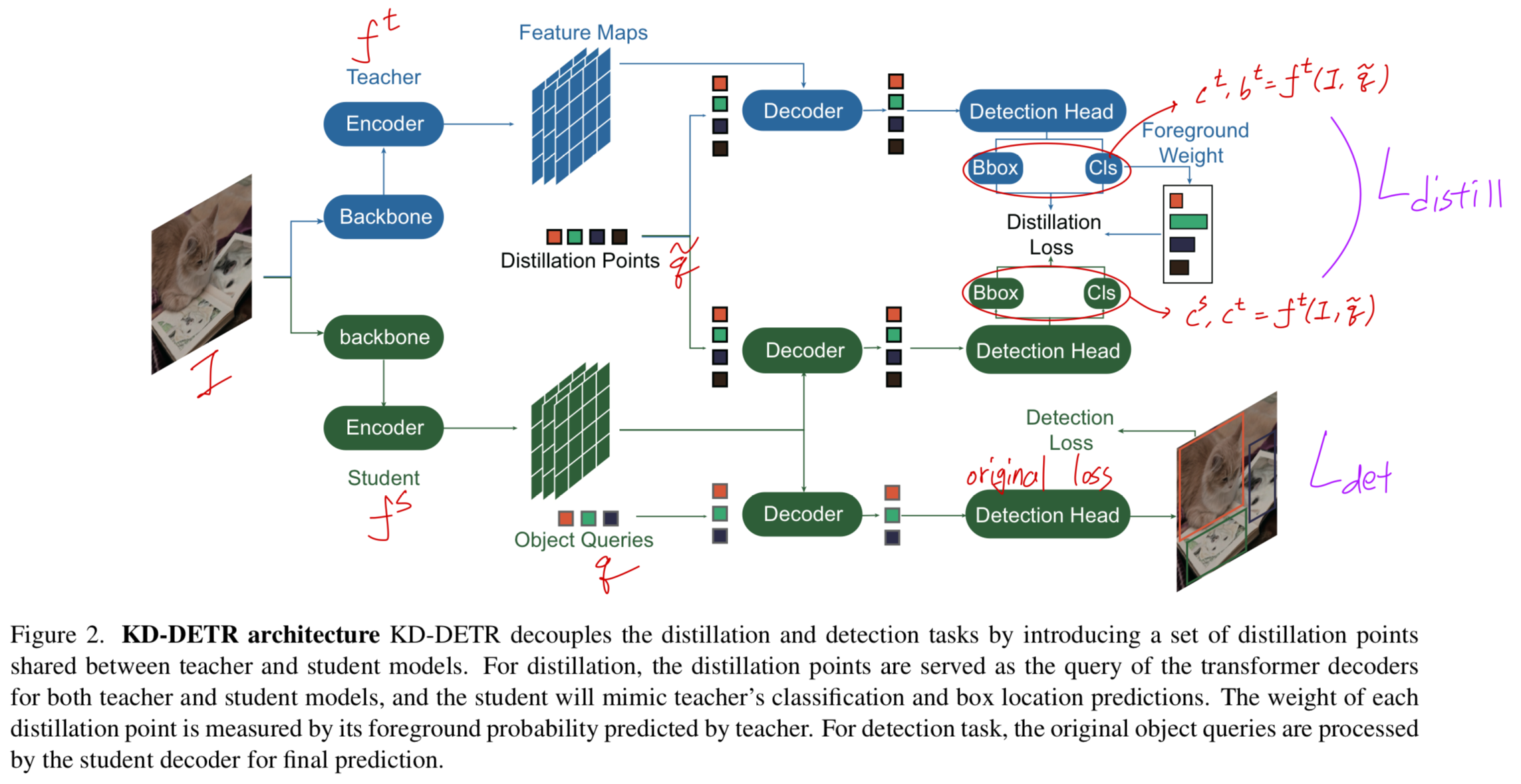 KD-DETR은 teacher model과 student model 간에 공유되는 a set of specialized object queries 를 도입하여 distillation points를 구성한다.
KD-DETR은 teacher model과 student model 간에 공유되는 a set of specialized object queries 를 도입하여 distillation points를 구성한다.
KD-DETR은 distillation task와 detection task를 분리하여 충분하고 일관된 distillation points를 제공한다.
우리는 original input을 , sampled distillation points를 로 denote한다.- detection task의 경우,
student model은 original detection loss로 optimized된다.
즉, original input 가 student model에 입력되어 category와 box location predictions을 수행하며,
이는 bipartite matching을 통해 GT에 할당되고 detection loss 가 계산된다. - distillation task의 경우,
sampling된 distillation points 는 student model과 teacher model 모두에 입력되어 category와 box location predictions 를 수행한다 :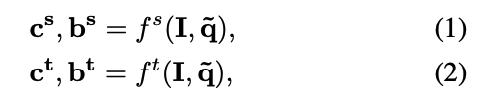 는 각각 student와 teacher model을 나타낸다.
는 각각 student와 teacher model을 나타낸다.
distillation loss는 다음과 같이 계산된다 :
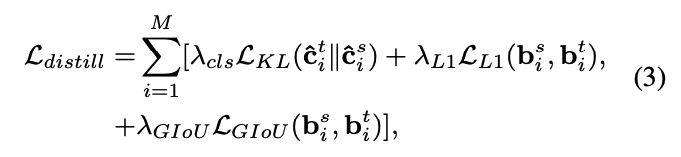

그래서 total Loss는 다음과 같이 계산된다 :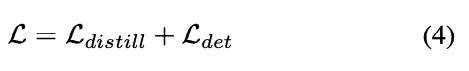
- detection task의 경우,
4.1. Distillation Points Sampling
- 일반적으로, object queries는 encoder에서 context features를 probing and pooling하여
특정 object를 담당하는 abstract features의 집합이다.
기존 연구들은 object queries를 anchors or reference points로 해석하며,
각 object queries가 feature map에서 특정 영역에 민감하다는 것을 밝혀냈다.
이러한 관점을 따르며, 우리는 general-to-specific sampling strategies for distillation points sampling 를 제공한다.
General Sampling with Random Initialized Queries.
- general sampling에서, feature map 전체를 sparse하게 scanning하여
다양한 locations에서 teacher의 일반적인 응답을 탐색하고자 한다.
따라서 우리는 random으로 initizlied된 object query set을 사용하여 general distillation points를 구성한다 :
, where denotes #(general distillation points).
teacher로부터 더 일반적인 지식을 학습하기 위해, 이 distillation points들은 학습 중에 학습되지 않으며, 매 iteration마다 다시 sampling된다.
Specific Sampling with Teacher Queries.
- general sampling이 feature의 global retrieval(탐색)을 제공하는 반면,
우리는 teacher가 더 많은 attention을 기울이는 regions에 초점을 맞추는 specific sampling 전략을 제안한다.
specific sampling을 위한 직관적인 방법은 teacher model에서 well-optimized object queries를 재사용하는 것이다 :
teacher model은 이러한 object queries에 더 집중하도록 학습되었으므로, 해당 영역에서의 예측이 더 정밀하고 유용한 정보를 포함하고 있다.
Foreground Rebalance Weight.
- fg와 bg regions 사이의 imbalance는 DETR에만 국한되지 않는 중요한 문제이다.
직관적인 방법은 teacher model이 예측한 distillation points의 classification score를 활용하여 distillation loss를 rebalance하는 것이다.
구체적으로, 높은 classification score를 가진 distillation points는 fg distillation points로 간주되며,
detection에 더 유용한 정보를 포함하고 있어 더 많은 attention을 가져야 한다.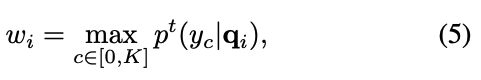 여기서 는 teacher model이 예측한 가 category 에 할당될 확률을 나타내며,
여기서 는 teacher model이 예측한 가 category 에 할당될 확률을 나타내며,
는 의 fg rebalance weight를 나타낸다.
이 방법을 통해, Eq.3는 다음과 같이 작성된다 :
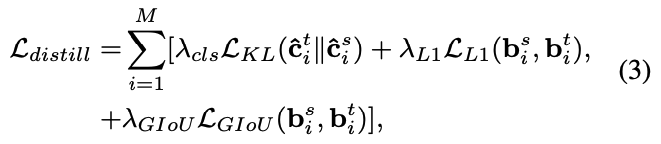
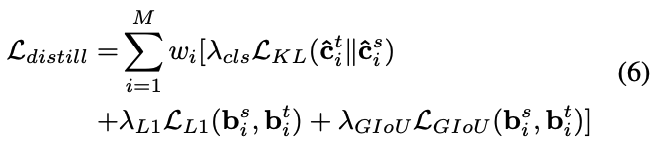
4.2. Generalization to Heterogeneous Distillation

