DETRDistill: A Universal Knowledge Distillation Framework for DETR-families

Abstract
-
Transformer-based detectors(DETRs)는 간단한 framework로 인기를 얻고 있지만, model 크기와 시간 소모가 커서 real world에서의 배치가 어렵다.
Knowledge Distillation은 large detectors를 small detectors로 compress하여 유사한 detection performance와 low inference cost를 제공할 수 있는 기술이 될 수 있다.
DETR이 object detection을 set prediction으로 정의하기 때문에, 기존의 전통적인 convolution-based detectors를 위한 KD 방법은 직접적으로 적용되지 않을 수 있다. -
본 논문에서는 DETR-families에 특화된 a novel knowledge distillation method인 DETRDistill을 제안한다.
구체적으로, 우리는 먼저 hungarian matching logits distillation을 설계하여 student model이 teacher DETR의 prediction과 정확히 일치하도록 유도한다.
다음으로, object-centric features에서 teacher model의 knowledge를 학습하도록 돕는 target-aware feature distillation을 제안한다.
마지막으로, student DETR의 convergence 속도를 개선하기 위해, well-trained queries와 teacher model의 stable assignment에서 student model이 빠르게 학습할 수 있도록 query-prior(우선) assignment를 도입한다. -
COCO dataset에서 Extensive experimental results는 우리 접근 방식의 효과를 검증한다.
특히, DETRDistill은 다양한 DETR을 2.0mAP 이상 개선하며, 심지어 teacher model을 능가하기도 한다.
1. Introduction
-
object detection은 input image에서 시각적 object의 위치를 지정하고 분류하는 것을 목표로 한다.
초기 연구에서는 주로 image의 local feature를 처리하기 위해 CNNs을 사용하여 이 작업을 수행했다.
이 방법은 anchor, label assignment, duplicate removal 등의 많은 inductive biases를 포함했다.
최근에는 DETR과 같은 transformer-based object detectors가 제안되었으며, detection을 set prediction task로 처리함으로써 detection pipeline을 크게 단순화하고 anchor sizes and ratios와 같은 hand-craft components의 번거로운 tuning에서 사용자를 해방시켰다. -
transformer-based detectors는 SOTA를 달성했음에도 불구하고, expensive computation problem으로 인해 real-time application에 배포하기 어렵다는 문제가 있다.
빠르고 정확한 detector를 얻기 위해 KD는 매력적인 기술이다.
일반적으로 KD는 heavy-weighted but powerful teacher model의 knowledge를
small and efficient student network로 전달하여 predictions or feature distributions을 모방하게 한다. -
object detection 연구 분야에서는 다양한 종류의 KD 방법이 발표되었다.
그러나 대부분의 방법들은 convolution-based detectors를 위해 설계되었으며,
detection frameworks 차이로 인해 transformer-based DETR에 바로 적용되지 않을 수 있다.
여기에는 최소한 두 가지 challenges가 있다 :- logits-level distillation methods are unusable for DETRs.
anchor-based or anchor-free convolution-based detectors의 경우, box predictions이 feature map grid와 밀접하게 관련되어 있어
Teacher와 student 간의 KD를 위한 box predictions의 strict spatial correspondence를 자연스럽게 보장한다.
그러나 DETR의 경우, decoder에서 생성된 box prediction은 unordered(순서가 없으며)하며,
teacher와 student 간의 prediction box 사이에 자연스러운 one-to-one correspondence가 없기 때문에 logits-level distillation이 불가능하다. - Feature-level distillation approaches may not suitable for DETRs
convolution과 transformer 간의 feature generation mechanism이 다르기 때문에,
interested object에 대한 feature activation 영역이 크게 다르다.
Fig. 2에서 볼 수 있듯이, convolution-based detector의 active region은 GT box 내부로 제한되어 있지만,
DETR detector는 background area에서도 추가적으로 activate된다. 따라서 이전의 feature-level KD methods를 DETR에 직접 적용하면 성능 향상이 보장되지 않으며, 때때로 student detectors의 성능을 저하시킬 수 있다. (Table 1 참고)
따라서 이전의 feature-level KD methods를 DETR에 직접 적용하면 성능 향상이 보장되지 않으며, 때때로 student detectors의 성능을 저하시킬 수 있다. (Table 1 참고)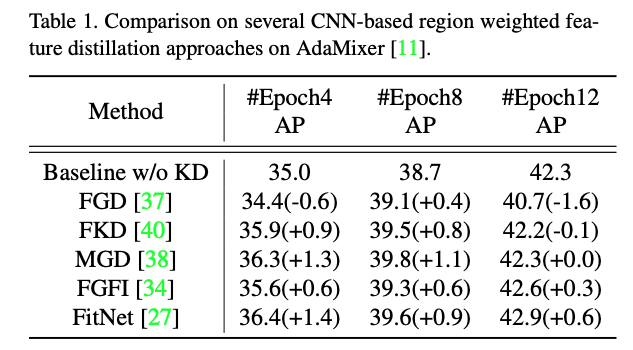
- logits-level distillation methods are unusable for DETRs.
-
위 challenges들을 해결하기 위해,
우리는 DETR 계열 detectors를 위해 특별히 설계된 knowledge distillation framework인DETRDistill을 제안한다
정확히 말하면, DETRDistill은 세 가지 구성 요소로 이루어져 있다. :Hungarian-matching logits distillation:
challenge 1을 해결하기 위해, 우리는 hungarian algorithm을 사용하여
student와 teacher의 prediction 간의 optimal bipartite matching을 찾아 logits-level에서 KD를 수행할 수 있었다.
그러나 teacher model에서 positive로 예측된 box 수가 매우 제한적이기 때문에, positivie predictions에만 KD를 적용하면 성능 향상이 크게 일어나지 않았다.
대신, teacher와 student model 간의 massive(대규모) negative predictions에
distillation loss를 도입하여 teacher detector에 내재된 knowledge를 최대한 활용하도록 제안한다.
또한, DETR 방법이 일반적으로 여러 Decoder layer를 포함하여 단계적인 prediction refinement를 수행하기 때문에,
각 단계에서 KD loss를 만들어 progressive(점진적인) distillation을 수행했다.Target-aware feature distillation:
challenge 2의 분석에 따라, 우리는 object queries와 teacher model의 feature를 활용하여 soft activation masks를 생성하는 방법을 제안한다.
well-trained teacher queries는 다양한 object target과 밀접하게 관련되어 있으므로,
이렇게 생성된 soft mask는 object-centric(객체 중심적)이 되어,
soft-mask-based feature-level distillation이 target-aware하게 이루어진다.Query-prior assignment distillation:
student model에서 query와 decoder parameter는 randomly initialized되므로,
student model에서 unstable bipartite assignment가 발생하여 slow convergence rate가 발생한다.
그러나 우리는 실험적으로 teacher model에서 well-trained queries는 항상 consistent(일관된) bipartite assignment를 생성할 수 있음을 발견했다. (Fig. 7)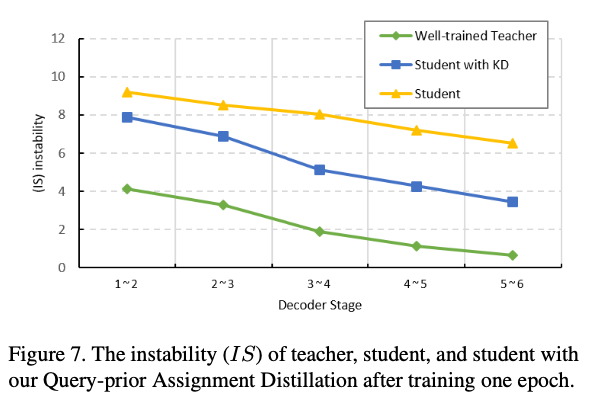 따라서 우리는 student model이 teacher의 queries를 추가적인 prior queries group으로 받아들여
따라서 우리는 student model이 teacher의 queries를 추가적인 prior queries group으로 받아들여
teacher network의 stable bipartite assignment를 기반으로 prediction을 생성하도록 장려하는 방법을 제안한다.
이러한 distillation은 student model이 빠르게 수렴하고 더 나은 성능을 달성하는 데 성공적으로 기여한다.
-
요약하자면, 우리의 contributions은 세 가지로 나눌 수 있다 :
- 우리는 DETR이 traditional convolution-based detectors와 비교하여 distillation methods에서 겪는 어려움을 자세히 분석했다.
- 우리는 logits-level, feature-level, and convergence rate 관점에서 각각 DETR을 위한 다양한 knowledge distillation methods를 제안한다.
- 우리는 COCO dataset에서 다양한 settings 하에 Extensive experiments 수행했으며, 그 결과 우리 방법의 effectiveness and generalization을 입증했다.
2. Related Work
2.1. Transformer-based Object Detectors
- Transformer의 NLP에서 뛰어난 성능 덕분에, 연구자들은 Transformer 구조를 visual tasks에도 적용하기 시작했다.
하지만 DETR의 training 과정은 매우 비효율적이라서, 많은 후속 연구들이 수렴 속도를 가속화하려고 시도했다.- 한 연구 분야는 attention mechanism을 재설계하려고 했다.
예를 들어, Dai et al. [43]은 reference points 주변의 variable sampling point features만 상호작용하여 sparse attention mechanism을 구축하는 Deformable DETR을 제안했다.
SMCA는 cross-attention을 제한하기 위해 Gaussian prior를 도입했다.
AdaMixer는 어떤 encoder도 사용하지 않고, channel 및 spatial dimension에서 adaptive weights로 sampling된 feature를 혼합하는 새로운 adpative 3D feature sampling strategy 설계했다. - 또 다른 연구 분야는 query의 의미를 재고하는 것이다.
Meng et al. [25]는 DETR이 cross-attention에서 content embedding에 의존하여 object의 극한을 찾는 것이 비효율적이라고 시각화하고,
query를 content 부분과 position 부분으로 분리할 것을 제안했다.
Anchor-DETR은 query의 2D reference points를 positional embedding으로 직접 사용하여 attention을 유도했다.
DAB-DETR은 location 정보 외에도 width and height information를 attention mechanism에 도입하여 다양한 크기의 object를 modeling했다.
DN-DETR은 training 가속화를 위해 qeury denoising 작업을 도입했다.
Gruop-DETR과 H-DETR은 Decoder training에서 auxiliary group으로 positive sample을 증가시켜 성능을 향상시켰다.
- 한 연구 분야는 attention mechanism을 재설계하려고 했다.
- 이전 연구들과 달리, 우리는 distillation을 통해 작은 model의 성능을 향상시키고자 한다.
2.2. Knowledge Distillation in Object Detection
-
Knowledge Distillation은 model compression을 위한 일반적인 방법이다.
FitNet, DeFeat, FGD, LD, MGD 등 CNN-based distillation 외에도
일부 연구는 vision transformer를 포함한다.
DeiT는 CNN teacher로부터 distillation token을 통해 ViT로 inductive bias를 전달하여 classification task에서 경쟁력 있는 성능을 달성했다.
ViDT는 patch token에서 KD를 수행하고 transformer detector의 variants를 제안했다. -
그러나 이러한 distillation은 DETR families에 직접 적용할 수 없다.
우리의 연구는 DETR의 다양한 구성 요소에서 나타나는 고유한 현상을 분석하고, 이를 기반으로 universal distillation strategy를 제안한다.
3. A Review of DETR
-
DETR은 backbone, transformer encoders, learnable query embedding 및 decoder를 포함한 end-to-end object detector이다.
주어진 image 에 대해, CNN backbone은 image의 spatial feature를 추출한 뒤,
transformer encoder(일부 variants는 encoder를 필요로 하지 않음)가 feature representation을 강화한다.
update된 feature 를 갖고, query embedding 이 여러 transformer decoder(일반적으로 6개)에 입력되며,
여기서 는 feature dimension이고, 은 고정된 queries 수이다.
각 decoder stage에서의 작업은 비슷하다 :
Firstly, query 간 상호 정보를 포착하기 위해 self-attention을 사용하여 query 간의 relation을 설정한다.
Secondly, flexible cross-attention을 통해 image feature와 상호작용하여 query와 유용한 semantic information을 aggregate한다.
Thirdly, FFN을 통해 각 query를 예측된 categories와 bboxes 로 decoding한다. -
training stage에서는,
Hungarian algorithm을 사용해 model prediction과 GT 사이의 matching cost를 최소화하여 bipartite matching을 얻는 것이 label assignemtn의 원칙이다.
optimal matching은 다음과 같이 해결된다 :
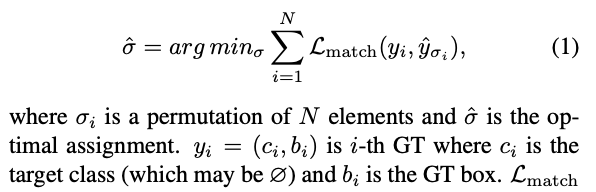 는 pair-wise matching cost이다 :
는 pair-wise matching cost이다 :
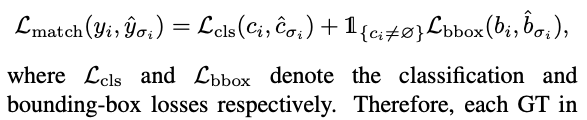 그러므로,
그러므로,
DETR에서 각 GT는 only one positive sample query에만 대응되고, 나머지 queries들은 negative samples로 볼 수 있다.
The final detection lsos function은 다음과 같이 정의된다 :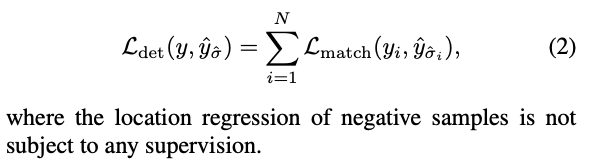
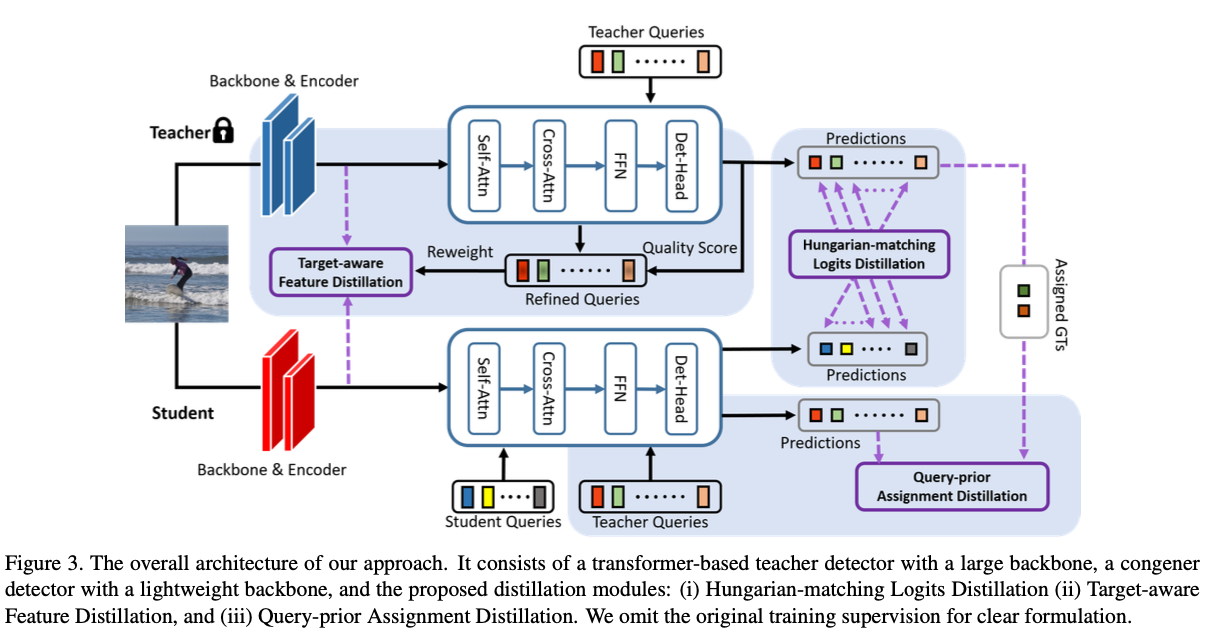
4. Our Approach : DETRDistill
-
이 section에서 우리는 제안된 DETRDistill의 세 가지 구성 요소에 대한 세부사항을 소개할 것이다 :
- Hungarian-matching Logits Distillation
- Target-aware Feature Distillation
- Query-prior Assignment Distillation
-
Fig.3은 DETRDistill의 overall architecture를 보여준다.
4.1. Hungarian-matching Logits Distillation
-
KD에서 가장 일반적인 전략 중 하나는 두 model 간의 prediction을 logits-level에서 직접 정렬하는 것이다.
그러나 query-based predictions in a set form은 DETR에서 teacher model의 결과와 student model의 결과를 질서 있게 대응시키는 것을 어렵게 만든다.
이를 해결하기 위해, 우리는 hungarian algorithm을 재사용하여 teacher model의 prediction과 student model의 prediction을 one-to-one matching하였다. -
공식적으로,
teacher model과 student model의 prediction을 각각 , 로 나타내며,
= {, }이고 으로 정의된다.
여기서 와 는 각각 teacher model의 positive prediction과 negative positive의 수를 나타내며,
는 teacher model의 총 decoder query 수이고, 은 student model의 총 decoder query 수이다.
일반적으로 은 보다 크거나 같으며, (RT-DETR-R50은 300개 R18은 200개)
teacher의 positive prediction은 target과 밀접하게 관련되어 있기 때문에
이를 knowledgeable pseudo GTs로 간주하고,
hungarian algorithm을 사용하여 이러한 teacher model의 positive prediction 과 student model의 prediction 간의 matching 를 찾는 것이 직관적인 접근 방법이다.
그러면 logits-level KD는 다음과 같이 이루어질 수 있다 :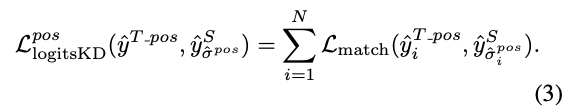 하지만 우리는 경험적으로 이러한 naive KD는 Table 8.에 나타난 것처럼 성능 향상이 미미하다는 것을 발견했다.
하지만 우리는 경험적으로 이러한 naive KD는 Table 8.에 나타난 것처럼 성능 향상이 미미하다는 것을 발견했다.
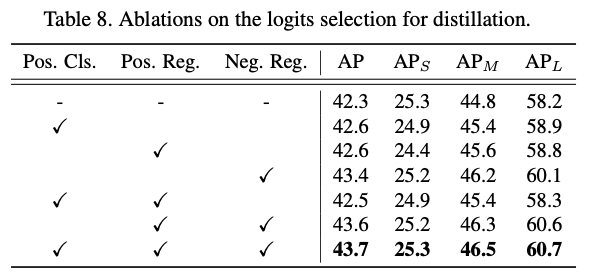 우리는 positive prediction 수가 매우 제한적이라는 가설을 세웠다 (image당 평균 7개이며, query의 총 수는 일반적으로 100개를 초과함)
우리는 positive prediction 수가 매우 제한적이라는 가설을 세웠다 (image당 평균 7개이며, query의 총 수는 일반적으로 100개를 초과함)
그리고 distill된 정보와 GT가 매우 중복된다고 생각한다.
반면에 teacher model의 많은 negative prediction은 무시되고 있으며, 우리는 이러한 prediction들도 가치가 있다고 주장한다.
Negative location distillation.
- teacher model은 일반적으로 well-optimized되어 있으므로 생성된 positive prediction과 negative prediction 간에
뚜렷한 차이가 있을 수 있어 hungarian algorithm이 그럴듯한 assignment를 생성할 수 있다.
즉, negatively predicted boxes는 object target에서 멀리 떨어져 있게 된다.
반면, randomly initialized student network는 이러한 효과를 가지지 못할 수 있으며,
student의 negative prediction이 positive prediction과 얽혀 있을 수 있다.
따라서 우리는 Teacher model의 negative prediction에 포함된 지식을 활용하기 위한 distillation nethod를 제안한다.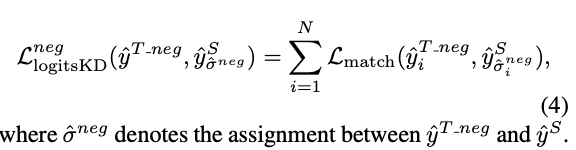
Progressive distillation.
- DETR decoders에서는 일반적으로 multiple stage로 되어 있고 stage-wise supervision이 default로 포함되어 있다는 점을 고려하여,
우리는 Eq. 3과 4에 명시된 KD loss를 각 decoder stage에 도입하여 progressive distillation을 수행할 것을 제안한다.
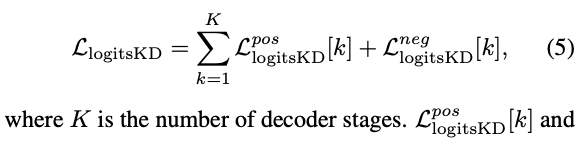
 우리는 teacher model의 stage-by-stage outputs에서 student model의 해당 stage로 knowledge를 transfer하며,
우리는 teacher model의 stage-by-stage outputs에서 student model의 해당 stage로 knowledge를 transfer하며,
단순히 Teacher model의 last stage output을 사용하여 student model의 모든 stage를 supervision하지 않는다.
그 이유는 최근 연구[3]에서 관찰된 것처럼 teacher model이 각기 다른 stage에서 서로 다른 knowledge를 포함하고 있다고 생각하기 때문이다.
이와 같은 distillation strategy는 teacher model에 있는 knowledge를 최대한 활용할 수 있으며, Table 9의 실험 결과가 우리의 주장을 입증한다.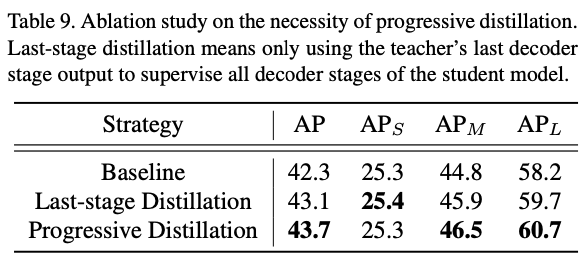
4.2. Target-aware Feature Distillation
- Detection 성능은 주로 FPN에서 생성된 Feature representations에 의해 결정되며,
이는 object target과 관련된 rich semantic information을 포함하고 있기 때문이다.
따라서 우리는 Teacher model의 knowledge를 feature-level에서 distillation하는 것이 필요하다고 주장한다.
teacher model의 spatial features를 모방하는 전형적인 방법은 다음과 같이 계산될 수 있다. 는 Teacher에 의해 생성된 feature representations.
는 Teacher에 의해 생성된 feature representations.
는 Student 의해 생성된 feature representations.
and 는 height and width.
는 teacher's feature의 channel 개수.
는 의 student's feature dimension을 dimension으로 변환해주는 learnable dimension adaptation layer.
는 두 matrices 사이의 Hadamard product.
는 다양한 KD 방법에서 유용한 영역을 선택하기 위한 soft mask를 나타낸다.
예를 들어, Romero et al. [27]는 mask를 1로 채워진 Matrix로 처리하며,
Wang et al. [34]는 anchor box와 GT box 사이의 IoU score를 기반으로 mask를 생성한다.
Sun et al. [30]은 GT box를 덮는 gaussian mask를 활용한다.
위 접근 방식들과는 달리, 우리는 query embedding과 feature representation 사이의 similartiy matrix를 계산하여 DETR에서 soft mask를 구성할 것을 제안한다.
공식적으로, teacher model의 전체 queries set 가 주어졌을 때,selection mask는 다음과 같이 얻을 수 있다 :
 하지만, 우리는 이러한 vanilla distillation 방법은 성능이 좋지 않다는 것을 경험적으로 발견했다. (Table 2)
하지만, 우리는 이러한 vanilla distillation 방법은 성능이 좋지 않다는 것을 경험적으로 발견했다. (Table 2)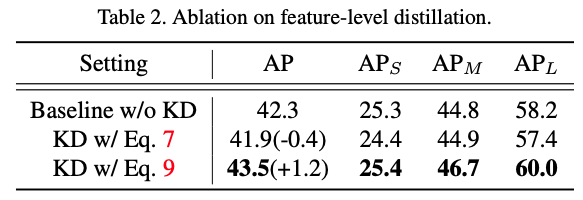 그 이유는 teacher model의 모든 object queries가 동일하게 유용한 cues(힌트)로 취급되어야 하는 것은 아니기 때문이라고 추정한다.
그 이유는 teacher model의 모든 object queries가 동일하게 유용한 cues(힌트)로 취급되어야 하는 것은 아니기 때문이라고 추정한다.
teacher queries에서 생성된 prediction을 기반으로, Fig. 4는 query-based masks 의 시각화 결과를 보여주며,
low-prediction scores를 가진 mask가 object regions 밖에 집중되는 것을 확인할 수 있다. 이러한 관찰에 따라,
이러한 관찰에 따라,
우리는 teacher queries를 선택적으로 사용하여 mask 를 생성할 것을 제안한다.
구체적으로 [8]에서 제안된 quality score를 측정 기준으로 사용한다. 그러면 target-aware quality score는 어떤 query가 KD에 더 많이 기여해야 하는지를 안내하는 지표로 사용되며,
그러면 target-aware quality score는 어떤 query가 KD에 더 많이 기여해야 하는지를 안내하는 지표로 사용되며,
Eq. 6의 KD loss는 다음과 같이 확장할 수 있다 :
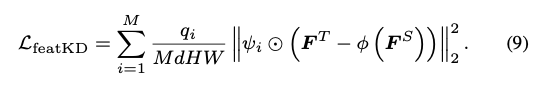
4.3. Query-prior Assignment Distillation
-
DETR에서 query와 decoder parameters는 일반적으로 model optimization을 위해 randomly initialized되기 때문에,
query는 서로 다른 training epoch에서 다양한 object에 할당될 수 있으며, 이로 인해 unstable bipartite graph matching과 느린 수렴 속도가 발생할 수 있다.[17]
KD setting에서는 student DETR의 training에도 동일한 문제에 직면하게 된다.
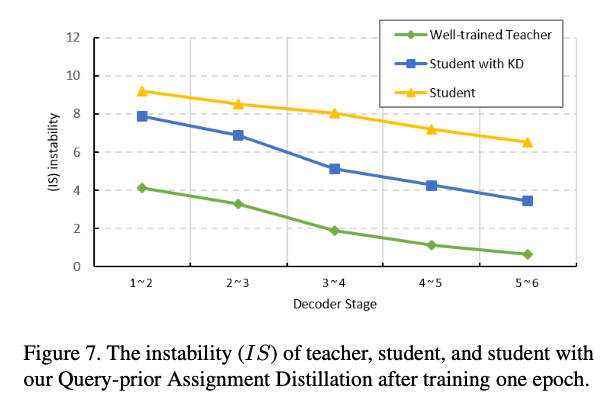
그러나 우리는 teacher model에서 well-optimized queries가 서로 다른 decoder stage 사이에서 안정적인 bipartite matching을 일관되게 달성할 수 있다는 것을 경험적으로 관찰했으며, 이는 student model의 training 안정성을 향상시키기 위해 teacher model의 지식을 활용하는 것이 직관적임을 보여준다.
이러한 motivation에 기반하여, 우리는 query-prior assignment distillation을 제안한다. -
구체적으로,
teacher query set 가 주어졌을 때,
input-GT pairs에 대해 teacher로부터 해당 assignment permutation 을 얻을 수 있다.
우리는 teacher query embedding 를 student model에 추가적인 prior queries group으로 입력하고,
teacher의 assignment 를 직접 사용하여 loss 계산에 사용될 것을 제안한다 :
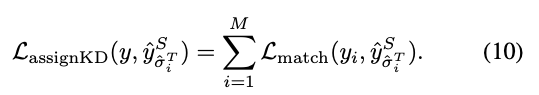 이 제안된 KD loss는 student model이 teacher queries를 사전 정보로 취급하도록 도와주며,
이 제안된 KD loss는 student model이 teacher queries를 사전 정보로 취급하도록 도와주며,
student detector가 가능한 한 stable assignment를 달성하도록 장려한다.
Fig. 7에서 볼 수 있듯이, 제안된 distillation loss를 통해 student model의 matching stability가 크게 향상되었다.
이 추가적인 teacher query group은 training 중에만 사용되며, student model은 최종 평가 시 default query set을 사용한다.
4.4. Overall Loss
- 종합하면,
student DETR training에 필요한 total loss는 a weighted combination of Eq. 2, Eq. 5, Eq. 9, and Eq.10 :

