[Paper Review] Model Compression - Knowledge Distillation
1.[2017 NIPS] Learning Efficient Object Detection Models with Knowledge Distillation
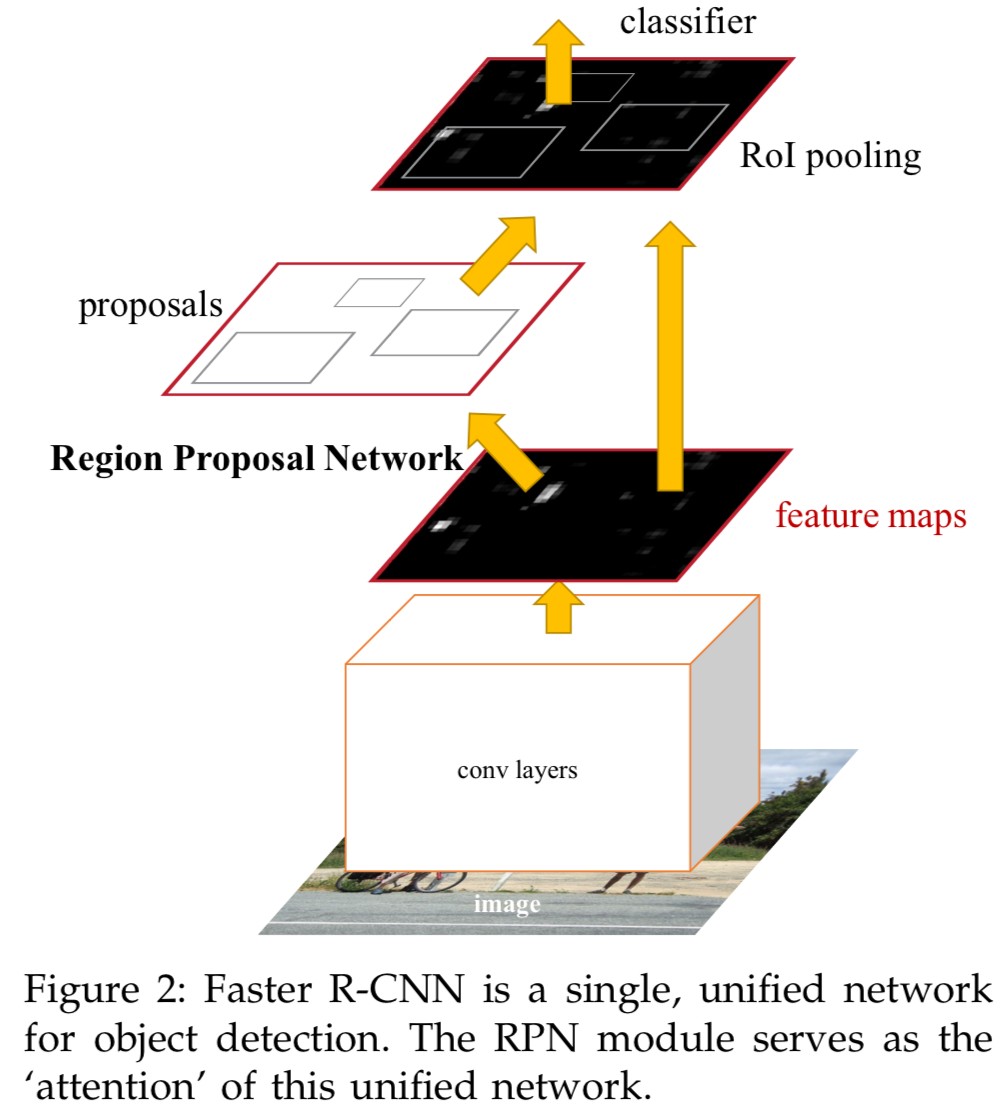
이 논문을 읽게 된 이유는 object detector의 knowledge distillation 관련한 연구를 진행하고 있는데 도움이 필요하기 때문...teacher model의 bbox prediction을student model이 유사하게 학습하도록 KL Dive
2.[Simple Review] MSSD: multi-scale self-distillation for object detection
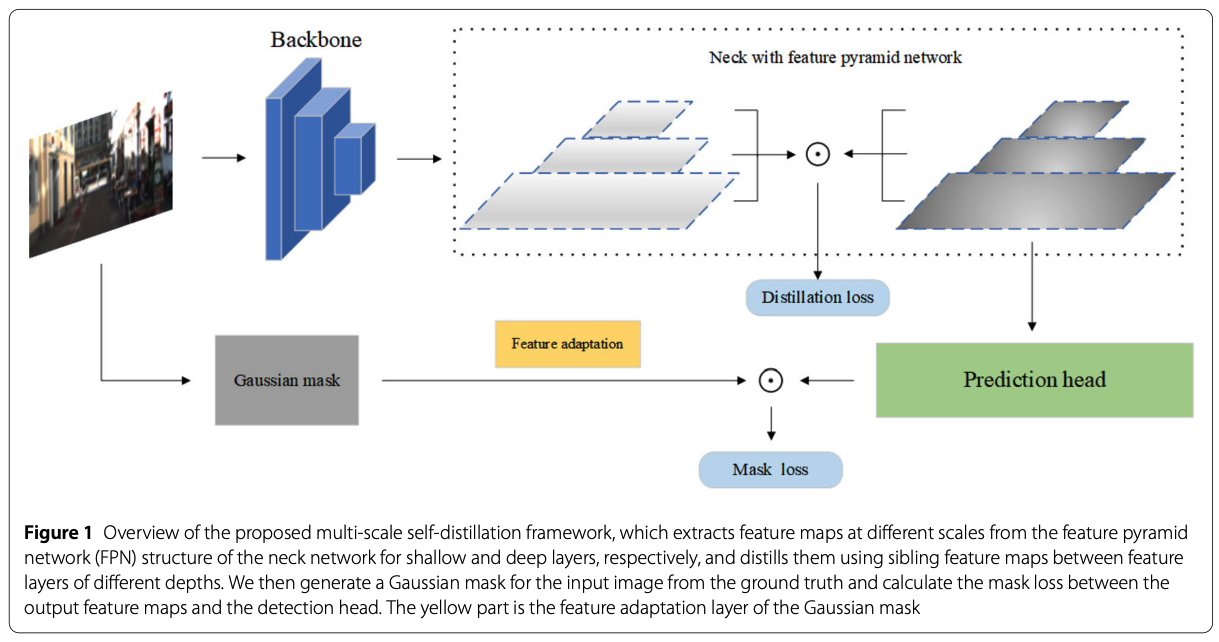
https://link.springer.com/article/10.1007/s44267-024-00040-3Jia, Z., Sun, S., Liu, G. et al. MSSD: multi-scale self-distillation for object detec
3.[중단] LGD: Label-guided Self-distillation for Object Detection
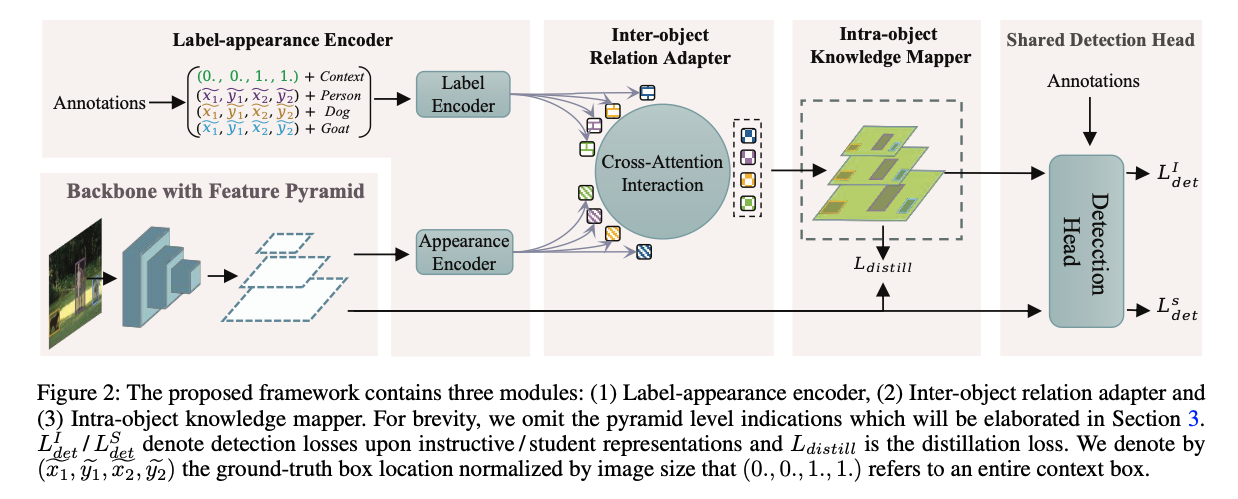
https://arxiv.org/abs/2109.11496Zhang, Peizhen, et al. "LGD: Label-guided self-distillation for object detection." Proceedings of the AAAI confer
4.Smooth and Stepwise Self-Distillation for Object Detection
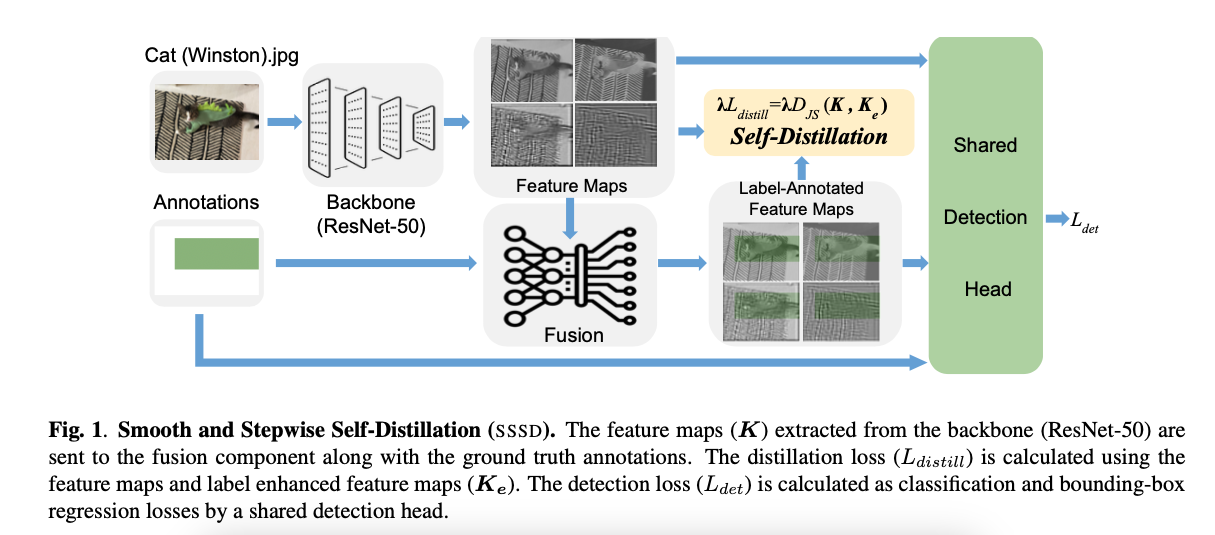
https://arxiv.org/abs/2303.05015Deng, Jieren, et al. "Smooth and Stepwise Self-Distillation for Object Detection." 2023 IEEE International Confer
5.[중단] PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient

https://papers.neurips.cc/paper_files/paper/2022/file/631ad9ae3174bf4d6c0f6fdca77335a4-Paper-Conference.pdfCao, Weihan, et al. "Pkd: General dist
6.CrossKD: Cross-Head Knowledge Distillation for Object Detection
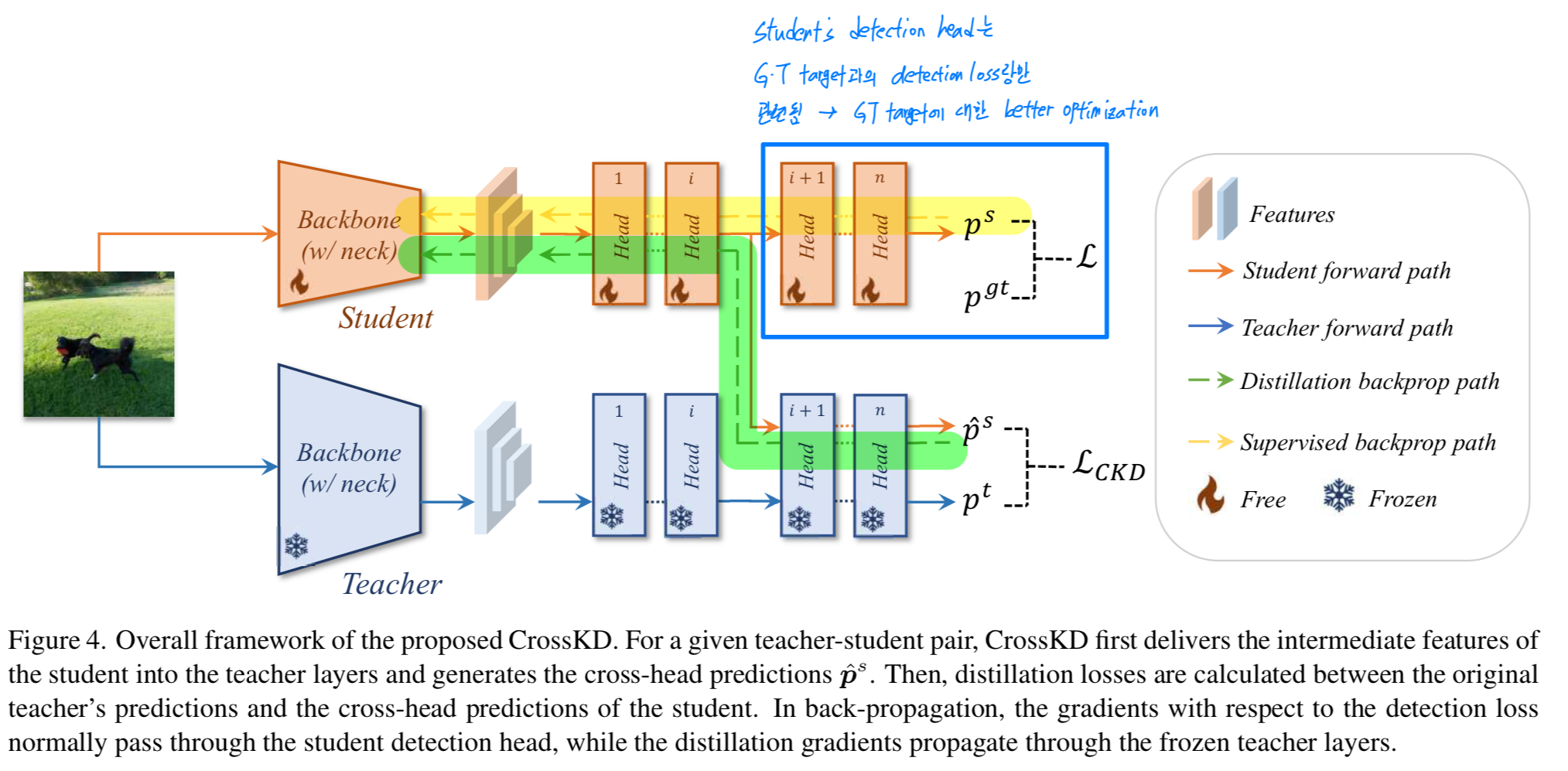
https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_CrossKD_Cross-Head_Knowledge_Distillation_for_Object_Detection_CVPR_2024_paper.pdfWang
7.$D^3$ETR: Decoder Distillation for Detection Transformer
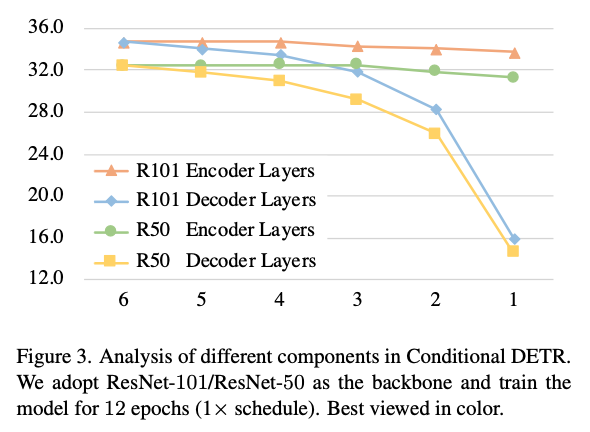
Chen, Xiaokang, et al. "D $^ 3$ ETR: Decoder Distillation for Detection Transformer." arXiv preprint arXiv:2211.09768 (2022).CNN-based detectors에서 다양한
8.DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
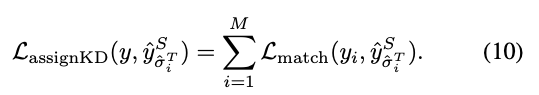
https://openaccess.thecvf.com/content/ICCV2023/papers/ChangDETRDistillAUniversalKnowledgeDistillationFrameworkforDETR-familiesICCV2023_paper.pdf Abst
9.KD-DETR: Knowledge Distillation for Detection Transformer with Consistent Distillation Points Sampling

https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_KD-DETR_Knowledge_Distillation_for_Detection_Transformer_with_Consistent_Distillation_
10.[Simple Review] Knowledge distillation: A good teacher is patient and consistent
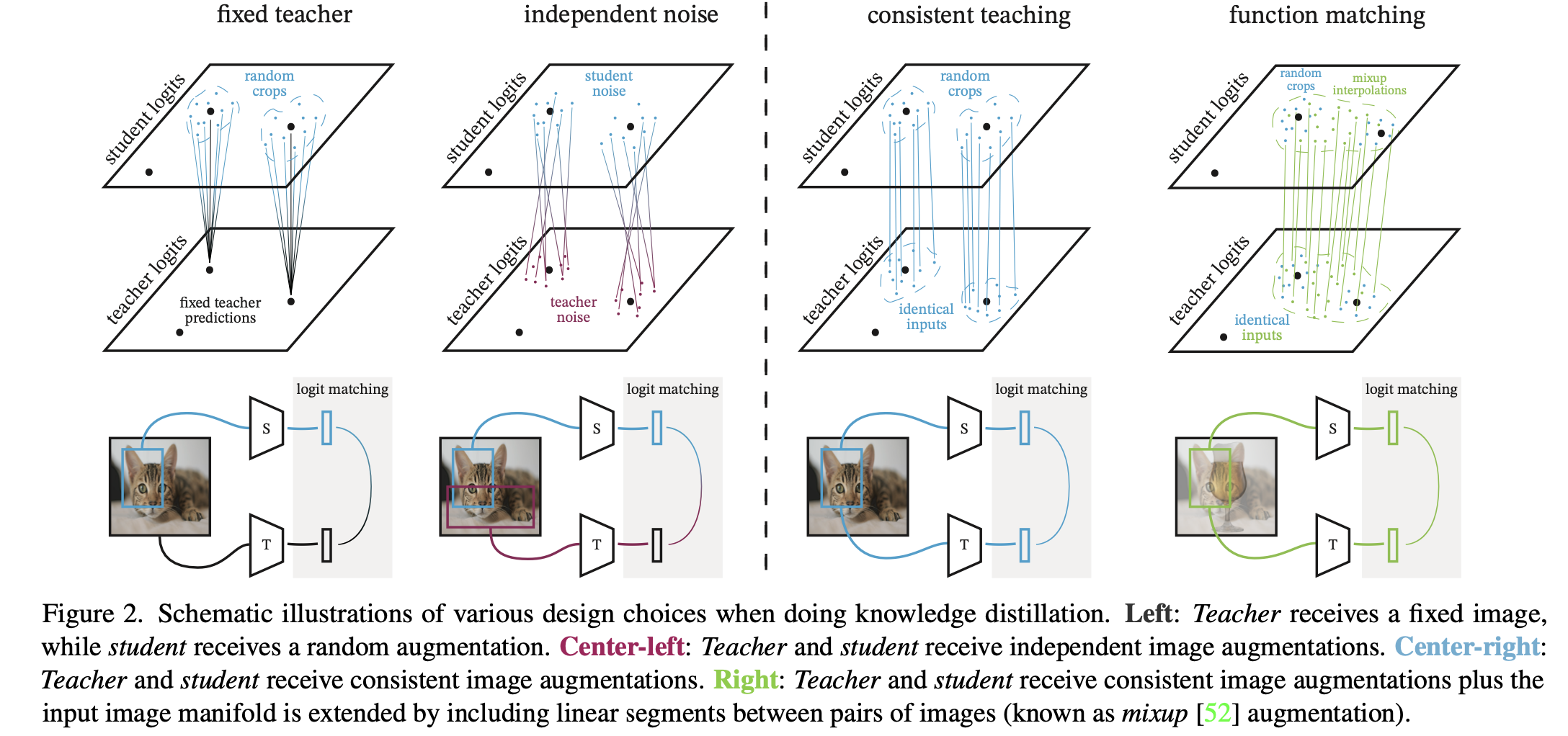
Beyer, Lucas, et al. "Knowledge distillation: A good teacher is patient and consistent." Proceedings of the IEEE/CVF conference on computer vision and
11.[중단] Residual error based knowledge distillation

KD는 model compression을 위한 가장 있는 방법 중 하나이다.key idea는 teacher model(T)의 knowledge를 student model(S)로 전달하는 것이다.그러나 기존 방법들은 S와 T의 학습 능력 간의 큰 차이로 인해 degrad