LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
Paper Info
- Graham, Benjamin, et al. "Levit: a vision transformer in convnet's clothing for faster inference." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
Abstract
-
우리는 high-speed regime(높은 속도 체제)에서 accuracy and efficiency 간의 trade-off를
optimize하는 image classification architecture를 design했다.
우리의 연구는 highly parallel processing hardware에서 경쟁력 있는
attention-based architecture에 대한 recent findings(최신의 발견)을 활용했다.
우리는 CNN에 대한 광범위한 연구에서의 principles들을 다시 검토하여
이를 Transformer에 적용하고,
특히 resolution이 감소하는 activation maps을 도입했다.
또한, Vision transformer에서 positional information을 통합하는 새로운 방식인
attention bias를 도입했다. -
결과적으로,
우리는 fast inference image classification을 위한 hybrid neural network인LeViT를 제안한다.
우리는 다양한 HW platform에서 Efficiency 측정을 고려하여 광범위한 application scenarios를 반영하려고 했다.
우리의 광범위한 실험은 우리의 기술적 선택이 대부분의 architecture에서 적합함을 실증적으로 입증한다.
전반적으로, LeViT는 speed/accuracy tradeoff 측면에서 기존의 ConvNet과 Vision Transformers를 능가한다.
(예를 들어, 80% ImageNet Top-1 acc에서 LeViT는 CPU에서 EfficientNet보다 5배 빠름)
(We release the code at https://github.com/facebookresearch/LeViT)
1. Introduction
-
이 논문에서는 ViT/DeiT model보다
small and medium-sized architectures 영역에서 더 나은 trade-offs를 제공하기 위해 design space를 탐구한다.
우리는 특히 performance-accuracy trade-off,
예를 들어 ImageNet-1K-val에 대한 Figure 1에 나타난
throughput(images/speed) performance를 optimizing하는 데에 관심이 있다.
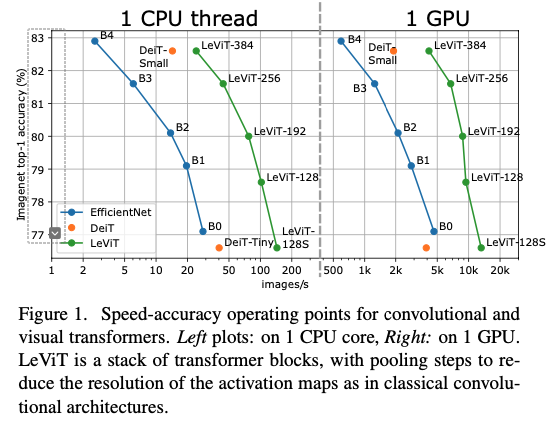
-
많은 연구가 classifier and feature extractors의 memory footprint를 줄이는 것을 목표로 하는 반면,
inference speed도 동일하게 중요하며 high throughput은 better energy efficiency와도 연관된다.
이 연구에서 우리의 목표는
GPU와 같은 고도로 병렬적인 architecture, 일반적인 Intel CPU, mobile device에서 흔히 볼 수 있는 ARM HW에서 더 나은 inference speed를 가진
vision transformer-based family of models을 개발하는 것이다. -
우리의 solution은 Transformer components 대신
convolution-like features(convolution과 유사한 특징)을 학습하는
convolution components를 re-introduce(다시 도입)한다.
특히, 우리는 Transformer의 uniform structure를
LeNet architecture와 유사하게 pooling이 있는 Pyramid로 대체한다.
따라서 우리는 이를 LeViT라고 부른다. -
computational complexity에서 Transformer가 Convolution architectures보다 빠른 이유는 다음과 같은 설득력 있는 이유들이 있다.
대부분의 HW accelerators(GPUs, TPUs)는 large matrix multiplications을 수행하도록 최적화되어 있다.
Transformer에서는 attention과 MLP block이 주로 이러한 연산에 의존한다.
반면에, convolution은 complmex data access pattern을 요구하기 때문에
그 연산은 종종 IO에 의해 제한된다.
이러한 considerations은 speed/accuracy tradeoff를 탐구하는 데 중요하다.
The contributions
- 이 논문의 contirbution은
ViT model을 width and spatial resolution 측면에서
축소할 수 있게 하는 기술들이다.- attention을 downsampling mechanism으로 사용하는 multi-stage transformer architecture
- first layer에서 #features를 줄이는 computationally efficient patch descriptor
- ViT의 positional embedding을 대체하는 학습된, per-head translation-invariant attention bias
- 주어진 compute time 내에서 network capacity를 향상시키는 redesigned Attention-MLP block
2. Related Work
Transformers
(skip)
The vision transformer (ViT)
- Transformer는 Convolution보다 built-in structure가 적고,
특히 인접한 image elements에 집중하는 inductive bias가 없어,
큰 dataset과 강력한 data augmentation이 필요함.
Positional encoding
- transformer는 input을 set(집합)으로 받아들이므로 input 순서에 invariant하다.
하지만 language나 image에서는 input이 순서가 중요한 중요한 구조에서 나온다.
original transformer는 input에 absolute non-parametric positional encoding을 포함한다.
다른 연구에서는 이를 parametric encoding으로 대체하거나,
Fourier-based kernelized version을 채택한다.
Absolute position encoding은 input set의 fixed size를 강제하지만,
일부 연구에서는 token 간의 relative position을 encodeing하는 relative position encoding을 사용한다.
우리의 연구에서는 이러한 명시적인 positional encoding을 spatial information을 암시적으로 encoding하는 positional biases로 대체한다.
Attention along other mechanisms.
-
vision을 위한 neural network architecture에서
attention mechanism을 포함하려는 연구들이 있었다.
mechanism은 channel-wise로 사용되어,
convolution layer를 보완하는 cross-feature information을 capture하거나,
network의 다른 branch에서 path를 선택하거나,
혹은 이 두가지를 결합하는 데에 사용된다.
예를 들어,
the squeeze-and-excite network of Hu et al.은
layer의 feature들 간의 channel-wise relationship을 modeling하기 위한 attention module을 포함하고 있다.
또한, Li et al.[37]은 network branch 간의 attention mechanism을 사용하여
neuron의 receptive field를 적응적으로 조정한다. -
최근에 Transformer의 등장은 다른 Module들의 이점을 누리는 hybrid architecture를 이끌어냈다.
Bello [45]는 positional attention component와 함께 approximated content attention을 제안했다.
Child et al.[23]은 network의 초기 layer가 지역적으로 연결된 pattern을 학습하는 것을 관찰했는데,
이는 convolution과 유사한 pattern이다.
이는 Transformer와 Convolution Network에서 영감을 받은 hybrid architecture가 유명한 design choice임을 시사한다.
몇몇 최근 연구들은 다양한task를 위해 hybrid architecture 방식을 탐구하고 있다.
image classification에서는, Pyramid Visoin Transformer(PVT)가 우리의 연구와 병행하여 발표되었는데,
이는 ResNet에서 영감을 받은 design으로 주로 object 및 instance segmentation task을 처리하기 위해 설계되었다. -
또한 우리의 연구와 동시에,
Yuan et al.은 Tokens-to-Tokens ViT(T2T-ViT) model을 제안했다.
PVT와 유사하게, 이 Model의 설계는 각 layer 후에 output을 re-tokenization하여
주변 token들을 aggregating함으로써 점진적으로 token 수를 줄이는 데 의존한다. -
이러한 최근 방법들은 accuracy and inference time 간의 trade-off에 대해 우리 연구만큼 집중하진 않는다.
그들은 이 Compromise(타협점, 절충안)에 있어서 경쟁력이 없다.
3. Motivation
- 이 section에서는
transformer patch projection layer의 convolutional behavior에 대해 논의할 것이다.
그 다음, standard convolutional architecture(ResNet-50)에 Transformer(DeiT-S)를
"grafting experiments(접목 실험)"을 수행한다.
이 분석을 통해 도출된 결론은 Section 4.에서의 후속 design choices에 대한 동기를 부여했다.
3.1. Convolutions in the ViT architecture
- ViT's patch extractor는 stride 16의 convolution이다.
또한, patch extractor의 output은 학습된 weight에 의해 곱해져 첫 번째 self-attention layer의 q, k, v embedding을 형성하므로,
이를 input의 convolutional functions으로 간주할 수 있다.
이것은 DeiT와 PVT와 같은 variants에서도 마찬가지이다.
Figure 2에서는 attention head별로 나누어진 DeiT의 첫번째 layer의 attention weight를 시각화했다. convolutional architecture의 typical patterns을 관찰할 수 있다.
convolutional architecture의 typical patterns을 관찰할 수 있다.
attention heads는 specific pattern(low-frequency colors/high frequency graylevels)으로 specialize되고, 그 pattern은 Gabor filter와 유사하다.
Convolution masks가 상당히 중첩되는 convolution에서는,
Mask의 spatial smoothness은 중첩으로부터 온다 : 인접 pixel은 대략 동일한 gradient를 받는다.
ViT convolution에서는 중첩이 없다.
smoothness mask는 data augmentation에 의해 발생할 가능성이 크다.
image가 두 번, 약간 translated된 상태로 제시될 때, 동일한 gradient가 각 filter를 통해 전달되어 이 spatial smoothness를 학습한다.
따라서 Transformer architecture에서 "inductive bias"가 없더라도,
training 과정에서 traditional convolutional layers와 유사한 filter가 생성된다.
3.2. Preliminary experiment: grafting
-
ViT image classifier의 저자들은 traditional ResNet-50 위에 transformer layer를 쌓는 실험을 진행했다.
이 경우 ResNet은 transformer layer를 위한 feature extractor로 작동하며,
Gradient는 두 Network를 통해 propagate될 수 있다.
그러나 그들의 실험에서는 transformer layer의 수가 고정되어 있다. (e.g. 12 layers for ViT-Base) -
이 subsection에서는,
유사한 computiational budget 내에서 Transformer와 CNN을 혼합하는 가능성을 조사한다:
우리는 convolutional stage와 transformer layer 수를 변화시킬 때 얻어지는 trade-off를 탐구했다.
우리의 목표는 실행 시간을 제어하면서 convolution과 transformer hybrid의 variations(변형)을 평가하는 것이다.
Grafting.
- 이 grafting 실험은 ResNet-50과 DeiT-Small을 결합하는 것이다.
두 network는 유사한 실행 시간을 갖는다.
우리는 ResNet-50의 상위 stage를 잘라내고,
마찬가지로 DeiT layer수를 줄인다 (transformer와 MLP block수는 동일하게 유지)
잘린 ResNet이 DeiT가 사용하는 activation map보다 더 큰 activation map을 생성하기 때문에,
그 사이에 Pooling layer를 도입했다.
preliminary(예비) experiments에서 average pooling이 가장 잘 작동한다는 것을 발견했다.
positional embedding과 classification token은
convolution layer와 transformer layer stack 사이의 interface에 도입된다.
ResNet-50 stage에는 ReLU activation units과 batch normalization을 사용한다.
Results
-
Table 1에 결과를 요약했다.
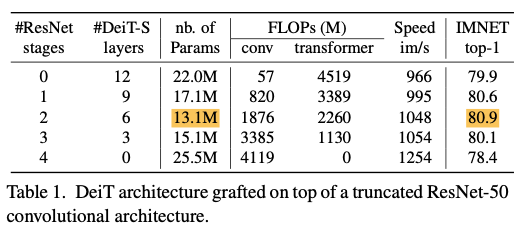 grafted architecture는 DeiT와 ResNet-50 단독 사용보다 더 나은 결과를 보여준다.
grafted architecture는 DeiT와 ResNet-50 단독 사용보다 더 나은 결과를 보여준다.
smallest number of parameters와 best accuracy는 ResNet-50의 두 stage를 사용한 경우에 나타나는데,
이는 ConvNet의 큰 세 번째 stage를 제외하기 때문이다.
이 실험에서 setting은 DeiT와 유사하다 : 300 epoch 동안 training, ImageNet에서 top-1 validation accuracy를 측정하며, GPU가 초당 처리할 수 있는 image 수로 speed를 측정. -
흥미로운 관찰 중 하나는 Figure 3에서 보이는 것처럼,
 grafted model의 training convergence가 초기 epoch에서는 convnet과 유사하고,
grafted model의 training convergence가 초기 epoch에서는 convnet과 유사하고,
이후에는 DeiT-S와 유사한 convergence 속도로 전환된다는 것이다.
hypothesis 중 하나는 conv layer가 초기 Layer에서 low-level information을 더 효율적으로 학습할 수 있는 능력이 있다는 것이다.
이는 강력한 Inductive bias, 특히 translation invariance 덕분이다.
이들은 의미 있는 Patch embedding에 빠르게 의존하며,
이는 초기 epoch 동안의 faster convergence를 설명할 수 있다.
Discussion.
- 실행 시간이 제한된 환경에서는 transformer 아래에 convolution stage를 삽입하는 것이 유리한 것으로 보인다.
grafted architecture의 가장 정확한 variants에서는 대부분의 처리가 여전히 transformer stack에서 이루어진다.
따라서 다음 section의 우선 순위는 transformer의 계산 비용을 줄이는 것이다.
이를 위해 단순히 접목하는 것 대신, transformer architecture를 convolutional stages와 더 밀접하게 merge할 필요가 있다.
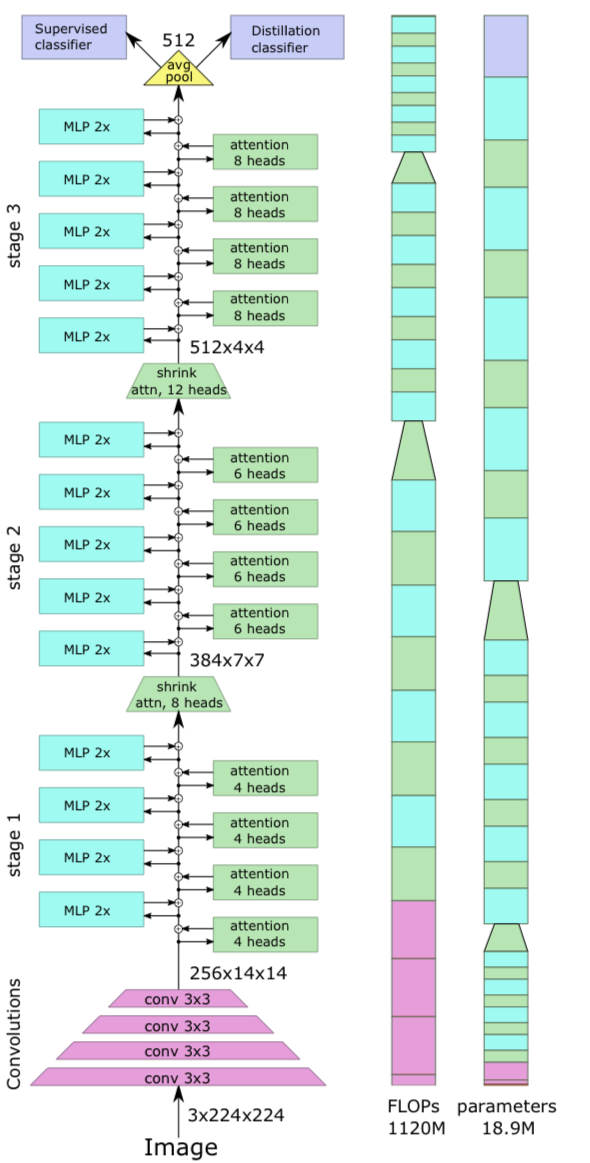
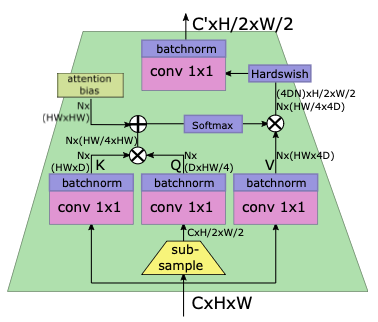
4. Model
- 이 section에서
우리는 LeViT architecture의 design process를 설명하고,
어떠한 tradeoffs를 얻었는지 설명할 것이다.
architecture는 Figure 4.에 요약되어 있다.
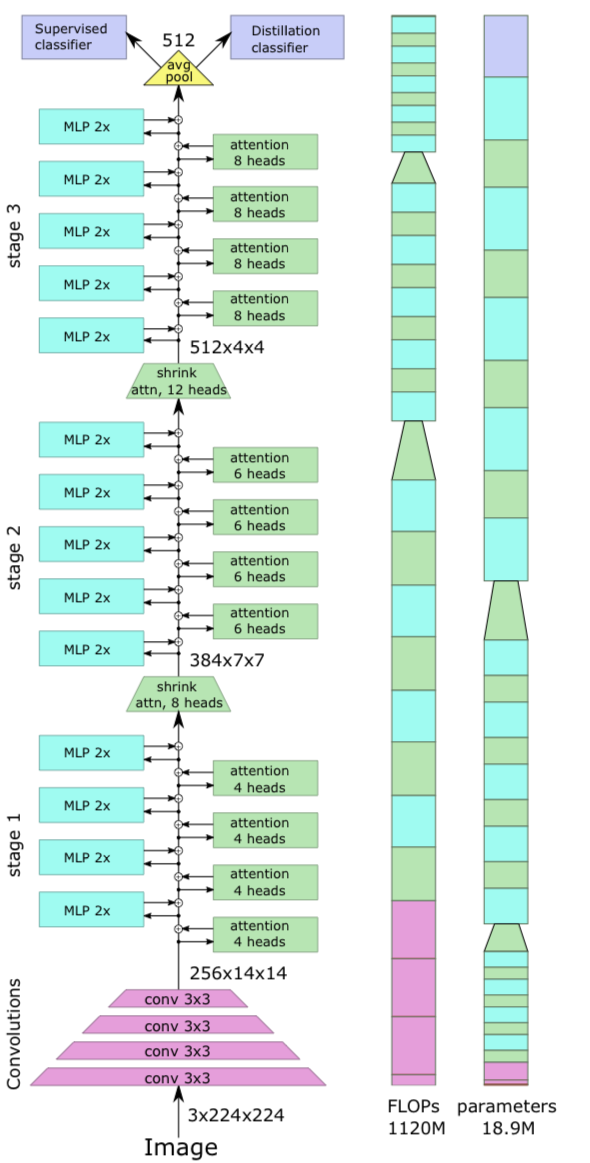
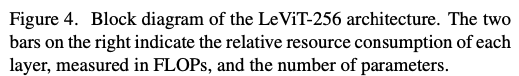
4.1. Design principles of LeViT
-
LeViT는 ViT architecture와 DeiT training method를 기반으로 하며,
convolution architecture에서 유용한 components를 통합한다.
첫 번째 step은 compatible(호환 가능한) representation을 얻는 것이다.
classification embedding의 역할을 제외하고,
ViT는 activation map을 처리하는 layer stack이다.
실제로, intermediate "token" embedding은
FCN architecture(BCHW 형식)에서의 전통적인 activation maps으로 볼 수 있다.
따라서 activation map에 적용되는 operations(pooling, convolution)은
DeiT의 intermediate representation에도 적용될 수 있다. -
이 연구에서는 parameter수를 최소화하는 것이 아니라 computation을 최적화하는 데 초점을 맞춘다.
ResNet family가 VGG network보다 더 효율적인 design decisions 중 하나는
처음 두 stages에서 상대적으로 적은 computation budget으로 강력한 resolution reduction을 적용하는 것이다.
activation map이 ResNet의 big third stage에 도달할 때쯤, resolution은 이미 축소되어
convolution이 작은 activation map에 적용되므로 computational cost가 줄어든다.
4.2. LeViT components
Patch embedding
-
Section 3에서 preliminary analysis는
small convnet을 transformer stack의 input에 적용할 때 accuracy가 향상될 수 있음을 보여줬다. -
LeViT에서는 input에 4개의 conv layer(stride 2)를 적용하여
resolution 축소를 수행하기로 결정했다.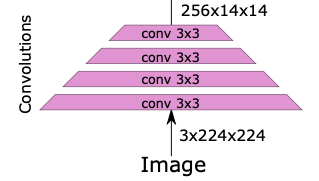 channel수는 으로 증가한다.
channel수는 으로 증가한다.
이는 중요한 정보를 잃지 않으면서 transformer의 하위 layer로 들어가는 activation map input을 축소한다.
LeViT-256을 위한 patch extractor는
image shape 를 로 변환하여 184MFLOPs를 소모한다.
(비교를 위해 ResNet-18의 처음 10개 layer는 동일한 dimensionality reduction를 1042MFLOPs로 수행한다.)
No classification token
- tensor format을 사용하기 위해,
우리는 classification token을 제거했고,
CNN과 유사하게, last activation map에 대한 average pooling으로 교체하였다.
 training 동안에 distillation을 위해서,
training 동안에 distillation을 위해서,
우리는 classification과 distillation task를 위한 separate heads를 train시켰다.
test 시에는 두 head의 output을 평균화한다.
실제로, or tensor format을 사용하여 구현될 수 있으며, 더 효율적인 것을 선택하면 된다.
Normalization layers and activations
-
ViT architecture의 FC layer는 conv와 동일하다.
-
ViT는 각 atetention and MLP unit 이전에 LayerNorm을 적용하는 반면,
LeViT는 각 convolution 후에 BN을 수행한다.
[54]에 따라,
residual connection과 결합되는 BatchNorm의 weight parameter를 0으로 initialized한다.
inference를 위해 BatchNorm을 convolution과 병합하여
LayerNomr 보다 runtime에서의 이점이 된다. -
DeiT는 GELU function을 사용했지만,
LeViT의 모든 non-linear activations은 Hardswish이다.
Multi-resolution pyramid
-
convolutional architectures는 pyramid로 구축되며,
처리 중에 activation maps의 resolution이 줄어들면서 channel 수가 증가한다.
Section 3에서 우리는 ResNet-50 stages를 사용하여 transformer stack을 pre-process했다. -
LeViT는 transformer architecture 내에 ResNet stages를 통합한다.
stage 내부의 architecture는 visual transformer와 유사하다 :
a residual structure with alternated MLP and activation blocks.
다음으로 우리는 classical set과 비교하여
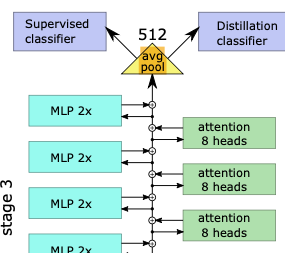
attention blocks(Figure 5)의 modifications을 review할 것이다.
Downsampling.
- LeViT stage 사이에,
activation map의 size를 줄이기 위해 shrinking attention block을 사용했다 :
transformation(변환) 전에 subsampling을 적용하고,
이는 soft activation의 output으로 propagate된다.
이는 의 input tensor size를 인 output tensor로 mapping하며,
여기서 는 보다 크다.
 scale의 변화로 인해,
scale의 변화로 인해,
이 attention block은 residual connection 없이 사용되었다.
정보 손실을 예방하기 위해서,
우리는 attention head의 수를 로 설정했다.
Attention bias instead of a positional embedding.
-
positional embedding은 attention block sequence의 input에만 포함된다.
따라서 positional encoding이 상위 layer에서도 중요하기 때문에,
이는 intermediate representations에서도 유지되며 불필요하게 representation capacity를 사용하게 된다. -
따라서 우리의 목표는 각 attention block 내에 positional information을 제공하고,
attention mechanism에 명시적으로 relative position information을 주입하는 것이다 :
우리는 단순히 attention maps에 attention bias를 추가했다.
두 pixel 와 사이의
하나의 head 에 대한 scalar attention value는 다음과 같이 계산된다.
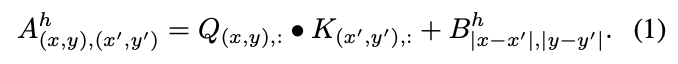 첫 번째 term은 classical attention이다.
첫 번째 term은 classical attention이다.
두 번째 term은 translation-invariant attention bias이다.
각 head는 서로 다른 pixel offsets에 대응하는 parameter를 갖는다.
differences and $y-y'을 symmetrizing(대칭화)하면
model이 flip invariance를 가지고 학습하도록 유도된다.
Smaller keys.
- bias term은 key들이 location information을 encoding해야 하는 부담을 줄여주므로,
value matrix 에 비해 key matrices 와 의 size를 줄일 수 있다.
Key의 size를 제한하면, matrix product 를 계산하는 데 필요한 시간이 줄어든다.
Key의 size가 인 경우, 는 2D channels을 갖도록 구성했다.
residual connection이 없는 downsampling layer의 경우,
정보 손실을 방지하기 위해 의 dimension을 로 설정했다.
Attention activation.
- 서로 다른 heads의 output들을 combine하는 데에 사용되는 regular linear projection을 하기 전에
product 에 Hardswish activation을 적용했다.
이는 ResNet bottleneck residual block과 유사한데,
가 convolution의 output이고,
가 spatial convolution에 해당하며,
projection이 또 다른 convolution이기 때문이다.
Reducing the MLP blocks.
- ViT의 MLP residual block은 embedding dimension을 4배로 증가시키는
linear layer로 시작하여 non-linearity를 적용하고
다시 다른 non-linearity를 통해 원래 embedding의 dimension으로 축소시킨다.
vision architecture에서는 MLP가 주로 실행 시간과 parameter 측면에서 더 비용이 많이 든다.
LeViT에서는 "MLP"가 conv로 대체되며, 일반적인 BN이 이어진다.
이 단계의 computational cost를 줄이기 위해, 우리는 convolution의 expansion factor를 에서 로 줄였다.
우리의 design 목표는 attention과 MLP block이 거의 동일한 수의 FLOP을 사용하는 것이다.
4.3. The LeViT family of models
- LeViT model은 computation stage의 size를 변화시킴으로써
다양한 speed-accuracy tradeoff를 생성할 수 있다.
우리는 이들을 첫 번째 transformer에 입력되는 channel 수로 식별한다.
예를 들어, LeViT-256은 transformer 단계에 입력되는 channel 수가 256개인 model을 의미한다.
Table 2는 이 논문에서 평가했던 model들이 어떤 stages로 design되어있는지 보여준다.


5. Experiments
