[Simple Review] CoAtNet: Marrying Convolution and Attention for All Data Sizes
Paper Info.
- Dai, Zihang, et al. "Coatnet: Marrying convolution and attention for all data sizes." Advances in neural information processing systems 34 (2021): 3965-3977.
Abstract
-
Transformer는 computer vision 분야에서 점점 많은 관심을 받고 있지만, 여전히 CNN보다는 성능이 뒤처진다.
이 연구에서는 Transformer가 model capacity는 더 크지만, 적절한 inductive bias의 부족으로 인해 generalization 성능이 CNN보다 나쁠 수 있음을 보여준다. -
두 가지 architecture의 강점을 효과적으로 결합하기 위해, 우리는 CoAtNets(CoAt는 "코트"라고 발음)라는 hybrid model을 제시.
CoAtNets는 두 가지 주요 insight에 기반을 두고 있다.- Depthwise Convolution과 Self-Attention은 간단한 상대적 Attention을 통해 자연스럽게 통합될 수 있다.
- Convolution layer와 attention layer를 수직적으로 쌓는 것은 generalization, capacity, efficiency를 놀랍도록 효과적으로 향상시킨다.
-
실험 결과, CoAtNets는 다양한 dataset에서 resource constraints 없이 SOTA 성능을 달성했습니다.
- 아무 data 없이, 86% ImageNet top-1 accuracy
- ImageNet-21K의 13M images로 Pretrain한 경우, 88.56% top-1 accuracy
- JFT-3B로 확장하면 ImageNet에서 90.88%의 top-1 accuracy를 달성하여 새로운 SOTA를 달성함.
1. Introduction
-
AlexNet 이후, ConvNets은 computer vision에서 지배적인 model architecture가 되었다.
한편, NLP 분아야서 Transformer와 같은 self-attention model의 성공으로 많은 이전 연구들이 attention을 computer vision으로 가져오려고 시도했었다.
최근에는 Vision Transformer(ViT)가 vanilla Transformer layer만으로도 ImageNet-1k에서 합리적인 성능을 얻을 수 있음을 보여줬다.
더 중요한 점은, large-scale weakly labeled JFT-300M dataset에서 pretrain한 경우, ViT가 SOTA ConvNets과 견줄만한 결과를 얻어,
Transformer model이 ConvNets보다 더 높은 capacity를 가질 수 있음을 나타냈다. -
ViT가 방대한 JFT-300M training images를 사용한 인상적인 결과를 보여주었지만, 낮은 data 환경에서는 여전히 ConvNets보다 성능이 떨어진다.
후속 연구들은 기본 ViT를 개선하기 위해 special regularization and stronger data augmentation을 사용했지만,
이러한 ViT variants model들은 동일한 양의 data와 computation 자원 하에서 ImageNet classification에서 SOTA convolution-only models을 능가하지 못했다.
이는 vanilla Transformer layer가 ConvNets가 가진 특정 inductive bias가 부족하며,
이를 보완하기 위해 상당한 양의 data와 computation 자원이 필요함을 시사한다.
예상할 수 있듯이, 많은 최근 연구자들은 Transformer model에 ConvNets의 Inductive bias를 통합하려고 노력하고 있다.
예를 들어,
attention layer에 local receptive fields를 부여하거나,
attention 및 FFN layer에 암묵적 또는 명시적인 convolution 연산을 추가하는 방법이 등이 있었다.
하지만 이러한 접근법들은 임시적이거나 특정 속성을 주입하는 데 집중되어 있으며, convolution과 attention이 결합될 때 각각의 역할에 대한 체계적인 이해가 부족한 상태이다.
- 이 연구에서,
우리는 generalization과 model capacity라는 machine learning의 두 가지 근본적인 측면에서
convolution과 attention을 hybridizing(결합하는) 문제를 체계적으로 연구한다.
연구 결과에 따르면,
conv layer는 강력한 inductive bias 덕분에 빠른 convergence 속도로 더 나은 generalization 성능을 보이는 반면,
attention layer는 더 큰 dataset에서 더 높은 model capacity를 가지고 있다.
convolution과 attention layer를 결합하면 더 나은 generalizatio과 capacity를 달성할 수 있지만,
여기서 중요한 과제는 accurac와 efficiency 간의 균형을 맞추기 위해 이를 효과적으로 결합하는 방법이다.
논문에서는 두 가지 주요 insight를 조사한다.
- 일반적으로 사용되는 Depthwise Convolution이 간단한 relative attention을 통해 attention layer에 효과적으로 통합될 수 있다는 점을 관찰했다.
- convolution과 attention layer를 적절한 방식으로 단순히 쌓는 것이 더 나은 generalization과 capacity를 달성하는 데 상당히 효과적일 수 있다.
이러한 insight 바탕으로 ConvNets과 Transformers의 장점을 모두 누릴 수 있는 간단하면서도 효과적인 network architecture인 CoAtNet을 제안한다.
2. Model
- 이 section에서,
우리는 어떻게 "최적으로" convolution과 transformers를 결합할 것인가에 대한 질문에 집중할 것이다.
대략적으로 말하면, 우리는 질문에 대해 2가지 parts로 나누었다.
- How to combine the convolution and self-attention within one basic computational block?
- Hwo to vertically stack different types of computational blocks together to form a complete network?
이 나눔에 대한 합리성은 우리의 design choices를 점차적으로 밝히면서 더 명확해질 것이다.
2.1 Merging Convolution and Self-Attention
- Convolution에 대해서는 주로 MBConv Block(
MoBileNetV2 Conv Block)에 집중한다.
이는 spatial interaction을 포착하기 위해 depthwise convolution을 사용한다.
이 선택의 주요 이유는 Transformer의 FFN module과 MBConv 모두 "inverted bottleneck" design을 사용한다는 점이다.
이는 input channel 크기를 먼저 4배로 expansion하고,
나중에 4x-wide hidden state를 원래 channel 크기로 다시 projection하여 residual connection을 가능하게 한다.
inverted bottleneck의 similarity 외에도,
depthwise convolution과 self-attention이 사전 정의된 receptive field에서 값의 dimension별 weighted sum으로 표현될 수 있다는 점들을 주목한다.
구체적으로, convolution은 고정된 kernel을 사용하여 local receptive field에서 정보를 수집한다.
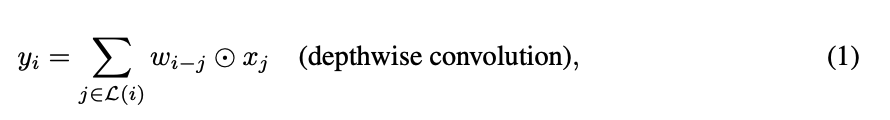 여기서 는 각각 위치 에서의 input과 output이며,
여기서 는 각각 위치 에서의 input과 output이며,
는 주변의 local neighborhood, 예를 들어 image 처리에서 를 중심으로 한 grid를 나타낸다.
대조적으로 ,
self-attention은 receptive field를 global spatial space로 설정하고, ()쌍 사이의 re-normalized된 쌍별 similarity를 기반으로 weight를 계산한다.
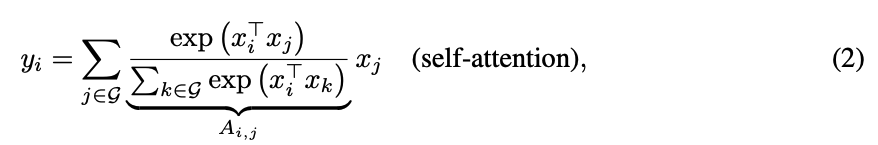 여기서 는 global spatial space를 나타낸다.
여기서 는 global spatial space를 나타낸다.
이것들을 최적으로 결합하는 방법에 대한 질문에 들어가기 전에,
Depthwise Convolution과 Self-Attention의 상대적인 강점과 약점을 비교하는 것이 가치가 있다.
이를 통해 유지하고자 하는 좋은 특성을 파악할 수 있다.
- 첫번째로,
depthwise convolution kernel 은 input-independent parameter of static value인 반면,
attention weight 는 input의 representation에 동적으로 의존한다.
따라서 self-attention은 서로 다른 spatial position 간의 complicated relational interactions(복잡한 상호작용)을 포착하기 훨씬 쉽다.
이는 high-level concepts을 처리할 때 바람직한 특성이다.
그러나 이러한 flexibility는 특히 data가 제한될 때 overfitting의 위험을 수반한다. - 두번째로,
어떤 위치 쌍 ()가 주어졌을 때, 해당하는 convolution weight 는 나 의 특정 값보다는 그들 간의 상대적 이동인 에만 관심을 갖는다.
이 특성은 종종 translation invariance라고 불리며, 이는 크기가 제한된 dataset에서 generalization을 개선하는 것으로 밝혀졌다.
absolution positional embeddings를 사용하는 standard Transformer(ViT)는 이 특성을 갖추지 못했다.
이것이 ConvNets가 dataset이 엄청나게 크지 않은 경우 Transformer보다 일반적으로 더 나은 성능을 보이는 이유의 일부를 설명한다. - 마지막으로,
receptive field의 크기는 self-attention과 convolution 간의 가장 중요한 차이점 중 하나이다.
일반적으로 큰 receptive field는 더 많은 context 정보를 제공하여 더 높은 model capacity를 가능하게 한다.
따라서 global receptive field는 vision 분야에서 self-attention을 사용하는 주요 동기가 되어왔다.
그러나 큰 Receptive field는 상당히 더 많은 계산을 필요로 한다.
global attention의 경우, spatial size에 대해 complexity가 2차적으로 증가하기 때문에,
이는 self-attention model을 적용할 때의 근본적인 trade-off가 되어왔다.
- 첫번째로,
- 위 비교를 바탕으로,
이상적인 model은 Table 1.에서 제시된 3가지 바람직한 특성을 결합할 수 있어야 한다.
 Eqn. (1)의 Depthwise Convolution과 Eqn. (2)의 self-attention의 유사한 형태를 고려할 때,
Eqn. (1)의 Depthwise Convolution과 Eqn. (2)의 self-attention의 유사한 형태를 고려할 때,
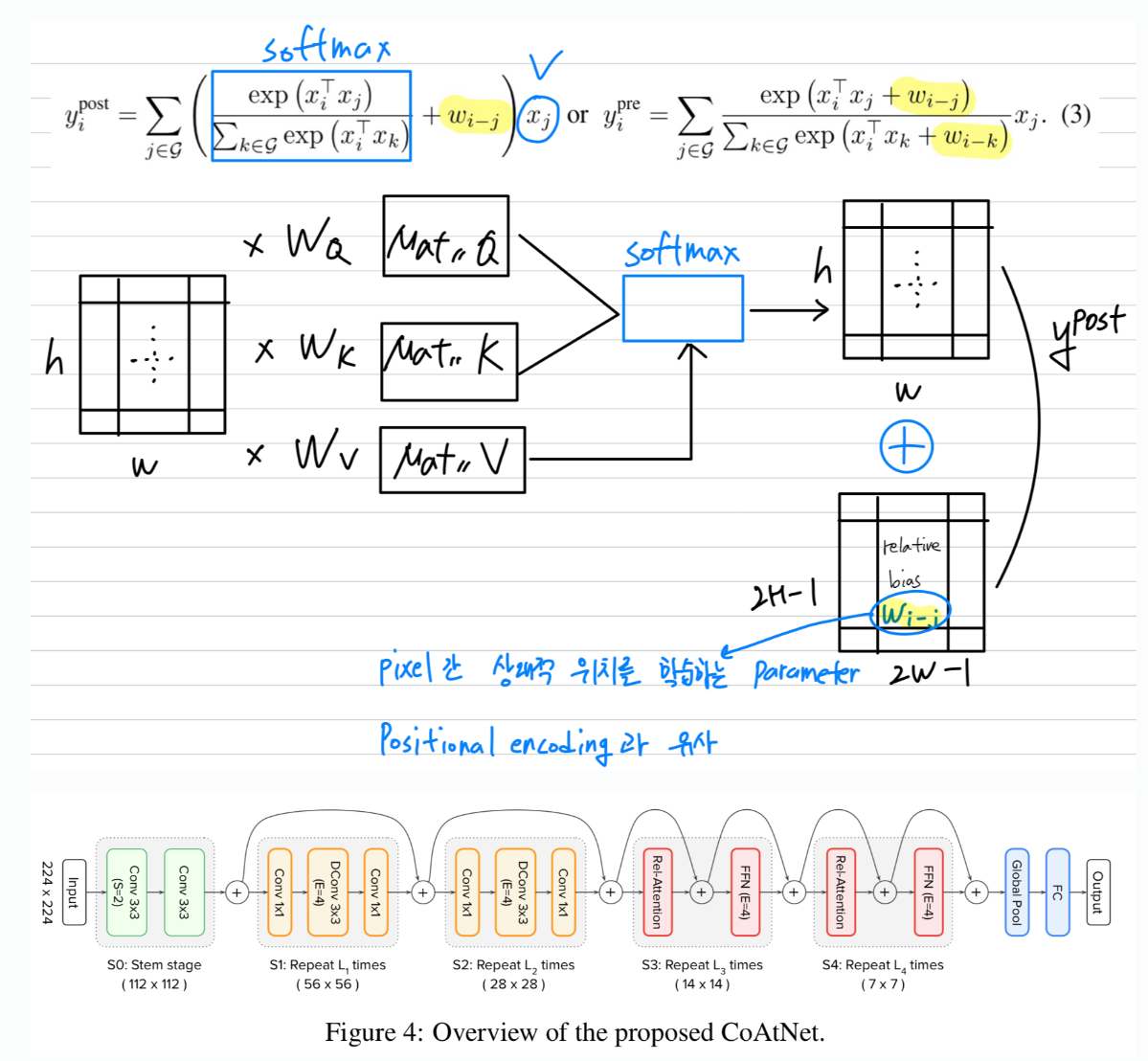
이를 달성할 수 있는 간단한 아이디어는 global static convolution kernel을 adaptive attention matrix와 Softmax normalization 전후에 단순히 합산하는 것이다.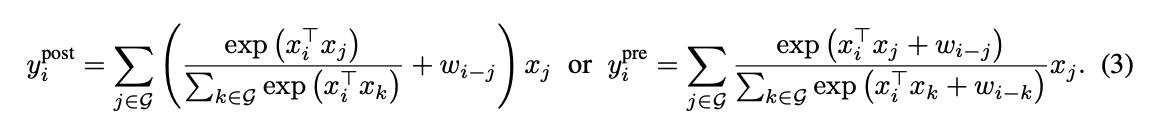 놀랍게도, 이 아이디어는 지나치게 단순화된 것처럼 보이지만,
놀랍게도, 이 아이디어는 지나치게 단순화된 것처럼 보이지만,
Pre-normalization version인 는 특정한 변형의 상대적 self-attention에 해당한다.
이 경우, attention weight 는 translation equivalence 와 input-adaptive 이 함께 결정되며,
이러한 특성을 그들의 상대적인 크기에 따라 모두 효과를 볼 수 있다. (?)
중요한 점은, Parameter 수를 급증시키지 않으면서 global convolution kernel을 가능하게 하기 위해,
Eqn (1)의 를 vector가 아닌 scalar로 다시 정의했다. (즉, ).
의 scalar 공식화의 장점 중 하나는 모든 에 대한 를 검색하는 것이
pairwise dot-product attention을 계산함으로써 명확하게 포함되므로 추가 비용이 최소화된다는 것이다.
이러한 이점을 고려하여, 제안된 CoAtNet model의 핵심 구성 요소로 Eqn. (3)의 pre-normalization relative attention variant가 있는 Transformer block을 사용할 것이다.
(이를 Relative-Attention Block이라고 하는듯)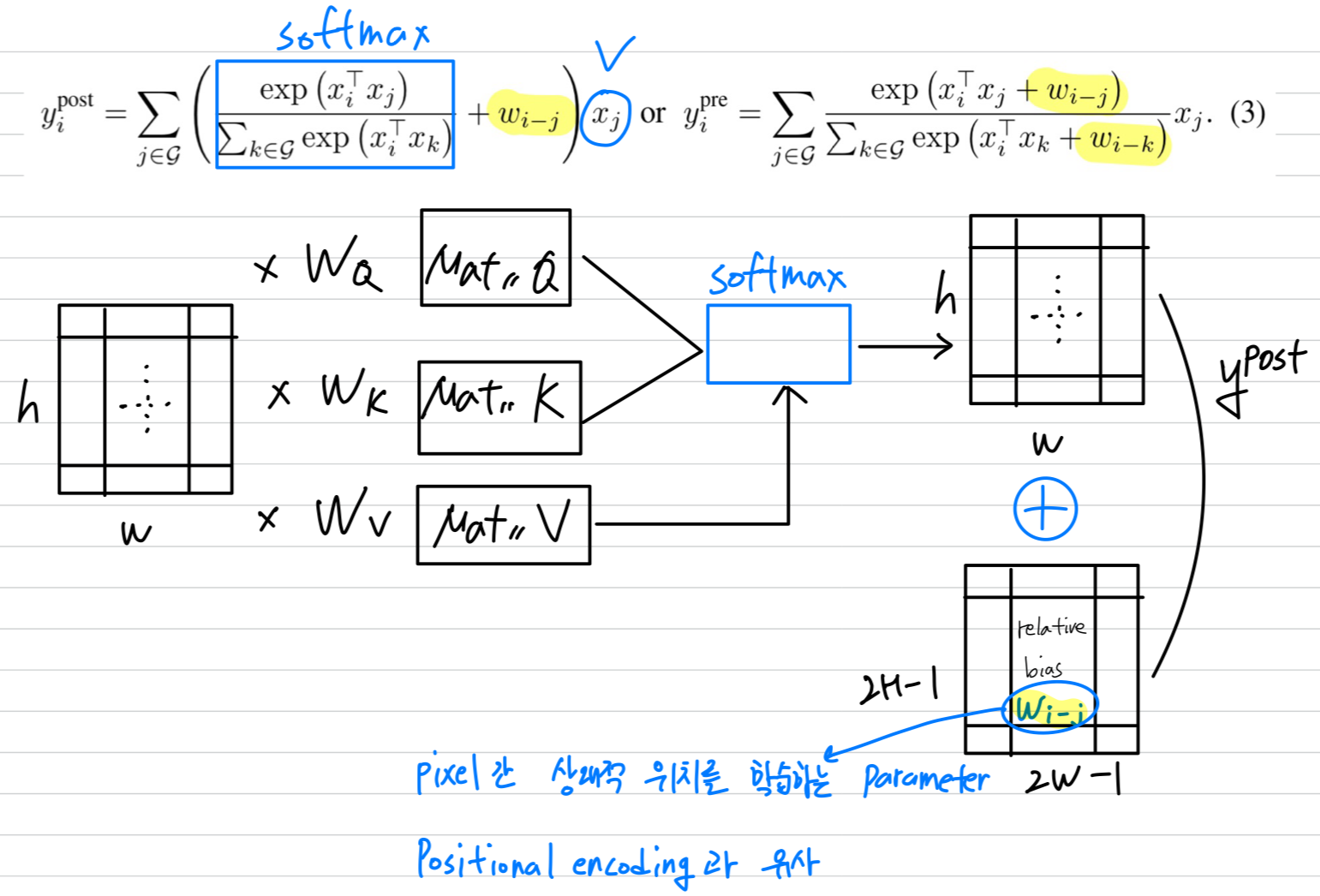
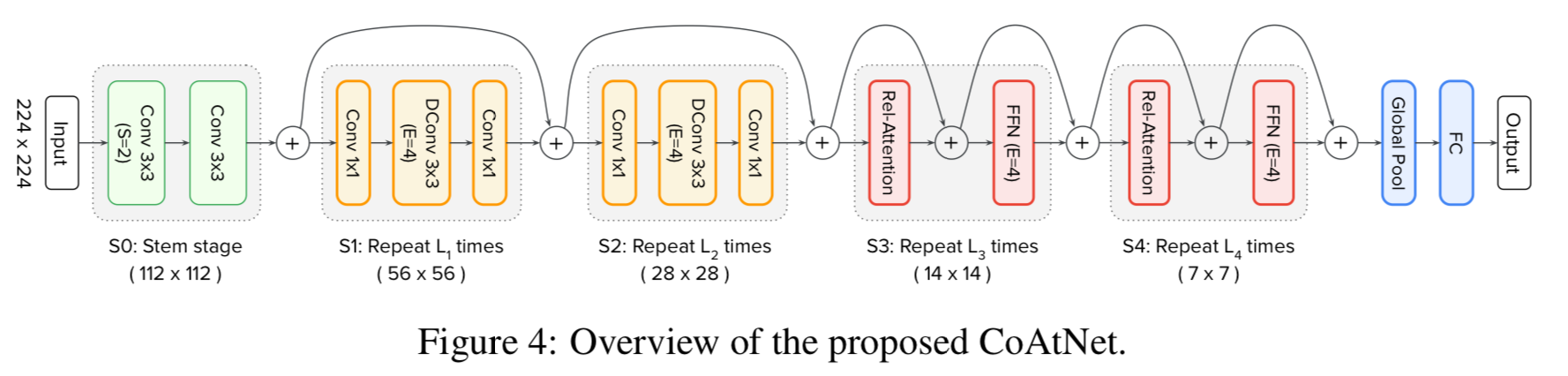
2.2 Vertical Layout Design
- convolution과 attention을 결합하는 깔끔한 방법을 알아낸 후, 전체 Network를 stack하는 방법을 고려할 것이다.
앞서 말했듯이 global context는 spatial size에 대해 quadratic complexity를 갖는다.
따라서 Eqn. (3)의 relative attention을 raw image에 직접 적용하면,
일반적인 크기의 image에서 많은 pixel 수 때문에 계산이 지나치게 느려진다.
따라서 실용적으로 사용 가능한 network를 구성하기 위해 3가지 주요 옵션을 고려한다 :- (A) : spatial size를 줄이기 위해 down-sampling을 수행하고, Feature map이 관리 가능한 수준에 도달한 후 global relative attention을 사용
- (B) : attention에서 global receptive field 를 convolution에서와 같이 local field 로 제한하는 local attention을 적용
- (C) : spatial size에 대해 linear complexity만 갖는 특정 linear attentino variant로 quadratic Softmax attention을 대체한다.
- option (C)를 간단히 실험해봤으나, 좋으 ㄴ결과를 얻지 못함.
option (B)의 경우, local attention을 구현하는 데에 많은 non-trivial shape formatting operations이 필요하며,
이는 집중적인 memory access를 요구한다.
따라서 우리는 option (A)에 집중 구현하여 empirical study(Section 4.)에 다른 결과들과 비교할 것이다.
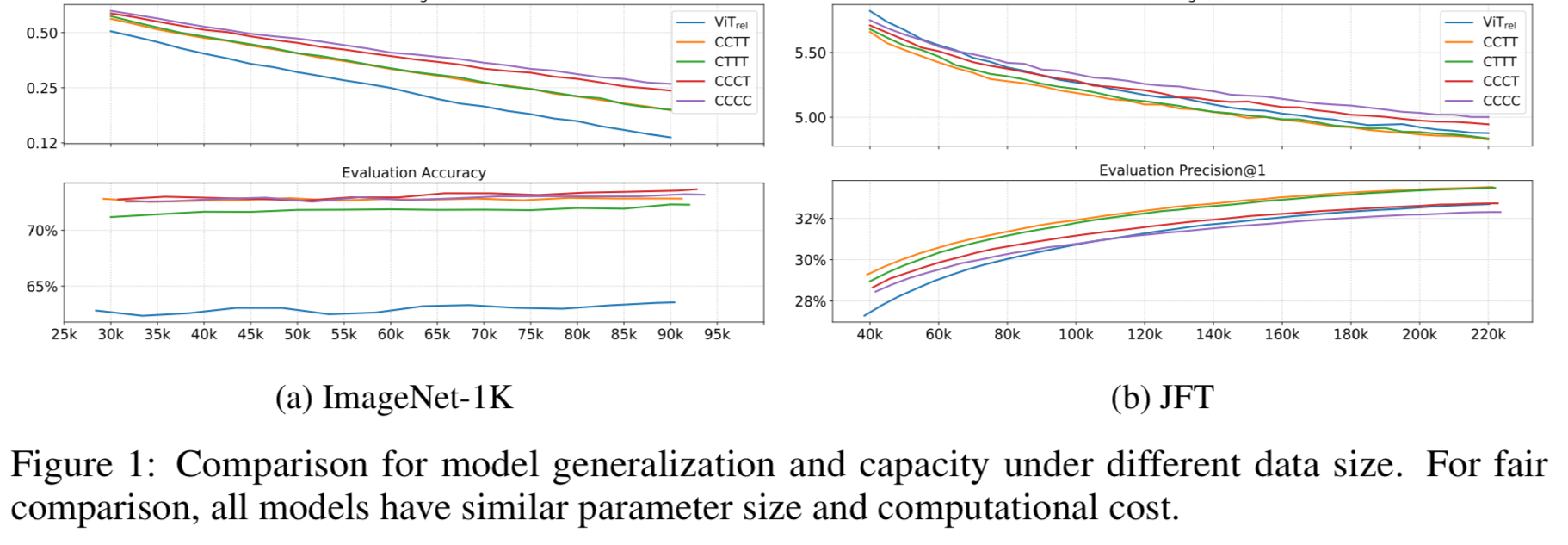
- generalization과 model capacity를 비교하기 위해서,
우리는 ImageNet-1K와 JFT Dataset에 대해서 hybrid models의 variants를 training해볼 것이다.
(C and T denote Convolution and Transformer repectively.)
몰랐던 개념
relative attention:
참고자료
내 생각
핵심은
Convolution의 inductive bias로 인한 Generalization 장점과
Transformer의 global context를 파악할 수 있다는 점, model capacity를 높일 수 있다는 장점을
결합하고 각각의 특징(단점)에 대한 Trade-off를 적절히 조절할 수 있는 classification architecture를 제안했다는 점이다.
이러한 hybrid architecture는 앞서 말한 두 CNN과 Transformer의 장점을 적절히 사용한다면 분명한 강점이 있을 것 같아서 후속 연구가 활발히 진행될 것 같다.
추가로 결합했을 때 기대되는 효과로 intuition 말고, 각각에 대한 자세한 효과를 논리적(수식 필요)으로 입증하는 논문이 나왔으면 좋겠다.
