[2017 NIPS] Learning Efficient Object Detection Models with Knowledge Distillation
이 논문을 읽게 된 이유는 object detector의 knowledge distillation 관련한 연구를 진행하고 있는데 도움이 필요하기 때문...
teacher model의 bbox prediction을
student model이 유사하게 학습하도록 KL Divergence Loss를 사용하려고 하는데,
어떻게 해야 잘 training이 될 수 있는지 공부하기 위해서 관련 논문들을 찾다가 이 논문을 찾게 되었다.
Paper Info
- Authors : Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, Manmohan Chandraker
- subject : NIPS 2017
- link : https://proceedings.neurips.cc/paper/2017/hash/e1e32e235eee1f970470a3a6658dfdd5-Abstract.html
Abstract
-
model compression과 같은 노력은 더 적은 parameter로 compact model을 학습하지만,
이는 정확도가 크게 감소한다. -
이 연구에서
knowledge distillation 및 hint learning을 사용하여
개선된 accuracy를 가진 compact하고 빠른 object detection networks를 학습하는 새로운 framework를 제안할 것이다. -
우리는
class imbalance를 해결하기 위한 weighted cross-entropy loss,
regression component 처리를 위한 teacher bounded loss및
intermediate teacher distribution에서 더 나은 학습을 위한 adaptive layer와 같은
여러 혁신을 통해 이를 해결했다.
1 Introduction
-
CNN으로 object detection에 많은 발전이 있었다.
하지만 many application을 위해서는 speed가 key component인데,
아직 real-time으로부터는 거리가 멀다. -
model compression을 통한 classification works들은 매우 큰 speed-up을 보였지만,
여전히 original and compressed models 사이의 accuracy gap이 존재한다. -
반면에 knowledge distillation에 대한 거시적인 연구들은 깊거나 복잡한 model의 행동을
모방하도록 훈련된 얕거나 압축된 model이 accuracy의 하락의 일부 또는 전체를 회복할 수 있다는 것을 보여줬다. [3, 20, 34]
하지만 이 결과는 모두 classification에서만 해당되는 내용이다. -
distillation technique을 multi-class object detection에도 적용하는 것은 몇 가지 이유로 challenging하다.
- compression으로 인해, detection model의 성능이 저하된다.
- 각 class가 동등하게 중요하다고 가정하여 classification을 위한 knowledge distillation이 제안되었지만,
detection에서는 background class가 훨씬 더 흔하기 때문에 그렇지 않다. - detection은 classification과 bounding box regression의 요소를 결합한 더 복잡한 task이다.
- 우리는 동일한 domain 내에서 knowledge를 transferring하는 데 중점을 두는 반면,
다른 연구들은 다른 domain의 data에 의존할 수 있다. (?)
-
위 challenge들을 처리하기 위해서,
우리는 knowledge distillation을 이용한 object detection을 위한 빠른 model을 train시키는 방법을 제안할 것이다.
우리의 contribution은 네 가지로 구성된다 :- 우리는
knowledge distillation을 통해
compact multi-class object detection model을 학습하기 위한
end-to-end trainable framework를 제안한다.(Section 3.1) - 우리는 새로운 loss를 제안한다.
특히, 우리는 background class와 object class 간에 misclassification의 영향이
불균형하게 작용하는 것을 고려한 classification을 위한weighted cross entropy(Section 3.2)를 제안한다.
또한knowledge distillation을 위한 teacher bounded regression loss(Section 3.3) 및
hint learning을 위한 adaptive layers(Section 3.4)를 제안한다. - 우리는 여러 대규모 public benchmark를 사용하여 포괄적인 경험적 평가를 수행함.
모든 benchmark에서 일관되게 압축된 빠른 network를 사용하여 object detection accuracy가 상당히 향상되었다는 것을 보여줌. (Section 4.1 - 4.3). - 우리는 우리의 framework의 행동의 일반화와 underfitting 문제와 관련시켜 이해를 제시함. (Section 4.4)
- 우리는
2 Related Work
Knowledge Distillation
- Knowledge distillation은 model compression을 통해 accuracy를 유지하는 또 다른 방법이다.
- Bucila et al.[3]은 여러 model의 출력을 모방하는 single neural network를 train하는 알고리즘을 제안한다.
- Ba and Caruana [2]는 [3]의 idea를 채택하여 network를 더 얕고 넓은 향태로 압축하는데,
여기서 압축된 model은 'logits'을 모방한다. - Hinton et al. [20]은 [3]보다 일반적인 case인 knowledge distillation을 제안하는데,
여기서 teacher model의 prediction을 'soft label'로 적용하고,
L2 loss 대신 temperature cross entropy loss를 제안한다. - Romero et al. [34]은 network를 훈련하기 위한 two-stage strategy를 소개한다.
그들의 방법에서 teacher layer의 middle layer는 student model의 훈련을 안내하기 위한 'hint'를 제공한다.
3 Method
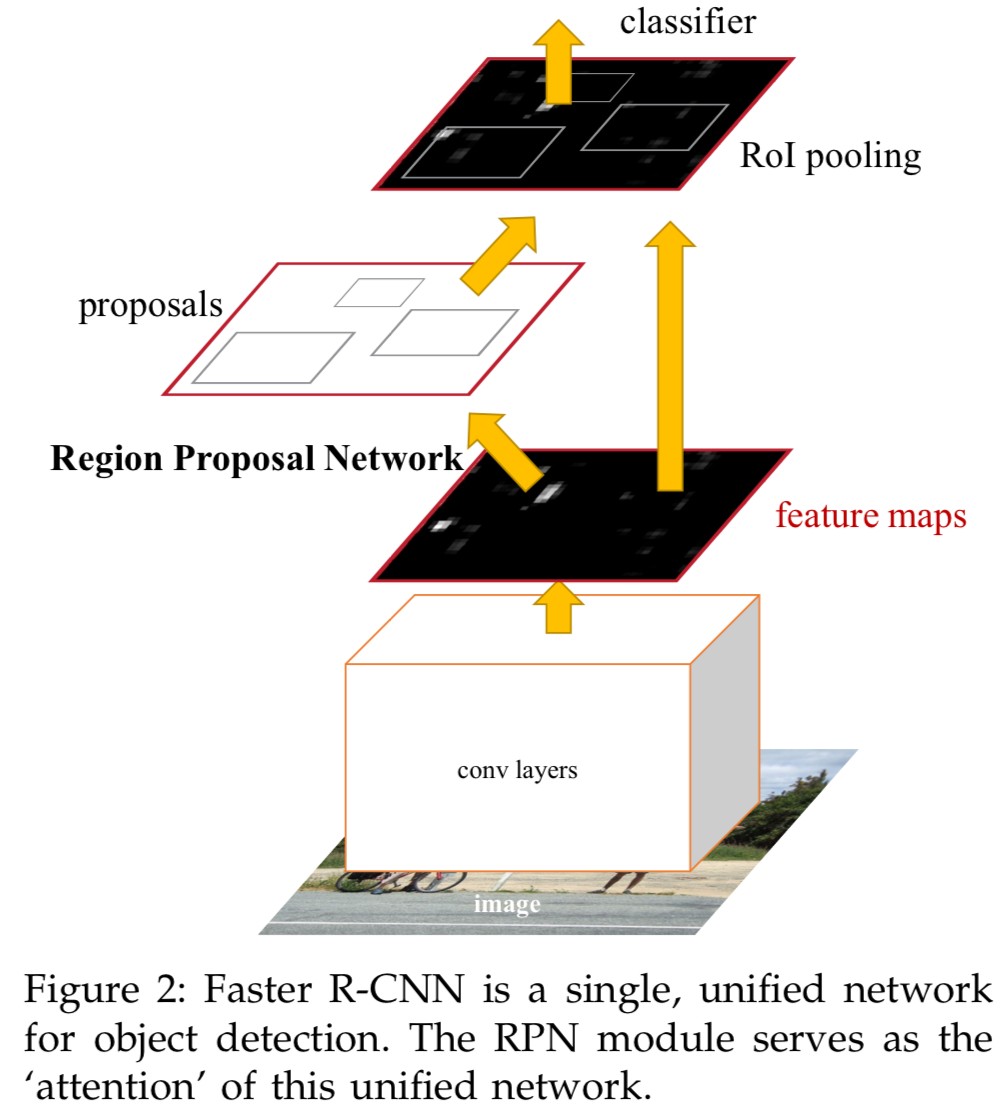
- 이번 연구에서, 우리는 Faster R-CNN을 object detection framework로 채택했다.
Faster-RCNN은 세 가지 module로 구성된다.- convolution layer를 통한 shared feature extraction
- object proposals을 생성하는 a region proposal network(RPN)
- 각 object proposal에 대한 detection score와 spatial adjustment vector를 반환하는 classification 및 regression network(RCN).
RCN과 RPN은 1)의 output을 모두 feature로 사용하며,
RCN은 또한 RPN의 output을 input으로 사용한다.
3.1 Overal Structure
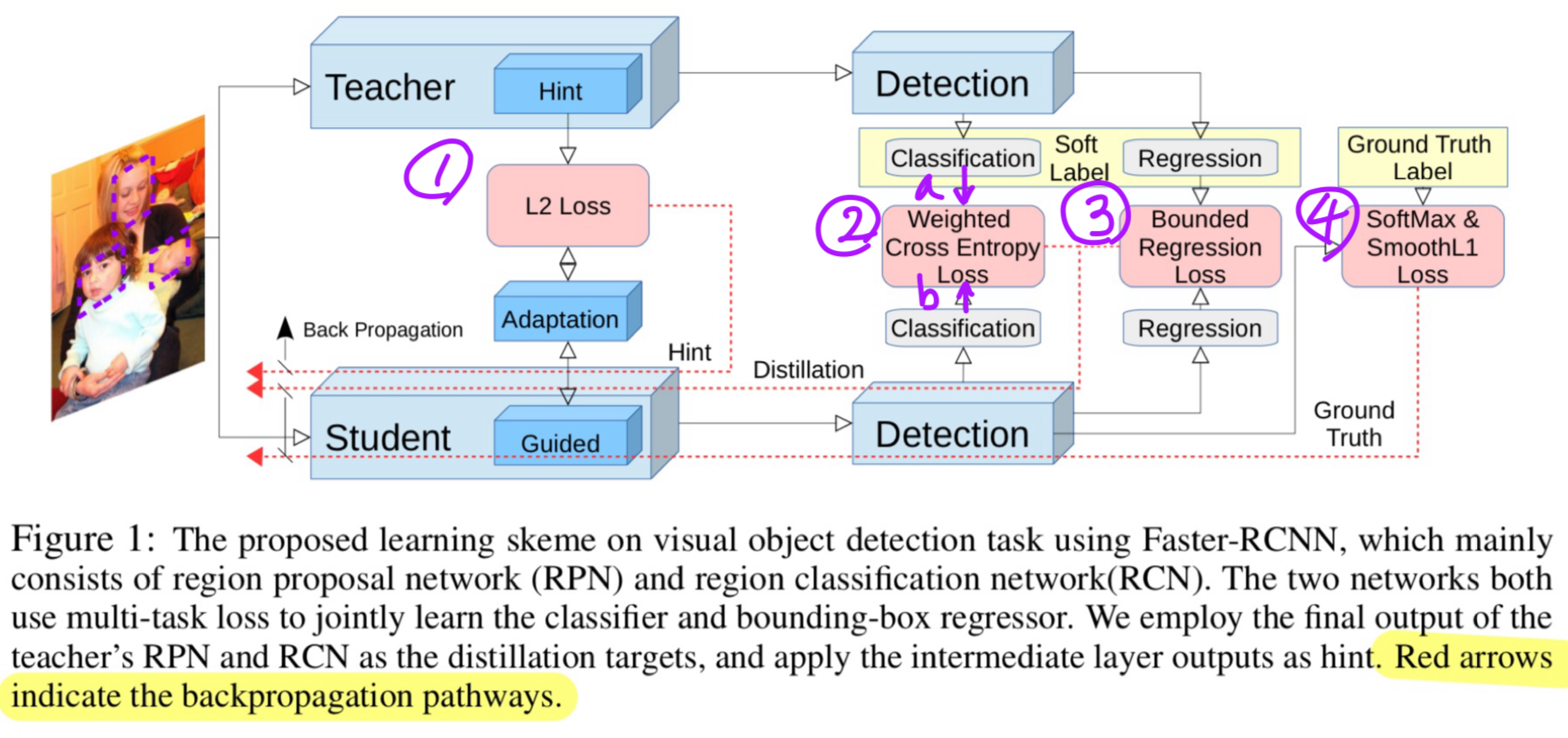
- 우리의 overall learning framework는 Figure 1.에 설명되어 있다.
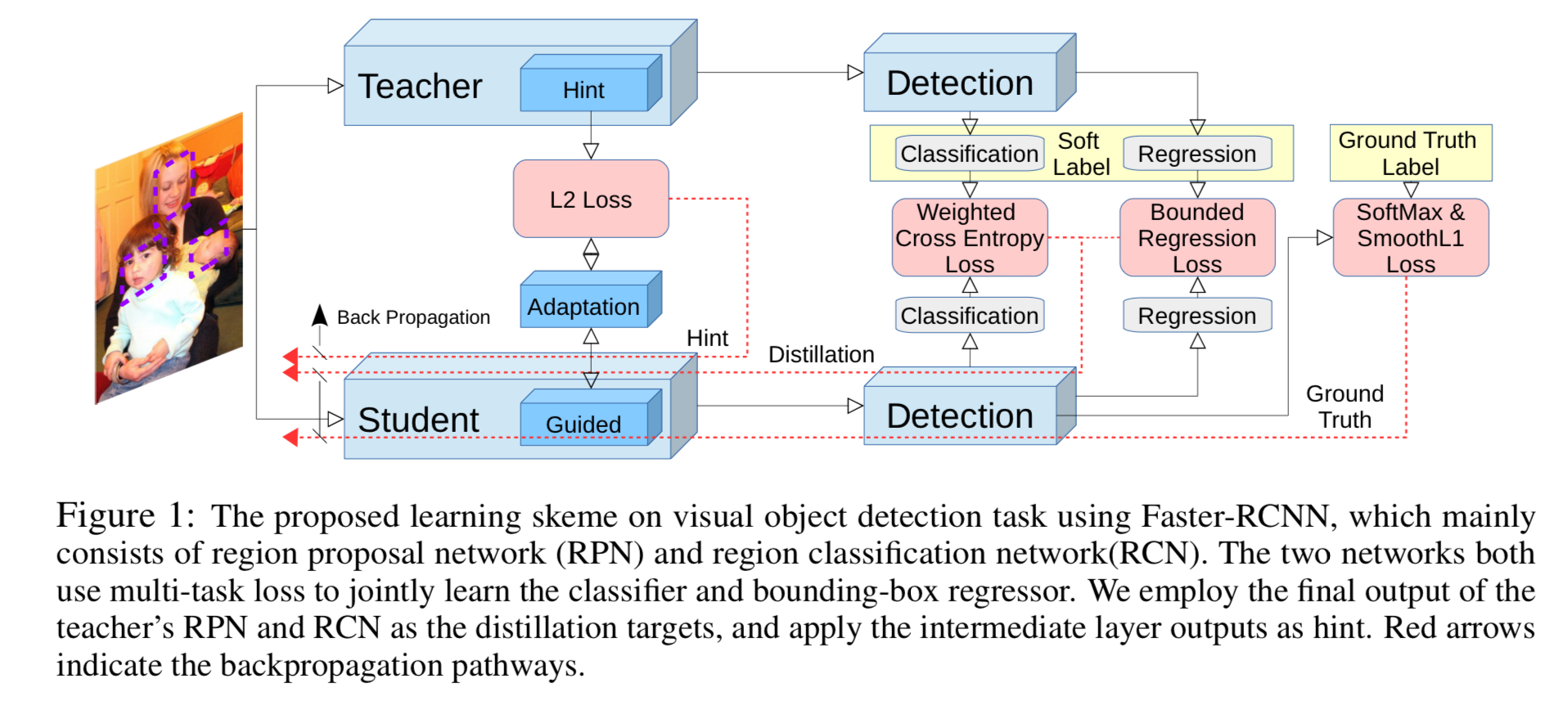
- 먼저,
우리는 hint based learning[34]을 채택하여
student network의 feature representation이 teacher network와 유사하도록 유도함. - knowledge distillation framework[3, 20]을 사용하여
RPN과 RCN의 강력한 classification module을 얻음.
object detection에서 category imbalance issue를 처리하기 위해,
distillation framework에 weighted cross entropy loss를 적용. - teacher의 regression output을 upper bound의 형태로 전송.
즉, 만약 student의 regression output이 teacher보다 우수하다면,
추가적인 loss를 적용하지 않음.
- 먼저,
- Our overall learning objective can be written as follows :
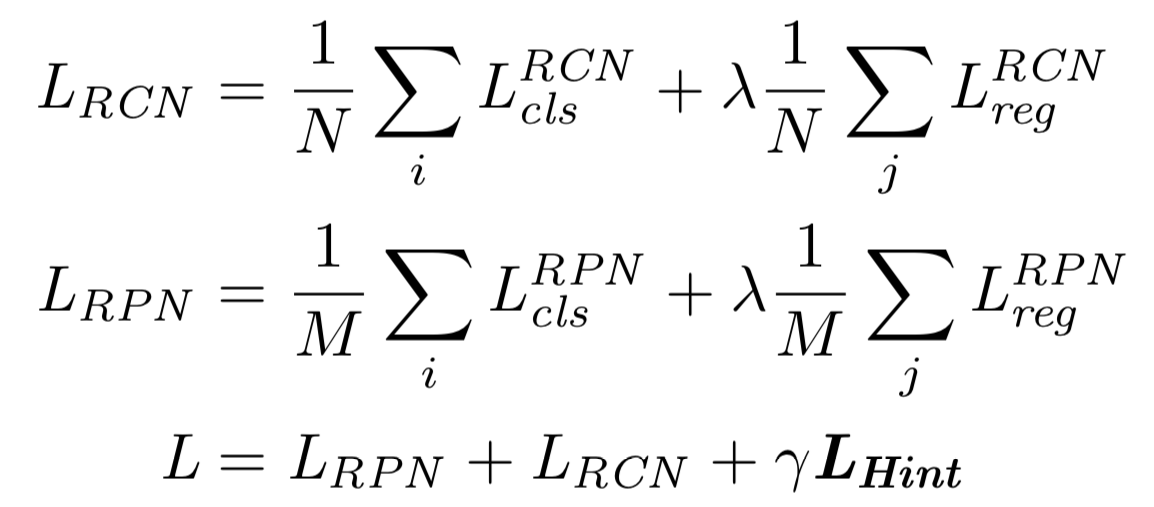
- : the batch-size for RCN
- : the batch-size for RPN
- : the classifier loss function that
combines the hard softmax loss using the GT labels
and the soft knowledge distillation loss[20] of (2). - : the bounding box regression loss that
combines smoothed L1 loss[13]
and our newly proposed teacher bounded L2 regression loss of (4). - : the hint based loss function that encourages the student to mimic the teacher's feature response, expressed as (6).
- and : hyper-parameters to control the balance between different losses.
We fix them to be and
3.2 Knowledge Distillation for Classification with Imbalanced Classes
3.3 Knowledge Distillation for Regression with Teacher Bounds
3.4 Hint Learning with Feature Adaptation
Section 3 Summary >

4 Experiments
