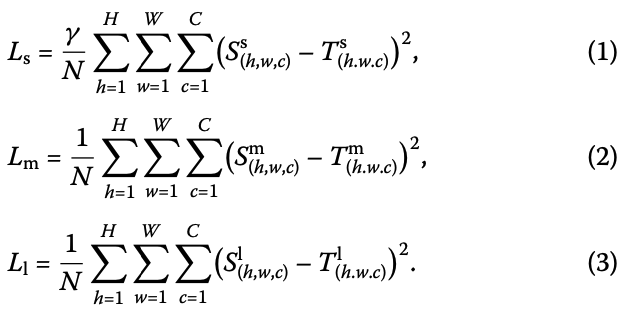[Simple Review] MSSD: multi-scale self-distillation for object detection
https://link.springer.com/article/10.1007/s44267-024-00040-3#citeas
Paper Info
Jia, Z., Sun, S., Liu, G. et al. MSSD: multi-scale self-distillation for object detection. Vis. Intell. 2, 8 (2024). https://doi.org/10.1007/s44267-024-00040-3
Abstract
-
Knowledge distillation 기법은 DL 분야에서 널리 사용되고 있다.
하지만 teach와 student 간의 knowledge를 transfer하는 inefficiencies가 존재하며,
student model은 teacher model의 knowledge를 완전히 학습하지 못한다. -
따라서 우리는 single model 내의 network layer에서 self-distillation을 통해 knowledge distillation을 달성하고자 한다.
또한 우리는 self-distillation idea를 object detection task에 적용해보고 multi-scale self-distillation approach를 제안한다.
추가로, distillation 과정에서 target position detection의 정확성을 향상시키기 위해 target region을 기반으로 한 Gaussian mask를 auxiliary detection method로 제안한다. -
우리는 single-stage detector YOLO를 사용하여 KITTI dataset에 우리의 approach를 검증했다.
그 겨로가 teacher model을 사용하지 않은 baseline에 비해 accuracy가 2.8% 향상되었음을 입증했다.
1. Introduction
-
KD(Knowledge Distillation)가 처음 제안되었을 때는 주로 image classification task에 사용되었고,
object detection에서는 덜 사용되었다.
이는 주로 teacher network의 soft label output이 student network가 the location of target(목표 위치)를 찾는 데 직접적으로 도움되지 않았기 때문이다.
이후, teacher network의 middle layer feature 정보를 student network에 전달하여 object detection에 필요한 localization information을 얻는 방법이 제안되었다.
하지만 이러한 learning process는 비효율적이며, student network는 보통 teacher network의 모든 knowledge를 학습하지 못한다. -
따라서 우리는 전통적인 distillation techniques의 단점을 self-distillation을 통해 해결하고자 한다.
large teacher network를 training시키는 대신, student network 자체에서 valid(유효한) information을 추출하고
student network가 스스로의 teacher가 되도록 하여 computational cost of training을 줄인다. -
object detection model의 framework는 일반적으로 backbone network, neck network, detection head로 구성된다.
backbone network는 image의 feature 정보를 추출하고,
neck network는 보통 FPN 및 PAN과 같이 서로 다른 scale의 feature map extraction information을 결합하여
backbone과 neck network는 semantic and positional information을 상호 작용하며 더 잘 fusion된다.
final detection head는 output feature map을 detecting하는 역할을 한다.
이전의 object detection에 사용된 knowledge distillation 방법에서는 보통 backbone network의 intermediate layer의 output feature map을 distillation했다.
이는 teacher network의 feature map 정보에 global weight를 할당하여 student network가 이를 학습하도록 하는 방식이었다. -
하지만 우리는 neck network의 정보가 더 풍부하다고 생각한다.
shallow network feature map은 더 큰 scale의 정보를 포함하고 있어 small object detection에 더 적합하며,
deep network feature map은 더 작은 scale에서 large object detection에 더 적합하다.
우리는 neck network에서 세 가지 다른 scale의 feature map에 대해 동시에 distillation learning을 수행하며,
network의 output part가 자체 middle layer에서 해당 scale의 feature 정보를 학습하도록 한다.
이 접근 방식은 multi-scale targets을 detecting하는 데 더 유리할 수 있다.
우리 방법은 다른 multi-scale detection module과 달리 network 구조를 변경하지 않고, original network structure에서만 distillation operations을 수행하며 다양한 깊이와 shallow netwwork의 feature information을 탐색하는 데에 중점을 둔다. -
또한,
object detection에서 일반적으로 사용되는 knowledge distillation은 전체 feature map 정보를 distillation하고 학습하므로
target position을 결정하는 과정에서 오류가 발생할 수 있으며, target position을 포착하기 어렵다.
따라서 우리는 distillation 과정에서 target의 local area에 대해 더 효과적으로 학습시키기 위해 Gaussian mask for assisted detection을 추가했다.
이 Gaussian mask의 주요 목적은 target의 ground truth region을 Gaussian value로 encoding하고
나머지 background region을 0으로 설정하여 foreground와 background를 구별하는 것임.
마지막으로, 이 encoded region과 model의 output feature map 사이의 MSE loss를 계산한다.
우리가 생성한 Gaussian mask는 feature adaptation layer를 통해 다양한 scale의 output feature map에 matching될 수 있으며,
이를 통해 다양한 object detector에 적용되어 detection accuracy를 향상시킬 수 있다.
- 요약하자면, 이 article의 key contribution은 다음과 같다.
- huge teacher model을 train시켜야 할 필요를 없앰.
대신에 a simple model이 its own teacher가 됨.
이는 많은 training time and computational cost를 줄일 수 있고,
device 측면에서 real-time processing and deployment가 가능해짐- 우리는 neck network에서 다양한 scale의 feature map을 distillation하여 효과적인 feature information을 추출하고,
이를 output feature map과 비교하여 distillation loss를 계산하는 Multi-scale distillation scheme을 제안한다.
이 multi-scale target을 detection하는 데 도움이 되며, 특히 small object detection의 accuracy를 향상시킨다.- 게다가, distillation learning 동안에 more accurate positioning of the target을 위해서,
image processing 동안 foreground와 background를 구분할 수 있는 Gaussian mask를 만들었다.
그런 다음 detection 단계와 output result 사이의 mask loss를 계산하여 model의 detection accuracy를 향상시킨다.
이러한 방법들은 model의 basic structure를 변경하지 않기 때문에 #Params를 크게 증가시키지 않는다.
2. Related Works
(skip)
3. Method
3.1 Multi-scale distillation loss
-
이 section에서는 제안된 multi-scale distillation framework에 대해 자세히 설명한다.
대표적인 object detector인 YOLO는 model에 multi-scale detection structure를 통합하고 있다.
model의 volume and computational cost를 고려하여, 우리는 실험의 주요 framework로 YOLOv5 network를 선택했다.
그 주요 framework는 Fig. 1에 보여지고 있으며, backbone network, neck network, detection head의 세 가지 주요 components를 포함하고 있다.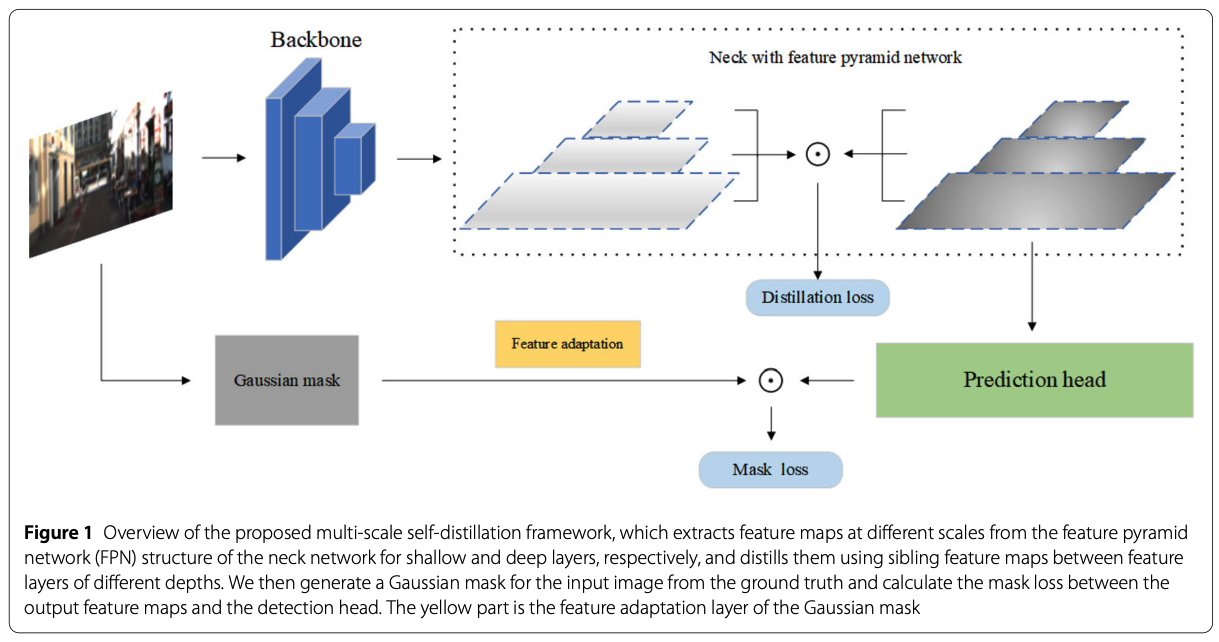
-
CNN-based detector가 계속 발전함에 따라 multi-scale target detection에 대한 요구가 증가하면서,
다양한 detector는 multi-scale target detection을 촉진하는 module을 network에 추가했다.
Figure 2는 YOLOv5의 network structure를 보여주며, neck network는 FPN+PAN module의 조합이다.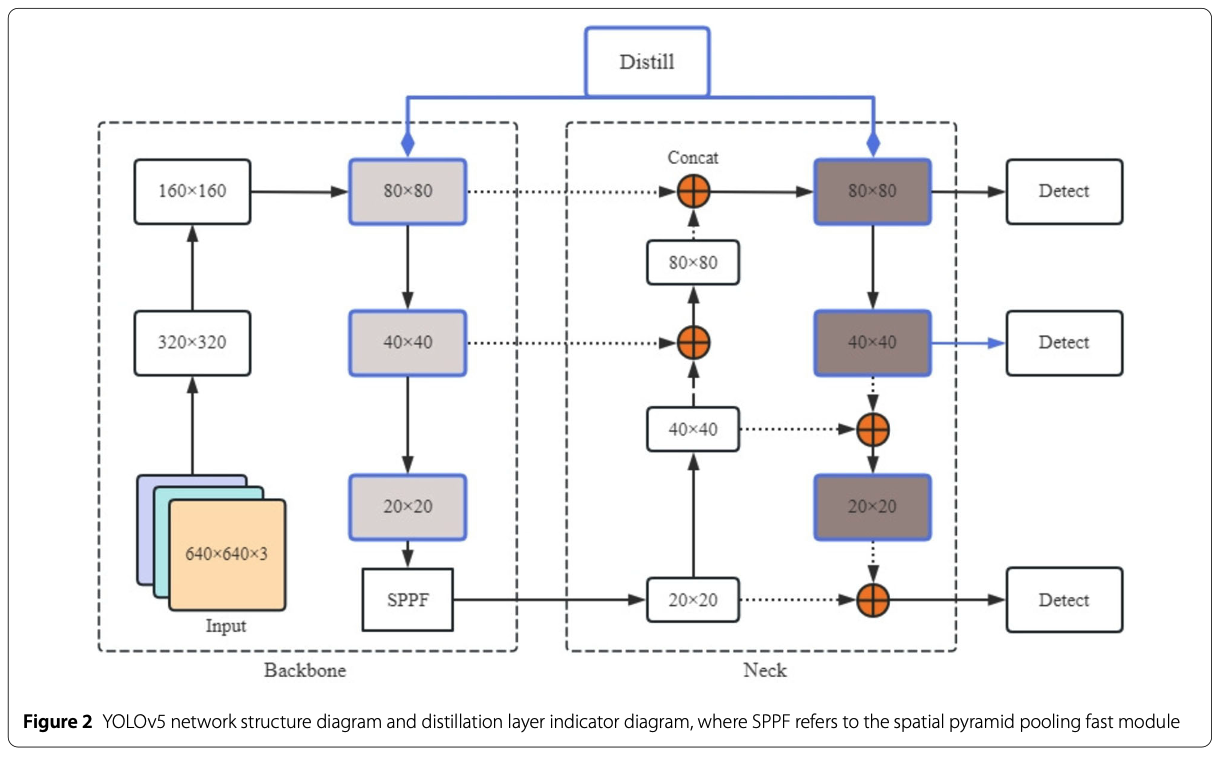 우리는 FPN의 서로 다른 scale의 feature layer를 teachers로 사용하고, 더 깊은 PAN output 부분을 students로 사용한다.
우리는 FPN의 서로 다른 scale의 feature layer를 teachers로 사용하고, 더 깊은 PAN output 부분을 students로 사용한다.
feature map의 scale은 세 번 변경된다.
larger scale의 feature map은 original image와 비교하여 downsampling rate가 적고 receptive field가 작기 때문에, smaller object를 detection할 수 있으며, 더 작은 anchor가 할당 된다.
따라서 우리는 small feature maps에 large target()을,
medium-sized feature maps에 medium-sized targets()을,
large feature maps에 small targets()을 detection한다.
동일한 scale의 Feature map 사이의 distillation loss를 계산한다.
세 가지 다른 scale의 distillation loss를 각각 계산하며, 서로 다른 scale에서 target detection accuracy를 더 잘 향상시키기 위해,
세 loss에 서로 다른 weight coefficients(계수)를 할당했다.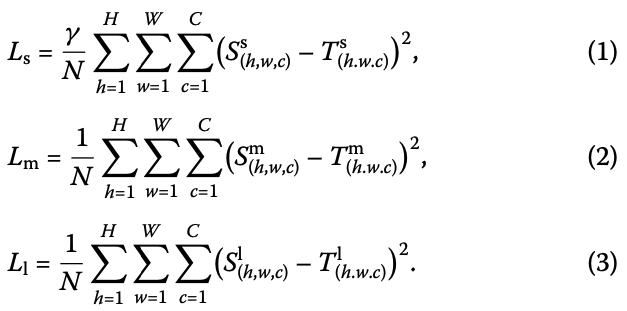
Critique
- 논문에서는 backbone이 teacher, neck이 student라고 했지만
사실 knowledge distillatoin하는 loss를 살펴보면,
teacher와 student 구분이 없는 loss function이다.
matrix frobenius norm이기 때문에 S와 T가 서로 자리가 바뀌어도 loss값은 똑같이 나온다...
이 loss의 원리를 자세히 설명을 해줬다면 좋았을 듯하다