[2020 CVPR] EfficientDet: Scalable and Efficient Object Detection
[Paper Review] Efficient and Scalable
Paper Info
- Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and efficient object detection." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
Abstract
-
Computer vision에서 model efficiency는 점점 중요해지고 있다.
이 논문에서는 object detection을 위한 neural network architecture design choices를 체계적으로 연구하고,
efficiency를 향상시키기 위한 몇 가지 key optimization을 제안할 것이다.- 첫째,
우리는 쉽고 빠른 multi-scale feature fusion을 가능하게 하는
weighted bi-directional feature pyramid network(BiFPN)을 소개할 것이다. - 둘째,
우리는 backbone, feature network, and box/class prediction networks의
resolution, depth, width를 동시에 균일하게 확장하는
compound(복합) scaling method를 제안할 것이다.
- 첫째,
-
이러한 optimizations과 EfficientNet backbone을 바탕으로,
우리는 EfficientDet이라는 새로운 object detector 계열을 개발했다.
이 object detector는 다양한 resource constraints에서 이전 기술보다 훨씬 뛰어난 efficiency를 일관되게 달성한다. -
특히, single-model and single-scale에서, 우리의 EfficientDet-D7은 COCO test-dev에서
52M params와 325B FLOPs로 state-of-the-art 52.2 AP를 달성하여,
이전 detector보다 4~9배 더 작고 13~42배 적은 FLOPs를 사용한다.
https://github.com/google/automl/tree/master/efficientdet
1. Introduction
-
A natural question is:
higher accuracy와 better efficiency를 갖추면서도
다양한 resource constraints(e.g., from 3B to 300B FLOPs)에 걸쳐
scalable detection architecture를 구출할 수 있을까? 이다. -
이 논문은 detector architectures의 다양한 design chioces를 체계적으로 연구하여
이 문제를 해결하는 것을 목표로 한다.
one-stage detector paradigm에 기반하여,
우리는 backbone, feature fusion, and class/box network에 대한 design choices를 검토하고 두 가지 주요 과제를 식별했다.-
Challenge 1: efficient multi-scale feature fusion -
FPN이 도입된 이후로, multi-scale feature fusion을 위해 널리 사용되어 왔다.
최근에는 PANet, NAS-FPN, 그리고 다른 연구들이 cross -scale feature fusion을 위한 더 많은 network 구조를 개발했다.
그러나 대부분의 이전 연구들에서는 서로 다른 input feature들을 단순히 구분 없이 합산했지만,
이러한 서로 다른 input feature들이 서로 다른 resolution에 있기 때문에,
우리는 이들이 fused output feature에 대게 불균형하게 기여한다는 것을 관찰했다.
➡️ 이 문제를 해결하기 위해, 우리는 단순하지만 매우 효과적인 weighted bi-directional feature pyramid network(BiFPN)를 제안한다.
이는 서로 다른 input feature들의 중요성을 학습할 수 있는 learnable weights를 도입하며,
top-down and bottom-up multi-scale feature fusion을 반복적으로 적용한다. -
Challenge 2: model scaling -
이전 연구들은 주로 bigger backbone network 또는 larger input image sizes에 의존하여 higher accuracy를 달성하려고 했다.
그러나 우리는 accuracy와 efficiency를 둘 다 고려할 때,
feature network와 box/class prediction network를 scaling up하는 것도 중요하다는 것을 관찰했다.
최근 연구들에 영감을 받아, 우리는 object detector를 위한 a compound scaling method를 제안한다.
이 방법은 backbone, feature network, box/class prediction network의 resolution/depth/width를 모두 함께 scaling한다.
-
2. Related Work
One-stage Detectors:
Multi-Scale Feature Representations:
- PANet adds an extra bottom-up path aggregation network on top of FPN
Model Scaling:
3. BiFPN
- 이 section에서,
우리는 우선 multi-scale feature fusion problem을 정의하고 나서,
BiFPN에 대한 main idea를 소개할 것이다.
3.1. Problem Formulation
-
Multi-scale feature fusion은 다른 resolution에 대한 features들끼리 aggregate하는 것을 목표로 한다.
공식적으로, 다음의 a list of multi-scale features ,
where P_{li}^{in} represents the feature at level
가 주어졌다고 했을 때,
우리의 목표는 서로 다른 features들을 효과적으로 aggregate하고 a list of new features를 output할 수 있는 transformation 를 찾는 것이다. :
-
The conventional
FPN은 top-down manner로 multi-scale feature를 aggregate한다.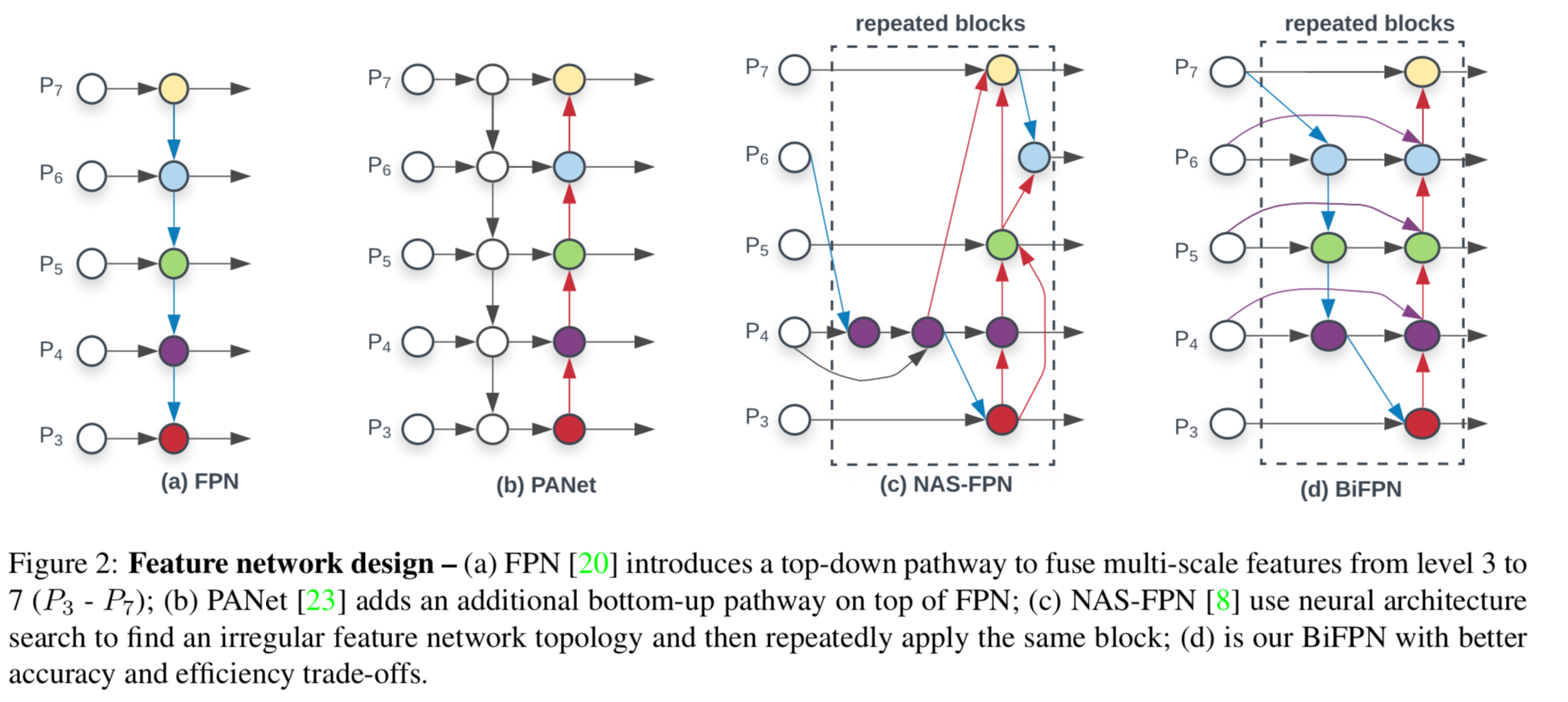

3.2. Cross-Scale Connections
-
Conventional top-down
FPN은 본질적으로 one-way information flow로 인해 한계가 있다.
이 문제를 해결하기 위해서,PANet은 추가의 bottom-up path aggregation network가 추가되었다.
NAS-FPN은 (이 당시) 최근에 나온 기술로, nerual architecture search를 사용하여
더 나은 cross-scale feature network topology를 탐색한다.
하지만 이 과정에서 탐색에 수천 시간의 GPU를 필요로 하며, 찾은 network는 불규칙하고 해석과 수정이 어렵다고 한다.
세가지 networkFPN,PANet,NAS-FPN의 performance and efficiency를 연구한 결과,
우리는PANet이FPNandNAS-FPN보다
more parameters and computations cost가 들지만, better accuracy를 보이는 것을 관찰했다. -
PANet의 efficiency를 향상시키기 위해서,
우리는 cross-scale connections을 위한 몇가지 optimization을 소개할 것이다:- 우리는 one input edge를 갖는 nodes를 제거했다.
우리의 직관은 간단하다.
만약 feature fusion 없이 only one input edge를 갖는 node가 있다면,
그 node는 서로 다른 features를 fusing하는 목적의 feature network에 적은 기여를 할 것이다.
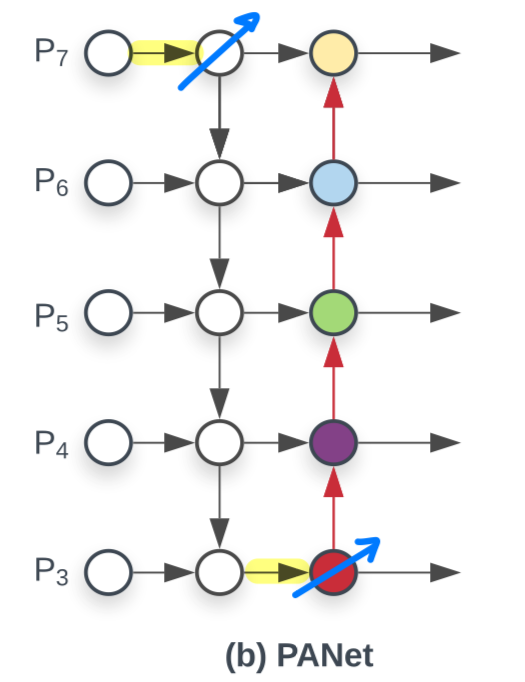
- 만약 feature들이 same level에 있다면,
original input을 output node로 연결해주는 추가의 edge를 추가했다.
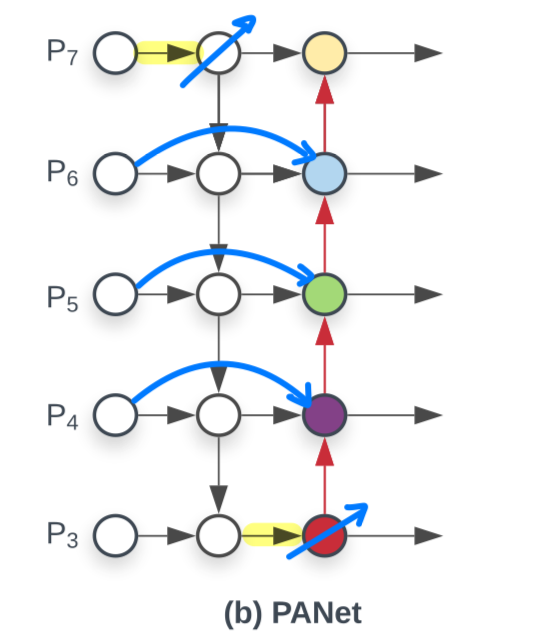
- one top-down and one bottom-up path를 갖는 PANet과는 달리,
우리는 각각의 bidirectional(top-down & bottom-up) path를 하나의 feature network layer로 취급하여,
더욱 high-level feature fusion을 가능하게 하기 위해 layer를 여러 번 반복하였다.
(Section 4.2에서는 compound scaling method를 사용하여
different resource constraints를 위해 얼만큼의 layer가 필요한지 결정하는 방법에 대해 discuss할 것이다.)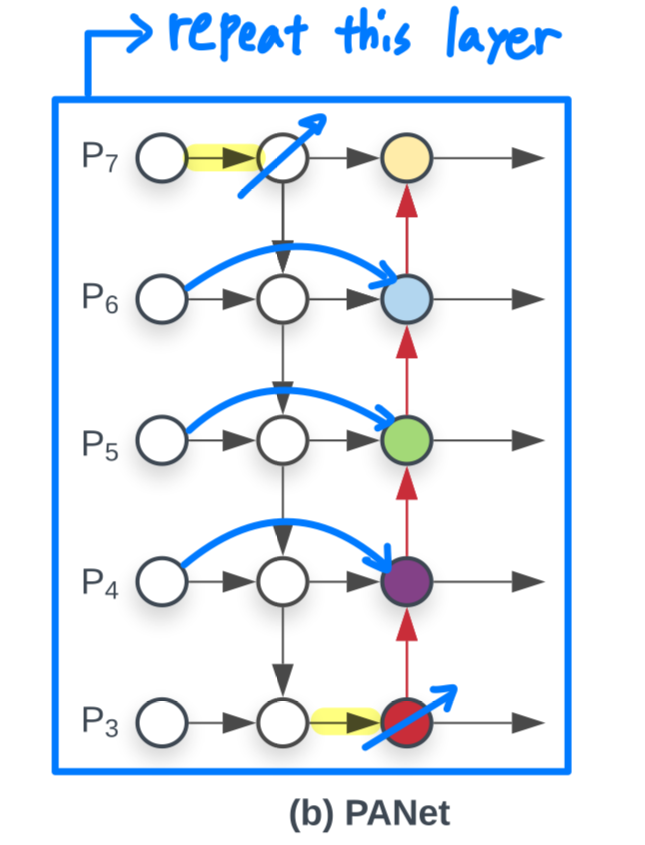
PANet에 대해 위 3가지 optimizations을 통해,
우리는bidirectional feature pyramid network(BiFPN)이라고 불리는 새로운 feature network를 소개한다.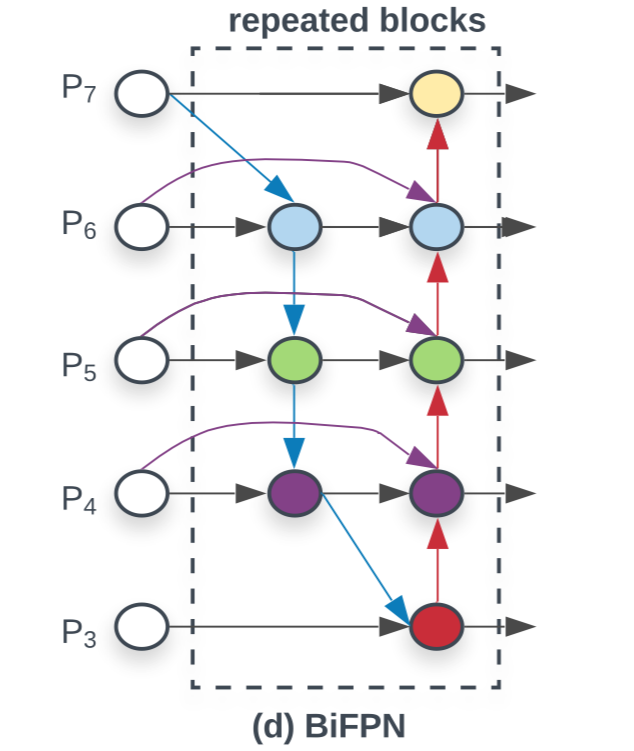
- 우리는 one input edge를 갖는 nodes를 제거했다.
3.3 Weighted Feature Fusion
-
서로 다른 resolutions끼리 feature를 fusing할 때,
가장 흔한 방법은 그들을 same resolution으로 resize하고 더하는 것이다. -
하지만 우리는 서로 다른 input features들은 서로 다른 resolution이기 때문에,
각각의 feature들은 output feature에 unequally하게 contribute한다는 것을 관찰했다.
이 문제를 해결하기 위해,
우리는 각 input에 additional weight를 추가하고,
network가 각각의 input feature의 중요성을 학습하도록 하는 것을 제안한다.
이 idea에 기반하여, 우리는 세가지 weighted fusion approaches를 제안한다 :- Unbounded fusion
- Softmax-based fusion
- Fast normalized fusion
Unbounded fusion
- Unbounded fusion : ,
where is a learnable weight that can be a scalar(per-feature), a vector(per-channel), or a multi-dimensional tensor (per-pixel).
이 scale이 다른 approaches보다 minimal computational cost로 경쟁력 있는 accuracy를 달성할 수 있다는 것을 발견했다.
하지만,
scalar weight는 unbounded하기 때문에, training instability를 야기할 수 있다.
그러므로, 우리는 각각의 weight의 value range를 bound하기 위해 weight normalization을 의존했다.
Softmax-based fusion
- Softmax-based fusion : .
직관적인 idea는 각 weight에 softmax를 적용하는 것이다.
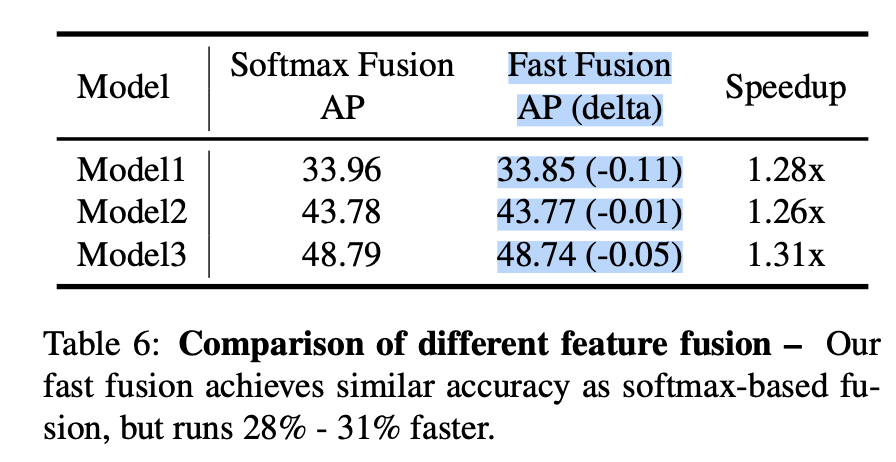
하지만, section 6.3의 ablation study에서 보여주듯이,
extra softmax는 GPU HW의 significant slowdown을 초래한다.
extra latency cost를 minimize하기 위해서, 우리는 fast fusion approach를 제안한다.
Fast normalized fusion
- Fast normalized fusion : , where is ensured by applying a Relu after each ,
and is a small value to avoid numerical instability.
비슷하게, the value of each normalized weight도 0~1의 값을 갖는데,
softmax operation이 없기 때문에, 더욱 효율적이다.
우리의 ablation study에서 이 fast fusion approach가 softmax-based fusion보다 비슷한 학습효과를 보이면서, GPUs에서 30% 이상의 속도 향상을 보였다.
우리의 final BiFPN은
bidirectional cross-scale connections과 the fast normalized dfusion을 통합하였다.
구체적인 예시로, BiFPN의 level 6에서의 두개의 fused features를 설명한다.
4. EfficientDet
- 우리의 BiFPN에 기반하여,
우리는EfficientDet이라고 하는 새로운 detection model 계열을 개발했다.
4.1. EfficientDet Architecture
-
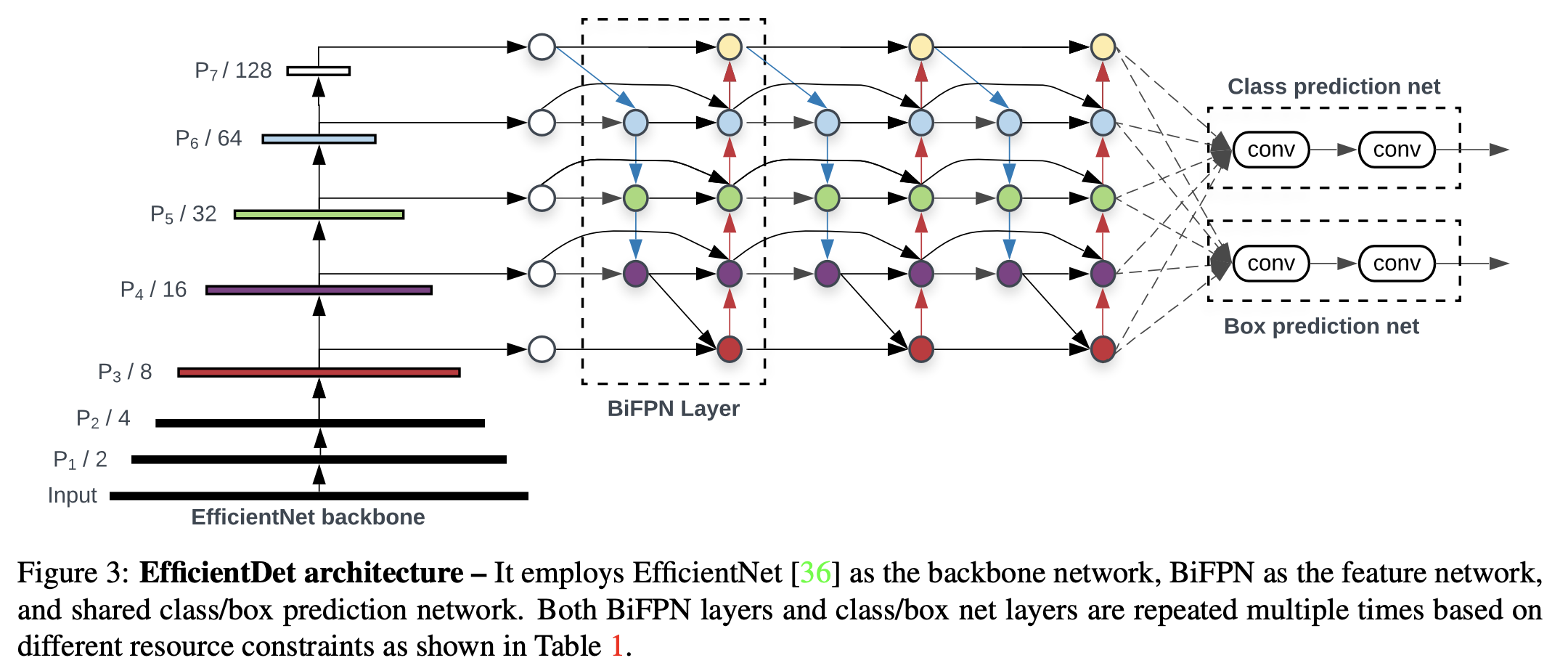
Figure 3에 EfficientDet의 전반적인 architecture가 있다.
EfficientDet은 크게 보면 one-stage detector paradigm을 따른다. -
우리는 ImageNet-pretrained EfficientNets을 backbone network로 사용했다.
우리의 proposed BiFPN은 feature network로 제공되고,
BiFPN은 backbone network로부터 level 3-7 features 를 받고
반복적으로 top-down and bottom-up bidirectional feature fusion을 적용한다.
이 fused features들은 object class와 bbox predictions을 만들어내기 위해
각각 a class network와 box network로 들어간다.
class and box network weights는 모든 level의 features 사이에서 공유된다.
4.2. Compund Scaling
-
accuracy and efficiency를 둘 다 optimizing하면서,
우리는 resource constraints의 넓은 specturm을 만족할 수 있는 family of models를 개발하고 싶었다.
여기서, key challenge는 how to scale up a baseline EfficientDet model 이다. -
이전 연구들은 bigger backbone networks, using larger input images, or stacking more FPN layers 등으로
baseline detector를 scale up해왔다.
하지만 이러한 방법들은 오로지 a single or limited scaling dimension에 집중하기 때문에 비효율적이다. -
우리는 backbone network, BiFPN network, class/box network, and resolution의 모든 dimension을 동시에 scale up할 수 있게
a simple compound coefficient 를 사용하는,
object detection을 위한 a new compound scaling method를 제안한다. -
object detectors들은 classification model들보다 훨씬 많은 scaling dimension을 갖기 때문에,
모든 dimension을 위한 grid search는 너무 expensive하다.
그러므로, 우리는 heuristic-based scaling approach를 사용했지만,
모든 dimension을 동시에 scaling up한다는 main idea를 따른다.
Backbone network
- 우리는 EfficientNet-B0 to B6에서 사용한 width/depth scaling coefficients를 그대로 사용했다.
(ImageNet-pretrained checkpoints를 사용하기 쉬웠기 때문)
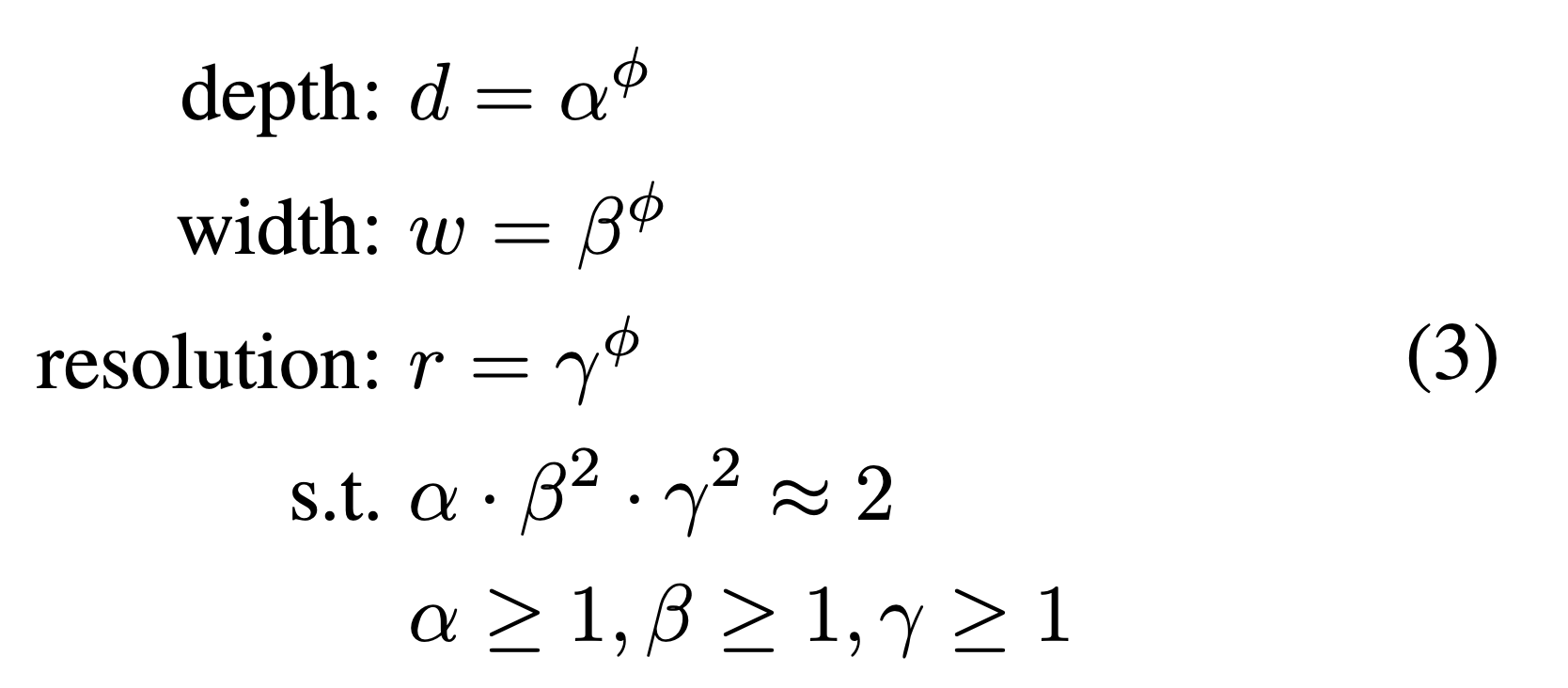

(자세히 읽어보진 않았지만, coefficient 값에 따라 scaling이 되어 EfficientNet- to 이 정해지는듯)
BiFPN network
-
우리는 depth는 small integers 값이 필요하기 때문에
BiFPN depth인 (#layers)을 linearly increase했다. -
BiFPN width인 (#channels)에 대해서는
[36]에서 처럼 exponentially grow했다. -
구체적으로, 우리는 a list of values 에서 grid serach를 수행했고,
BiFPN width scaling factor로 best value인 1.35를 선택했다.
공식적으로, BiFPN width and depth는 다음의 식에 의해 scaled되어진다 :

Box/class prediction network
- 우리는 box/class prediction network의 width를 BiFPN과 항상 똑같게 유지했다.
(i.e. )
depth는 다음의 식을 이용하여 linearly increase했다.
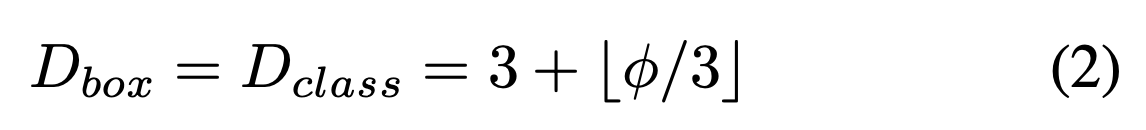
Input image resolution
- BiFPN에서 feature level 3-7이 사용되었기 때문에,
input resolution은 로 dividable해야 한다.
그래서 우리는 다음의 식을 이용하여 linearly increase했다.
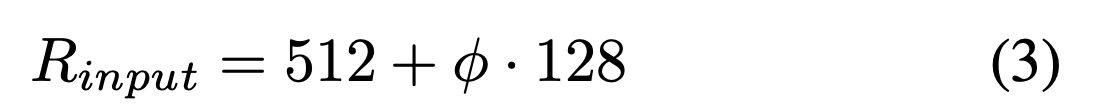
값을 다르게 하여 Equations 1, 2, 3에 적용해서,
우리는 EfficientDet-D0() to D7()까지 개발했다.
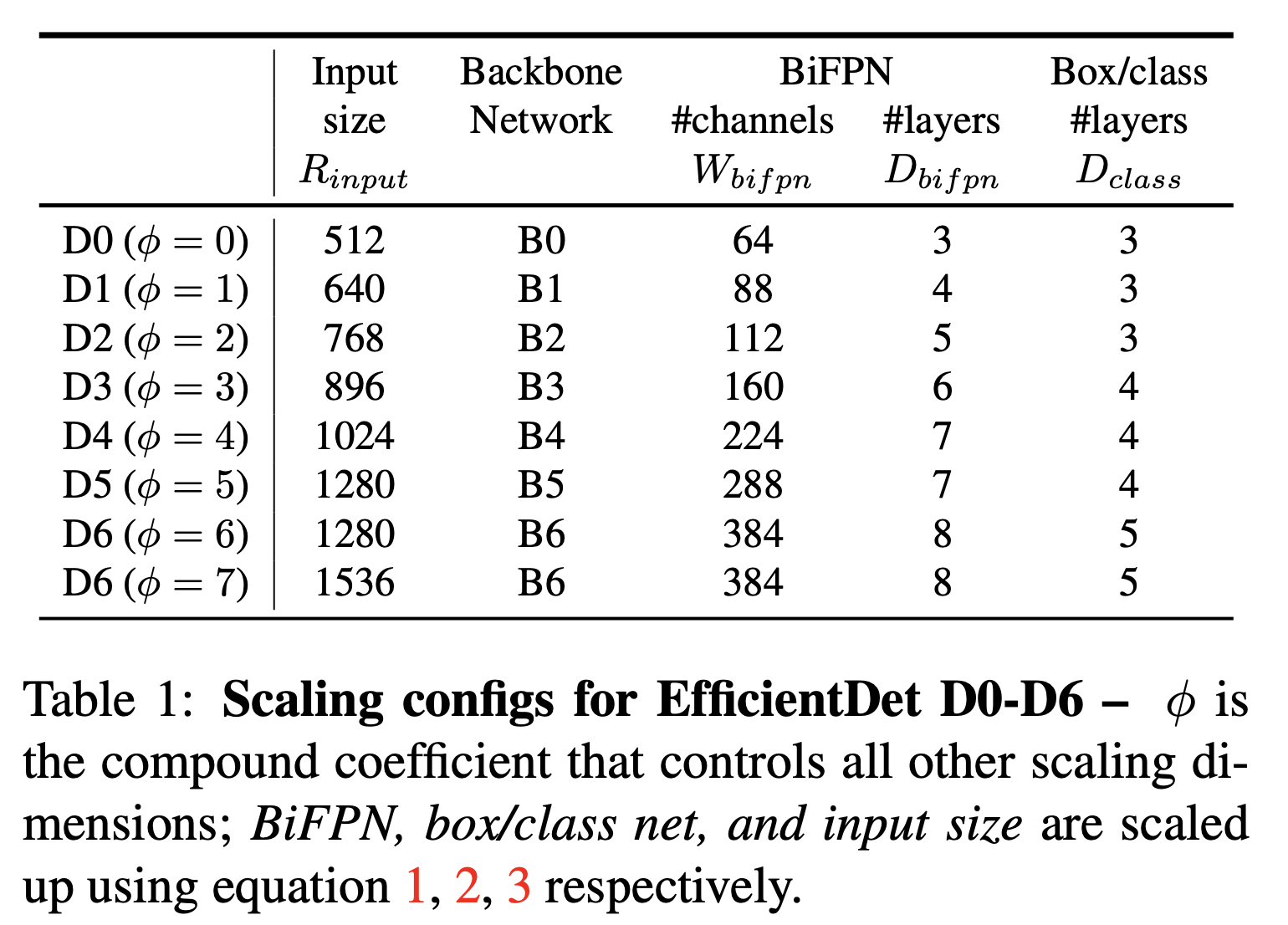 우리의 scaling이 heuristic-base라 optimal이 아닐 수 있지만,
우리의 scaling이 heuristic-base라 optimal이 아닐 수 있지만,
이 simple scaling method가 다른 single-dimension scaling method들보다 훨씬 efficiency가 뛰어나다는 것을 보여준다.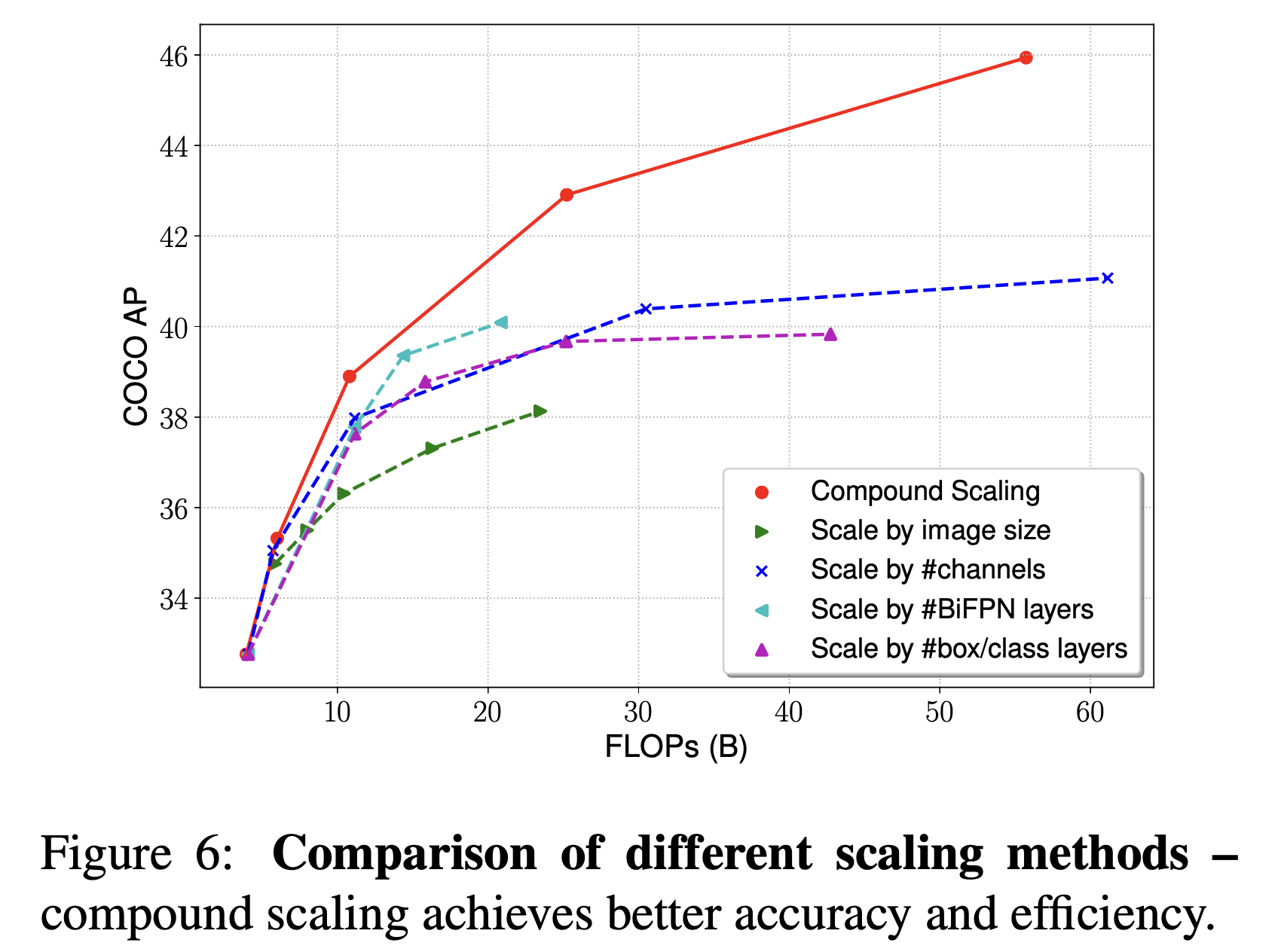
5. Experiments
(skip)
