[2016 IEEE][Simple Review] Region-based Convolutional Networks for Accurate Object Detection and Segmentation
[Paper Review] 2D Object Detection
Paper Info
-
R. Girshick, J. Donahue, T. Darrell and J. Malik, "Region-Based Convolutional Networks for Accurate Object Detection and Segmentation," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 1, pp. 142-158, 1 Jan. 2016, doi: 10.1109/TPAMI.2015.2437384.
-
authors : Ross Girshick; Jeff Donahue; Trevor Darrell; Jitendra Malik
1. Introduction
-
LeCun and colleagues는 backpropagation을 이용한 stochastic gradient descent이
real-world handwritten character recognition problems에서 훨씬
effective하다고 주장했었다.
➡️ 이러한 model들은 convolutional networks, CNNs, or ConvNets으로 알려짐. -
CNNs은 1990년대에 사용하기에는 heavy했고,
support vector machine의 등장에 관심이 쏠렸었다. -
2012년에 Krizhevsky가 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서
CNNs을 사용한 image classification의 잠재력을 보여줌으로써
다시금 CNNs이 주목받기 시작했다. -
여기서 드는 궁금증은
ImageNet에 대한 CNN classification result가
PASCAL VOC Challenge에 대한 object detection으로도
generalization될 수 있는가?
였다.
우리는 이 결과를 얻기 위해서,
우리는 두가지 Problems에 대한 solution을 개발함으로써
image classification과 object detection 사이의 gap을 줄였다.-
How can we localize objects with a deep network?
(deep network로 object를 어떻게 localization할 것인가?)- localization을 하기 위한 one approach는 detection을 regression problem으로 바꾸는 것이다.
이는 single object를 detection하는 것에는 좋지만,
multiple objects를 detection하기에는 복잡하거나 한 image에 대해서 많은 assumption이 이루어져야 하는 단점이 있음. - 또 다른 approach로는 sliding-window detector를 사용하는 것인데,
이는 computational efficiency하지만,
모든 object가 같은 aspect ratio(종횡비)를 갖고 있을 때에만 성립된다는 단점이 있음. - 우리는
recognition using regionsparadigm을 적용함으로써
localization problem을 해결했다.
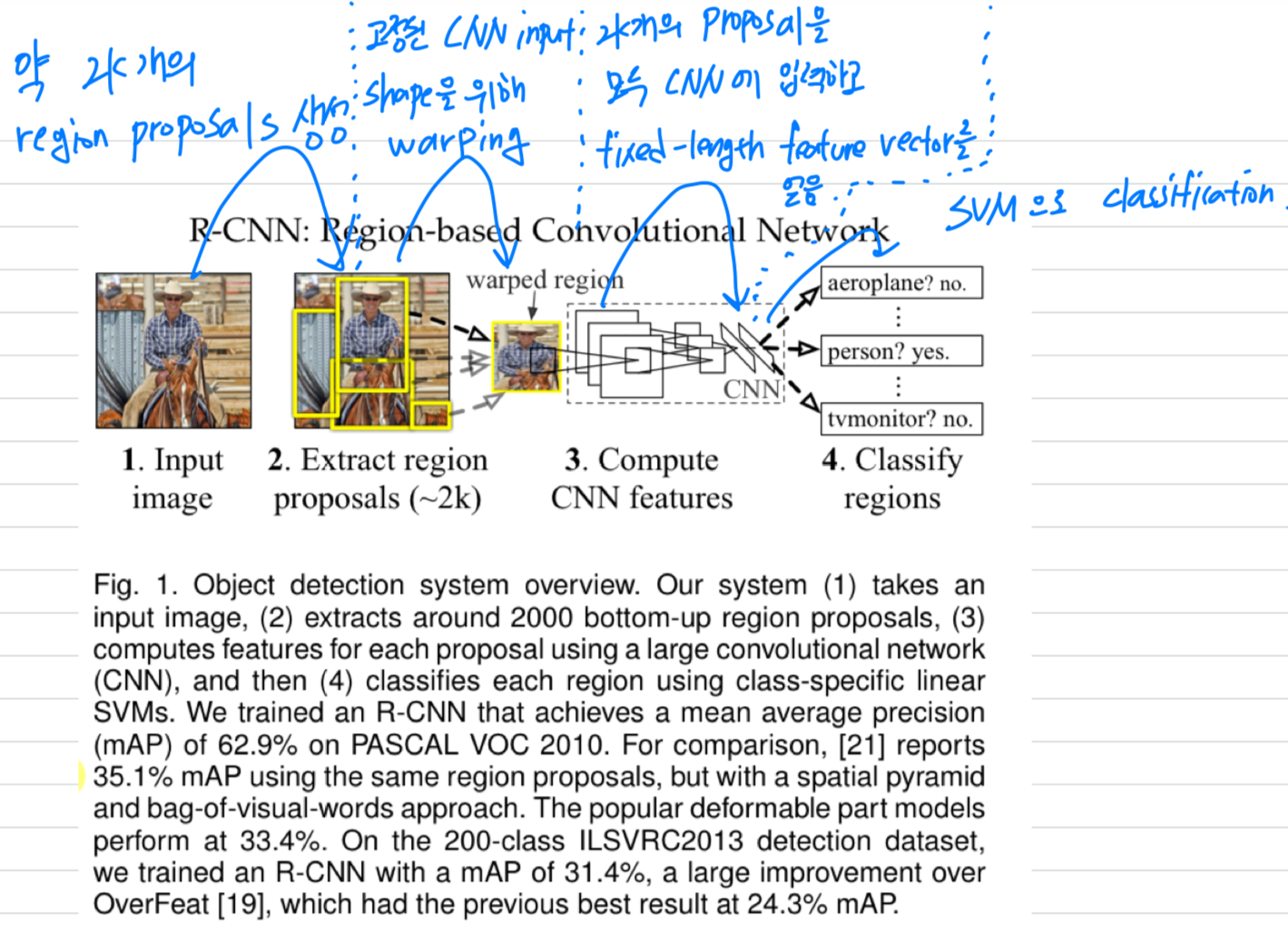
test time에,
우리의 method는 input image에 대해 약 2,000개의 category-independent region proposals을 생성하고,
CNN을 사용하여 각 proposal로부터 fixed-length feature vector를 생성하고,
각 region을 category-specific linear SVMs으로 classification함.
우리는 각 region proposal의 shape에 관계 없이,
fixed-size CNN input을 계산하기 위해
simple warping technique을 사용했다.
- localization을 하기 위한 one approach는 detection을 regression problem으로 바꾸는 것이다.
-
How can we train a high-capacity model with only a small quantity of annotated detection data?
(적은 data로 어떻게 큰 model을 train시킬 것인가?)- a large auxiliary dataset(ILSVRC)에 supervise pre-training을 시킨 후에,
PASCAL dataset에 fine-tuning을 했다.
이는 data가 부족할 때, high-capacity CNNs을 학습시키기 위한 effective paradigm이다.
- a large auxiliary dataset(ILSVRC)에 supervise pre-training을 시킨 후에,
-
2. Related Work
(skip)
-
Deep CNNs for object detection
-
Scalability and speed
-
Localization methods
-
Transfer Learning
-
R-CNN extensions
3. Object Detection with an R-CNN
- Our object detection system은 three modules로 구성되어 있다.
- The first generates category-independent region proposals
- The second module is a convolutional network that extracts a fixed_length feature vector from each region
- The third module is a set of class-specific linear SVMs.
3.1. Module design
3.1.1. Region proposals
-
category-independent region proposal을 생성하는 방법에 대한
다양한 논문들이 있다.
예를 들어,
objectness[51], selective search[21], category-independent object proposal[52], constrained parametric min-cuts(CPMC)[22], multi-scale combinatorial grouping[25], ... -
R-CNN은 prior detection work ([21], [54])와 비교를 가능하게 하기 위해 selective search를 사용했다.
3.1.2. Feature extraction
-
우리는 CNN을 사용하여 each region proposal로부터
fixed-length feature vector를 extract했다.
(fixed length feature vector는 4096-dimension)
CNN architecture는 system hyperparameter이다.
우리는 대부분의 실험을 AlexNet으로 했다. -
region proposal에 대한 feature를 compute하기 위해,
우리는 먼저 해당 region의 image data를 CNN에 호환되는 형식으로 변환해야 했다.
(CNN architecture는 fixed S x S pixel size의 input을 요구함)
우리는 가장 simple하게 candidate region의 size or aspect ration 관계 없이,
bounding box에 대한 모든 pixel을 required size에 맞게 warp했다.
3.2 Test-time detection
- test time에는,
test image에 대해 selective search를 수행하여 약 2,000개의 region proposals을 추출한다.
우리는 각 proposal을 warping하고 나서 features를 구하기 위해 CNN에 forward propagatation한다.
그리고 나서, 각 class에 대해 trained된 SVM을 사용하여
각 추출된 feature vector에 대해 score를 얻는다.
image에 대해서 모든 scored regions을 얻으면,
우리는 class마다 independent하도록 greedy non-maximum suppression을 적용하여
지정된 threshold보다 높고, 지금의 region score보다 higher score를 가진 selected region과의 IoU가 존재한다면 reject.
(이미 같은 object에 대해 score가 더 높은 region이 있기 때문에 중복해서 detection할 필요는 없기 때문에 NMS)
3.3. Training
(skip)
3.3.1 Supervised pre-training
3.3.2 Domain-specific fine-tuning
3.3.3 Object category classifiers
3.4 Results on PASCAL VOC 2010-12
3.5 Results on ILSVRC2013 detection
4. Anaylsis
4.1 Visualizing learned features
4.2 Ablation studies
4.2.1 Peformance layer-by-layer, without fine-tuning
4.2.2 Performance layer-by-layer, with fine-tuning
4.2.3 Comparison to recent feature learning methods
4.3 Network architectures
4.4 Detection error analysis
4.5 Bounding-box regression
4.6 Qualitative results
5. The ILSVRC2013 Detection Dataset
5.1 Dataset overview
5.2 Region proposals
5.3 Training data
5.4 Validation and evaluation
5.5 Ablation study
5.6 Relationship to OverFeat
6. Semantic Segmentation
6.1 CNN features for segmentation
6.2 Results on VOC 2011
7. Implementation and Design Details
7.1 Object proposal transformations
7.2 Positive vs. negative examples and softmax
7.3 Bounding-box regression
7.4 Analysis of cross-dataset redundancy
8. Conclusion
