https://github.com/THU-MIG/yolov10
Paper Info.
Wang, Ao, et al. "Yolov10: Real-time end-to-end object detection." arXiv preprint arXiv:2405.14458 (2024).
Abstract
-
지난 몇년간,
YOLOs는 effective balance between computational cost and detection performance 덕분에
real-time object detection 분야의 우수한 paradigm으로 이끌어왔다.
researcher들은 YOLOs에 대한 architectural designs, optimization objectives, data augmentation strategies 등을 탐구해왔고, 놀라운 발전을 이루었다. -
(기존 YOLOs의 문제점 지적)
하지만,
post-processing에서 non-maximum suppression(NMS)에 대한 의존은
YOLOs의 end-to-end deployment를 방해하고,
inference latency에 불리하게 작용한다.
게다가,
YOLOs의 various components로 이루어진 design은 comprehensive(포괄적이고),
thorough inspection(철저한 조사)가 부족하여
눈에 띄는 computational redundancy를 유발하고 model's capability를 제한한다.
➡️ 이는 suboptimal efficiency를 초래하며 performance improvements에 대한 상당한 potential을 남긴다. -
(이 논문의 핵심 idea에 대한 abstract)
이 논문에서,
우리는 YOLOs의 performance-efficiency boundary를
post-processing과 model architecture 양면에서 더욱 향상시키고자 한다.
이를 위해,
우리는 the consistent(일관된) dual assignments for NMS-free training of YOLOs를 제시하여
경쟁력있는 performance and low inference latency를 동시에 가져왔다.
또한,
우리는 the holistic efficiency-accuracy driven(기반의) model design strategy를 소개할 것이다.
우리는 efficiency and accuracy 관점에서 YOLOs의 다양한 components를 포괄적으로 optimize하여
computational overhead를 크게 줄이고 capability를 향상시켰다.
- 연구의 결과로,
real-time end-to-end object detection을 위한 새로운 YOLO series인YOLOv10이 만들어졌다.
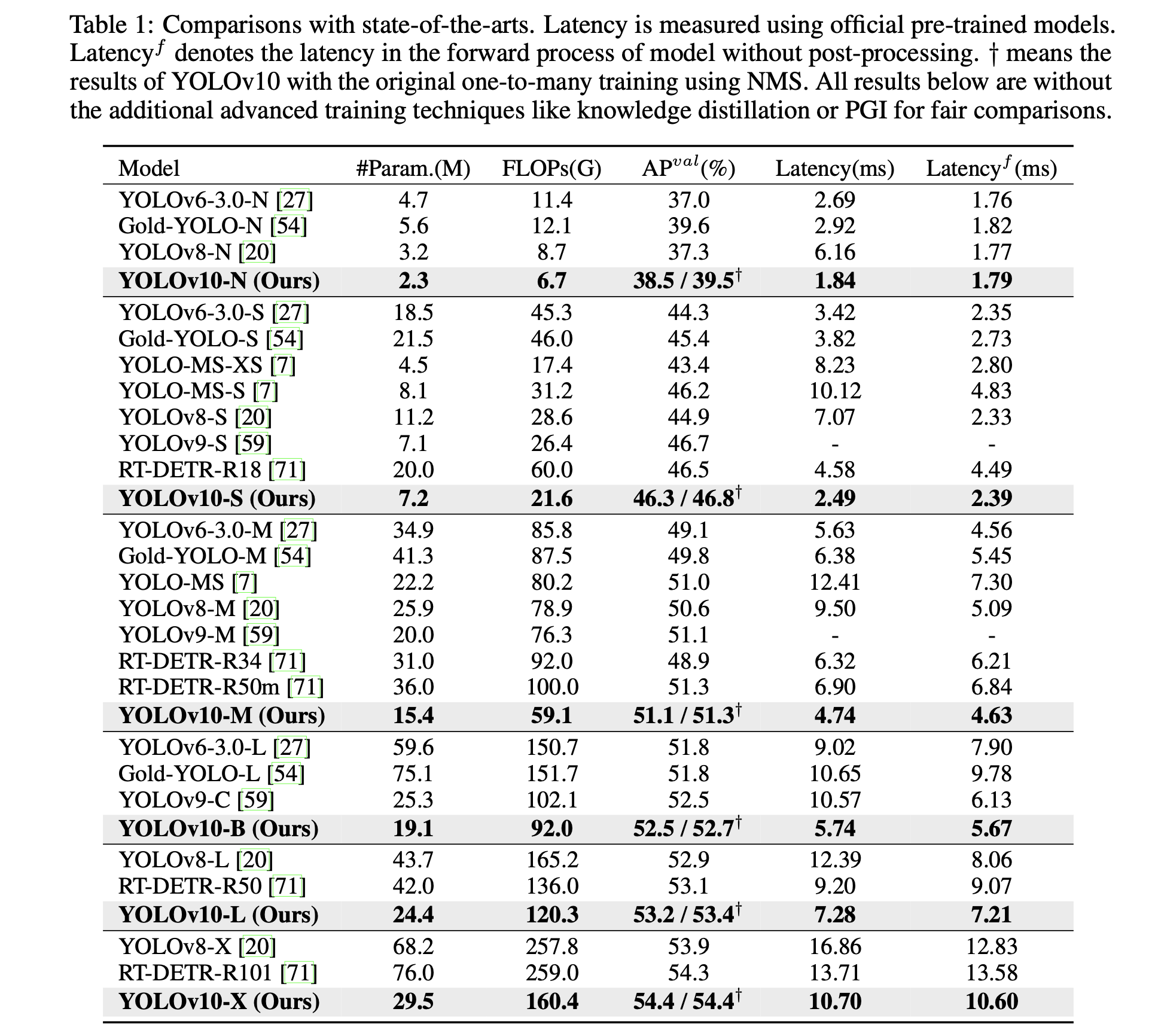
Extensive(광범위한) experiments로 YOLOv10이 다양한 model scale에서
SOTA performance and efficiency를 달성한다는 것을 보였다.
예를 들어,
YOLOv10-S는 COCO dataset에 대해서
비슷한 AP를 유지하면서 RT-DETR-R18보다 1.8배 빠르고, #params와 FLOPs는 2.8배 작다.
YOLOv9-C와 비교했을 때, YOLOv10-B는 동일한 성능을 유지하면서 latency가 46% 줄고, #params가 25% 적다.
thesis:
the consistent dual assignments for NMS-free training과
holistic efficiency-accuracy driven model design을 통해
강화된 real-time object detector를 소개한다.
1. Introduction
- Real-time object detection은 computer vision의 연구 영역에서 항상 focal point이다.
low latency 내에서 image의 object categories and positions을 정확하게 예측하는 것이 목표이다.
YOLOs는 performance and efficicency 사이의 좋은 balance 덕분에 인기가 증가하고 있다.
YOLOs의 detection pipeline은 두가지로 구성된다 :
the model forward process and the NMS post-processing.
하지만 두 단계는 여전히 결함이 존재하고, suboptimal accuracy-latency boundaries를 유발한다.
(문제점 1) : NMS는 inference latency가 크고, end-to-end detector들은 아직 optimal이 아니다.
- 구체적으로, YOLOs는 training 중에 one-to-many label assignment를 사용한다.
이는 우수한 성능을 보여주지만, inference 시 best positive prediction을 선택하기 위해 NMS가 필요하다.
이는 inference speed를 저하시킬 뿐만 아니라, NMS의 hyperparameter에 성능이 민감하게 반응하여 YOLOs가 optimal end-to-end deployment에 달성하는 것을 방해한다.- 이 문제를 해결하기 위한 한 가지 방법은 최근 도입된 end-to-end DETR architecture를 채택하는 것이다.
예를 들어, RT-DETR은 efficient hybrid encoder와 uncertainty-minimal query selection을 통해 DETRs을 real-time applications의 영역으로 끌어들였다.
그럼에도 불구하고, DETRs를 배포하는 데 내재된 complexity는 accuracy와 speed 간의 optimal balance를 달성하는 능력을 저해한다. - 또 다른 방법은 redundant prediction을 억제하기 위해 일반적으로 one-to-one assignment strategy를 활용하는 CNN-based detector를 위한 end-to-end detection을 탐구하는 것이다.
그러나 이들은 일반적으로 추가적인 inference overhead를 도입하거나 suboptimal perfomance를 달성한다.
- 이 문제를 해결하기 위한 한 가지 방법은 최근 도입된 end-to-end DETR architecture를 채택하는 것이다.
(문제점 2) : YOLO는 computational redundancy가 존재하기 때문에 suboptimal efficiency이다.
- 게다가, YOLO의 기본적인 challenge는 model architecture design이다.
efficient and effective model architecture를 위해서,
backbone에서 DarkNet, CSPNet, EfficientRep and ELAN 등
neck에서는 PAN, BiC, GD and REpGFPN 등이 연구되어 왔다.
이러한 연구들이 있었지만 아직 YOLOs에는 considerable computational redundancy가 존재하고,
inefficient parameter utilization and suboptimal efficiency를 유발한다.
- 이 연구에서는 이러한 문제들을 해결하고 YOLOs의 accuracy-speed boundaries를 확장하는 것이 목표이다.
detection pipeline 전반에 걸쳐 post-processing 및 model architecture를 대상으로 한다.
이를 위해,
- 우리는 먼저 consistent(일관된) dual assignments strategy를 제시하여
NMS-free YOLOs의 redundant prediction 문제를 해결한다.
dual label assignment와 consisten matching metric을 통해
model이 훈련 중에 풍부하고 조화로운 supervision을 받을 수 있도록 하며,
inference 시 NMS가 필요 없게 하여 high efficiency로 경쟁력 있는 성능을 달성할 수 있다.- 둘째로,
model architecture에 대한 전반적인 efficiency-accuracy 중심의 model design strategy를 제안하여
YOLOs의 다양한 구성 요소에 대한 종합적인 점검을 수행했다.
efficiency를 위해,
lightweight classification ehad, spatial-channel decoupled downsampling, and rank-guided block design을 제안하여
computational redundancy를 줄이고 더 효율적인 architecture를 구현한다.
accuracy를 위해,
large-kernel convolution을 탐구하고 효과적인 partial self-attention module을 제시하여
model의 성능 향상의 잠재력을 low cost로 활용한다.
2. Related Work
Real-time object detectors
-
Real-time object detection은
low latency 안에서 object를 classify and locate하는 것을 목표로 한다. -
과거 몇 년 동안, efficient detector를 위한 많은 노력들이 있었다.
- YOLOv1, v2, v3에서는 backbone, neck, head 3개 part로 구성된 detection architecture를 보였다.
- YOLOv4, v5는 DarkNet을 대체하기 위한 CSPNet design,
data augmentation strategies, enhanced PAN, 등을 소개했다. - YOLOv6는 neck and backbone 각각을 위한 BiC and SimCSPSPPF,
anchor-aided training and self-distillation strategy를 소개했다. - YOLO7은 풍부한 gradient flow path를 위한 E-ELAN을 소개하고
several trainable bag-of-freebies methods를 탐구했다. - YOLOv8는 effective feature extraction and fusion을 위한 C2f building block을 소개했다.
- Gold-YOLO는 multi-scale feature fusion capability를 확장시키기 위해
advanced GD mechanism을 소개했다. - YOLOv9은 architecture를 향상시키기 위한 GELAN과 training process를 확장시키기 위한 PGI를 소개했다.
End-to-end object detectors
-
End-to-end object detection은 traditional pipeline에서 벗어나
streamlined된 architecture를 제공하는 paradigm 전환으로 부각되고 있다.- DETR은 Transformer architecture를 도입하고 hungarian loss를 사용하여
one-to-one matching prediction을 달성함으로써 hand-crafted components와 post-processing을 제거했다.
그 이후, DETR variants들이 performance and efficiency를 향상시키기 위해 제안되었다. - Deformable-DETR은 multi-scale deformable attention module을 활용하여 convergence speed를 가속화했다.
- DINO는 contrastive denoising, mix query selection, and look forwrd twice scheme(두 번 앞으로 보기 방식)을 DETRs에 통합했다.
- RT-DETR은 efficient hybrid encoder를 설계하고 uncertainty-minimal query selection을 제안하여 accuracy and latency를 모두 개선했다.
- DETR은 Transformer architecture를 도입하고 hungarian loss를 사용하여
-
또 다른 End-to-end object detection은 CNN detectors를 base로 한다.
- Learnable NMS와 relation networks는 duplicated predictions을 제거하기 위해 또 다른 network를 제시한다.
- OneNet and DeFCN은 fully convolutional networks로 end-to-end object detection을 가능하게 하는 one-to-one matching strategies를 제안한다.
- FCOS는 optimal sample for predition을 선택하기 위한 positive sample selector를 도입했다.
3. Methodology
3.1 Consistent Dual Assignments for NMS-free Training
- training 중에,
YOLOs는 일반적으로 TAL(Task Alignment Learning)을 활용하여 각 instance에 대해 multiple positive samples을 할당한다.
one-to-many assignment를 채택하면 풍부한 supervisory signals이 제공되어 optimization이 용이해지고 superior performance을 달성할 수 있다.
하지만 이는 YOLOs가 NMS post-processing에 의존하게 만들어
deployment 시 suboptimal inference efficiency를 유발한다.
- 이전 연구들은 redundant predictions을 억제하기 위해 one-to-one matching을 탐구했으나,
이는 보통 추가적인 inference overhead를 도입하거나 최적의 performance를 제공하지 못한다.
이번 연구에서는dual label assignmentsandconsistent matching metric을 통해
NMS-free training strategy을 제시하여 high efficiency and competitive performance를 동시에 달성했다.
Dual label assignments
-
one-to-many assignment와 달리,
one-to-one matching은 각 ground truth에 하나의 prediction만 할당하여
NMS post-processing을 피할 수 있다.
그러나 이는 weak supervision(지도)을 유발하기 때문에,
suboptimal accuracy and convergence speed를 유발한다.
다행히, 이러한 결함은 one-to-many assignment로 보완할 수 있다.
이를 위해 YOLOs에 두 가지 할당 방식(one-to-one, one-to-many)를 결합하는
dual label assignment를 도입한다. -
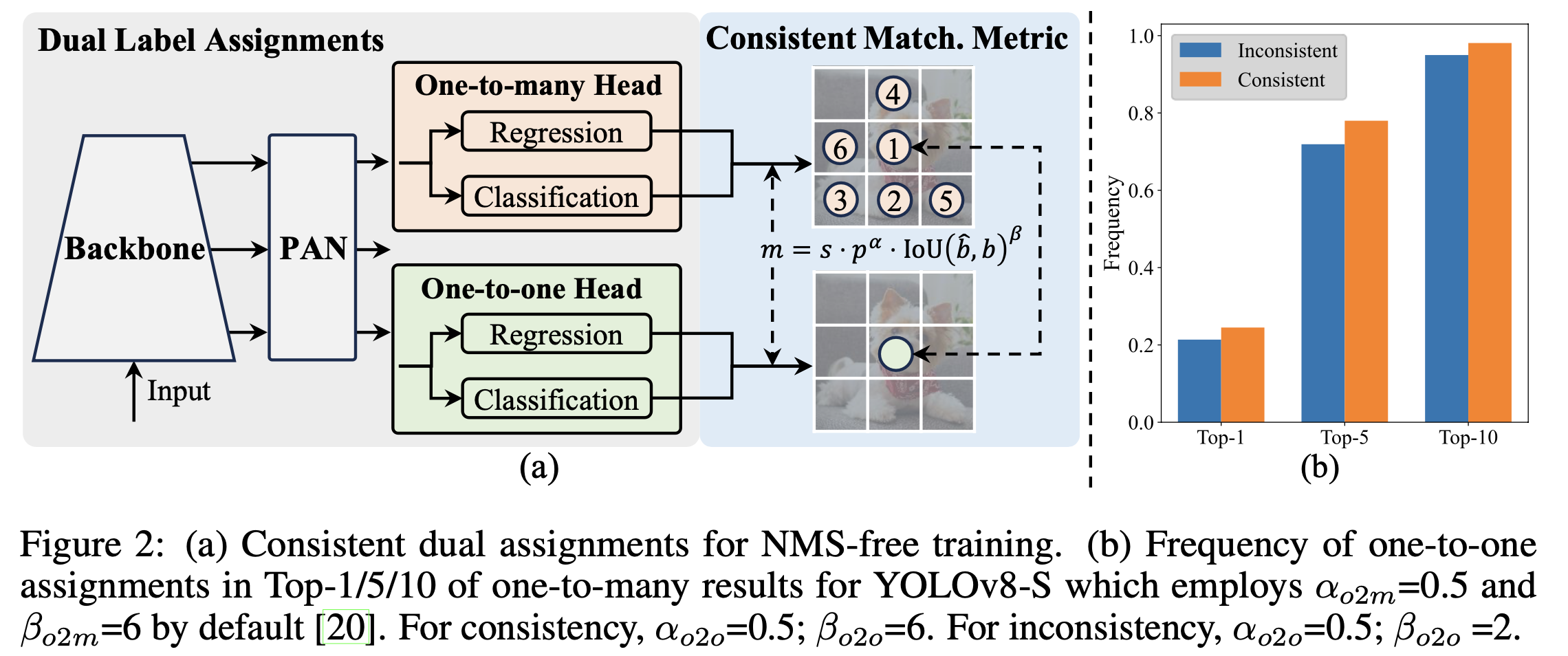
구체적으로, Figure 2.(a)에서 보여지는 것과 같이,
우리는 YOLOs에 또 다른 one-to-one head를 추가했다.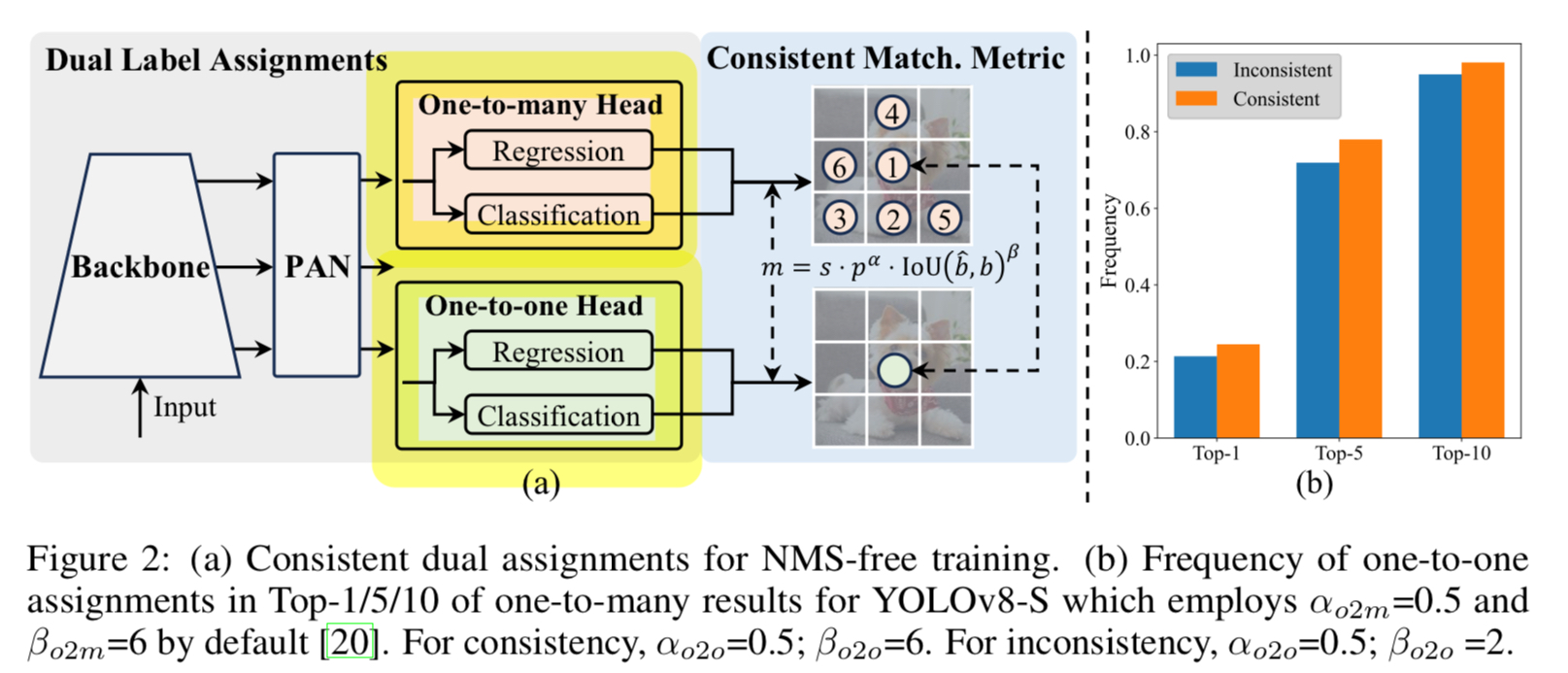 이 head는 동일한 구조를 유지하며 original one-to-many branch와 동일한 optimization objectives(목표)를 채택하지만,
이 head는 동일한 구조를 유지하며 original one-to-many branch와 동일한 optimization objectives(목표)를 채택하지만,
one-to-one matching을 활용하여 label assignments을 얻는다.
training 중에는 두 head가 model과 함께 jointly optimized되어
one-to-many assignment가 제공하는 rich supervision을 backbone과 neck에서 누릴 수 있게 한다.
inference 시에는 one-to-many head를 버리고 one-to-one head를 사용하여 prediction을 수행한다.
이를 통해 추가적인 inference cost 없이 end-to-end deployment가 가능해진다.
또한, one-to-one matching에서는 Hungarian matching과 동일한 성능을 달성하면서도
추가적인 training time을 덜 소모하는 top-1 selection을 채택한다.
Consistent matching metric
-
assignment 동안에,
one-to-one과 one-to-many 접근법들은 둘 다
predictions과 instances 사이의 concordance(일치)의 정도를 정량적으로 평가하기 위한 metric을 사용한다. -
두 branch 모두 prediction aware matching을 달성하기 위해, 우리는 uniform matching metric을 사용했다.
 우리는
우리는
one-to-many metrics을 ,
one-to-one metrics을
이라고 denote한다.- 는 classification score
- 는 bbox of preidction, 는 bbox of instance
- 는 prediction의 anchor point가 instance 내에 있는지를 나타내는 spatial prior
- 는 semantic prediction task(classification)을 위한 hyperparameter
- 는 location regression task(localization)을 위한 hyperparameter
-
dual label assignments에서,
one-to-many branch는 one-to-one branch 보다 much richer supervisory signal(훨씬 더 풍부한 지도 signal)을 제공한다.
직관적으로,
one-to-one head의 supervision을 one-to-many head와 harmonize(조화)시킬 수 있다면,
one-to-one branch를 one-to-head의 optimization 방향으로 최적화시킬 수 있다.
결과적으로,
one-to-one head는 inference 중에 더 향상된 quality의 samples을 제공하여 성능이 향상될 수 있다.
이를 위해,
우리는 먼저 두 heads 사이의 supervisoin gap을 분석하였다.
training 동안의 randomness 때문에, 우리는 동일한 값으로 초기화되고 동일한 predictions을 생성하는 두 heads로 분석을 시작했다.
(즉, one-to-one head와 one-to-many head는 같은 and IoU for each prediction-instance pair를 만드는 상태에서 분석을 시작)
우리는 두 branches의 regression targets은 충돌되지 않는다는 것을 강조한다.
왜냐하면 matching된 predictions은 동일한 targets을 공유하고 matching되지 않은 predictions은 무시되기 때문이다.
따라서 supervision gap은 서로 다른 classification targets에서 발생한다.
(bbox regression은 두 branch의 prediction이 동일하므로 gap을 측정할 수 없기 때문에,
classification targets으로 gap을 측정했다는 의미인듯?)
- 주어진 instance에 대해서,
그것의 largest IoU를 ,
largest one-to-many matching scores를 ,
largest one-to-one matching scores를 라고 부른다.
one-to-many branch가 positive samples 를 산출하고
one-to-one branch가 metric 인 번째 prediction을 선택한다고 가정하면,
(는 o2m이 예측한 모든 positive sample들, 는 o2o이 가장 잘 예측한 matching scores)
우리는 다음과 같이 classification target을 도출할 수 있다.
the classification target for
and for task aligned loss.
따라서 두 branch 사이의 supervision gap은 서로 다른 classification objectives(목표)의 1-Wasserstein distance로 도출될 수 있다.
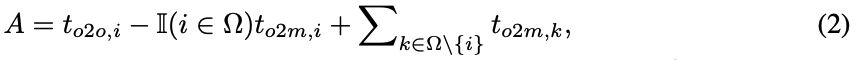 우리는 가 증가할수록 gap이 줄어드는 것을 관찰했다.
우리는 가 증가할수록 gap이 줄어드는 것을 관찰했다.
이는 가 내에서 higher ranks일 때 발생한다.
gap은 일 때 최소가 된다. (즉, 가 내에서 best positive sample일 때이다.)
이를 달성하기 위해,
우리는 consistent matching metric을 제안한다.
즉, and 이며, 이는 을 의미한다.
따라서 one-to-many head의 best positive sample은 one-to-one head에도 best positive sample이 된다.
결과적으로, 두 branch는 일관되고 조화롭게 optimized될 수 있다.
간단히 하기 위해, default로 , 즉 and 을 사용했다.
(gap =를 줄이기 위해, 을 증가시켜야 한다는 의미인듯?)
향상된 supervision alignment를 확인하기 위해,
우리는 one-to-one matching pairs의 top-1/5/10 내에서 one-to-one matching의 수를 training 후에 계산했다.
Figure 2.(b)에 표시된 바와 같이, consistent matching metric 하에서 alignment가 향상되었다.
(수학적 증명의 더 포괄적 이해를 위해, appendix를 참고)
Holistic Efficiency-Accuracy Driven Model Design
- post-processing 외에도,
YOLOs의 model architectures는 efficiency-accuracy trade-offs에서 큰 challenges를 제기한다.
비록 이전 연구에서는 다양한 design strategies를 탐구했지만, YOLO의 다양한 components에 대한 종합적인 검토는 여전히 부족하다.
그 결과, model architecture는 무시할 수 없는 computational redundancy and constrained capability를 보여주며
이는 high efficiency and performance를 달성하기 위한 잠재력을 방해한다.
이제, 우리는 efficiency and accuracy 관점에서 YOLOs를 전체적으로 design하고자 한다.
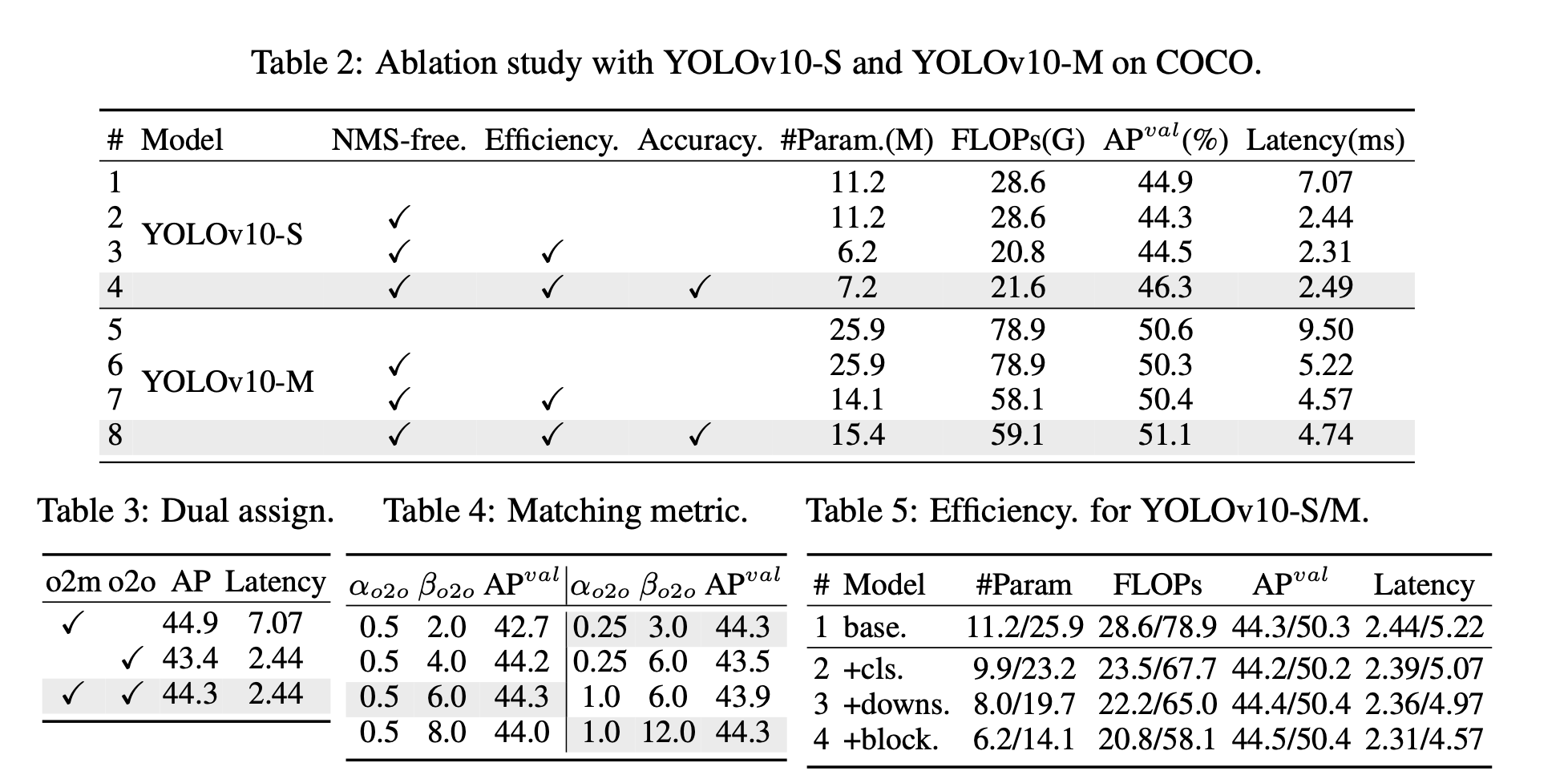
Efficiency driven model design
-
(1) : Lightweight classification head.
YOLO에서 classification과 regression heads는 보통 동일한 architecture를 공유한다.
하지만, 이 두 Head는 computational overhead에 있어 상당한 차이를 보인다.
예를 들어,
YOLOv8-S에서
classification head의 FLOPs와 #param은 각각 5.95G/1.51M으로,
regression head의 2.34G/0.64M에 비해 2.5배 정도 많다.
그러나 classification error와 regression error를 분석한 결과(Tab. 6), regression head가 YOLO의 성능에 더 중요한 역할을 한다는 것을 발견했다.
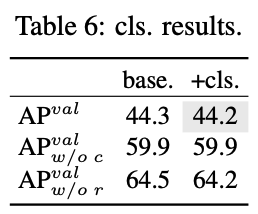 따라서 성능에 큰 영향을 주지 않고도 classification head의 overhead를 줄일 수 있다.
따라서 성능에 큰 영향을 주지 않고도 classification head의 overhead를 줄일 수 있다.
따라서 우리는 단순히 classifiaction head에 대한 lightweight architecture를 채택하여,
두 개의 3x3 kernel size의 depthwise separable convs와, 뒤 따르는 1x1 conv로 구성했다. -
(2) : Spatial-channel decoupled downsampling.
YOLOs는 일반적으로 stride 2의 standard conv를 이용하여,
spatial downsampling(from to ) 및 channel transformation (from to )을 동시에 수행한다.
이는 의 computational cost와 의 parameter 수를 도입하게 된다.
대신, 우리는 spatial reduction과 channel increase operations을 분리하여 더 효율적인 downsampling을 가능하게 하는 방법을 제안한다.
구체적으로,
먼저 pointwise conv를 활용하여 channel dimension을 조절한 후,
depthwse conv을 활용하여 spatial downsampling을 수행한다.
이는 computational cost를 로, #params를 로 줄여준다.
동시에 downsampling 중 information retention(정보 보존)을 최대화하여,
latency reduction과 함께 경쟁력 있는 성능을 제공한다. -
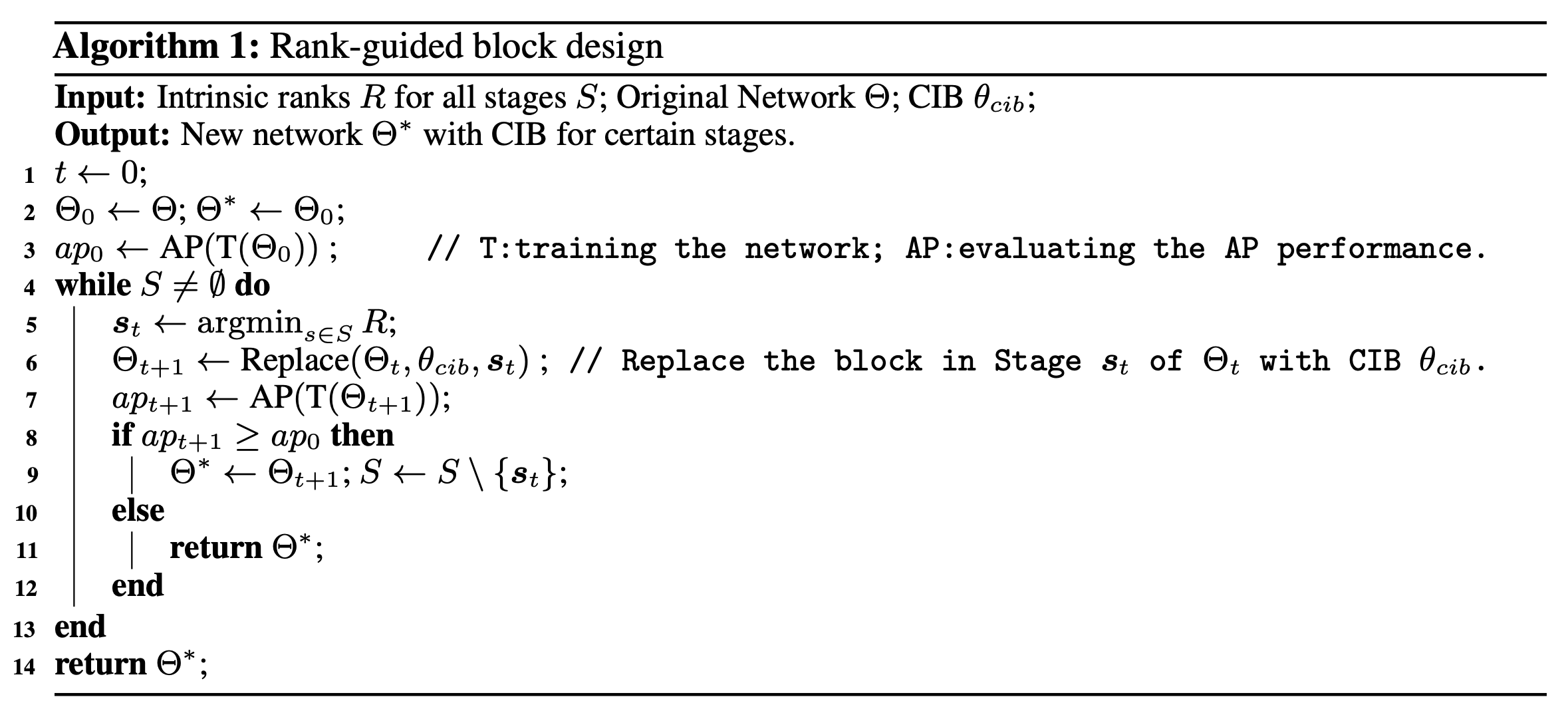
(3) Rank-guided block design.
YOLOs는 보통 모든 stages에서 same basic building block을 사용한다.
(YOLOv8에서는 bottleneck block을 사용)
YOLOs를 위한 homogeneous(동차의) design을 철저히 검토하기 위해,
우리는 각 stage의 redundancy를 분석하기 위한 intrinsic(내재적) rank를 사용한다.
구체적으로,
각 stage의 마지막 basic block에서 마지막 conv의 numerical rank를 계산하는데,
이는 threshold보다 큰 singular values의 수를 세는 것이다.
Fig. 3.(a)는 YOLOv8의 결과를 보여주며, deep stages and large model이 더 많은 redundancy를 보이는 경향이 있음을 나타낸다.
이 관찰은 모든 stage에 동일한 block design을 적용하는 것이 best capacity-efficiency trade-off가 아니라는 것을 시사한다.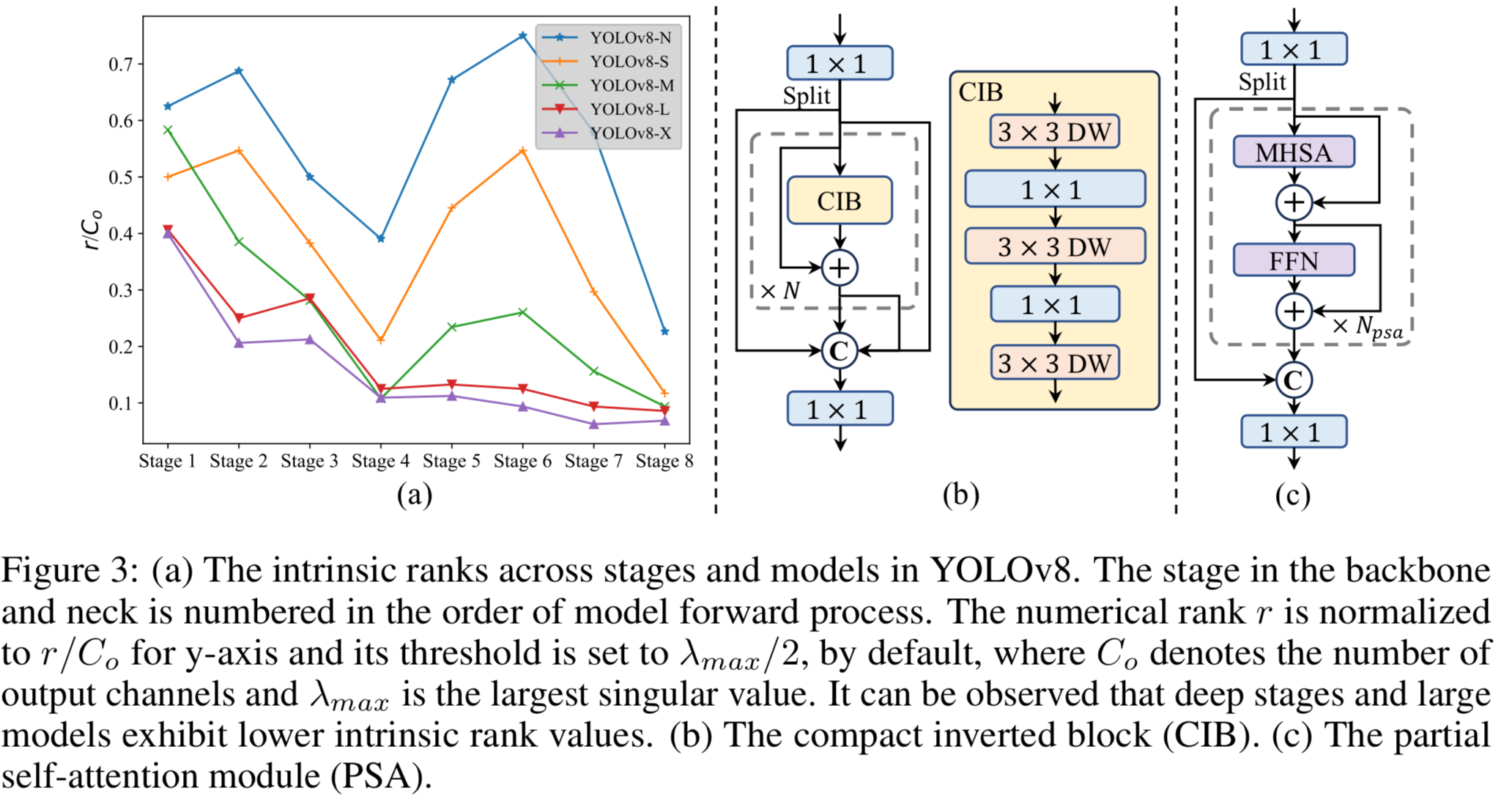 이를 해결하기 위해, 우리는 redundant가 있는 stage의 complexity를 줄이기 위해 rank-guided block design scheme을 제안한다.
이를 해결하기 위해, 우리는 redundant가 있는 stage의 complexity를 줄이기 위해 rank-guided block design scheme을 제안한다.
먼저, spatial mixing을 위한 cheap depthwise convolutions과 channel mixing을 위한 cost-effective pointwise convolutions을 채택한
compact inverted block(CIB) structure를 제시한다.
이는 ELAN structure에 embedded될 수 있는 efficient basic building block 역할을 할 수 있다.
다음으로,
경쟁력 있는 capacity를 유지하면서 best efficiency를 달성하기 위해 rank-guided block allocation strategy를 권장한다.
구체적으로,
model이 주어지면 모든 stage를 intrinsic ranks에 따라 오름차순으로 정렬한다.
그런 다음, leading stage의 basic block을 CIB로 교체하는 성능 변화를 검사한다.
주어진 model과 비교하여 성능 저하가 없으면 다음 stage로 교체를 진행하고, 그렇지 않으면 process를 중단한다.
결과적으로,
우리는 성능을 손상시키기 않으면서 높은 efficiency를 달성하기 위해 stage 및 model scales에 걸쳐 adaptive compact block design을 구현할 수 있었다.
(page 제한으로 인해, details of algorithm은 appendix에..)
Accuracy driven model design
-
우리는 accuracy driven design을 위해서,
large-kernel conv and self-attention을 추가로 탐구하여 minimal cost 안에서 performance를 향상시키고자 하였다. -
(1) Large-kernel convolution :
large-kernel depthwise conv는 receptive field와 model's capacity를
확장시킬 수 있는 효과적인 방법이다.
하지만,
이를 모든 stage에서 단순히 사용하는 것은 small object를 detection하기 위한
shallow features를 초래할 수 있으며,
high-resolution stages에서 상당한 I/O overhead와 latency를 유발할 수 있다.
따라서,
우리는 deep stages에서 CIB 내에 large-kernel depthwise convolutions을 활용할 것을 제안한다.
구체적으로, CIB의 두 번째 3x3 depthwise conv의 kernel size를 7x7로 증가시킨다.
추가적으로, structural reparameterization 기법을 사용하여 optimization 문제를 완화하면서 inference overhead 없이 또 다른 3x3 depthwise convolution branch를 도입한다.
또한, model size가 커질수록 receptive field가 자연스럽게 확장되므로,
large-kernel conv는 small model scales에만 채택한다. -
(2) Partial self-attention (PSA).
Self-attention은 뛰어난 global modeling capability 덕분에 다양한 visual tasks에서 널리 사용되고 있다.
하지만,
Self-attention은 high cmoputational cost and memory footprint가 존재한다.
이를 해결하기 위해서,
attention head redundancy를 고려하여 효율적인 partial self-attention(PSA) design을 제안한다.
이는 Fig.3.(c)에 있다.
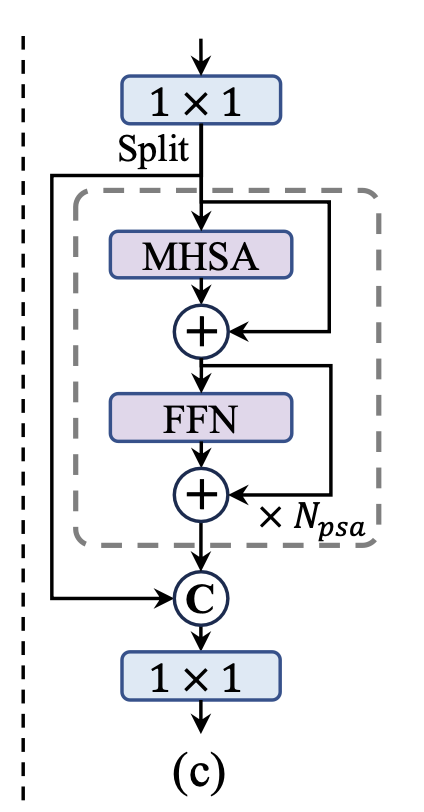 구체적으로,
구체적으로,
1x1 conv 후에 feature를 channel 별로 두 부분으로 균등하게 분할한다.
한 부분만 multi-head self-attention module(MHSA)와 FFN으로 구성된 block에 입력한다.
두 부분은 다시 concatenated되고 1x1 conv에 의해 fusion된다.
또한, LeViT([21])에 따라 MHSA에서 query와 key의 dimension을 value의 절반으로 할당하고,
fast inference를 위해 LayerNorm을 BatchNorm으로 교체한다.
게다가, PSA는 self-attn의 quadratic computational complexity으로부터
초과의 overhead를 줄이기 위해 resolution이 가장 낮은 Stage 4 이후에만 배치된다.
이러한 방식으로, low computational cost로 global representation learing ability를 YOLOs에 통합하여 model의 capability와 성능을 향상시킬 수 있다.
4. Experiments
4.1 Implementation Details

4.2 Comparison with state-of-the-arts
4.3 Model Analyses
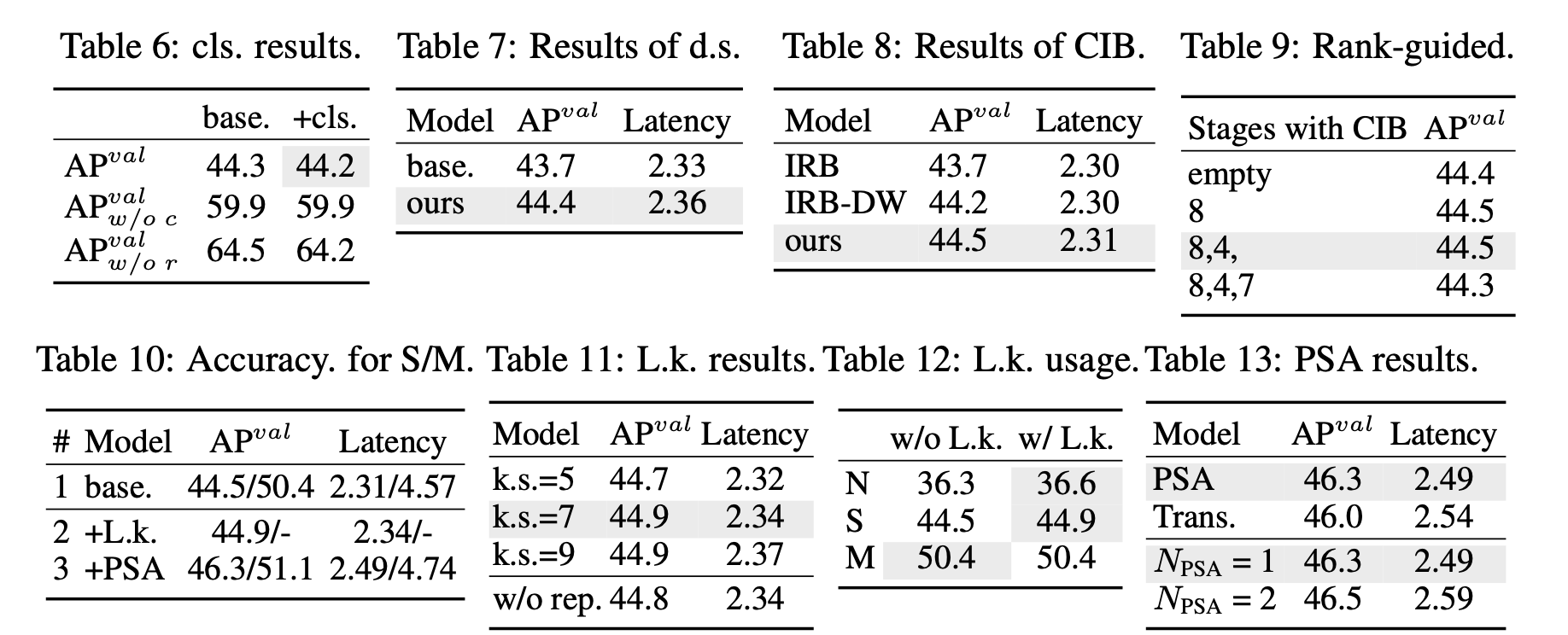
5. Conclusion
-
이 연구에서,
우리는 YOLOs의 detection pipeline 전반에 걸쳐 post-processing과 model architecture를 목표로 했다.- post-processing에 대해서,
우리는 NMS-free training을 위한 consistent dual assignments를 제안하여
efficient end-to-end detection을 달성했다. - model architecture에 대해서는 performance-efficiency trade-offs를 개선하는
holistic(전방위적인) efficiency-accuracy driven model design strategy를 도입했다.
- post-processing에 대해서,
-
이를 통해 YOLOv10, a new real-time end-to-end object detector를 탄생시켰다.
