- 자료 참고, 출처 :
- 이 사전 지식들의 original paper를 모두 읽진 않고, 어떠한 아이디어인지만 간략하게 알기 위한 정리.
2.2. Bag of freebies
Bag of Freebies(BoF):
inference cost를 증가시키지 않고도 accuracy를 높이는 방법이 몇가지 있는데,
우리는 이것을 bag of freebies(BoF) 라고 부른다.
data augmentation
photometric distortions (Brightness, contrast, hue, saturation, noise)
photometric distortions:
brightness, contrast, hue(색상, 빛깔), saturations(채도), noise를 조정하여 data augmentation
 https://wikidocs.net/163078
https://wikidocs.net/163078
geometric distortions (Random scaling, cropping, flipping, rotating)
geometric distortions:
image scaling, cropping, flipping, rotating하여 data augmentation

 https://wikidocs.net/163078
https://wikidocs.net/163078
random erase
random erase:
일반적인 data augmentation 기법(flipping, cropping, rotating 등)의 occlusion(폐색)문제의 한계를 해결하기 위한 기법.- occlusion : 하나의 object가 다른 object에 의해 가려지는 문제
- occlusion 문제를 해결하기 위해 training image들에 대해서
- kept unchanged
- we randomly choose a rectangle region of an arbitrary size, and assign the pixels within the selected region with random values(or the ImageNet mean pixel value)

- random erasing으로 인한 효과로는
- 전체 부분의 일부를 가리는 것이므로 random cropping에 비해 object의 전체 구조가 보존됨.
- random하게 지정된 region에 값을 재할당하는 행위는 noise를 가하는 행위와 비슷함.
이는 noise와 occlusion에 robust하도록 만듦.
또한 overfitting을 regularization하는 효과.
(data augmentation과 regularization이 동시에 존재) - parameter 학습이 전혀 필요 없고, memory 소모가 필요하지 않으면서, 가벼운 기법임

CutOut
https://arxiv.org/pdf/1708.04552.pdf
CutOut:
main idea로는 "occlusion 문제를 해결하기 위해 일부러 occlusion된 image를 network에 학습시키자."
CutOut은 dropout 방식과 유사하지만 두 가지 중요한 차이점이 존재- cutout은 오직 CNN의 input layer unit만 생략한다.
- cutout에서 생략되는 영역은 개별 pixel 단위가 아니라, 연속된 영역이다.
연속된 영역의 생략은 이어지는 feature map으로 전파되고, context에 의해 생략정보가 복구되지 못하게 한다.

random erasing과 CutOut의 차이점은
비워진 영역에 값을 채운다면? random erasing. 아니면? CutOut인듯.
보통 혼합해서 쓰인다고 함.
hide-and-seek and grid mask
hide-and-seek:
image를 grid로 나누어 각 patch를 매 iteration마다 random하게 지우면서 학습하는 방법.
이는 object의 한 부분에 집중하는 것이 아닌 다양한 부분을 보면서 general하게 prediction할 수 있는 효과.
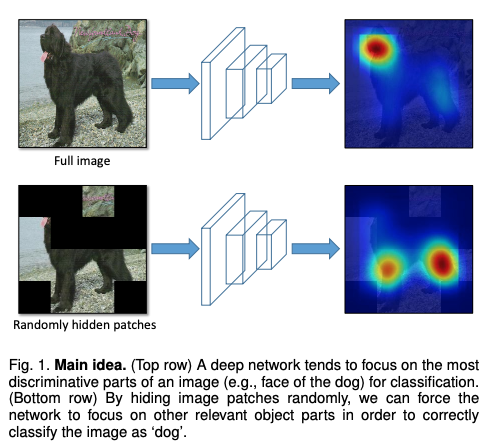
MixUp, (BoF for backbone) Label Smoothing
-
https://www.youtube.com/watch?v=9lJyowQgJ8o
 input 를 output 로 mapping하는 model 를 찾는 것이 목표.
input 를 output 로 mapping하는 model 를 찾는 것이 목표.- Risk는 Loss의 Expectation = 와 의 loss의 기댓값
이는 공간에서 Loss 값을 적분한 결과라고 정의할 수 있음 - 에 대한 Risk를 최소로 만드는 를 찾는 것이 목적.
- 실제로는 전체 공간 를 알지 못하고, 일부분만 알고 있기 때문에 라고 정의함.
Empirical Risk는 우리가 갖고 있는 data에 대한 Risk이다.
우리의 data는 finite(한정적, 유한한)하기 때문에 적분이 아니라 전체 Loss의 평균을 구하는 것으로 대체될 수 있다. - 결론적으로
Empirical Risk를 최소로 하는 를 찾는 것이 목표이다.
- Risk는 Loss의 Expectation = 와 의 loss의 기댓값
-
즉,
ERM(Empirical Risk Minimization)은
새로운 data가 들어왔을 때 일반적으로 딥러닝 model이 학습하는 방식이다. -
mixup simple code로 기존의 ERM 대신 수정된 학습 방법을 사용한다.
mixup simple code로 새로운 를 만들어 낸다.


-
위의 mixup code로 아래의 그림처럼 새로운 data를 만들어 낸다.
이는 data augmentation과 동시에 regularization 효과가 있다.

-
label smoothing은 generalization 성능을 높이기 위해 label을 smoothing하는 기술.
구체적으로 3개의 class가 존재한다고 가정했을 때,- one-hot vector로 표현하는 방식을 hard labeling 방식이라고 한다.
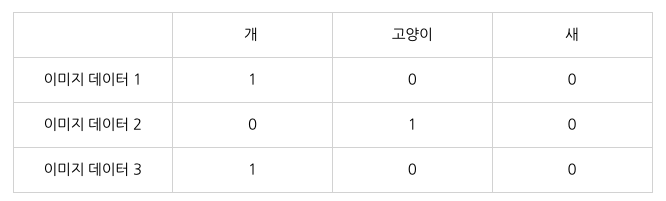
- 반면에 label을 smoothing해서 정답 class만이 아닌 다른 class에 대해서도 확률 값을 부여하는 것이 soft labeling(label smoothing) 방식이라고 한다.
이는 model이 과잉 확신을 하지 않도록 하여, overfitting을 막는 효과가 있어 generalization 성능이 좋아진다고 함.
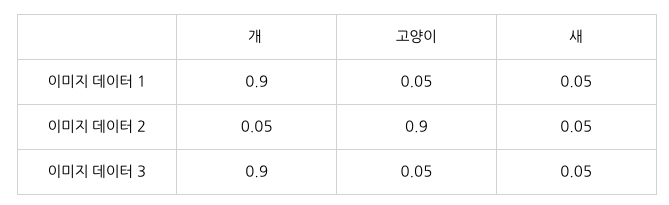
- one-hot vector로 표현하는 방식을 hard labeling 방식이라고 한다.
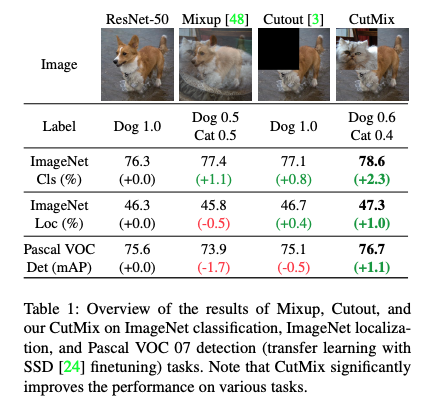
(BoF for backbone) CutMix
CutMix는 Cutout과 Mixup을 합친 data augmentation 기법.


(BoF for backbone) Mosaic
mosaic은 4개의 서로 다른 image의 size를 줄여 한 장의 image로 만드는 기법이다
 https://www.analyticsvidhya.com/blog/2023/12/mosaic-data-augmentation/
https://www.analyticsvidhya.com/blog/2023/12/mosaic-data-augmentation/
mosaic data augmentation의 효과로,
1장의 image로 4장의 image를 학습하는 효과를 주어 적은 batch size로도 학습이 용이하고,
object size가 줄어들어 작은 object를 detection하기 어렵다는 YOLO의 단점을 극복할 수 있게 한다.
DropOut, DropConnect
https://startnow95.tistory.com/3
-
dropout은 layer의 node를 random하게 0으로 만듦.
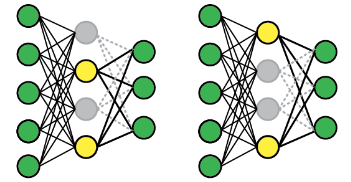
-
dropconnect는 layer의 weight를 비활성화시키고, node는 그대로 활성화되도록 유지.
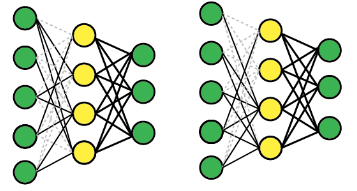
(BoF for backbone, detector) DropBlock
dropblock은 random하게 node를 0으로 만드는 것이 않는다.
이는 semantic information을 removing하는 데에 효과적이지 않기 때문에
activations 근처에 관련 information(node)들을 drop하여
즉, continuous regions을 dropping함으로써 certain semantic information(e.g. head or feet)을 removing할 수 있다.
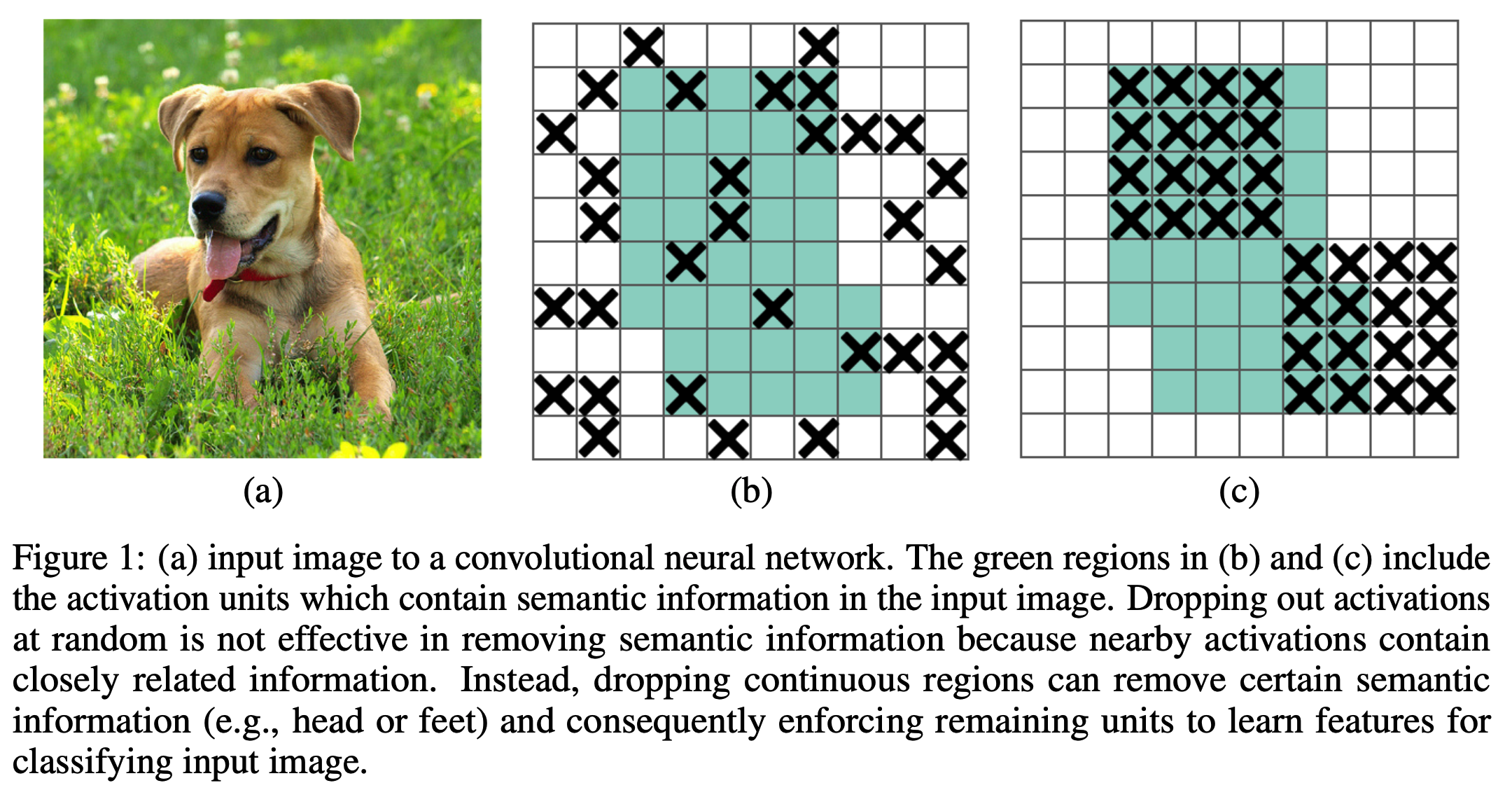
focal loss
https://gaussian37.github.io/dl-concept-focal_loss/
focal loss는 one-stage detector의 accuracy 성능을 개선하기 위해 고안됨.
one-stage detector는 two-stage detector에 비해 class imbalance가 심하다는 것이다.- 예를 들어,
background에 대하여 box를 친 것과 실제 object에 대하여 box를 친 것의 비율을 살펴보면
압도적으로 background에 대하여 box를 친 것이 많다는 것이다. - 대부분의 location은 학습에 필요가 없는 easy negative이므로 학습에 비효율적임
easy negative 각각은 높은 확률로 object가 아님을 잘 구분될 수 있어서 loss값은 작지만
비율이 굉장히 크기 때문에 전체 loss 및 gradient를 계산할 때, easy negative의 영향이 압도적으로 커지는 문제가 발생.
➡️ Focal Loss
- 예를 들어,
Focal Loss는 easy example의 weight를 줄이고 hard negative example에 대한
학습에 초점을 맞추는 Cross Entropy Loss 함수의 변형이라고 할 수 있음.
Cross Entropy Loss, 에서- Loss에 곱해지는 항인 에서 의 값을 잘 조절해야 좋은 성능을 얻을 수 있음.
- 추가적으로 전체적인 loss 값을 조절하는 값 또한 논문에서 사용되어 값을 조절하여 적절한 값을 제시했다.
논문에서는 를 최종적으로 사용했음.
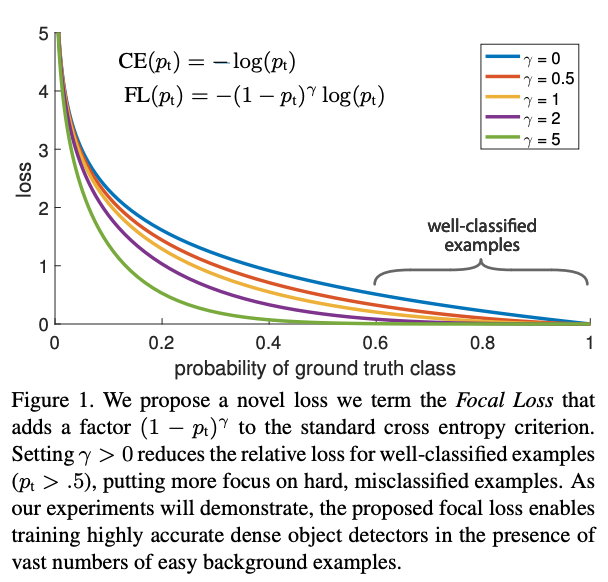 위 그래프를 통하여 focal loss의 속성을 다음과 같이 3가지로 분류할 수 있음
위 그래프를 통하여 focal loss의 속성을 다음과 같이 3가지로 분류할 수 있음- 잘못 classification되어 가 작아지게 되면 도 1에 가까워지고 log(p_t)값 또한 커져서 loss에 반영됨
- 가 1에 가까워지면 은 0에 가까워지고 CE Loss와 동일하게 값 또한 줄어듦.
- 에서 를
focusing parameter라고 하며 Easy Example에 대한 loss 비중을 낮추는 역할을 함.
knowledge distillation
(https://youtu.be/pgfsxe8sROQ?si=ezs1hWvSGkTgkNt8)
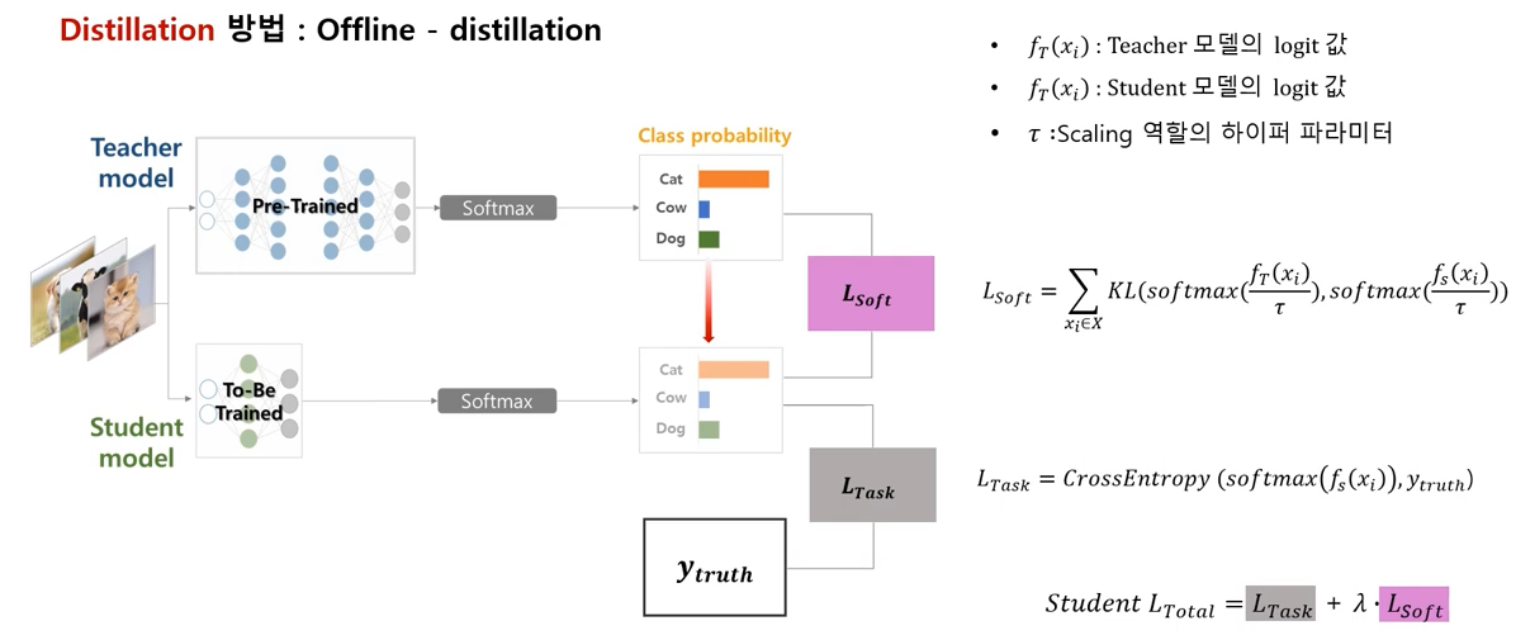
knowledge distillation:
prediction accuracy가 높은 teacher model(big & deep)의 knowledge를
전달하여 단순한 student model(small & shallow) model로 비슷한 좋은 성능을 내고자 하는 아이디어- 구체적인 방법 :
- knowledge :
logit이 softmax를 거쳐 나온 class probability = soft target를 teacher model의 knowledge로 사용한다.
(hard target으로 한다면, 정보의 손실이 크기 때문에 soft target)
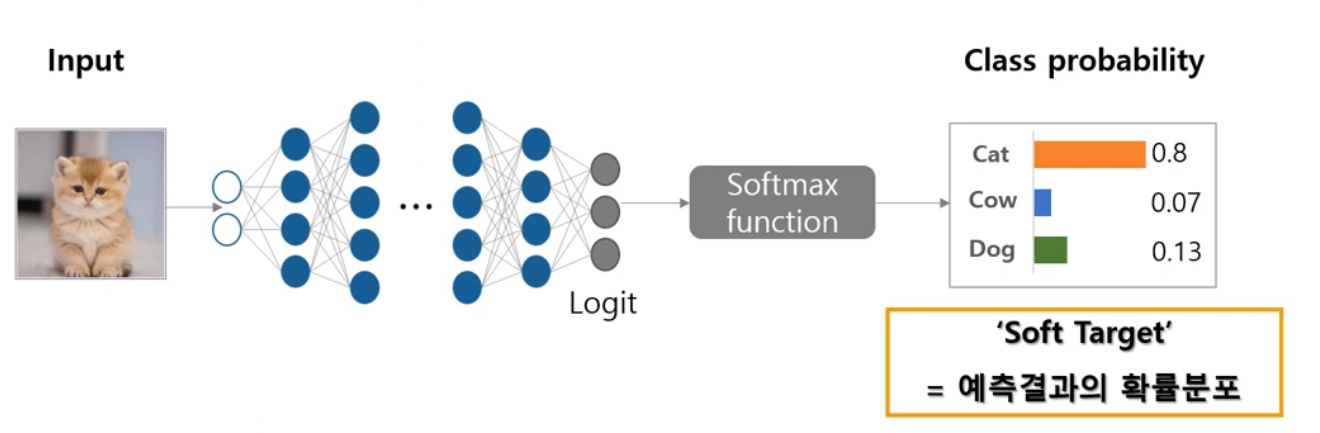 soft target에서 가장 큰 logit을 갖는 출력값은 1에 매우 가깝고,
soft target에서 가장 큰 logit을 갖는 출력값은 1에 매우 가깝고,
나머지는 logit을 갖는 출력값은 0에 매우 가까운 값을 가지게 될 것임.
(Temperature) : scaling 역할의 hyper parameter 인데,
일 때, softmax function과 동일
일 수록, 더욱 softer probability distribution을 갖게 된다.
- distillation :
teacher model을 pre-trained시켜 높은 성능을 만들게 한다.
student model은 teacher model의 probability distribution과 유사하도록 학습되어진다.
학습시에,
loss function에 distillation loss term을 추가하고 teacher model의 knowledge를 반영하면서 학습된다.
- knowledge :
- 구체적인 방법 :
GIoU Loss
-
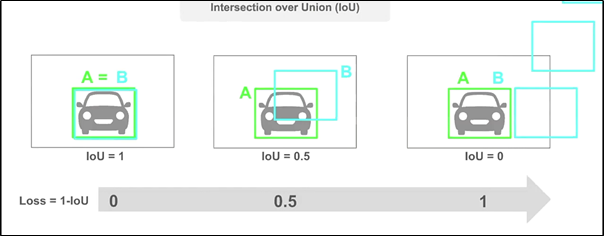
IoU loss는 다음과 같이
predicted bbox와 gt bbox의 IoU가 0일 때, 어느 정도의 오차로 생기는지 알 수 없어서 문제가 생긴다.
이를 해결하기 위한 방법이GIoU(Generalized IoU)이다.
-
GIoU:

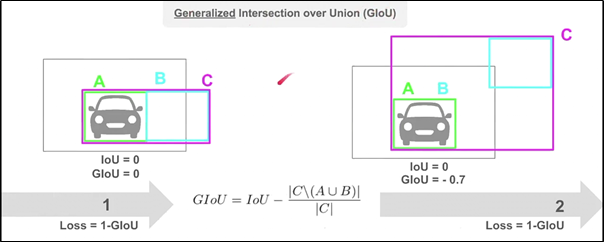
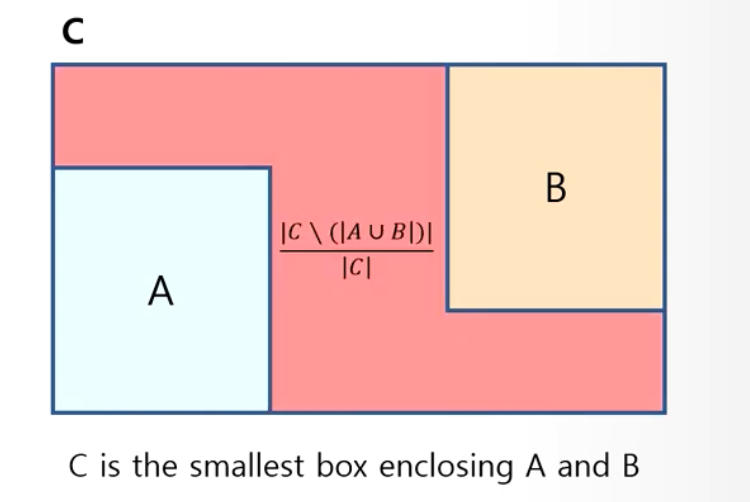 C bbox는 A(gt bbox)와 B(predicted bbox)를 포함하는 가장 작은 bbox이다.
C bbox는 A(gt bbox)와 B(predicted bbox)를 포함하는 가장 작은 bbox이다.
Algorithm 1에 따라- IoU가 1인(GT bbox와 완전히 일치) 경우에는,
IoU=1 이 되고, C bbox term이 0이 되니까 GIoU = 1이 되고, Loss = 1 - GIoU = 0이 된다. - IoU가 0인(GT bbox와 완전히 불일치) 경우에는,
IoU=0이 되고, C bbox term은 어느 정도 불일치하는냐에 따라 값이 커지게 된다.
만약 불일치의 정도가 매우 크다면, C bbox term은 1에 가까워지게 되고,
GIoU는 -1에 가까워지게 되어, Loss는 2에 가까워지게 된다.
- IoU가 1인(GT bbox와 완전히 일치) 경우에는,
-
따라서 Loss function을 1-GIoU로 하게 된다면, loss는 0~2의 값의 범위를 갖게 된다.
DIoU Loss
DIoU (Distance-IoU):
DIoU는 두 box가 겹치지 않았을 때,
GIoU처럼 bbox의 영역을 넓히지 않고 중심 좌표를 통해 박스의 distance 차이를 최소화함으로써 수렴 속도를 향상.
(BoF for detector) CIoU Loss
- bbox에 대한 좋은 Loss는 overlap area, central point distance, aspect ratio 세 요소를 고려하는 것이라고 주장함.
따라서 overlap area와 central point distance를 고려하는 DIoU에
추가적으로 aspect ratio를 고려하는 CIoU를 제안함.
2.3. Bag of specials
enhance receptive field
(BoS for detector) SPP
https://www.youtube.com/watch?v=i0lkmULXwe0
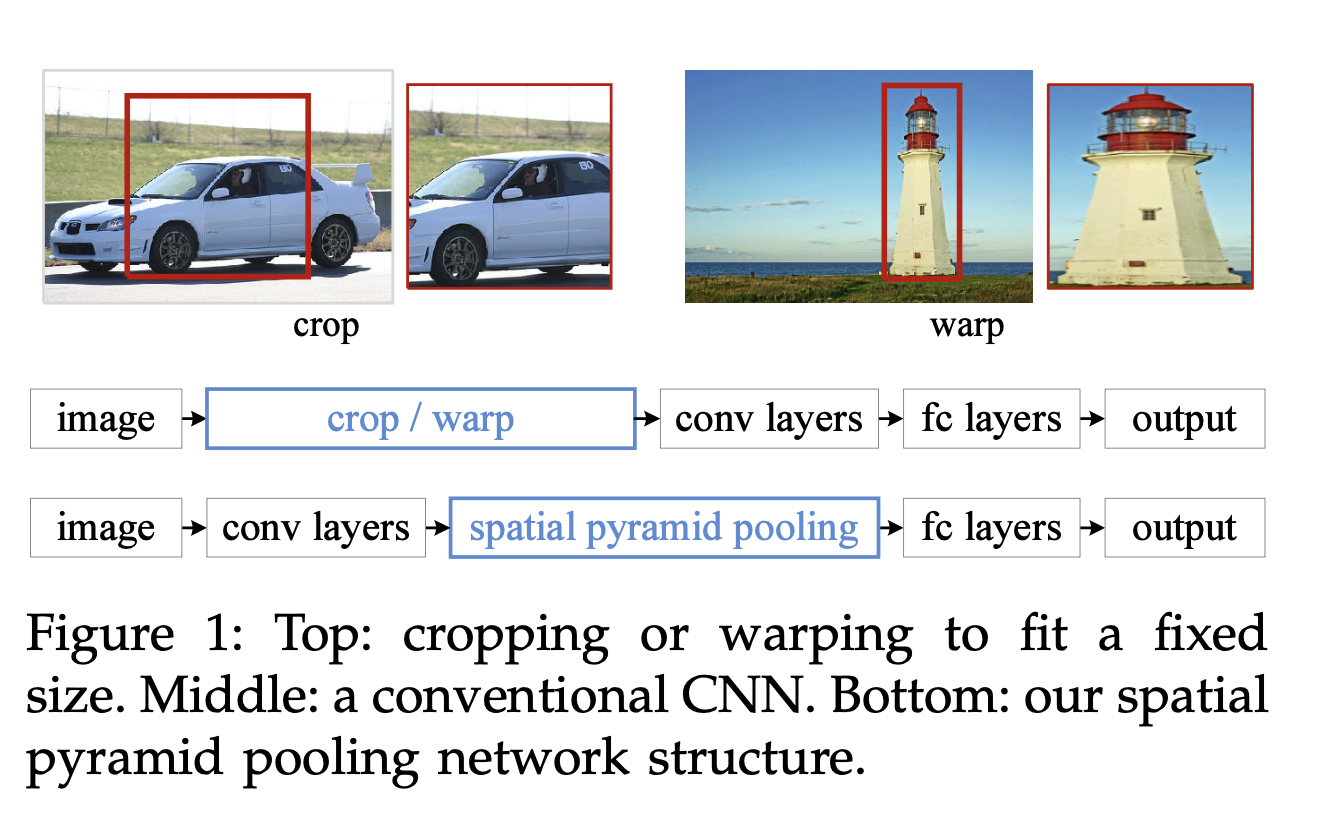
SPP의 가장 큰 contribution은 고정된 size의 input image를 넣지 않아도 되는 것.
이전에는 image -> data preprocessing -> conv layers -> fc layers -> output
SPP는 image -> conv layers -> Spatial Pyramid Pooling -> fc layers -> output
- 논문에서는 SPPNet을 extension of Bag-of-Words(BoW) model 이라고 말함.
Bag-of-Words란?
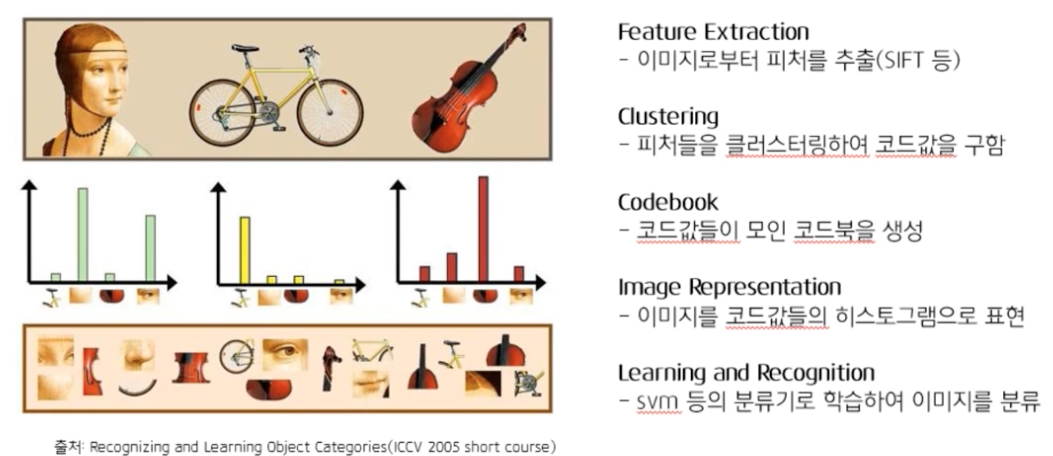
SPPNet에서는 BoW에서처럼 다양한 feature들의 값으로 표현하게 됨.
SPPNet에서는 feature들을 bin이라고 함.
다양한 크기의 bin(일정한 개수 개)을 통해 고정된 길이의 결과값을 만듦과 동시에, 다양한 scale의 feature를 extraction.
다양한 scale의 feature를 extraction했기 때문에, 특정 scale에 대해서 overfitting하는 다른 model의 문제점을 개선할 수 있었음.- details :
bin을 일정한 개수 m개로 고정.
각 공간 bin에 k개의 filter pooling.
최종적으로 k x m 차원의 고정길이 vector가 만들어짐.
예를 들어,
bin은 4x4, 2x2, 1x1으로 21개.
filter는 conv5의 filter 256개.
최종적으로 21 x 256 차원의 고정길이 vector가 만들어짐.

- details :
ASRP
(skip)
RFB
(skip)
attention module
Squeeze-and-Excitations(SE)
(skip)
(BoF for detector) Spatial Attention Module(SAM)
Spatial Attention Module(SAM):
CBAM은 CAM(Channel Attention Moduule) + Spatial Attention Module(SAM) 으로 구성되어 있어서
SAM은 CBAM의 구성 요소가 된다.
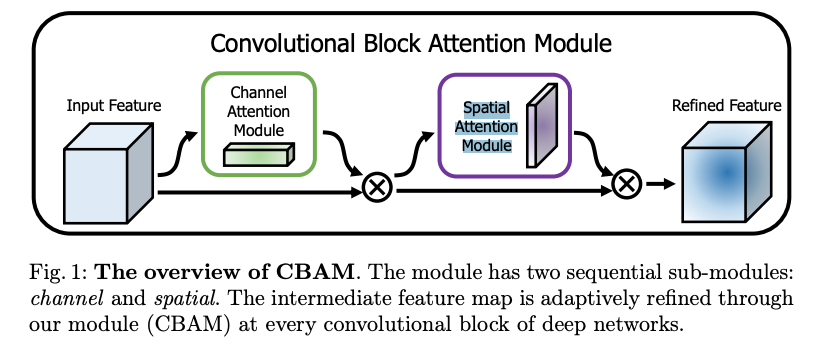
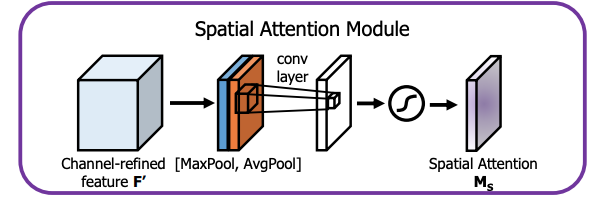
 CAM에서 channel attention map과 input feature map을 곱하여 생성한 에서 channel을 축으로 Maxpool, Avgpool을 적용해 생성한 1 x H x W의 F_avg, F_max를 concat한다.
CAM에서 channel attention map과 input feature map을 곱하여 생성한 에서 channel을 축으로 Maxpool, Avgpool을 적용해 생성한 1 x H x W의 F_avg, F_max를 concat한다.
여기에 7 x 7 conv를 적용하여 Spatial Attention Map을 생성.- SAM은 어디에 중요한 정보가 있는지 집중하도록 하는 효과가 있다고 함.
feature integration
Skip connections
(skip)
hyper-column
(skip)
SFAM
(skip)
ASFF
(skip)
BiFPN
(skip)
activation function
LReLU
PReLU
ReLU6
ReLU6:
https://gaussian37.github.io/dl-concept-relu6/
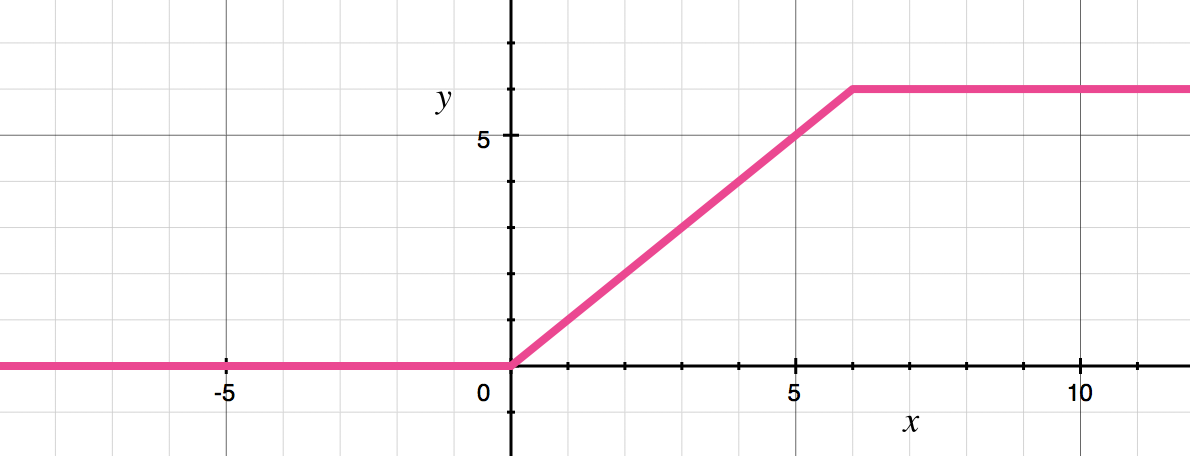
- ReLU6를 사용하는 이유 :
DL model 성능을 최적화할 때, fixed-point로 변환해야 하는 경우가 있다.
특히 embedded에서는 중요한 문제이다.
만약 upper bound 없다면, point를 표현하는 데 수많은 bit를 사용해야 하지만
6으로 upper bound를 둔다면, 최대 3bit만 있으면 되기 때문에 최적화 관점에서 큰 도움이 된다. - 여러 upper bound를 두고 실험해봤지만 6이 가장 성능이 좋았다고 함.
- ReLU6를 사용하는 이유 :
SELU
-
ELU:
Exponential Linear Unit.
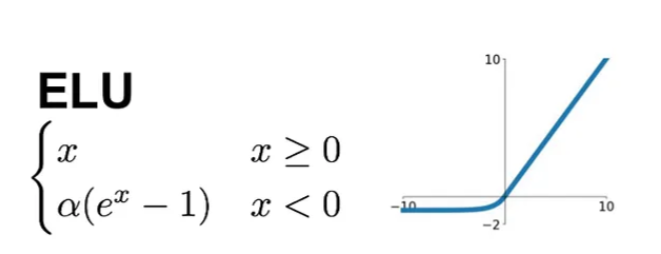
-
SELU (Scaled ELU):
https://wikidocs.net/196832
ELU에 scale 상수 를 곱해준 함수.
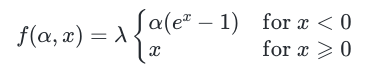
Swish
hard-Swish
(BoS for backbone, detector) Mish
-
Mish:
모든 점에서 미분 가능.
단조증가함수가 아님.
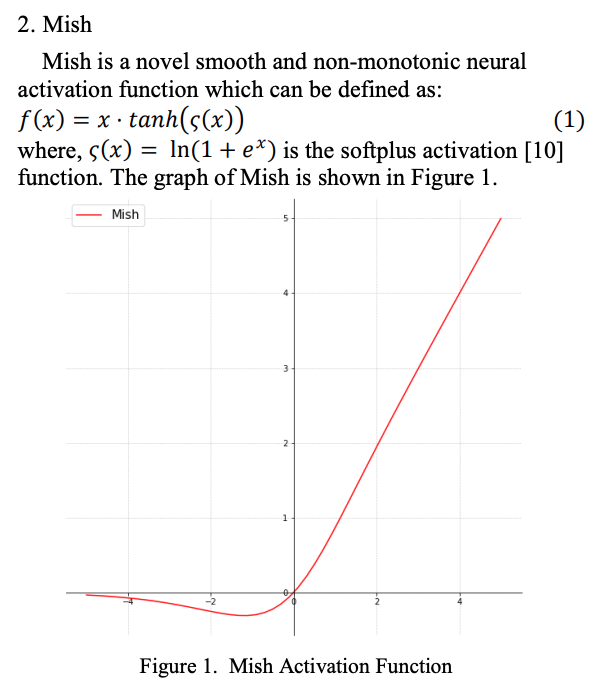
-
Figure 5.와 같이, 다른 activation function에 비해
Loss 분포가 낮으면서도 부드럽고 넓은 minima를 가짐.- unbounded above이므로 sigmoid, tanh와 같이 gradient가 0인 구간이 없음
- 모든 구간에서 미분가능한 smoooth function이므로 optimization 측면에서 유리하여 parameter initilization이나 lr에 덜 민감.

post processing method
NMS
greedy NMS
soft NMS
(BoF for detector) DIoU NMS
-
DIoU:
Distance-IoU.
은 Euclidean distance를 의미하고,
와 는 각각 predicted bbox, target bbox의 중심점 좌표를 의미.
c는 predicted bbox와 target bbox를 최소화하여 포함하는 대각선 길이.
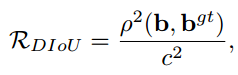

-
DIoU는 non overlapping된 경우에 두 box의 거리를 최소화하는 방향응ㄹ 제공하므로 GIoU Loss보다 빠르게 수렴한다는 장점이 있음.
DIoU Loss는 NMS의 threshold로 사용한다.
IoU를 threshold로 사용하는 NMS는 동일한 class를 갖는 bbox가 겹쳐있다면 해당 box를 suppression하는 문제점이 존재함.
예를 들어, 얼룩말들이 뭉쳐져 있다면, 하나의 얼룩말만 남겨두고 나머지 얼룩말은 supression됨.
DIoU를 threshold로 사용한다면 bbox의 중심점이 다른 경우도 고려하므로
gt bbox가 겹쳐져 있는 경우에 대해서 robust 하다는 장점이 있음.

3.1. Selection of architecture
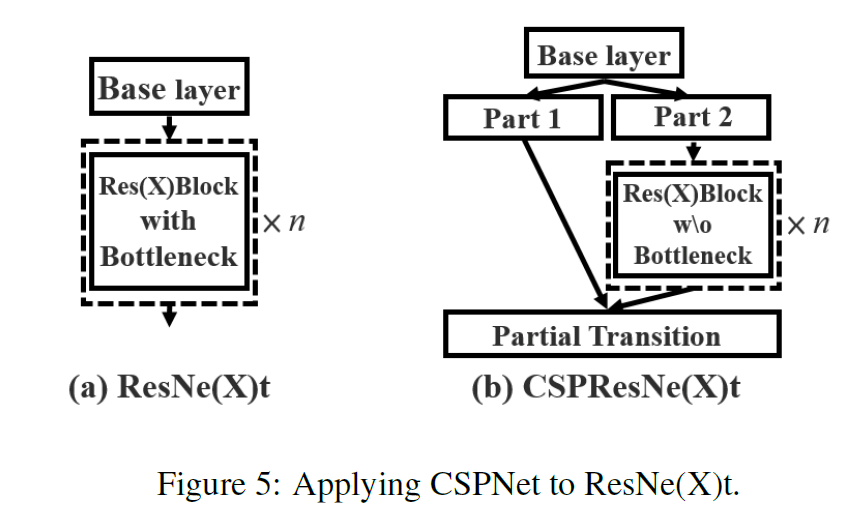
CSPNet
CSP(Cross Stage Partial):
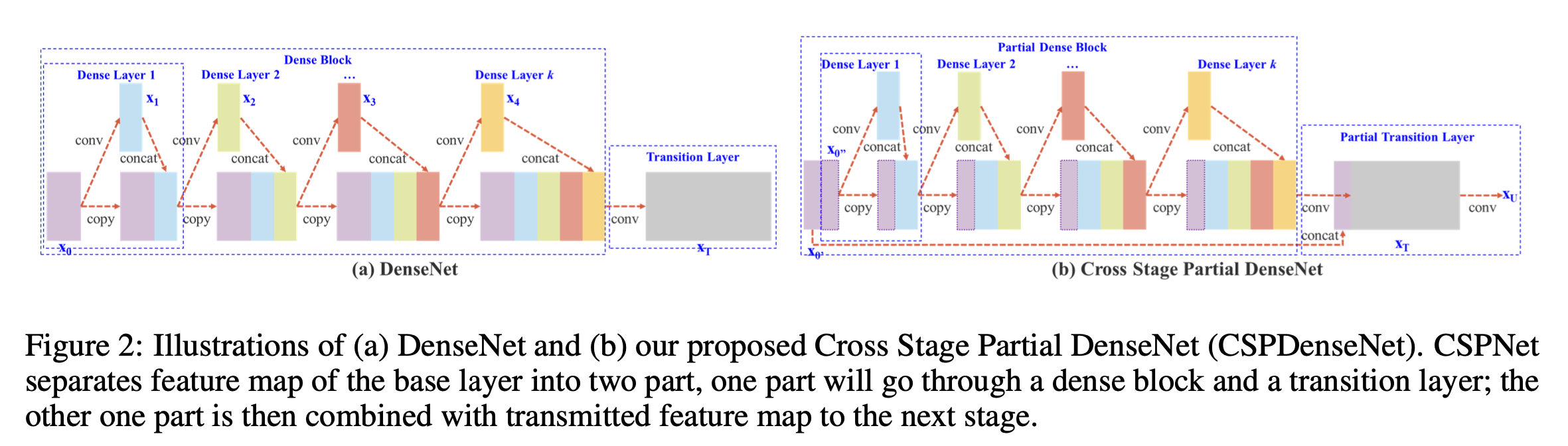
CSPResNext50
CSPResNe(X)t:
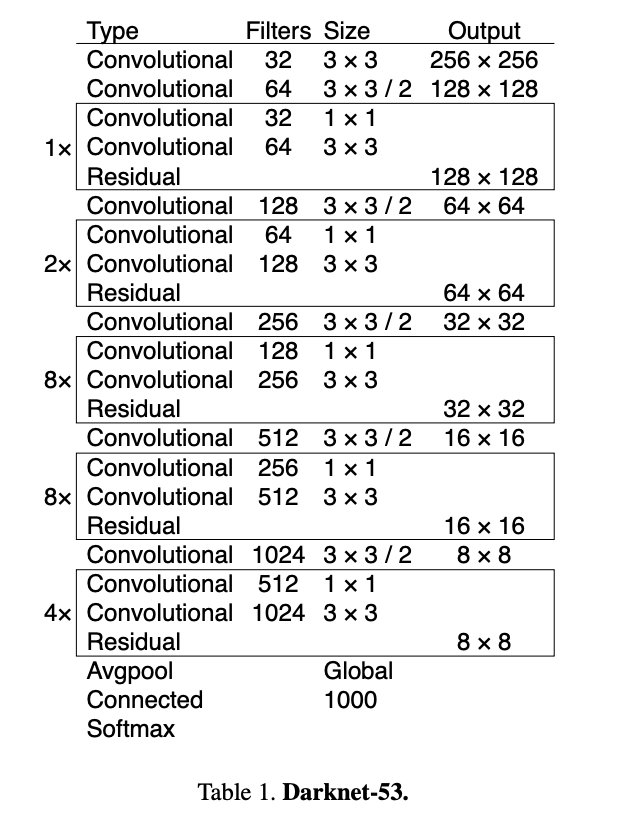
(architecture) CSPDarknet53
- YOLOv3에서 사용한 DarkNet에 CSP 적용.
(BoS for detector) SPP block
(위에서 다룬 내용)
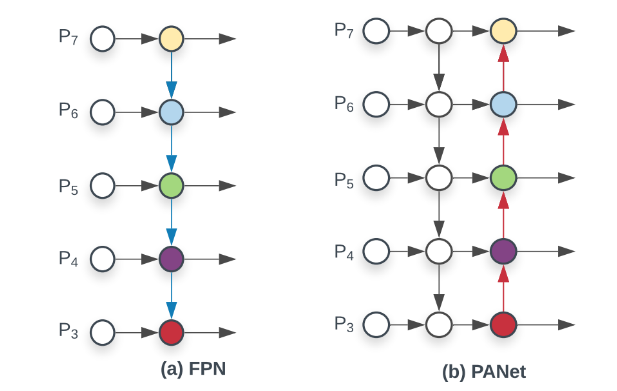
(BoF for detector) PAN path-aggregation block
(BoS for backbone) Cross-stage partial connections (CSP)
(위에서 다룸)
(BoS for backbone) Multi-input weighted residual connections (MiWRC)
(BoF for detector) CmBN
(BoF for detector) Self-Adversarial Training (SAT)
(BoF for detector) Eliminate grid sensitivity
(BoF for detector) Consine annealing scheduler
(BoF for detector) Optimal hyper-parameters
(BoF for detector) Random training shapes
