[2020 CVPR](YOLOv4) YOLOv4: Optimal Speed and Accuracy of Object Detection
[Paper Review] 2D Object Detection

Info
paper: YOLOv4: Optimal Speed and Accuracy of Object Detectionauthor: Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liaosubject: CVPR 2020
이해를 위한 자료들

Abstract
-
CNN accuracy를 향상시키는 데에 매우 많은 features(기능)들이 사용된다.
실제로 이러한 기능들을 combination하여 testing할 때,
결과에 대한 theoretical justification(이론적인 정당성)이 필요하다. -
몇가지 기능들은 특정 model에 대해서만 잘 동작할 수 있거나,
오로지 small-scale dataset에 대해서만 잘 동작할 수 있다.
하지만 BN과 residual-connection과 같은 몇가지 기능들은
대다수의 models, tasks, datasets에 보편적으로 잘 적용될 수 있다. -
우리는 이처럼, 보편적으로 잘 동작할 수 있는 new features들을 적용하여
Tesla V100에서 실시간 속도로 MS COCO dataset에서 43.5% AP (65.7% AP50)의 결과를 달성했다.- WRC (Weighted-Residual-Connections)
- CSP (Cross-Stage-Partial-connections)
- CmBN (Cross mini-Batch Normalization)
- SAT (Self-adversarial-training)
- Mish-activation
- Mosaic data augmentation
- DropBlock regularization
- CIoU loss
1. Introduction
-
최근 성능이 좋은 neural network들은 real-time으로 동작하지 않으며
large mini-batch-sizeㅔ서 여러 GPUs를 사용하여 학습해야 한다.
우리는 이러한 문제를 해결하기 위해
하나의 conventional(전통적인) GPU에서 real-time으로 동작하는 CNN을 만들었으며,
training을 하는 데에 오직 하나의 conventional GPU만 있으면 된다. -
The main goal of this work is designing a fast operating speed of an object detector in production systems
and optimization for parallel computations,
rather than the low computation volume theoretical indicator(BFLOP).
We hope that the designed object can be easily trained and uesed.- 예를 들어, 단 하나의 conventional GPU를 사용하여 train and test를 하는 사람은 figure 1. 처럼 real-time, high quality, and convincing object detection results을 달성할 수 있도록 하는 것.
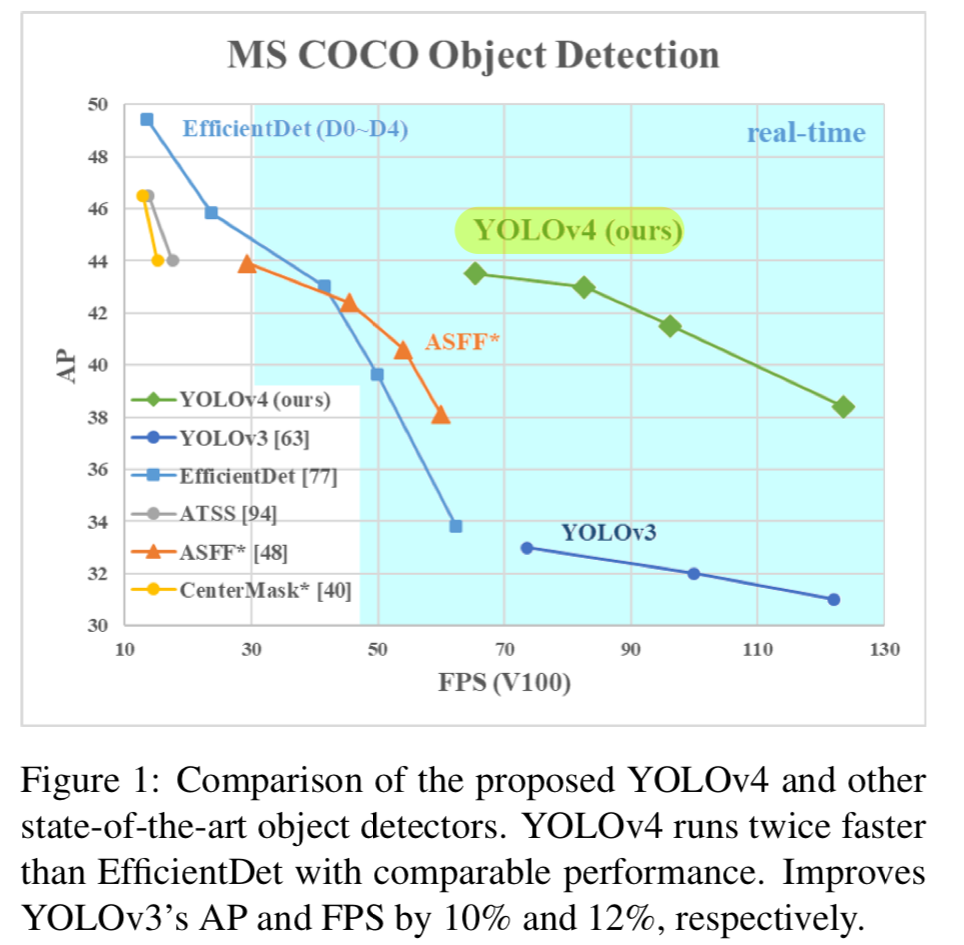
- 예를 들어, 단 하나의 conventional GPU를 사용하여 train and test를 하는 사람은 figure 1. 처럼 real-time, high quality, and convincing object detection results을 달성할 수 있도록 하는 것.
-
Our contributions are summarized as follows :
- an efficient and powerful object detection model
- verify the influence of state-of-the-art Bag-of-Freebies and Bag-of-Specials methods
- modify state-of-the-art methods and make them more efficient and suitable for single GPU training, include CBN, PAN, SAM, etc.
2. Related work
2.1 Object detection models
-
최근의 detector들은 두 가지 part로 구성되어 있다.
- ImageNet에 pre-train된
backbone- GPU platform에서 동작하는 detector들의 backbone은 VGG, ResNet, ResNeXt, DenseNet 등이 될 수 있다.
- CPU platform에서 동작하는 detector들의 backbone은 SqueezeNet, MobileNet, or ShuffleNet 등이 될 수 있다.
- classes and bounding boxes를 predict하는
head
head part는 다시 2가지로 categorized될 수 있다.- one-stage object detector :
대표적인 one-stage object detector로는 YOLO, SSD, RetinaNet 등이 있다. - two-stage object detector :
대표적인 two-stage object detector로는 R-CNN series(Faster R-CNN, R-FCN, Libra R-CNN)가 있다.
최근에는 anchor-free one-stage object detector들(CenterNet, CornerNet, FCOS, etc.)이 개발되어지고 있다.
- one-stage object detector :
- ImageNet에 pre-train된
-
최근에는 backbone과 head 사이에 몇가지 layer들이 추가되는 추세이다.
그 layer들은 보통 different stages로부터 feature maps을 collect하는 데에 사용되고,
이 layer들을neck이라고 부른다.
neck은 several bottom-up paths와 several top-down paths로 구성되어 있다.- 이러한 mechanism을 갖춘 networks들은
Feature Pyramid Network(FPN), Path Aggregation Network(PAN), BiFPN, and NAS-FPN 등이 있다.
- 이러한 mechanism을 갖춘 networks들은
-
위 model들에 추가적으로,
새로운 backbone or new whole model을 만드는 것을 연구하는 사람들도 있다. -
종합적으로, 일반적인 object detector들은 이와 같은 several parts로 구성되어 있다.
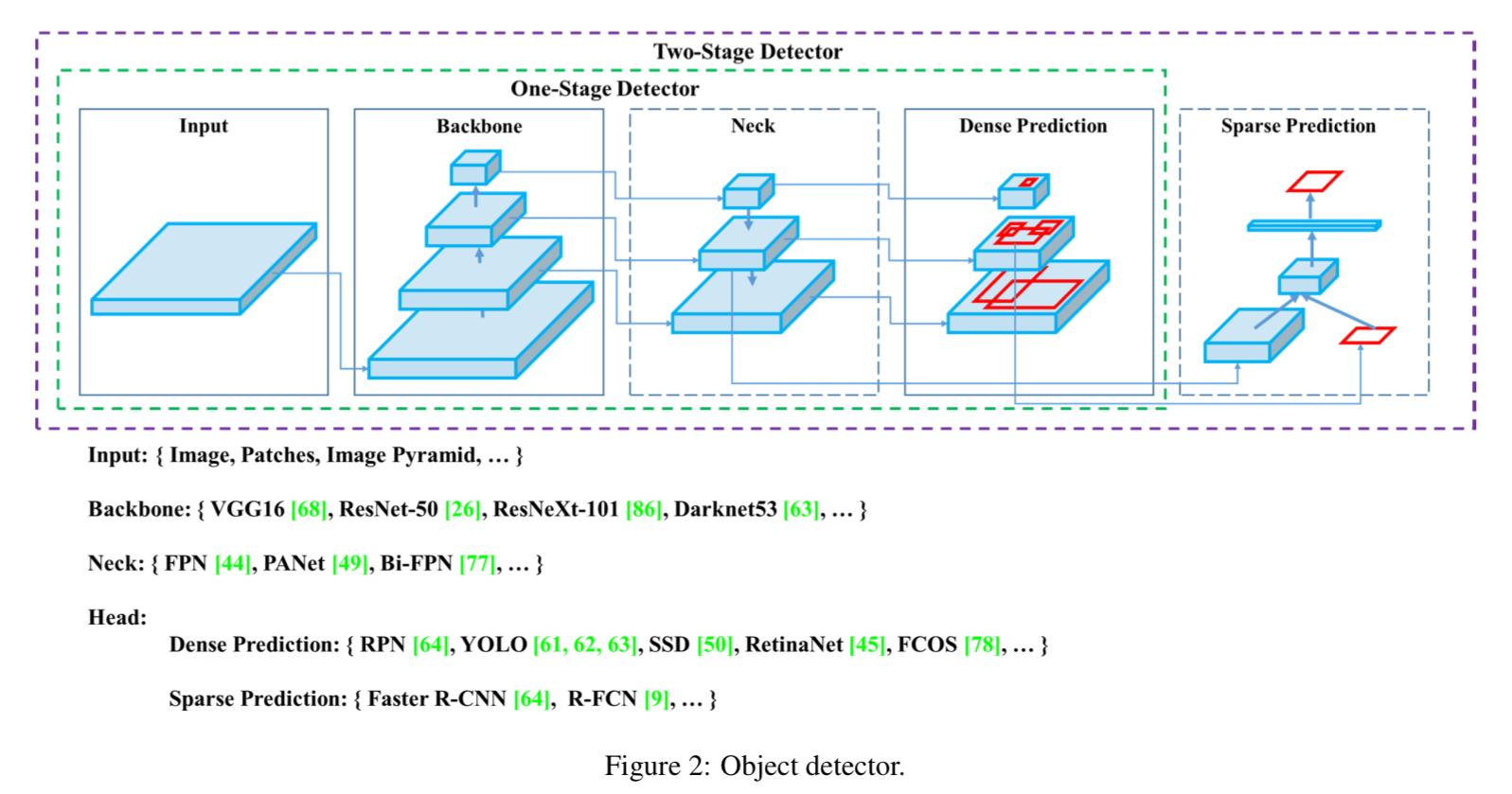

2.2 Bag of freebies
- inference cost를 증가시키지 않고도 accuracy를 높이는 방법이 몇가지 있는데,
우리는 이것을bag of freebies(BoF)라고 부른다.
object detection에 사용되는BoF methods은 다음과 같다.data augmentation- photometric distortions (Brightness, contrast, hue, saturation, noise)
- geometric distortions (Random scaling, cropping, flipping, rotating)
- random erase and CutOut
- hid-and-sekk and grid mask
- MixUp
- CutMix
DropOut, DropConnect, DropBlock- the problem of semantic distribution bias(imbalance between different classes)
focal lossto deall with the problem of data imbalance existing between various classes- In order to obtain a better soft label, the concept of
knowledge distillation(정수) to design the label refinement network.
- objective function of BBox regression
- MSE Loss
: bbox의 각 점의 좌표를 직접적으로 estimate하는 것.
이는 independent variable이지만 실제로 object의 integrity를 고려하지 않음.
따라서 IoU loss IoU Loss
: IoU는 scale invariant representation이기 때문에,
traditional method이 {x, y, w, h}의 l1 또는 l2 loss을 계산할 때
scale 이 증가함에 따라 loss도 증가하는 문제를 해결.
이후로 IoU Loss를 향상시킨 loss들이 개발됨.GIoU LossDIoUCIoU
- MSE Loss
2.3 Bag of specials
- inference cost를 조금 더 사용 및 post-processing을 통해
accuracy를 많이 향상시키는 방법을bag of specials(BoS)라고 부른다.
BoS의 종류는 다음과 같다.- enhance receptive field
- SPP, ASPP, RFB
- attention module
- Squeeze-and-Excitation(SE), Spatial Attention Module(SAM)
- feature integration
- Skip connection, hyper-column, SFAM, ASFF, BiFPN
- activation function
- ReLU, LReLU, PReLU, ReLU6, SELU, Swish, hard-Swish
- post-processing method
- NMS, greedy NMS, soft NMS, DIoU NMS
- enhance receptive field
3. Methodology
- 기본적인 목표는 neural network의 operating speed를 빠르게 만드는 것이었다.
우리는 real-time neural networks의 두 가지 options을 설명하겠다.- For GPU - we use a small number of groups in conv layers : CSPResNeXt50, CSPDarknet53
- For VPU - we use grouped-convolution, but we refrain from using Squeeze-and-excitement blocks
3.1. Selection of architecture
- 우리의 목표는 input network resolution, #conv layer, #parameter, #layer output
사이의 optimal balance를 찾는 것이다.- 예를 들어,
많은 논문에서 ImageNet object classification에 대해서,
CSPResNext50이 CSPDarknet53과 비교했을 때 더 좋은 성능을 보인다.
하지만 MS COCO dataset에 object detection에 대해서,
CSPDarknet53이 더 좋은 성능을 보인다.
- 예를 들어,
- 두 번째 목표는
receptive field를 증가시키기 위한 additiodnal block을 선택하고
서로 다른 backbone 수준에서의 parameter aggregation을 위한 best method를 선택하는 것이다.
(e.g. FPN, PAN, ASFF, BiFPN)
classification을 위한 optimal reference model은 detector로써 optimal은 아니다.
detector는 다음의 것들이 필요하다.- Higher input network size(resolution) - for detection multiple small-sized objects
- More layers - for a higher receptive field to cover the increased size of input network
- More parameters - for greater capacity of a model to detect multiple objects of different sizes in a single image
- 우리는 a model with larger receptive field size와 a larger number of parameters을
backbone으로써 select되어져야 한다고 가정할 수 있다.
 이론적 근거와 우리의 다양한 experiments를 통해
이론적 근거와 우리의 다양한 experiments를 통해
CSPDarknet53 neural network가 detector에 대한 backbone으로
optimal model임을 보여준다.
- 다양한 sizes에 대한 receptive field의 영향력은 다음과 같이 요약할 수 있다.
- object size에 따라 - entire object를 볼 수 있음
- network size에 따라 - object에 대한 context를 볼 수 있음
- network size를 초가화는 경우 - image point와 final activation 간의 connection 개수가 증가
- 우리는 CSPDarknet53에
SPP block을 추가하였다.
왜냐하면 SPP block은 receptive field를 크게 증가시키고,
가장 중요한 context feature를 분리하며
network operation speed의 감소가 거의 없기 때문이다.
우리는 YOLOv3에서 사용된 FPN 대신,
서로 다른 backbone level에서의 다양한 detector에 대한 parameter aggregation method로PANet을 사용한다.- 최종적으로,
우리는 YOLOv4의 architecture로 CSPDarknet53 backbone, SPP adiitional module, PANet path-aggregation neck, 그리고 anchor based YOLOv3 head를 선택했다. - 추후에 우리는 detector를 위한 BoF의 content를 많이 늘릴 계획이다.
이로 인해 some problem을 처리할 수 있고 detector accuracy를 증가시킬 수 있을 것이다. - 우리는 Cross-GPU Batch Normalization 또는 expensive specialized device를 사용하지 않았다.
이는 누구나 일반적은 graphic processor인 GTX 1080Ti 또는 RTX 2080Ti에서
우리의 state-of-the-art 결과를 재현할 수 있도록 할 수 있다.
- 최종적으로,
3.2. Selection of BoF and BoS
- object detection training을 향상시키기 위해서,
CNN은 보통 다음의 것들을 사용한다.- Activations : ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- trainin activation function에 대해서,
ReLU and SELU는 train이 더 어렵기 때문에 candidate list에서 제외시켰고,
ReLU6는 quantization network를 위해 특별히 design되어졌다.
- trainin activation function에 대해서,
- Bounding box regression loss : MSE, IoU, GIoU, CIoU, DIoU
- Data Augmentation : CutOut, MixUp, CutMix
- Regularization method : DropOut, DropPath, Spatial DropOut, or DropBlock
- Regularization에 대해서는
DropBlock을 발표한 연구자들이 다른 방법들과 자세히 비교하여,
그들의 regularization method가 많은 우위를 보였다.
따라서 망설임 없이 DropBlock을 regularization method로 선택하였다.
- Regularization에 대해서는
- Normalization of the network activations by their mean and variance : BN, Cross-GPU BN, Filter Response Normalization, or Cross-Iteration BN
- Normalization에 대해서는,
오직 하나의 GPU를 사용하는 training strategy에 중점을 두기 위해서
syncBN을 고려하지 않았다.
- Normalization에 대해서는,
- Skip-connections : Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections
- Activations : ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
3.3. Additional improvements
-
single GPU training에 적합한 designed detector를 찾기 위해서,
우리는 다음의 additional design과 improvements를 만들었다 :- a new method of data augmentation Mosaic, and Self-Adversarial Training(SAT)
- we select optimal hyper-parameters while applying genetic algorithms
- We modify some exsiting methods to make our design suitable
for efficient training and detection - modified SAM, modified PAN, and Cross mini-Batch Normalization(CmBN)
-
Mosaic는 4개의 training image를 혼합시킨 new data augmentation method이다.
그러므로 CutMix는 단지 2개의 input image를 mix시키는 반면에,
Mosaic는 4개의 서로 다른 contexts는 mix되어진다.
이는 normal context 이외에 objects를 detection할 수 있게 한다.
추가로, BN은 각 layer에서 4개의 서로 다른 image들로부터 activation statistics를 계산한다.
이는 large mini-batch size의 필요성을 크게 줄일 수 있다. -
Self-Adversarial Training(SAT)도 또한 2개의 forward backward stages로 동작되는 new data augmentation technique이다.
1st stage에서 neural network는 network의 weight 대신 image를 수정한다.
이 방법으로 neural network는 자체적으로 adversarial attack(적대적 공격)을 수행하여
원하는 object가 image에 없는 것처럼 속이게 된다.
2nd stage에서는, neural network가 normal 방식으로 object를 detect하도록 train되어진다. -
CmBN(Cross mini-Batch Normalization)은 Figure 4에 보여지듯이, CBN의 modified version이다.
CmBN은 a single batch 내 mini-batch 간에만 statistics를 collect한다.
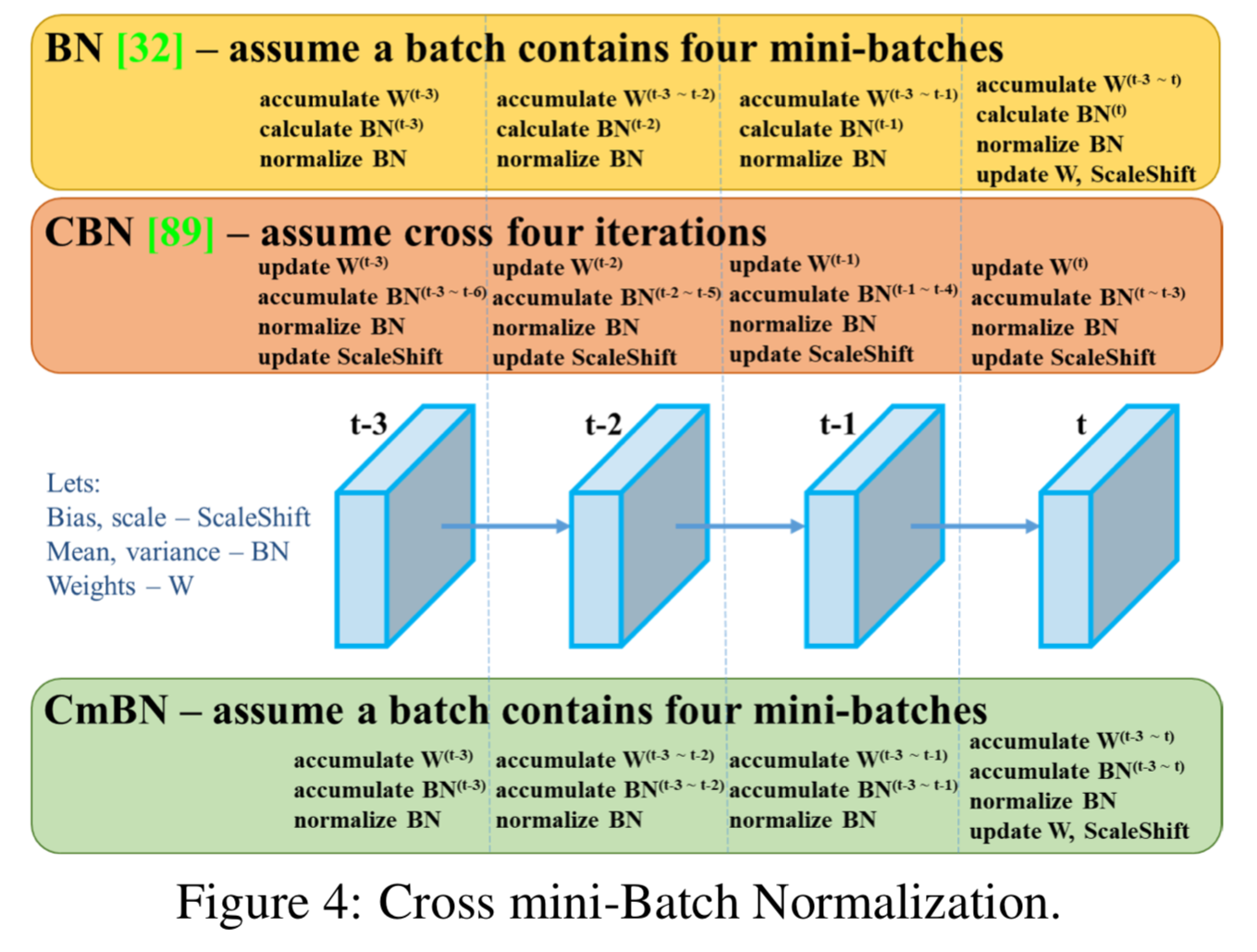
-
우리는 SAM을 spatial-wise attention에서 point-wise attention으로 수정하고,
PAN의 shortcut connection을 concatenation으로 대체하였다.
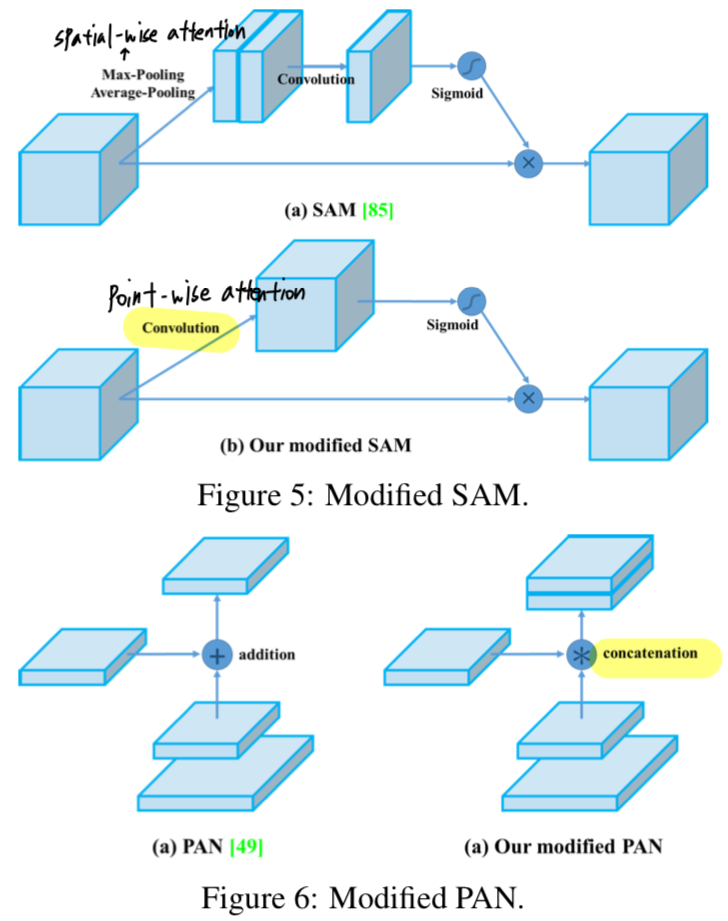
3.4. YOLOv4
- 이 section에서, 우리는 YOLOv4에 대한 detail에 대해 자세하게 이야기할 것이다.
YOLOv4 consists of :
- Backbone : CSPDarknet53
- Neck : SPP, PAN
- Head : YOLOv3
YOLOv4 uses :

4. Experiments
- 우리는 서로 다른 training improvement techiniques들의 influence를
평가하기 위해ImageNet에 classifier accuracy를 test하였고,
그리고 나서MS COCO dataset에 detector accuracy를 test하였다.
4.1. Experimental setup

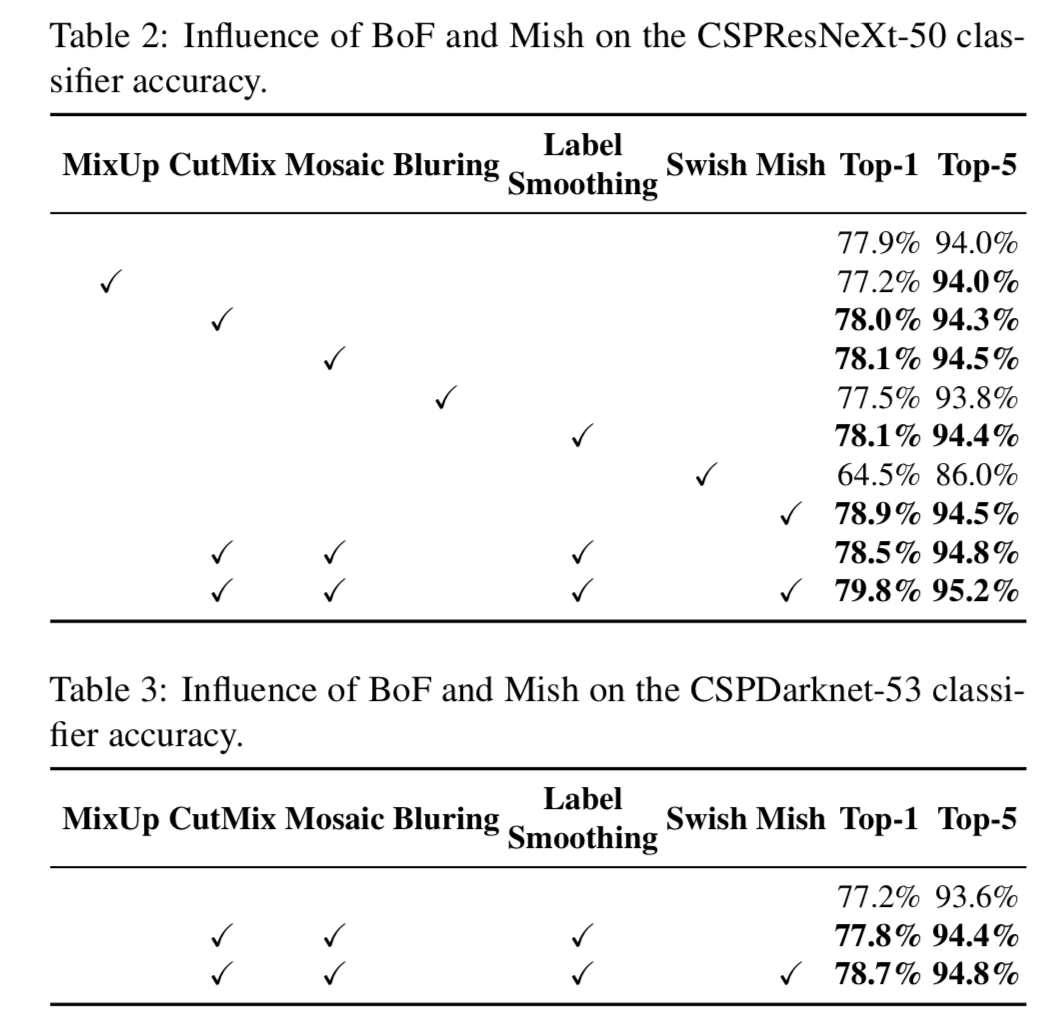
4.2. Influence of different features on Classifier training

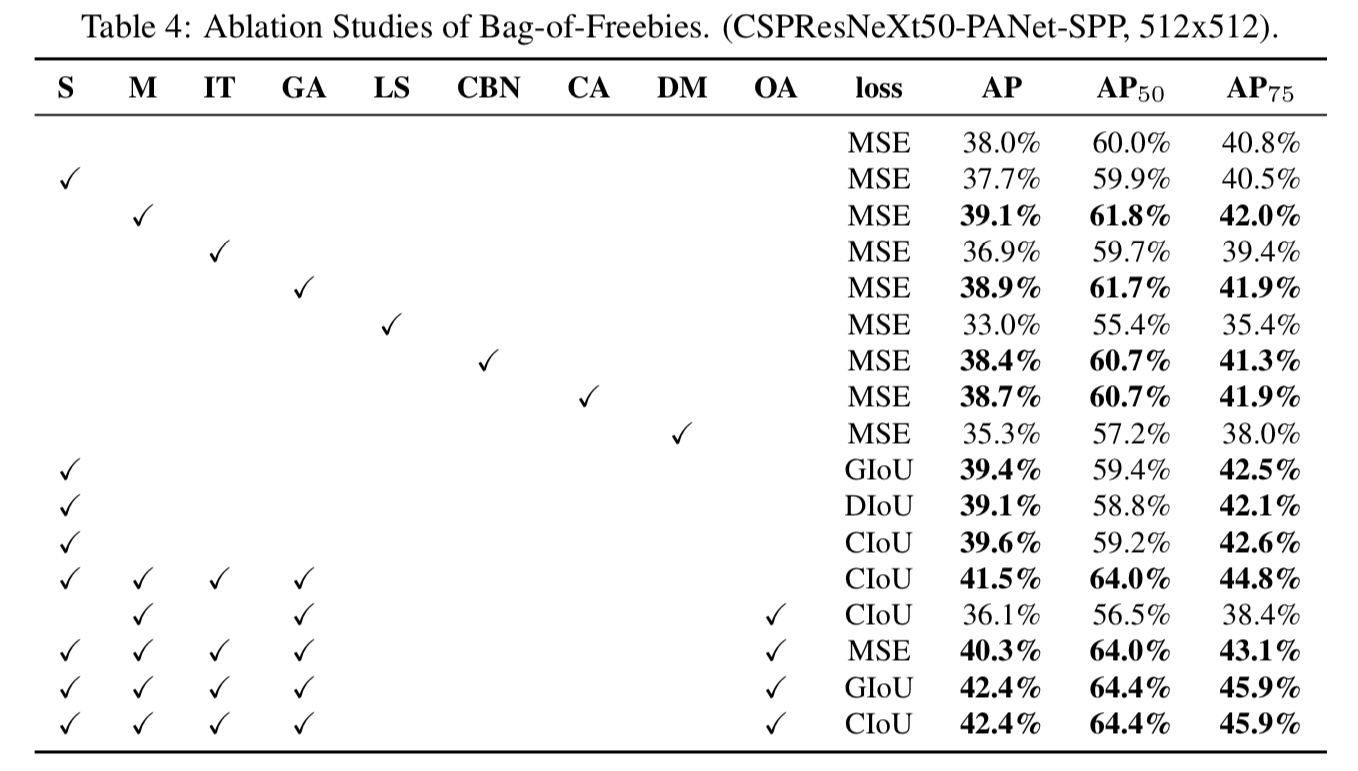
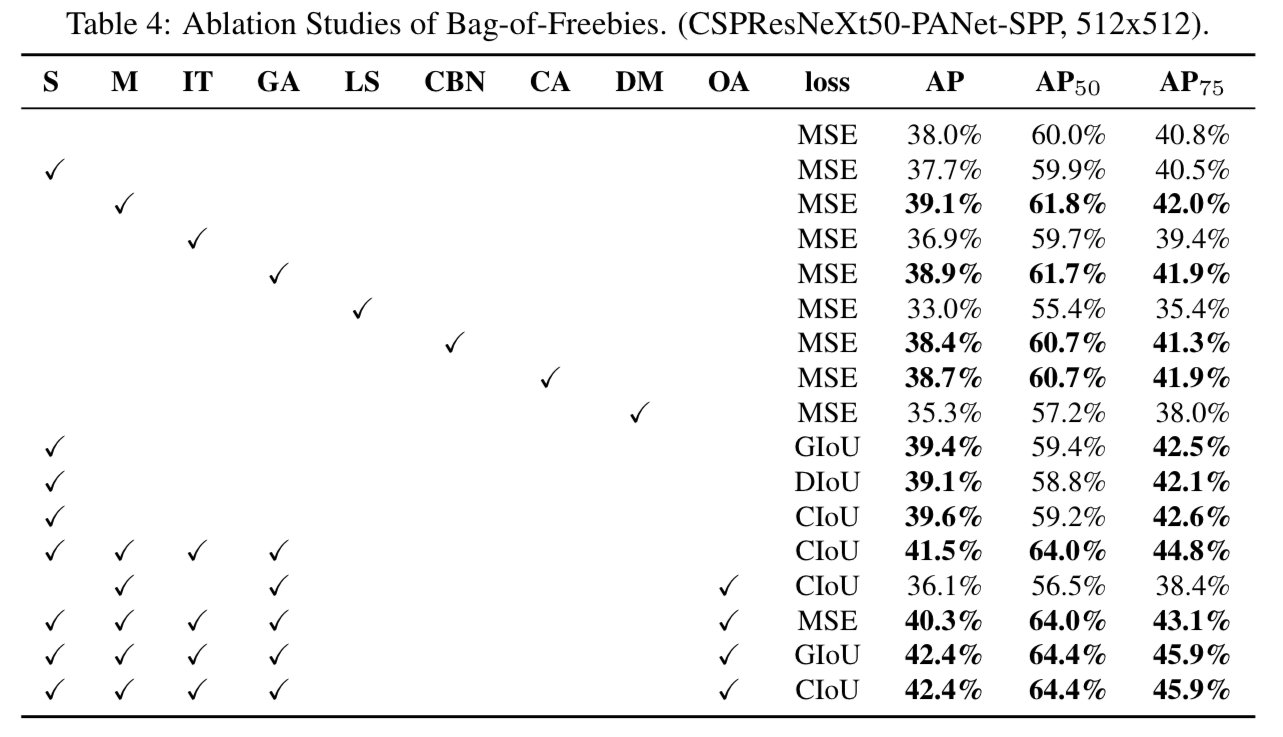
4.3. Influence of different features on Detector training
-
우리는 FPS에 영향을 미치지 않고 detector의 accuracy를 높이는 다양한 feature들을 연구하여 BoF list를 확장시켰다.
-
추가적인 연구는 PAN, RFB, SAM, Gaussian YOLO(G) 및 ASFF와 같은 다양한 BoF가
detector의 training accuracy에 미치는 영향에 관한 것이다.

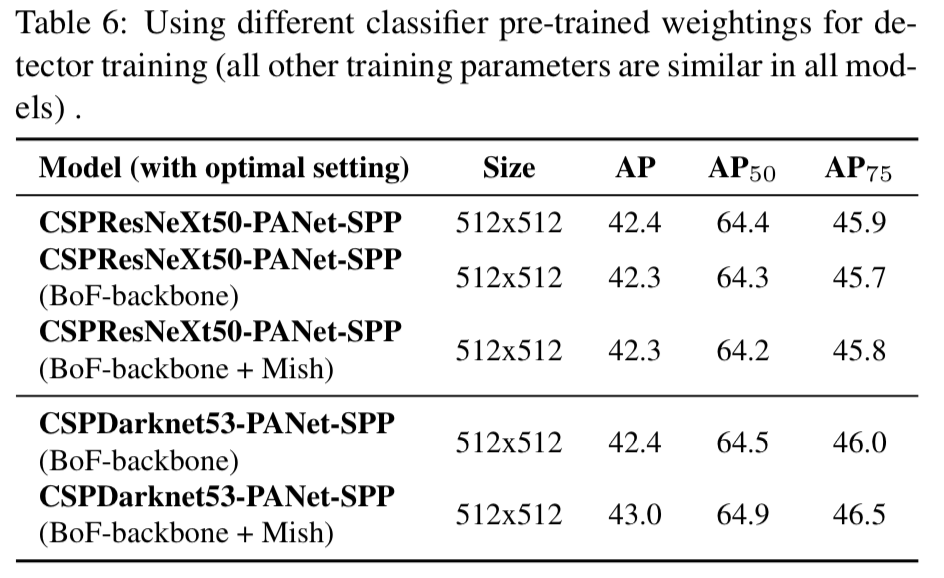
4.4. Influence of different backbones and pre-trained weightings on Detector training
- 그 다음으로,
Figure 6.에 나타안 것과 같이 다양한 backbone model이 detector accuracy에 미치는 영향을 연구했다.
우리는 best classification accuracy를 갖는 model이 꼭 best detector accuracy를 갖는 것이 아니라는 것을 알아냈다.
-
첫번째로
CSPResNeXt50 model이 CSPDarknet53 model보다 더 높은 classification accuracy를 보였지만,
CSPDarknet53 model은 object detection에서 더 높은 accuracy를 보였다. -
두번째로,
BoF와 Mish를 사용하여 CSPResNeXt50 classifier를 training시키면 classification accuracy가 높아지지만,
이러한 pre-trained weighting을 detector training에 더 적용하면 detector의 accuracy가 낮아진다.
하지만 BoF와 Mish를 사용하여 CSPDarknet53 classifier를 training시키면,
pre-trained weightings를 사용한 detector의 accuracy와 classifier의 accuracy가 동시에 증가한다.
결과적으로 detector로써 CSPDarknet53 backbone이 CSPResNeXt50보다 더 적합하다.
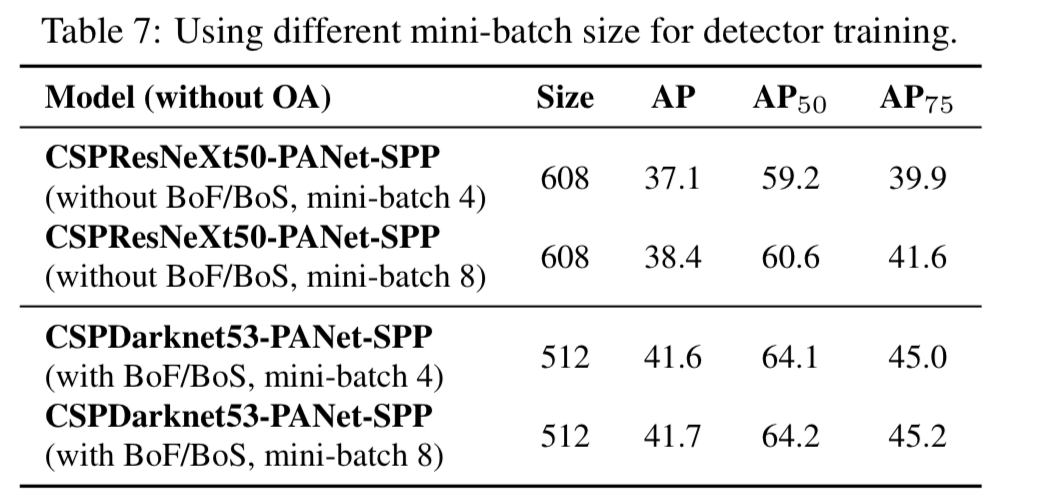
4.5. Influence of different mini-batch size on Detector training
- 마지막으로,
서로 다른 mini-batch size로 train된 model의 결과를 분석했다.
Figure 7. result에서 볼 수 있듯이,
우리는 BoF와 BoS training strategy를 적용한 후에는,
mini-batch size가 detector의 성능에 거의 영향을 미치지 않는 것을 알아냈다.
이 결과는 BoF와 BoS를 도입한 후에는 고가의 GPU를 사용하여 training시킬 필요가 없어졌다는 것을 의미한다.
즉, 누구나 일반적인 GPU 하나만을 사용하여 excellent detector를 train시킬 수 있다.
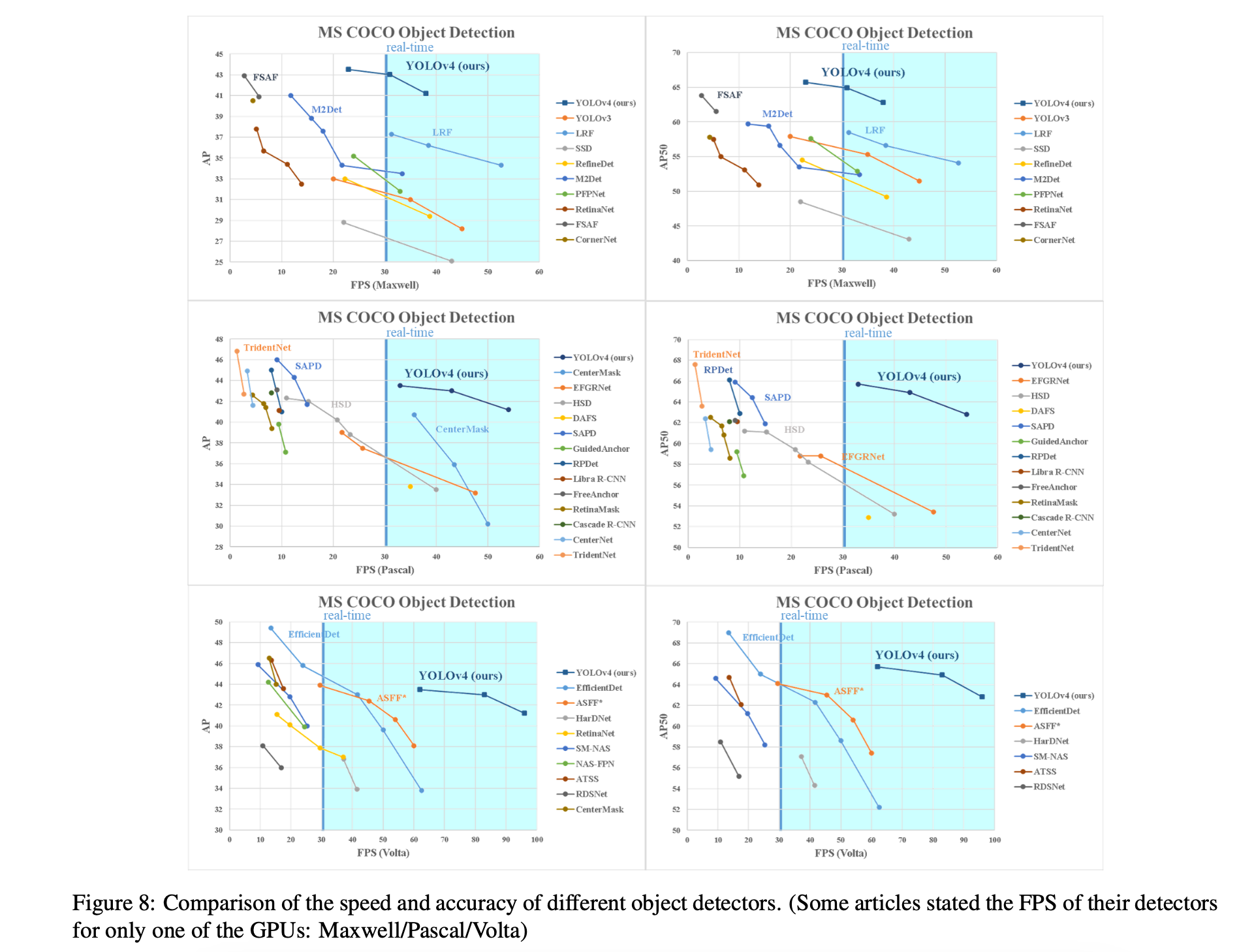
5. Results
-
다른 state-of-the-art object detector로 얻은 결과를 비교한 것은 Figure 8.에 있다.
우리의 YOLOv4는 Pareto optimality curve에 있으며
speed and accuracy에서 가장 빠르고 정확한 detector이다.
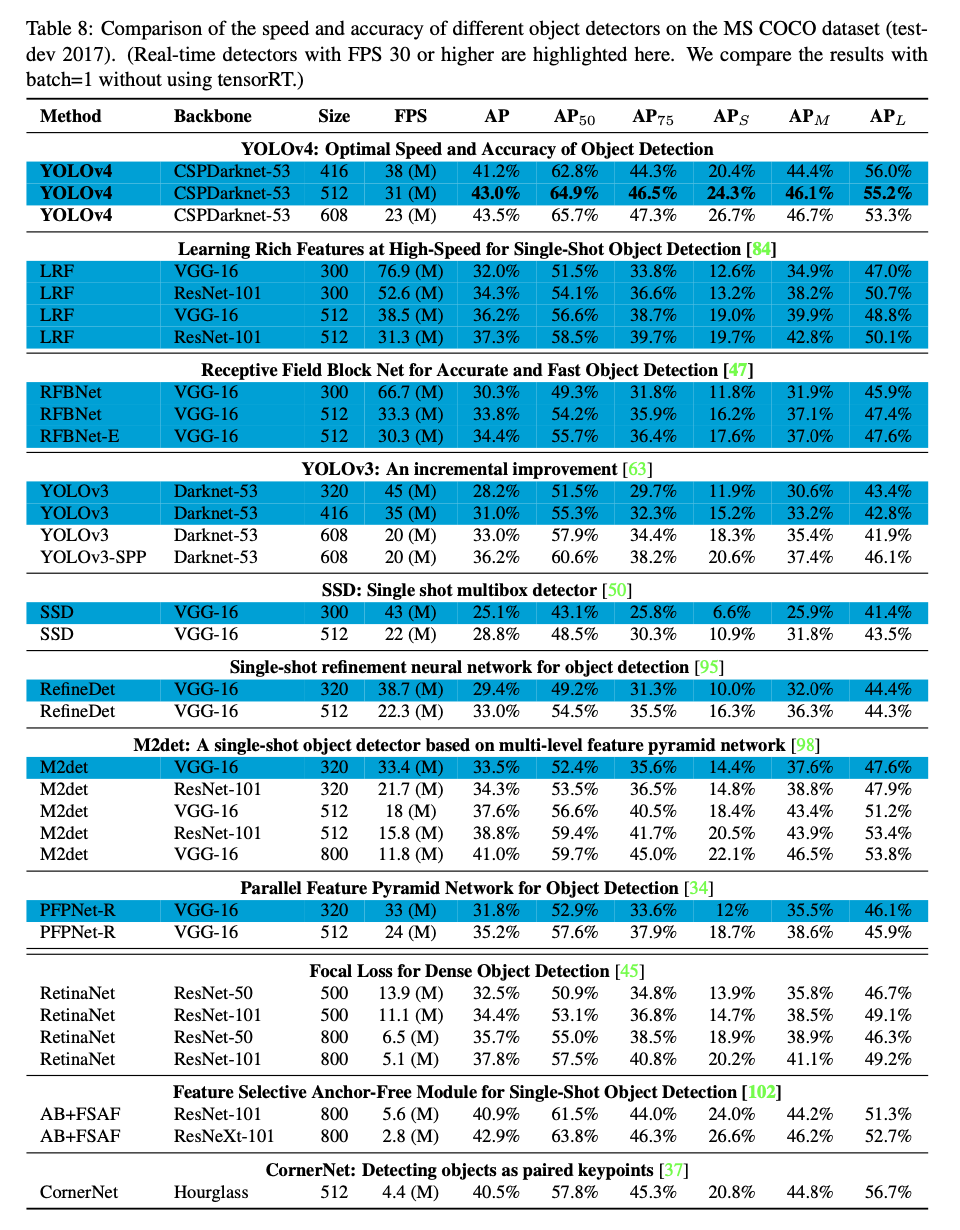
-
다양한 방법들이 inference time 검증을 위해
다른 architecture의 GPU를 사용하기 때문에,
우리는 YOLOv4를 Maxwell, Pascal, Volta architecture의 일반적으로 사용되는 GPU에서 작동시키고 다른 state-of-the-art methods들과 비교했다.- Table 8은
Maxwell GPU(GTX Titan X or Tesla M40 GPU도 될 수 있음)을 사용한
frame rate 비교 결과를 나열한 것이다.
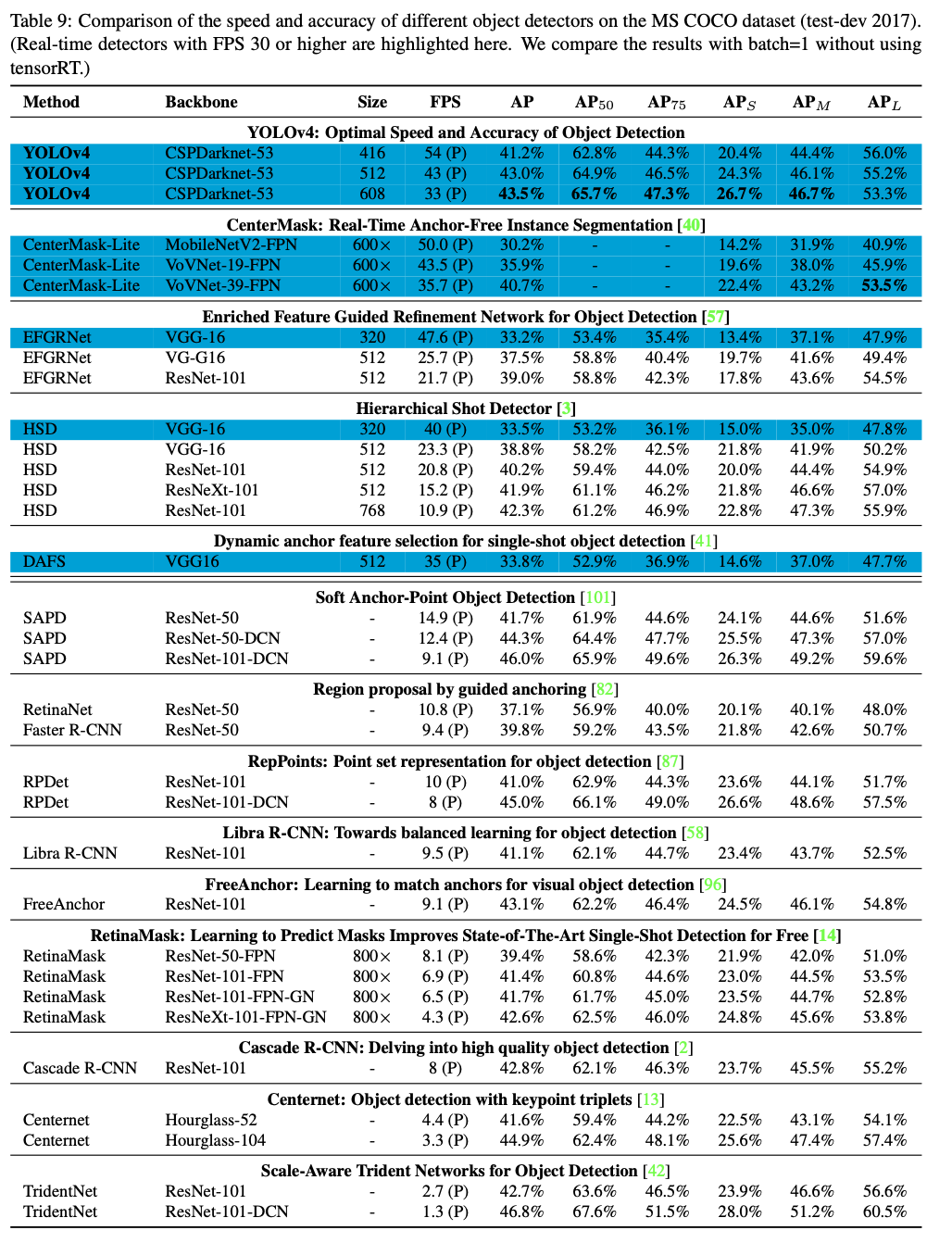
- Table 9는
Pascal GPU(Titan X, Titan Xp, GTX 1080 Ti or Tesla P100 GPU도 될 수 있음)을 사용한
frame rate 비교 결과를 나열한 것이다.
- Table 10은
Volta GPU(Titan Volta or Tesla V100 GPU도 될 수 있음)를 사용한
frame rate 비교 결과를 나열한 것이다.
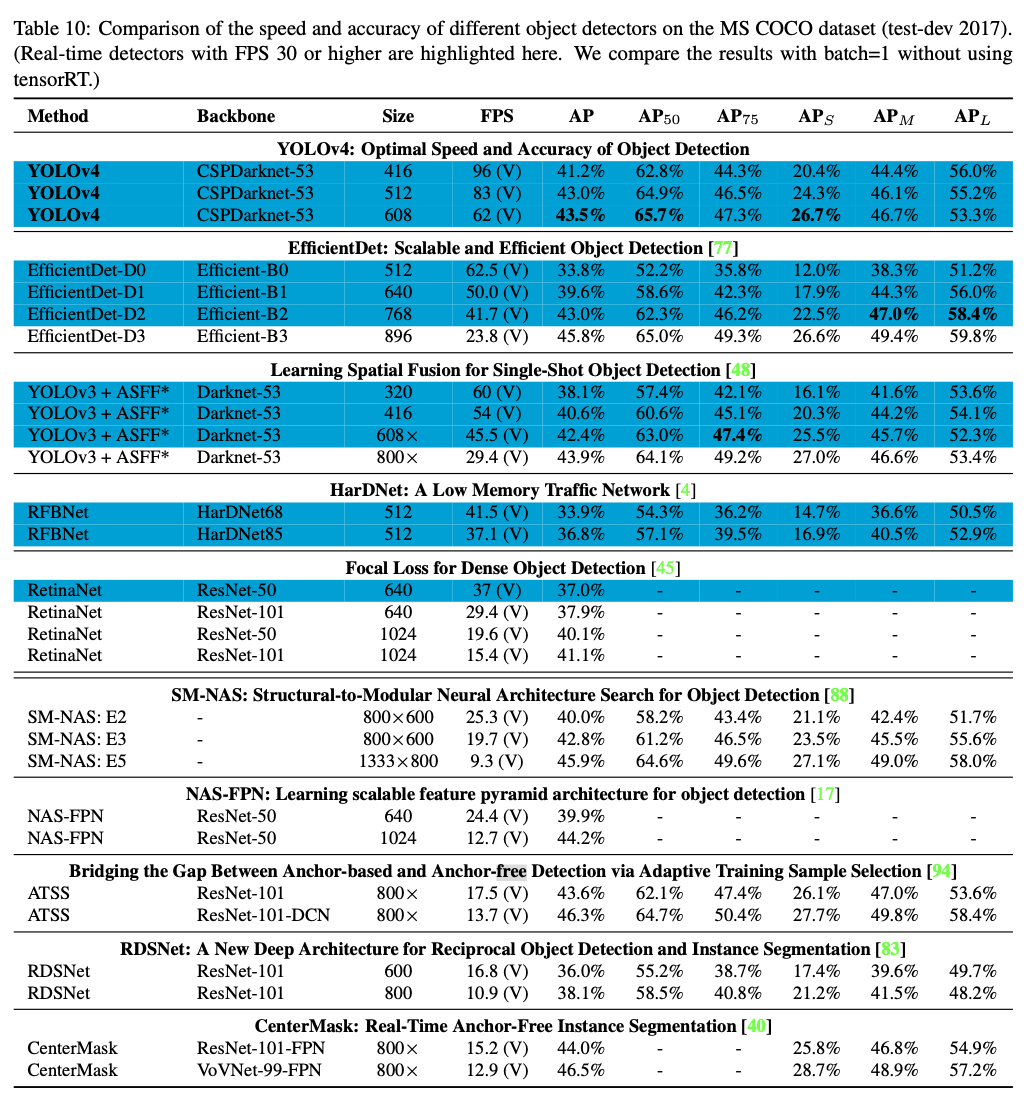
- Table 8은
6. Conclusions
Summary
https://www.youtube.com/watch?v=6f7jglewoWg&t=684s


나의 의견
-
YOLOv4부터 architecture에
neck이 추가되어 현대식 CNN을 사용한 detector model에 가까워졌다고 생각한다.
하지만 YOLOv4는 최신에 고안된 논문들(여러 technique들 = BoF, BoS들)을 짬뽕하여
ablation study로 어떤 조합이 최적의 조합인지 매우 많은 실험만을 진행한 것을 알 수 있다.
그래서 이 논문은 논문으로써 가치는 크게 없는 것 같다고 생각한다.
왜냐하면 이미 있던 기술들을 조합만 다르게 하여 성능과 속도를 평가한 것이고,
획기적인 아이디어나 이 domain에 큰 contribution은 없다고 생각하기 때문이다. -
추가로, YOLO series는 YOLOv4부터 시작하여 중구난방의 겉잡을 수 없는 variants들이 많이 생성되고 있어 기술을 쫓아가기가 힘들다고 생각한다.
그리고 YOLO variants들은 길을 잃어가고 있다는 생각도 든다...
이름은 YOLO이지만 이름만 YOLO인 느낌이랄까
