[2023 CVPR] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[Paper Review] 2D Object Detection
Paper Info.
- Wang, Chien-Yao, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023.
Abstract
-
architecture optimization and training optimization와 관련된 새로운 approaches이 지속적으로 발전됨에 따라,
SOTA methods를 다룰 때 두 가지 연구 주제가 발생했다. -
이 주제를 해결하기 위해, 우리는 trainable bag-of-freebies oriented solution을 제안한다.
우리는 flexible and efficient training tools with the proposed architecture and the compound scaling method를 결합했다.
- YOLOv7은 5 FPS에서 120 FPS 범위에서 속도와 정확성 모두에서 모든 알려진 객체 탐지기를 초월하며,
GPU V100에서 30 FPS 이상의 실시간 객체 탐지기 중에서 가장 높은 정확도인 56.8% AP를 기록하고 있습니다.
(소스 코드는 https://github.com/WongKinYiu/yolov7)
1. Introduction
-
일부 edge device는 vanilla convolution, depth-wise convolution, or MLP operations과 같은 다양한 연산을 가속화하는 데 초점을 맞추고 있다.
본 논문에서 제안한 real-time object detector는 mobile GPU와 edge부터 cloud까지의 GPU device 모두를 지원할 수 있기를 기대한다. -
최근 몇 년 동안, real-time object detector는 여전히 다양한 edge device를 위해 개발되고 있다.
예를 들어, MCUNet과 NanoDet은 low-power single-chip을 생산하고 edge CPU에서의 inference speed를 향상시키는 데 중점을 두었다.
YOLOX와 YOLOR과 같은 방법은 다양한 GPU에서의 inference speed를 향상시키는 데에 중점을 두고 있다. -
최근에는 real-time object detector 개발이 효율적인 architecture design에 집중되고 있다.
CPU에서 사용될 수 있는 real-time object detector는 대부분 MobileNet, ShuffleNet, 또는 GhostNet을 기반으로 design되었다.
반면, GPU에서 사용되는 real-time object detector는 대부분 ResNet, DarNet, 또는 DLA를 사용하고,그 후 CSPNet 전략을 통해 architecture를 최적화한다. -
이 논문에서 제안하는 방법은 현재의 real-time object detector와는 방향이 다르다.
architecture optimization 외에도, 제안된 방법은 training process에 중점을 둔다.
우리의 focus는 object detection의 accuracy 향상을 위한 training cost를 강화할 수 있는 optimized module and optimization methods에 있으며,
inference cost를 증가시키지 않는 것을 목표로 한다.
이러한 module과 optimization methods를trainable bag-of-freebies라고 부른다.
- 최근 model re-parameterization과 dynamic label assignment는 network training과 object detection에서 중요한 topic이 되고 있다.
주로 이와 같은 새로운 개념들이 소개된 후에는, object detector의 training에는 많은 새로운 issue들이 생겨난다.
이 논문에서는 우리가 발견한 새로운 문제를 제시하고 이를 해결하기 위한 효과적인 방법을 제안한다.- model re-parameterization에 대해서는,
다양한 network layer에 적용 가능한 model re-parameterization strategies를 gradient propagation path의 개념을 통해 분석하고,
계획된 re-parameterization model을 제안한다. - 또한, dynamic label assignment technology를 활용할 때,
multiple output layers를 가진 model의 training에서 새로운 문제가 발생하는 것을 발견했다.
그 문제는 "How to assign dynamic targets for the outputs of different branches?"이다.
이 문제를 해결하기 위해, 우리는 'coarse-to-find'라고 불리는 새로운 label assignment method를 제안한다.
- model re-parameterization에 대해서는,
- 이 논문의 contribution은 다음과 같다 :
- 여러 trainable bag-of-freebies methods를 설계하여, real-time object detection에서 detection accuracy를 크게 향상시키면서도 inference cost를 증가시키지 않도록 한다.
- object detection methods 발전에 따라 two new issues를 발견했고,
해결하기 위한 방법을 제안한다.- re-parameterization module이 원래의 module을 어떻게 대체할 것인가?
- dynamic label assignment strategy가 다양한 output layer에 대한 assignment를 어떻게 처리할 것인가?
- parameters and computation을 효과적으로 활용할 수 있는 "extend" and "compound scaling" methods를 제안한다
- 우리가 제안한 방법은 real-time object detector의 많은 params와 computation을 효과적으로 줄이고,
faster inference speed and higher detection accuracy를 달성할 수 있다.
2. Related work
(skip)
3. Architecture
3.1. Extended efficient layer aggregation networks
-
efficient architecture designing에 대한 대부분의 literature에서 main consideration은
#parameters, computation량, 그리고 computational density에 그치고 있다.
[52]에서는 memory access cost의 특성에서 출발하여,
input/output channel ratio, #branches of the architecture, and the element-wise operation이 network inference speed에 미치는 영향을 분석했다.
[14]는 model scaling을 수행할 때 activation도 추가적으로 고려했으며,
이는 conv layer의 output tensor의 elements수에 더 많은 주의를 기울이는 것을 의미한다. -
Figure 2 (b)의 CSPVoVNet design은 VoVNet의 variation으로,
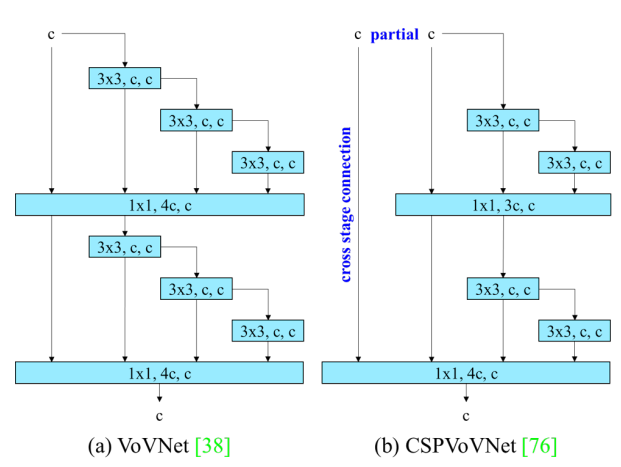 위에서 언급한 기본적인 설계 문제를 고려하는 것 외에도,
위에서 언급한 기본적인 설계 문제를 고려하는 것 외에도,
CSPVoVNet의 architecture는 gradient path를 분석하여 서로 다른 layer의 weight가 보다 다양한 feature를 학습할 수 있도록 한다.
이러한 gradient analysis approach는 inference를 더 빠르고 정확하게 만든다. -
Figure 2 (c)의 ELAN은 다음의 design strategy를 고려한다 - "How to design an efficient network?".
그들은 다음과 같은 결론에 도달했다 :
longest shortest gradient path를 제어함으로써, deeper network가 효과적으로 학습하고 수렴할 수 있다는 것이다.
-
ELAN [78]은 다음과 같은 설계 전략을 고려합니다: "효율적인 네트워크를 어떻게 설계할 것인가?" 그들은 다음과 같은 결론에 도달했습니다: 가장 긴 최단 그래디언트 경로를 제어함으로써, 더 깊은 네트워크가 효과적으로 학습하고 수렴할 수 있다는 것이다.
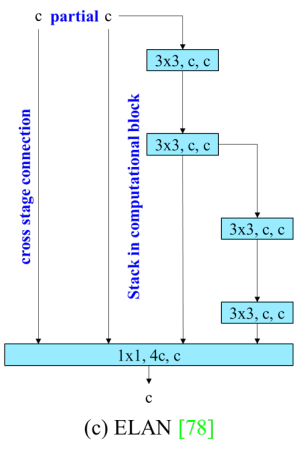 이 논문에서는 ELAN을 기반으로 하는 Extended-ELAN (E-ELAN)을 제안하며,
이 논문에서는 ELAN을 기반으로 하는 Extended-ELAN (E-ELAN)을 제안하며,
그 주요 아키텍처는 Figure 2 (d)에 나와 있다.
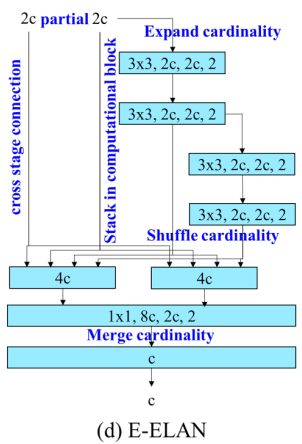
-
large-scale ELAN에서 gradient path length와 #computational blocks와 관계없이,
system은 stable state에 도달하게 된다.
computational block을 무제한으로 쌓게 되면 이 stable state는 파괴될 수 있으며,
parameter utilization rate가 감소될 것이다.
제안된 E-ELAN은 expand, shuffle, merge cardinality를 사용하여 원래의 gradient path를 파괴하지 않고 network의 learning ability를 강화시킬 수 있는 기능을 구현한다.
architecture 측면에서, E-ELAN은 computational block의 architecture만 변경하고,
transition layer의 architecture는 아예 바꾸지 않는다.
우리의 strategy는 group convolution을 사용하여 computational block의 channel과 cardinality를 확장하는 것이다.
우리는 같은 group parameter와 channel ratio를 모든 computational layer의 모든 computational block에 적용한다.
그런 다음, 각 computational block에서 계산된 feature map을 설정된 group parameter 에 따라 개의 group으로 shuffled된 후,
이를 다시 concatenate한다.
이때, 각 group의 feature map의 channel 수는 원래 architecture의 channel 수와 동일하다.
마지막으로, 개의 feature map group을 추가하여 merge cardinality를 수행한다.
E-ELAN은 원래 ELAN design architecture를 유지하면서도 다양한 computational block group이 더 다양한 features를 학습하도록 유도할 수 있다.
3.2. Model scaling for concatenation-based models
-
model scaling의 main purpose는 model의 일부 속성을 조정하여 다양한 scale의 model을 생성함으로써
서로 다른 inference speed의 needs를 만족시키는 것이다. -
model scaling 방법들은 주로 PlainNet이나 ResNet과 같은 architecture에서 사용된다.
이러한 architecture에서 scale up 또는 scale down을 수행할 때,
각 layer의 in-degree와 out-degree는 변하지 않으므로,
각 scaling factor가 parameter와 computation량에 미치는 영향을 독립적으로 분석할 수 있다.
그러나 이러한 방법들을 concatenation-based architecture에 적용하면,
depth에 대한 scaling up or scaling down을 수행할 때 concatenation-based computational block 바로 뒤에 위치한 transition layer의 in-degree가 감소하거나 증가하는 것을 확인할 수 있다 (Figure 3 (a) and (b))
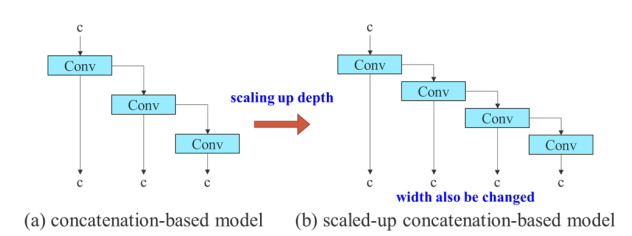 위의 현상으로부터,
위의 현상으로부터,
concatenation-based model에 대해 다양한 scaling factor를 개별적으로 분석할 수 없으며,
함께 고려해야 한다는 것을 알 수 있다.
예를 들어, scaling-up depth를 수행하면 transition layer의 input channel과 output channel 간의 비율이 변경되어 model의 HW usgae가 감소할 수 있다.
따라서, concatenation-based model에 대해 적절한 compound model scaling method를 제안해야 한다.
computational block의 depth factor를 scaling할 때, 해당 block의 output channel 변경도 함께 계산되어야 한다.
그런 다음, 동일한 양의 변경을 transition layer에 대해 width factor scaling을 수행한다.
이 결과는 Figure 3 (c)에서 확인할 수 있다.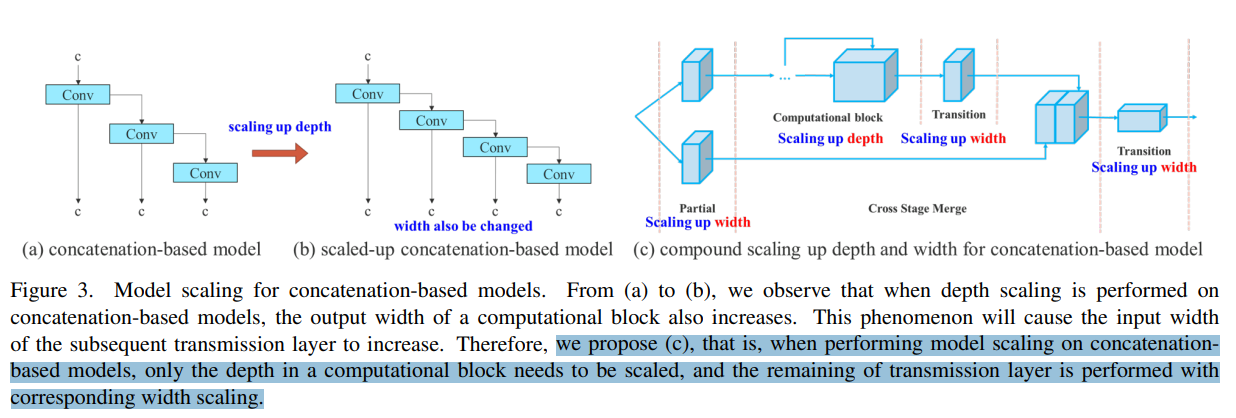 우리가 제안하는 compound scaling method는 model이 inital design에서 가졌던 특성을 유지하며 optimal structure를 유지할 수 있다.
우리가 제안하는 compound scaling method는 model이 inital design에서 가졌던 특성을 유지하며 optimal structure를 유지할 수 있다.
4. Trainable bag-of-freebies
4.1. Planned re-parameterization model
-
RepConv는 VGG에서 우수한 성능을 달성했지만, 이를 ResNet이나 DenseNet과 같은 비단순(non-plain) architecture에 직접 적용하면 accuracy가 크게 저하된다.
우리는 gradient flow propagation paths를 사용하여 re-parameterization convolution이 어떻게 다양한 network와 결합되어야 하는지를 분석했으며, 이에 맞춰 re-parameterization model을 design했다. -
RepConv는 실제로 conv, conv, 그리고 identity connection을 하나의 conv layer에서 결합했다.
RepConv와 다양한 architecture의 combination 및 performance를 분석한 결과,
RepConv의 identity connection이 ResNet의 residual과 DenseNet의 concatenation을 파괴하여 다양한 feature map에 대한 more diversity of gradients을 제공한다는 것을 발견했다.
이러한 이유로, 우리는 identity connection이 없는 RepConv(= RepConvN)을 사용하여 planned(계획된) re-parameterization model architecture를 설계했다.
즉, 우리의 생각은 residual or concatenation이 있는 conv layer를 re-parameterization conv로 대체할 때는 identity connection이 없어야 한다는 것이다.
Figure 4는 우리가 설계한 “planned re-parameterization model”이 PlainNet과 ResNet에 적용된 예를 보여준다.
(residual-based model과 concatenation-based model에서의 complete planned re-parameterization model experiment는 ablation study section에서 보여줄 것임.)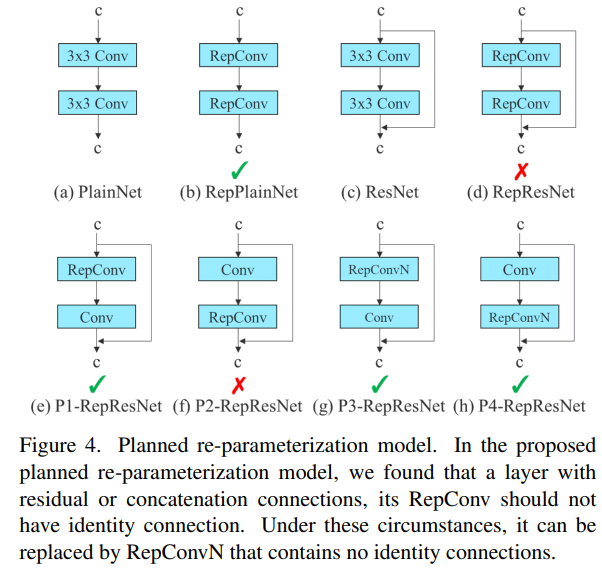
4.2. Coarse for auxiliary and fine for lead loss
-
Deep supervision은 deep network를 training하는 데 사용되는 기술로,
주요 개념은 network의 middle layer에 추가적인 auxiliary head를 추가하고,
shallow network weights를 assistant loss를 통해 guide하는 것이다.
일반적으로 잘 수렴하는 ResNet과 DenseNet과 같은 architecture에서도 deep supervision은 많은 작업에서 model의 성능을 크게 향상시킬 수 있다.
Figure 5 (a)와 (b)는 각각 deep supervision이 "without(없는)" object detector acthicture와 "with(있는)" object detector acthicture를 보여준다.
이 논문에서는 final output을 담당하는 head를lead head라고 부르며,
training을 보조하는 데 사용되는 head는auxiliary head라고 부른다.
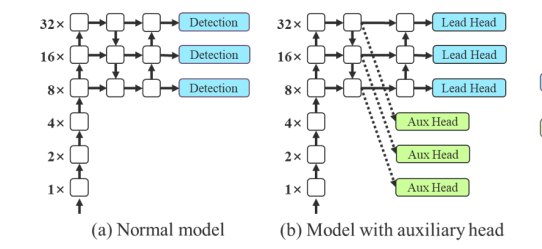
-
다음으로 label assignment issue를 논의하고자 한다.
과거에는 deep network training에서 label assignmetn가 주로 ground truth에 직접 참조하여 주어진 rule에 따라 hard label을 생성하는 것을 의미했다.
그러나 최근 몇 년 동안, object detection을 예로 들면,
researchers들은 종종 network가 예측한 output의 quality and distribution을 고려하여 GT와 함께 optimization methods를 사용해 reliable soft label을 생성한다.
예를 들어, YOLO는 bbox reression의 prediction IoU와 GT를 objectness의 soft label로 사용한다.
본 논문에서는 network prediction results와 GT를 함께 고려하여 soft label을 할당하는 mechanism을label assigner라고 부른다.
- Deep supervision은
auxiliary head또는lead head의 상황에 관계없이 target objectives에 대해 학습할 필요가 있다.
soft label assigner관련 기술을 개발하는 과정에서, 우리는 우연히 새로운 파생 문제를 발견했다.
즉, "auxiliary head와 lead head에 soft label을 어떻게 할당할 것인가?"이다.
현재로서는 이와 관련된 literature은 아직 이 문제를 탐구하지 않았다.
현재 가장 인기 있는 방법의 결과는 Figure 5 (c)에서 보여주며,
이는 auxiliary 와 lead head를 분리한 다음,
각자의 prediction results와 GT를 사용하여 label assignment를 수행하는 방법이다.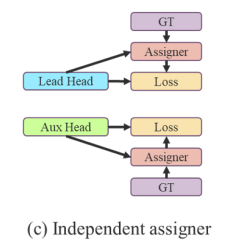
본 논문에서 제안하는 방법은 lead head prediction을 통해 auxiliary head와 lead head 모두를 guide하는 a new label assignment method이다.
즉, lead head prediction을 guide로 사용하여 coarse-to-fine hierarchical labels을 생성하고,
이를 auxiliary head와 lead head learning에 각각 사용한다.
제안된 두 가지 deep supervision label assignment strategies는 Figure 5 (d) 와 (e)에 각각 표시되어 있다.
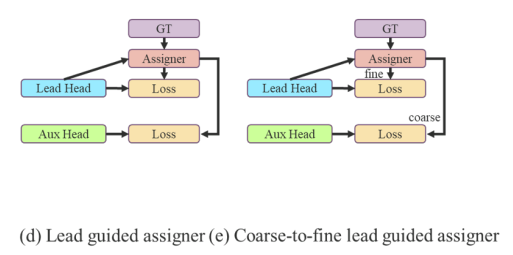
Lead head guided label assigner
- Lead head guided label assignmer는 주로 lead head의 prediction result와 GT를 기반으로 계산되며,
optimization process를 통해 soft label을 생성한다.
이 soft label set은 auxiliary head와 lead head 모두의 target training model로 사용된다.
이렇게 하는 이유는 lead head가 상대적으로 strong learning capability를 갖고 있기 때문에,
lead head에서 생성된 soft label이 source data와 target 간의 distribution 및 correlation을 더 잘 대표할 수 있기 때문이다.
또한, 이러한 학습을 generalized residual learning으로 볼 수 있다.
shallower auxiliary head가 lead head에서 이미 학습한 정보를 직접 학습하도록 함으로써,
lead head는 아직 학습되지 않은 residual information을 학습하는 데에 더 집중할 수 있게 된다.
Coarse-to-fine lead head guided label assigner
-
Coarse-to-fine lead head guided label assigner 또한 lead head의 predicted result와 GT를 사용하여 soft label을 생성한다.
그러나 이 과정에서는 두 가지 다른 soft label set, 즉 coarse label과 fine label을 생성한다.- fine label은 lead head guided label assigner에서 생성된 soft label과 동일하며,
- coarse label은 positive sample assignment process의 constraints를 완화하며 더 많은 grid를 positive target으로 취급하여 생성된다.
이렇게 하는 이유는 auxiliary head의 학습 능력이 lead head보다 강하지 않기 때문에, 학습해야 할 정보를 잃어버리는 것을 방지하고자 auxiliary head의 recall을 최적화하는 데 중점을 둔다.
-
lead head의 output에 대해서는,
높은 recall results에서 높은 precision results를 filtering하여 final output을 생성할 수 있다.
그러나 추가된 coarse label의 weight가 fine label의 weight와 가까울 경우,
final prediction에서 bad prior(우선순위)가 발생할 수 있음을 유의해야 한다.
따라서 추가된 coarse positive grids가 영향을 미치지 않도록 decoder에서 제약을 두어,
추가된 coarse positive grids가 완벽한 soft label을 생성할 수 없도록 한다.
이 mechanism은 학습 과정에서 fine label과 coarse label의 중요성을 동적으로 조정할 수 있게 하며,
fine label의 optimizable upper bound가 항상 coarse label보다 높도록 한다.
(Lead Head에서의 optimize가 Aux Head의 optimize보다 항상 잘 되도록 한다는 얘기 같은데...
이해가 잘 안 되어서 어떻게 구현했는지 코드를 살펴봐야 하겠다...)
모르는 것
-
ELAN(Efficient Layer Aggregation Networks) :
-
(V) group convolution? https://sjkoding.tistory.com/76
-
Figure 4가 어떻게 그려졌는지? (체크 표시와 X표시는 무엇을 뜻하는지?)
