연구 아이디어 철회 & 실패 원인 분석
-
실패 원인 1 : 우선 Hint = #objects를 prediction하기 위해서는 object detection 또는 semantic segmentation과 같은 능력이 있는 network가 필요한데,
내가 Hint를 prediction하려는 부분은 backbone + sub-network이기 때문에 충분한 능력을 학습할 수 없다.
backbone은 image에 대한 local한 Feature들만 extraction하기 때문에 global context를 파악하여
image 내의 전체 object 개수를 prediction하기에 model capability가 매우 떨어진다. -
실패 원인 2 : 만약 Hint = #objects prediction이 성공적으로 개발되었다고 가정하자.
하지만, training은 batch 단위로 이루어지기 때문에 image-specific한 sub-network를 만들기 위해서는 training에서 복잡한 코드 수정이 이루어짐.
(예를 들어,
예측한 #objs가 [3, 120, 84, 6]라고 했을 때,
첫 번째 image에 3개의 instance가 있고, ... 네 번째 image에 6개의 instance가 있다는 의미인데,
각 batch 안의 4개의 image를 image-specific하게 model을 adaptive하게 forward & backward하기 위해서는
if문으로 해당 image의 instance가 몇 개인지 파악하고 해당하는 weight의 update가 이루어지지 않게 수정해야 함)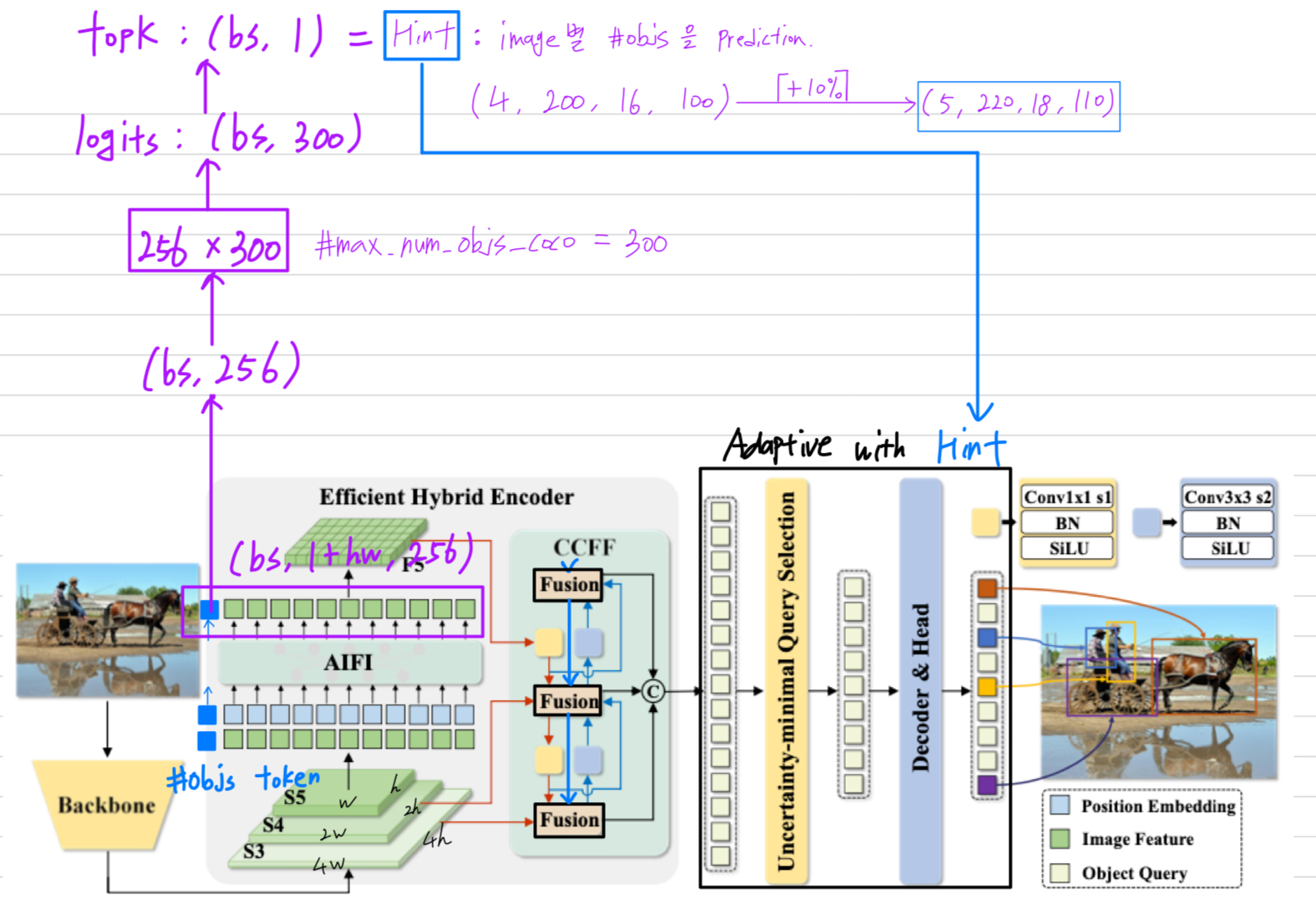 이는 깔끔하고 직관적인 아이디어가 될 수 없고, 연구로서의 의미와 매력이 없음.
이는 깔끔하고 직관적인 아이디어가 될 수 없고, 연구로서의 의미와 매력이 없음.
+ (좋은 연구 아이디어는 구현이 심플하고 직관적이어야 한다는 피드백을 받음)
