[2023 ICCV][중단] Robust Mixture-of-Expert Training for Convolutional Neural Networks
[Paper Review] Efficient and Scalable
Paper Info

Abstract
- DL architecture로 떠오르고 있는, Sparsely-gated MoE는
high-acc and ultra-efficient model inference를 가능하게 하는 유망한 방법으로 입증되어 왔다.
MoE 인기 성장에도 불구하고, 특히 convolutional neural networks(CNNs)의 adversarial(적대적, 대립적) robustness 측면에서 MoE의 potential을 탐구한 연구는 거의 없었다.
CNNs의 the lack of robustness가 main hurdles(주요 장애물) 중 하나가 되었기 때문에, 본 논문에서는 다음과 같은 질문을 제기한다:- How to adversarially robustify a CNN-based MoE model?
(어떻게 하면 CNN-based MoE model을 적대적으로 robust하게 만들 수 있을까?) - Can we robustly train it like an ordinary CNN model?
(MoE model을 일반 CNN model처럼 robust하게 train할 수 있을까?)
- How to adversarially robustify a CNN-based MoE model?
- 우리의 pilot study(선행 연구)는
conventional adversarial training(AT) mechanism(vanilla CNNs용으로 개발된)이
MoE-CNN을 robust하게 만드는 데 더 이상 효과적이지 않음을 보여준다.
이 phenomenon을 더 잘 이해하기 위해, 우리는 MoE-CNN의 robustness를 두 가지 dimension으로 분해한다:- Robustness of routers (즉, data-specific experts를 선택하는 gating functions)
- Robustness of experts (즉, backbone CNN의 subnetworks로 정의된 router-guided pathways)
-
분석 결과, routers와 experts가 기존 AT mechanism에서 서로 적응하기 어렵다는 것을 알 수 있었다.
이에 따라 우리는 MoE를 위한 a new router-expert alternating Adversarial training(router-expert 교대 대립적 학습?) framework, termed ADVMoE를 제안한다. -
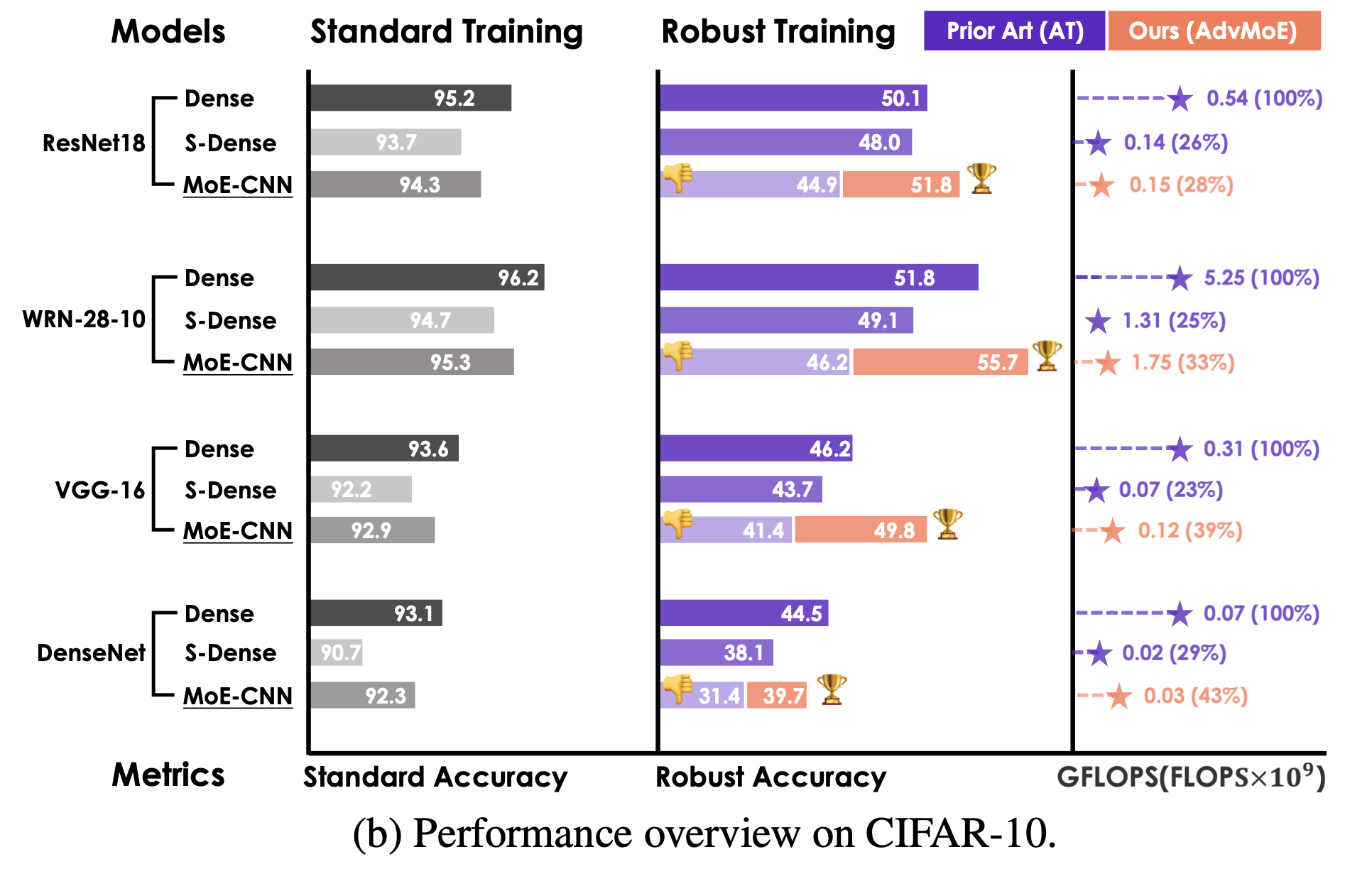
제안된 방법의 효과는 4가지 일반적으로 사용되는 CNN model architecture와 4개의 benchmark dataset에서 입증되었다.
결과적으로, ADVMoE는 original dense CNN보다 1%~4%의 adversarial robustness improvement를 달성했으며,
sparsity-gated MoE의 efficiency merit을 누려 inference cost를 50% 이상 줄일 수 있었다.
https://github.com/OPTML-Group/Robust-MoE-CNN
1. Introduction
-
다양한 DL tasks에서 outrageously large networks가 SOTA를 달성했음에도 불구하고,
이러한 models들을 cheaply train and deploy하는 것은 여전히 challenging하다.
주요 bottleneck은 the lack of parameter efficiency이다:
A single data prediction은 full model의 a small portion of the parameters만 activating하면 충분하다. -
efficient DL을 위한 접근법으로,
sparse MoE는 specific inputs에 대해 optimal response를 보이는 parameters를 기반으로
model을 divide and conquer하여 inference costs를 줄이는 것을 목표로 한다.
typical MoE structure는
'experts' (original backbone network로부터 추출된 sub-models)와
'routers' (각 layer에서 expert 선택을 결정하는 small-scale gating networks)
로 구성된다. -
inference시,
sparse MoE는 input data에 대해
the most relevant experts를만 activating하여
expert-guided pathway를 형성한다.
이를 통해 sparse MoE는 inference efficiency를 향상시킬 수 있다. (Fig. 1의 'GFLOPS')
 Architecture-wise(구조적으로?),
Architecture-wise(구조적으로?),
sparse MoE는 CNN과 ViTs 모두에 사용되었다.
그러나 본 연구에서는 CNNs을 위한 sparse MoE에 중점을 둔다.
이는 CNN용 non-sparse MoE에 비해 sparse MoE 연구가 상대적으로 미흡하며,
adversarial robustness (본 연구의 또 다른 key performance metric)가 CNNs의 context에서 광범위하게 연구되었기 때문이다. -
DL의 main weaknes 중 하나는 the lack of adversarial robustness로 알려져 있다.
예를 들어, CNN은 adversarial attacks에 쉽게 속을 수 있다.
adversarial attacks은 잘못된 predictions을 위해 생성된 tiny input perturbations(미세한 입력 변형)을 의미한다.
따라서 CNN의 AT는 a main research thrust(주 연구 방향)로 자리 잡았다.
그러나 CNN이 sparse MoE와 결합될 경우,
sparse MoE로 인해 향상된 inference efficiency가
더 복잡한 adversarial training recipes의 대가를 치르는지는 명확하지 않다.
이에 우리는 다음과 같은 질문을 제기한다:
 (sparse MoE-integrated CNNs의 adversarial robustness에 대한 new insights는 무엇인가?
(sparse MoE-integrated CNNs의 adversarial robustness에 대한 new insights는 무엇인가?
그리고 AT mechanism에 적합한 mechanism은 무엇인가?)
현재 문헌에서는 문제 가 미해결 상태로 남아 있다.
본 연구와 가장 관련성이 높은 연구는 [30]으로, MoE의 adversarial robustness를 조사하고 기존 AT recipe[24]를 사용해 adversarial attacks에 defend(방어)했다.
그러나 이 연구는 ViT architecture에만 초점을 맞췄으며,
sparse MoE-base CNN(본 연구에서는 MoE-CNN으로 명명)의 robustification 강화에 대한 연구는 공백으로 남아 있다.
가장 중요한 것은, CNN을 robust하게 만들기 위해서 널리 사용되는 vanilla AT가
MoE-CNN에서는 더 이상 효과적이지 않다는 점을 발견했다는 것이다.
따라서 새로운 solution이 필요하다.
를 해결하기 위해서, 우리는 다음을 수행해야 한다.- MoE-CNN에서 AT에 대한 careful sanity checks(신중한 사전 검증)
- AT failure cases(실패 사례)에 대한 in-depth analysis(심층 분석)
- sparse MoE의 generalization and efficiency를 유지하면서 robustness를 효과적으로 향상시킬 수 있는 new AT principles 개발
-
구체적으로, our contributions are unfoleded below.
- 우리는 MoE robustness를 두 가지 dimensions으로 나누어 분석했다(CNN과는 다른 방식으로):
routers' robustness and experts' robustness
이와 같은 robustness 분석은 AT의 (in)effectiveness에 대한 새로운 insights를 제공한다. - 위의 robustness 분석에 영감을 받아,
우리는 ADVMoE라고 불리는 MoE를 위한 새로운 Adversarial training framework를 제안한다.
이 framework는 routers와 experts가 협력하여 MoE-CNN의 전반적인 robustness를 향상시키도록 만든다. - 실험 결과...
- 우리는 MoE robustness를 두 가지 dimensions으로 나누어 분석했다(CNN과는 다른 방식으로):
몰랐던 것
- Adversarial training?
참고자료: https://m.blog.naver.com/kisooofficial/223231367433

중단 이유
- adversarial attacks에 대해 Robust한 adversarial training framework for MoE에 대한 논문임.
나는 CNN을 위한 MoE 연구를 알고 싶은데, 이 논문은 CNN + AT에 집중적임.
