[2019 NeurIPS] CondConv: Conditionally Parameterized Convolutions for Efficient Inference
[Paper Review] Efficient and Scalable
Paper Info

Abstract
-
Conv layers는 modern deep NN에서 basic building blocks 중 하나임.
이에 대한 한가지 기초적인 assumption은 conv kernels이 한 dataset의 모든 examples에 대해서 공유되어야 한다는 것임. -
We propose conditionally parameterized convolutions (CondConv), which learn specialized convolutional kernels
for each example.
normal conv를 CondConv로 바꿈으로써 efficient inference를 유지하면서, network의 size and capacity를 증가시킬 수 있음. -
We demonstrate that scaling networks with CondConv
improves the performance and inference cost trade-off
of several existing convolutional neural network architectures on both classification and detection tasks.
1. Introduction
-
conv layers의 design에 대한 한가지 fundamental assumption은
the same conv kernels이 한 dataset 내의 모든 example에 대해 적용되어야 한다는 것이다.
이러한 assumption과 mobile deployment에 초점을 맞추기 때문에, 현대의 computationally efficient models은 very few parameters를 갖는다.
그러나 inference 시 엄격한 latency requirements를 가진,
real-time server-side video processing 및 self-driving cars의 perception과 같은
computer vision applications이 점점 늘어나고 있다.
이 논문에서, 우리는 이러한 apps에 더 적합한 models을 design하는 것을 목표로 한다. -
우리는 input에 따라 convolutional kernels을 computing하는
conditionally parameterized convolutions (CondConv)를 제안하며,
기존의 static convolutional kernels의 paradigm에 도전한다.
구체적으로, CondConv layer에서 convolutional kernels을 개의 experts 조합으로 parameterize한다.
, 여기서 은 gradient descent를 통해 학습되는 input의 functions이다.
CondConv layer의 capacity를 증가시키기 위해, model developers는 #experts를 늘릴 수 있다.
이는 convolutional kernel의 size 자체를 늘리는 것보다 훨씬 더 computationally efficient하다.
왜냐하면 convolutional kernel은 input의 여러 위치에 반복적으로 적용되는 반면, experts의 조합은 input당 한 번만 이루어지기 때문이다.
이를 통해 model developers는 efficient inference를 유지하면서 model capacity and performance를 증가시킬 수 있다.
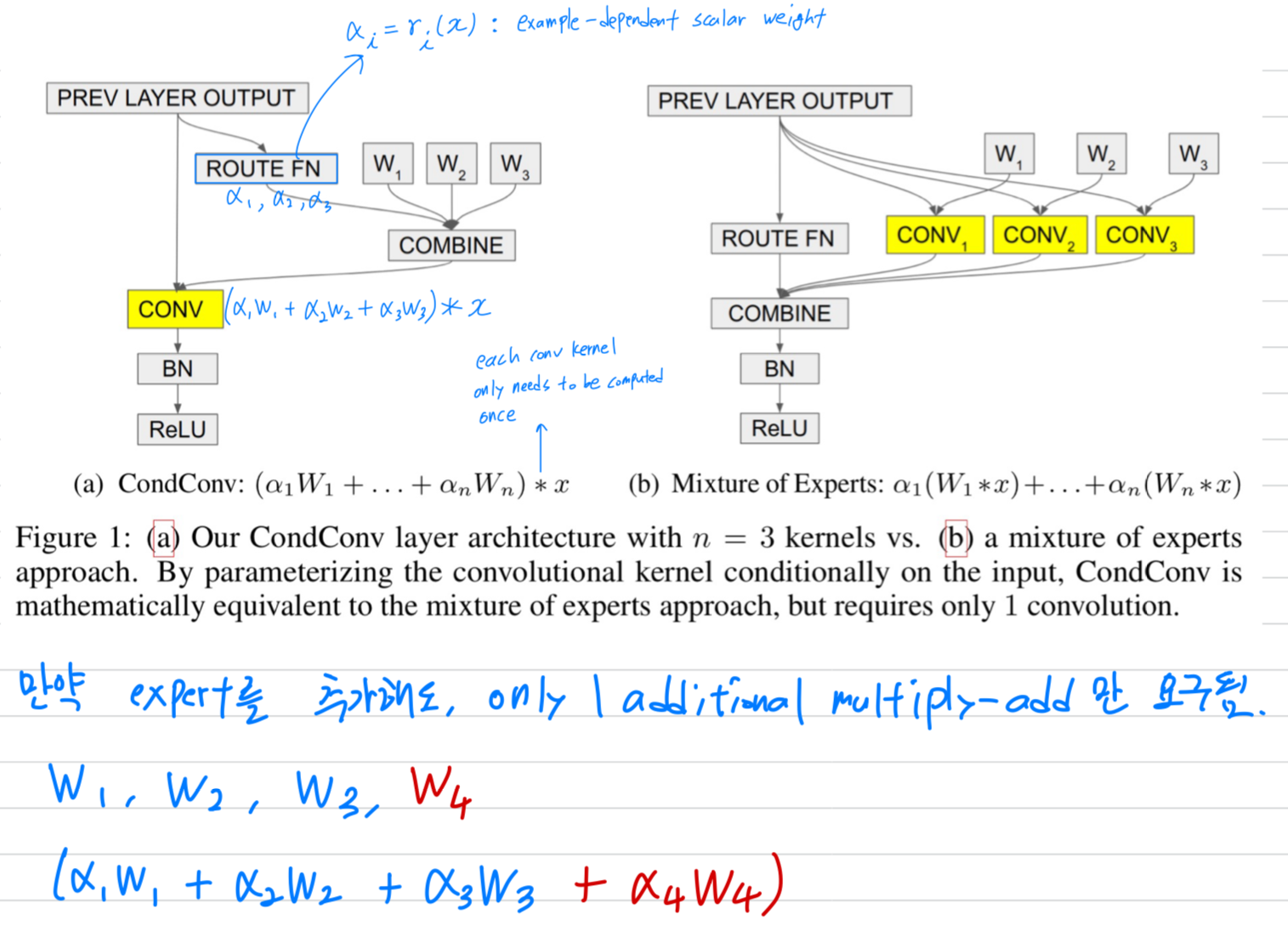
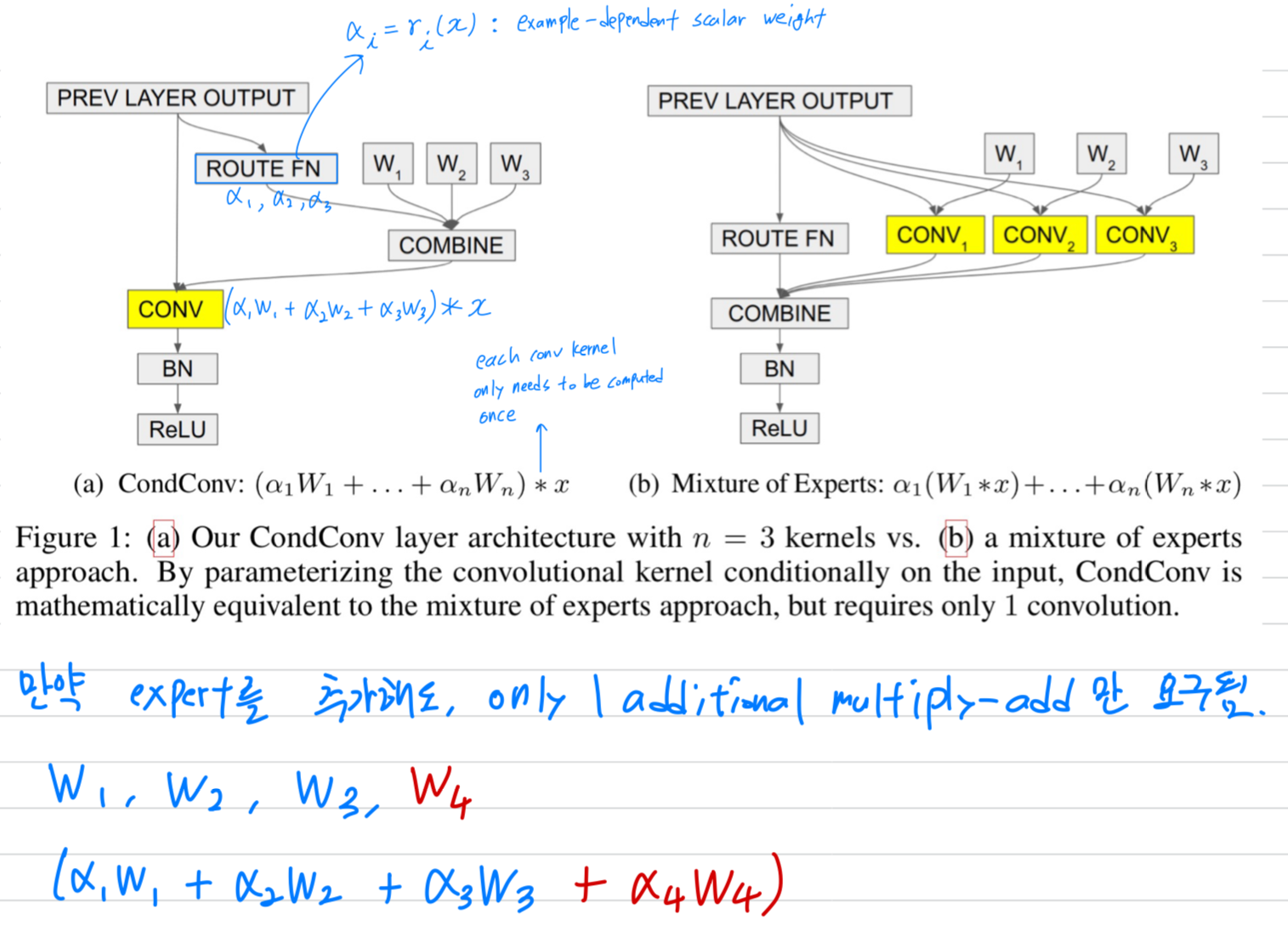
- CondConv는 CNN architecture에서 기존 conv layers의 대체로 바로 사용될 수 있다.
ImageNet classification 및 COCO object detection에서 여러 CNN architecture의 conv layer를 CondConv로 교체할 때, model의 capacity and performance가 향상되며 efficient inference가 유지됨을 입증했다.
분석 결과, CondConv layers는 conditional conv kernels을 계산하기 위해 examples 간 의미적으로 유의미한 관계를 학습함을 발견함.
2. Related Work
Conditional computation
-
CondConv처럼, conditional computation은 computation cost의 비례적인 증가 없이 model capacity를 증가하는 것을 목표로 한다.
conditional computation models에서, 이는 each example당 entire network의 일부분만을 activating함으로써 달성되어졌다.
하지만, conditional computation models은 각각의 examples들이 서로 다른 experts로 가는 discrete routing deicions을 필요로 하기 때문에 train하기에 challenging하다.
이러한 approaches와 달리, CondConv는 discrete routing of examples을 필요로 하지 않아서, gradient descent로 쉽게 optimized될 수 있다. -
Shazeer et al. [37]은 sparsely-gated mixture-of-experts layer를 제안했다.
이는 noisy top-k gating을 활용하여 LLM에서 siginificant success를 달성했다.
computation에 대한 이전 연구들은 different sets of examples을 different sub-networks와 함께 process시키어 large models을 designing하는 potential을 입증했다.
우리의 CondConv 연구는 each individual example이 서로 다른 weights로 처리될 수 있도록 함으로써 이 pardigm의 boundaries(한계)를 확장했다.
Weight generating networks
- Ha et al. [13]은 larger network의 weights를 생성하기 위해 a small network를 사용하는 방법을 제안했다.
CondConv와 달리, 이 방법에서는 CNN에서 모든 dataset example에 동일한 weights를 사용한다.
이는 더 많은 weight-sharing을 가능하게 하여 parameter 수를 줄일 수 있지만, original network에 비해 worse performance된다.
Multi-branch convolution networks
- Inception and ResNext와 같은 Multi-branch architectures는 다양한 CV tasks에서 성공을 거두고 있다.
이러한 architectures에서는 한 layer가 여러 개의 conv branches로 구성되며,
final output은 이 branch들이 aggregated되어 계산된다.
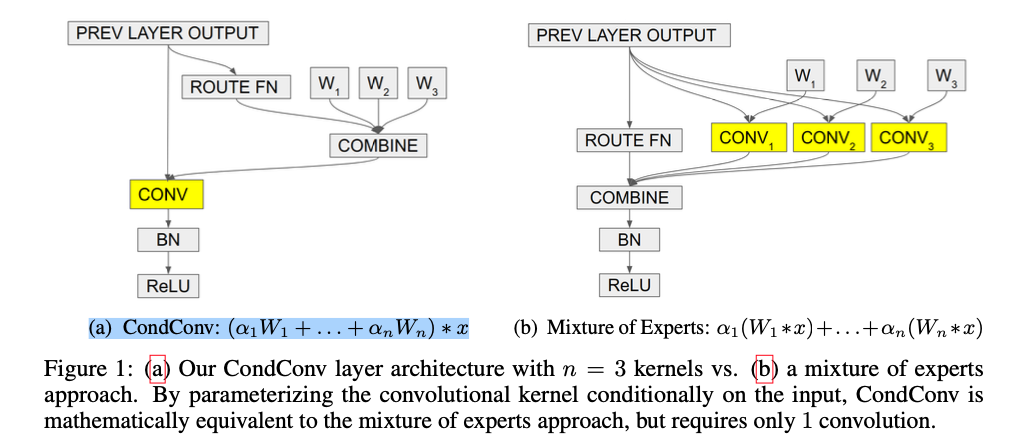
CondConv layer는 수학적으로 각 branch가 a single convolution이고 outputs이 weighted sum으로 aggregated되는 multi-branch conv layer와 동등하지만,
단 한 번의 convolution 계산만 하면 된다.
Example dependent activation scaling
(skip)
Input-dependent convolutional layers
(skip)
3. Conditionally Parameterized Convolutions
-
a regular conv layer에서, all input examples에 대해 같은 conv kernel이 사용된다.
a CondConv layer에서는, conv kernel이 input example에 따라 계산된다. (Fig 1a)
구체적으로, CondConv에서 conv kernels은 다음과 같이 parameterize된다:
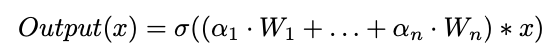 where
where
each 는 routing function에 의해 학습된 parameters를 사용해 계산되는 example-dependent scalar weight이며,
은 #experts,
는 activation function이다.
a conv layer에 CondConv를 적용할 때, 각 kernel 는 original conv의 kernel과 same dimensions이다.
일반적으로 conv layer의 capacity를 증가시키려면 kernel의 height/width 또는 #input/output channels을 늘린다.
그러나 convolution에서 추가되는 각 추가의 parameter는 input feature map의 #pixels에 비례하여 추가적인 multiply-adds을 요구하므로,
input size가 클수록 computation이 급격히 증가한다.
반면, CondConv layer에서는 각 example별로 expert 명의 linear combination을 통해 conv kernel을 계산한 후 이를 적용한다.
중요한 점은, 각 conv kernel은 한 번만 계산되지만 input image에서 many different positions에 반복적으로 사용된다는 것이다.
따라서 을 늘림으로써, network의 capacity를 효과적으로 증가시킬 수 있으며, inference cost는 소폭만 증가한다.
추가되는 각 parameter는 only 1 additional multiply-add만 요구된다.
- 궁금한 점 :
- routing funciton의 내부는 어떻게 되어있는가? (바로 밑에 설명 있음)
- routing function은 pre-trained된건가? jointly trained되는건가?
- 의 distribution은 매우 유동적일건데, 학습이 불안정하지 않으려나..?
- 은 model capacity 증가를 위해서 새로 추가된 개의 weight겠지?
그럼 original model의 capacity는 배가 된거겠지?
- 궁금한 점 :
-
CondConv layer는 더 많은 expensive linear MoEs formulation과 수학적으로 동일하다.
각 expert는 a static conv에 대응한다 (Fig 1b):
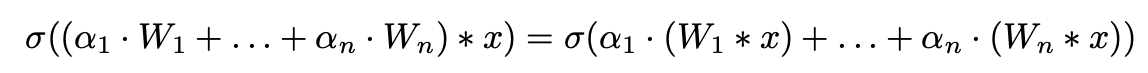 그러므로, CondConv는 개의 experts를 갖는 a linear MoEs formulation과 동일한 capacity를 갖지만
그러므로, CondConv는 개의 experts를 갖는 a linear MoEs formulation과 동일한 capacity를 갖지만
only one convolution만 필요로 하기 때문에 computationally efficient하다. -
per-example routing function은 CondConv performance에 중요한 역할을 한다:
만약 learned routing function이 모든 examples에 대해 동일하다면, Cond Conv layer는 a static conv layer와 동일한 capacity를 갖는다.
우리는 computationally efficient하고, input examples 사이에 의미있는 differentiate(미분)과 easily interpretable한
a per-example routing function을 design하길 원한다.
우리는 three steps으로부터 example-dependent routing weights 를 계산한다: GAP, FC layer, Sigmoid activation
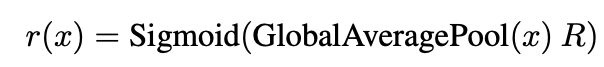 여기서 은 pooled inputs을 expert weights로 mapping하는 learned routing weights이다.
여기서 은 pooled inputs을 expert weights로 mapping하는 learned routing weights이다.
normal conv operation은 local receptive fields에서만 작동하므로, 우리의 routing function은 global context를 사용하여 local operations을 적응할 수 있도록 한다.
CondConv layer는 network의 모든 conv layer를 대신하여 사용할 수 있다.
이 approach는 depth-wise convs and fc layers에도 쉽게 확장할 수 있다.
4. Experiments
-
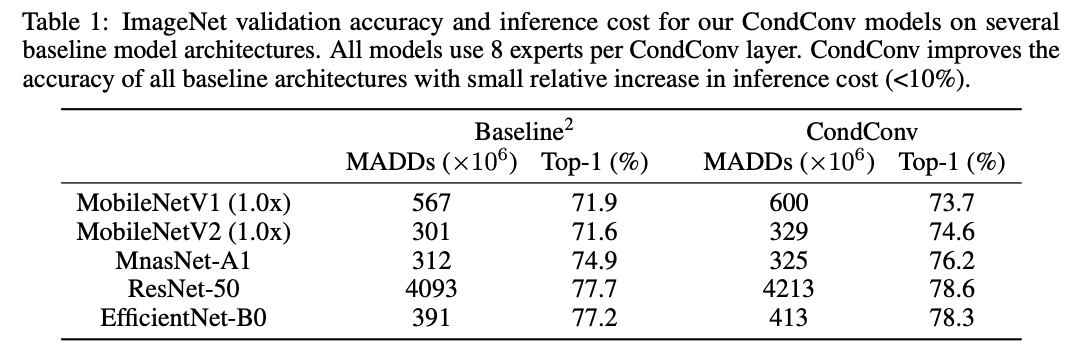
우리는 MobileNetV1, V2, ResNet-50, MnasNet, and EfficientNet을 scaling up함으로써
ImageNet classification and COCO object detection에 대해서 CondConv를 평가했다. -
CondConv model을 train하는 두 가지 options이 있다.
- 각 example에 대한 kernel을 먼저 계산한 다음 batch size가 1인 convolution을 적용하는 것이다. (Fig. 1a)
- linear MoEs formulation(Fig. 1b)을 사용하여 각 branch에 대해 batch convs을 수행한 다음 outputs을 sum하는 것이다.
현대 accelerators는 large batch convs에 대해 train되도록 optimized되어 있으며 small batch sizes에 대해서 완전히 utilize하기 어렵다.
따라서 small #experts(<=4)에는 두 번째 방식을 사용하여 CondConv layer를 train하는 것이 더 효율적인 것으로 나타났다.
large #experts(>4)에는 첫 번째 바식을 사용하여 직접 CondConv layer를 train하는 것이 더 효율적이다.
4.1 ImageNet Classification
4.2 COCO Object Detection

