
1. OCR (Optical Character Recognition, 광학 문자 인식)
- 이미지나 문서에서 문자를 식별하고 디지털 텍스트로 변환하는 기술.
- 주로 스캔된 문서, 사진 속 글자, 번호판, 손글씨 등의 텍스트를 자동으로 인식하는 데 사용
기본적인 OCR 방식
1. 이미지 전처리(그레이스케일 변환, 이진화, 노이즈 제거)
2. 문자 영역 감지
3. 문자 패턴을 데이터베이스와 비교
4. 최적의 텍스트 추출
- OpenCV와 Tesseract OCR을 사용하면 Python에서 쉽게 구현할 수 있으며,
딥러닝 기반의 EasyOCR, PaddleOCR, Google Vision OCR 등을 활용하면 한글과 다양한 언어의 인식률을 더욱 높일 수 있다고 한다.
2. Tesseract OCR
Tesseract OCR ← 이곳에서 Tesseract 설치 가능 (단, 윈도우만)
- Google이 개발한 오픈소스 광학 문자 인식(Optical Character Recognition, OCR) 엔진
- 다양한 언어를 지원하며 높은 정확도의 문자 인식을 제공한다.
- 기본적으로 LSTM(Long Short-Term Memory) 기반의 딥러닝 OCR 모델을 포함하고 있으며, tesseract-ocr 엔진과 함께 pytesseract 라이브러리를 사용하면 Python에서도 쉽게 적용할 수 있다.
Tesseract OCR 설치 과정...🫨
설치는 그냥 하면 되지만, 중요한 것만 적어두겠다.
- Language data에서 영어로 한굴...(Hangul) 하고 뭐라 적혀 있는 것들 체크!
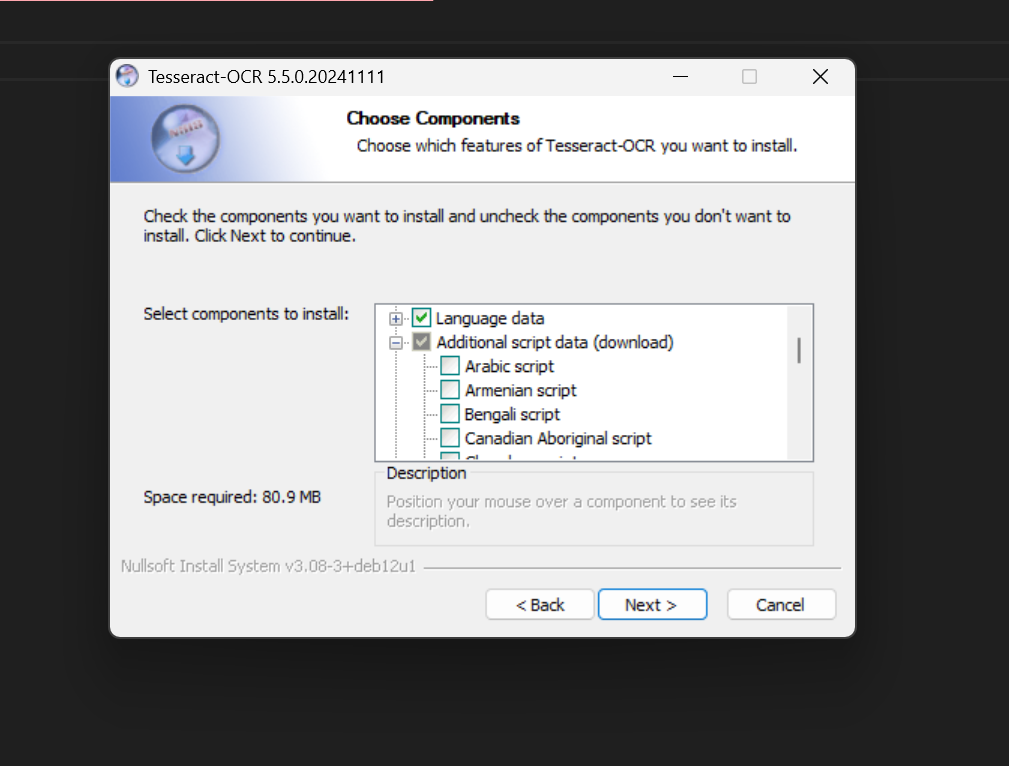
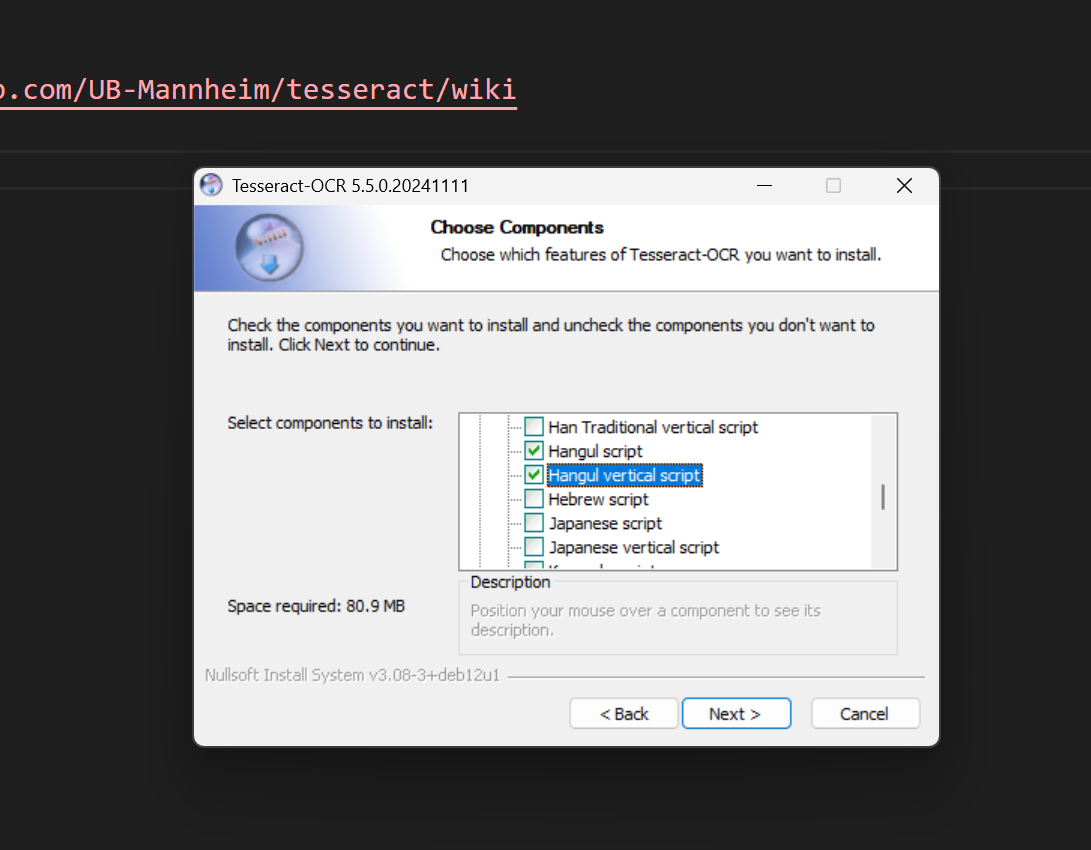
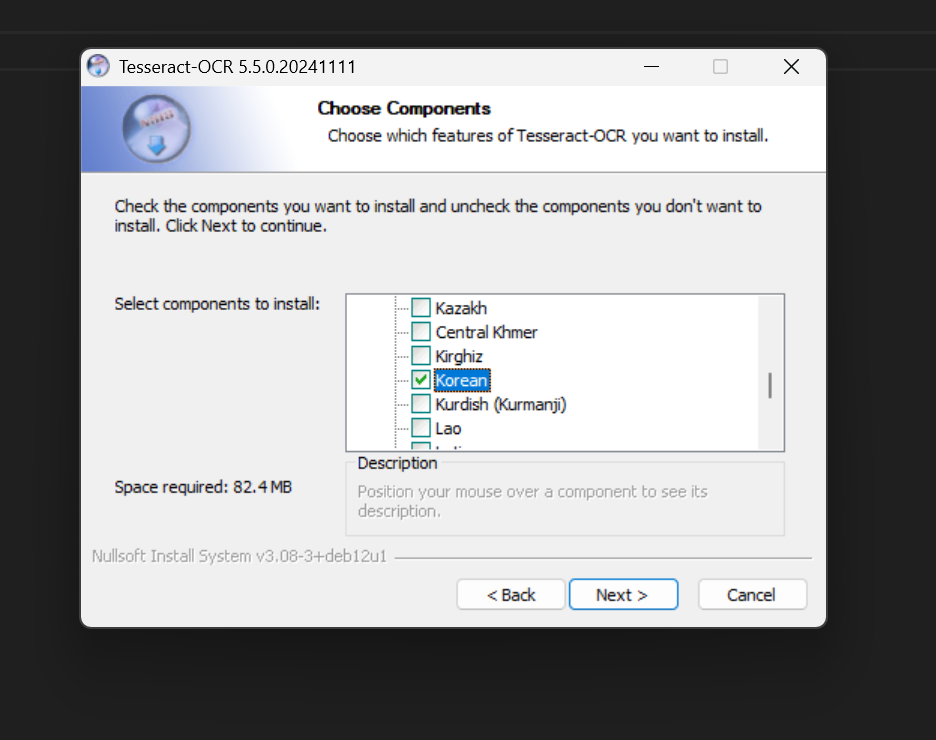
- Additional language data(download)에 Korean 체크!

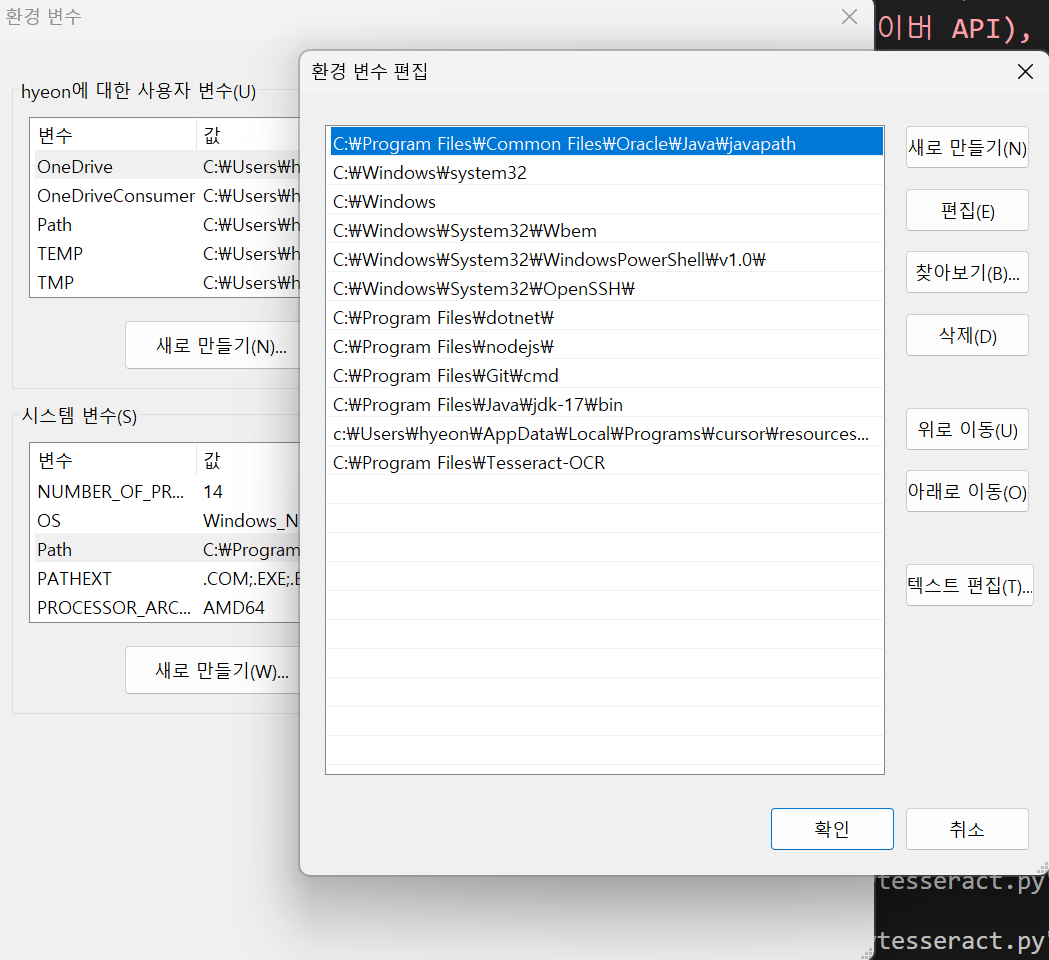
- Tesseract_OCR 경로 확인 : C:\Program Files\Tesseract-OCR
- Windows "고급 시스템 설정"에서 Tesseract 실행파일 경로를 환경변수로 등록
(시스템 변수의 변수 Path 클릭 후, 편집 누르면 환경 변수 편집 창이 뜬다. 여기 마지막에 새로만들기 해서 아까 확인한 경로 붙여넣기!!!)
pytesseract 설치 : cmd창에서 pip install pytesseract 입력
29_tesseract.py
# OCR(Optical Character Recognition)
# 영상이나 문서에서 텍스트를 자동으로 인식하고 컴퓨터가 이행할 수 있는 텍스트 데이터로 변환하는 과정
# Tesseract, EasyOCR, PaddleOCR, CLOVA OCR(네이버 API), Cloud Vision(구글 API) ...
# Tesseract
# https://github.com/UB-Mannheim/tesseract/wiki
import cv2
import pytesseract
img = cv2.imread('./images/hello.png')
dst = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# lang = 'kor', lang='eng' , lang = 'kor+eng'
text = pytesseract.image_to_string(dst, lang='kor+eng')
print(text)안녕하세요 OCR
Hello OCR30_businesscard.py
import cv2
import pytesseract
import numpy as np
'''
[[903. 199.]
[179. 200.]
[159. 593.]
[938. 581.]]
'''
def reorderPts(pts):
idx = np.lexsort((pts[:, 1], pts[:, 0])) # lexsort((y, x)): x 기준 정렬 후 y 기준으로 재정렬
print(idx)
pts = pts[idx]
print(pts)
if pts[0, 1] > pts[1, 1]:
pts[[0, 1]] = pts[[1, 0]]
# pts[0]와 pts[1]은 둘 다 좌측에 있는 점들인데,
# 위쪽이 먼저 와야 하므로 y값(1번 인덱스)이 작은 쪽이 pts[0]이 되도록 바꿈.
if pts[2, 1] < pts[3, 1]:
pts[[2, 3]] = pts[[3, 2]]
# pts[2]와 pts[3]은 우측에 있는 점들인데,
# pts[2]는 우하단이 되어야 하므로 y값이 더 큰 쪽이 와야 함.
print(pts)
return pts
img = cv2.imread('./images/businesscard2.jpg')
dw, dh = 700, 400
srcQuad = np.array([[0, 0], [0, 0], [0, 0], [0, 0]], np.float32)
dstQuad = np.array([[0, 0], [0, dh], [dw, dh], [dw, 0]], np.float32)
dst = np.zeros((dh, dw), np.uint8)
src_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, src_bin = cv2.threshold(src_gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
contours, _ = cv2.findContours(src_bin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cpy = img.copy()
for pts in contours:
if cv2.contourArea(pts) < 500:
continue
approx = cv2.approxPolyDP(pts, cv2.arcLength(pts, True)*0.02, True)
cv2.polylines(cpy, [approx], True, (0, 255, 0), 2)
print(approx)
print(approx.reshape(4, 2).astype(np.float32))
srcQuad = reorderPts(approx.reshape(4, 2).astype(np.float32))
pers = cv2.getPerspectiveTransform(srcQuad, dstQuad)
dst = cv2.warpPerspective(img, pers, (dw, dh))
dst_gray = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY)
print(pytesseract.image_to_string(dst_gray, lang='kor+eng'))
cv2.imshow('img', img)
cv2.imshow('cpy', cpy)
cv2.imshow('dst', dst)
cv2.waitKey()
reorderPts(pts)함수는 OpenCV에서 투시 변환을 정확히 하기 위해,
입력된 네 개의 점(사각형 꼭짓점)의 순서를 재정렬하는 함수이다.
사각형 모양의 네 점 pts가 아무 순서로 들어와도,
항상 다음과 같은 순서로 정렬되도록 한다.[0] 좌상단 (Top-left) [1] 좌하단 (Bottom-left) [2] 우하단 (Bottom-right) [3] 우상단 (Top-right)이 순서대로 정렬해야
cv2.getPerspectiveTransform()이 제대로 동작한다.


[[[903 199]]
[[179 200]]
[[159 593]]
[[938 581]]]
[[903. 199.]
[179. 200.]
[159. 593.]
[938. 581.]]
[2 1 0 3]
[[159. 593.]
[179. 200.]
[903. 199.]
[938. 581.]]
[[179. 200.]
[159. 593.]
[938. 581.]
[903. 199.]]
ST. MARY'S 개개 ORTHOPEDICS
YY 성모튼튼 정형외과
송 금 비 도수치료사 /실장
서울 관악구 남현동 1057-22 HAYS 3S
(남부순환로 2056 남서울농협 3층)
Tel. 02.583.5544 Fax. 02.583.8181
도수치료실 070.4415.6114 Mobile. 010.4532.1687조금 틀린 것도 있지만 문자를 잘 인식한 것 같다.
31_lexsort.py
import numpy as np
# np.lexsort()
# 여러 개의 키 배열을 전달할 때, 맨 마지막 배열을 1차 기준, 그 앞의 배열을 그 다음 기준으로 삼아서 정렬
# 맨 뒤에 있는 배열이 가장 우선순위가 높음
# 결과는 정렬된 순서의 인덱스 배열
# np.lexsort((키2, 키1))
ndarr1 = np.array([1, 5, 1, 4, 4])
ndarr2 = np.array([9, 4, 0, 4, 0])
result = np.lexsort((ndarr2, ndarr1))
# 1, 1, 4, 4, 5
# 인덱스: 0, 2, 3, 4, 1
# ndarr1 값이 같은 경우 ndarr2로 비교
# [2, 0, 4, 3, 1]
print(result)
surnames = ('Hertz', 'Galilei', 'Hertz')
first_names = ('Heinrich', 'Galileo', 'Gustav')
result = np.lexsort((first_names, surnames))
# 1, 0, 2
# 1, 2, 0
print(result)
x = [
[1, 2, 3, 4],
[4, 3, 2, 1],
[2, 1, 4, 3]
]
y = [
[2, 2, 1, 1],
[1, 2, 1, 2],
[1, 1, 2, 1]
]
print(np.lexsort((x, y), axis=1))
# 2, 3, 0, 1
# 2, 0, 3, 1
# 1, 0, 3, 2
The light shines in the darkness.