Abstract
- Differential Neural Architecture Search 방법은 NAS 방법 중 가장 유명한 방법임
- 모델학습과 모델 서치를 같이하며
- 모델 파라메터를 공유하며
- gradient decent기반이기 때문에
- 간단하며, 효율적
- 서치 단계 마지막에는 가중치가 가장 큰 값을 가지는 operation이 선택된다.
- superent 최적화 방법은 많이 논의 되었지만, architecture selection 방법은 관심이 없음
- 아키텍처 가중치의 값의 크기는 모델의 성능과는 큰 관계가 없다는 이론적, 실험적 분석을 제공함
- perturbation-based architecture 선택 방법을 제안함
1. Introduction
배경
- NAS는 산업과 학계에서 수작업으로 이루어지는 고성능 모델 개발 프로세스를 자동화 시킬 수 있는 가능성 때문에 주목받아왔다
- DARTS는 end-to-end 방식의 gradient-decent 기반의 매우 효율적인 방식의 탐색을 한다.
- NAS는 continuous relxation(연속적 추정?)을 통해 이산적 방식의 모델 선택을 architecture parameter를 사용하여 연속적 방식으로 바꾸었다.
- supernet의 결과는 gradient 방식을 통해 optimized 될 수 있고 마지막에 가장 큰 parameter를 가지는 operation이 선택 된다.
- 간단한 ranodom search로 DART의 성능을 이룰 수 있다는 논문이 제기 되는 등 DARTS의 성능 및 효율성에 대한 의문이 계속 있어왔다.
- 하지만
the value of α가 operation의 예측력으로 쓰이는 상황에 대한 논의는 매우 조금밖에 이루어지지 않았다.
연구하면서 찾은 내용
- larger
α와 높은 validation accuracy는 별 관계가 없었다. - supernet 입장에서는 좋았던 skip connection이
α를 통한 모델 선택 이후에는 오히려 문제가 된다는 점
해결 방법
- an alternative perturbation-based architecture selection method
- Supernet에 대하여 가장 좋은 operation은 얼마나 많이 supernet의 accuracy를 혼란(perturb) 시킬 수 있는지에 따라 결정됨
결과
- 성능향상
- 기존의 robustness 문제 해결
2. BACKGROUND AND RELATED WORK
2-1 Preliminaries of Differentiable Architecture Search (DARTS)
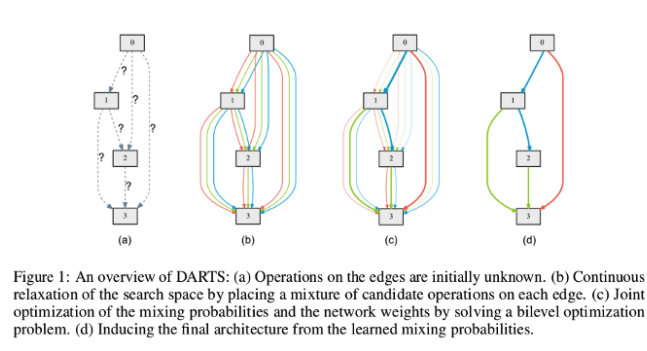
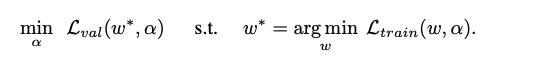
continuous relaxed network=supernet
2-2 Failure mode analysis of DARTS
- the robustness 가 부족함
- 다른 연구는 supernet 학습의 실패로 원인을 지적하고 있지만 저자는 selection 과정의 실패로 봄
2-3 Progressive search space shrinking
- NAS 연구의 한 줄기 중 점진적으로 탐색 공간을 줄여 탐색 비용을 줄여가는 방법이 존재한다.
α에 기반하여 operation이 큰 역할을 보이지 않으면 초반에 prune하는 방식이다.- 본 연구는 oprtaion이 얼마나 supernet에 기여하는지를 기반으로 모델을 선택하기 때문에 이 연구들과는 상관 없는 연구이다 .
3. THE PITFALL OF MAGNITUDE-BASED ARCHITECTURE SELECTION IN DARTS
- 이론적, 실험적으로
α크기는 별 도움 안 됨을 이 장에서 보임
3.1 α MAY NOT REPRESENT THE OPERATION STRENGTH
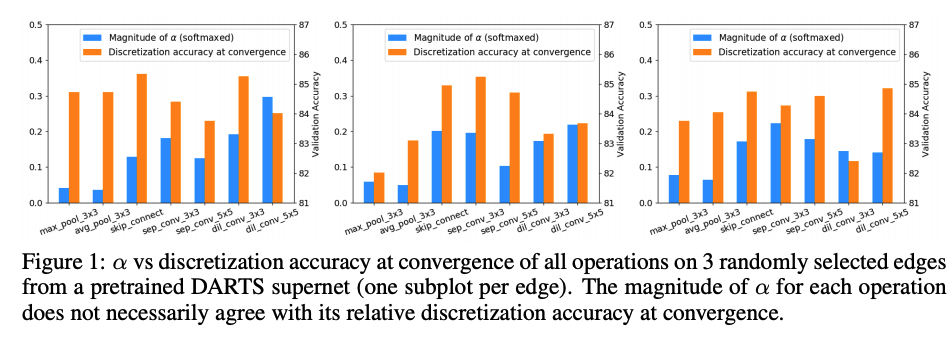
- 랜덤으로 선택했을 경우 operaion으로 인한 validation accuracy와
αmaginutde - 별 상관이 없다
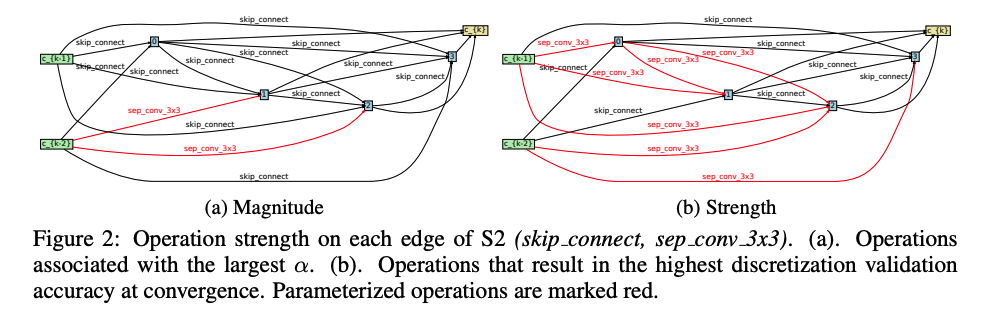
- search space S2 =
(skip connect, sep conv 3x3) - S2만 사용하여 DART를 학습하여
αmaginutde 기준으로 선택하면 Figure2 (a) 에서처럼 거의 모든 operaion이 skip connect가 되어 버린다. - 반면 operation의 strength 기반으로 선택하면 (b)와 같이 변한다.
3.2 A CASE STUDY: SKIP CONNECTION
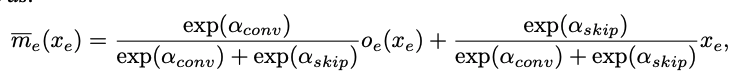
-
S2 =
(skip connect, sep conv 3x3)에서 특정 cell에서의 결과 값을 위와 같이 표현 가능 -
이때 cell이 계산해야할 최적의 값을 m*라고 하자
-
위식의 추정값은 m*와 같을 수록 좋으므로 아래 식을 최소화 하는
α를 구하면 된다 -
위식을 최소화 하는
α는 아래와 같은 특성을 가진다 -
생각해보면 학습이 잘 될 수록 모든 이전 layer가 학습이 잘 되었다면, 는 m*와 같은 값을 것이다.
- 따라서 conv의
α는variance식에 따라 계속 작아진다.
- 따라서 conv의
-
따라서 학습이 진행될 수록skip connection의 크기가 계속 증가될 수 밖에 없다.
-
잘생각해보면 x_e는 학습이 진행될 수록 m*와 값이 같아질 것이기 때문에 모델은 이를 활용하기 위해 skip의
α를 계속 키울 것이다.
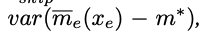
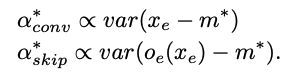
4. PERTURBATION-BASED ARCHITECTURE SELECTION
α 가 모델을 선택하게 하는 대신에 operation의 strength를 측정하여 모델 선택을 함
- operation을 마스킹한 후 학습을 하였을 때 supernet의 accuracy가 떨어지는 정도를 stength로 정의함

5. EXPERIMENTAL RESULTS
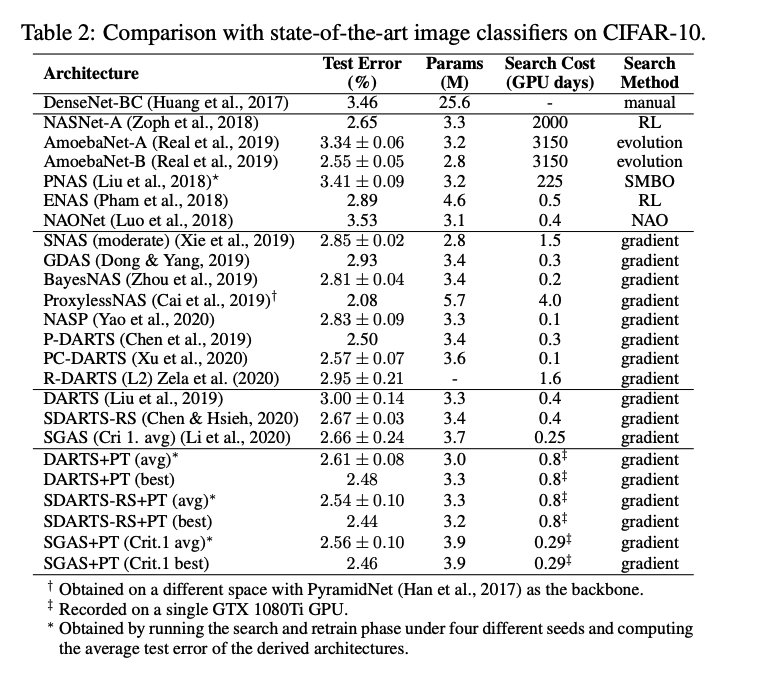
5.1 RESULTS ON DARTS’ CNN SEARCH SPACE
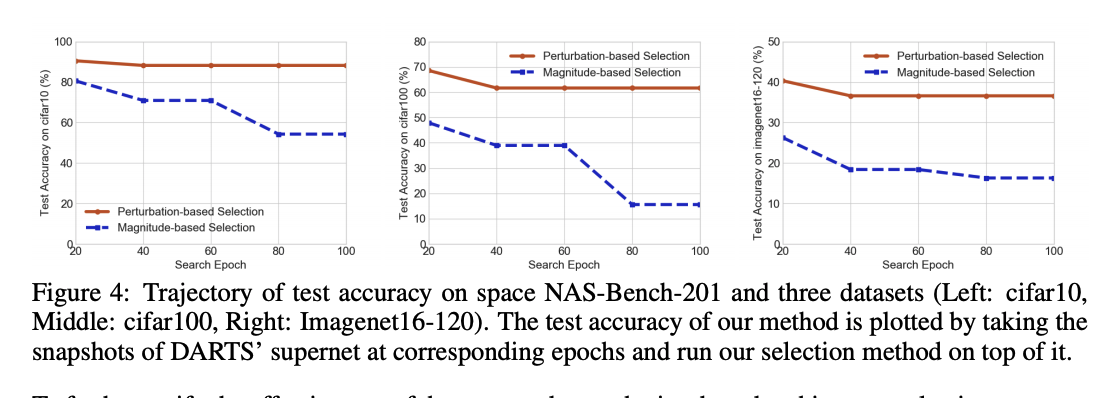
5.2 PERFORMANCE ON NAS-BENCH-201 SEARCH SPACE

Machine Learning Engineer: recsys, mlops