Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
국민대학교 인공지능학회 (XAI)
Abstract
기존 object detection 시스템(Fast R-CNN 포함)은 Region Proposal 단계가 병목 현상이 존재한다. 이를 해결하기 위해 제안된 것이 Region Proposal Network (RPN) :
- Fully convolutional 구조로 이미지 전역에서 objectness score와 bounding box를 동시에 예측한다.
- Fast R-CNN과 convolutional layer를 공유하여 region proposal을 거의 비용없이 생성한다.
region proposal network와 fast r-cnn을 통합하여 end-to-end 학습이 가능해진다.
일종의 attention 매커니즘처럼 RPN이 “어디에 집중할지(볼지)” 알려준다.
요약하면, Faster R-CNN은 정확도와 구조 최적화의 대표 모델이며 YOLO보다 느리지만 더 정밀한 detection을 목표로하는 시스템이다.
여기서 region proposal의 단계가 뭔지 몰라서 찾아봤다.
Region Proposal 단계란?
사전적 정의로는 이미지 안에 객체가 있을 법한 위치(영역)을 먼저 후보로 먼저 찾는 과정이다. 이건 object detection 파이프라인에서 가장 처음에 수행되는 중요한 단계라고 나와있었다.
- 전체 이미지에는 객체가 있을 수도 있고 없을 수도 있는 수많은 영역이 있습니다. 이 중에서 객체가 있을 가능성이 높은 영역들만 후보(region proposals)로 추려내는 과정이 필요하다.
- 이후 단계는 이 후보들만 분류 및 박스 보정을 수행하기 때문에 숙도와 성능에 큰 영향을 준다.
예전 방식 (전통적인 Region Proposal)
| 방법 | 설명 |
|---|---|
| Selective Search | 색상, 텍스처, 형태 등을 기반으로 유사한 영역을 병합해 객체 후보 영역을 생성함 (비학습 방식) |
| EdgeBoxes, MCG 등 | 경계(edge) 기반으로 가능한 객체 영역 추출 |
이런 방식들은 느리고, 딥러닝과 별개로 동작한다.
RPN의 등장으로 바뀐 점
Faster R-CNN에서는 Region Proposal을 위해 별도 알고리즘을 쓰지 않고, CNN 내부에서 학습 가능한 RPN(Region Proposal Network)을 사용합니다:
- 이미지 feature map 위에서 각 위치(anchor)에 대해:
- Object일 확률 (objectness score)
- Bounding box 좌표 조정값를 함께 예측합니다.
- 이걸 통해 빠르고 정확하게 region proposals를 생성할 수 있습니다.
1. Introduction
Region Proposal Network (RPN)이라는 네트워크를 제안한다. 이 RPN은 이미지 전체를 보는 CNN featur를 Fast R-CNN과 공유하면서 거의 공짜 수준의 계산으로 region proposal을 생선한다. 쉽게 다시 말하면 원래는 별도로 제안하던 객체 후보 위치를 CNN이 한 번 돌 때 한번에 뽑아버리는 구조다.
RPN은 fully convolutional한 구조로 되어 있어서 이미지 위를 슬라이딩하며 각 위치에서 객체일 확률(objectness)과 박스 좌표를 동시에 예측한다. 그리고 이렇게 뽑은 proposal들을 Fast R-CNN이 받아서 분류와 정밀한 박스 조정을 해주는 방식으로 동작한다. 이 구조 때문에 전체 모델은 빠르면서도 높은 정확도를 유지할 수 있었다.
2. Related Works
RPN은 완전한 합성곱 신경망 구조를 사용하여, 이미지 내의 각 위치에서 객체일 확률과 그 위치의 bounding box를 동시에 예측한다.
이 RPN은 기존 detection 네트워크인 Fast R-CNN과 convolutional feature를 공유하여 proposal을 생성하므로, 계산 비용이 매우 낮다.
그리고 RPN은 각 위치마다 여러 크기와 비율의 anchor box를 사용한다. 각 anchor에 대해 objectness와 box 위치를 예츠갛ㄴ다. 이렇게 뽑은 proposal을 Fast R-CNN이 받아 분류와 회귀를 수행한다. RPN과 Fast R-CNN을 하나의 네트워크로 통합해 학습할 수 있었다.
RPN과 Fast R-CNN을 통합하여 하나의 end-to-end 네트워크로 학습할 수 있으며, 이 구조를 통해 속도와 정확도를 동시에 향상시킬 수 있다.
VGG-16을 기반으로 할 때 전체 시스템은 GPU에서 5fps 속도를 달성하고, PASCAL VOC 및 MS COCO 데이터셋에서 state-of-the-art 성능을 기록하였다.
Faster R-CNN은 ILSVRC와 COCO 2015 대회에서 1위를 차지한 모델들의 기반이 되었으며, 다양한 비전 과제에 확장 가능함을 보였다.
Network 구조
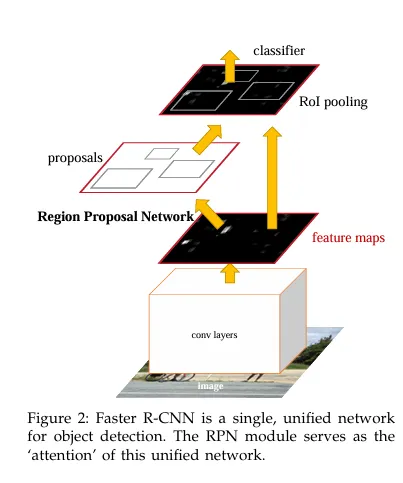
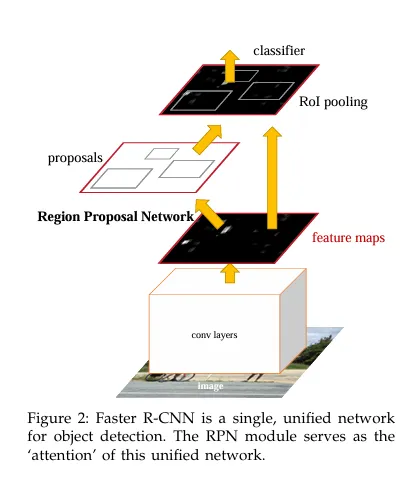
- 원본 이미지를 pre-trained된 CNN 모델에 입력하여 feature map이 추출된다.
- featuer map은 RPN에 전달되어 적절한 region proposals을 산출합니다.
- Region proposals와 1번째 과정에서 얻은 feature map을 통해 RoI pooling을 수행하여 고정된 크기의 feature map을 얻는다.
- Fast R-CNN 모델에 고정된 크기의 feature map을 입력하여 classification과 Bounding box regression을 수행한다.
이 그림은 Faster R-CNN이 하나의 CNN feature map을 공유하면서 RPN으로 후보를 만들고 RoI pooling을 통해 분류와 박스 예측까지 이어지는 통합구조를 보여준다.
RPN이 이 unified network에서 어디를 볼지 결정하는 attention 역할을 수행한다.
3.1 Region Proposal Networks
위에서 많이 언급했지만 더 상세하게 설명하는 부분이다. RPN은 입력 이미지로 부터 사각형 형태의 객체 후보 영역(proposal)들과 각 proposal에 대한 objectness score를 출력하는 네트워크이다. 이 구조는 fully convolutional network로 설계되었으며 Fast R-CNN과 convolution layer를 고유하도록 되어 있다. 실험에서는 ZF모델과 VGG16 모델을 사용하며 이들은 각각 5개 13개의 공유 가능한 conv layer를 가진다.
region proposal을 생성하기 위해 feature map 위를 작은 네트워크가 슬라이딩하며 지나간다. 이 작은 네트워크는3x3 크기의 지역 receptive field를 입력으로 받아서 먼저 256차원(ZF) or 512차원(VGG)의 feature로 변환한 후 두 개의 sibling layer에 전달 된다.
하나는 box regression을 수행하고 다른 하나는 objectness classification을 수행한다.
이 구조는 모든 위치에 대해 동일한 파라미터를 공유하며 실제 구현은 3x3 conv + 두 개의 1x1 conv layer로 구성된다.
3.1.1 Anchors
RPN은 feature map 위를 슬라이딩하면서 각 위치마다 여러 개의 bounding box를 예측한다. 이를 위해 각 위치에서 k개의 anchor box를 기준으로 예측을 수행한다. anchor는 특정 scale과 aspect ratio를 갖는 기준 박스이며 해당 위치를 중심으로 다양한 크기와 비율의 박스들이 생성된다. 논문에서는 3개의 scale(128², 256², 512²)과 3개의 aspect ratio (1:1, 1:2, 2:1)를 사용하여 각 위치마다 총 9개의 anchor(k=9)를 생성한다.
이러한 anchor들은 하나의 conv feature map에서 다양한 크기/비율의 객체를 예측할 수 있도록 한다 anchor는 이미지 내의 객체에 대한 회귀 기준점으로 사용되고 학습 시 각 anchor는 정답 박스와의 IoU를 기준으로 positive, negative로 라벨링된다.
3.1.2 Loss Function
RPN은 각 anchor마다 (1) 객체인지 아닌지 분류, (2) 박스 위치 조정(회귀) 두 가지 작업을 수행하므로 손실 함수도 이를 반영한 multi-task loss 구조를 사용한다.
📌 라벨 할당 기준:
- Positive (1):
- (i) 정답 박스와 IoU가 가장 높은 anchor
- (ii) IoU ≥ 0.7인 anchor
- Negative (0):
- 모든 정답 박스에 대해 IoU ≤ 0.3인 anchor
- 중간 범위는 무시하여 학습에 사용하지 않는다.
📌 Loss 함수:
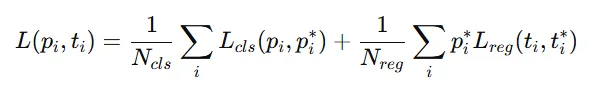
- : 예측한 objectness score
- : 정답 (1 or 0)
- : 예측/정답 박스 회귀 파라미터
- classification은 binary cross-entropy,
- regression은 smooth L1 loss를 사용한다.
3.1.3 Training RPNs
BPN은 end-to-end로 학습 가능한 구조이며 역전파와 SGD를 통해 학습한다. 학습 시에는 Fast R-CNN에서 사용한 것과 동일한 image-centric 샘플링 전략을 따른다.
한 번의 mini-batch는 이미지 한 장에서 나온 anchor들로 구성된다. 한 번의 mini-batch는 이미지 한 장에서 나온 anchor들로 구성된다. 전체 anchor 중 negative가 훨씬 많기 때문에 임의로 256개의 anchor만 샘플링하여 학습에 사용한다.
positive : negative 비율은 최대 1 : 1로 유지하며 positive anchor가 128개보다 적으면 나머지는 negative로 채운다.
RPN에 새로 추가된 layer는 평균 0, 표준 편차 0.01의 정규분포로 랜덤 초기화 한다. 공유되는 conv layer는 ImageNet 분류용으로 사전학습된 가중치를 사용한다. ZF 모델은 전체 layer를 학습하고 VGG 모델은 conv3_1 이후의 layer만 학습한다. (메모리 절약 목표)
- learning rate : 0.0001 (60k mini-batches), 이후 0.0001 (20k mini-batches)
- momentum : 0.9
- weight decaty : 0.0005
하이퍼파라미터는 이렇게 조정하고 프레임워크는 Caffe를 사용하여 구현했다.
3.2 Sharing Features for RPN and Fast R-CNN
지금까지는 RPN을 단독으로 학습하는 방식에 대해 설명했지만 실제로는 RPN이 만든 proposal을 Fast R-CNN이 사용하므로 두 네트워크는 하나의 CNN feature를 공유해야한다. 하지만 RPN과 Fast R-CNN을 따로 학습하면 conv layer의 파라미터가 서로 다르게 업데이트되므로 이를 토앟ㅂ하여 학습할 수 있는 방법이 필요하다.
논문에서는 convolutional layer를 공유하면서 학습하는 세 가지 방식을 제안한다.
(1) Alternating Training
- RPN을 먼저 학습한다.
- RPN이 만든 proposal로 Fast R-CNN을 학습한다.
- 학습된 Fast R-CNN의 conv layer를 고정하고 RPN만 다시 학습한다.
- 다시 Fast R-CNN의 고유 계층만 fine-tuning을 한다.
이 과정을 통해 두 네트워크가 공통된 conv layer를 공유하는 통합 네트워크가 완성된다.
논문에서는 실험에 이 방식을 사용한다.
(2) Approximate Joint Training
RPN과 Fast R-CNN을 하나의 네트워크로 결합하여 함께 학습한다. 각 training iteration에서 RPN이 region proposal을 생성하고, Fast R-CNN이 이를 사용해 detection loss를 계산한다. backpropagation 시에는 두 loss가 공유된 conv layer에 모두 전달된다.
다만 이 방식은 proposal box 좌표에 대한 gradient를 무시하므로 근사 방식이다. 그럼에도 불구하고 학습 속도가 25~50% 빨라지며 성능도 유사하다. 논문에서 공개한 python 코드에서는 이 방식을 사용한다.
(3) Non-Approximate Joint Training
이 방식은 proposla box 좌표에 대해서도 gradient를 전달하는 이론적으로 완전한 방식이다. 이를 위해 RoI pooling layer가 box 좌표에 대해 미분 가능해야 하며, 이를 가능하게 하려면 RoI warping 기법이 필요하다. 하지만 구현이 복잡하므로 논문에서 다루지 않음
(1).4 Alternating Training 요약
- ImageNet으로 초기화된 RPN을 학습한다.
- RPN의 proposal로 Fast R-CNN을 학습한다.
- Fast R-CNN의 conv layer를 고정하고 RPN을 다시 학습한다.
- 공유된 conv layer는 고정하고 Fast R-CNN의 나머지 계층만 fine-tuning한다.
이 과정을 통해 최종적으로 두 네트워크는 같은 feature를 공유하며 동작하는 통합된 객체 탐지 시스템이 된다.
3.3 Implementation Details
Faster R-CNN은 학습과 테스트 모두 단일 크기의 이미지를 사용한다.
입력 이미지는 짧은 변의 길이가 600픽셀이 되도록 리사이즈된다.
다중 스케일 이미지 피라미드를 사용하는 방식은 성능은 향상되지만 속도 측면에서 비효율적이라 사용하지 않는다.
ZF와 VGG 네트워크는 마지막 convolution layer까지의 stride가 16픽셀이다.
이 말은 리사이즈되기 전 일반적인 PASCAL VOC 이미지 기준으로는 약 10픽셀 간격으로 feature가 추출된다는 의미이다.
stride가 크더라도 성능은 좋게 유지되며, stride를 더 작게 조정하면 성능이 더 좋아질 수 있다.
anchor는 3개의 스케일(128², 256², 512²)과 3개의 aspect ratio(1:1, 1:2, 2:1)를 사용하여 총 9개의 anchor를 만든다.
이 설정은 특정 데이터셋에 맞춰 조정된 것이 아니며, 다음 섹션에서 이에 대한 ablation 실험을 수행한다.
이 구조는 이미지 피라미드나 필터 피라미드 없이도 다양한 크기와 비율의 객체를 처리할 수 있다.
또한 feature map의 receptive field보다 더 큰 객체도 예측할 수 있다.
학습 중에는 이미지 경계를 넘어가는 anchor는 loss 계산에서 제외한다.
예를 들어 1000×600 이미지에서는 약 60×40×9 = 21,600개의 anchor가 생성되며,
경계를 넘는 anchor를 제외하면 약 6,000개의 anchor만 학습에 사용된다.
경계 넘는 anchor를 학습에 포함시키면 에러가 커지고 학습이 수렴하지 않기 때문이다.
테스트 시에는 전체 이미지에 대해 RPN을 적용하고,
경계를 넘는 proposal이 생기면 이를 이미지 범위 내로 clipping한다.
