1. Data-Centric
AI 서비스가 현업에서 진행되는 과정
1. 프로젝트 정의
2. 데이터셋 준비
3. 모델의 학습과 디버깅
4. 배포 및 유지보수
각 기업 마다 다르지만 위 4가지는 꼭 들어간다.
그리고 모델 자체의 개발도 중요하지만, 프로젝트의 8할은 데이터가 차지하고 있으며 나머지 2할에서도, AI 서비스 자체가 모델 자체는 가져오는 경우가 많아서 어떻게 배포하고 유지보수할 지가 중요한 경우가 많다.
따라서 AI 프로젝트에서 가장 중요한 것은 바로 앞서 말한 Data-Centric한 접근법이라고 할 수 있다.
2. Data-Centric한 적용점들
Data Management: 새로운 데이터 수집
Data Augmentation: 데이터 증강
Data Filtering: 데이터 필터링
Synthetic Data: 합성 데이터
Label Consistency: 라벨링 방법 체계화
Data Consistency, Data Tool: 라벨링 Tool
위의 적용점들은
Data Quality Control
Data Augmentation
Synthetic Data 를 통한 모델 성능 향상의 향상이라고 할 수 있으며
학습 전략적인 측면에 있어서도
Curriculum Learning: 쉬운 데이터에서 어려운 데이터로 학습 순서 진행
Active Learning : 머신러닝 모델이 학습에 사용될 데이터 중에서 가장 유익한 데이터를 선택하여 레이블링 하는 방식
등의 방법을 활용하여 모델의 성능을 향상시킬 수 있다.
(이 외에도 데이터를 활용하여 모델의 성능지표를 개발할 수 있다.)
이외 구체적 예시들
- Outlier Detection and Removal (데이터셋에서 비정상적인 예시 처리)
- Error Detection and Correction (잘못된 데이터 및 레이블을 수정)
- Data Augmentation (adding examples to data to encode prior knowledge)
- Feature Engineering and Selection (데이터 표현 방식의 수정)
- Establishing Consensus Labels (크라우드 소싱된 데이터들에서 합의를 통해 진짜 라벨 설정)
3. 현실세계에서의 Data-Centric AI
3.1 Data-Flywheel
Data-Flywheel이란 특정 제품이 서비스되는 상황 속에서 쌓이는 Logging 데이터 등을 기반으로 서비스가 진행 될 수록 모델의 성능이 함께 높아지는 어떤 선순환 생태계라고 정의할 수 있다.
데이터 기반으로 모델과 상호작용 하며 여러 itteration을 돌며 모델과 데이터의 Quality가 높아지는 것
3.2 DMOps
1. Schema Design
2. Collection
3. Annotation
4. Evaluation
5. Versioning
Data Labeling Tool 또한 굉장히 중요하다.
Human FeedBack Data로 각 과정에서 충분히 Qualified 된 데이터를 얻는 것 또한 중요
4. 학계에서 데이터를 다루기 힘든 이유
데이터는 아직 미지의 영역이다.
프로젝트에 맞는 데이터 자체가 구하기 힘들고 접하는 것 조차 쉽지가 않다.
대개 데이터에 맞추어 프로젝트가 진행되기 때문
라벨링 작업에 대한 정해진 정답이 없으며 비용이 크다
무작정 많이 라벨링한다고 좋은 것은 아니다. 라벨링 노이즈가 생길 수 있으며, 구체적으로 정해진 정답이 없는 경우가 많아서 라벨러에 따라 라벨링이 다른 경우가 많다. 그리고 비용이 크다.
좋은 데이터를 만들려면?
일관성있는 라벨링과주요 케이스가 포함되어 있으며예상치 못한 케이스까지 포괄하는적절한 크기의 데이터가 중요하다.
Label Consistence
특이 Case에 대한 포괄성
데이터 양 그자체가 중요한 것이 아니라, 데이터의 질이 중요한 것!
적당한 크기의 데이터를 확보했다면, 해당 데이터의 Quality를 높히고 해당 데이터가 균등한지를 파악하여 적은 양이더라도 Balanace가 유지된 데이터셋으로 만들어주는 것이 필요하다.
라벨링 노이즈의 세기와 샘플 수는 역의 관계에 있다.
애당초 학계는 정해진 데이터셋(고정된 환경)이 중요하다.
이점이 바로 현실세계와의 차이점이다.
현실세계에서는 직접 데이터를 수집해야하는 경우도 많으며 프로젝트 또는 제품이 실행되는 환경 자체가 이미 설정한 가상환경과 같이 통제되지 않은 경우가 많다.
학계는 그러한 통제되지 않은 변수들로 가득한 데이터로 연구를 진행할 수 없기에 현실세계와의 간극이 존재한다.
5. 학계와 현실세계의 간극을 줄이기 위한 시도: DataPerf
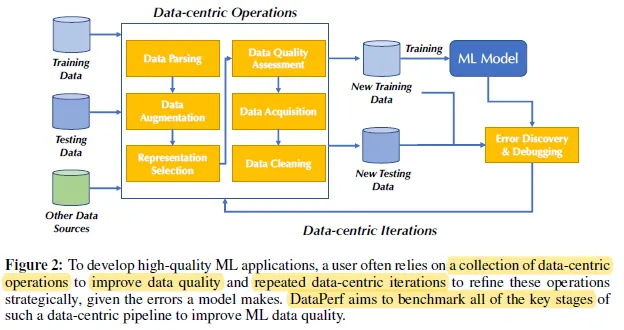
출처 : https://sh-tsang.medium.com/dataperf-benchmarks-for-data-centric-ai-development-aba9f8b1f22d
- 목표
- ML 데이터 품질 향상을 위하여 Data-Centric 파이프라인의 주요 단계를 벤치마크하고
- 데이터셋을 쉽고 반복 가능하게 유지 관리 및 평가한다.
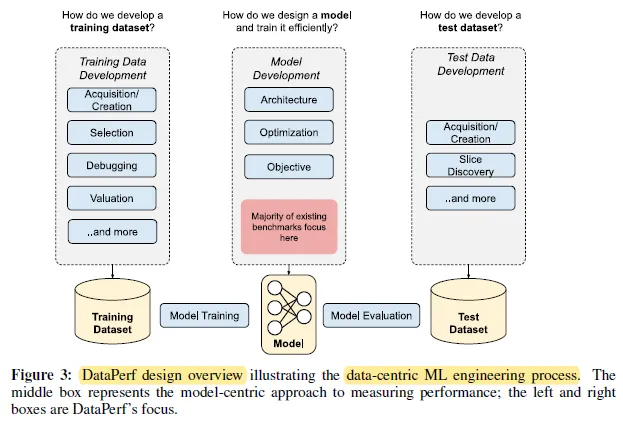
출처 : https://sh-tsang.medium.com/dataperf-benchmarks-for-data-centric-ai-development-aba9f8b1f22d
- DataPerf Design
- Data-Centric ML 엔지니어링 과정을 나타내며
- 모델은 고정하고, 데이터셋만 개선하여 정확도를 향상시킬 수 있는 벤치마크 Task를 정한다.
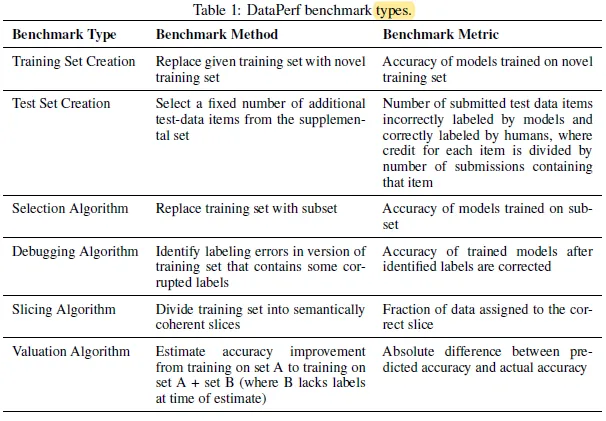
출처 : https://sh-tsang.medium.com/dataperf-benchmarks-for-data-centric-ai-development-aba9f8b1f22d
위 표는 DataPerf의 BenchMark types를 나열한 것으로 한국어로 번역하면
| 벤치마크 유형 | 벤치마크 방법 | 벤치마크 메트릭 |
|---|---|---|
| 훈련 세트 생성 | 주어진 훈련 세트를 새로운 훈련 세트로 교체 | 새로운 훈련 세트로 훈련된 모델의 정확도 |
| 테스트 세트 생성 | 보충 세트에서 추가 테스트 데이터 항목을 고정된 수로 선택 | 모델과 사람이 잘못 레이블링한 제출된 테스트 데이터 항목의 수. 각 항목에 대한 크레딧은 해당 항목을 포함한 제출 횟수로 나누어짐 |
| 선택 알고리즘 | 훈련 세트를 부분 집합으로 교체 | 부분 집합으로 훈련된 모델의 정확도 |
| 디버깅 알고리즘 | 일부 손상된 레이블이 포함된 훈련 세트 버전에서 레이블 오류 식별 | 식별된 레이블이 수정된 후 훈련된 모델의 정확도 |
| 슬라이싱 알고리즘 | 훈련 세트를 의미론적으로 일관된 그룹으로 나누기 | 올바른 그룹에 할당된 데이터의 비율 |
| 평가 알고리즘 | 세트 A에서 훈련된 모델의 정확도와 세트 A + B(이때 B는 추정 시 레이블이 없음)에서 훈련된 모델의 정확도 차이를 추정 | 예측된 정확도와 실제 정확도의 절대 차이 |
위 표와 같다.
참고 사이트
https://sh-tsang.medium.com/dataperf-benchmarks-for-data-centric-ai-development-aba9f8b1f22d
